FPF at CPDP 2023: Covering Hot Topics, from Data Protection by Design and by Default, to International Data Transfers and Machine Learning
At this year’s annual Computers, Privacy and Data Protection (CPDP) conference in Brussels, several Future of Privacy Forum (FPF) staff took part in different panels, organized by FPF, as well as academic, industry, and civil society groups. This blogpost provides a brief overview of these exciting events, and CPDP will publish recordings of them shortly.
May 24: EU Commission and ASEAN launch Joint Guide to Model Clauses for Data Transfers
On the conference’s first day, FPF Vice President for Global Privacy Gabriela Zanfir-Fortuna joined a panel organized by Haifa Center for Law and Technology (Faculty of Law, University of Haifa) on the GDPR’s effectiveness, alongside Tal Zarsky, Dean and Professor of Law at the University of Haifa’s Faculty of Law, Raphael Gellert, assistant professor in ICT and private law at Radboud University, Sam Jungyun Choi, associate in the technology regulatory group of Covington & Burling LLP, and Amit Ashkenazi, research student and adjunct lecturer on cyber law and policy at the University of Haifa. The panel contributed to current reflections on the effectiveness of the GDPR, five years after its enactment, by focusing on challenges arising from the regulatory design it sets forth. Gabriela noted that data protection law is much broader than the GDPR because it has a fundamental element behind it, meaning that the right to the protection of personal data is protected as a fundamental right at a constitutional level in the EU. She also stressed that ongoing adoption of the GDPR has catalyzed more societal interest in law, technology, and data protection rights and concepts.
Photo: CPDP Panel on Exploring the Many Faces of the GDPR – in Search of Effective Data Protection Regulation, 5/24/2023
Later that day, Gabriela moderated a panel organized by the EU Commission, which served as a platform to launch a “Joint Guide to ASEAN Model Contractual Clauses and EU Standard Contractual Clauses.” The Guide identifies commonalities between the two sets of model clauses and aims to “assist companies present in both jurisdictions with their compliance efforts under both sets of clauses.” The panel was joined by Denise Wong, Deputy Commissioner-designate, Personal Data Protection Commission Singapore, and Assistant Chief Executive-Designate of the Infocomm Media Development Authority, Alisa Vekeman, European Commission, International Affairs and Data Flow team, and Philipp Raether, Group Chief Privacy Officer, Allianz. The panelists noted that model clauses are the most used mechanisms for international data transfers and that efforts like the Joint Guide are a promising solution for a global regime underpinning flows of personal data across different jurisdictions, while providing safeguards for individuals and their data. Officials in the panel noted that the Guide is just the first step in this EU-ASEAN collaboration on model clauses, noting that a set of best practices from companies who use both is to be expected in the near future.
To wrap up the first day of the conference, FPF’s Policy Councel for Global Privacy, Katerina Demetzou, joined a panel on the constitutionalization of data rights in the Global South, along with Mariana Marques Rielli, Institutional Development Coordinator at Data Privacy Brazil, Laura Schertel Mendes, law Professor at the University of Brasilia (UnB) and at the Brazilian Institute for Development, Education and Research (IDP) and Senior Visiting Researcher at the Goethe-Universität Frankfurt am Main with the Capes/Alexander von Humboldt Fellowship, and Risper Onyango, advocate of the High Court of Kenya, currently serving as a Digital Policy Lead under the Digital Economy Department at the Lawyers Hub. In her intervention, Katerina explored how the GDPR has been applied by Data Protection Authorities in Europe to emotion recognition AI systems and to Generative AI. Her examples emphasized that discussions about AI governance and AI regulation should examine existing data protection law applications to these systems and develop in response to gaps in these legal systems.
Photo: Panel on From Theory to Practice: Digital Constitutionalism and Data Justice in Movement in the Global South, 5/24/2023
May 25: High Level Discussion Spurred by FPF’s Data Protection by Design and by Default Case-Law Report
On May 17, FPF launched a comprehensive Report on the enforcement of the EU’s GDPR Data Protection by Design and by Default (DPbD&bD) obligations, which are outlined in GDPR Article 25. The Report is informed by extensive research covering more than 92 decisions from Data Protection Authorities (DPAs) and national Courts, and it offers specific Guidance and other policy documents issued by regulators.
On May 25, FPF organized a panel moderated by the Report’s co-author Christina Michelakaki, FPF Policy Fellow for Global Privacy, on the enforcement of Article 25 GDPR and the uptake of Privacy Enhancing Technologies (PETs). Marit Hansen, State Data Protection Commissioner of Land Schleswig-Holstein, Jaap-Henk Hoepman, Professor, Radboud University Nijmegen/University of Groningen, Cameron Russell, Primary Privacy Advisor on Global Payments Matters at eBay, and Stefano Leucci, Legal and Technology expert at the European Data Protection Supervisor joined the panel. The speakers offered their perspectives on the Article 25 GDPR enforcement, delving into topics such as the interrelation between dark patterns and by default settings, the role of Article 25 GDPR in preventing harms from AI systems, and the maturity of PETs.
Photos: CPDP workshop on State-of-Play of Privacy Preserving Machine Learning (PPML), and CPDP Panel on the Enforcement of Data Protection by Design & Default: Consequences for the Uptake of Privacy-Enhancing Technologies, 5/25/2023
Photo: CPDP Panel on the Enforcement of Data Protection by Design & Default: Consequences for the Uptake of Privacy-Enhancing Technologies, 5/25/2023
FPF’s Managing Director for Europe, Rob van Eijk, organized and facilitated a workshop exploring how to clear the path towards alternative solutions for processing of (personal) data with Machine Learning. Four data scientists, Lindsay Carignan (Holistic AI), Nigel Kingsman (Holistic AI), Victor Ruehle (Microsoft Research), and Reza Shokri (National University of Singapore) joined the workshop. The group introduced an easy to understand privacy auditing framework that quantitatively measures privacy risks in ML systems, while also exploring the relationship between bias and regulations in legislation such as the EU AI Act. You can watch the recording of the workshop here.
The same day, Rob also joined a panel on PETs, consumer protection, and the online ads ecosystem with Marek Steffen Jansen, Privacy Policy Lead – EMEA/Global at Google, Anthony Chavez, VP of Product Management of Google, Marie-Paule Benassi, lawyer, economist, data scientist, and Head of Enforcement of Consumer Law and Redress at the European Commission, Stefan Hanloser, VP Data Protection Law at ProSiebenSat.1 Media SE, and Christian Reimsbach-Kounatze, Information Economist and Policy Analyst at the OECD Directorate for Science, Technology and Innovation. You can watch the recording of the panel here.
May 26: Reflections on automation, compliance and data protection law
Finally, Gabriela participated in a day-long “philosopher’s seminar” on compliance and automation in data protection law organized by CPDP, ALTEP-DP, COHUBICOL under the leadership of Prof. Mireille Hildebrandt, which will flow into a series of published research papers later on in 2023.
While celebrating the five years anniversary of the GDPR becoming applicable, at a pivotal moment of growth and change for emerging technologies, CPDP 2023 in Brussels gave the FPF team an extraordinary opportunity to engage with and facilitate collaborative dialogues with leading academics, technologists, policy experts, and regulators.
New FPF Report: Unlocking Data Protection by Design and by Default: Lessons from the Enforcement of Article 25 GDPR
On May 17, the Future of Privacy Forum launched a new report on enforcement of the EU’s GDPR Data Protection by Design and by Default (DPbD&bD) obligations, which are outlined in GDPR Article 25. The Report draws from more than 92 data protection authority (DPA) cases, court rulings, and guidelines from 16 EEA member states, the UK, and the EDPB to provide an analysis of enforcement trends regarding Article 25. The identified cases cover a spectrum of personal data processing activities, from accessing online services and platforms, to tools for educational and employment contexts, to “emotion recognition” AI systems for customer support, and many more.
The Report aims to explore the effectiveness of the DPbD&bD obligations in practice, informed by how DPAs and courts enforced Article 25. For instance, we analyze whether DPAs and courts find breaches of Article 25 without links to other infringements of the regulation and what provisions enforcers tend to apply together with Article 25 the most, including the general data protection principles and requirements related to data security under Article 32. We also look at what controls and controller behavior are and are not deemed sufficient to comply with Article 25.
The GDPR’s DPbD&bD provisions in Article 25 oblige controllers to: 1) adopt technical and organizational measures (TOMs) that, by design, implement data protection principles into data processing and protect the rights of individuals whose personal data is processed; and 2) ensure that only personal data necessary for each specific purpose is processed. Given the breadth of these obligations, it has been argued that Article 25 makes the GDPR “stick” by bridging the gap between its legal text and practical implementation. GDPR’s DPbD&bD obligations are seen as a tool to enhance accountability for data controllers, implement data protection effectively, and add emphasis to the proactive implementation of data protection safeguards.
Our analysis on the enforcement, and ultimately the effectiveness, of Article 25 is all the more important, given the increasing development and deployment of novel technologies involving very complex personal data processing, like Generative AI, and rising data protection concerns. Understanding how Article 25 obligations manifest in practice and the requirements of DPbD&bD may prove essential for the next technological age.
This Report outlines and explores the key elements of GDPR Article 25, including the:
Role of the controller;
Qualified nature of the obligation;
Concept of appropriate TOMs;
Stage of the data processing activity in which TOMs should be applied; and
Effectiveness requirement.
Additionally, we analyze the individual concepts of “by Design” and “by Default,” identify divergent enforcement trends, and explore three common applications of Article 25 (direct marketing, privacy preservation and Privacy Enhancing Technologies (PETs), and EdTech). This Report also includes a number of Annexes that seek to provide more information on the specific cases analyzed and a comparative overview of DPA enforcement actions.
Our analysis determines that European DPAs diverge in how they interpret the preventive nature of Article 25 GDPR. Some are reluctant to find violations in cases of isolated incidents or where Article 5 GDPR principles are not violated, while others apply Article 25 preventively before further GDPR breaches or even planned data processing. Our research also finds that most DPAs are reluctant to specify appropriate protective measures and to explicitly outline the role of PETs. Ultimately, the Report shows that despite the novelty of Article 25, and the criticism surrounding its vague and abstract wording, it is a frequent source of some of the highest GDPR fines, highlighting the need for organizations to maintain a firm grasp over the concepts of DPbD&bD.
Vietnam’s Personal Data Protection Decree: Overview, Key Takeaways, and Context
Author: Kat MH Hille
The following is a guest post to the FPF blog from Kat MH Hille, an attorney with expertise in corporate, aviation, and data protection law. She graduated with a J.D. from the University of Iowa, School of Law, and has extensive experience practicing law in both the United States and Vietnam (contact: https://www.linkedin.com/in/katmhh/). The guest blog reflects the opinion of the author only. Guest blog posts do not necessarily reflect the views of FPF.
On April 17, 2023, the Vietnamese Government promulgated the Decree of Personal Data Protection (Decree), which was initially published as a draft on February 9, 2021 and went through several revisions. Before the Decree’s issuance, personal data protection in Vietnam was governed by 19 different laws and regulations, resulting in a fragmented legal framework. The Decree aims to fill these gaps and provide a comprehensive and uniform approach to personal data protection in Vietnam, extending safeguards for personal data to over 97 million people.
This post provides an overview of the Decree, including key dates, context, legal effects, requirements and how they fare with other comprehensive data protection law regimes around the world. Building on this foundation, certain key provisions and notable features of the Decree that warrant attention, including:
A prohibition on the sale and purchase of personal data through any means unless otherwise permitted by law.
The recognition of “Personal Data Controllers and Processors” as a distinct legal entity, with a mixed nature.
A strict purpose limitation principle that doesn’t allow for other uses of personal data than for the “registered purposes”.
Location data, creditworthiness, and financial data are protected as sensitive data, among other categories.
The Decree does not include “legitimate interests” among the lawful grounds for processing personal data, but it includes a permission related to personal data made public through legal means.
A specific clarification that silence or lack of response from the data subject does not constitute valid consent.
Increased transparency notices about personal data processed for advertising and marketing purposes.
Access requests require hefty documentation from data subjects, but they must be responded to within 72 hours – so do correction and deletion requests.
Data Transfer Assessments and a registration with the competent authority are requirements for all cross-border data transfers.
The lack of a prescriptive list of fines and sanctions.
Enforcement entrusted to an existing Government agency.
These provisions will be discussed in detail below.
1. Overview
The Decree is significant despite its lower status in Vietnam’s hierarchy of laws
As personal data protection is a new and developing area of law in Vietnam, Vietnam’s first legislative instrument on personal data protection takes the form of a “decree,” which is ranked lower in Vietnam’s statutory hierarchy than a code or law, and it is the result of executive action. A benefit of enacting a decree is that it can be done so more easily, without the need for approval from the National Assembly. Nevertheless, the Vietnamese Government’s goal is to ultimately enact a comprehensive and robust law for effective and enforceable personal data protection in 2024, according to a Decision issued by the Prime Minister in January 2022.
However, the Decree’s status means that in the event of conflicting regulations on the same issue, codes and laws would take precedence over the Decree. That said, the Decree remains the first comprehensive personal data protection regulation in Vietnam. Despite its lower legal status, the Decree still carries significant weight and impact in regulating personal data protection in Vietnam, and those who fail to comply with its provisions will still face legal consequences.
The Decree incorporates a unique blend of global standards and Vietnamese characteristics
Like other data protection laws inspired by the European Union (EU)’s General Data Protection Regulation (GDPR), the Decree sets out the responsibilities of organizations and individuals that process personal data, as well as the rights of individuals over their personal data.
However, the Decree also includes unique provisions that are specific to Vietnam’s context, such as a prohibition on the sale and purchase of personal data through any means, unless otherwise provided by law (Article 3.4), which may have significant consequences on the activity of data brokers and other businesses engaged in commodification of personal data. Additionally, organizing the collection, transfer, purchase, or sale of personal data without the consent of the data subject or the act of establishing software systems, as well as implementing technical measures for these purposes constitutes a violation of the Decree.
The Decree introduces the concept of “Personal Data Controllers and Processors,” which are entities or individuals that function both as Personal Data Controllers and Personal Data Processors. This definition is unique to the Decree and distinguishes it from other data protection laws around the world that typically only recognize the separate categories of Personal Data Controllers and Personal Data Processors. While the inclusion of Personal Data Controllers and Processors is meant to provide greater clarity and precision in defining the roles and responsibilities of different actors involved in personal data processing, it may actually add unnecessary complexity to the already complex landscape of privacy laws. This is because a single entity could be classified as both a Personal Data Controller and a Personal Data Processor depending on the specific definition being used, making it difficult to navigate and comply with the requirements of different privacy laws across different jurisdictions.
Further, the enacted Decree does not include a specific fine structure for violation of the Decree (the 2021 draft of the Decree proposed specific fines for single violations of the Decree, including fines of up to 5% of a personal data processor’s revenue for the most serious violations). Rather, the enacted Decree outlines a general provision that violators may be subject to disciplinary action, administrative penalties, or criminal prosecution, depending on the seriousness of the offense.
Furthermore, compared with the 2021 draft of the Decree, the final Decree does not provide for the establishment of a personal data protection commission to enforce the regulation. Rather, the Decree assigns responsibility for enforcing its requirements to an existing agency within the Ministry of Public Security (MPS), the Cybersecurity and High-Tech Crime Prevention Department (A05).
While MPS will need to clarify key provisions in subsequent regulations, the Decree creates the first comprehensive foundation to govern data processing activities in Vietnam. The Decree will take effect on July 1, 2023, giving organizations only two months to make the necessary adjustments to their business and operations in order to comply with the new regulations. Significant aspects of the Decree are explored below in greater detail.
2. The (extra)territorial scope introduces a nationality criterion for covered entities
The Decree applies to Vietnamese agencies, organizations, and individuals (whether based within or outside of Vietnam), and to foreign agencies, organizations, and individuals that are either based in Vietnam or that are based overseas and directly participate in or are otherwise involved in personal data processing activities in Vietnam.
Note that “personal data processing” covers a wide range of activities in relation to personal data, including collection, recording, analysis, verification, storage, alteration, disclosure, combination, access, retrieval, erasure, encryption, decryption, copying, sharing, transmission, provision, transfer, and deletion, as well as other related actions (Article 2.7).
There is still ambiguity as to the distinction between being “involved in” and “directly participating in” personal data processing activities, as well as the level of involvement with such activities that would bring a party within the scope of the Decree. Clarity on these issues through further regulations or guidance would be useful, especially considering that many third-party service providers or software vendors may arguably have some involvement in processing personal data.
3. The Decree recognizes a slightly different set of covered actors than other data protection laws
The Decree covers four categories of parties who process personal data:
“Personal Data Controllers” (PDCs) are organizations or individuals that determine the purposes and means of personal data processing. Personal Data Controllers have the most obligations under the Decree.
“Personal Data Processors” (PDPs) are organizations or individuals that process personal data on behalf of a Personal Data Controller under a contract or agreement with the Personal Data Controller.
“Personal Data Controllers and Processors” (PDCPs) are organizations or individuals that are simultaneously Personal Data Controllers and Personal Data Processors.
“Third Parties” (TPs) are any organization or individual authorized to process personal data other than Data Subjects, Personal Data Controllers, Personal Data Processors, or Personal Data Controllers and Processors.
In recognizing a distinction between controllers and processors, the final Decree removes ambiguity that was present in the 2021 draft of the Decree, which only provided for two categories of actors: personal data processors and third parties.
4. New processing principles, such as “no sale and purchase of personal data by any means”
The Decree outlines eight principles that govern data processing activities, which are similar to those recognized by the GDPR, including lawfulness, transparency of processing, purpose limitation, data minimization, accuracy, storage limitation, and appropriate measures to ensure the security of personal data. However, there are some notable differences.
Sale or Purchase of Personal Data: The Decree takes a more stringent stance than the GDPR by explicitly prohibiting the sale and purchase of personal data in any form, unless otherwise permitted by law. However, another provision in the Decree states that the act of “setting up software systems, technical measures or organization of the … purchase and sale of personal data without the consent of the data subject” is a violation (Article 22). Read together, the two provisions appear to imply that the purchase or sale with consent from the data subject could be permissible. Due to its ambiguity, further clarification is needed.
This stringent prohibition is a direct response to the numerous cases of personal data misuse that have occurred in Vietnam in recent years, including identity theft, financial fraud, intrusive advertising, and the exploitation of vulnerable individuals. A report showed that in 2022 alone, more than 17 million pieces of personal data were illegally harvested and sold for fraud and each personal data entry has been traded 987 times per day. However, the inclusion of a strict prohibition may conversely have a significant impact on industries that rely heavily on the use of personal data to drive innovation and business growth. It is possible that future circulars or guidelines may provide more clarity on this issue, including potential exceptions or allowances for certain use cases.
Notwithstanding this broad prohibition, PDCs and PDCPs may still share personal data with others if they obtain the data subject’s consent to do so, except when such sharing could harm national defense, national security, or public order and safety or could affect the safety or physical or mental health of others (Article 14). However, business entities and individuals providing marketing, product launching, and advertising services may only utilize personal data of their customers collected through their own business activities for conducting such services, if they obtain the data subject’s consent (Article 21).
Purpose Limitation: The Decree imposes a stricter purpose limitation compared to the GDPR, which allows for additional processing if it is compatible with the original purpose. Under the Decree, personal data can only be processed for the specific purposes that have been “registered” or “declared” by the PDC, PDP, PDCP, or TP. This requires these entities to ensure that their data processing activities do not deviate from or expand upon the registered and declared purposes. However, it is important to note that the Decree does not provide any guidance on how processing purposes are to be registered.
5. Covered data: broad definition of sensitive personal data, and stricter accountability rules for its processing
The Decree provides a broad definition of personal data, aligned with other comprehensive data protection laws. It defines personal data as any information that is expressed in the form of symbol, text, digit, image, sound or in similar forms in an electronic environment that is associated with a particular natural person or helps identify a particular natural person. Personally identifiable information means any information that is formed from the activities of an individual and, when used with other maintained data and information, can identify such particular natural person.
The Decree categorizes personal data into two groups: basic personal data and sensitive personal data, and includes an additional set of rules for the latter.
Basic personal data includes the following forms of personal data:
A person’s name(s);
A person’s date of birth, death, or having gone missing;
A person’s gender;
A person’s place of birth or residence;
A person’s nationality;
An image of an individual;
A number associated with a person, such as a telephone number or a number in an official document, such as an identity card number, driver’s license number, etc.;
A person’s marital status;
Information about a person’s family relationships;
Information about the individual’s online accounts or activities; and
Any other types of personal data that do not qualify as sensitive personal data.
Sensitive personal data is defined as personal data related to an individual’s privacy, a breach of which would directly affect the individual’s legitimate rights and interests.
The Decree provides a non-exhaustive list of types of personal data that would be considered sensitive, including:
A person’s political or religious views;
Information about a person’s health status or private life that is included in a person’s medical record (other than information about a person’s blood type);
Information relating to a person’s racial or ethnic origin;
Information about an inherited or acquired genetic characteristics of an individual;
Information about an individual’s physical attributes and biological characteristics;
Information about an individual’s sex life or sexual orientation;
Data about crimes and offenses that are collected and stored by law enforcement agencies;
Customer information of credit institutions, foreign bank branches, payment intermediary service providers, and other authorized organizations;
Information about the location of an individual that has been obtained through location services; and
Any other information that is subject to legal requirements to implement specific security measures.
The list of sensitive personal data provided is more extensive than the GDPR’s definition of sensitive personal data. It includes types of data such as customer information from financial institutions and location data obtained through location services. As non-cash transactions and targeted advertising become increasingly prevalent in Vietnam, these types of data are frequently collected by most businesses. As a result, a wider range of entities, including small and medium businesses, may be subject to sensitive personal data protection requirements due to the broad scope of the list.
The Decree imposes more stringent protection measures for sensitive personal data than for basic personal data. For instance, regulated entities that process sensitive personal data must specifically notify data subjects of any processing of their sensitive personal data. Organizations that are covered by the Decree also must designate a department within their organization and appoint an officer which will beresponsible for overseeing the protection of sensitive personal data and communicating with the A05.
Nevertheless, it is important to note that small, medium, and start-up enterprises are given a grace period of 2 years from their establishment to comply with these sensitive data requirements, unless such enterprises are directly engaged in processing personal data (Article 43). To qualify for the exemption, companies in agriculture, forestry, aquaculture, industrial, and construction sectors must have fewer than 200 employees and annual revenue below 200 billion Vietnamese dong (equivalent to approximately 8.7 million USD) or total capital below 100 billion Vietnamese dong (approximately 4.3 million USD), while commercial and service sector companies must have fewer than 100 employees and annual revenue below 300 billion Vietnamese dong (approximately 13 million USD) or total capital below 100 billion Vietnamese dong (approximately 4.3 million USD) in accordance with Decree No. 80/2021/ND-CP (2021) on Elaboration of Articles of the Law on Provision of Assistance for Small and Medium Enterprises.
6. Legal bases for processing personal data: no “legitimate interests,” but introducing “publicly disclosed” personal data
The Decree recognizes six legal bases for processing personal data, namely:
Where valid consent for processing personal data is obtained from the data subject;
In cases of emergency where personal data must be processed immediately to protect life or health of the data subject or others;
Wherethe personal data is publicly disclosedin accordance with the law;
Where a competent state agency processes personal data:
In a state of emergency relating to national defense and security, social order and safety, major disasters, or dangerous epidemics;
When there is a risk of threat to national security and defense that has not yet reached the level of declaring a state of emergency; or
To prevent and combat riots, terrorism, crimes, and violations of the law;
Where personal data is processed to fulfill contractual obligations of the data subject with relevant agencies, organizations, or individuals as provided by law; and
Where personal data is processed to serve the operations of state agencies as prescribed by specialized laws.
Additionally, under Article 18 of the Decree, competent governmental agencies may obtain personal data from audio and video recording activities in public places without the consent of data subjects. However, when conducting recording activities, the authorized agencies and organizations are responsible for informing data subjects that they are being recorded.
Notably, the Decree does not provide a “legitimate interests” lawful ground like the GDPR. Nevertheless, legitimate interests are recognized in other provisions of the Decree. In particular, Article 8 stipulates “Prohibited Acts,” including processing personal data to create information that affect “legitimate rights and interests of other organizations and individuals”.
As for “valid consent”, there are several conditions that must be met when obtaining it, pursuant to Article 11 of the Decree:
The consent must be freely given and fully informed.
The consent must be explicitly and specifically expressed. This can be done in writing, orally, or through other clear actions, such as checking a consent box, sending a text message, or selecting technical consent settings. The consent must also be given in a format that can be printed, copied, or verified, meaning that it must be able to be saved and documented for future reference.
When making a request for consent, the PDC and the PDCP must list out the types of personal data, the purposes for which consent is sought, organizations and individuals processing personal data and the rights and obligations of data subjects. The consent applies only to the specific purpose(s) stated. This language suggests that catch-all consent to all purposes is not allowed.
Furthermore, partial or conditional consent is allowed, but silence or lack of response from the data subject does not constitute valid consent. This appears to preclude implied or deemed forms of consent.
Consent for processing the personal data of a missing or deceased person may be obtained from the person’s spouse, children, or parents. If none of these individuals are available, valid consent cannot be obtained (Article 19).
The given consent remains valid until it is withdrawn by the data subject or until a competent state agency requests otherwise in writing. PDCs and PDCPs bear the burden of proof in case of a dispute regarding the lack of consent from a data subject.
Data subjects may request to withdraw their consent to processing of their personal data (Article 12). When a data subject does so, the PDC or PDCP must inform the data subject of any potential negative consequences or harms from the withdrawal of consent.
If the data subject still wishes to proceed, all parties involved in processing the personal data, including the PDC or PDCP and any PDPs or TPs, must cease processing the personal data. There is no set time frame for fulfilling this obligation, but it should be done within a reasonable period of time.
The withdrawal of consent must be in a format that can be printed, copied in written form, or verified electronically. The withdrawal of consent shall not render unlawful any data processing activities that were lawfully performed based on the consent given prior to the withdrawal.
7. The rights of the data subject include transparency and control rights, but also rights to legal remedies
Article 9 of the Decree provides data subjects with 11 rights over their personal data, which are linked to corresponding obligations on entities that process personal data:
Right to be informed about the processing activities involving their personal data.
Right of consentor to withhold consent to the processing of their personal data.
However, if a data subject chooses to provide consent for the processing of their personal data, the data subject is responsible for ensuring that any information provided is accurate and complete (Article 10).
Right to access their personal data in order to view, correct, or request correction of the data.
Right to withdraw consent to the processing of their personal data.
Right to delete their personal data or request that such data be deleted
Right to restrict processing of their personal data by request.
Right to be provided with a copy of their personal data or port their personal data to another entity.
Right to object to use or disclosure of their personal data for advertising and marketing purposes.
Right to make complaints and denunciations and/or commence legal action according to law.
Right to claim damages according to law where data subjects’ rights under personal data protection regulations have been violated, unless parties agree to the contrary, or as otherwise provided by law.
Right to request orders for protection of their rights under relevant provisions of the Civil Code, the Decree, and other laws. Available orders under Article 11 of Vietnam’s Civil Code include termination of the violating act, public apology or rectification, performance of civil obligations, compensation, or reversal of a violating decision.
Note that all of these rights are subject to exceptions provided by the Decree or other relevant laws.
7.1. Transparency requirements include detailed notices and access rights on a tight deadline
According to Article 11 and 13, before processing a data subject’s personal data, a PDC or PDCP must provide a notification to the data subject containing the following information:
The types of personal data being processed;
The purpose(s) for processing the data;
The means of processing data;
The organizations or individuals involved in processing of the data;
The data subject’s rights and obligations under the Decree;
Potential consequences and harms from processing;
The duration of processing, including the start and end dates; and
Where personal data is processed for advertising and marketing purposes, the content, method, form, and frequency of product marketing (Article 21).
However, such notification is not required when personal data is being processed by a competent state authority or if the data subjects have been fully informed of, and have given valid consent to, the processing of their personal data.
Data subjects have the right to request that PDCs and PDCPs provide them with a copy of their personal data or share a copy of their personal data to a third party acting on their behalf (Article 14). The PDC or PDCP must fulfill such a request within 72 hours of receiving it.
The request must be submitted in the Vietnamese language and made in a standardized format as set out in the Appendix to the Decree. The request must include the requestert’s full name, residential address, national identification number, citizen identification card number, or passport number; fax number, telephone number, and email address (if any); and the form of access and the reason and purpose for requesting the personal data. The data subject must also specify the name of the document, file, or record to which their request pertains (Article 14.6). This requirement can impose a significant burden on data subjects as they may not always be fully aware of which documents or records their personal data is contained within. Additionally, the complexity of data processing can further complicate matters and make it difficult for the data subject to identify the relevant documents.
It is important to note that, unlike the GDPR, the Decree does not require a PDC or PDCP to provide data subjects with comprehensive information about the processing of their personal data in a concise, transparent, intelligible, and easily accessible form, using clear and plain language.
Moreover, there are certain circumstances in which a PDC or PDCP are not required to provide the data subject with a copy of their personal data. These include where:
Such provision may threaten national defense, national security, or social order and safety;
Such provision may endanger the safety, physical, or mental health of others; or
The data subject has not given consent for the disclosure or authorized a representative to receive their personal data.
7.2. The Decree provides for an absolute right to object to processing, as well as correction and deletion rights
A PDC or PDCP must promptly fulfill a data subject’s request to access their personal data, correct their personal data, or have their personal data corrected, according to Article 15.
The PDP and any third party shall be authorized to edit the personal data of the data subject only after obtaining written consent from the PDC and PDCP and ensuring that the data subject has given their consent.
If the PDC or PDCP is unable to fulfill the request due to technical or other reasons, the PDC or PDCP must notify the data subject within 72 hours.
If a data subject requests that the processing of their personal data be restricted or otherwise objects to the processing of their personal data, the PDC or PDCP must respond to the request within 72 hours of receiving it (Article 9).
One important difference between this requirement and the one in the GDPR is that the Decree does not provide any exceptions to this requirement. Under the GDPR, a controller may be able to demonstrate compelling legitimate grounds that override the interests, rights, and freedoms of the data subject, or may be able to claim that they need the data for the establishment, exercise, or defense of legal claims.
According to Article 16, the PDC or PDCP must delete personal data about a data subject within 72 hours of a request by the data subject, if:
The personal data is no longer necessary for the purpose to which the data subject consented;
The data subject withdraws consent for processing of the personal data;
There is no lawful reason to continue processing the personal data;
The personal data is processed for a purpose other than one to which the data subject has consent or is otherwise is processed unlawfully; or
Deletion of the personal data is required by law.
Personal data shall be deleted irretrievably by the PDC, PDCP, PDP, and/or TP if it was processed for improper purposes or the consented purpose(s) has been fulfilled, if storage is no longer necessary, or if the entity responsible for the data has dissolved or terminated business operations due to legal reasons.
Like the GDPR, the Decree recognizes certain exceptions to the right to delete personal data, such as where:
The law prohibits deletion of the personal data;
Continued processing of the personal data is necessary for legal, statistical, or scientific research purposes; or
The personal data is processed by a competent government agency for lawful purposes or in emergency situations that threaten life, health, or safety.
However, unlike the GDPR, personal data that has been lawfully made available to the public is also exempt from the right to deletion (Article 18). As a result, the PDC or PDCP may reject a data subject’s request to delete personal data that has become public, regardless of whether there are any other lawful grounds for retaining such data. This differs from the GDPR, which does not provide exceptions based solely on the public availability of data.
8. Obligations of Controllers and Processors, from written processing agreements to data security and accountability obligations
PDPs are under an obligation to only receive personal data from a PDC after signing an agreement on data processing with the PDC and only process the data within the scope of that agreement (Article 39). The Decree also provides that personal data must be deleted or returned to the PDC upon completion of the data processing.
8.1. Data security and data breach notification requirements
The Decree has dedicated data security requirements for PDCs. For instance, Article 38 asks them to implement organizational and technical measures, as well as appropriate security and confidentiality measures to ensure that personal data processing activities are conducted lawfully. They also need to review and update these measures as necessary, and record and store a log of the system’s personal data processing activities.
Appropriate security measures are also relevant in the PDC – PDP relationship, as PDCs must select a suitable PDP for specific tasks and only work with a PDP that has in place appropriate protection measures. Interestingly, both PDCs and PDPs have a distinct obligation to cooperate with the MPS and competent state agencies by providing information for investigation and processing of any violations of the laws and regulations on personal data protection.Organizations and individuals involved in personal data processing must implement measures to protect personal data and prevent unauthorized collection of personal data from their systems and service devices. Article 22 of the Decree also prohibits the use of software systems, technical measures, or the organization of activities for the unauthorized collection, transfer, purchase, or sale of personal data without the consent of the data subject.
Under Article 23 of the Decree, in the event of a violation of personal data protection regulations, both the PDC and the PDP, or PDCP, are required to promptly inform the A05. The notification must be made no later than 72 hours after the violation occurred. If the notification is delayed, the reason for the delay must be provided. The current wording in the Decree is broad and without further clarifications and guidance it could be interpreted as meaning a notification is required for any violation of the Decree, not just for data breaches.
The notification must include a detailed description of the violation, such as the time, location, act, organization or individual involved, types and amount of personal data affected, contact details of those responsible for protecting personal data, potential consequences and damages of the violation, and measures taken to resolve or minimize harm. If it is not feasible to provide a complete notification at once, it can be done incrementally or progressively.
However, Decree 13 does not provide a specific procedure for A05 to handle complaints related to personal data protection violations. Further guidance or clarifications may be issued in the future.
8.2. “Impact Assessment Reports” that have to be made available for inspection
Article 24 of the Decree requires PDCs and PDCPs to compile an impact assessment report (IAR) from the commencement of personal data processing and make the report available for inspection by the A05 within 60 days thereafter.
The IAR must contain:
Information and contact details of the PDC or PDCP and its data protection officer(s);
Details of the types of personal data being processed and the purpose for doing so;
Identities of recipients of the data (including those outside of Vietnam);
The circumstances of any cross-border data transfers of the data;
A description of measures implemented to protect the data;
The time frame for processing and deletion of data; and
An evaluation of the impact and potential risks associated with the processing of personal data.
PDPs are also required to compile an IAR. However, the required content is slightly different, reflecting the difference in roles between PDCs/PCDPs and PDPs. For instance, the Decree requires a PDP to provide a description of the processing activities and types of personal data processed, rather than stating the purpose(s) for processing the data.
9. Cross-Border Data Transfers have a legal definition and a registration requirement
Article 25 of the Decree defines a cross-border transfer of personal data as:
The transfer of personal data of Vietnamese citizens to a location outside of Vietnam; or
The use of a location outside of Vietnam to process thepersonal data of Vietnamese citizens.
This definition includes the:
Transfer of personal data to overseas organizations for processing; and
Processing of personal data using automated systems located outside of Vietnam (note that Article 2.13 of the Decree defines automated personal data processing as the electronic processing of personal data to analyze, evaluate, and predict the behaviors, habits, preferences, reliability, tendencies, capacities, and locations of an individual).
In the absence of further specification and relying on a literal reading of the wording in Article 25, a possible interpretation of this definition is that processing outside of Vietnam the personal data of Vietnamese citizens who live outside Vietnam would also qualify as a cross-border data transfer under the Decree. If this interpretation is correct, it would mean that all foreign organizations or individuals processing personal data outside of Vietnam would be subject to the Decree’s “cross-border data transfer” requirements even if there is no actual border of Vietnam involved, insofar as they process the personal data of Vietnamese citizens. It should be noted that the scope of the Decree, as stipulated in Article 1.2, only applies to foreign agencies, organizations, and individuals that are in Vietnam or that directly participate or are involved in the personal data processing activities in Vietnam. This ambiguity may be clarified in a guidance document in the future.
Before a covered entity may transfer personal data out of Vietnam, the Decree requires that the entity must:
Undertake a data transfer assessment (DTA);
Apply to the A05 by submitting a copy of the DTA together with a form specified in the Decree to the Department within 60 days from the date of processing;
Provide further information to the A05 if the application is complete or if any information is incorrect; and
Notify the Department after the data transfer has taken place successfully.
The DTA must contain the following information:
Information and contact details of the transferrer and receiver of the personal data of Vietnamese citizens;
The full name and contact details of the organization and/or individual that is in charge of the transferrer;
Descriptions and explanations of the purposes for the transfer;
Descriptions and clarification of the type of personal data to be transferred;
The measures applied to comply with the Decree’s requirements to protect personal data;
Assessment of the impact of personal data processing, the potential consequences and damage, and measures to reduce or eliminate such risk or harm;
Details of the consent of the data subject given with a clear understanding of the feedback mechanism and complaint procedures available in the event of incidents or requests; and
A binding contract between the transferer and the receiver specifying the responsibilities of the parties involved regarding the personal data processing.
In light of the consent disclosure required as part of the DTA and in the absence of further regulatory guidance, it seems that consent is the only basis for cross-border transfers. In addition to all requirements for a valid consent, in the context of cross-border transfers, the consent shall include a clear explanation of the feedback mechanism and the available procedures for lodging complaints in the event of incidents or requests, ensuring a comprehensive understanding for the individuals involved.
The MPS will conduct inspection of the DTA annually unless a violation, data incident, or leakage occurs. The MPS may cease transfers in cases where:
Personal data is found to be used for activities that violate the interests and national security;
The transfer fails to comply with requirements for the DTA; or
Loss or leakage of the personal data of Vietnamese citizens occurs.
It should be noted that data localization is separately governed under Decree No. 53/2022/ND-CP, which implements the Law on Cybersecurity. The decree applies to both domestic and foreign companies operating in Vietnam’s cyberspace, specifically those providing telecom, internet, and value-added services that collect, analyze, or process private information or data related to their service users. According to the decree, these companies must store the data locally and have a physical presence in Vietnam. They are also required to retain the data for a minimum of 24 months.The types of personal data subject to localization include “(i) personal information of cyberspace service users in Vietnam in the form of symbols, letters, numbers, images, sounds, or equivalences to identify an individual; (ii) data generated by cyberspace service users in Vietnam, including account names, service usage timestamps, credit card information, email addresses, IP addresses from the last login or logout session, and registered phone numbers linked to accounts or data; (iii) data concerning the relationships of cyberspace service users in Vietnam, such as friends and groups with whom these users have connected or interacted.” (Article 26, Decree 53). The governing authority responsible for these regulations is A05 as well.
However, it remains unclear from the provided information whether personal data falling within the scope of Decree 53 can be transferred cross-border after fulfilling all requirements, including obtaining valid consents from data subjects. It is possible that the regulations are strictly interpreted to prohibit cross-border transfers for such types of data.
10. Specific Requirements for Children Personal Data
Like the GDPR, Article 20 of the Decree provides special protection for children’s personal data, with a focus on safeguarding their rights and best interests. However, the age threshold for obtaining valid consent differs between the two laws. In Vietnam, the Decree requires the consent of a parent or legal guardian and of children aged seven or older, while the GDPR only allows individuals over 16 to give consent independently for processing of their personal data.
It is important to note that in Vietnam, children under the age of 16 are not considered to have legal capacity, meaning that they cannot legally enter into contracts on their own behalf except in exceptional cases. As such, the effect of the child’s consent absent that of a parent or legal guardian is not entirely clear, although the requirement to obtain consent from the child was likely included in the Decree to reflect the child’s opinion on the processing of their personal data.
PDCs, PDPs, PDCPs, and TPs must verify the age of children before processing their personal data. However, the Decree does not explicitly provide an age verification process. Processing of children’s personal data must cease, and the personal data must be deleted irretrievably, where:
The processing is not for a purpose covered by valid consent;
The purpose for processing the personal data has been completed;
The child’s parent or legal guardian withdraws their consent for processing of the child’s data; or
There is a request to do so from a competent state authority that can provide sufficient evidence that the processing has a negative impact on children’s rights and interests.
The Decree states that only the child’s parent or legal guardian can withdraw consent for the processing of the child’s data, leaving it unclear whether the child can revoke their consent and have their data deleted if they wish to do so.
Conclusion
Vietnam’s new Decree on Personal Data Protection marks a significant milestone in protecting personal data in the country. The Decree introduces key concepts and principles of personal data protection, and sets out specific requirements for data processors and controllers. It also establishes a regulatory framework for obtaining consent for data processing activities, cross-border data transfers, and children data protection, which can contribute to safeguarding the privacy and security of individuals’ personal data.
While the Decree addresses many of the current challenges facing personal data protection in Vietnam, there are still gaps that need to be addressed in forthcoming guiding documents, including the lack of a specific procedure for handling complaints related to personal data protection violations, the conflicting provisions on the sale of personal data need to be clarified, the impact of cross-border data transfers and clear guidelines and requirements for such transfers and a more defined fine structure. It should also provide guidance on automated processing and establish regulations for biometric data. As Vietnam continues to develop its data protection laws, it is important for the law to address key issues such as automated personal data processing, biometrics or facial recognition, global data transfer baseline standards, and the need to balance business development with data protection.
In conclusion, the country’s commitment to personal data protection and privacy is a crucial step in the digital age. As Vietnam continues to strengthen its data protection framework, it will be interesting to see how it aligns with, and how it contributes to emerging frameworks in the region and around the world.
Editors: The success of this article would not have been possible without the dedicated efforts of Dominic Paulger, Josh Lee Kok Thong, and Isabella Perera,as well as the tremendous encouragement of Dr. Gabriela Zanfir-Fortuna from the Future of Privacy Forum.
Analysis of a Decade of Israeli Judicial Decisions Related to Data Protection (2012-2022)
Adv. Rivki Dvash with the assistance of Mr. Guy Zomer1
Background
The Future of Privacy Forum’s office in Tel Aviv (Israel Technology Policy Institute – ITPI) sought to examine the judicial decisions in civil actions under Israel’s Privacy Law, which includes rules that regulate data protection. We examined the extent to which the general public demands protection of the right to privacy through judicial proceedings. We also analyzed the privacy and data protection issues that concern the public enough to appeal to the court, as well as identified any patterns in the appeals.
It is important to note that there is a contradiction inherent in taking civil actions to remedy privacy and data protection violations since appealing to judicial bodies brings attention to and publicly catalogs the disputes. 2 As such, there is an occasional interest to not pursue these matters in order to prevent additional publication or exposure of information that could increase the harm of the initial violation of privacy. Accordingly, the data gathered in this analysis does not necessarily reflect the complete interest and desire the public has in protecting privacy, but rather the cases in which individuals chose to seek judicial remedy under the Privacy Law.
In order to examine all of these cases, we asked Mr. Guy Zomer of Octopus – Public Information for All (R.A.) – which works to make public information, including that related to judicial proceedings, accessible through the Tolaat Hamishpat – to compile all the rulings since 2012 that mention privacy violations and retrieve relevant metadata for our analysis.
The overview below highlights the information and insights gathered from the metadata.
Methodology
Collection of rulings from the Nevo website
In order to locate rulings related to privacy violations, we queried all published rulings issued from January 1, 2012, to December 31, 2022 to find those that included reference to Section 2 of the Privacy Law, 5741-1981 (from now on referred to as “the Law”), which defines an invasion of privacy and what constitutes a civil tort (and a criminal offense). The dataset only includes rulings issued in ordinary courts (magistrate, district, and supreme), and not those issued in special courts such as the Family Court and the Labor Court.
Initial screening
Since we wanted to concentrate on civil proceedings to discover common patterns, we removed criminal judgments and appeal proceedings from the dataset. We also chose to examine and compare decisions related to class actions separately from other civil proceedings.
We identified a total of 293 judgments issued in civil lawsuits and 29 judgments in class actions that referred to privacy violations.
Data collection
The dataset of civil claim decisions related to privacy violations initially only contained primary data such as the opening and closing dates of proceedings and the amount of the claims. We then added the following secondary data:
The additional grounds in the civil lawsuit (defamation, spam, etc.), if any;
The specific grounds for which the claim was filed (in other words, which subsection of Section 2 is used), even if the court did not recognize the requested cause or all the grounds for which the claim was filed;
The relationship between the plaintiff and the defendant (neighbor, employer-employee3, family, etc.);
Whether the plaintiff claimed concrete damage or compensation without proof of damage;
Whether the court recognized defense claims (this refers to the acceptance of defense claims in a judicial decision, and not to the fact that the defending party raised them);
Who won the lawsuit;
The amount of compensation mandated due to the violation of privacy;
The amount of expenses that have been mandated; and
The total amount of compensation that was mandated, including expenses or other grounds.
We examined class action cases separately from civil lawsuits since class actions focus more on potential harm to a group of people rather than an individual and the monetary compensation is structured differently with three components: individual winnings, group winnings, and lawyer fees, which are higher than is usually customary and serve as an incentive to file class actions.
Preliminary research findings
1) It should be noted that the data we examined only related to published judgments. We have yet to learn about the number of relevant claims in which the proceedings were stopped for various reasons (such as a settlement or lack of legal proceedings by the plaintiff or closed-door proceeding). Given that there is no labeling of privacy protection procedures in the Net HaMishpat (the computerized system for managing court cases in Israel), it is impossible to locate such information.
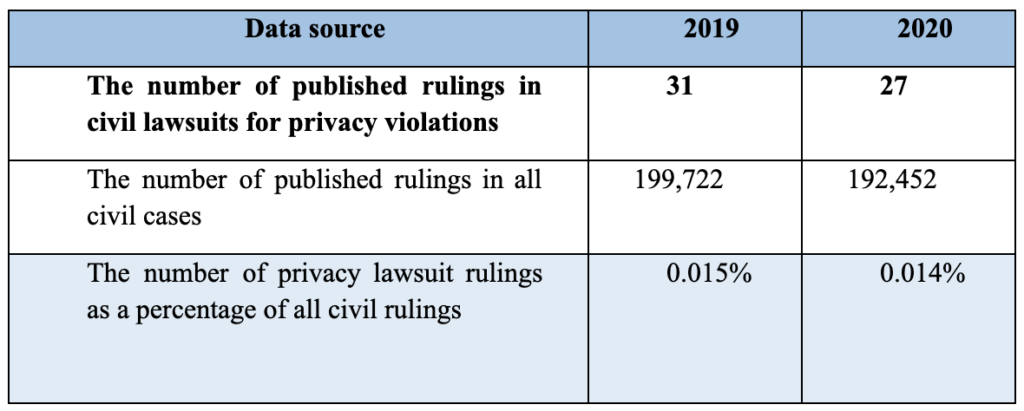
2) There is a small number of verdicts related to privacy violations and there are only several dozen privacy cases yearly. In comparison, in 2019, about 200,000 cases were closed in the Magistrates’ and District Courts. 4 Furthermore, in 2020, about 192,400 cases were closed in these courts. 5 In other words, the judgments in matters of privacy in Israel are a negligible percentage of all civil proceedings.
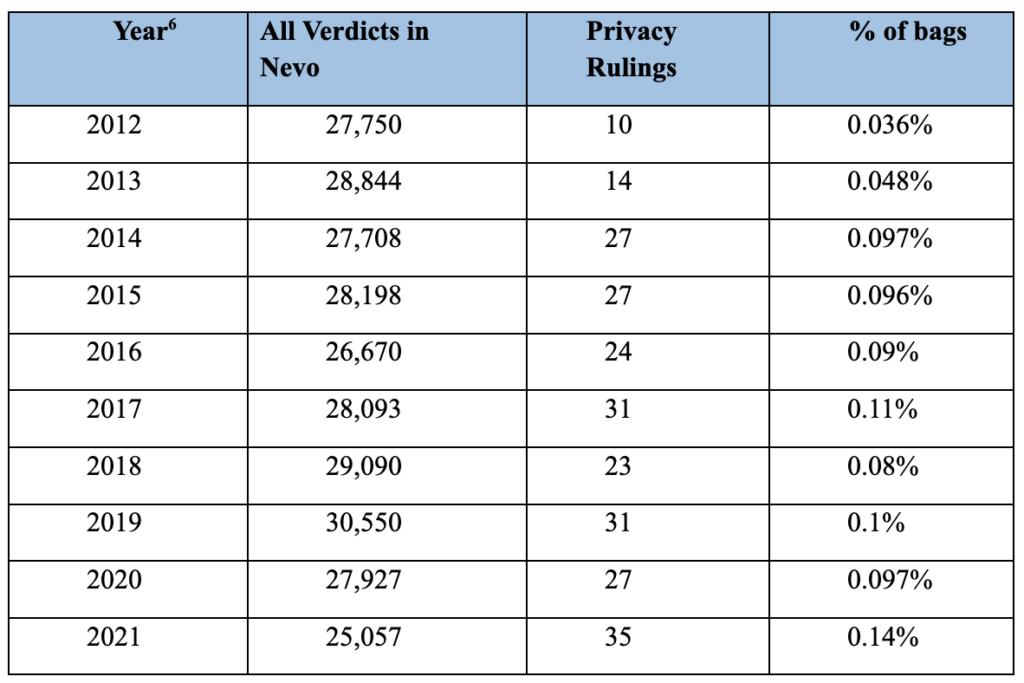
3) We looked at the approximate weight of published privacy violation claims as a percentage of total published civil lawsuits over several years to see whether there are any patterns. Although this method is not statistically accurate, it is still useful to examine the variable ratio between all judgments and privacy judgments published in Nevo.
However, even in the test mentioned above, we could not locate or indicate a clear trend, as seen below.
Findings
Civil Lawsuits
1. In all the cases, except for one,7 the plaintiffs preferred to claim compensation without proof of damage under section 29A of the Law.
2. The most common issue in civil lawsuits is the photographing of a person and placing of cameras in public, and sometimes even private spheres, accounting for 5.1% of claims.
3. We did not find any civil lawsuits for torts from privacy violations in databases. The initial assumption was that such claims are found in class actions (see below).
4. Civil lawsuits for privacy violations were generally connected to legal claims for other torts. Less than 20% of the claims filed for privacy violations were filed as a single damage (17%).
5. 19.8% of plaintiffs chose to file their claim in “Small Claims Courts,” which allow for relatively quick and no-frills compensation in an amount limited to up to NIS 36,400 (roughly USD 10,000).
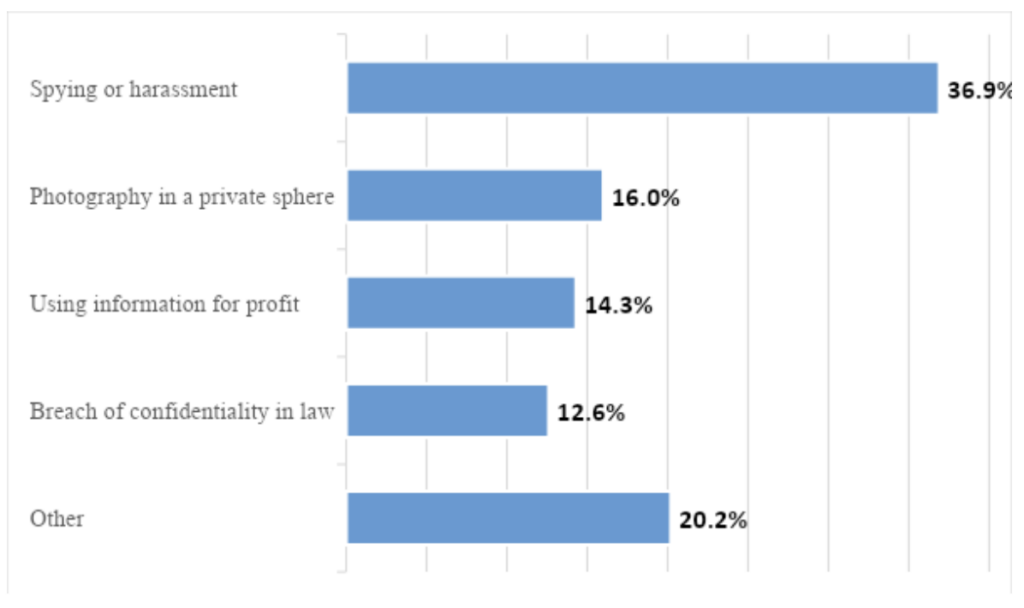
6. The main ground for civil lawsuits is the “spying on or tracing of a person,” or other harassment. This ground appears in 36.9% of civil court rulings. For context of how dominant this cause is, the second most common ground (photographing a person without their permission) is cited in only 16% of all judgments.
7. The most common relationship between plaintiffs and defendants is a consumer relationship (24%) or a neighbor’s dispute (21.8%). A citizen’s claims against the authorities account for 8.9% of all claims, with the leading cause of action for this type of relationship being a breach of the confidentiality obligation established by the Law (40%).
8. Although privacy violations from media exposure create significant harm due to their broad exposure of information, only a low percentage of filed claims are due to this type of violation (7.5%). Additionally, claims due to this type of violation are always accompanied by a civil lawsuit for other claims such as defamation. Generally, defamation claims appear next to privacy violation claims (52%).
9. 9.9% of privacy claims also involved spam claims filed under Section 30A of the Communications Law. This finding is interesting because during the legislative process for spam regulations, it was determined that they should be incorporated into the Communications Law instead of the Privacy Law. Regardless, even in decisions that recognized both privacy and spam violations, the compensation amounts remained extremely low (no more than a few thousand shekels).
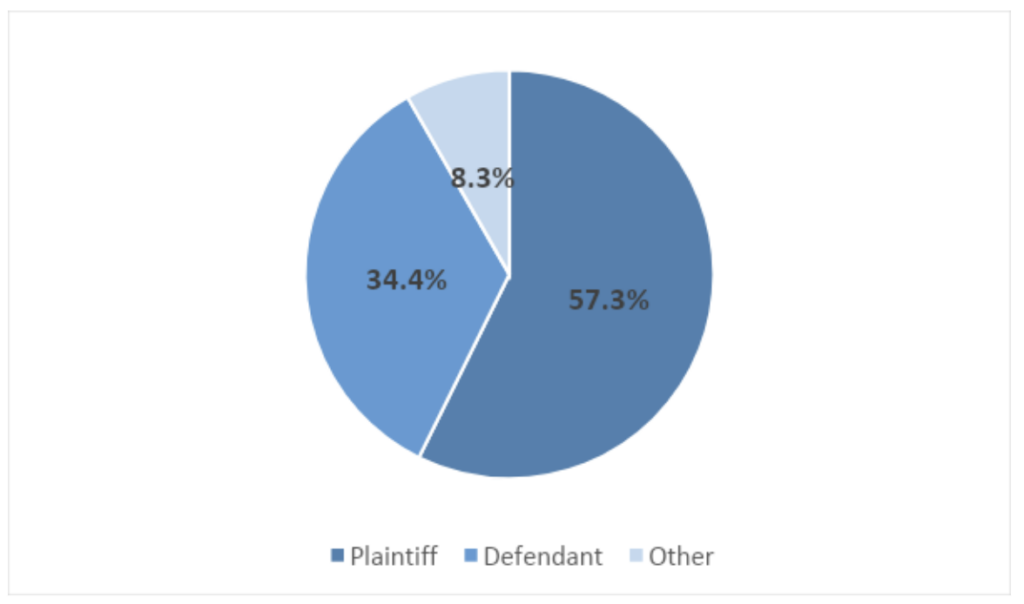
10. In most cases (57.3%), the plaintiff won the claim, compared to 34.4% of cases in which the defendant won (in the other claims, there was no definitive decision). However, a deeper examination of these claims shows that only 46.7% of them were compensated for the privacy violation. In other words, sometimes the plaintiff won the case, but not on the grounds of the privacy violation, or general compensation was provided without specifically referring to the privacy violation.
11. In almost a quarter of the rulings (24.5%), the court recognized legal defense protections under the Law. 9 The most recognized protection (40.3%) is in the case of “legitimate personal interest” (section 18(2)(c)).
Class Actions
12. Class actions related to privacy violations (29 cases) account for a small number of all class actions (6493 cases). However, the relative share (4.5%) is larger than the ratio of civil privacy violation claims compared to all civil claims (about 0.09%). This larger relative share is even more significant given that privacy violation class actions in Israel are more limited tools than civil lawsuits since class actions can only apply to the specific types of claims listed in the second addendum to the Class Actions Law, 5766-2006. 10
13. Most of the class actions that include grounds for privacy violations are also related to consumer protection.
14. Spam violations constitute the additional (or, more precisely, the primary) ground in a significant share of privacy violation class actions (69%). Four cases (15.4%) also mentioned the issue of registering the databases that are the subjects of the claims.11 Furthermore, in four cases (15.4%), it was claimed that the information security of the databases in question were compromised.
15. In 17.2% of privacy violation cases the court rejected the motion to file a class action.
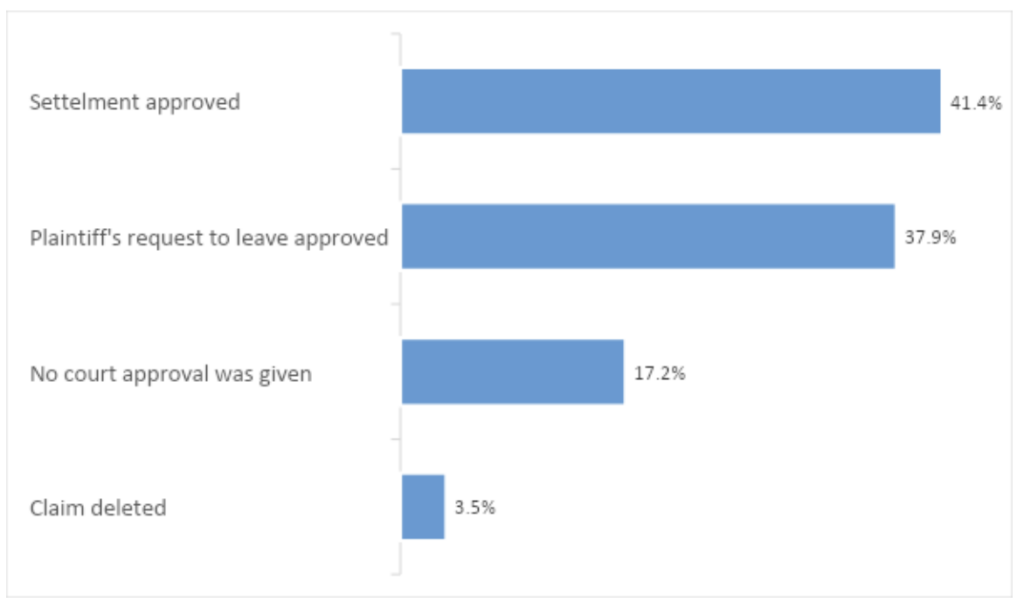
16. Of the 29 cases in which a judgment was given (including court rejection to form a class action), in 41.4% of cases, the court approved the settlement, and in 37.9% of cases, the court approved the plaintiff’s motion for leave.
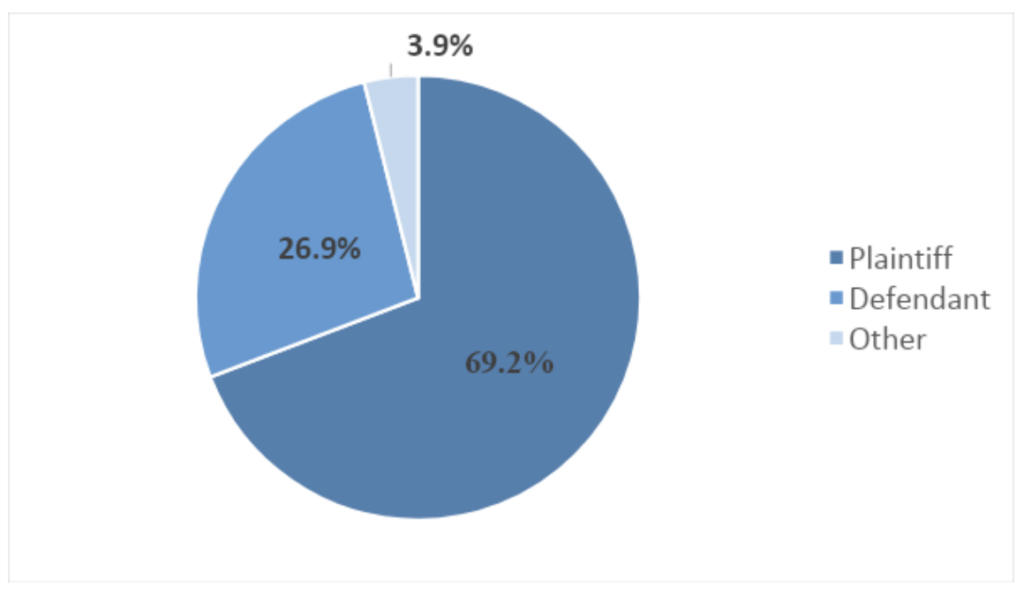
17. 69.2% of claims ended in favor of the plaintiff, and only about 26.9% of the decisions favored the defendant, with plaintiffs liable for expenses in only four cases (15.4%).
Conclusion
Despite the difficulty in getting clear insights into privacy violation civil lawsuits and class actions due to the scarcity of rulings in this area, it is still necessary to examine these decisions.
The small number of claims in this area may indicate the public’s lack of interest in exercising its right to compensation when privacy violations occur. Part of this disinterest is likely due to the desire to prevent additional publication or exposure of information that could increase the harm from the initial privacy violation. Interestingly, the larger amount of privacy violation class actions as a percentage of all class action lawsuits (compared to civil lawsuits) indicates that given a larger financial incentive and decreased risk of exposure of individuals’ personal information, the desire to file lawsuits may increase. This tentative hypothesis is supported by the higher numbers of class action and civil lawsuits related to spam violations, both of which have high compensation potential and do not reveal additional personal information about plaintiffs. However, given the small absolute number of both class action and civil lawsuits related to privacy violations, more research is needed to fully examine the motivations of plaintiffs.
Even with the small number of claims, there are still several interesting findings, including clarity into the types of privacy violations that concern the public. For example, it is evident that plaintiffs mostly bring violations related to neighbor disputes and placement of cameras in public spaces for surveillance. The research also shows that despite the higher potential for privacy violations from state authorities or the greater harm from violations of database-related provisions of the Law, there are almost no lawsuits concerning these issues. One potential hypothesis for the lack of these claims is that there are power gaps between citizens and authorities, as well as data subjects and database owners, that disincentivize lawsuits. Although class actions can strengthen the power of the consumer, they still require proof of damage and also cannot be filed against the state.
In conclusion, it is impossible to point to a change or a clear trend of citizens exercising their right to privacy in civil lawsuits over the past decade.
Editor: Isabella Perera
This text has been translated and adapted into English from the original report published on January 30, 2023, available in Hebrew following this link.
1 Thanks to Adv. Limor Shmerling-Magazanik, former Director of ITPI, for her comments on this report.
2 In Israel, the default is that legal proceedings are published stating the parties’ names.
3 It should be noted that even in civil proceedings in ordinary courts (not the Labor Court), we still found claims related to employee-employer relationships.
4 See Annual Report 2019 – Court Administration (in Hebrew), pp. 25 and 37. In the district courts, 8,278 civil cases were closed, and in magistrates’ courts, 191,444 such cases were closed.
5 See Annual Report 2020 – Court Administration (in Hebrew), pp. 25 and 37. In the district courts, 7,578 civil cases were closed, and in magistrates’ courts, 184,874 such cases were closed.
6 We did not include 2022 because there was a change in the classification of cases in civil lawsuits that altered how the selected group was sampled.
7 Civil Action (Magistrate court – Haifa) 54043-11-12 Naor v. Clal Pension and Provident Fund Ltd. (11/4/2014) (in Hebrew), in which the plaintiff lost.
8 As of January 2023.
9 Section 18 of the Privacy Law.
10 Such as dealers, banking corporations, financial services providers, etc.
11 In Israel, there is still an obligation to register databases.
Workplace Discrimination and Equal Opportunity
Why monitoring cultural diversity in your European workforce is not at odds with GDPR
Author: Prof. Lokke Moerel*
The following is a guest post to the FPF blog from Lokke Moerel, Professor of Global ICT Law at Tilburg University and a lawyer with Morrison & Foerster (Brussels).
The guest blog reflects the opinion of the author only. Guest blog posts do not necessarily reflect the views of FPF.
“It has been said that figures rule the world. Maybe. But I am sure that figures show us whether it is being ruled well or badly.” – Johann Wolfgang von Goethe
I. Introduction
It is a known fact that discrimination persists in today’s labor markets,1 this despite EU anti-discrimination and equality laws—such as the Racial Equality Directive—specifically prohibiting practices that put employees at a particular disadvantage based on racial or ethnic origin.2 In a market where there is an acute scarcity of talent,3 we see HR departments struggle with how to eliminate workplace discrimination and create an inclusive culture in order to be able to recruit and support an increasingly diverse workforce. By now, many organizations have adopted policies to promote diversity, equity, and inclusion (DEI) in their organizations and the need has arisen to monitor and evaluate their DEI efforts.
Without proper monitoring, DEI efforts may well be meaningless or even counterproductive.4 To take a simple example, informal mentoring is known to be an important factor for internal promotions, and informal mentoring is less available for women and minorities.5 Organizations setting up a formal internal mentoring program to address this imbalance would like to monitor whether the program is attracting minorities to participate in the program and achieving its goal of promoting equity. If not, the program may unintentionally only exacerbate existing inequalities. Monitoring is therefore required to evaluate whether the mentoring indeed results in more equal promotions across the workforce or whether changes to the program should be made.
Organizations are hesitant to monitor these policies in the EU based on a seemingly persistent myth that the EU General Data Protection Regulation 2016/679 (GDPR) would prohibit such practices. This article shows that it is actually the other way around. Where discrimination, lack of equal opportunity, or pay inequity at the workplace is pervasive, monitoring of DEI data is a prerequisite for employers to be able to comply with employee anti-discrimination and equality laws, and to defend themselves appropriately against any claims.6
For historic reasons,7 the collection of racial or ethnic data is considered particularly sensitive in many EU member states. EU privacy laws provide for a special regime to collect sensitive data categories such as data revealing racial or ethnic origin, disability, and religion, based on the underlying assumption that collecting and processing such data increases the risk of discrimination.
However, where racial or ethnic background are ‘visible’ as a matter of fact to recruiters and managers alike, individuals from minority groups may be discriminated against without recording any data. It is therefore only by recording the data that potential existing discrimination may be revealed, and bias can be eliminated from existing practices.8
A similar issue has come to the fore where tools are used which are powered by artificial intelligence (AI). We often see in the news that the deployment of algorithms leads to discriminatory outcomes.9 If self-learning algorithms discriminate, it is not because there is an error in the algorithm, it is because the data used to train the algorithm are “biased.” It is only when you know which individuals belong to vulnerable groups that bias in the data can be made transparent and algorithms trained properly.10 Also here, it is not the recording of the sensitive data that is wrong, it is humans who discriminate, and the recording of the data detects this bias. Organizations should be aware that the “fairness” principle under the GDPR cannot be achieved by unawareness. In other words, race blind is not race neutral, and unawareness does not equal fairness. That sensitive data may be legitimately collected for these purposes under European data protection law11 is explicitly provided for in the proposed AI Act.12
It is therefore not surprising, that minority interest groups that represent the groups whose privacy is actually at stake, actively advocate for such collection of data and monitoring. Equally, EU and international institutions unequivocally consider collection of DEI data indispensable for monitoring and reporting purposes in order to fight discrimination. EU institutions further explicitly confirm that the GDPR should not be considered an obstacle preventing the collection of DEI data, but instead establishes conditions under which collecting and processing of such data are allowed.
From 2024 onwards, large companies in the EU will be subject to mandatory disclosure requirements for compliance with environmental, social, and governance (ESG) standards under the upcoming EU Corporate Sustainability Reporting Directive (CSRD). The CSRD requires companies to report on actual or potential adverse impacts on their workforce with regard to equal treatment and opportunities, which are difficult to measure without collecting and monitoring DEI data.
Currently, the regulation of collection and processing of DEI data is mainly left to the Member States. EU anti-discrimination and equality laws do not impose an obligation on organizations to collect DEI data for monitoring purposes, but neither do they prohibit collecting such data. In the absence of a specific requirement or prohibition, the processing of DEI data is regulated by the GDPR. The GDPR provides for ample discretionary powers for the Member States to provide for legal bases in their national laws to process DEI data for monitoring purposes. In practice, most Member States, however, have not used the opportunity under the GDPR to provide for a specific legal basis in their national laws for processing racial or ethnic data for monitoring purposes (with notable exceptions).13 As a consequence, collection and processing of DEI data for monitoring purposes is taking place on a voluntary basis, whereby employees are asked to fill out surveys based on self-identification. This is in line with the GDPR, which provides for a general exception allowing organizations to process DEI data based on the explicit consent of the individuals concerned, provided that the Member States have not excluded this option in their national laws. In practice, Member States have not used this discretionary power; they have not excluded the possibility of relying on explicit consent for the collection of DEI data. This leaves explicit consent as a valid, but also the only practically viable, option to collect DEI data for monitoring purposes.14 Both human rights frameworks and the GDPR itself facilitate such monitoring, provided there are safeguards to protect abuse of the relevant data in accordance with data minimization and privacy-by-design requirements.15 We now see best practices developing as to how to monitor DEI data while limiting the impact on the privacy of employees, and rightfully so. In literature, collecting racial or ethnic data for monitoring is rightfully described as “a problematic necessity, a process that itself needs constant monitoring.”16
2. Towards a positive duty to monitor for workplace discrimination
Where discrimination in the workplace is pervasive, monitoring of DEI data for quantifying discrimination in those workplaces is essential for employers to be able to comply with anti-discrimination and equality laws. As indicated above, there is no general requirement under the Racial Equality Directive to collect, analyze, and use DEI data. This Directive, however, does provide for a shift in the burden of proof.17 Where a complainant establishes facts from which a prima facie case of discrimination can be presumed, it will fall to the employer to prove that there has been no breach of the principle of equal treatment. Where workplace discrimination is pervasive, a prima facie case will be easy to make, and it will fall to the employer to disprove any such claim, which will be difficult without any data collection and monitoring. The argument that the GDPR does not allow for processing such data will not relieve the employer of its burden of proof. See, in a similar vein, European Committee of Social Rights, European Roma Rights Centre v. Greece18:
Data collection
27. The Committee notes that, in connection with its wish to assess the allegation of the discrimination against Roma made by the complainant organisation, the Government stated until recently that it was unable to provide any estimate whatsoever of the size of the groups concerned. To justify its position, it refers to legal and more specifically constitutional obstacles. The Committee considers that when the collection and storage of personal data [are] prevented for such reasons, but it is also generally acknowledged that a particular group is or could be discriminated against, the authorities have the responsibility for finding alternative means of assessing the extent of the problem and progress towards resolving it that are not subject to such constitutional restrictions.”
Since as early as 1989,19 all relevant EU and international institutions have, with increasing urgency, issued statements that the collection of DEI data for monitoring and reporting purposes is indispensable to the fight against discrimination.20 See, for example, the EU Anti-racism Action Plan 2020‒202521 (the “Action Plan”) in which the European Commission explicitly states:
Accurate and comparable data is essential in enabling policy-makers and the public to assess the scale and nature of discrimination suffered and for designing, adapting, monitoring and evaluating policies. This requires disaggregating data by ethnic or racial origin.22
In the Action Plan, the European Commission notes that equality data remains scarce, “with some member states collecting such data while others consciously avoid this approach.” The Action Plan subsequently provides significant steps to ensure collection of reliable and comparable equality data at the European and national level.23
On the international level, the United Nations (UN) takes an even stronger approach, considering collection of DEI data that allow for disaggregation for different population groups to be part of governments’ human rights obligations. See the UN 2018 report, “A Human Rights-based approach to data, leaving nobody behind in the 2030 agenda for sustainable development” (the “UN Report”):24
Data collection and disaggregation that allow for comparison of population groups are central to a HRBA [human rights-based approach] to data and form part of States’ human rights obligations.25 Disaggregated data can inform on the extent of possible inequality and discrimination.
The UN Report notes that this was implicit in earlier treaties, but that “more recently adopted treaties make specific reference to the need for data collection and disaggregated statistics. See, for example, Article 31 of the Convention on the Rights of Persons with Disabilities.”26
Many of the reports referred to above explicitly state that the GDPR should not be an obstacle for collecting this data. For example, in 2021 the EU High Level Group on Non-discrimination Equality and Diversity issued “Guidelines on improving the collection and use of equality data,”27 which explicitly state:
Sometimes data protection requirements are understood as prohibiting collection of personal data such as a person’s ethnic origin, religion or sexual orientation. However, as the explanation below shows the European General Data Protection Regulation (GDPR), which is directly applicable in all EU Member States since May 2018, establishes conditions under which collection and processing of such data [are] allowed.
The UN Special Rapporteur on Extreme Poverty and Human Rights even opined that the European Commission should start an infringement procedure where a Member State continues to misinterpret data protection laws as not permitting data collection on the basis of racial and ethnic origin.28
In light of the above, employers referring to GDPR requirements to avoid collecting DEI data for monitoring purposes are starting to appear to be driven more by a wish to avoid workplace scrutiny than by genuine concerns for the privacy of their employees.29 The employees whose privacy is at stake are exactly those who are potentially exposed to discrimination. At the risk of stating the obvious, invoking the GDPR as a prohibition on DEI data collection with the outcome that organizations avoid or are constrained from detecting discrimination of these groups, runs contrary to the GDPR’s entire purpose. The GDPR is about preserving the privacy of the employees while protecting them against discrimination.
Not surprisingly, the minority interest groups, who represent the groups whose privacy is actually at stake, actively advocate for such collection of data and monitoring.30 If anything, their concerns as to collection of DEI data for DEI monitoring purposes is that these groups often do not feel represented in the categorization of the data collected.31 If these are too generic or do not allow for splitting out of intersecting inequalities (like being female and from a minority), specific vulnerable groups may well fall outside the scope of DEI monitoring and therefore outside the scope of potential DEI policy measures. It is widely acknowledged that already the setting of the categories may represent bias, and the core principle of relevant human rights frameworks for collecting DEI data is to involve relevant minority stakeholders in a bottom-up process of indicator selection (the human rights principle of participation),32 and further ensure data collection is based on the principle of self-identification, which requires that surveys should always allow for free responses (including no responses) as well as indicating multiple identities (see section 4 on the human rights principle of self-identification).
3. ESG reporting
Under the upcoming CSRD,33 large companies34 will be subject to mandatory disclosure requirements on ESG matters from 2024 onwards (i.e., in their annual reports published in 2025).35 The European Commission is tasked with setting the reporting standards and has asked the European Financial Reporting Advisory Group (EFRAG) to provide recommendations for these standards. In November 2022, EFRAG published the first draft standards. The European Commission is now consulting relevant EU bodies and Member States, before adopting the standards as delegated acts in June 2023.
One of the draft reporting standards provides for a standard on reporting on a company’s own workforce (European Sustainability Reporting Standard S1 (ESRS S1)).36 This standard requires a general explanation of the company’s approach identifying and managing any material, actual, and potential impacts on its own workforce in relation to equal treatment and opportunities for all, including “gender equality and equal pay for work of equal value” and “diversity.” From the definitions in ESRS S1, it is clear that “equal treatment” requires that there shall be “no direct or indirect discrimination based on criteria such as gender and racial or ethnic origin; “equal opportunities” refers to equal and nondiscriminatory access to opportunities for education, training, employment, career development and the exercise of power without any individuals being disadvantaged on the basis of criteria such as gender and racial or ethnic origin.
ESRS S1 provides a specific chapter on metrics and targets, which requires mandatory public reporting metrics on a set of specific characteristics of a company’s workforce, which does include gender, but not racial or ethnic origin.37 Reading all standards, however, it is difficult to imagine how companies could report on the standards without collecting and monitoring DEI data internally.
For example, the general disclosure requirements of ESRS S1 require the company to disclose all of its policies relating to equal treatment and opportunity,38 including:
d) Whether and how these policies are implemented through specific procedures to ensure discrimination is prevented, mitigated, and acted upon once detected, as well as to advance diversity and inclusion in general.
It is difficult to see how companies can comply with reporting the information in clause (d) which requires reporting how the policies are implemented to ensure discrimination is prevented, mitigated, and acted upon once detected, without collecting DEI data.
ESRS S1 further clarifies how disclosures under S1 relate to disclosures under ESRS S2, which includes disclosures where potential impacts on a company’s own workforce have an impact on the company’s strategy and business model(s). See:
Based on the reporting requirements above, collecting and monitoring of DEI data will be required for mandatory disclosures, which also provides for a legal basis under the GDPR for collecting such data, provided the other provisions of GDPR are complied with as well as broader human rights principles. Before setting out the GDPR requirements, a brief summary is provided of the broader human rights principles that apply to data collection of DEI data for monitoring purposes.
4. Human rights principles
The three main human rights principles in relation to data collection processes are self-identification, participation, and data protection.39 The principle of self-identification requires that people should have the option of self-identifying when confronted with a question seeking sensitive personal information related to them. As early as 1990, the Committee on the Elimination of Racial Discrimination held that identification as a member of a particular ethnic group “shall, if no justification exists to the contrary, be based upon self-identification by the individual concerned.”40 A personal sense of identity and belonging cannot in principle be restricted or undermined by a government-imposed identity and should not be assigned through imputation or proxy. This entails that all questions on personal identity, whether in surveys or administrative data, should allow for free responses (including no response) as well as multiple identities.41 Also, owing to the sensitive nature of survey questions on population characteristics, special care is required by data collectors to demonstrate to respondents that appropriate data protection and disclosure control measures are in place.42
5. EU data protection law requirements
Collecting racial or ethnic data for monitoring is rightfully described in literature as “a problematic necessity, a process that itself needs constant monitoring.”43 The collection and use of racial and ethnic data to combat discrimination is not an “innocent” practice.44 Even if performed on an anonymized or aggregated basis, it can contribute to exclusion and discrimination. An example is when politicians argue, based on statistics, that there are “too many” people of a certain category in a country.45
Collection and processing of racial and ethnic data is not illegal in the EU. In general, no Member State imposes an absolute prohibition on collecting this data.46 There is also no general requirement under the Racial Equality Directive to collect, analyze, and use equality data. Obligations to collect racial or ethnic data also do not generally seem to be codified in law in the Member States, with notable exceptions in Finland, Ireland and (pre-Brexit) the UK.47
In the absence of specific prohibitions and specific requirements in EU and Member State law, processing of racial and ethnic data is governed by the GDPR, which provides a special regime for processing “special categories of data” such as data revealing racial or ethnic origin.48/49
Article 9 of the GDPR prohibits the processing of special categories of data, with notable exceptions. The prohibition does not apply (insofar as relevant here)50 when:
The individual has given explicit consent to the processing of personal data for one or more specified purposes, except where EU or Member State law provides that the prohibition may not be lifted by the individual (Article 9(2) sub. (a) GDPR).
The processing is necessary for reasons of substantial public interest on the basis of EU or Member State law (Article 9(2) sub. (g) GDPR).
The processing is necessary for statistical purposes in accordance with Article 89(1) GDPR based on EU or Member State law (Article 9(2) sub. (j) GDPR).
For the conditions to apply, provisions must be made in EU or Member State law which permit processing where necessary for substantial public interest or statistical purposes. In practice, most Member States have not used their discretionary power under the GDPR to provide a specific legal basis in their national law for processing racial or ethnic data for these purposes.51 Member States have, however, also not used the possibility under GDPR to provide in their national law that the prohibition under Article 9 may not be lifted by consent. This leaves explicit consent as a valid, but also the only practically viable, option to collect DEI data for monitoring purposes.52 This is in line with human rights principles, provided reporting is based on self-identification.
Once the CDRD has been implemented in the national laws of the Member States, collecting DEI data will be required for mandatory ESG disclosures, which will be permitted under Article 9(2) sub. (g) GDPR (reason of substantial public interest). Where organizations collect this data the human rights principles set out above should be observed, in particular that reporting should be based on self-identification. In practice, the legal basis of substantial public interest, will therefore very much mirror the legal basis of explicit consent and the safeguards and mitigating measures set out below will equally apply.
5.1 Explicit consent
The requirements for valid consent are strict, especially in the workplace.53 For instance, consent must be ‘freely given’, which is considered problematic in view of the imbalance of power between the employer and the individual.54 The term ‘explicit’ refers to the way consent is expressed by the individual. It means that the data subject must give an express statement of consent. An obvious way to make sure consent is explicit would be to expressly confirm consent in a written statement, an electronic form or in an email.55
For employee consent to be valid, employees need to have genuine free choice as whether to provide the information or not without any detrimental effects. This includes no downside whatsoever to an employee refusing to provide consent, which would be the case if refusal of consent would, for example, exclude the employee from any positive action initiatives.56 To ensure that consent is indeed freely given, the voluntary nature of the reporting for employees should be twofold: (1) the act of completing a survey or questionnaire related to one’s racial or ethnic background should be voluntary and (2) the survey or questionnaire should include options for the employee to respond with (an equivalent of) “I choose not to say.” The individual status of a survey or questionnaire (i.e., completed or not completed), as well as the provided answers, should not be visible to the employer on an individual basis. This is in practice realized by privacy-by-design measures (see further below).
Note that for consent to be valid, it needs to be accompanied with clear information as to why it is being collected and how it will be used (consent needs to be “specific and informed”).57 In addition, employees should be informed that consent can be withdrawn at any time and that any withdrawal of consent will not affect the lawfulness of processing prior to the withdrawal.58
When consent is withdrawn, any processing of personal data (to the extent it is identifiable) will need to stop from the moment that the consent is withdrawn. However, where data are collected and processed in the aggregate (see section 5.2 below on privacy-by-design requirements), employees will no longer be identifiable or traceable, and, therefore, any withdrawal of consent will not be effective in relation to data already collected and included in such reports.
5.2 General data protection principles
Obtaining consent does not negate or in any way diminish the data controller’s obligations to observe the principles of processing enshrined in the GDPR, especially Article 5 of the GDPR with regard to fairness, necessity, and proportionality, as well as data quality.59 Employers will further have to comply with principles of privacy-by-design.60 In practice, this means that employers should only process the personal data that they strictly need for their pursued purposes and in the most privacy-friendly manner. For example, employers can collect DEI data without reference to individual employees (i.e., without employees providing their name, or other unique identifier, such as a personnel number or email address). In this manner, employers will comply with data minimization and privacy-by-design requirements, limiting any impact on the privacy of their employees. In practice we see also that employers involve a third-party service provider, and request employees to send the information directly to the third-party provider. The third-party service provider subsequently only shares aggregate information with the employer.
From a technical perspective, it is possible to achieve a similar segregation of duties within the company’s internal HR system (like Workday or SuccessFactors), whereby data are collected on a de-identified basis and only one or two employees within the diversity function have access to de-identified DEI data for statistical analysis and subsequently report to management on an aggregate basis only (ensuring individual employees cannot be singled out or re-identified).61 This requires customization of HR systems, which is currently underway. Where employers have a works council, the works council will need to provide its prior approval for any company policy related to the processing of employee data. As part of the works council approval process, the privacy-by-design measures can be verified.
For the sake of completeness, note that where data collection and processing are on a truly anonymous basis, the provisions of the GDPR would not apply.62 The threshold under the GDPR for data to be truly anonymous is, however, very high and is unlikely to be met where employers collect such data from their employees. Any application of anonymization techniques, such as pseudonymization (e.g., removal or replacement of unique identifiers and names) therefore do not take the data processing outside the scope of the GDPR, but are rather necessary measures to meet data minimization and privacy-by-design requirements.
6. The way forward
It is no longer possible to hide behind the GDPR to avoid collecting DEI data for monitoring purposes. The direction of travel is towards meaningful DEI policies, monitoring, and reporting (such as under CSRD). Collecting data relating to racial and ethnic origin has been labeled “a problematic necessity, a process that itself needs constant monitoring.” This is the negative way of qualifying DEI data collection and monitoring. A positive human rights-based approach is that data-collection processes should be based on self-identification, participation, and data protection. Where all three principles are safeguarded, the process will be controlled and can be trusted without being inherently problematic or in need of constant monitoring.The path forward revolves around building trust with the workforce (and their works councils and trade unions). If trust is not already a given, the recommendation is to start small (in less sensitive jurisdictions), engage with works councils or the workforce at large, and in light of the upcoming CRSD, start now.63
Self-identification: A company requires the full trust of its employees to be able to collect representative DEI data from them based on self-identification. If introduction of DEI data collection is perceived by employees as abrupt and countercultural, or a box-ticking exercise unlikely to result in meaningful change, surveys will not be successful. For employees to fill out surveys disclosing sensitive data, trust is required that their employer is serious about its DEI efforts and that data collection and monitoring complements these efforts based on the aphorism “We measure what we treasure.” Practice shows that when a certain tipping point is reached, employees are proud to self-identify and contribute to the DEI statistics of their company.
Trust will be undermined if employees do not recognize themselves in any pre-defined categories. Proper self-identification entails that any pre-defined categories are relevant to a country’s workforce, allow for free responses (including no response) as well as allow for identifying with multiple identities. Trust of employees will be enhanced, if the company has put careful thought into the reporting metrics, ensuring that reporting can actually inform where the company can focus interventions to bring about meaningful change. For example, is important to ensure reporting metrics are not just outcome-based (tracking demographics, without knowing where a problem exists), but are also process-based. Process-based metrics can pinpoint problems in employee-management processes such as hiring, evaluation, promotion, and executive sponsorship. If outcome metrics inform a company that it has limited percentages of specific minorities, process metrics may show in which part of its processes (or part of a process, e.g., which part of the hiring process) a company needs to focus to bring about meaningful change. Examples of these metrics include the speed at which minorities move up the corporate ladder and salary differentials between different categories in comparable jobs.
Participation: Trust requires an inclusive bottom-up process whereby employees (and their works councils) have a say in the data collection and monitoring procedure. For example, in setting the categories in a survey to ensure minority employees can ‘recognize’ themselves in those categories, in setting the reporting metrics to ensure these may bring about meaningful change as well as in setting the data protection safeguards (see below).
Data protection:To gain employees’ trust, data protection principles, such as data security, data minimization and privacy-by-design, must be fully implemented. A company will need to submit a data collection and processing protocol to its works council and receive its approval, specifying all organizational, contractual and technical measures ensuring that data are collected on a de-identified basis, and access controls are in place to ensure access to the data is limited to one or two employees of the diversity team in order to generate statistics only.
Country Reports
Below we provide a summary of the legal basis available under the laws of France, Germany, Italy, Spain and The Netherlands, and available to collect racial and ethnic background data of their employees for purposes of monitoring their DEI policies (DEI Monitoring Purposes). Note that in all cases also the general data processing principles apply (such as privacy-by-design requirements) as set out in section 5.2, but are not repeated here.
Belgium
Olivia Vansteelant & Damien Stas de Richelle, Laurius
Summary requirements for processing racial and ethnic background data
Under Belgian law, there is neither a specific legal requirement for employers to collect data revealing racial or ethnic origin of their employees, nor is there a general prohibition for employers to collect such data.
Companies with their registered office or at least one operating office in the Brussels-Capital Region can lawfully process personal data on foreign nationality or origin for DEI Monitoring Purposes on the basis of necessity to exercise their labour law rights and obligations. All companies can lawfully process racial or ethnic background data for DEI Monitoring Purposes based on explicit consent of their employees. Employers with a works council should consult their works council before implementing any policy related to processing data revealing racial or ethnic origin of their employees, but no approval from the works council is required by law.
Necessity to exercise labour law rights and obligations (art. 9(2) b) GDPR). The basis for this exception can be found in the Decision of the Government of the Brussels-Capital Region of 7 May 2009 regarding diversity plans and the diversity label and the Ordonnance of the Government of the Brussels-Capital Region of 4 September 2008 on combatting discrimination and promoting equal treatment in the field of employment.
According to this Decision, companies with their registered office or at least one operating office in the Brussels-Capital Region are entitled to draft a diversity plan to address the issue of discrimination in recruitment and develop diversity at the workplace. No similar regulations currently exist in the Flemish or Walloon regions. Many Flemish NGOs are urging the Flemish Government to work towards a sustainable and inclusive labour market with monitoring and reporting as an important basis for evaluation of diversity. They are asking the Flemish Government to put its full weight behind this before the 2024 elections.
Under this Decision, employers are permitted to analyze the level of diversity amongst their personnel by classifying their workforce into categories, including that of foreign nationality or origin. To classify employees in this category and, hence, collect data on foreign nationality or origin. It is possible that employers may indirectly collect data revealing racial or ethnic origin due to a possible link with, or inference drawn from, information on nationality or origin. However, the Decision does not cover data revealing racial or ethnic origin and there would be no condition permitting such collection under Article 9(2)(b) GDPR.
Explicit consent. The Belgian Implementation Act does not expressly exclude the possibility of processing racial or ethnic data based on employees’ consent. For all other purposes of processing racial and ethnic background data, employers can therefore rely on explicit consent and voluntary reporting by employees. We refer to the conditions for explicit consent set out above in section 5.1, as they apply in the same manner to Belgium. To ensure that consent is indeed freely given, the voluntary nature of the reporting for employees should be twofold: (1) the act of completing a survey or questionnaire related to one’s racial or ethnic background should be voluntary and (2) the survey or questionnaire should include options for the employee to respond with (an equivalent of) “I choose not to say.”
France
Héléna Delabarre & Sylvain Naillat, Nomos, Société D’Avocats
Summary requirements for processing racial and ethnic background data
Under French law, the processing of race and ethnicity data is prohibited in principle under (i) a general provision of the French Constitution, and (ii) some specific provisions of French data protection laws, which is also the public position of the French Data Protection Authority’s (CNIL). French law does not recognize any categorization of people based on their (alleged) races or ethnicity and the prohibition of processing race and ethnicity data has been reaffirmed by the French Constitutional Court in a decision related to public studies whose purpose was to measure diversity/minority groups. However, while race and ethnicity data may not be collected or processed, objective criteria relating to geographical and/or cultural origins, such as name, nationality, birthplace, mother tongue, etc., can be considered by employers in order to measure diversity and to fight against discrimination.
In a public paper from 201264 (that has not been contradicted since) the CNIL confirmed that employers may collect and process data about objective criteria relating to “origin,” such as the birthplace of the respondent and his/her parents, his/her mother tongue, his/her nationality and that of his/her parents, etc., if such processing is necessary for the purpose of conducting statistical studies aiming at measuring and fighting discrimination. The CNIL also considers that questions about self-identification and how the respondent feels perceived by others can be asked if necessary, in view of the purpose of the data collection and any other questions asked. See the CNIL’s paper:
In accordance with the decision of the Constitutional Court of 15 November 2007 and the insights of the Cahiers du Conseil, studies on the measurement of diversity cannot, without violating Article 1 of the Constitution, be based on the ethnic or racial origins of the persons. Any nomenclature that could be interpreted as ethno-racial reference must therefore be avoided. It is nevertheless possible to approach the criterion of “origin” on the basis of objective data such as the place of birth and the nationality at birth of the respondent and his or her parents, but also, if necessary, on the basis of subjective data relating to how the respondent self-identifies or how the person feels perceived by others.65
Based on the guidance from the CNIL, several public studies have been conducted relying on the collection of information considered permissible by the CNIL, i.e., (i) whether or not respondents felt discriminated against based on their origins or skin colour; (ii) how the respondent self-identifies; and (iii) statistics about the geographical and/or cultural origins of the respondents.66 The provision of any information should be entirely voluntary and the rules regarding explicit consent in section 5.1 above apply in the same manner to France. Any questions relating to the collection of data regarding geographical and/or cultural origins should be objective, and in the absence of the need to identify (directly or indirectly) the individuals, then the collection process should be entirely anonymous.
Germany
Hanno Timner, Morrison & Foerster
Legal basis for processing racial and ethnic background data
Under German law, there is neither a specific legal requirement for employers to collect racial and ethnic background data of their employees, nor is there a general prohibition for employers to collect such data.
Employers in Germany can lawfully process racial and ethnic background data for DEI Monitoring Purposes on the basis of (i) necessity to exercise their labour law rights and obligations or (ii) based on explicit consent of their employees. If the employer has a works council, the works council has a co-determination right for the implementation of diversity surveys and questionnaires in accordance with Section 94 of the Works Council Act (Betriebsverfassungsgesetz – “BetrVG”) if the information is not collected anonymously and on a voluntary basis. If the information is collected electronically, the works council may have a co-determination right in accordance with Section 87(1), no. 6 BetrVG.
Necessity to exercise labour law rights or obligations. According to Section 26(3) of the German Federal Data Protection Act (Bundesdatenschutzgesetz – “BDSG”), the processing of racial and ethnic background data in the employment context is only permitted if the processing is necessary for the employer to exercise rights or comply with legal obligations derived from labour law, social security, and social protection law, and there is no reason to believe that the data subject has an overriding legitimate interest in not processing the data. One of the rights of the employer derives from Section 5 of the German General Equal Treatment Act (Allgemeines Gleichbehandlungsgesetz – “AGG”), according to which employers have the right to adopt positive measures to prevent and stop discrimination on the grounds of race or ethnicity. As a precondition to the adoption of such measures, employers may collect data to identify their DEI needs.
Explicit consent. For all other purposes of processing racial and ethnic background data, employers will have to rely on explicit consent and voluntary reporting by employees. We refer to the conditions for explicit consent set out above in section 5.1, as they apply in the same manner to Germany. Further, Section 26(2) BDSG specifies that the employee’s level of dependence in the employment relationship and the circumstances under which consent was given have to be taken into account when assessing whether an employee’s consent was freely given. According to Section 26(2) BDSG, consent may be freely given, in particular, if it is associated with a legal or economic advantage for the employee, or if the employer and the employee are pursuing the same interests. This can be the case if the collection of data also benefits employees, e.g., if it leads to the establishment of comprehensive DEI management within the employer’s company.
Ireland
Colin Rooney & Alison Peate, Arthur Cox
Summary requirements for processing racial and ethnic background data
Under Irish law, there is neither a specific legal requirement for employers to collect racial and ethnic background data of their employees, nor is there a general prohibition for employers to collect such data.
Explicit consent: Employers in Ireland can lawfully process race and ethnicity data for their own specified purpose based on the explicit consent of employees. It should be noted that the Irish Data Protection Commission has said that in the context of the employment relationship, where there is a clear imbalance of power between the employer and employee, it is unlikely that consent will be given freely. While this does not mean that employers can never rely on consent in relation to the processing of employee data, it does mean that the burden is on employers to prove that consent is truly voluntary, as explained in section 5.1 above. In the context of collecting data relating to an employee’s racial or ethnic background, employers should ensure that employees are given the option to select “prefer not to say”.
Statistical purposes: If the employer intends to process race and ethnicity data solely for statistical purposes, it could rely on Article 9(2)(j) of the GDPR and section 54(c) of the Irish Data Protection Act 2018 (the “2018 Act”), provided that the criteria set out in section 42 of the 2018 Act are met. This allows for race and ethnicity data to be processed where it is necessary and proportionate for statistical purposes and where the employer has complied with section 42 of the 2018 Act. Section 42 requires that: (i) suitable and specific measures are implemented to safeguard the fundamental rights and freedoms of the data subjects in accordance with Article 89 GDPR; (ii) the principle of data minimisation is respected; and (iii) the information is processed in a manner which does not permit identification of the data subjects, where the statistical purposes can be fulfilled in this manner.
Italy
Marco Tesoro, Tesoro and Partners
Summary requirements for processing racial and ethnic background data
The Italian Data Protection Code (IDPC) regulates the processing of personal data under Article 9 of the GDPR, stating that the legal basis for the processing of such data must be to comply with a law or regulation (art. 2-ter(1), IDPC), or for reasons of relevant public interest. Under Italian law, no specific legal basis has been implemented to process racial or ethnic data for reasons of public interest.
Explicit consent. We refer to the conditions for explicit consent set out above in section 5.1, as they apply in the same manner to Italy. The IDPC does not expressly exclude the possibility of processing racial and ethnicity data based on employees’ consent. Employers wanting to collect and process racial and ethnicity data on the basis of employees’ consent under Art. 9 of the GDPR, however, should ensure that the consent is granted on a free basis and, where possible, involve the trade unions they are associated with (as well as their Works Council, where relevant). The trade unions should be able to i) ascertain and certify that the employees’ consent has been freely given; and ii) ensure that employees are fully aware of their rights and of the consequences of providing such data. In the absence of associated trade unions, employers may inform the local representative of the union associations who signed the collective bargaining agreement (CBA) that applies (if any). Furthermore, employers should ensure that employees are given the option to “prefer not to say.”
Statute of Workers. It is also worth noting that under Italian law, there is a general prohibition on the collection of information not strictly related or needed to assess the employee’s professional capability. Per Article 8, Law 23 May 1970, no. 300 “Statute of Workers,” race and ethnicity data should not be collected or used by employers to impact in any way the decision to hire a candidate or to manage any of the terms of the employment relationship.
Spain
Laura Castillo, Gómez-Acebo & Pombo
Summary requirements for processing racial and ethnic background data
Under the Organic Law 3/2018 of 5th December on the Protection of Personal Data and Guarantee of Digital Rights (SDPL), there is a general prohibition on collecting racial and ethnic background information unless: (i) there is a legal requirement to do so (per Article 9 of the SDPL); or (ii) the employees have provided their explicit consent (although the latter is not without risk).
Fulfilment of a legal requirement. The Comprehensive Law 15/2022 of 12th July, for Equal Treatment and Non-Discrimination (the “Equal Treatment Law”) guarantees and promotes the right to equal treatment and non-discrimination. This Law expressly states that no limitations, segregations, or exclusions may be made based on ethnicity or racial backgrounds, i.e., nobody can be discriminated against on grounds of race or ethnicity. In this context, any positive discrimination measures that have been implemented as a result of the Equal Treatment Law have been included in collective bargaining agreements (CBA) or collective agreements as agreed with the unions or the relevant employee representatives. Where there is a requirement in the CBA to collect race and ethnicity data from employees, employers can do so, as this would constitute a legal requirement. In circumstances where the CBA does not specifically require the collection of this type of information, employers can either seek to include such a provision in the terms of the CBA or a collective agreement and work with the unions or legal representatives to do so, or take an alternative approach and rely on explicit consent, as set out immediately below.
Explicit consent. In principle, an employee’s consent on its own is not sufficient to lift the general prohibition on the processing of sensitive data under the SDPL. However, one of the main aims of the prohibition pursuant to the SDPL is to avoid discrimination. Therefore, if the purpose of collection is to promote diversity, it is arguable (although this has not yet been tested in Spain) that employers can rely on explicit consent, and we refer to the conditions for explicit consent set out above in section 5.1, as they apply in the same manner to Spain. In addition to the conditions in section 5.1, Spanish case law has determined that the employee’s level of dependence within the employment relationship and the circumstances under which consent is given should be considered when assessing whether an employee’s consent is freely given. It is therefore not recommended that employers obtain or process race and ethnicity data of its employees during the recruitment or hiring process, or before the end of the probationary period, unless a CBA regulates this issue in a different manner. Employers should also ensure that employees are given the option to “prefer not to say” and ensure that they are able to prove that consent is genuinely voluntary, as explained in section 5.1 above.
The Netherlands
Marta Hovanesian, Morrison & Foerster
Summary requirements for processing racial and ethnic background data
Under Dutch law, there is neither a specific legal requirement for employers to collect racial and ethnic background data of their employees, nor is there a general prohibition for employers to collect such data.
Employers in the Netherlands can lawfully process racial and ethnic background data of their employees for DEI Monitoring Purposes on the basis of (i) the substantial public interest on the basis of Dutch law or (ii) the explicit consent of the employees. Employers with a works council need to ensure their works council approves any policy related to processing Equality Data.
Substantial public interest. The Netherlands has implemented the conditions of Article 9(2) GDPR for the processing of racial and ethnic background data in the Dutch GDPR Implementation Act (the “Dutch Implementation Act”). More specifically, Article 25 of the Dutch Implementation Act provides that racial and ethnicity background data (limited to country of birth and parents’ or grandparents’ countries of birth) may be processed (on the basis of substantial public interest) if processing is necessary for the purpose of restoring a disadvantaged position of a minority group, and only if the individual has not objected to the processing. Reliance on this condition requires the employer to, among other things, (i) demonstrate that certain groups of people have a disadvantaged position; (ii) implement a wider company policy aimed at restoring this disadvantage; and (iii) demonstrate that the processing of race and ethnicity data is necessary for the implementation and execution of said policy.
Explicit consent. Employers can collect racial and ethnicity background data of their employees for DEI Monitoring Purposes based on explicit consent and voluntary reporting by employees. The conditions for consent set out above in section 5.1 apply in the same manner to the Netherlands.
Cultural Diversity Barometer. Note that Dutch employers with more than 250 employees have the option to request DEI information from Statistics Netherlands about their own company. Statistics Netherlands, upon the Ministry of Social Affairs and Employment’s request, created the “Cultural Diversity Barometer”. The Barometer allows employers to disclose certain non-sensitive personal data to Statistics Netherlands, which, in turn, will report back to the relevant employers with a statistical and anonymous overview of the company’s cultural diversity (e.g., percentage of employees with a (i) Dutch background, (ii) western migration background, and (iii) non-western migration background). Statistics Netherlands can either provide information about the cultural diversity within the entire organization or within specific departments of the organization (provided that the individual departments have more than 250 employees).
United Kingdom
Annabel Gillham, Morrison & Foerster (UK) LLP
Summary requirements for processing racial and ethnic background data
Under UK law, there is no general prohibition on the collection of employees’ racial or ethnic background data by employers, provided that specific conditions pursuant Article 9 of the retained version of the GDPR (UK GDPR) are met. It is fair to say that the collection of such data is increasingly common in the UK workplace, with several organizations electing to publish their ethnicity pay gap.[1] In some cases, collection of racial or ethnic background data is a legal requirement. For example, with respect to accounting periods beginning on or after April 1, 2022 certain large listed companies are required to include in their published annual reports a “comply or explain” statement on the achievement of targets for ethnic minority representation on their board [2] and a numerical disclosure on the ethnic background of the board.[3]
Employers in the UK can lawfully process racial and ethnic background data of their employees for DEI Monitoring Purposes where the processing is (i) necessary for reasons of substantial public interest on the basis of UK law [4]; or (ii) carried out with the explicit consent of the employees [5]. Employers should ensure that they check and comply with the provisions of any agreement or arrangement with a works council, trade union or other employee representative body (e.g., relating to approval or consultation rights) when collecting and using such data.
Substantial public interest. Article 9 of the retained version of the UK GDPR prohibits the processing of special categories of data, with notable exceptions similar to those set out in section 5 above. Schedule 1 to the UK Data Protection Act 2018 (DP Act 2018) sets out specific conditions for meeting the “substantial public interest” ground under Article 9(2)(g) of the UK GDPR. Two conditions are noteworthy in the context of the collection of racial and ethnic background data.
The first is an “equality of opportunity or treatment” condition. This is available where processing of personal data revealing racial or ethnic origin is necessary for the purposes of identifying or keeping under review the existence or absence of equality of opportunity or treatment between groups of people of different racial or ethnic origins with a view to enabling such equality to be promoted or maintained.[6] There are exceptions – the data must not be used for measures or decisions with respect to a particular individual, nor where there is a likelihood of substantial damage or substantial distress to an individual. Individuals have a specific right to object to the collection of their information.
The second condition covers “racial and ethnic diversity at senior levels of organisations”.[7] Organisations may collect personal data revealing racial or ethnic origin where as part of a process of identifying suitable individuals to hold senior positions (e.g., director, partner or senior manager), is necessary for the purposes of promoting or maintaining diversity in the racial and ethnic origins of individuals holding such positions andcan reasonably be collected without the consent of the individual. When relying on this condition, organisations should factor in any risk that collecting such data may cause substantial damage or substantial distress to the individual.
In order to rely on either condition set out above, organisations must prepare an “appropriate policy document” outlining the principles set out in the Article 9 UK GDPR conditions and the measures taken to comply with those principles, along with applicable retention and deletion policies.
Explicit consent [8]The conditions for consent set out in section 5.1 above apply in the same manner to the UK. Consent must be a freely given, specific, informed and unambiguous indication of an employee’s wishes. Therefore, any request for employees to provide racial or ethnic background data should be accompanied with clear information as to why it is being collected and how it will be used for DEI Monitoring Purposes.
[1] Ethnicity pay gap reporting – Women and Equalities Committee (parliament.uk)
[2] At least one board member must be from a minority ethnic background (as defined in the Financial Conduct Authority, Listing Rules and Disclosure Guidance and Transparency Rules (Diversity and Inclusion) Instrument 2022, https://www.handbook.fca.org.uk/instrument/2022/FCA_2022_6.pdf.
[6] Paragraph 8, Part 2 of Schedule 1 to the DP Act 2018.
[7] Paragraph 9, Part 2 of Schedule 1 to the DP Act 2018.
[8] Article 9(2)(a) UK GDPR.
* Ms. Moerel thanks Annabel Gillham, a partner at Morrison & Foerster in London, for her valuable input on a previous version of this article.
1 For recent statistics, see “A Union of equality: EU anti-racism action plan 2020-2025,” https://ec.europa.eu/info/sites/default/files/a_union_of_equality_eu_action_plan_against_racism_2020_-2025_en.pdf, p. 2, referring to wide range of surveys conducted by the EU Agency for Fundamental Rights (FRA) pointing to high levels of discrimination in the EU, with the highest level in the labor market (29%), both in respect of looking for work but also at work.
2 See, specifically, Council Directive 2000/43/EC of June 29, 2000, implementing the principle of equal treatment between persons irrespective of racial or ethnic origin (“Racial Equality Directive”), Official Journal L 180, 19/07/2000 P. 0022–0026. Action to combat discrimination and other types of intolerance at the European level rests on an established EU legal framework, based on a number of provisions of the European Treaties (Articles 2 and 9 of the Treaty on European Union (TEU), Articles 19 and 67(3) of the Treaty on the Functioning of the European Union (TFEU), and the general principles of non-discrimination and equality, also reaffirmed in the EU Charter of Fundamental Rights (in particular, Articles 20 and 21).
4 For a list of examples why diversity policies may fail: https://hbr.org/2016/07/why-diversity-programs-fail. See also Data-Driven Diversity (hbr.org): “According to Harvard Kennedy School’s Iris Bohnet, U.S. companies spend roughly $8 billion a year on DEI training—but accomplish remarkably little. This isn’t a new phenomenon: An influential study conducted back in 2006 by Alexandra Kalev, Frank Dobbin, and Erin Kelly found that many diversity-education programs led to little or no increase in the representation of women and minorities in management.”
5 Research shows that lack of social networks and mentoring and sponsoring is a limiting factor for the promotion of women, but this is even stronger for cultural diversity, due to the lack of a “social bridging network,” a network that allows for connections with other social groups, see Putnam, R.D. (2007) “E Pluribus Unum: Diversity and Community in the Twenty-first Century,” Scandinavian Political Studies, 30 (2), pp. 137‒174. While white men tend to find mentors on their own, women and minorities more often need help from formal programs. Introduction of formal mentoring shows real results: https://hbr.org/2016/07/why-diversity-programs-fail.
6 Quote is fromhttps://hbr.org/2022/03/data-driven-diversity.
7 Historically, there have been cases of misuse of data collected by National Statistical Offices (and others), with extremely detrimental human rights impacts, see Luebke, D. & Milton, S. 1994, “Locating the Victim: An Overview of Census-Taking, Tabulation Technology, and Persecution in Nazi Germany.” IEEE Annals of the History of Computing, Vol. 16 (3). See also W. Seltzer and M. Anderson, “The dark side of numbers: the role of population data systems in human rights abuses,” Social Research, Vol. 68, No. 2 (summer 2001), the authors report that during the Second World War, several European countries, including France, Germany, the Netherlands, Norway, Poland, and Romania, abused population registration systems to aid Nazi persecution of Jews, Gypsies, and other population groups. The Jewish population suffered a death rate of 73 percent in the Netherlands. In the United States, misuse of population data on Native Americans and Japanese Americans in the Second World War is well documented. In the Soviet Union, micro data (including specific names and addresses) were used to target minority populations for forced migration and other human rights abuses. In Rwanda, categories of Hutu and Tutsi tribes introduced in the registration system by the Belgian colonial administration in the 1930s were used to plan and assist in mass killings in 1994.
8 The quote is from the Commission for Racial Equality (2000), Why Keep Ethnic Records? Questions and answers for employers and employees (London, Commission for Racial Equality).
9 In the U.S., for example, “crime prediction tools” proved to discriminate against ethnic minorities. The police stopped and searched more ethnic minorities, and as a result this group also showed more convictions. If you use this data to train an algorithm, the algorithm will allocate a higher risk score to this group. Discrimination by algorithms is therefore a reflection of discrimination already taking place “on the ground”. https://www.cnsnews.com/news/article/barbara-hollingsworth/coalition-predictive-policing-supercharges-discrimination.
11 See also the guidance of the UK Information Commissioner (ICO) on AI and data protection, Guidance on AI and data protection | ICO. In earlier publications, I have argued that the specific regime for processing sensitive data under the GDPR is no longer meaningful. Increasingly, it is becoming more and more unclear whether specific data elements are sensitive. Rather, the focus should be on whether the use of such data is sensitive. Processing of racial and ethnic data to eliminate discrimination in the workplace is an example of non-sensitive use, provided that strict technical and organizational measures are implemented to ensure that the data are not used for other purposes. See https://iapp.org/news/a/gdpr-conundrums-processing-special-categories-of-data/ and https://iapp.org/news/a/11-drafting-flaws-for-the-ec-to-address-in-its-upcoming-gdpr-review/.
12 Article 10(2) sub. 5 of the draft AI Act allows for the collection of special categories of data for purposes of bias monitoring, provided that appropriate safeguards are in place, such as pseudonymization.
13 A notable exception is the UK, which long before its exit from the EU, legislated for the collection of racial and ethnic data to meet the requirements of the substantial public interest condition for purposes of both “Equality of opportunity or treatment” and “Racial and ethnic diversity at senior levels” and further provided for criteria for processing ethnic data for statistical purposes, see Schedule 1 to the UK Data Protection Act 2018 (inherited from its predecessor, the Data Protection Act 1998), and the Information Commissioner’s Office Guidance on special category data, 2018. Schedule 1 also provides for specific criteria to meet the requirements of the statistical purposes condition. See here. Another exception is the Netherlands, which allows for limited processing of racial and ethnic data (limited to country of birth and parents’ or grandparents’ countries of birth) for reason of substantial public interest.
18 Complaint No. 15/2003, decision on the merits, Dec. 8, 2004, § 27.
19 See, e.g., ECRI General Policy Recommendation No. 4 on national surveys on the experience and perception of discrimination and racism from the point of view of potential victims, adopted on Mar. 6, 1998.
20 See the Report prepared for the European Commission, “Analysis and comparative review of equality data collection practices in the European Union Data collection in the field of ethnicity,” 2017, data_collection_in_the_field_of_ethnicity.pdf (europa.eu), https://op.europa.eu/en/publication-detail/-/publication/cd5d60a3-094d-11e7-8a35-01aa75ed71a1#:~:text=The%20European%20Handbook%20on%20Equality,to%20achieve%20progress%20towards%20equality. For example, the European Handbook on Equality Data initially dating from 2007, already stated that “Monitoring is perhaps the most effective measure an organisation can take to ensure it is in compliance with the equality laws.” The handbook was updated in 2016 and provides a comprehensive overview of how equality data can be collected, https://op.europa.eu/en/publication-detail/-/publication/cd5d60a3-094d-11e7-8a35-01aa75ed71a1/language-en.
23 EU Anti-racism Action Plan 2020-2025, p. 21, under reference to: Niall Crowley, Making Europe more Equal: A Legal Duty? https://www.archive.equineteurope.org/IMG/pdf/positiveequality_duties-finalweb.pdf, which reports on the Member States that already provide for such positive statutory duty. See p. 16 for an overview of explicit preventive duties requiring organizations to take unspecified measures to prevent discrimination, shifting responsibility to act from those experiencing discrimination to employers. They can stimulate the introduction of new organizational policies, procedures and practices on such issues.
25 For instance, target 17.18 in the 2030 Agenda requests that Social Development Goals indicators are disaggregated by income, gender, age, race, ethnicity, migratory status, disability, geographic location, and other characteristics relevant in national contexts.
30 See policy statement on the website of the European Network Against Racism (ENAR); as well as the statement dated 28 September 2022 issued by Equal@Work Partners calling on the EU to implement conducive legal frameworks that will bring operational and legal certainty to organizations willing to implement equality data collection measures on the grounds of race, ethnicity and other related categories., https://www.enar-eu.org/about/equality-data. See also here.
31 For an excellent article on all issues related to ethnic categorization, see Bonnett, A., & Carrington, B. (2000), “Fitting into categories or falling between them? Rethinking ethnic classification,” British Journal of Sociology of Education, 21(4), pp. 487‒500.
33 See Corporate Sustainability Reporting Directive (Nov. 10, 2022), at point (4) of Article 1, available here.
34 The new EU sustainability reporting requirements will apply to all large companies that fulfill two of the following three criteria: more than 250 employees, €40 million net revenue, and more than €20 million on the balance sheet), whether listed or not. Lighter reporting standards will apply to small and medium enterprises listed on public markets.
35 See Article 1 (Amendments to Directive 2013/34/EU) sub. (8), which introduces new Chapter 6a Sustainability Reporting Standards, pursuant to which the European Commission will adopt a delegated act, specifying the information that undertakings are to disclose about social and human factors, which include equal treatment and opportunity for all, including diversity provisions.
36 See European Financial Reporting Advisory Group, Draft European Sustainability Reporting Standard S1 Own Workforce, Nov. 2022, here
37 The initial working draft of ESRS S1 published by EFRAG for public consultation did include a public reporting requirement also of the total number of ‘employees belonging to vulnerable groups, where relevant and legally permissible to report’ (see disclosure requirement 11), Download (efrag.org). This requirement was deleted from the draft standards presented by EFRAG to the European Commission.
45 See older examples in Bonnett and Carrington 2000.
46 European Commission, Analysis and comparative review of equality data collection practices in the European Union Data collection in the field of ethnicity, p. 14, https://commission.europa.eu/system/files/2021-09/data_collection_in_the_field_of_ethnicity.pdf. Even in France, often seen as a case of absolute prohibition, ethnic data collection is possible under certain exceptions. The same applies to Italy. Italian Workers’ Statute (Italian Law No. 300/1970), Article 8, expressly forbids employers from collecting and using ethnic data to decide whether to hire a candidate and to decide any other aspect of the employment relationship already in place (like promotions). Collecting such data for monitoring workplace discrimination and equal opportunity falls outside the prohibition (provided it is ensured such data cannot be used for other purposes).
48 Data revealing racial or ethnic origin qualifies as a “special category” of personal data under Article 9 of the GDPR. Data on nationality or place of birth of a person or their parents do not qualify as special categories of data and can as a rule be collected without consent of the surveyed respondent. However, if they are used to predict ethnic or racial origin, they become subject to the regime of Article 9 GDPR for processing special categories of data.
50 Note that Article 9(2)(b) of the GDPR provides a condition for collecting racial and ethnic data where it “is necessary for the purposes of carrying out the obligations and exercising specific rights of the controller or of the data subject in the field of employment … in so far as it is authorised by Union or Member State law….” There is currently no Union or Member State law that provides for an employer obligation to collect racial or ethnic data for monitoring purposes. However, EU legislators considered this to be a valid exception for Member States to implement in their national laws. Art. 88 of the GDPR states that Member States may, by law or collective agreements, provide for more specific rules to ensure the protection of the rights and freedoms of employees with respect to the processing of employees’ personal data in the employment context. In particular, these rules may be provided for the purposes of, inter alia, equality and diversity in the workplace.
53 Article 4(11) of the GDPR defines consent as “any freely given, specific, informed, and unambiguous indication of the data subject’s wishes by which he or she, by a statement or by a clear affirmative action, signifies agreement to the processing of personal data relating to him or her.”
54 Guidance of the European Data Protection Board has made it explicit in a series of guidance documents that, for the majority of data processing at work, consent is not a suitable legal basis due to the nature of the relationship between employer and employee. See also Opinion 2/2017 on data processing at work (WP249), paragraph 3.3.1.6.2, at https://edpb.europa.eu/sites/default/files/files/file1/edpb_guidelines_202005_consent_en.pdf.
61 See Article 29 Working Party Opinion 05/2014 on Anonymization Techniques, adopted on 10 April 2014.
62 Recital 26 of the GDPR states the principles of data protection should not apply to anonymous information which does not relate to an identified or identifiable natural person, or which relates to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable. Recital 26 further states that the GDPR does not concern the processing of such anonymous information, including for statistical or research purposes.
63 For an informative article on the practicalities of implementing data-driven diversity proposals, see Data-Driven Diversity (hbr.org). The distinction between outcome-based and process-based metrics is based on this article.
FPF at IAPP’s Europe Data Protection Congress 2022: Global State of Play, Automated Decision-Making, and US Privacy Developments
Authored by Christina Michelakaki, FPF Intern for Global Policy
On November 16 and 17, 2022, the IAPP hosted the Europe Data Protection Congress 2022 – Europe’s largest annual gathering of data protection experts. During the Congress, members of the Future of Privacy Forum (FPF) team moderated and spoke at three different panels. Additionally, on November 14, FPF hosted the first Women@Privacy awards ceremony at its Brussels office, and on November 15, FPF co-hosted the sixth edition of its annual Brussels Privacy Symposium with the Vrije Universiteit Brussels (VUB)’s Brussels Privacy Hub on the issue of “Vulnerable People, Marginalization, and Data Protection” (event report forthcoming in 2023).
In the first panel for IAPP’s Europe Data Protection Congress, Global Privacy State of Play, Gabriela Zanfir-Fortuna (VP for Global Privacy, Future of Privacy Forum) moderated a conversation on key global trends in data protection and privacy regulation in jurisdictions from Latin America, Asia, and Africa. Linda Bonyo (CEO, Lawyers Hub Africa), Annabel Lee (Director, Digital Policy (APJ) and ASEAN Affairs, Amazon Web Services), and Rafael Zanatta (Director, Data Privacy Brasil Research Association) participated.
Finally, in the third panel, Perspectives on the Latest US Privacy Developments, Keir Lamont(Senior Counsel, Future of Privacy Forum) participated in a conversation focused on data protection developments at the federal and state level in the United States. Cobun Zweifel-Keegan(Managing Director, D.C., IAPP) moderated it, and Maneesha Mithal (Partner, Privacy and Cybersecurity, Wilson Sonsini Goodrich & Rosati) and Dominique Shelton Leipzig,(Partner, Cybersecurity & Data Privacy; Leader, Global Data Innovation & AdTech, Mayer Brown) also participated.
Below is a summary of the discussions in each of the three panels:
1. Global trends and legislative initiatives around the world
In the first panel, Global Privacy State of Play, Gabriela Zanfir-Fortuna stressed that although EU and US developments in privacy and data protection are in the spotlight, the explosion of regulatory action in other regions of the world is very interesting and deserves more attention.
Linda Bonyo touched upon the current movement in Africa where countries are adopting their own data protection laws, primarily inspired by the European model of data protection regulation, since they trust that the GDPR is a global standard and lack the resources to draft policies from scratch. Bonyo also added that the lack of resources and limited expertise are the main reasons why African countries struggle to establish independent Data Protection Authorities (DPAs). She then stressed that the Covid-19 pandemic revived discussions about a continental legal framework to address data flows. Regarding enforcement, she noted that for Africa, the approach looks rather “preventative” than “punitive.” Bonyo also underlined that it is common for big tech companies to operate outside of the continent and only have a small subsidiary in the African region, rendering local and regional regulatory action less impactful than in other regions.
Annabel Lee offered her view on the very dynamic Asia-Pacific region, noting that the latest trends, especially post-GDPR, include not only the introduction of new GDPR-like laws but also the revision of existing ones. Lee noted, however, that the GDPR is a very complex piece of legislation to “copy,” especially if a country is building its first data protection regime. She then focused on specific jurisdictions, noting that South Korea has overhauled its originally fragmented framework with a more comprehensive one and that Australia will implement a broad extraterritorial element in its revised law. Then Lee stated that when it comes to implementation and interpretation, data protection regimes in the region differ significantly, and countries try to promote harmonization by mutual recognition. With regards to enforcement, she stressed that it is common to see occasional audits and that in certain countries, such as Japan, there is a very strong culture of compliance. She also added that education can play a key role in working towards harmonized rules and enforcement. Lee offered Singapore as an example, where the Personal Data Protection Commission gives companies explanations not only on why they are in breach but also on why they are not in breach.
Rafael Zanatta explained that after years of strenuous discussions, there is an approved data protection legislation in Brazil (LGPD) that has already been in place for a couple of years. The new DPA created by the LGPD will likely ramp up its enforcement duties next year and has, so far, focused on building experimental techniques (to help incentivize associations and private actors to cooperate) and publishing guidelines, namely non-binding rules that will provide future interpretation for cases. Zanatta stressed that Brazil has been experiencing the formalization of autonomous data protection rights with supreme court rulings stating that data protection is a fundamental right different from privacy. He underscored that it will be interesting to see how the private sector applies data protection rights given their horizontal effect and the development of concepts like positive obligations and the collective dimension of rights. He explained that the extraterritorial applicability of Brazil’s law is very similar to the GDPR since companies do not need to operate in Brazil for the law to apply. He also touched upon the influence of Mercosur, a South American trade bloc, in discussions around data protection and the collective rights of the indigenous people of Bolivia in light of the processing of their biometric data. With regards to enforcement, he explained that in Brazil, it is happening primarily through the courts due to Brazil’s unique system where federal prosecutors and public defenders can file class actions.
2. Looking beyond case law on automated decision-making
In the second panel, Automated Decision-making and Profiling: Lessons from Court and DPA Decisions, Sebastião Barros Vale offered an overview of FPF’s ADM Report, noting that it contains analyses of more than 70 DPA decisions and court rulings concerning the application of Article 22 and other related GDPR provisions. He also briefly summarized the Report’s main conclusions. One of the main points he highlighted is that the GDPR covers automated decision-making (ADM) comprehensively beyond Article 22, including through the application of overarching principles like fairness and transparency, rules on lawful grounds for processing, and carrying out Data Protection Impact Assessments (DPIA).
Ruth Boardman underlined that the FPF Report reveals the areas of the law that are still “foggy” regarding ADM. Boardman also offered her view on the Portuguese DPA decision concerning a university using proctoring software to monitor students’ behavior during exams and detect fraudulent acts. The Portuguese DPA ruled that the Article 22 prohibition applied, given that the human involvement of professors in the decisions to investigate instances of fraud and invalidate exams was not meaningful. Boardman further explained that this case, along with the Italian DPA’s Foodhino case, shows that the human in the loop must have meaningful involvement in the process of making a decision for Article 22 GDPR to be inapplicable. She added that internal guidelines and training provided by the controller may not be definitive factors but can serve as strong indicators of meaningful human involvement. Regarding the concept of “legal or similarly significant effects” — another condition for the application of Article 22 GDPR – Boardman noted the link between such effects and contract law. For example, in the case of national laws transposing the e-Commerce Directive in which adding a product to a virtual basket counts as an offer to the merchant and not as a binding contract, no legal effects are triggered. She also added that meaningful information about the logic behind ADM should include the consequences that data subjects can suffer and referred to an enforcement notice from the UK’s Information Commissioner Office concerning the creation of profiles for direct marketing purposes.
Simon Hania argued that the FPF Report showed the robustness of the EDPB guidelines on ADM and that ADM triggers GDPR provisions that are relevant to fairness and transparency. With regards to the “human in the loop” concept, Hania claimed that it is important to involve multiple humans and ensure that they are properly trained to avoid biased decisions. Then he elaborated on a case concerning Uber’s algorithms that match drivers with clients, where Uber drivers requested access to data to assess whether the matching process was fair. For the Amsterdam District Court, the drivers did not demonstrate how the matching process could have legal or similarly significant effects on them, which meant that drivers did not have enhanced access rights that would only apply if ADM covered by Article 22 GDPR was at stake. However, when ruling on an algorithm used by another ride-hailing company (Ola) to calculate fare deductions based on drivers’ performance, the same Court found that the ADM at issue had significant effects on drivers. For Hania, a closer inspection of the two cases reveals that both ADM schemes affect drivers’ ability to earn or lose remuneration, which highlights the importance of financial impacts when assessing the effects of ADM as per Article 22. He also touched on a decision from the Austrian DPA concerning a company that scored individuals on the likelihood they would belong to certain demographic groups, as the DPA mandated the company to inform individuals about how it calculated their individual scores. For Hania, the case shows that controllers need to explain the reasons behind their automated decisions – regardless of whether they are covered by Article 22 GDPR or not – to comply with the fairness and transparency principles of Article 5 GDPR.
Gintare Pazereckaite noted that the FPF Report is particularly helpful in understanding inconsistencies in how DPAs apply Article 22 GDPR. She then stressed that the interpretation of “solely automated processing” should be done in light of protecting and safeguarding data subjects’ fundamental rights. Pazereckaite also referred to the criteria set out by the EDPB guidelines that clarify the concept of the “legal and similarly significant effects.” She added that data protection rules such as accountability and data protection by design play an important role in allowing data subjects to understand how ADM works and what consequences it may bring up. Lastly, Pazereckaite commented on Article 5 of the proposed AI Act – which contains a list of prohibited AI practices – and its importance when an algorithm does not trigger Article 22 GDPR.
3. ADPPA and regional laws re-shaping US data protection regime
In the last panel, Perspectives on the Latest US Privacy Developments, Keir Lamont offered an overview of recent US Congressional efforts to enact the American Data Privacy and Protection Act (ADPPA) and outstanding areas of disagreement. For him, the bill would introduce stronger rights and protections than those set forth in existing state-level laws; including a broad scope; strong data minimization provisions; limitations on advertising practices; enhanced privacy-by-design requirements; algorithmic impact assessments; and a private right of action. In contrast, existing state laws typically adhere to the outdated opt-in/opt-out paradigm for establishing individual privacy rights.
Maneesha Mithal explained that in the absence of comprehensive federal privacy legislation, the Federal Trade Commission (FTC) has largely taken on the role of DPA by virtue of having jurisdiction over a broad range of sectors in the economy and acting both as an enforcement and rulemaking agency. Mithal explained that the FTC enforces four existing privacy laws in the US and can also take action against both unfair and deceptive trade practices. For example, the FTC can enforce against any statement (irrespective of whether it is in a privacy policy or the context of user interfaces), material omissions (for example, the FTC has concluded that a company did not inform its clients that it was collecting second by second television data and was further sharing it), and unfair practices in the data security area. Mithal pointed out that since the FTC does not have the authority to seek civil penalties for first-time violations, it is trying to introduce additional deterrents by naming individuals (for example, in the case of an alcohol provider, the FTC named the CEO for failing to prioritize security) and is using its power to obtain injunctive relief. For example, in a case where a company was unlawfully using facial recognition systems, the FTC ordered the company to delete any models or algorithms that were used, and thus FTC applied the fruit to the poisonous tree theory. Mithal also noted that although the FTC has historically not been active as a rulemaking authority due to procedural issues along with the lack of resources and time considerations, it is initiating a major rulemaking involving “Commercial Surveillance and Lax Data Security Practices.”
Finally, Dominique Shelton Leipzig offered remarks on state-level legislation focusing on the California Consumer Privacy Act (CCPA) as amended by the California Privacy Rights Act (CPRA), adding that Colorado, Connecticut, Utah, and Virginia have similar laws. She elaborated on the CPRA’s contractual language, comparing California’s categorization of “Businesses,” “Contractors,” “Third Parties,” and “Service Providers” to the GDPR’s distinction between controllers and processors. Shelton Leipzig also explained that the CPRA introduced a highly disruptive model for the ad tech industry since consumers can opt out of both the sale of data, as well as the sharing of data. The CPRA also created a new independent rulemaking and enforcement Agency, the first in the US, focusing only on data protection and privacy. Finally, she addressed the recently enacted California Age-Appropriate Design Code Act, which focuses on the design of internet tools, and stressed that companies are struggling to implement it.
FPF Report: Automated Decision-Making Under the GDPR – A Comprehensive Case-Law Analysis
On May 17, the Future of Privacy Forum launched a comprehensive Report analyzing case-law under the General Data Protection Regulation (GDPR) applied to real-life cases involving Automated Decision Making (ADM). The Report is informed by extensive research covering more than 70 Court judgments, decisions from Data Protection Authorities (DPAs), specific Guidance and other policy documents issued by regulators.
The GDPR has a particular provision applicable to decisions based solely on automated processing of personal data, including profiling, which produces legal effects concerning an individual or similarly affects that individual: Article 22. This provision enshrines one of the “rights of the data subject”, particularly the right not to be subject to decisions of that nature (i.e., ‘qualifying ADM’), which has been interpreted by DPAs as a prohibition rather than a prerogative that individuals can exercise.
However, the GDPR’s protections for individuals against forms of automated decision-making (ADM) and profiling go significantly beyond Article 22. In this respect, there are several safeguards that apply to such data processing activities, notably the ones stemming from the general data processing principles in Article 5, the legal grounds for processing in Article 6, the rules on processing special categories of data (such as biometric data) under Article 9, specific transparency and access requirements regarding ADM under Articles 13 to 15, and the duty to carry out data protection impact assessments in certain cases under Article 35.
This new FPF Report outlines how national courts and DPAs in the European Union (EU)/European Economic Area (EEA) and the UK have interpreted and applied the relevant EU data protection law provisions on ADM so far – before and after the GDPR became applicable -, as well as the notable trends and outliers in this respect. To compile the Report, we have looked into publicly available judicial and administrative decisions and regulatory guidelines across EU/EEA jurisdictions and the UK. It draws from more than 70 cases – 19 court rulings and more than 50 enforcement decisions, individual opinions, or general guidance issued by DPAs, – from a span of 18 EEA Member-States, the UK, and the European Data Protection Supervisor (EDPS). To complement the facts of the cases discussed, we have also looked into press releases, DPAs’ annual reports, and media stories.
Some examples of ADM and profiling activities assessed by EU courts and DPAs and analyzed in the Report include:
School access and attendance control through Facial Recognition technologies
Online proctoring in universities and automated grading of students
Automated screening of job applications
Algorithmic management of platform workers
Distribution of social benefits and tax fraud detection
Automated credit scoring
Content moderation decisions in social networks
FPF Training: Automated Decision-Making under the GDPR
Ready to get an in-depth understanding of the GDPR’s Automated Decision-Making requirements? Register for our upcoming virtual training session on November 9, where FPF experts will cover the critical elements of Article 22, recent DPA decisions, consent requirements, and more.
Our analysis shows that the GDPR as a whole is relevant for ADM cases and has been effectively applied to protect the rights of individuals in such cases, even in situations where the ADM at issue did not meet the high threshold established by Article 22 GDPR. Among those, we found detailed transparency obligations about the parameters that led to an individual automated decision, a broad reading of the fairness principle to avoid situations of discrimination, and strict conditions for valid consent in cases of profiling and ADM.
Moreover, we found that when enforcers are assessing the threshold of applicability for Article 22 (“solely” automated, and “legal or similarly significant effects”), the criteria they use are increasingly sophisticated. This means that:
Courts and DPAs are looking at the entire organizational environment where ADM is taking place, from the controller’s organizational structure, to reporting lines and the effective training of staff, in order to decide whether a decision was “solely” automated or had meaningful human involvement; and
Similarly, when assessing the second criterion for the applicability of Article 22, enforcers are looking at whether the input data for an automated decision includes inferences about the behavior of individuals, and whether the decision affects the conduct and choices of the persons targeted, among other multi-layered criteria.
A recent preliminary ruling request sent by an Austrian court in February 2022 to the Court of Justice of the European Union (CJEU) may soon help clarify these concepts, as well as other related to the information which controllers need to give data subjects about ADM’s underlying logic, significance and envisaged consequences for the individual.
The findings of this Report may also serve to inform the discussions about pending legislative initiatives in the EU that regulate technologies or business practices that foster, rely on,or relate to ADM and profiling, such as the AI Act, the Consumer Credits Directive, and the Platform Workers Directive.
On May 20, the authors of the report discussed with prominent European data protection experts some of the most impactful analyzed decisions during an FPF roundtable. These include cases related to the algorithmic management of platform workers in Italy and the Netherlands, the use of automated recruitment and social assistance tools, and creditworthiness assessment algorithms. The discussion also covered pending questions sent by national courts to the CJEU on matters of algorithmic transparency under the GDPR. View a recording of the conversation here, and download the slides here.
What the Biden Executive Order on Digital Assets Means for Privacy
Author: Dale Rappaneau
Dale Rappaneau is a policy intern at the Future of Privacy Forum and a 3L at the University of Maine School of Law.
On March 9, the Biden Administration issued an Executive Order on “Ensuring Responsible Developments of Digital Assets” (“the Order”), published together with an explanatory Fact Sheet. The Order states that the growing adoption of digital assets throughout the economy and inconsistent controls to mitigate their risks necessitates a new governmental approach to regulating digital assets.
The Order outlines a whole-of-government approach to address a wide range of technological frameworks, including blockchain protocols and centralized systems. The Order frames this approach as an important step toward safeguarding consumers and businesses from illicit activities and potential privacy harms involving digital assets. In particular, it calls for a list of federal agencies and regulators to assess digital assets, consider future action, and ultimately provide reports recommending how to achieve the Order’s numerous policy goals. The Order recognizes the importance of incorporating data and privacy protections into this approach, which indicates that the Administration is actively considering the privacy risks associated with digital assets.
1. Covered Technologies
Definitions
Digital Assets – The Order defines digital assets broadly, including cryptocurrencies, stablecoins, and all central bank digital currencies (CBDCs), regardless of the technology used. The term also refers to any other representations of value or financial instrument issued or represented in a digital form through the use of distributed ledger technology relying on cryptography, such as a blockchain protocol.
CBDC – The Order defines a Central Bank Digital Currency (“CBDC”) as digital money that is a direct liability of the central bank, not of a commercial bank. This definition aligns with the recent Federal Reserve Board CBDC report. A U.S. CBDC could support a faster and more modernized financial system, but it would also raise important policy questions including how it would affect the current rules and regulations of the U.S. financial sector.
Cryptocurrencies – These are digital assets that may operate as a medium of exchange and are recorded through distributed ledger technologies that rely on cryptography. This definition is notable because blockchain is often mistaken as the only form of distributed ledger technology, leading some to believe that all cryptocurrencies require a blockchain. However, the Order defines cryptocurrencies by reference to distributed ledger technology – not blockchain – and seems to cover both mainstream cryptocurrencies utilizing a blockchain (e.g., bitcoin or Ether) and alternative cryptocurrencies built on distributed ledger technology without a blockchain (e.g., IOTA).
Stablecoins – The Order recognizes stablecoins as a category of cryptocurrencies featuring mechanisms aimed at maintaining a stable value. As reported by relevant agencies, stablecoin arrangements may utilize distributed or centralized ledger technology.
Implications of Covered Technologies
From a technical perspective, distributed ledger technologies such as blockchain stand in stark contrast to centralized systems. Blockchain protocols, for example, allow users to conduct financial transactions on a peer-to-peer level, without requiring oversight from the private sector or government. Centralized ledger technology, as used by most credit cards and banks, typically requires a private sector or government actor to facilitate financial transactions. In this environment, the data flows through the actor, who carries obligations to monitor and protect the data.
Despite the technical differences between these approaches, the Order appears to group these very different financial transaction systems into the single umbrella term of digital assets. It does this by including within the scope of the definition of digital assets all CBDCs, even ones utilizing centralized ledger technology, and other assets using distributed ledger technology. This homogenization of technological concepts may indicate that the Administration is seeking a uniform regulatory approach to these technologies.
2. Privacy Considerations of the EO
Section 2 of the Order states the principal policy objectives with respect to digital assets, which include: exploring a U.S. CBDC; ensuring responsible development and use of digital assets and their underlying ledger technologies; and mitigating finance and national security risks posed by the illicit use of digital assets.
Notably, the Administration uses the word “privacy” five times in this section, declaring that digital assets should maintain privacy, shield against arbitrary or unlawful surveillance, and incorporate privacy protections into their architecture. The need to ensure that digital assets preserve privacy raises notable, albeit different, implications for both centralized and decentralized technologies.
Privacy Implications of a United States CBDC
The Order places the highest urgency on developing and deploying a U.S. CBDC, which must be designed to include privacy protections. The Order states that a United States CBDC would be the liability of the Federal Reserve, which is currently experimenting with a number of CBDC system designs, including centralized and decentralized ledger technologies, as well as alternative technologies. Although the Federal Reserve has not chosen a particular system, the monetary authority has listed numerous privacy-related characteristics that should be incorporated into a United States CBDC regardless of the technology used.
First, the Federal Reserve recognizes that a CBDC would generate data about users’ financial transactions in the same ways that commercial banks and nonbanks do today. This may include a user’s name, email address, physical address, know-your-customer (KYC) data, and more. Depending on the design chosen for the CBDC, this data may be centralized under the control of a single entity or distributed across ledgers held by multiple entities or users.
Second, because of the robust rules designed to combat money laundering and financing of terrorism, a CBDC would need to allow intermediaries to verify the identity of the person accessing CBDC, just as banks and financial institutions currently do so. For this reason, the Federal Reserve states that a CBDC would need to safeguard an individual’s privacy while deterring criminal activity.
This intersection between consumer privacy and the transparency needed to monitor criminal activity gets to the heart of the Order. On one hand, a United States CBDC would provide certain data security and privacy protections for consumers under the current rules and regulations imposed on financial institutions. The Gramm-Leach-Bliley Act (GLBA), for example, includes privacy and data security provisions that regulate the collection, use, protection, and disclosure of nonpublic personal information by financial institutions (15 U.S.C.A. §§ 6801 to 6809). But on the other hand, the CBDC would likely require the Federal Reserve, or entrusted intermediaries, to monitor and verify the identity of users to reduce the likelihood of illicit transactions.
It is unclear whether current rules and regulations would apply if the CBDC utilizes distributed ledger technology, given that they typically establish scope via definitions of applicable entities using particular data. Because users (and not financial institutions) hold copies of the data ledger under distributed ledger technology systems, pre-existing privacy laws may fail to cover large amounts of data processing and provide adequate safeguards to consumers. In addition, as the next section suggests, it is unclear how monitoring and verification would occur under a CBDC that uses distributed ledger technology. This raises further questions in how policymakers can navigate the intersection of privacy and transaction monitoring.
Privacy Implications of Distributed Ledger Technologies
Distributed ledger technologies often attempt to create an environment where users do not have to reveal their personal information. Transactions under these systems typically do not filter through a singular entity such as the Federal Reserve, but instead happen on a peer-to-peer level, with users directly exchanging digital assets without third-party oversight. In this environment, users can complete transactions utilizing hashed identifiers rather than their own information, and these transactions usually occur without the supervision of a private or government entity. Together, the use of hashed identifiers and lack of supervision creates a digital environment ripe with identity-shielding protections.
However, experts recognize that distributed ledger technologies also create a multitude of financial risks. If users can conduct transactions on a peer-to-peer level without supervision or revealing their identity, they can more easily conduct illicit activities, including money laundering, terror funding, and human and drug trafficking.
The Order acknowledges these benefits and risks. The Fact Sheet prioritizes privacy protections and efforts to combat criminal activities, which indicates that the Order seeks to emphasize the privacy-preserving aspects of new distributed ledger technologies while finding ways to restrict illicit financial activity. Such an emphasis may represent an enhanced governmental effort to address criminal activities in the digital asset landscape while avoiding measures that would create risks to privacy and data protection.
3. Future Action: Privacy and Law Enforcement Equities
The Order’s repeated emphasis on privacy seems to align with the Biden Administration’s current focus on prioritizing privacy and data protection rulemaking. The Order acknowledges both necessary safeguards to combat illicit activities and the need to embed privacy protections in the regulation of digital assets.
The U.S. Department of the Treasury and the Federal Reserve have articulated concerns regarding how bad actors exploit distributed ledger technologies for illicit purposes, and those agencies will likely make recommendations to strengthen government oversight and supervision capabilities. However, the Order’s emphasis on privacy seems to indicate that the Administration wants to ensure privacy protections while also enabling traceability to monitor users, verify identities, and investigate illicit activities.
The question is, will the Administration find a way to preserve the privacy protections of centralized and distributed ledger technology, while also promoting the efficacy of monitoring illicit activities? That answer will likely come once agencies and regulators start providing reports that recommend steps to achieve the Order’s goals. Until then, the answer remains unknown, and entities utilizing cryptocurrencies or other digital assets should stay aware of a possible shift in how the Federal Government regulates the digital asset landscape.
Reading the Signs: the Political Agreement on the New Transatlantic Data Privacy Framework
The President of the United States, Joe Biden, and the President of the European Commission, Ursula von der Leyen, announced last Friday, in Brussels, a political agreement on a new Transatlantic framework to replace the Privacy Shield.
This is a significant escalation of the topic within Transatlantic affairs, compared to the 2016 announcement of a new deal to replace the Safe Harbor framework. Back then, it was Commission Vice-President Andrus Ansip and Commissioner Vera Jourova who announced at the beginning of February 2016 that a deal had been reached.
The draft adequacy decision was only published a month after the announcement, and the adequacy decision was adopted 6 months later, in July 2016. Therefore, it should not be at all surprising if another 6 months (or more!) pass before the adequacy decision for the new Framework will produce legal effects and actually be able to support transfers from the EU to the US. Especially since the US side still has to pass at least one Executive Order to provide for the agreed-upon new safeguards.
This means that transfers of personal data from the EU to the US may still be blocked in the following months – possibly without a lawful alternative to continue them – as a consequence of Data Protection Authorities (DPAs) enforcing Chapter V of the General Data Protection Regulation in the light of the Schrems II judgment of the Court of Justice of the EU, either as part of the 101 noyb complaints submitted in August 2020 and slowly starting to be solved, or as part of other individual complaints/court cases.
If you are curious about what the legal process will look like both on the US and EU sides after the agreement “in principle”, check out this blog post by Laila Abdelaziz of the “Privacy across borders project” at American University.
After the agreement “in principle” was announced at the highest possible political level, EU Justice Commissioner Didier Reynders doubled down on the point that this agreement is reached “on the principles” for a new framework, rather than on the details of it. Later on he also gave credit to Commerce Secretary Gina Raimondo and US Attorney General Merrick Garland for their hands-on involvement in working towards this agreement.
In fact, “in principle” became the leitmotif of the announcement, as the first EU Data Protection Authority to react to the announcement was the European Data Protection Supervisor, who wrote that he “Welcomes, in principle”, the announcement of a new EU-US transfers deal – “The details of the new agreement remain to be seen. However, EDPS stresses that a new framework for transatlantic data flows must be sustainable in light of requirements identified by the Court of Justice of the EU”.
Of note, there is no catchy name for the new transfers agreement, which was referred to as the “Trans-Atlantic Data Privacy Framework”. Nonetheless, FPF’s CEO Jules Polonetsky submits the “TA DA!” Agreement, and he has my vote. For his full statement on the political agreement being reached, see our release here.
Some details of the “principles” agreed on were published hours after the announcement, both by the White House and by the European Commission. Below are a couple of things that caught my attention from the two brief Factsheets.
The US has committed to “implement new safeguards” to ensure that SIGINT activities are “necessary and proportionate” (an EU law legal measure – see Article 52 of the EU Charter on how the exercise of fundamental rights can be limited) in the pursuit of defined national security objectives. Therefore, the new agreement is expected to address the lack of safeguards for government access to personal data as specifically outlined by the CJEU in the Schrems II judgment.
The US also committed to creating a “new mechanism for the EU individuals to seek redress if they believe they are unlawfully targeted by signals intelligence activities”. This new mechanism was characterized by the White House as having “independent and binding authority”. Per the White House, this redress mechanism includes “a new multi-layer redress mechanism that includes an independent Data Protection Review Court that would consist of individuals chosen from outside the US Government who would have full authority to adjudicate claims and direct remedial measures as needed”. The EU Commission mentioned in its own Factsheet that this would be a “two-tier redress system”.
Importantly, the White House mentioned in the Factsheet that oversight of intelligence activities will also be boosted – “intelligence agencies will adopt procedures to ensure effective oversight of new privacy and civil liberties standards”. Oversight and redress are different issues and are both equally important – for details, see this piece by Christopher Docksey. However, they tend to be thought of as being one and the same. Being addressed separately in this announcement is significant.
One of the remarkable things about the White House announcement is that it includes several EU law-specific concepts: “necessary and proportionate”, “privacy, data protection” mentioned separately, “legal basis” for data flows. In another nod to the European approach to data protection, the entire issue of ensuring safeguards for data flows is framed as more than a trade or commerce issue – with references to a “shared commitment to privacy, data protection, the rule of law, and our collective security as well as our mutual recognition of the importance of trans-Atlantic data flows to our respective citizens, economies, and societies”.
Last, but not least, Europeans have always framed their concerns related to surveillance and data protection as being fundamental rights concerns. The US also gives a nod to this approach, by referring a couple of times to “privacy and civil liberties” safeguards (adding thus the “civil liberties” dimension) that will be “strengthened”. All of these are positive signs for a “rapprochement” of the two legal systems and are certainly an improvement to the “commerce” focused approach of the past on the US side.
Lastly, it should also be noted that the new framework will continue to be a self-certification scheme managed by the US Department of Commerce.
What does all of this mean in practice? As the White House details, this means that the Biden Administration will have to adopt (at least) an Executive Order (EO) that includes all these commitments and on the basis of which the European Commission will draft an adequacy decision.
Thus, there are great expectations in sight following the White House and European Commission Factsheets, and the entire privacy and data protection community is waiting to see further details.
In the meantime, I’ll leave you with an observation made by my colleague, Amie Stepanovich, VP for US Policy at FPF, who highlighted that Section 702 of the FISA Act is set to expire on December 31, 2023. This presents Congress with an opportunity to act, building on such an extensive amount of work done by the US Government in the context of the Transatlantic Data Transfers debate.
Understanding why the first pieces fell in the transatlantic transfers domino
The Austrian DPA and the EDPS decided EU websites placing US cookies breach international data transfer rules
Two decisions issued by Data Protection Authorities (DPAs) in Europe and published in the second week of January 2022 found that two websites, one run by a contractor of the European Parliament (EP), and the other one by an Austrian company, have unlawfully transferred personal data to the US merely by placing cookies (Google Analytics and Stripe) provided by two US-based companies on the devices of their visitors. Both decisions looked into the transfers safeguards put in place by the controllers (the legal entities responsible for the websites), and found them to be either insufficient – in the case against the EP, or ineffective – in the Austrian case.
Both decisions affirm that all transfers of personal data from the EU to the US need “supplemental measures” on top of their Article 46 GDPR safeguards, in the absence of an adequacy decision and under the current US legal framework for government access to personal data for national security purposes, as assessed by the Court of Justice of the EU in its 2020 Schrems II judgment. Moreover, the Austrian case indicates that in order to be effective, the supplemental measures adduced to safeguard transfers to the US must “eliminate the possibility of surveillance and access [to the personal data] by US intelligence agencies”, seemingly putting to rest the idea of the “risk based approach” in international data transfers post-Schrems II.
This piece analyzes the two cases comparatively, considering they have many similarities other than their timing: they both target widely used cookies (Google Analytics, in addition to Stripe in the EP case), they both stem from complaints where individuals are represented by the Austrian NGO noyb, and it is possible that they will be followed by similar decisions from the other DPAs that received a batch of 101 complaints in August 2020 from the same NGO, relying on identical legal arguments and very similar facts. This piece analyzes the most important findings made by the two regulators, showing how their analyses were in sync and how these analyses likely preface similar decisions for the rest of the complaints.
1.“Personal data” is being “processed” through cookies, even if users are not identified and even if the cookies are thought to be “inactive”
In the first decision, the European Data Protection Supervisor (EDPS) investigated a complaint made by several Members of the European Parliament against a website made available by the EP to its Members and staff in the context of managing COVID-19 testing. The complainants raised concerns with regard to transfers of their personal data to the US through cookies provided by US based companies (Google and Stripe) and placed on their devices when accessing the COVID-19 testing website. The case was brought under the Data Protection Regulation for EU Institutions (EUDPR), which has identical definitions and overwhelmingly similar rules to the GDPR.
One of the key issues that was analyzed in order for the case to be considered falling under the scope of the EUDPR was whether personal data was being processed through the website by merely placing cookies on the devices of those who accessed it. Relying on its 2016 Guidelines on the protection of personal data processed through Web Services, the EDPS noted in the decision that “tracking cookies, such as the Stripe and Google Analytics cookies, are considered personal data, even if the traditional identity parameters of the tracked users are unknown or have been deleted by the tracker after collection”. It also noted that “all records containing identifiers that can be used to single out users, are considered as personal data under the Regulation and must be treated and protected as such”.
The EP argued in one of its submissions to the regulator that the Stripe cookie “had never been active, since registration for testing for EU Staff and Members did not require any form of payment”. However, the EP also confirmed that the dedicated COVID-19 testing website, which was built by its contractor, copied code from another website run by the same contractor, and “the parts copied included the code for a cookie from Stripe that was used for online payment for users” of the other website. In its decision, the EDPS highlighted that “upon installation on the device, a cookie cannot be considered ‘inactive’. Every time a user visited [the website], personal data was transferred to Stripe through the Stripe cookie, which contained an identifier. (…) Whether Stripe further processed the data transferred through the cookie is not relevant”.
With regard to the Google Analytics cookies, the EDPS only notes that the EP (as controller) acknowledged that the cookies “are designed to process ‘online identifiers, including cookie identifiers, internet protocol addresses and device identifiers’ as well as ‘client identifiers’”. The regulator concluded that personal data were therefore transferred “through the above-mentioned trackers”.
In the second decision, which concerned the use of Google Analytics by a website owned by an Austrian company and targeting Austrian users, the DPA argued in more detail what led it to find that personal data was being processed by the website through Google Analytics cookies, under the GDPR.
1.1 Cookie identification numbers, by themselves, are personal data
The DPA found that the cookies contained identification numbers, including a UNIX timestamp at the end, which shows when a cookie was set. It also noted that the cookies were placed either on the device or the browser of the complainant. The DPA affirmed that relying on these identification numbers makes it possible for both the website and Google Analytics “to distinguish website visitors … and also to obtain information as to whether the visitor is new or returning”.
In its legal analysis, the DPA noted that “an interference with the fundamental right to data protection … already exists if certain entities take measures – in this case, the assignment of such identification numbers – to individualize website visitors”. Analyzing the “identifiability” component of the definition of “personal data” in the GDPR, and relying on its Recital 26, as well as on Article 29 Working Party Opinion 4/2007 on the concept of “personal data”, the DPA clarified that “a standard of identifiability to the effect that it must also be immediately possible to associate such identification numbers with a specific natural person – in particular with the name of the complainant – is not required” for data thus processed to be considered “personal data”.
The DPA also recalled that “a digital footprint, which allows devices and subsequently the specific user to be clearly individualized, constitutes personal data”. The DPA concluded that the identification numbers contained in the cookies placed on the complainant’s device or browser are personal data, highlighting their “uniqueness”, their ability to single out specific individuals and rebutting specifically the argument the respondents made that no means are in fact used to link these numbers to the identity of the complainant.
1.2 Cookie identification numbers combined with other elements are additional personal data
However, the DPA did not stop here and continued at length in the following sections of the decision to underline why placing the cookies at issue when accessing the website constitutes processing of personal data. It noted that the classification as personal data “becomes even more apparent if one takes into account that the identification numbers can be combined with other elements”, like the address and HTML title of the website and the subpages visited by the complainant; information about the browser, operating system, screen resolution, language selection and the date and time of the website visit; the IP address of the device used by the complainant. The DPA considers that “the complainant’s digital footprint is made even more unique following such a combination [of data points]”.
The “anonymization function of the IP address” – which is a function that Google Analytics provides to users if they wish to activate it – was expressly set aside by the DPA, considering that during fact finding it was shown the function was not correctly implemented by the website at the time of the complaint. However, later in the decision, with regard to the same function and the fact that it was not implemented by the website, the regulator noted that “the IP address is in any case only one of many pieces of the puzzle of the complainant’s digital footprint”, hinting therefore that even if the function would have been correctly implemented, it wouldn’t have necessarily led to the conclusion that the data being processed was not personal.
1.3 Controllers and other persons “with lawful means and justifiable effort” will count for the identifiability test
Drilling down even more on the notion of “identifiability” in a dedicated section of the decision, the DPA highlights that in order for the data processed through the cookies at issue to be personal, “it is not necessary that the respondents can establish a personal reference on their own, i.e. that all information required for identification is with them. […] Rather, it is sufficient that anyone, with lawful means and justifiable effort, can establish this personal reference”. Therefore, the DPA took the position that “not only the means of the controller [the website in this case] are to be taken into account in the question of identifiability, but also those of ‘another person’”.
After recalling that the CJEU repeatedly found that “the scope of application of the GDPR is to be understood very broadly” (e.g. C-439/19B, C-434/16Nowak, C-553/07Rijkeboer), the DPA nonetheless stated that in its opinion, the term “anyone” it referred to above, and thus the scope of the definition of personal data, “should not be interpreted so broadly that any unknown actor could theoretically have special knowledge to establish a reference; this would lead to almost any information falling within the scope of application of the GDPR and a demarcation from non-personal data would become difficult or even impossible”.
This being said, the DPA considers that the “decisive factor is whether identifiability can be established with a justifiable and reasonable effort”. In the case at hand, the DPA considers that there are “certain actors who possess special knowledge that makes it possible to establish a reference to the complainant and identify him”. These actors are, from the DPA’s point of view, certainly the provider of the Google Analytics service and, possibly the US authorities in the national security area. As for the provider of Google Analytics, the DPA highlights that, first of all, the complainant was logged in with his Google account at the time of visiting the website.
The DPA indicates this is a relevant fact only “if one takes the view that the online identifiers cited above must be assignable to a certain ‘face’”. The DPA finds that such an assignment to a specific individual is in any case possible in the case at hand. As such, the DPA states that: “[…] if the identifiability of a website visitor depends only on whether certain declarations of intent are made in the account (user’s Google account – our note), then, from a technical point of view, all possibilities of identifiability are present”, since, as noted by the DPA, otherwise Google “could not comply with a user’s wishes expressed in the account settings for ‘personalization’ of the advertising information received”. It is not immediately clear how the ad preferences expressed by a user in their personal account are linked to the processing of data for Google Analytics (and thus website traffic measurement) purposes, and it seems that this was used in the argumentation to substantiate the claim that the second respondent generally has additional knowledge across its various services that could lead to the identification or the singling out of the website visitor.
However, following the arguments of the DPA, on top of the autonomous finding that cookie identification numbers are personal data, it seems that even if the complainant wouldn’t have been logged into his account, the data processed through the Google Analytics cookies would have still been considered personal. In this context, the DPA “expressly” notes that “the wording of Article 4(1) of the GDPR is unambiguous and is linked to the ability to identify and not to whether identification is ultimately carried out”.
Moreover, “irrespective of the second respondent” – so even if Google admittedly did not have any possibility or ability to render the complainant identifiable or to single him out, other third parties in this case were considered to have the potential ability to identify the complainant: US authorities.
1.4 Additional information potentially available to US intelligence authorities, taken into account for the identifiability test
Lastly, according to the decision, the US authorities in the national security area “must be taken into account” when assessing the potential of identifiability of the data processed through cookies in this case. The DPA considers that “intelligence services in the US take certain online identifiers, such as the IP address or unique identification numbers, as a starting point for monitoring individuals. In particular, it cannot be ruled out that intelligence services have already collected information with the help of which the data transmitted here can be traced back to the person of the complainant.”
To show that this is not merely a “theoretical danger”, the DPA relies on the findings of the CJEU in Schrems II with regard to the US legal framework and the “access possibilities” it offers to authorities, and on Google’s Transparency Report, “which proves that data requests are made to [it] by US authorities.” The regulator further decided that even if it is admittedly not possible for the website to check whether such access requests are made in individual cases and with regard to the visitors of the website, “this circumstance cannot be held against affected persons, such as the complainant. Thus, it was ultimately the first respondent as the website operator who, despite publication of the Schrems II judgment, continued to use the Google Analytics tool”.
Therefore, based on the findings of the Austrian DPA in this case, at least two of the “any persons” mentioned in Recital 26 GDPR that will be considered when deciding who can have lawful means to identify data so that the data is deemed personal are the processor of a specific processing operation, as well as the national security authorities that may have access to that data, at least in cases where this access is relevant (like in international data transfers). This latter finding of the DPA raises questions whether national security agencies in general in a specific jurisdiction may be considered by DPAs as an actor who has “lawful means” and additional knowledge when deciding if a data set links to an “identifiable” person, also in cases where international data transfers are not at issue.
The DPA concluded that the data processed by the Google Analytics cookies is personal data and falls under the scope of the GDPR. Importantly, the cookie identification numbers were found to be personal data by themselves. Additionally, the other data elements potentially collected through cookies together with the identification numbers are also personal data.
2.Data transfers to the US are taking place by placing cookies provided by US-based companies on EU-based websites
Once the supervisory authorities established that the data processed through Google Analytics and, respectively, Stripe cookies, were personal data and were covered by the GDPR or EUDPR respectively, they had to ascertain whether an international transfer of personal data from the EU to the US was taking place in order to see whether the provisions relevant to international data transfers were applicable.
The EDPS was again concise. It stated that because the personal data were processed by two entities located in the US (Stripe and Google LLC) on the EP website, “personal data processed through them were transferred to the US”. The regulator strengthened its finding by stating that this conclusion “is reinforced by the circumstances highlighted by the complainants, according to which all data collected through Google Analytics is hosted (i.e. stored and further processed) in the US”. For this particular finding, the EDPS referred, under footnote 27 of the decision, to the proceedings in Austria “regarding the use of Google Analytics in the context of the 101 complaints filed by noyb on the transfer of data to the US when using Google Analytics”, in an evident indication that the supervisory authorities are coordinating their actions.
In turn, the Austrian DPA applied the criteria laid out by the EDPB in its draft Guidelines 5/2021 on the relationship between the scope of Article 3 and Chapter V GDPR, and found that all the conditions are met. The administrator of the website is the controller and it is based in Austria, and, as data exporter, it “disclosed personal data of the complainant by proactively implementing the Google Analytics tool on its website and as a direct result of this implementation, among other things, a data transfer to the second respondent to the US took place”. The DPA also noted that the second respondent, in its capacity as processor and data importer, is located in the US. Hence, Chapter V of the GDPR and its rules for international data transfers are applicable in this case.
However, it should also be highlighted that, as part of fact finding in this case, the Austrian DPA noted that the version of Google Analytics subject to this case was provided by Google LLC (based in the US) until the end of April 2021. Therefore, for the facts of the case which occurred in August 2020, the relevant processor and eventual data importer was Google LLC. But the DPA also noted that since the end of April 2021, Google Analytics has been provided by Google Ireland Limited (based in Ireland).
One important question that remains for future cases is whether, under these circumstances, the DPA would find that an international data transfer occurred, considering the criteria laid out in the draft EDPB Guidelines 5/2021, which specifically require (at least in the draft version, currently subject to public consultation) that “the data importer is located in a third country”, without any further specifications related to corporate structures or location of the means of processing.
2.1 In the absence of an adequacy decision, all data transfers to the US based on “additional safeguards”, like SCCs, need supplementary measures
After establishing that international data transfers occurred from the EU to the US in the cases at hand, the DPAs assessed the lawful ground for transfers used.
The EDPS noted that EU institutions and bodies “must remain in control and take informed decisions when selecting processors and allowing transfers of personal data outside the EEA”. It followed that, absent an adequacy decision, they “may transfer personal data to a third country only if appropriate safeguards are provided, and on condition that enforceable data subject rights and effective legal remedies for data subjects are available”. Noting that the use of Standard Contractual Clauses (SCCs) or another transfer tool do not substitute individual case-by-case assessments that must be carried out in accordance with the Schrems II judgment, the EDPS stated that EU institutions and bodies must carry out such assessments “before any transfer is made”, and, where necessary, they must implement supplemental measures in addition to the transfer tool.
The EDPS recalled some of the key findings of the CJEU in Schrems II, in particular the fact that “the level of protection of personal data in the US was problematic in view of the lack of proportionality caused by mass surveillance programs based on Section 702 of the Foreign Intelligence Surveillance Act (FISA) and Executive Order (EO) 12333 read in conjunction with Presidential Policy Directive (PPD) 28 and the lack of effective remedies in the US essentially equivalent to those required by Article 47 of the Charter”.
Significantly, the supervisory authority then affirmed that “transfers of personal data to the US can only take place if they are framed by effective supplementary measures in order to ensure an essentially equivalent level of protection for the personal data transferred”. Since the EP did not provide any evidence or documentation about supplementary measures being used on top of the SCCs it referred to in the privacy notice on the website, the EDPS found the transfers to the US to be unlawful.
Similarly, the Austrian DPA in its decision recalled that the CJEU “already dealt” with the legal framework in the US in its Schrems II judgment, as based on the same three legal acts (Section 702 FISA, EO 12333, PPD 28). The DPA merely noted that “it is evident that the second respondent (Google LLC – our note) qualifies as a provider of electronic communications services” within the meaning of FISA Section 702. Therefore, it has “an obligation to provide personally identifiable information to US authorities pursuant to 50 US Code §1881a”. Again, the DPA relied on Google’s Transparency Report to show that “such requests are also regularly made to it by US authorities”.
Considering the legal framework in the US as assessed by the CJEU, just like the EDPS did, the Austrian DPA also concluded that the mere entering into SCCs with a data importer in the US cannot be assumed to ensure an adequate level of protection. Therefore, “the data transfer at issue cannot be based solely on the standard data protection clauses concluded between the respondents”. Hence, supplementary measures must be adduced on top of the SCCs. The Austrian DPA relied significantly on the EDPB Recommendation 1/2020 on measures that supplement transfer tools when analyzing the available supplementary measures put in place by the respondents.
2.2 Supplementary measures must “eliminate the possibility of access” of the government to the data, in order to be effective
When analyzing the various measures put in place to safeguard the personal data being transferred, the DPA wanted to ascertain “whether the additional measures taken by the second respondent close the legal protection gaps identified in the CJEU [Schrems II] ruling – i.e. the access and monitoring possibilities of US intelligence services”. Setting this as a target, it went on to analyze the individual measures proposed.
The contractual and organizational supplementary measures considered in the case:
notification of the data subject about data requests (should this be permissible at all in individual cases),
the publication of a transparency report,
the publication of guidelines “for handling government requests”,
careful consideration of any data requests.
The DPA considered that “it is not discernable” to what extent these measures are effective to close the protection gap, taking into account that the CJEU found in the Schrems II judgment that even “permissible (i.e. legal under US law) requests from US intelligence agencies are not compatible with the fundamental right to data protection under Article 8 of the EU Charter of Fundamental Rights”.
The technical supplementary measures considered were:
the protection of communications between Google services,
the protection of data in transit between data centers,
the protection of communications between users and websites,
“on-site security”,
encryption technologies, for example encryption of data at rest in data centers,
processing pseudonymous personal data.
With regard to encryption as one of the supplementary measures being used, the DPA took into account that a data importer covered by Section 702 FISA, as is the case in the current decision, “has a direct obligation to provide access to or surrender such data”. The DPA considered that “this obligation may expressly extend to the cryptographic keys without which the data cannot be read”. Therefore, it seems that as long as the keys are kept by the data importer and the importer is subject to the US law assessed by the CJEU in Schrems II (FISA Section 702, EO 12333, PPD 28), encryption will not be considered sufficient.
As for the argument that the personal data being processed through Google Analytics is “pseudonymous” data, the DPA rejected it relying on findings made by the Conference of German DPAs that the use of cookie IDs, advertising IDs, and unique user IDs does not constitute pseudonymization under the GDPR, since these identifiers “are used to make the individuals distinguishable and addressable”, and not to “disguise or delete the identifying data so that data subjects can no longer be addressed” – which the Conference considers to be one of the purposes of pseudonymization.
Overall, the DPA found that the technical measures proposed were not enough because the respondents did not comprehensively explain (therefore, the respondents had the burden of proof) to what extent these measures “actually prevent or restrict the access possibilities of US intelligence services on the basis of US law”.
With this finding, highlighted also in the operative part of the decision, the DPA seems to de facto reject the “risk based approach” to international data transfers, which has been specifically invoked during the proceedings. This is a theory according to which, for a transfer to be lawful in the absence of an adequacy decision, it is sufficient to prove the likelihood of the government accessing personal data transferred on the basis of additional safeguards is minimal or reduced in practice for a specific transfer, regardless of the broad authority that the government has under the relevant legal framework to access that data and regardless of the lack of effective redress.
The Austrian DPA is technically taking the view that it is not sufficient to reduce the risk of access to data in practice, as long as the possibility to access personal data on the basis of US law is actually not prevented, or in other words, not eliminated. This conclusion is apparent also from the language used in the operative part of the decision, where the DPA summarizes its findings as such: “the measures taken in addition to the SCCs … are not effective because they do not eliminate the possibility of surveillance and access by US intelligence agencies”.
If other DPAs confirm this approach for transfers from the EU to the US in their decisions, the list of potentially effective supplemental measures for transfers of personal data to the US will remain minimal – prima facie, it seems that nothing short of anonymization (per the GDPR standard) or any other technical measure that will effectively and physically eliminate the possibility of accessing personal data by US national security authorities will suffice under this approach.
A key reminder here is that the list of supplementary measures detailed in the EDPB Recommendation concerns all international data transfers based on additional safeguards, to all third countries in general, in the absence of an adequacy decision. In the decision summarized here, the supplementary measures found to be ineffective concern their ability to cover “gaps” in the level of data protection of the US legal framework, as resulting from findings of the CJEU with regard to three specific legal acts (FISA Section 702, EO 12333 and PPD 28). Therefore, the supplementary measures discussed and their assessment may be different for transfers to another jurisdiction.
2.3 Are data importers liable for the lawfulness of the data transfer?
One of the most consequential findings of the Austrian DPA that may have an impact on international data transfers cases moving forward is that “the requirements of Chapter V of the GDPR must be complied with by the data exporter, but not by the data importer” – therefore, under this interpretation, the organizations that are on the receiving end of a data transfer, at least when they are a processor for the data exporter like in the present case, cannot be found in breach of the international data transfers obligations under the GDPR. The main argument used was that “the second respondent (as data importer) does not disclose the personal data of the complainant, but (only) receives them”. As a result, Google was found not to breach Article 44 GDPR in this case.
However, the DPA did consider that it is necessary to look further, and as part of separate proceedings, into how the second respondent complied with its obligations as a data processor, and in particular the obligation to process personal data on documented instructions from the controller, including with regard to transfers of personal data to a third country or an international organization, as detailed in Article 28(3)(a) and Article 29 GDPR.
3.Sanctions and consequences: Between preemptive deletion of cookies, reprimands and blocking transfers
Another commonality of the two decisions summarized is that neither of them resulted in a fine. The EDPS issued a reprimand against the European Parliament for several breaches of the EUDPR, including those related to international data transfers “due to its reliance on the Standard Contractual Clauses in the absence of a demonstration that data subjects’ personal data transferred to the US were provided an essential equivalent level of protection”. It is significant to mention that the EP asked the website service provider to disable both Google Analytics and Stripe cookies in a matter of days after being contacted by the complainants on October 27, 2020. The cookies at issue were active between September 30, when the website became available, and November 4, 2020.
In turn, the Austrian DPA found that “the Google Analytics tool (at least in the version of August 14, 2020) can thus not be used in compliance with the requirements of Chapter V GDPR”. However, as discussed above, the DPA found that only the website operator – as the data exporter – was in breach of Article 44 GDPR. The DPA decided not to issue a fine in this case.
However, the DPA pursues to impose a ban on the data transfers or a similar order against the website, with some procedural complications. In the middle of the proceedings, the Austrian company that was in charge of managing the website transferred the responsibility of operating it to a company based in Germany, therefore the website is not under its control any longer. But since the DPA noted that Google Analytics continued to be implemented on the website at the time of the decision, it resolved to refer the case to the competent German supervisory authority with regard to the possible use of remedial powers against the new operator.
Therefore, it seems that stopping the transfer of personal data to the US without appropriate safeguards seems to be the focus in these cases, rather than sanctioning the data exporters. The parties have the possibility to challenge both decisions before their respective competent Court and require a judicial review within a limited period of time, but there are no indications yet whether this will happen.
4. The big picture: 101 complaints and collaboration among DPAs
The decision published by the Austrian DPA is the first one in the 101 complaints that noyb submitted directly to 14 DPAs across Europe (EU and the European Economic Area) at the same time in August 2020, from Malta, to Poland, to Lichtenstein, with identical legal arguments centered on international data transfers to the US through the use of Google Analytics or Facebook Connect, and all against websites of local or national relevance – so most likely these complaints will be considered outside the One-Stop-Shop mechanism.
The bulk of the 101 complaints were submitted to the Austrian DPA (about 50), either immediately under its competence, as in the analyzed case, or as part of the One-Stop-Shop mechanism where the Austrian DPA acts as the concerned DPA from the jurisdiction where the complainant resides, which likely needed to forward the cases to the many lead DPAs in the jurisdictions were the targeted websites have their establishment. This way, even more DPAs will have to make a decision in these cases – from Cyprus, to Greece, to Sweden, Romania and many more. About a month after the identical 101 complaints were submitted, the EDPB decided to create a taskforce to “analyse the matter and ensure a close cooperation among the members of the Board”.
In contrast, the complaint against the European Parliament was not part of this set, it was submitted separately at a later date to the EDPS, but relying on similar arguments on the issue of international data transfers to the US through Google Analytics and Stripe cookies. Even if it was not part of the 101 complaints, it is clear that the authorities indeed cooperated or communicated, with the EDPS making a direct reference to the Austrian proceedings, as shown above.
In other signs of cooperation, both the Dutch DPA and the Danish DPA have published notices immediately after the publication of the Austrian decision to alert organizations that they may soon issue new guidance in relation to the use of Google Analytics, specifically referring to the Austrian case. Of note, the Danish DPA highlighted that “as a result of the decision of the Austrian DPA” it is now “in doubt whether – and how – such tools can be used in accordance with data protection law, including the rules on transfers of personal data to third countries”. It also called for a common approach of DPAs on this issue: “it is essential that European regulators have a common interpretation of the rules”, since data protection law “intends to promote the internal market”.
In the end, the DPAs are applying findings from a judgment made by the CJEU, which has ultimate authority in the interpretation of EU law that must be applied across all EU Member States. All this indicates that it is likely a series of similar decisions will be successively published in the short to medium future, with small chances of seeing significant variations. This is why these two cases summarized here can be seen as the first two pieces that fell in a domino.
This domino, though, will not only be about the 101 cases and the specific cookies they target – it eventually concerns all US based service providers and businesses that receive personal data from the EU potentially covered by the broad reach of FISA Section 702 and EO 12333; all EU based organizations, from website operators, to businesses, schools, and public agencies, that use the services provided by the former or engage them as business partners, and disclose personal data to them; and it might as well affect all EU based businesses that have offices and subsidiaries in the US and that make personal data available to these entities.