Overcoming Hurdles to Effective Data Sharing for Researchers
In 2021, challenges faced by academics in accessing corporate data sets for research and the issues that companies were experiencing to make privacy-respecting research data available broke into the news. With its long history of research data sharing, FPF saw an opportunity to bring together leaders from the corporate, research, and policy communities for a conversation to pave a way forward on this critical issue. We held a series of four engaging dinner-time conversations to listen and learn from the myriad voices invested in research data sharing. Together, we explored what it will take to create a low-friction, high-efficacy, trusted, safe, ethical, and accountable environment for research data sharing.
FPF formed an expert program committee to set the agenda for the discussion series. The committee guided our selection of topics to discuss, helped identify talented experts to present their views, and introduced FPF to new and salient stakeholders to the research data sharing conversation. The four virtual dinners were held on Thursday, November 4, November 16, December 2, and December 18. Below are significant points of discussion from each event.
The Landscape of Data Sharing
During the first dinner discussion, participants emphasized the importance of reviewing research for ethical soundness and methodological rigor. Many highlighted the challenges of performing consistent and fair ethical and methodological reviews given corporate and research stakeholders’ different expectations and capabilities. FPF has explored this dynamic in the past: both companies and researchers operate with a responsibility to the public that requires technical, ethical, and organizational work to fulfill. The ability of critical stakeholders, including consumers themselves, to articulate the clear and practical steps they take to build trusted public engagement in data sharing varies widely.
Participants offered that one of the key steps necessary to improve public and stakeholder trust in data sharing is to improve education for all parties on the topic. In particular, current efforts should be revised and expanded to more intuitively explain data collection, stewardship, hygiene, interoperability, and the differences in corporate and researchers’ data needs and expectations. Participants suggested improving consumers’ digital literacy so that consent to collecting or using personal data can be more meaningful and dynamic.
Research Ethics and Integrity for a Data Sharing Environment
During our second dinner, two topics emerged. First, participants pointed out how regulations and organizational rules limit the ability of institutions to superintend the ethical, technical, and administrative reviews called for in discussions of data sharing.
Second, the participants honed in on data de-identification and anonymization as critical components of ethical and technical review of proposed data uses for research. While variations in the interpretation of research ethics regulations and norms by Institutional Review Boards (IRBs) lead to an inconsistent and shifting landscape for researchers and companies, the expert panelists pointed out that the variation between IRBs is not as significant as the variation between regulatory controls for research governed by federal restrictions (the Common Rule) and those applied to commercial research under consumer protection laws.
Several participants advocated for a comprehensive U.S. federal data privacy law to equalize institutional variations, eliminate gaps between consumer data protection and research data protections, and clarify protections for research uses of commercial data. Efforts to close such regulatory gaps would require educating all stakeholders, including legislators, researchers, data scientists, and companies’ data protection officers, about the relative differences between risks around research data and risks associated with commercial use or breach of consumer data.
While participants recommended comprehensive privacy legislation as an ideal, serious consideration was paid to the role that specific agency rule-making efforts could play in this space. One of the topics for rulemaking was the concept of data anonymization. Participants considered how to achieve agreement on the ethical imperative for data anonymization. They identified some important steps toward anonymization, such as developing a more agreeable definition of “anonymous” that could be implemented by the many different parties involved in the research data sharing process and providing essential technical support to achieve the expected standards of data anonymization.
The Challenges of Sharing Data from the Perspective of Corporations
During our third dinner, the discussion focused on assessing researchers’ fitness to access an organization’s data. We also discussed evaluating research projects in light of public interest expectations. There was widespread agreement that data sharing is vital for various reasons, such as promoting the next generation of scientific breakthroughs and holding companies publicly accountable. On the other hand, there was disagreement on ensuring that data is available for research and that individuals’ privacy is continuously protected.
Some asserted that privacy was being used as an argument by companies to protect their interests and that it is not as tricky a standard to achieve as is described. Others disagreed with this assessment, saying that they always assumed the worst when it came to the efficacy of privacy protections.
There are also technical and social barriers to democratizing access to corporate data for research. Participants pointed out that technical barriers can be low bars, like file size and type, or high barriers, such as overcoming data fragmentation, including personnel expertise when reviewing projects, building and maintaining shareable data, and managing sector-specific privacy legislation that governs what companies must do to achieve existing data privacy requirements.
Social barriers were discussed as high bars, like limiting access to researchers affiliated with the “right” institutions. Participants discussed how to sufficiently democratize know-how to expand corporate data-sharing and build and maintain the trusted network relationships critical for facilitating data sharing across various parts of the researcher-company environment. Consent reemerged as both a technical and social barrier to data sharing. In particular, participants addressed the problem of securing consumers’ meaningful consent for the use of data in unforeseen but beneficial research use cases that may arise far in the future.
Legislation, Regulation, and Standardization in Data Sharing
During the final dinner conversation, participants tackled the challenging issues of legislation, regulation, and standardization in the research data sharing environment. There was broad agreement that there should be standards for data sharing to make the process more accessible and data more usable. Most participants agreed that data should be FAIR and harmonious. Still, there was disagreement over what field or institution is a good model for this (economics, astronomy, and the US Census were discussed as possibilities).
There was agreement that researchers should meet a certain standard to be given access, but this must be done carefully to avoid creating tiers of first and second-class researchers. The discussion highlighted the importance of having shared standards, vocabulary, terminology, and expectations about the amount of data and supporting material to be transferred.
Interoperability of terms, ontologies, and expectations was another concern flagged throughout the dinner; merely having data available to researchers does not guarantee that they can use it. There was disagreement about what kind of role the National Institutes of Standards and Technology (NIST), the Federal Trade Commission (FTC), and the National Science Foundation (NSF), or researchers’ professional institutions should play or if all of them should play a role in enforcing these standards.
Having access to the code used to process data represents another barrier to research. It isn’t easy to replicate experiments and make discoveries without interoperability and code sharing. There was agreement that an unethical side of data use could complicate any efforts to create positive benefits. Those challenges include zombie data, predatory publication outlets, rogue analysts, and restricting access to research that may have national security implications.
Some Topics Came Up Repeatedly
Persistent topics of discussion throughout the dinners that should be addressed through future legislative or regulatory efforts included: ensuring data quality, data storage requirements (i.e., whether data resides with the firm or with a third party), the incentive structure for academics to share their data with other scholars and with companies, and the emerging role for synthetic data as a method for sharing valuable data representation without transferring the customers’ actual specific and sensitive data.
The series also tackled challenging privacy questions in general, such as: are there special considerations for sharing the data of children or teens (or other vulnerable or protected classes)? Is there a role for funders and publishers to more strongly require documentation for verifying accountability around the use of shared data? Is there a need for involvement by the Office of Research Integrity (ORI) and research misconduct investigators in the supervision of research data sharing?
Next steps toward Responsible Research Data Sharing
In the coming weeks and months, FPF will work with participants in the dinner series to consolidate the knowledge shared during the salon series into a “Playbook for Responsible Data Sharing for Research.” Developed for corporate data protection officers and their counterparts in research institutions, this playbook will cover:
the contracting, capacity-stabilization, and accountability-assurances that should govern research projects using shared data;
managing review of ethics and research project design while respecting research independence review the design of research projects using shared data;
the challenges that researchers must surmount to access and use shared data resources;
the need for effective communication of the findings from such research projects.
We look forward to sharing the “Playbook for Responsible Data Sharing for Research” with the FPF community and our many new friends and partners from the research community in the early months of 2022. Follow FPF on LinkedIn and Twitter, and subscribe to email to receive notification of its release.
Stanford Medicine & Empatica, Google and Its Academic Partners Receive FPF Award for Research Data Stewardship
The second-annual FPF Award for Research Data Stewardship honors two teams of researchers and corporate partners for their commitment to privacy and ethical uses of data in their efforts to research aspects of the COVID-19 pandemic. One team is a collaboration between Stanford Medicine researchers led by Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, and medical wearable and digital biomarker company Empatica. The other team is a collaboration between Google’s COVID-19 Mobility Reports and COVID-19 Aggregated Mobility Research Dataset projects, and researchers from multiple universities in the United States and around the globe.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award was established with the support of the Alfred P. Sloan Foundation, a not-for-profit grantmaking institution that supports high-quality, impartial scientific research and institutions.
The first of this year’s awards recognizes a partnership between a team from Stanford Medicine, consisting of Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from Stanford University’s School of Medicine’s Department of Genetics, and Empatica. The project studied whether data collected by Empatica’s researcher-friendly E4 device, which measures skin temperature, heart rate, and other biomarkers, could detect COVID-19 infections prior to the onset of symptoms.
To ensure the data sharing project minimized privacy risks, both teams took a number of steps including:
Establishing limits on the sharing and use of personal health information.
Using a researcher-friendly version of Empatica’s E4 device that prevents the collection of geolocation data, IP address, or mobile International Mobile Equipment Identity (IMEI) identifiers.
Using QR codes to link participants to specific wearable devices to ensure that participant names and study record IDs would not be shared.
The second award honors Google for its work to produce, aggregate, anonymize, and share data on community movement during the pandemic through its Community Mobility Report and Aggregated Mobility’ Research Dataset projects. Google’s privacy-driven approach was illustrated by the company’s collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. This group of researchers used the shared data from Google to assess the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories.
Google ensured the protection of this shared data in both projects by:
Anonymizing the Mobility Reports through differential privacy, which intentionally adds random noise to metrics in a manner that maintains both users’ privacy and the accuracy of the data.
Requiring that Google review all publications using these data sets to ensure the researchers describe the dataset and its limitations correctly, and that the researchers do not inadvertently re-identify any individual users.
Developing strict privacy protocols agreements and partner criteria for the Agg-epi dataset.
FPF Issues Award for Research Data Stewardship to Stanford Medicine & Empatica, Google & Its Academic Partners
WASHINGTON, DC(June 29, 2021) – The second-annual FPF Award for Research Data Stewardship honors two teams of researchers and corporate partners for their commitment to privacy and ethical uses of data in their efforts to research aspects of the COVID-19 pandemic. One team is a collaboration between Stanford Medicine researchers led by Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, and medical wearable and digital biomarker company Empatica. The other team is a collaboration between Google’s COVID-19 Mobility Reports and COVID-19 Aggregated Mobility Research Dataset projects, and researchers from multiple universities in the United States and around the globe.
“Researchers rely on data to find solutions to the challenges facing our society, but data must only be shared and used in a way that protects individual rights,” said Jules Polonetsky, CEO of the Future of Privacy Forum. “The teams at Stanford Medicine, Empatica, and Google employed a variety of techniques in their research to ensure data was used ethically – including developing strong criteria for potential partners, aggregating and anonymizing participant data, discarding data sets at risk of being re-identified, and conducting extensive ethics and privacy reviews.”
The FPF Award for Research Data Stewardship was established with the support of the Alfred P. Sloan Foundation, a not-for-profit grantmaking institution that supports high-quality, impartial scientific research and institutions.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award highlights companies and academics who demonstrate novel best practices and approaches to sharing corporate data in order to advance scientific knowledge.
Stanford Medicine and Empatica Partnership
Smartwatches and other wearable devices that continuously measure biometric data can provide “digital vital signs” for the user. Dr. Mishra’s team, consisting of Dr. Michael Snyder, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from the Stanford University School of Medicine’s Department of Genetics, received anonymized data from Empatica’s E4 wristband, including data on participants’ skin temperature, heart rate, and electrodermal activity. This data was collected by the Stanford Medicine team to study whether it could be used to detect COVID-19 infections prior to the onset of symptoms. To ensure that this data sharing project minimized potential privacy risks, both Empatica and the Stanford Medicine team took a number of steps, including:
Establishing limits on the sharing and use of personal health information.
Using a researcher-friendly device, Empatica’s E4, that prevents the collection of geolocation data, IP address, or mobile International Mobile Equipment Identity (IMEI) identifiers.
Using QR codes to link participants to specific wearable devices to ensure that participant names and study record IDs would not be shared.
“A large part of our job is to embed research and its results into products that will improve people’s lives.” Said Matteo Lai, CEO of Empatica, “Patients are always at the center of this endeavor, and so naturally are their needs: privacy, a great experience, a sense of safety, high quality are all part of our responsibility. We are honored that this approach and care is recognized as something to strive for.”
The research project is ongoing.
Google’s Community Mobility Information
Google has also been recognized with the second-annual FPF Award for Research Data Stewardship for its work to produce, aggregate, anonymize, and share data on community movement during the COVID-19 pandemic. In response to requests from public health officials, Google created Community Mobility Reports (CMRs) to provide aggregated, anonymized insights into how community mobility has changed in response to policies aimed at combating COVID-19. To ensure that personal data, including an individual’s location, movement, or contacts, cannot be derived from the metrics, the data included in Google’s CMRs goes through a robust anonymization process that employs differential privacy techniques while providing researchers and public health authorities with valuable insights to help inform official decision-making.
Google is also being recognized for a related project, the Aggregated Mobility Research Dataset. In addition to the COVID-19 CMR data, which were made publicly available online, this dataset was shared with specific qualified researchers for the sole purpose of studying the effects of COVID-19. The research was shared with qualified individual researchers (those with proven track records in studying epidemiology, public health, or infectious disease) that accepted the data under contractual commitments to use the data ethically while maintaining privacy. Google was also able to share more detailed mobility data with these researchers, while keeping strong mathematical privacy protections in place. Examples of research that utilized Google’s Aggregated Mobility Research Dataset include:
Hierarchical organization of urban mobility and its connection with city livability
Examining COVID-19 forecasting using spatio-temporal graph neural networks
“As the COVID-19 crisis emerged, Google moved to support public health officials and researchers with resources to help manage the spread,” said Dr. Karen DeSalvo, Chief Health Officer, Google Health. “We heard from the public health community that mobility data could help provide them an understanding of whether people were social distancing to interrupt the spread. Given the sensitivity of mobility data, we needed to deliver this information in a privacy preserving way, and we’re honored to be recognized by FPF for our approach.”
Google ensured the protection of this shared data in both projects by:
Anonymizing the Mobility Reports through differential privacy, which intentionally adds random noise to metrics in a manner that maintains both users’ privacy and the accuracy of the data.
Organizing information by trips taken to different types of locations, rather than providing data about granular geographic areas to protect community privacy
Requiring that Google review all publications using the Aggregated Mobility Research Dataset to ensure the researchers describe the dataset and its limitations correctly
Developing strict privacy protocols agreements and partner criteria for the Aggregated Mobility Research Dataset.
Google’s privacy-driven approach was illustrated by the company’s direct collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. The researchers evaluated the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories using anonymized and aggregated mobility data from Google users who had opted-in to share their data for research. The shared data resulted in an academic paper which will be published in Nature Communications. The project found that state-level emergency declarations resulted in a 9.9% reduction in time spent away from places of residence, with the implementation of social distancing policies resulting in an additional 24.5% reduction in mobility the following week, and shelter-in-place mandates yielding a further 29% reduction in mobility. Notably, these decreases in mobility were associated with significant reductions in reported COVID-19 cases two to four weeks later.
Research from Stanford Medicine and Empatica, Inc: Early Detection of COVID-19 Using Empatica Smartwatch Data
Tejaswini Mishra, PhD, Michael Snyder, PhD, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from the Stanford University School of Medicine’s Department of Genetics, and Empatica Inc. are the recipients of the second-annual FPF Award for Research Data Stewardship. The collaboration between the research team from Stanford Medicine and Empatica, a medical wearable and digital biomarker company, assessed whether wearable devices could be used to detect COVID-19 infections prior to the onset of symptoms, producing valuable insights that have the potential to change how we monitor and address the spread of infectious diseases.
Robust privacy protections built into the project – including setting clear limits on the sharing and use of data, a third-party ethics review, the use of specially-designed research devices, and a comprehensive assessment of privacy and security practices and risks – ensured that individuals’ health information remained private throughout the data sharing and research process.
“A large part of our job is to embed research and its results into products that will improve people’s lives.” Said Matteo Lai, CEO of Empatica, “Patients are always at the center of this endeavor, and so naturally are their needs: privacy, a great experience, a sense of safety, high quality are all part of our responsibility. We are honored that this approach and care is recognized as something to strive for.”
The Research Project
Wearable devices such as consumer smartwatches continuously measure biometric data, including heart rate and skin temperature, that can act as “digital vital signs” informing the wearer about their health status.The collaboration between the research team at Stanford University, led by Michael Snyder, professor and chair of genetics, and Empatica, Inc, explored whether data from wearable devices can be used to detect COVID-19 infections prior to the onset of symptoms. To study whether digital health data from the Empatica E4 Wristband could be used to identify the onset of COVID-19, researchers received skin temperature, electrodermal activity, heart rate, and accelerometer data collected by wristbands worn by 148 study participants for 30 consecutive days. Additionally, researchers received usage compliance metrics for each participant in order to ensure participant compliance with approved study protocol. The research project is ongoing.
Data Protection Procedures and Processes in the research by Stanford Medicine and Empatica Inc.
Establish Limits on Sharing & Use of personal health information (PHI) Data. As part of its legally binding collaboration agreement, Stanford Medicine limited the Stanford PHI data shared with Empatica to COVID-19 test dates and results. Furthermore, Stanford arranged for COVID-19 lab test reporting to be delivered directly to the School of Medicine, without allowing PHI access to Empatica, even though the company paid for the COVID-19 tests.
Ethics Review. During the launch process, the Stanford and Empatica teams developed a research ethics protocol for submission to the Stanford University Institutional Review Board (IRB). The ethics protocol was approved by the Stanford IRB.
Assessment of Privacy & Security Practices. Stanford employed QR codes to link specific participants with specific wearable device serial numbers, such that participant identifiers including names and study record IDs, which are usually sequential, were not shared with Empatica.
Privacy & Security Risk Assessment. Researchers at Stanford and Empatica assessed potential security risks that could arise through their collaboration by initiating a Data Risk Assessment (DRA) by the Stanford University Privacy office (SUPO) to examine the systems set up by Empatica for privacy and security. Empatica readily provided all of the required materials and SUPO certified the project as “low risk.”
Privacy-Protective Research Tools. The project used “researcher version” Empatica devices for the study, which have privacy-enhanced functionality that prevents the Empatica mobile app from collecting geolocation data, IP address, or International Mobile Equipment Identifiers (IMEI). Additionally, Stanford employed QR codes to link specific participants with specific wearable device serial numbers to ensure that participant identifiers, including names and study record IDs, were not shared with Empatica.
Lessons for Future Data-Sharing Projects
The data-sharing collaboration between the research team at Stanford Medicine and Empatica highlights a number of valuable lessons that companies and academic institutions may apply to future data-sharing collaborations.
Work the Process. Empatica and the research team at Stanford Medicine established a clear process to obtain necessary approvals and maintain privacy protections throughout the research collaboration, including a comprehensive Data Risk Assessment, Institutional Review Board (IRB) review, and legal review processes. The research team at Stanford Medicine worked diligently to ensure that they adhered to all plans, processes, and frameworks throughout the research collaboration.
Use Technology to Enhance Privacy. The Stanford research team and Empatica took advantage of technology, where possible, to promote privacy throughout the project. Stanford employed QR codes to prevent the need to share participant identifiers, including names and study record IDs, with Empatica.
Use Privacy-Protective Research Tools. The project used Empatica’s special “researcher version” wearable devices for the study, which include privacy-enhanced functionality to prevent the Empatica mobile app from collecting unnecessary data that could negatively impact study participants’ privacy. Furthermore, Empatica’s devices store and transmit data in an encrypted manner, ensuring that participants’ data could not be accessed by unintended users.
Collaborate Constantly & Responsibly. Empatica and Stanford researchers maintained active communication throughout the study, including weekly meetings to assess the progression of their collaboration, as well as any issues or needs related to their research project. Empatica team members have proactively offered to leave meetings to avoid PHI being shared with them or discussed in their presence, even accidentally.
The Selection Process
Nominees for the Award for Research Data Stewardship were judged by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. The Award Committee evaluated projects based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
Google: COVID-19 Community Mobility Reports
Google has been recognized with the second-annual FPF Award for Research Data Stewardship for its work to produce, aggregate, anonymize, and share data on community movement during the COVID-19 pandemic. Google’s Community Mobility Reports go through a robust anonymization process that employs differential privacy techniques to ensure that personal data, including an individual’s location, movement, or contacts, cannot be derived from the metrics, while providing researchers and public health authorities with valuable insights to help inform official decision making.
As part of their award submission, Google submitted details about an example research collaboration with researchers from Boston University, Harvard University, and Brown University, which evaluated the impacts of state-level policies on mobility and subsequent COVID-19 case trajectories. Ultimately, researchers found that states with mobility policies experienced substantial reductions in time people spent away from their places of residence. That was ultimately connected to decreases in COVID-19 case growth.
Google was also recognized for a related project – the Google COVID-19 Aggregated Mobility Research Dataset – centered around the same underlying anonymized data with small differences in the privacy protections and procedures used. For the purposes of this award, we have combined both Google projects to produce a series of considerations for future data-sharing projects.
“As the COVID-19 crisis emerged, Google moved to support public health officials and researchers with resources to help manage the spread,” said Dr. Karen DeSalvo, Chief Health Officer, Google Health. “We heard from the public health community that mobility data could help provide them an understanding of whether people were social distancing to interrupt the spread. Given the sensitivity of mobility data, we needed to deliver this information in a privacy preserving way, and we’re honored to be recognized by FPF for our approach.”
The Research Project
Since the beginning of the pandemic and during most of 2020, social distancing remained the primary mitigation strategy to combat the spread of COVID-19 in the United States.In responsetorequests from public health officials to provide aggregated, anonymized insights on community movement that could be used to make critical decisions to combat COVID-19, Google set up Community Mobility Reports to provide insights into what has changed in response to policies aimed at combating COVID-19. The reports chart movement trends over time by geography, across different categories of places such as retail and recreation, groceries, pharmacies, parks, transit stations, workplaces, and residential. To date, the aggregated, anonymized data sets have been heavily used for scientific research and economic analysis, as well as informing policy making by national and local governments and inter-governmental organizations.
Google’s approach to privacy was illustrated by the company’s collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. The researchers evaluated the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories using anonymized and aggregated mobility data from Google users who had opted-in to share their data for research. Then they correlated the decreases in mobility tied to state-level policies with changes in the number of reported COVID-19 cases. The project produced the following insights:
State-level emergency declarations resulted in a 9.9% reduction in time spent away from places of residence.
Implementation of one or more social distancing policies resulted in an additional 24.5% reduction in mobility the following week.
Subsequent shelter-in-place mandates yielded an additional 29% reduction in mobility.
Decreases in mobility were associated with substantial reductions in case growth two to four weeks later.
Google was also recognized for a related research project, the Google COVID-19 Aggregated Mobility Research Dataset. In addition to the COVID-19 Community Mobility Reports data, which were made publicly available online, this dataset was shared with specific, qualified researchers for the sole purpose of studying the effects of COVID-19. The research was shared with qualified individual researchers (those with proven track records in studying epidemiology, public health, or infectious disease) that accepted the data under contractual commitments to use the data ethically while maintaining privacy. Google was also able to share more detailed mobility data with these researchers while keeping strong mathematical privacy protections in place.
Data Protection Procedures and Processes in the Google COVID-19 Mobility Reports & Google COVID-19 Aggregated Mobility Research Dataset
Protocol Development, Partner Criteria, and Agreements. Given the sensitive nature of the data, Google developed strict, technical privacy protocols and stringent partner criteria for the Aggregated Mobility Research Dataset to determine how and with whom to share an aggregated version of the underlying data. Data sharing agreements were offered only to well-established non-governmental researchers with proven publication records in epidemiology, public health, or infectious disease, and the scope of research was limited to studying the effects of COVID-19.
Generating Anonymized Metrics. The anonymization process for the COVID-19 Mobility Reports involves differential privacy, a technical process that intentionally adds random noise to metrics in a way that maintains both users’ privacy and the overall accuracy of the aggregated data. Differential privacy represents an important step in the aggregation and anonymization process. The metrics produced through the differential privacy process are then used to assess relative percentage changes in movement behavior for each day from a baseline and those percentage changes are subsequently published by Google.
Aggregation of Data.The metrics are aggregated per day and per geographic area. There are three levels of geographic areas, referred to as granularity levels, including metrics aggregated by country or region (level 0), metrics aggregated by top-level geopolitical subdivisions like states (level 1), and metrics aggregated by higher-resolution granularity like counties (level 2).
Discarding Anonymized, but Geographically Attributable, Data. In addition to the privacy protections implemented through the differential privacy process, Google discards all metrics for which the geographic region is smaller than 3km2, or for which the differentially private count of contributing users (after noise addition) is smaller than 100.
Pre-Publication Review. Due to the sensitivity of the COVID-19 Aggregated Mobility Research Dataset, Google reviews all research involving this dataset prior to publication, including those without Google attribution. This is done to ensure that they describe the dataset and its limitations properly, and that researchers don’t use the dataset improperly, for example, by combining datasets that may lead to the re-identification of individual users.
Lessons for Future Data-Sharing Projects
Google’s COVID-19 Mobility Reports and Google COVID-19 Aggregated Mobility Research Dataset projects highlight a number of valuable lessons that companies and academic institutions may apply to future data sharing collaborations.
Develop Robust Partner Criteria. Upon launching the Google COVID-19 Aggregated Mobility Research Dataset project,Google established strict criteria for research partners outside of government in order to ensure that academic researchers are proven stewards of privacy-protective research with established records in epidemiology, public health, and/or infectious disease. By developing stringent protocols for their academic partners, Google worked to ensure that data is used responsibly and only for the study of the effects of COVID-19.
Consider Differential Privacy. Google’s COVID-19 Mobility Reports data sharing project employed differential privacy to provide mathematical assurances that no individual user data could be manually inspected, studied, or re-identified. The mathematical process that underlines the differential privacy process adds random noise to metrics in a manner that ensures both user privacy and the overall accuracy of the data, which are essential given the use cases of the data.
Share Aggregated Data. By aggregating data by day and geographic location, Google provided further assurances that location and behavior could not be attributed to any single individual, protecting their privacy while providing valuable insights to researchers and public health authorities. The Google team set a geographic threshold for aggregated data, such that data that has been aggregated into geographic regions smaller than 3km2 was discarded.
Tailor Formats & Privacy Protections to Your Audience. The team knew that mobility data could provide a variety of insights in different contexts. Rather than choosing a single application, they tailored their privacy protections to meet the needs of both a publicly available data set and one that could be shared under the terms of a specific agreement.
The Selection Process:
Nominees for the Award for Research Data Stewardship were judged by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. The Award Committee evaluated projects based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
Automated Decision-Making Systems: Considerations for State Policymakers
In legislatures across the United States, state lawmakers are introducing proposals to govern the uses of automated decision-making systems (ADS) in record numbers. In contrast to comprehensive privacy bills that would regulate collection and use of personal information, automated decision-making system (ADS) bills in 2021 specifically seek to address increasing concerns about racial bias or unfair outcomes in automated decisions that impact consumers, including housing, insurance, financial, or governmental decisions.
So far, ADS bills have taken a range of approaches, with most prioritizing restrictions on government use and procurement of ADS (Maryland HB 1323); requiring inventories of government ADSs currently in use (Vermont H 0236); impact assessments for procurement (CA AB-13); external audits (New York A6042); or outright prohibitions on the procurement of certain types of unfair ADS (Washington SB 5116). A handful of others would seek to regulate commercial actors, including in insurance decisions (Colorado SB 169), consumer finance (New Jersey S1943), or the use of automated decision-making in employment or hiring decisions (Illinois HB 0053, New York A7244).
At a high level, each of these bills share similar characteristics. Each proposes general definitions and general solutions that cover specific, complex tools used in areas as varied as traffic forecasting and employment screening. But the bills are not consistent with regard to requirements and obligations. For example, among the bills that would require impact assessments, some require impact assessments universally for all ADS in use by government agencies, others would require impact assessments only for specifically risky uses of ADS.
As states evaluate possible regulatory approaches, lawmakers should: (1) avoid a “one size fits all” approach to defining automated decision-making by clearly defining the particular systems of concern; (2) consult with experts in governmental, evidence-based policymaking; (3) ensure that impact assessments and disclosures of risk meet the needs of their intended audiences; (4) look to existing law and guidance from other state, federal, and international jurisdictions; and (5) ensure appropriate timelines for technical and legal compliance, including time for building capacity and attracting qualified experts.
1. Avoid “one size fits all” solutions by clearly identifying the automated decision-making systems of concern.
An important first step to the regulation of automated decision-making systems (“ADS”) is to identify the scope of systems that are of concern. Many lawmakers have indicated that they are seeking to address automated decisions such as those that use consumer data to create “risk scores,” creditworthiness profiles, or other kinds of profiles that materially impact our lives and involve the potential for systematic bias against categories of people. But, the wealth of possible forms of ADS and the many settings for their use can make defining these systems in legislation very challenging.
Automated systems are present in almost all walks of modern life, from managing wastewater treatment facilities to performing basic tasks such as operating traffic signals. ADS can automate the processing of personal data, administrative data, or myriad forms of other data, through the use of tools ranging in complexity from simple spreadsheet formulas, to advanced statistical modeling, rules-based artificial intelligence, or machine learning. In an effort to navigate this complexity, it can be tempting to draft very general definitions of ADS. However, these definitions risk being overbroad and capturing ADS systems that are not truly of concern — i.e. because they do not impact people or carry out significant decision-making.
For example, a definition such as “a computational process, including one derived from machine learning, statistics, or other data processing or artificial intelligence techniques, thatmakes a decision or facilitates human decision-making” (New Jersey S1943) would likely include a wide range of traditional statistical data processing, such as estimating average number of vehicles per hour on a highway to facilitate automatic lane closures in intelligent traffic systems. This would place an additional, significant requirement for conducting complex impact assessments for many of the tools behind established operational processes. In contrast, California’s AB-13 takes a more tailored approach, aiming to regulate “high-risk application[s]” of algorithms that involve “a score, classification, recommendation, or other simplified output,” that support or replace human decision-making, in situations that “materially impact a person” (12115(a)&(b)).
In general, compliance-heavy requirements or prohibitions on certain practices may be appropriate only for some high-risk systems. The same requirements would be overly prescriptive or infeasible for systems powering ordinary, operational decision-making. Successfully distinguishing between high-risk use cases and those without significant, personal impact will be crucial to crafting tailored legislation that addresses the targeted, unfair outcomes without overburdening other applications.
Lawmakers should ask questions such as:
Who owns or is responsible for the ADS? Is the system being used by government decision-makers, commercial actors, or both (private vendors contracted by government agencies)? The relevant “owner” of a system may determine the right balance of transparency, accountability, and access to underlying data necessary to accomplish the legislative goals.
What kind of data is involved? Many systems use a wide range of data that may or may not include personal information (information related to reasonably identifiable individuals), and may or may not include “sensitive data” (personal data that reveals information about race, religion, health conditions, or other highly personal information). In some cases, non-sensitive data can act as a “proxy” for sensitive information (such as the use of zip code as a proxy for race). Data may also be obtained from sources of varying quality, accuracy, or ethical collection, for example: public records, government collection, regulated commercial sectors (banks or credit agencies), commercial data brokers, or other commercial sources.
Who is impacted by the decision-making? Does the decision-making impact individuals, groups of individuals, or neither? Is there a possibility for disparate impact in who is affected, i.e. that certain races, genders, income levels, or other categories of people will be impacted differently or worse than others?
Is the decision-making legally significant? In most cases, our tolerance for automated decision-making depends on the decision being made. Some decisions are commonplace or operational, such as automated electrical grid management. Other decisions are so relevant to our individual lives and autonomy that use of automated systems in this context demands greater transparency, human involvement, or even auditing such as: financial opportunities, housing, lending, educational opportunities, or employment. Still other decisions may be in a “grey area”: for example, automated delivery of online advertisements is common, but questions about algorithmic bias in ad quality or who sees certain types of ads (e.g. ads for particular jobs) are leading to increasing scrutiny.
Does the system assist human decision-making or replace it? Some systems replace human decision-making entirely, such as when a system generates an automated approval or denial of a financial opportunity that occurs without human review. Other systems assist human decision-makers by generating outputs such as scores or classifications that allow decision-makers to complete tasks, such as grading a test or diagnosing a health condition.
When do “meaningful changes” occur? Many legislative efforts seek to trigger requirements for new or updated impact assessments when ADSs change, or “meaningfully change.” For such requirements, lawmakers should establish clear criteria for what constitutes a “meaningful change.” For example, machine learning systems that adapt based upon a stream of sensor or customer data change constantly, whether by changing the weights attached to features or by eliminating features. Whether adaptations made as a consequence of typical machine learning operations constitute meaningful changes is an important question best poised to be answered in ways specific to each learning and adapting system. The velocity and variety of changes to ADS driven by machine learning may require other forms of ongoing assessment to identify abnormalities or potential harms as they arise.
These questions can help guide legislative definitions and scope. A “one size fits all” solution not only risks creating burdensome requirements in situations where they are not needed, but is also less likely to ensure stronger requirements in situations where they are needed — leaving potentially biased algorithms to operate without sufficient review or standards to address resulting outcomes that are biased or unfair. An appropriate definition is a critical first step for effective regulation.
2. Consult with experts in governmental, evidence-based policymaking.
Evidence-based policymaking legislation, popular in the late 1990s and early 2000s, required states to construct systems to eradicate human bias by employing data-driven practices for key areas of state decision-making, such as criminal justice, student achievement predictions, and even land use planning. For example, as defined by the National Institute of Corrections, the vision for implementing evidence based practice in community corrections is “to build learning organizations that reduce recidivism through systematic integration of evidence-based principles in collaboration with community and justice partners” (see resources at the Judicial Council of California 2021). The areas chosen for application of evidence-based policymaking are presently causing high degrees of concern about applications of ADS as the mechanisms for ensuring use of evidence and elimination of subjectivity. Examining the goals envisioned in evidence-based policymaking legislation may clarify whether ADS are appropriate tools for satisfying those goals.
In addition to consulting the policies encouraging evidence-based making in order to identify the goals for automated decision-making systems (ADSs) the evidence-based research findings reviewed to support this legislation can also direct legislators to contextually relevant, expert, sources of data that should be incorporated into ADS or into the evaluation of ADS. Likewise, legislators should reflect on the challenges to implementation of effective evidence-based decision-making, such as unclear definitions, poor data quality, challenges to statistical modelling, and a lack of interoperability of public data sources, as these challenges are similar to those complicating use of ADS.
3. Ensure that impact assessments and disclosures of risk meet the needs of their intended audiences.
Most ADS legislative efforts aim to increase transparency or accountability through various forms of mandated notices, disclosures, data protection impact assessments, or other risk assessments and mitigation strategies. These requirements serve multiple, important goals, including helping regulators understand data processing, and increasing internal accountability through greater process documentation. In addition, public disclosures of risk assessments benefit a wide range of stakeholders, including: the public, consumers, businesses, regulators, watchdogs, technologists, and academic researchers.
Given the needs of different audiences and users of such information,lawmakers should ensure that impact assessments and mandated disclosures are leveraged effectively to support the goals of the legislation. For example, where legislators intend to improve equity of outcomes between groups, they should include legislative support for tools to improve communication to these groups and to support incorporation of these groups into technical communities. Where sponsors of ADS bills intend to increase public awareness of automated decision-making in particular contexts, legislation should require and fund consumer education that is easy to understand, available in multiple languages, and accessible to broad audiences. In contrast, if the goal is to increase regulator accountability and technical enforcement, legislation might mandate more detailed or technical disclosures be provided non-publicly or upon request to government agencies.
The National Institutes of Standards and Technology (NIST) has offered recent guidance on explainability in artificial intelligence that might serve as a helpful model for ensuring that impact assessments are useful for the multiple audiences they may serve. The NIST draft guidelines suggest four principles for explainability for audience sensitive, purpose driven, ADS assessment tools: (1) Systems offer accompanying evidence or reason(s) for all outputs; (2) Systems provide explanations that are understandable to individual users; (3) The explanation correctly reflects the system’s process for generating the output; and (4) The system only operates under conditions for which it was designed or when the system reaches a sufficient confidence in its output (p.2). These four principles shape the types of explanations needed to ensure confidence in algorithmic or automated decision-making systems (ADSs), such as explanations for user benefit, for social acceptance, for regulatory and compliance purposes, for system development, and for owner benefit (p. 4-5).
Similarly, the European Commission’s Guidelines on Automated Individual Decision-Making and Profiling provides recommendations for complying with the GDPR’s requirement that individual users be given “meaningful information about the logic involved.” Rather than requiring a complex explanation or exposure of the algorithmic code, the Commission explains that a controller should find simple ways to tell the data subject the rationale behind, or the criteria relied upon to reach a decision. This may include which characteristics are considered to make a decision, the source of the information, and its relevance. It should not be overly technical, but sufficiently comprehensive for a consumer to understand the reason for the decision.
Regardless of the audience, mandated disclosures should be used cautiously as, especially when made public, such disclosures can also create certain risks, such as opportunities for data breaches, exfiltration of intellectual property (IP), or even attacks on the algorithmic system which could identify individuals or cause the systems to behave in unintended ways.
4. Look to existing law and guidance from other state, federal, and international jurisdictions.
Although US lawmakers have specific goals, needs, and concerns driving legislation in their jurisdictions, there are clear lessons to be learned from other regimes with respect to automated decision-making. Most significantly, there has been a growing, active wave of legal and technical guidance in the European Union in recent years regarding profiling and automated decision-making, following the passage of the GDPR. Lawmakers may also seek to ensure interoperability with the newly passed California Privacy Rights Act (CPRA) or Virginia Consumer Data Protection Act (VA-CDPA), both of which create requirements that impact automated decision-making, including profiling. Finally, the Federal Trade Commission enforces a number of laws that could be harnessed to address concerns about biased or unfair decision-making. Of note, Singapore is also a leader in this space, launching their Model AI Governance Framework in 2019. It is useful to understand the advantages or limitations of each model and to recognize the practical challenges of adapting systems for each jurisdiction.
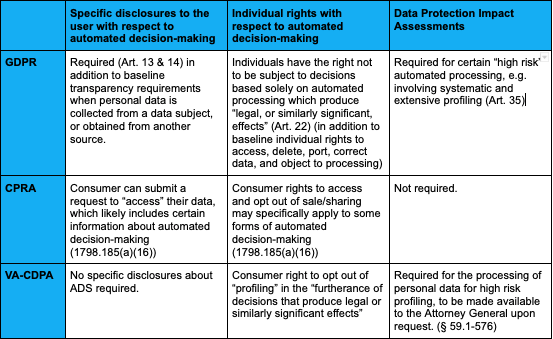
General Data Protection Regulation (GDPR)
The EU General Data Protection Regulation (GDPR) broadly regulates public and private collection of personal information. This includes a requirement that all data processing be fair (Art. 5(1)(a)). The GDPR also creates heightened safeguards specifically for high risk automated processing that impact individuals, especially with respect to decisions that produce legal, or other significant, effects concerning individuals. These safeguards include organizational responsibilities (data protection impact assessments); and individual empowerment provisions (disclosures, and the right not to be subject to certain kinds of decisions based solely on automated processing).
Organizational Responsibilities. Data protection impact assessments (DPIAs) required under the GDPR for “high risk” processing activities, must include a systematic description of the envisaged processing operations and the purposes of the processing, an assessment of the necessity and proportionality of the processing operations in relation to the purposes, an assessment of the risks to the rights and freedoms of data subjects, and measures envisaged to address the risks, including safeguards, security measures and mechanisms to ensure the protection of personal data. Recital 75 of the GDPR, which details the Art. 35 DPIA requirements, provides details about the nature of the data processing risks intended to be covered. In addition the GDPR requires all automated processing to incorporate technical and organizational measures to implement data protection by design principles (Art. 25).
Individual Control. In addition to providing organizational responsibilities such as data protection impact assessments (DPIAs), the GDPR also requires controllers to provide data subjects with information relating to their automated processing activities (Art. 13 & 14). In particular, controllers must disclose the existence of automated decision-making, including profiling, meaningful information about the logic involved, and the significance and envisaged consequences of processing for the data subject. These disclosures are required when personal data is collected from a data subject, and also when personal data is not obtained from a data subject. In addition, the GDPR creates the right for an individual not to be subject to decisions based solely on automated processing which produce legal, or similarly significant, effects concerning an individual (Art. 22). Suitable measures to safeguard the data subject’s rights, freedoms, and legitimate interests include the rights for an individual to: (1) obtain human intervention on the part of the controller (human in the loop), (2) express their point of view, and (3) contest a decision.
California Privacy Rights Act (CRPA)
The California Privacy Rights Act (CPRA), passed via Ballot Initiative in 2020, expands on the California Consumer Privacy Act (CCPA)’s requirements that businesses comply with consumer requests to access, delete, and opt-out of the sale of consumer data.
While the CPRA does not create any direct consumer rights or organizational responsibilities with respect to automated decision-making, its consumer access rights includes access to information about “inferences drawn . . . to create a profile” (Sec. 1798.140(v)(1)(K)) and most likely information about the use of the consumer’s data for automated decision-making.
Notably, the CPRA added a new definition of “profiling” to the CCPA, while authorizing the new California oversight agency to engage in rulemaking. In alignment with the GDPR, the CPRA defines “profiling” as “any form of automated processing of personal Information . . . to evaluate certain personal aspects relating to a natural person, and in particular to analyze or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behavior, location or movements” (1798.140(z)).
The CPRA authorizes the new California Privacy Protection Agency to issue regulations governing automated decision-making, including “governing access and opt‐out rights with respect to businesses’ use of [ADS], including profiling and requiring businesses’ response to access requests to include meaningful information about the logic involved in such decision-making processes, as well as a description of the likely outcome of the process with respect to the consumer.” (1798.185(a)(16)). Notably, this language lacks the GDPR’s “legal or similarly significant” caveat, meaning that the CPRA requirements around access and opt-outs may extend to processing activities such as targeted advertising based on profiling.
Virginia Consumer Data Protection Act (VA-CDPA)
The Virginia Consumer Data Protection Act (VA-CDPA), which passed in 2021 in Virginia and will come into effect in 2023, takes an approach towards automated decision-making inspired by both the GDPR and CPRA.
First, its definition of “profiling” aligns with that of the GDPR and CPRA (§ 59.1-571). Second, it imposes a responsibility upon data controllers to conduct data protection impact assessments (DPIAs) for high risk profiling activities (§ 59.1-576). Third, it creates a right for individuals to opt out of having their personal data processed for the purpose of profiling in the furtherance of decisions that produce legal or similarly significant effects concerning the consumer (§ 59.1-573(5)).
Organizational Responsibilities. The VA-CDPA requires data controllers to conduct and document data protection impact assessments (DPIAs) for “profiling” that creates a “reasonably foreseeable risk of (i) unfair or deceptive treatment of, or unlawful disparate impact on, consumers; (ii) financial, physical, or reputational injury to consumers; (iii) a physical or other intrusion upon the solitude or seclusion, or the private affairs or concerns, of consumers, where such intrusion would be offensive to a reasonable person; or (iv) other substantial injury to consumers.” These DPIA’s are required to identify and weigh the benefits against the risks that may flow from the processing, as mitigated by safeguards employed to reduce such risks. They are not intended to be made public or provided to consumers. Instead, these confidential documents must be made available to the State Attorney General upon request, pursuant to an investigative civil demand.
Individual Control. The VA-CDPA grants consumers the right to submit an authenticated request to opt-out of the processing of personal data for purposes of profiling “in the furtherance of decisions that produce legal or similarly significant effects concerning the consumer,” which is defined as “a decision made by the controller that results in the provision or denial by the controller of financial and lending services, housing, insurance, education enrollment, criminal justice, employment opportunities, health care services, or access to basic necessities, such as food and water.”
The FTC Act and broadly applicable consumer protection laws
Finally, a range of federal consumer protection and sectoral laws already apply to many businesses’ uses of automated decision-making systems. The Federal Trade Commission (FTC) enforces long-standing consumer protection laws prohibiting “unfair” and “deceptive” trade practices, including the FTC Act. As recently as April 2021, the FTC warned businesses of the potential for enforcement actions for biased and unfair outcomes in AI, specifically noting that the “sale or use of – for example – racially biased algorithms” would violate Section 5 of the FTC Act.
The FTC also noted its decades of experience enforcing other federal laws that are applicable to certain uses of AI and automated decisions, including the Fair Credit Reporting Act (if an algorithm is used to deny people employment, housing, credit, insurance, or other benefits), and the Equal Credit Opportunity Act (making it “illegal for a company to use a biased algorithm that results in credit discrimination on the basis of race, color, religion, national origin, sex, marital status, age, or because a person receives public assistance”).
Comparison chart:
5.Ensure appropriate timelines for technical and legal compliance, including building capacity and attracting qualified experts.
In general, timelines for government agencies and companies to comply with the law should be appropriate to the complexity of the systems that will be needed to review for impact. Many government offices may not be aware that the systems they use every day to improve throughput, efficiency, and effective program monitoring may constitute “automated decision-making.” For example, organizations using Customer Relations Management (CRM) software from large vendors may be using predictive and profiling systems built into that software. Also, governmental offices suffer from siloed procurement and development strategies and may have built or purchased overlapping ADS to serve specific, sometimes narrow, needs.
Lack of government funding, modernization, or resources to address the complexity of the systems themselves, and the lack of prior requirements for tracking automated systems in contracts or procurement decisions, means that many agencies will not readily have access to technical information on all systems in use. Automated decision-making systems (ADSs) have been shown to suffer from technological debt, opaque and incomplete technical documentation, or are dependent on smaller automated systems that can only be discovered through careful review of source code and complex information architectures.
Challenges such as these were highlighted during 2020 as a result of the COVID-19 pandemic, which prompted millions to pursue temporary unemployment benefits. When applications for unemployment benefits surged, some state unemployment agencies discovered that their programs were written in the infrequently used programming language, COBOL. Many resource-strapped agencies were using stop-gap code, intended for temporary use, to translate COBOL into more contemporary coding languages. As a result, many agencies lacked programming experts and capacity to efficiently process the influx of claims. Regulators should ensure that offices have time, personnel, and funding to undertake the digital archaeology necessary to reveal the many layers of ADSs used today.
Finally, lawmakers should not overlook the challenges of identifying and attracting qualified technical and legal experts. For example, many legislative efforts envision a new or expanded government oversight office with the responsibility to review automated impact assessments. Not only will the personnel needed for these offices need to be able to meaningfully interpret algorithmic impact assessments, they will need to do so in an environment of high sensitivity, publicity, and technological change. As observed in many state and federal bills calling for STEM and AI workforce development, the talent pipeline is limited and legislatures should address the challenges of attracting appropriate talent as a key component of these bills. Likewise, identifying appropriate expectations of performance, including ethical performance, for ADS review staff will take time, resources, and collaboration with new actors, such as the National Society of Professional Engineers, whose code of conduct governs many working in fields responsible for designing or using ADS.
What’s Next for Automated Decision System Regulation?
States are continuing to take up the challenge of regulating these complex and pervasive systems. To ensure that these proposals achieve their intended goals, legislators must address the ongoing issues of definition, scope, audience, timelines and resources, and mitigating unintended consequences. More broadly, legislation should help motivate more challenging public conversations about evaluating the benefits and risks of using ADS as well as the social and community goals for regulating these systems.
At the highest level, legislatures should bear in mind that ADS are engineered systems or products that are subject to product regulations and ethical standards for those building products. In addition to existing laws and guidance, legislators can consult the norms of engineering ethics, such as the NSPE’s code of ethics, which requires that engineers ensure their products are designed so as to protect as paramount the safety, health and welfare of the public. Stakeholder engagement, including with consumers, technologists, and the academic community, is imperative to ensuring that legislation is effective.
FPF Seeks Nominations for 2021 Research Data Stewardship Award
The Call for Nominations for the 2021 FPF Award for Research Data Stewardship is now open. You can find the nominations forms here. We ask that nominations be submitted by Monday, March 1, 2021.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award highlights companies and academics who demonstrate novel best practices and approaches to sharing corporate data in order to advance scientific knowledge.
The 2020 Research Data Stewardship Award was given to Lumos Labs and Professor Mark Steyvers for their path breaking work using data to model human attention and cognition. We look forward to reading submissions of innovative work in cognitive science and any other scientific field this year. We are keenly interested in multidisciplinary work that shows the power of shared data to answer questions that span multiple fields of inquiry.
Academics and their corporate partners are invited to nominate a successful data-sharing project that reflects privacy protective approaches to data protection and ethical data sharing. Nominations will be reviewed and selected by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. Nominated projects will be judged based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
The nominations form will be open until February 19th. If you have questions about the nomination form, the process of review, or any other information about the award, please contact Dr. Sara Jordan at sjordan at fpf dot org.