A Visual Guide to Practical Data De-Identification
For more than a decade, scholars and policymakers have debated the central notion of identifiability in privacy law. De-identification, the process of removing personally identifiable information from data collected, stored and used by organizations, was once viewed as a silver bullet allowing organizations to reap data benefits while at the same time avoiding risks and legal requirements.
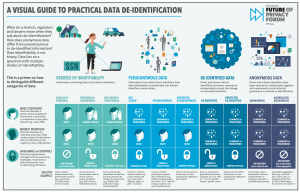
However, the concept of de-identification has come under intense pressure to the point of being discredited by some critics. Computer scientists and mathematicians have come up with a re-identification tit for every de-identification tat. At the same time, organizations around the world necessarily continue to rely on a wide range of technical, administrative, and legal measures to reduce the identifiability of personal data to enable critical uses and valuable research while providing protection to individuals’ identity and privacy.
The debate around the contours of the term personally identifiable information, which triggers a set of legal and regulatory protections, continues to rage, with scientists and regulators frequently referring to certain categories of information as “personal” even as businesses and trade groups define them as “de-identified” or “non-personal.”
The stakes in the debate are high. While not foolproof, de-identification techniques unlock value by enabling important public and private research, allowing for the maintenance and use – and, in certain cases, sharing and publication – of valuable information, while mitigating privacy risk.
* * *
Omer Tene, Kelsey Finch and Jules Polonetsky have been working to address these thorny issues in a paper titled Shades of Gray: Seeing the Full Spectrum of Practical Data De-Identification. The paper is published in the Santa Clara Law Review.
Read our opinion piece via The International Association of Privacy Professionals.
Accompanying this paper is our Visual Guide to Practical Data De-Identification.


