Understanding the "World of Geolocation Data"
How is location data generated from mobile devices, who gets access to it, and how? As debates over companies and public health authorities using device data to address the current global pandemic continue, it is more important than ever for policymakers and regulators to understand the practical basics of how mobile operating systems work, how apps request access to information, and how location datasets can be more or less risky or revealing for individuals and groups. Today, Future of Privacy Forum released a new infographic, “The World of Geolocation Data” that explores these issues.
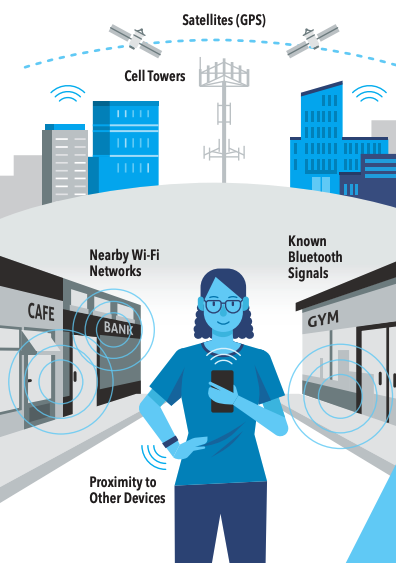
In this infographic, we demonstrate how mobile devices, such as smartphones, interpret signals from their surroundings – including GPS satellites, cell towers, Wi-Fi networks, and Bluetooth – to generate a precise location measurement (latitude and longitude). This measurement is provided by the mobile operating system to mobile apps through a Location Services API when they request it and receive the user’s permission. As a result, apps must comply with the technical and policy controls set by the mobile operating systems, such as App Store Policies.
Many different entities (including, but not limited to mobile apps) provide location features or use location data for a variety of other purposes. Different entities are subject to different restrictions, such as public commitments, privacy policies, contracts and licensing agreements, user controls, app store policies, and sector-specific laws (such as telecommunications laws for mobile carriers). In addition, broadly applicable privacy and consumer protection laws will generally apply to all commercial entities, such as the California Consumer Privacy Act, or the Federal Trade Commission Act (FTC Act).

Finally, in addition to legal and policy controls, location datasets can be technically modified to further mitigate risks to individuals and groups. Some of those practical mitigation steps might include:
- Using proximity instead of location.
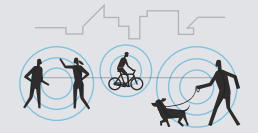 Proximity to nearby devices can be measured without revealing a device’s actual location. The use of nearby signals (such as Bluetooth) can be less risky than collecting a detailed location history of a device.
Proximity to nearby devices can be measured without revealing a device’s actual location. The use of nearby signals (such as Bluetooth) can be less risky than collecting a detailed location history of a device. - Reducing precision or accuracy. Location data can be accurate (revealing of a device’s true location) or inaccurate, as well as precise (granular, such as that a device is located on a specific street corner) or imprecise (a city or country). The more accurate and precise the data, the more revealing it tends to be, and the greater the risks of re-identification.
- Avoiding persistent identifiers
 (reducing persistence or frequency). Prolonged location tracking is more revealing of individual behavior when it is more frequently collected and for longer amounts of time. As a result, using a persistent identifier (such as an IMEI Number or Advertising ID) usually creates more risk than using a random or rotating identifier.
(reducing persistence or frequency). Prolonged location tracking is more revealing of individual behavior when it is more frequently collected and for longer amounts of time. As a result, using a persistent identifier (such as an IMEI Number or Advertising ID) usually creates more risk than using a random or rotating identifier. - Redacting home and work locations. Known locations that are tied to an individual’s identity, such as that person’s home or workplace, often contribute to device data being more easily re-identified.
- Redacting sensitive locations. Some locations are particularly sensitive because of what they may reveal about the device owner, such as hospitals, schools, nightclubs, abortion clinics, dispensaries, or political organizations and events. Although these locations may not always increase risks of re-identification, they do bring higher risks of abuses or unexpected uses, and can often be redacted or geo-fenced so that data is not collected in the first place.
- Applying de-identifying techniques. Many techniques can be applied to further reduce risk of identifying individuals within a dataset, including aggregating the data, applying computational methods such as differential privacy. Risk can be further reduced through administrative access controls within an organization that strictly limit who has access to raw data.