Privacy Scholarship Research Reporter: Issue 3, December 2017 – 2017 Privacy Papers for Policymakers Award Winners
Notes from FPF
On December 12, 2017, FPF announced the winners of our 8th Annual Privacy Papers for Policymakers (PPPM) Award. This Award recognizes leading privacy scholarship that is relevant to policymakers in the United States Congress, at U.S. federal agencies, and for data protection authorities abroad.
In this special issue of the Scholarship Reporter, you will find this year’s six winning papers. From the many nominated privacy-related papers published in the last year, these six were selected by Finalist Judges, after having been first evaluated highly by a diverse team of academics, advocates, and industry privacy professionals from FPF’s Advisory Board. Finalist Judges and Reviewers agreed that these papers demonstrate a thoughtful analysis of emerging issues and propose new means of analysis that can lead to real-world policy impact, making them the “must-read” privacy scholarship today.
This year’s winning papers grapple with a range of issues critical to regulators. The papers analyze broad conceptions of how regulators, markets, and society at large consider different conceptions of privacy, prompting the reader to think critically about assumed paradigms.
Striking the balance between foundational analysis and narrower proposals, “Artificial Intelligence Policy: A Roadmap and Primer,” outlines the role of artificial intelligence in law and policy, and how relevant governance strategies should develop. “Designing Against Discrimination in Online Markets” taxonomizes design and policy strategies for diminishing discriminatory mechanisms in online platforms and “Health Information Equality” proposes mechanisms to prevent the disproportionate effects of secondary health data usage on vulnerable populations.
“The Public Information Fallacy” argues that the definition of “public information” is unsettled and hazy, meriting a more rigorous analysis of the definition in legal determinations and policy discourse. In “The Undue Influence of Surveillance Technology Companies on Policing,” the author argues that the role of surveillance technology companies must be curtailed to facilitate meaningful transparency about how that technology is used by police departments. “Transatlantic Data Privacy Law”, calls for a coalesced understanding of how privacy is conceptualized between the rights-based model in Europe and the marketplace-based model in the United States.
As always, we would love to hear your feedback on this issue. You can email us at [email protected].
Jules Polontetsky, CEO, FPF
Artificial Intelligence Policy: A Primer and Roadmap
R. CALO
This paper provides a roadmap (not the road) to the major policy questions presented by AI today. The goal of the essay is to give sufficient detail to describe the challenge of AI without providing the policy outcome. It discusses the contemporary policy environment around AI and the key challenges it presents including: justice and equality; use of force; safety and certification; privacy and power; and taxation and displacement of labor. As it relates to privacy in particular, the author posits that the acceleration of artificial intelligence, which is intimately tied to the availability of data, will play a significant role in this evolving conversation in at least two ways: (1) the problem of pattern recognition and (2) the problem of data parity.
Authors’ Abstract
Talk of artificial intelligence is everywhere. People marvel at the capacity of machines to translate any language and master any game. Others condemn the use of secret algorithms to sentence criminal defendants or recoil at the prospect of machines gunning for blue, pink, and white-collar jobs. Some worry aloud that artificial intelligence will be humankind’s “final invention.”
This essay, prepared in connection with UC Davis Law Review’s 50th anniversary symposium, explains why AI is suddenly on everyone’s mind and provides a roadmap to the major policy questions AI raises. The essay is designed to help policymakers, investors, technologists, scholars, and students understand the contemporary policy environment around AI at least well enough to initiate their own exploration.
Topics covered include: Justice and equity; Use of force; Safety and certification; Privacy (including data parity); and Taxation and displacement of labor. In addition to these topics, the essay will touch briefly on a selection of broader systemic questions: Institutional configuration and expertise; Investment and procurement; Removing hurdles to accountability; and Correcting mental models of AI.
Designing Against Discrimination in Online Markets
K. EC LEVY, S. BAROCAS
This article provides a conceptual framework for understanding how platforms’ design and policy choices introduce opportunities for users’ biases to affect how they treat one another. Through empirical review of design-oriented interventions used by a range of platforms, and the synthesis of this review into a taxonomy of thematic categories, the authors hope to prompt greater reflection on the stakes of such decisions made by platforms already, guide platforms’ future decisions, and provide a basis for empirical work measuring the impacts of design decisions on discriminatory outcomes. In Part I, the empirical review of platforms is described, and the strategies used to develop the taxonomy are presented. In Part II, the ten thematic categories that emerged from this review are detailed, and how platforms’ design interventions might mediate or exacerbate users’ biased behaviors is discussed. Part III describes the ethical dimensions of platforms’ design choices.
Authors’ Abstract
Platforms that connect users to one another have flourished online in domains as diverse as transportation, employment, dating, and housing. When users interact on these platforms, their behavior may be influenced by preexisting biases, including tendencies to discriminate along the lines of race, gender, and other protected characteristics. In aggregate, such user behavior may result in systematic inequities in the treatment of different groups. While there is uncertainty about whether platforms bear legal liability for the discriminatory conduct of their users, platforms necessarily exercise a great deal of control over how users’ encounters are structured—including who is matched with whom for various forms of exchange, what information users have about one another during their interactions, and how indicators of reliability and reputation are made salient, among many other features. Platforms cannot divest themselves of this power; even choices made without explicit regard for discrimination can affect how vulnerable users are to bias. This Article analyzes ten categories of design and policy choices through which platforms may make themselves more or less conducive to discrimination by users. In so doing, it offers a comprehensive account of the complex ways platforms’ design choices might perpetuate, exacerbate, or alleviate discrimination in the contemporary economy.
This paper posits that the ability to collect and aggregate data about patients — including physical conditions, genetic information, treatments, responses, and outcomes — is changing medical research today. The author states that the collection of such information raises serious ethical concerns because it imposes special burdens on specific patients whose records form the data pool for queries and analyses. This article argues that laws should distribute information burdens across society in a just manner. Part I lays out how new laws and policies are facilitating the disproportionate collection and public use of data. Part II details the kinds of burdens such practices can impose. Part III provides an ethical framework to assess these inequities. Part IV then shows what regulatory and statutory levers can be used to render secondary research more equitable. Finally, the author outlines a framework to reorganize privacy risk in ways that are ethical and just. Where bioethics has sought only to incorporate autonomy concerns in health data collection, this framework provides a guide for moving beyond autonomy to equity concerns.
Authors’ Abstract
In the last few years, numerous Americans’ health information has been collected and used for follow-on, secondary research. This research studies correlations between medical conditions, genetic or behavioral profiles, and treatments, to customize medical care to specific individuals. Recent federal legislation and regulations make it easier to collect and use the data of the low-income, unwell, and elderly for this purpose. This would impose disproportionate security and autonomy burdens on these individuals. Those who are well-off and pay out of pocket could effectively exempt their data from the publicly available information pot. This presents a problem which modern research ethics is not well equipped to address. Where it considers equity at all, it emphasizes underinclusion and the disproportionate distribution of research benefits, rather than overinclusion and disproportionate distribution of burdens.
I rely on basic intuitions of reciprocity and fair play as well as broader accounts of social and political equity to show that equity in burden distribution is a key aspect of the ethics of secondary research. To satisfy its demands, we can use three sets of regulatory and policy levers. First, information collection for public research should expand beyond groups having the lowest welfare. Next, data analyses and queries should draw on data pools more equitably. Finally, we must create an entity to coordinate these solutions using existing statutory authority if possible. Considering health information collection at a systematic level—rather than that of individual clinical encounters—gives us insight into the broader role that health information plays in forming personhood, citizenship, and community.
The goal of this article is to highlight the many possible meanings of “public” and make the case to clarify the concept in privacy law. The main thesis is that because there are so many different possible interpretations of “public information,” the concept cannot be used to justify data practices and surveillance without first articulating a more precise meaning that recognizes the values affected. The author believes the law of public information has failed to clarify whether the concept is a description, a designation, or just another way of saying something is “not private.” In this document, a review of the law and discourse of public information is provided, a survey of the law and literature to propose three different ways to conceptualize “public information” is discussed and finally, a case for clarity is made.
Authors’ Abstract
The concept of privacy in “public” information or acts is a perennial topic for debate. It has given privacy law fits. People struggle to reconcile the notion of protecting information that has been made public with traditional accounts of privacy. As a result, successfully labeling information as public often results in a free pass for surveillance and personal data practices. It has also given birth to a significant and persistent misconception—that public information is an established and objective concept.
In this article, I argue that the “no privacy in public” justification is misguided because nobody even knows what “public” even means. It has no set definition in law or policy. This means that appeals to the public nature of information and contexts in order to justify data and surveillance practices is often just guesswork. Is the criteria for determining publicness whether it was hypothetically accessible to anyone? Or is public information anything that’s controlled, designated, or released by state actors? Or maybe what’s public is simply everything that’s “not private?”
The main thesis of this article is that if the concept of “public” is going to shape people’s social and legal obligations, its meaning should not be assumed. Law and society must recognize that labeling something as public is both consequential and value-laden. To move forward, we should focus the values we want to serve, the relationships and outcomes we want to foster, and the problems we want to avoid.
The Undue Influence of Surveillance Technology Companies on Policing
E. E. JOH
This essay identifies three recent examples in which surveillance technology companies have exercised undue influence over policing: stingray cellphone surveillance, body cameras, and big data programs. By “undue influence,” the author is referring to the commercial self-interest of surveillance technology vendors that overrides principles of accountability and transparency normally governing the police. The article goes on to examine the harms that ensue when this influence goes unchecked, and suggests some means by which oversight can be imposed on these relationships.
Authors’ Abstract
Conventional wisdom assumes that the police are in control of their investigative tools. But with surveillance technologies, this is not always the case. Increasingly, police departments are consumers of surveillance technologies that are created, sold, and controlled by private companies. These surveillance technology companies exercise an undue influence over the police today in ways that aren’t widely acknowledged, but that have enormous consequences for civil liberties and police oversight. Three seemingly unrelated examples — stingray cellphone surveillance, body cameras, and big data software—demonstrate varieties of this undue influence. The companies which provide these technologies act out of private self-interest, but their decisions have considerable public impact. The harms of this private influence include the distortion of Fourth Amendment law, the undermining of accountability by design, and the erosion of transparency norms. This Essay demonstrates the increasing degree to which surveillance technology vendors can guide, shape, and limit policing in ways that are not widely recognized. Any vision of increased police accountability today cannot be complete without consideration of the role surveillance technology companies play.
In this paper, the authors state that because of data restrictions of two major EU mandates, bridging the transatlantic data divide is a matter of the greatest significance. On the horizon is a possible international policy solution around “interoperable,” or shared legal concepts. President Barack Obama and the Federal Trade Commission (FTC) promoted this approach. The extent of EU–U.S. data privacy interoperability, however, remains to be seen. In exploring this issue, this article analyzes the respective legal identities constructed around data privacy in the EU and the United States. It identifies profound differences in the two systems’ image of the individual as bearer of legal interests.
Authors’ Abstract
International flows of personal information are more significant than ever, but differences in transatlantic data privacy law imperil this data trade. The resulting policy debate has led the EU to set strict limits on transfers of personal data to any non-EU country—including the United States—that lacks sufficient privacy protections. Bridging the transatlantic data divide is therefore a matter of the greatest significance.
In exploring this issue, this Article analyzes the respective legal identities constructed around data privacy in the EU and the United States. It identifies profound differences in the two systems’ images of the individual as bearer of legal interests. The EU has created a privacy culture around “rights talk” that protects its “data subjects.” In the EU, moreover, rights talk forms a critical part of the postwar European project of creating the identity of a European citizen. In the United States, in contrast, the focus is on a “marketplace discourse” about personal information and the safeguarding of “privacy consumers.” In the United States, data privacy law focuses on protecting consumers in a data marketplace.
This Article uses its models of rights talk and marketplace discourse to analyze how the EU and United States protect their respective data subjects and privacy consumers. Although the differences are great, there is still a path forward. A new set of institutions and processes can play a central role in developing mutually acceptable standards of data privacy. The key documents in this regard are the General Data Protection Regulation, an EU-wide standard that becomes binding in 2018, and the Privacy Shield, an EU–U.S. treaty signed in 2016. These legal standards require regular interactions between the EU and United States and create numerous points for harmonization, coordination, and cooperation. The GDPR and Privacy Shield also establish new kinds of governmental networks to resolve conflicts. The future of international data privacy law rests on the development of new understandings of privacy within these innovative structures.
“Transatlantic Data Privacy Law” by P. M. Schwartz, K.N. Peifer 106 Georgetown Law Journal 115 (2017) UC Berkeley Public Law Research Paper.
Privacy Papers 2017: Spotlight on the Winning Authors
Today, FPF announced the winners of the 8th Annual Privacy Papers for Policymakers (PPPM) Award. This Award recognizes leading privacy scholarship that is relevant to policymakers in the United States Congress, at U.S. federal agencies, and for data protection authorities abroad.
From many nominated privacy-related papers published in the last year, six were selected by Finalist Judges, after having been first evaluated highly by a diverse team of academics, advocates, and industry privacy professionals from FPF’s Advisory Board. Finalist Judges and Reviewers agreed that these papers demonstrate a thoughtful analysis of emerging issues and propose new means of analysis that can lead to real-world policy impact, making them “must-read” privacy scholarship for policymakers.
by Ryan Calo, Associate Professor of Law, University of Washington
Ryan Calo is the Lane Powell and D. Wayne Gittinger Associate Professor at the University of Washington School of Law. He is a faculty co-director (with Batya Friedman and Tadayoshi Kohno) of the University of Washington Tech Policy Lab, a unique, interdisciplinary research unit that spans the School of Law, Information School, and Paul G. Allen School of Computer Science and Engineering. Professor Calo’s research on law and emerging technology appears in leading law reviews (California Law Review, University of Chicago Law Review, and Columbia Law Review) and technical publications (MIT Press, Nature, Artificial Intelligence) and is frequently referenced by the mainstream media (NPR, New York Times, Wall Street Journal). Professor Calo serves as an advisor to many organizations, including the AI Now Institute, and is a member of the R Street Institute’s board.
by Woodrow Hartzog, Professor of Law and Computer Science, Northeastern University
Woodrow Hartzog is a Professor of Law and Computer Science at Northeastern University, where he teaches privacy and data protection law, policy, and ethics. He holds a joint appointment with the School of Law and the College of Computer and Information Science.Professor Hartzog’s work has been published in numerous scholarly publications such as the Yale Law Journal, Columbia Law Review, California Law Review, and Michigan Law Review and popular national publications such as The Guardian, Wired, BBC, CNN, Bloomberg, New Scientist, Slate, The Atlantic, and The Nation. He has testified twice before Congress on data protection issues. His book, Privacy’s Blueprint: The Battle to Control the Design of New Technologies, is forthcoming in Spring 2018 from Harvard University Press.The Undue Influence of Surveillance Technology Companies on Policing
by Elizabeth E. Joh, Professor of Law, UC Davis School of Law
Elizabeth E. Joh is a Professor of Law at the University of California, Davis School of Law, and is the recipient of the 2017 Distinguished Teaching Award. Professor Joh has written widely about policing, technology, and surveillance. Her scholarship has appeared in the Stanford Law Review, the California Law Review, the Northwestern University Law Review, the Harvard Law Review Forum, and the University of Pennsylvania Law Review Online. She has also provided commentary for the Los Angeles Times, Slate, and the New York Times.
by Craig Konnoth, Associate Professor of Law, Colorado Law, University of Colorado, Boulder
Craig Konnoth Professor Konnoth’s work lies at the intersection of health law and policy, bioethics, civil rights, and technology. His papers consider how health privacy burdens are created and distributed, how medical discourse is used both to enable and harm civil rights and autonomy, and how technology can be used to improve health outcomes. He has examined these issues in in contexts as diverse as religion and biblical counseling, consumer rights and transparency, FDA regulation, and collection of individual data. His publications have appeared in the Yale Law Journal, the Hastings Law Journal, the Penn Law Review, the Iowa Law Review, the online companions to the Penn Law Review & the Washington & Lee Law Review, and as chapters in edited volumes.Before arriving at the University of Colorado, Craig was a Sharswood and Rudin Fellow at Penn Law School and NYU Medical School, where he taught health information law, health law, and LGBT health law and bioethics.Before that he was the Deputy Solicitor General and the Inaugural Earl Warren Fellow at the California Department of Justice where he litigated primarily before the United States Supreme Court, and also before the California Supreme Court and the Ninth Circuit Court of Appeals. Cases involved the contraceptive mandate in the Affordable Care Act, Sexual Orientation Change Efforts, Facebook privacy policies, and cellphone searches. Before moving into government, Craig was the R. Scott Hitt Fellow in Law & Policy at the Williams Institute at UCLA Law School, where he focused on issues affecting same-sex partners, long term care, and Medicaid coverage issues, and drafted HIV rights legislation. He holds a J.D. from Yale, and an M.Phil. from the University of Cambridge. He clerked for Judge Margaret McKeown of the Ninth Circuit Court of Appeals.
by Karen Levy, Assistant Professor, Department of Information Science at Cornell University; and Solon Barocas, Assistant Professor in the Department of Information Science at Cornell University
Karen Levy Karen Levy is an assistant professor in the Department of Information Science at Cornell University and associated faculty at Cornell Law School. She researches how law and technology interact to regulate social life, with particular focus on social and organizational aspects of surveillance. Dr. Levy’s research analyzes the uses of data collection for social control in various contexts, from long-haul trucking to intimate relationships, with emphasis on inequality and marginalization. She holds a Ph.D. in Sociology from Princeton University and a J.D. from Indiana University Maurer School of Law. Before joining Cornell, she was a postdoctoral fellow at NYU’s Information Law Institute and at the Data & Society Research Institute.
Solon Barocas is an Assistant Professor in the Department of Information Science at Cornell University. His current research explores ethical and policy issues in artificial intelligence, particularly fairness in machine learning, methods for bringing accountability to automated decision-making, and the privacy implications of inference. He was previously a Postdoctoral Researcher at Microsoft Research, where he worked with the Fairness, Accountability, Transparency, and Ethics in AI group, as well as a Postdoctoral Research Associate at the Center for Information Technology Policy at Princeton University. Solon completed his doctorate in the Department of Media, Culture, and Communication at New York University, where he remain a Visiting Scholar at the Center for Urban Science + Progress.
by Paul M. Schwartz, Jefferson E. Peyser Professor of Law, Berkeley Law School; and Karl-Nikolaus Peifer, Director of the Institute for Media Law and Communications Law of the University of Cologne and Director of the Institute for Broadcasting Law at the University of Cologne
Paul M. Schwartz is a leading international expert on information privacy law. He is Jefferson E. Peyser Professor at the University of California, Berkeley Law School and a director of the Berkeley Center for Law and Technology. Professor Schwarz is the author of many books, including the leading casebook, “Information Privacy Law,” and the distilled guide, “Privacy Law Fundamentals,” each with Daniel Solove. Schwartz’s over fifty articles have appeared in journals such as the Harvard Law Review, Yale Law Journal, Stanford Law Review, University of Chicago Law Review and California Law Review.
Professor Schwartz is co-reporter of the American Law Institute’s Restatement of Privacy Law Principles. He is a past recipient of the Berlin Prize Fellowship at the American Academy in Berlin and a Research Fellowship at the German Marshall Fund in Brussels. Schwartz is also a recipient of grants from the Alexander von Humboldt Foundation, Fulbright Foundation, and the German Academic Exchange. He is a member of the organizing committee of the Privacy + Security Forum, International Privacy + Security Forum, and Privacy Law Salon. Schwartz publishes on a wide array of privacy and technology topics including cloud computing, financial privacy, European data privacy law, and comparative privacy law.
Karl-Nikolaus Peifer is the Director of the Institute for Media Law and Communications Law of the University of Cologne and Director of the Institute for Broadcasting Law at the University of Cologne. He studied law, economics and romanic languages at the of Universities of Trier, Bonn, Hamburg and Kiel. In 2003 he was appointed to be a judge at the Court of Appeals in Hamm/Germany, in 2013 at the Court of Appeals in Cologne. He was a Visiting Professor at the University of Illinois in 2009 and at the University of California at Berkeley from 2009 to 2012. In 2011 he was among the experts heard during the sessions of the Parliamentary Commission “Internet und Digital Society”. His main fields of research are Intellectual Property and Media Law.
The Finalist Judges also selected three papers for Honorable Mention on the basis of their uniformly strong reviews from the Advisory Board.
The winning authors have been invited to join FPF and Honorary Co-Hosts Senator Edward J. Markey, and the Co-chairs of the Congressional Bi-Partisan Privacy Caucus, to present their work at the U.S. Senate with policymakers, academics, and industry privacy professionals. This annual event will be held on February 27, 2018, the day before the Federal Trade Commission’s PrivacyCon. FPF will subsequently publish a printed digest of summaries of the winning papers for distribution to policymakers, privacy professionals, and the public. RSVP here to join us.
This Year's Six Must-Read Privacy Papers: The Future of Privacy Forum Announces Recipients of Annual Privacy Award
FOR IMMEDIATE RELEASE
December 12, 2017
Contact: Melanie Bates, Director of Communications, [email protected]
This Year’s Six Must-Read Privacy Papers: The Future of Privacy Forum Announces Recipients of Annual Privacy Award
Washington, DC – Today, the Future of Privacy Forum announced the winners of the 8th Annual Privacy Papers for Policymakers Award. The PPPM Award recognizes leading privacy scholarship that is relevant to policymakers in the U.S. Congress, at U.S. federal agencies, and for data protection authorities abroad. The winners of the 2017 PPPM Award are:
Transatlantic Data Privacy Law, by Paul Schwartz, UC Berkeley School of Law and Karl-Nikolaus Peifer, University of Cologne
From many nominated privacy-related papers published in the last year, these six were selected, after having been first evaluated highly by a diverse team of academics, advocates, and industry privacy professionals from FPF’s Advisory Board. It was agreed that these papers demonstrate a thoughtful analysis of emerging issues and propose new means of analysis that can lead to real-world policy impact, making them “must-read” privacy scholarship for policymakers.
At last year’s event, a new element to the program was introduced — the Student Paper Award. For this award, the student work must meet similar guidelines as those set for the general Call for Nominations. The following paper was selected for the Student Paper Award: The Market’s Law of Privacy: Case Studies in Privacy/Security Adoption, by Chetan Gupta, UC Berkeley.
“Academic scholarship can serve as a valuable resource for policymakers who are often wrestling with challenging privacy issues,” said Jules Polonetsky, FPF’s CEO. Now more than ever, topics such as artificial intelligence, algorithmic discrimination, connected cars, and transatlantic data flows, are at the forefront of the privacy debate. These papers are ‘must-reads’ for any thoughtful policymaker who wants to make an impact in this rapidly evolving space.”
The winning authors have been invited to join FPF and Honorary Co-Hosts Senator Edward J. Markey and Co-Chairs of the Congressional Bi-Partisan Privacy Caucus to present their work at the U.S. Senate with policymakers, academics, and industry privacy professionals. This annual event will be held on February 27, 2018, the day before the Federal Trade Commission’s PrivacyCon. FPF will subsequently publish a printed digest of summaries of the winning papers for distribution to policymakers, privacy professionals, and the public.
This event is supported by National Science Foundation Grant No. 1654085. Any opinions, findings and conclusions or recommendations expressed in these papers are those of the authors and do not necessarily reflect the views of the National Science Foundation.
###
The Future of Privacy Forum (FPF) is a non-profit organization that serves as a catalyst for privacy leadership and scholarship, advancing principled data practices in support of emerging technologies. Learn more about FPF by visiting www.fpf.org.
Unfairness By Algorithm: Distilling the Harms of Automated Decision-Making
Analysis of personal data can be used to improve services, advance research, and combat discrimination. However, such analysis can also create valid concerns about differential treatment of individuals or harmful impacts on vulnerable communities. These concerns can be amplified when automated decision-making uses sensitive data (such as race, gender, or familial status), impacts protected classes, or affects individuals’ eligibility for housing, employment, or other core services. When seeking to identify harms, it is important to appreciate the context of interactions between individuals, companies, and governments—including the benefits provided by automated decision-making frameworks, and the fallibility of human decision-making.
Recent discussions have highlighted legal and ethical issues raised by the use of sensitive data for hiring, policing, benefits determinations, marketing, and other purposes. These conversations can become mired in definitional challenges that make progress towards solutions difficult. There are few easy ways to navigate these issues, but if stakeholders hold frank discussions, we can do more to promote fairness, encourage responsible data use, and combat discrimination.
To facilitate these discussions, the Future of Privacy Forum (FPF) attempted to identify, articulate, and categorize the types of harm that may result from automated decision-making. To inform this effort, FPF reviewed leading books, articles, and advocacy pieces on the topic of algorithmic discrimination. We distilled both the harms and potential mitigation strategies identified in the literature into two charts. We hope you will suggest revisions, identify challenges, and help improve the document by contacting [email protected]. In addition to presenting this document for consideration for the FTC Informational Injury workshop, we anticipate it will be useful in assessing fairness, transparency and accountability for artificial intelligence, as well as methodologies to assess impacts on rights and freedoms under the EU General Data Protection Regulation.
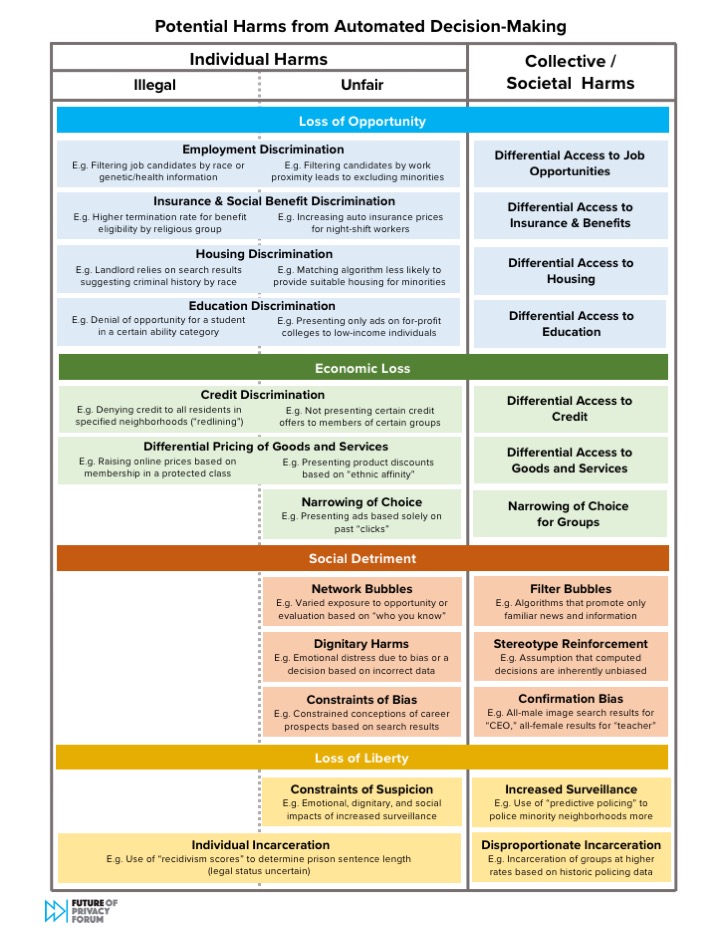
The Chart of Potential Harms from Automated Decision-Making
This chart groups the harms identified in the literature into four broad “buckets”—loss of opportunity, economic loss, social detriment, and loss of liberty—to depict the various spheres of life where automated decision-making can cause injury. It also notes whether each harm manifests for individuals or collectives, and as illegal or simply unfair.
We hope that by identifying and categorizing the harms, we can begin a process that will empower those seeking solutions to mitigate these harms. We believe that a more clear articulation of harms will help focus attention and energy on potential mitigation strategies that can reduce the risks of algorithmic discrimination. We attempted to include all harms articulated in the literature in this chart; we do not presume to establish which harms pose greater or lesser risks to individuals or society.
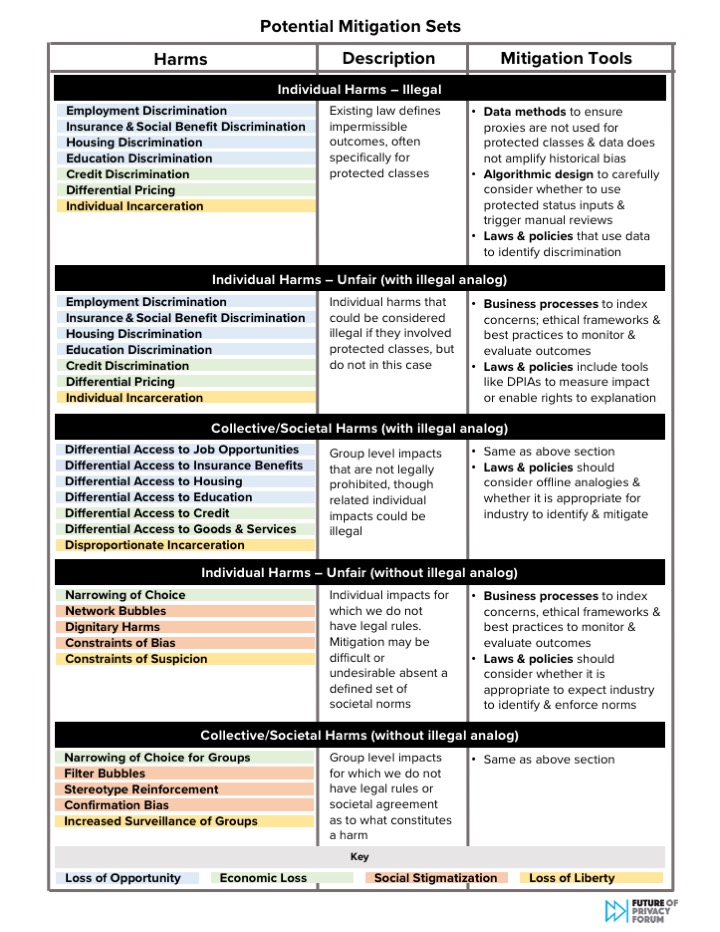
The Chart of Potential Mitigation Sets
This chart uses FPF’s taxonomy to further categorize harms into groups that are sufficiently similar to each other that they could be amenable to the same mitigation strategies.
Attempts to solve or prevent this broad swath of harms will require a range of tools and perspectives. Such attempts benefit by further categorization of the identified harms, into five groups of similar harms. These groups include: (1) individual harms that are illegal; (2) individual harms that are simply unfair, but have a corresponding illegal analog; (3) collective/societal harms that have a corresponding individual illegal analog; (4) individual harms that are unfair and lack a corresponding illegal analog; and (5) collective/societal harms that lack a corresponding individual illegal analog. The chart includes a description of the mitigation strategies that are best positioned to address each group of harms.
There is ample debate about whether the lawful decisions included in this chart are fair, unfair, ethical, or unethical. Absent societal consensus, these harms may not be ripe for legal remedies.
Responsible Research and Privacy Practices Workshop generates new research opportunities
On November 2-3, 2017, the Future of Privacy Forum’s Research Coordination Network partnered with Facebook, Bentley University and University of Central Florida to host a workshop titled “Bridging Industry and Academia to Tackle Responsible Research and Privacy Practices”. As the title infers, the purpose of the workshop was to bring together key stakeholders from across industry, civil society, and academia to advance the privacy research agenda, focusing on topics including data analytics and privacy-preserving technologies, privacy and ethics in user research and people-centered privacy design.
As initiatives in each of these areas continue to gain considerable momentum, this was the opportune time to identify promising avenues for forming new academic and private sector collaborations. A primary goal of the workshop was to foster new collaborations and start working together to forge meaningful progress in these areas by creating possible research opportunities via “working groups”.
The 43 attendees comprised a mix from industry and academia. Organizations represented included Facebook, Microsoft, Knexus Research Corporation and Swiss Re. From the academic community, attendees included Professors of Computer Science, Law and Public Policy, Assistant Professors, and PhD/Doctoral/Graduate students from institutions such as MIT, Harvard, UC Berkley and NYU.
The workshop began with a thought provoking panel discussion with our distinguished Advisory Board members: Chris Clifton of Purdue University; Lorrie Cranor from Carnegie Mellon University; Lauri Kanerva of Facebook; Helen Nissenbaum from Cornell Tech and New York University; and Jules Polonetsky of Future of Privacy Forum. Participants then joined a working group based on the three main workshop themes mentioned above. These working groups developed concrete project ideas and developed new partnerships across disciplinary lines with the end-goal of working together to bring these project ideas to fruition.
Eight substantive themes were identified within the three main workshop topics. During working sessions, groups spent time developing a clearly defined problem statement for these identified themes. Themes and problem statements generated by the working groups included:
Data Analytics and Privacy Preserving Technologies: Governance – Creating a risk matrix that supports a concrete governance framework for data analytics
Data Analytics and Privacy Preserving Technologies: Outcomes Measurements – Bridging the gaps between computational privacy metrics and perceived privacy
Differential Privacy – Towards practical deployments and interpretability of privacy guarantees
Privacy and Ethics in User Research: Informed Consent – Models for informed consent for research at scale: Informing, consenting, and empowering users at scale
Privacy and Ethics in User Research: Beyond IRB – Drafting clear guidelines for research that falls outside of IRBs (e.g., archived data, public data)
Privacy and Ethics in User Research: Research Practices – Developing and distributing community norms around ethical research practices
People-Centered Privacy Design: Understanding Users and Individual Differences – Developing better technology and policy norms to address peoples’ different perceptions and concerns?
People-Centered Privacy Design: Rich, Complex, and Disconnected UIs –Enabling people to understand what the system knows and does, (b) enabling people to know if they should be worried, and (c) designing systems that allow people to make proactive and reactive choices about their data
The working groups plan to further develop the initial concepts created during the workshop and are expected to present concrete outcomes and deliverables at the next convening in about one year. The outcomes of this inaugural meeting will be sustained through future workshops that will be co-created by our growing community of academics and industry professionals. To learn more about this initiative, contact Margaret Honda at Future of Privacy Forum at [email protected].
This event is partially supported by National Science Foundation Grant No. 1654085. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
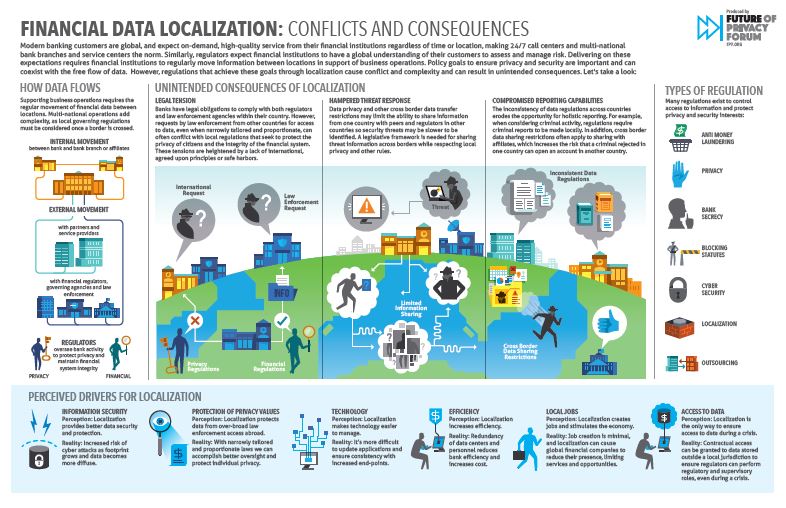
Financial Data Localization: Conflicts and Consequences
How has the growing trend of global financial data localization laws affected financial institutions handling difficult questions of data privacy? What have been the practical impacts of these laws? FPF addresses these questions in a new info-graphic: “Financial Data Localization: Conflicts and Consequences” (view the info-graphic here) (Pdf).
Financial Data Localization: Conflicts and Consequencesexplores the perceived drivers as well as the potential unintended consequences of the growing trend of global data localization laws. Data localization laws, which require data about a country’s residents be processed or stored inside the geographical boundaries of a country, are often perceived as a way to protect privacy, stimulate a local economy, or maintain national control over data and technology, among other motivations.
Despite the importance of these goals, there may be better ways to safeguard privacy and protect individuals’ financial data (for example, through narrowly tailored and proportionate law enforcement access requests) while avoiding unintended consequences. This info-graphic highlights three ways in which such laws may lead to unintended results: First, legal tension is often created by banks’ conflicting obligations to comply with local privacy laws and international law enforcement requests; second, threat responses may be hampered by cross-border data transfer restrictions that limit banks’ abilities to share security threats from one country to another; and finally, banks’ reporting abilities may be compromised by regulations that restrict cross border data transfer and regulations that require criminal reports to be made locally, increasing the risk that a criminal rejected in one country can open an account in another country.
As more countries consider data localization laws, these issues will continue to grow in importance. Recently, for example, the Brazilian Central Bank proposed cybersecurity regulations that would prohibit financial institutions from using data processing and cloud computing services based abroad. According to some, regulations such as these could have negative implications for banks and consumers, including raising the costs of effective fraud detection.
As U.S. financial institutions grapple with these difficult questions, we hope that this info-graphic will contribute to the growing conversation around data localization laws and how best to protect privacy and security internationally.
Click to view full info-graphic (PDF).
NAI Combines Web, Mobile, and Cross-Device Tracking Rules for 2018
The Network Advertising Initiative (NAI) released its 2018 Code of Conduct yesterday, consolidating the rules for online and mobile behavioral advertising (interest-based advertising). NAI, a non-profit organization in Washington, DC, is the leading self-regulatory association for digital advertising, with over 100 members and a formalized internal review mechanism.
The 2018 NAI Code of Conduct combines the earlier requirements in the web-focused 2015 Code of Conduct and the 2015 Mobile Application Code into one document for both web and mobile — an overall positive change that recognizes the fact that digital advertising in web and mobile are no longer separate or distinct spheres. Instead, most advertisers today combine their digital advertising efforts across web and mobile, with increasing efforts towards measuring advertising effectiveness for a single user across devices, browsers, and platforms through cross-device tracking.
Key takeaways for understanding the 2018 Code of Conduct (read the full Code and Commentary here):
Updates to Key Terminology. The biggest change to the NAI Code is that NAI has updated key terminology to account for the combination of web and mobile and for a shifting legal landscape. The term “Personalized Advertising” now functions as an umbrella term for all online behavioral advertising (interest-based advertising) (OBA/IBA), including re-targeting and cross-app advertising. All of the requirements that previously applied to OBA/IBA and cross-app advertising continue to apply to Personalized Advertising.
“Device-Identifiable Information.” NAI has also replaced the term “non-Personally Identifiable Information” (non-PII) with a new term, “Device-Identifiable Information” (DII) with all of the previous rules continuing to apply. Among other requirements, the Code requires that companies using DII for Personalized Advertising provide users with an easy-to-use mechanism for opting out of advertising-related data collection and use. For privacy advocates, the shift in terminology is a welcome step forward, acknowledging that information tied to devices, e.g. user IDs in cookies or mobile advertising identifiers (IDFA), while less directly identifiable than names and email addresses, still implicate individual privacy and merit robust privacy controls.
“De-Identified Data.” In parallel to the updated terminology above (“non-PII” to “DII”), the 2018 Code also contains an updated definition of de-identified data. Data considered “de-identified” falls outside of the requirements of most privacy laws and regulations, including the NAI Code, because it is usually considered to have fewer privacy implications (or none at all) if properly de-identified through rigorous technical steps. Most definitions mirror the Federal Trade Commission’s “reasonable linkability” analysis set forth in the Commission’s 2012 Privacy Report. The 2018 NAI Code has updated its definition, now considering de-identified data to include “data that is not linked or intended to be linked to an individual, browser, or device,” replacing the previous “not linked or reasonably linkable.” The change, which likely reflects practical challenges for companies that are increasingly holding segmented data-sets not related to personalized advertising, shifts the NAI’s analysis from the nature of the data to its uses. As debates over de-identification continue (see, e.g., arguments from Princeton researchers Arvind Narayanan and Edward Felten, and/or for more information, FPF’s “Shades of Gray: Seeing the Full Spectrum of Practical Data De-identification”), it will be interesting to see whether and how a use-based analysis of de-identified data affects the industry for digital advertising.
Imported Requirements for Cross-Device. In Section II of the 2018 NAI Code of Conduct, the requirements for transparency and notice have been helpfully re-organized, and now incorporate NAI’s 2017 guidance on cross-device tracking. Specifically, the Code includes updates for:
Website Notice. The 2018 Code clarifies that publishers are required to publish “An explanation of the purposes for which data is collected by, or will be transferred to, third parties, including Cross-Device Linking if applicable…” – Section II.B. This is a positive change, particularly in light of findings published last year by the Federal Trade Commission’s Office of Technology Research and Investigation (OTech) on data collected online for purposes of cross-device tracking. According to OTech, out of 100 popular websites tested, “only three sites provided specific information to users about enabling third-party cross device tracking.” NAI’s requirements may help with improving these kinds of consumer-facing disclosures.
User Controls. The 2018 NAI Code maintains the same substantive requirements, including that users must be able to opt out of the use of their device-identifiable information (DII) for Personalized Advertising. The Opt Out also covers Cross-Device Tracking to a limited extent (Section II.C) — Specifically: “While a browser or device is opted out of Personalized Advertising by a member, that member shall: (a) Cease the collection of data for Personalized Advertising on the browser or device on which the user has expressed such choice, for use on that or any other browser or device associated through Cross-Device Linking… [and] (b) Cease Personalized Advertising on the browser or device on which the user has expressed such choice, with any data collected from a browser or device associated through Cross-Device Linking.” In other words, opting out of Personalized Advertising on a given browser or device only functions as an “Opt Out” for that particular browser or device — it does not carry the user’s preference across other devices/browsers, even if they are known to be linked to the same user. In part, this is likely because much of cross-device tracking is probabilistic (and thus more challenging to effectuate privacy choices, such as an Opt Out, across multiple devices). For more, check out the FTC’s 2017 Staff Report on Cross-Device Tracking.
Affirmative Opt In for Sensitive Data, and Precise Location Data. Finally, the 2018 Code keeps its strong requirements for its members to obtain an affirmative “Opt In” for any collection and use of Sensitive Data (defined broadly, and including, e.g. any inferences of a sensitive health condition, regardless of source) and Precise Location Data (defined in accompanying 2015 guidance on determining whether location is precise).
As the tools available in Ad Tech become more expansive, so do the corresponding privacy implications for individuals. In 2017, we have seen controversies over political advertising leading to the introduction of the Honest Ads Act, and influential academic research demonstrating how individuals might use the tools provided by Demand Side Platforms (DSPs) to surveil known targets by targeting advertisements to specific mobile identifiers and tracking when and how the ads are viewed (a process being called “ADINT”). In addition, a growing trend in Ad Tech involves the creation of detailed audience profiles from a variety of “offline” sources — such as loyalty programs and offline shopping habits — in ways that fall outside of the strictures of self-regulatory codes, but nonetheless may be unexpected or surprising to many consumers.
For these reasons, consumer education is more important than ever, and self-regulatory mechanisms such as the NAI Code of Conduct can go farther, even as they represent important baseline privacy protections. While we believe that more can be done to address consumer privacy in Ad Tech, we nonetheless applaud these efforts at building greater industry consensus and collaborating towards responsible data practices.
Where Are They Now? FPF Trains a New Generation of Privacy Leaders
FPF offers up-and-coming privacy professionals fellowship opportunities, often giving new graduates experience in the privacy world. In this post, we will take a look at some of FPF’s former employees who have gone on to successful privacy careers.
Kenesa Ahmad
Formerly: Legal and Policy Fellow, Future of Privacy Forum
Kenesa Ahmad is a partner at Aleada Consulting LLC, one of the first boutique privacy and data protection consulting firms in Silicon Valley. She is also the Chair and Co-Founder of Women in Security and Privacy (WISP) which is a nonprofit organization that aims to advance women in the privacy and security industries. “We [Kenesa and 7 other women] started the organization three years ago because we recognized the converging fields of privacy and security,” said Kenesa. “We want to ensure that there is diversity in this converging field.”
Additionally, Kenesa acts as a Security & Privacy Committee Member for Grace Hopper Celebration for Women in Computing. Previously, she worked for over four years with the Promontory Financial Group, LLC as a Privacy Associate. Kenesa says, “I was very fortunate to get a job with Promontory. I received invaluable experience from a mix of individuals who were just really smart, kind people who set me up for my job now.”
However, prior to her extensive work in these companies and committees, Kenesa received her JD from Ohio State University and LL.M. from Northwestern University. This led to her experience at FPF as a Legal and Policy Fellow for nearly two years. During her time with FPF, she worked closely with Peter Swire on various topics, including government surveillance, encryption, mobile applications, and more. In fact, she was awarded “Privacy Papers for Policy Makers 2012” for her essay “Going Dark vs. the Golden Age of Surveillance.”
“I’m so fortunate because at the time, FPF was much smaller and did not bring on many fellows. They gave me experience that I would not have gotten anywhere else. They gave me a very strong foundation in privacy,” said Kenesa. “I didn’t know it at the time, but FPF really changed my life.”
Heather Federman
Formerly: Legal and Policy Fellow, Future of Privacy Forum
Currently: Director of Enterprise Management & Privacy, Macy’s
Heather Federman attained her JD from Brooklyn Law School before she worked for FPF as a Legal and Policy Fellow from 2012-13. Since then, she has worked at Online Trust Alliance (OTA), American Express (Amex), and Macy’s in positions related to privacy. She reflects on her time at FPF, saying,
“It was a pretty exciting time for mobile privacy – the NTIA was undergoing its multistakeholder mobile app transparency process, the FTC was updating COPPA, and the California AG was tweeting at companies that their apps needed privacy policies. As a FPF Fellow, I had the opportunity to be involved in these efforts as well as our own internal initiatives like Mobile Location Analytics.”
After FPF, Heather became the Public Policy Director for OTA, which advocates for best practices to enhance the protection of security, privacy, and identity, while educating businesses, policymakers, and stakeholders. She met her boss at OTA through her work at FPF.
Heather then proceeded to work in the corporate world for Amex as the Senior Privacy Manager for over a year. At Amex, she focused on Global Branding, Marketing, and Digital Partnerships. She has mentioned that her connections at FPF helped position her for this job at Amex as well. “Sometimes the role of a privacy professional is weighing the benefits vs the risks when it comes to the organization’s data processing activities,” says Heather. “FPF is great because it really tries to walk that middle ground on issues.”
Heather is currently working as the Director of Enterprise Information Management & Privacy (EIM/P) at Macy’s. She is responsible for EIMP’s Policies, Programs, Communications and Training. Once again, Heather acknowledges that her work with FPF, specifically her involvement with the Mobile Location Analytics working group, allowed her to meet some influential people, including her current boss at Macy’s.
Now, approximately five years after her time as a Legal and Policy Fellow, Heather says, “FPF is great in that it has a mixture of policy, advocacy, and academia. Even today, I rely on FPF to keep me up to date on the latest and greatest of research.”
Joseph Jerome, who received his JD from New York University, is working as a Policy Counsel for the Center for Democracy & Technology (CDT). He focuses specifically on the legal and ethical issues that surround smart technologies and big data. Joe also has particular interest in transparency and accountability mechanisms and procedures involved in the use of data. “The best thing about CDT and being in privacy in general is that there is so much variety,” said Joe.
Before CDT, Joe worked as an associate at WilmerHale, focusing on cybersecurity and privacy practice. He dealt with advertising technologies and privacy compliance in the health and financial sectors.
However, before those impressive positions, Joe worked for almost 3 years at FPF as a Policy Counsel. Joe reflected on his time at FPF, saying, “I started there very early in my career, and when you deal with so many companies, people, and issues, you realize how little you know about everything.” Joe worked in several different issues at FPF, including big data, de-identification, geolocation, and much more.
“FPF was a really great launching pad,” said Joe. “Privacy is a pretty small community, and it seems like everybody knows everybody. Being at FPF was a really great way for me to make connections.”
Joe claims that it is unlikely he would have gotten his positions at WilmerHale and then CDT without the experience and connections he got at FPF.
Joe Newman
Formerly: Legal and Policy Fellow, Future of Privacy Forum
Joe Newman joined Ubisoft (a creator, publisher, and distributor of interactive entertainment) as a Senior Legal Counsel specializing in the field of Privacy. He will be focusing on North and South American privacy issues as well as the integration of European privacy laws and practices in Western society.
Before Ubisoft, Joe worked at Electronic Arts Inc. (EA) where he was a Privacy and Consumer Protection Attorney in California. There, Joe provided guidance to game development teams and central EA services, assisting with contract negotiation and resolving disputes. He focused on issues related to children’s privacy, government data requests, data governance, sweepstakes and promotions, international privacy compliance, e-commerce, advertising law, e-sports and competitive gaming, accessibility, end user-facing legal agreements, and data security.
In 2013-14, after obtaining his Juris Doctorate from George Washington University, Joe worked for FPF as a Legal and Policy Fellow. He focused on cutting-edge privacy issues, such as Do Not Track standards, international data transfer through the US-EU Safe Harbor, third-party vendor management, and tracking in modern videogames.
When reflecting on his time as a Legal and Policy Fellow, Joe said, “There was a lot of really exciting stuff going on that is still happening. My favorite project, and by far the most relevant to what I’m currently doing, was a white paper that Joe Jerome and I worked on together about data and privacy in video games. It was called ‘Press Start to Track: New Privacy Problems Raised by Video Game Technology.’” Joe cites that paper, which studied the tracking and usage of consumer data in videogames, as a major contributor to getting his job at EA.
He also values the unique standpoint from which FPF operates, which is “very much about finding real solutions that satisfy both industry and privacy needs.” He says,
“They position themselves in the middle of the road as a neutral party, as opposed to other places that are locked into a specific agenda. This makes a fellowship at FPF particularly good training for in-house work, which is all about finding good compromises.”
According to Joe, FPF helped him become familiar with the landscape, the technology, and the players involved in the industry, which was critical to his privacy career.









 terminology to account for the combination of web and mobile and for a shifting legal landscape. The term “Personalized Advertising” now functions as an umbrella term for all online behavioral advertising (interest-based advertising) (OBA/IBA), including re-targeting and cross-app advertising. All of the requirements that previously applied to OBA/IBA and cross-app advertising continue to apply to Personalized Advertising.
terminology to account for the combination of web and mobile and for a shifting legal landscape. The term “Personalized Advertising” now functions as an umbrella term for all online behavioral advertising (interest-based advertising) (OBA/IBA), including re-targeting and cross-app advertising. All of the requirements that previously applied to OBA/IBA and cross-app advertising continue to apply to Personalized Advertising.


