Data-Driven Pricing: Key Technologies, Business Practices, and Policy Implications
In the U.S., state lawmakers are seeking to regulate various pricing strategies that fall under the umbrella of “data-driven pricing”: practices that use personal and/or non-personal data to continuously inform decisions about the prices and products offered to consumers. Using a variety of terms—including “surveillance,” “algorithmic,” and “personalized” pricing—legislators are targeting a range of practices that often look different from one another, and carry different benefits and risks. Generally speaking, these practices fall under one of four categories:
Reward or loyalty program: A company offers a discount, reward, or other incentive to repeat customers who sign up for the program. In return, the company receives additional customer data.
Dynamic pricing: Rapidly changing the price of a particular product or service based on real-time analysis of market conditions and consumer behavior.
Consumer segmentation or profiling: A profile is created for a customer based on their personal data, including behavior and/or characteristics, and they are placed within a particular audience segment. Based on the profile or segment, they receive particular advertisements, prices, or promotions.
Search or product ranking: Altering the order in which search results or products appear, to give more prominence to certain results, based on general consumer data or specific customer behavioral data. This could potentially include changing the prominence of given products based on their price.
This resource distinguishes between these different pricing strategies in order to help lawmakers, businesses, and consumers better understand how these different practices work.
Tech to Support Older Adults and Caregivers: Five Privacy Questions for Age Tech
Introduction
As the U.S. population ages, technologies that can help support older adults are becoming increasingly important. These tools, often called “AgeTech”, exist at the intersection of health data, consumer technology, caregiving relationships, and increasingly, artificial intelligence, and are drawing significant investment. Hundreds of well funded start-ups have launched. Many are of major interest to governments, advocates for aging populations, and researchers who are concerned about the impact on the U.S. economy when a smaller workforce supports a large aging population.
AgeTech may include everything from fall detection wearables and remote vital sign monitors to AI-enabled chatbots and behavioral nudging systems. These technologies promise greater independence for older adults, reduced burden on caregivers, and more continuous, personalized care. But that promise brings significant risks, especially when these tools operate outside traditional health privacy laws like HIPAA and instead fall under a shifting mix of consumer privacy regimes and emerging AI-specific regulations.
A recent review by FPF of 50 AgeTech products reveals a market increasingly defined by data-driven insights, AI-enhanced functionality, and personalization at scale. Yet despite the sophistication of the technology, privacy protections remain patchy and difficult to navigate. Many tools were not designed with older adults or caregiving relationships in mind, and few provide clear information about how AI is used or how sensitive personal data feeds into machine learning systems.
Without frameworks for trustworthiness and subsequent trust from older adults and caregivers, the gap between innovation and accountability will continue to grow, placing both individuals and companies at risk. Further, low trust may result in barriers to adoption at a time when these technologies are urgently needed as the aging population grows and care shortages continue.
A Snapshot of the AgeTech Landscape
AgeTech is being deployed across both consumer and clinical settings, with tools designed to serve four dominant purposes:
Health Monitoring or managing a specific health condition such as dementias, heart conditions, or other long-term conditions.
Remote Monitoring which may include location-tracking by a family member or other caregiver, bodily mobility monitoring by a provider, or other general monitoring not related to a specific condition or diagnosis.
Daily Task Support including appointments, medication adherence, meals, and errands.
Emergency Use such as fall detection and prevention, emergency communications, and alerts.
Clinical applications are typically focused on enabling real-time oversight and remote data collection, while consumer-facing products are aimed at supporting safety, independence, and quality of life at home. Regardless of setting, these tools increasingly rely on combinations of sensors, mobile apps, GPS, microphones, and notably, AI used for everything from fall detection and cognitive assistance to mood analysis and smart home adaptation.
AI is becoming central to how AgeTech tools operate and how they’re marketed. But explainability remains a challenge and disclosures around AI use can be vague or missing altogether. Users may not be told when AI is interpreting their voice, gestures, or behavior, let alone whether their data is used to refine predictive models or personalize future content.
For tools that feel clinical but aren’t covered by HIPAA, this creates significant confusion and risk. A proliferation of consumer privacy laws, particularly emerging state-level privacy laws with health provisions are starting to fill the gap, leading to complex and fragmented privacy policies. For all stakeholders seeking to improve and support aging through AI and other technologies, harmonious policy-based and technical privacy protections are essential.
AgeTech Data is Likely in Scope of Many States’ Privacy Laws
Compounding the issue is the reality that these tools often fall into regulatory gray zones. If a product isn’t offered by a HIPAA-covered entity or used in a reimbursed clinical service, it may not be protected under federal health privacy law at all. Instead, protections depend on the state where a user lives, or whether the product falls under one of a growing number of state-level privacy laws or consumer health privacy laws.
Laws like New York’s S929/NY HIPA, which remains in legislative limbo, reflect growing state interest in regulating sensitive and consumer health data that would likely be collected by AgeTech devices and apps. These laws are a step toward closing a gap in privacy protections, but they’re not consistent. Some focus narrowly on specific types of health data individually or in tandem with AI or other technologies. For example, mental health chatbots (Utah HB452), reproductive health data (Virginia SB754), or AI disclosures in clinical settings (California AB3030). Other bills and laws have broad definitions that include location, movement, and voice data, all common types of data in our survey of AgeTech. Regulatory obligations may vary not just by product type, but by geography, payment model (where insurance may cover a product or service), and user relationship.
Consent + Policy is Key to AgeTech Growth and Adoption
In many cases, it is not the older adult but a caregiver, whether a family member, home health aide, or neighbor, who initiates AgeTech use and agrees to data practices. These caregiving relationships are diverse, fluid, and often informal. Yet most technologies assume a static one-to-one dynamic and offer few options for nuanced role-based access or changing consent over time.
For this reason, AgeTech is a good example of why consent should not be the sole pillar of data privacy. While important, relying on individual permissions can obscure the need for deeper infrastructure and policy solutions that relieve consent burdens while ensuring privacy. Devices and services that align privacy protections with contextual uses and create pathways for evidence-based, science-backed innovation that benefits older adults and their care communities are needed.
Five Key Questions for AgeTech Privacy
To navigate this complexity and build toward better, more trustworthy systems, privacy professionals and policymakers can start by asking the following key questions:
Is the technology designed to reflect caregiving realities?
Caregiving relationships are rarely linear. Tools must accommodate shared access, changing roles, and the reality that caregivers may support multiple people, or that multiple people may support the same individual. Regulatory standards should reflect this complexity, and product designs should allow for flexible access controls that align with real-world caregiving.
Does the regulatory classification reflect the sensitivity of the data, not just who offers the tool?
Whether a fall alert app is delivered through a clinical care plan or bought directly by a consumer, it often collects the same data and has the same impact on a person’s autonomy. Laws should apply based on function and risk. Laws should also consider the context and use of data in addition to sensitivity. Emerging state laws are beginning to take this approach, but more consistent federal leadership is needed.
Are data practices accessible, not just technically disclosed?
Especially in aging populations, accessibility is not just about font size, it’s about cognitive load, clarity of language, and decision-making support. Tools should offer layered notices, explain settings in plain language, and support revisiting choices as health or relationships change. Future legislation could require transparency standards tailored to vulnerable populations and caregiving scenarios.
Does the technology reinforce autonomy and dignity?
The test for responsible AgeTech is not just whether it works, but whether it respects. Does the tool allow older adults to make choices about their data, even when care is shared or delegated? Can those preferences evolve over time? Does it reinforce the user’s role as the central decision-maker, or subtly replace their agency with automation?
If a product uses or integrates AI, is it clearly indicated if and how data is used for AI?
AI is powering an increasing share of AgeTech’s functionality—but many tools don’t disclose whether data is used to train algorithms, personalize recommendations, or drive automated decisions. Privacy professionals should ask: Is AI use clearly labeled and explained to users? Are there options to opt out of certain AI-driven features? Is sensitive data (e.g., voice, movement, mood) being reused for model improvement or inference? In a rapidly advancing field, transparency is essential for building trustworthy AI.
A Legislative and Technological Path Forward
Privacy professionals are well-positioned to guide both product development and policy advocacy. As AgeTech becomes more central to how we deliver and experience care, the goal should not be to retrofit consumer tools into healthcare settings without safeguards. Instead, we need to modernize privacy frameworks to reflect the reality that sensitive, life-impacting technologies now exist outside the clinic.
This will require:
Consistent legislation that protects sensitive data regardless of who collects it;
Design standards that account for caregiving dynamics and decision-making capacity;
Craft AI frameworks in collaboration with stakeholders that foster transparency and safety;
Infrastructure for shared access and evolving consent, not just checkbox compliance.
The future of aging with dignity will be shaped by whether we can build privacy into the systems that support it. That means moving beyond consent and toward real protections, at the policy level, in the technology stack, and in everyday relationships that make care possible.
Nature of Data in Pre-Trained Large Language Models
The following is a guest post to the FPF blog by Yeong Zee Kin, the Chief Executive of the Singapore Academy of Law and FPF Senior Fellow. The guest blog reflects the opinion of the author only. Guest blog posts do not necessarily reflect the views of FPF.
The phenomenon of memorisation has fomented significant debate over whether Large Language Models (LLM) store copies of the data that they are trained on.1 In copyright circles, this has led to lawsuits such as the one by the New York Times against OpenAI that alleges that ChatGPT will reproduce NYT articles nearly verbatim.2 While in the privacy space, much ink has also been spilt over the question whether LLMs store personal data.
This blog post commences with an overview of what happens to data that is processed during LLM training3: first, how data is tokenised, and second, how the model learns and embeds contextual information within the neural network. Next, it discusses how LLMs store data and contextual information differently from classical information storage and retrieval systems, and examines the legal implications that arise from this. Thereafter, it attempts to demystify the phenomenon of memorisation, to gain a better understanding of why partial regurgitation occurs. This blog post concludes with some suggestions on how LLMs can be used in AI systems for fluency, while highlighting the importance of providing grounding and the safeguards that can be considered when personal data is processed.
While this is not a technical paper, it aims to be sufficiently technical so as to provide an accurate description of the relevant internal components of LLMs and an explanation of how model training changes them. By demystifying how data is stored and processed by LLMs, this blog post aims to provide guidance on where technical measures can be most effectively applied in order to address personal data protection risks.
What are the components of a Large Language Model?
LLMs are causal language models that are optimised for predicting the next word based on previous words.4 An LLM comprises a parameter file, a runtime script and configuration files.5 The LLM’s algorithm resides in the script, which is a relatively small component of the LLM.6 Configuration and parameter files are essentially text files (i.e. data).7 Parameters are the learned weights and biases,8 expressed as numerical values, that are crucial for the model’s prediction: they represent the LLM’s pre-trained state.9 In combination, the parameter file, runtime script and configuration files form a neural network.
There are two essential stages to model training. The first stage is tokenisation. This is when training data is broken down into smaller units (i.e. segmented) and converted into tokens. For now, think of each token as representing a word (we will discuss subword tokenisation later). Each token is assigned a unique ID. The mapping of each token to its unique ID is stored in a lookup table, which is referred to as the LLM’s vocabulary. The vocabulary is one of the LLM’s configuration files. The vocabulary plays an important role during inference: it is used to encode input text for processing and decode output sequences back into human-readable text (i.e. the generated response).
Figure 1. Sample vocabulary list from GPT-Legal; each token is associated with an ID (the vocabulary size of GPT-Legal is 128,256 tokens).
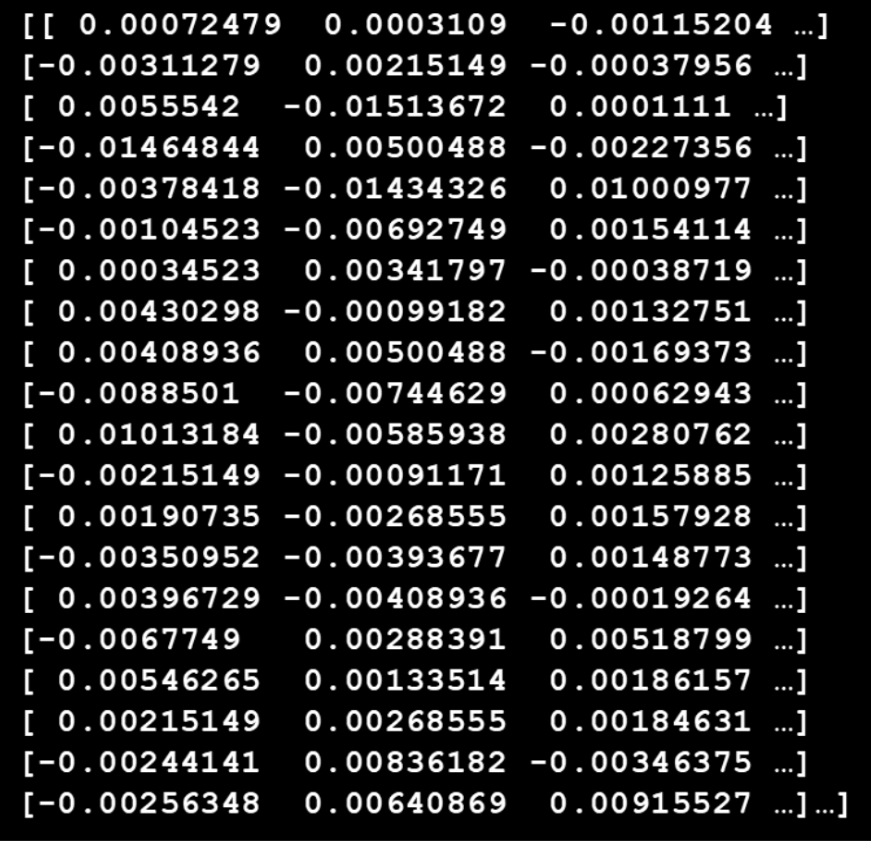
The next stage is embedding. This is a mathematical process that distills contextual information about each token (i.e. word) from the training data and encodes it into a numerical representation known as a vector. A vector is created for each token: this is known as the token vector. During LLM training, the mathematical representations of tokens (their vectors) are refined as the LLM learns from the training data. When LLM training is completed, token vectors are stored in the trained model. The mapping of the unique ID and token vector is stored in the parameter file as an embedding matrix. Token vectors are used by LLMs during inference to create the initial input vector that is fed through the neural network.
Figure 2. Sample embedding matrix from GPT-Legal: each row is one token vector, each value is one dimension (GPT-Legal has 128,256 token vectors, each with 4,096 dimensions)
LLMs are neural networks that may be visualised as layers of nodes with connections between them.10 Adjustments to embeddings also take place in the neural network during LLM training. Model training adjusts the weights and biases of the connections between these nodes. This changes how input vectors are transformed as they pass through the layers of the neural network during inference. This produces an output vector that the LLM uses to compute a probability score for each potential token that may follow, which increases or decreases the probability that one token will follow another. The LLM uses these probability scores to select the next token through various sampling methods.11 This is how LLMs predict the next token when generating responses.
In the following sections, we dive deeper into each of these stages to better understand how data is processed and stored in the LLM.
Stage 1: Tokenisation of training data
During the tokenisation stage, text is converted into tokens. This is done algorithmically by applying the chosen tokenisation technique. There are different methods of tokenisation, each with its benefits and limitations. Depending on the tokenisation method used, each token may represent a word or a subword (i.e. segments of the word).
The method that is commonly used in LLMs is subword tokenisation.12 It provides benefits over word-level tokenisation, such as a smaller vocabulary, which can lead to more efficient training.13 Subword tokenisation analyses the training corpus to identify subword units based on the frequency with which a set of characters occurs. For example, “pseudonymisation” may be broken up into “pseudonym” and “isation”; while, “reacting” may be broken up into “re”, “act” and “ing”. Each subword forms its own token.
Taking this approach results in a smaller vocabulary since common prefixes (e.g. “re”) and suffixes (e.g. “isation” and “ing”) have their own tokens that can be re-used in combination with other stem words (e.g. combining with “mind” to form “remind” and “minding”). This improves efficiency during model training and inference. Subword tokens may also contain white space or punctuation marks. This enables the LLM to learn patterns, such as which subwords are usually prefixes, which are usually suffixes, and how frequently certain words are used at the start or end of a sentence.
Subword tokenisation also enables the LLM to handle out-of-vocabulary (OOV) words. This happens when the LLM is provided with a word during inference that it did not encounter during training. By segmenting the new word into subwords, there is a higher chance that the subwords of the OOV word are found in its vocabulary. Each subword token is assigned a unique ID. The mapping of a token with its unique ID is stored in a lookup table in a configuration file, known as the vocabulary, which is a crucial component of the LLM. It should be noted that this is the only place within the LLM where human-readable text appears. The LLM uses the unique ID of the token in all its processing.
The training data is encoded by replacing subwords with their unique ID before processing.14 This process of converting the original text into a sequence of IDs corresponding to tokens is referred to as tokenisation. During inference, input text is also tokenised for processing. It is only at the decoding stage that human-readable words are formed when the output sequence is decoded by replacing token IDs with the matching subwords in order to generate a human-readable response.
Stage 2: Embedding contextual information
Complex contextual information can be reflected as patterns in high-dimensional vectors. The greater the complexity, the higher the number of features that are needed. These are reflected as parameters of the high dimension vectors. Contrariwise, low dimension vectors contain fewer features and have lower representational capacity.
The embedding stage of LLM training captures the complexities of semantics and syntax as high dimension vectors. The semantic meaning of words, phrases and sentences and the syntactic rules of grammar and sentence structure are converted into numbers. These are reflected as values in a string of parameters that form part of the vector. In this way, the semantic meaning of words and relevant syntactic rules are embedded in the vector: i.e. embeddings.
During LLM training, a token vector is created for each token. The token vector is adjusted to reflect the contextual information about the token as the LLM learns from the training corpus. With each iteration of LLM training, the LLM learns about the relationships of the token, e.g. where it appears and how it relates to the tokens before and after. In order to embed all this contextual information, the token vector has a large number of parameters, i.e. it is a high dimension vector. At the end of LLM training, the token vector is fixed and stored in the pre-trained model. Specifically, the mapping of unique ID and token vector is stored as an embedding matrix in the parameter file.
Model training also embeds contextual information in the layers of the neural network by adjusting the connections between nodes. As the LLM learns from the training corpus during model training, the weights of connections between nodes are modified. These adjustments encode patterns from the training corpus that reflect the semantic meaning of words and the syntactic rules governing their usage.15 Training may also increase or decrease the biases of nodes. Adjustments to model weights and bias affect how input vectors are transformed as they pass through the layers of the neural network. These are reflected in the model’s parameters. Thus, contextual information is also embedded in the layers of the neural network during LLM training. Contextual embeddings form the deeper layers of the neural network.
Contextual embeddings increase or decrease the likelihood that one token will follow another when the LLM is generating a response. During inference, the LLM converts the input text into tokens and looks up the corresponding token vector from its embedding matrix. The model also generates contextual representations that capture how the token relates to other tokens in the sequence. Next, the LLM creates an input vector by combining the static token vector and the contextual vector. As input vectors pass through the neural network, they are transformed by the contextual embeddings in its deeper layers. Output vectors are used by the LLM to compute probability scores for the tokens, which reflect the likelihood that one subword (i.e. token) will follow another. LLMs generate responses using the computed probability scores. For instance, based on these probabilities, it is more likely that the subword that follows “re” is going to be “mind” or “turn” (since “remind” and “return” are common words), less likely to be “purpose” (unless the training dataset contains significant technical documents where “repurpose” is used); and extremely unlikely to be “step” (since “restep” is not a recognised word).
Thus, LLMs capture the probabilistic relationships between tokens based on patterns in the training data and as influenced by training hyperparameters. LLMs do not store the entire phrase or textual string that was processed during the training phase in the same way that this would be stored in a spreadsheet, database or document repository. While LLMs do not store specific phrases or strings, they are able to generalise and create new combinations based on the patterns they have learnt from the training corpus.
2. Do LLMs store personal data?
Personal data is information about an individual who can be identified or is identifiable from the information on its own (i.e. direct) or in combination with other accessible information (i.e. indirect).16 From this definition, several pertinent characteristics of personal data may be identified. First, personal data is information in the sense that it is a collection of several datapoints. Second, that collection must be associated with an individual. Third, that individual must be identifiable from the collection of datapoints alone or in combination with other accessible information. This section examines whether data that is stored in LLMs retain these qualities.
An LLM does not store personal data in the way that a spreadsheet, database or document repository stores personal data. Billing and shipping information about a customer may be stored as a row in a spreadsheet; the employment details, leave records, and performance records of an employee may be stored as records in the tables of a relational database; and the detailed curriculum vitae of prospective, current and past employees may be contained in separate documents stored in a document repository. In these information storage and retrieval systems, personal data is stored intact and its association with the individual is preserved: the record may also be retrieved in its entirety or partially. In other words, each collection of datapoints about an individual is stored as a separate record; and if the same datapoint is common to multiple records, it appears in each of those records.17
Additionally, information storage and retrieval systems are designed to allow structured queries to select and retrieve specific records, either partially or in its entirety. The integrity of storage and retrieval underpins data protection obligations such as accuracy and data security (to prevent unauthorised alteration or deletion), and data subject rights such as correction and erasure.
For the purpose of this discussion, imagine that the training dataset comprises billing and shipping records that contain names, addresses and contact information such as email addresses and telephone numbers. During training, subword tokens are created from names in the training corpus. These may be used in combination to form names and may also be used to form email addresses (since many people use a variation of their names for their email address) and possibly even street names (since names are often named after famous individuals). The LLM is able to generate billing and shipping information that conform to the expected patterns, but the information will likely be incorrect or fictitious. This explains the phenomenon of hallucinations.
During LLM training, personal data is segmented into subwords during tokenisation. This adaptation or alteration of personal data amounts to processing, which is why a legal basis must be identified for model training. The focus of this discussion is the nature of the tokens and embeddings that are stored within the LLM after model training: are they still in the nature of personal data? The first observation that may be made is that many words that make up names (or other personal information) may be segmented into subwords. For example, “Edward” may not be stored in the vocabulary as is but segmented into the subwords “ed” and “ward”. Both these subwords can be used during decoding to form other words, such as “edit” and “forward”. This example shows how a word that started as part of a name (i.e. personal data), after segmentation, produces subwords that can be reused to form other types of words (some of which may be personal data, some of which may not be personal data).
Next, while the vocabulary may contain words that correspond to names or other types of identifiers, the way they are stored in the lookup table as discrete tokens removes the quality of identification from the word. A lookup table is essentially that: a table. It may be sorted by alphanumeric or chronological order (e.g. recent entries are appended to the end of the table). The vocabulary stores datapoints but not the association between datapoints that enables them to form a collection which can relate to an identifiable individual. By way of illustration, having the word “Coleman” in the vocabulary as a token is neither here nor there, since it could equally be the name of Hong Kong’s highest-ranked male tennis player (Coleman Wong) or the street that the Singapore Academy of Law is located (Coleman Street). The vocabulary does not store any association of this word to either Coleman Wong (as part of his name) or to the Chief Executive of the Singapore Academy of Law (as part of his office address).
Furthermore, subword tokenisation enables a token to be used in multiple combinations during inference. Keeping with this illustration, the token “Coleman” may be used in combination with either “Wong” or “Street” when the LLM is generating a response. The LLM does not store “Coleman Wong” as a name or “Coleman Street” as a street name. The association of datapoints to form a collection is not stored. What the LLM stores are learned patterns about how words and phrases typically appear together, based on what it observed in the training data. Hence, if there are many persons named “Coleman” in the training dataset but with different surnames, and no one else whose address is “Coleman Street”, then the LLM is likely to predict a different word after “Coleman” during inference.
Thus, LLMs do not store personal data in the same manner as traditional information storage and retrieval systems; more importantly, they are not designed to enable query and retrieval of personal data. To be clear, personal data in the training corpus is processed during tokenisation. Hence, a legal basis must be identified for model training. However, model training does not learn the associations of datapoints inter se nor the collection of datapoints with an identifiable individual, such that the data that is ultimately stored in the LLM loses the quality of personal data.18
3. What about memorisation?
A discussion of how LLMs store and reproduce data is incomplete without a discussion of the phenomenon of memorisation. This is a characteristic of LLMs that reflects the patterns of words that are found in sufficiently large quantities in the training corpus. When certain combination of words or phrases appear consistently and frequently in the training corpus, the probability of predicting that combination of words or phrases increases.
Memorisation in LLMs is closely related to two key machine learning concepts: bias and overfitting. Bias occurs when training data overrepresents certain patterns, causing models to develop a tendency toward reproducing those specific sequences. Overfitting occurs when a model learns training examples too precisely, including noise and specific details, rather than learning generalisable patterns. Both phenomena exacerbate memorisation of training data, particularly personal information that appears frequently in the dataset. For example, Lee Kuan Yew is Singapore’s first prime minister post-Independence with significant global influence; he lived at 38 Oxley Road. LLMs trained on a corpus of data from the Internet would have learnt this. Hence, ChatGPT is able to produce a response (without searching the Web) about who he is and where he lived. It is able to reproduce (as opposed to retrieve) personal data about him because they appeared in the training corpus in a significant volume. Because this sequence of words appeared frequently – and often – in the training corpus, when the LLM is given the sequence of words “Lee Kuan”, the probability of predicting “Yew” is significantly higher than any other word; and in the context of name and address of Singapore’s first prime minister, the probability of predicting Lee Kuan Yew and 38 Oxley Road is significantly higher than others.
This explains the phenomenon of memorisation. Memorisation occurs when the LLM learns frequent patterns and reproduces closely related datapoints. It should be highlighted that this reproduction is probabilistic. This is not the same as query and retrieval of data stored as records in deterministic information systems.
The first observation to be made is that whilst this is acceptable for famous figures, the same cannot be said for private individuals. Knowing that this phenomenon reflects the training corpus, the obvious thing to avoid is the use of personal data for training of LLMs. This exhortation applies equally to developers of pre-trained LLMs and deployers who may fine-tune LLMs or engage in other forms of post-training, such as reinforcement learning. There are ample good practices for this. Techniques may be applied on the training corpus before model training to remove, reduce or hide personal data: e.g. pseudonymisation (to de-identify individuals in the training corpus), data minimisation (to exclude unnecessary personal data) and differential privacy (adding random noise to obfuscate personal data). When inclusion of personal data in the training corpus is unavoidable, there are mitigatory techniques that can be applied to the trained model.
One such example is machine unlearning, a technique currently under active research and development, that has the potential of removing the influence of specific data points from the trained model. This technique may be applied to reduce the risk of reproducing personal data.
Another observation that may be made is that the reproduction of personal data is not verbatim but paraphrased, hence it is also referred to as partial regurgitation. This underscores the fact that the LLM does not store the associations between datapoints necessary to make them a collection of information about an individual. Even if personal data is reproduced, it is because of the high probability scores for that combination of words, and not the output of a query and retrieval function. Paraphrasing may introduce distortions or inaccuracies when reproducing personal data, such as variations in job titles or appointments. Reproduction is also inconsistent and oftentimes incomplete.
Unsurprising, since the predictions are probabilistic after all.
Finally, it bears reiterating that personal data is not stored as is but segmented into subwords, and reproduction of personal data is probabilistic, with no absolute guarantee that a collection of datapoints about an individual will always be reproduced completely or accurately. Thus, reproduction is not the same as retrieval. Parenthetically, it may also be reasoned that if the tokens and embeddings do not possess the quality of personal data, their combination during inference is processing of data, but just not the processing of personal data. Be that as it may, the risk of reproducing personal data – however, incomplete and inaccurate – can and must still be addressed. Technical measures such as output filters can be implemented as part of the AI system. These are directed at the responses generated by the model and not the model itself.
4. How should we use LLMs to process personal data?
LLMs are not designed or intended to store and retrieve personal data in the same way that traditional information storage and retrieval systems are; but they can be used to process personal data. In AI systems, LLMs provide fluency during the generation of responses. LLMs can incorporate personal data in their responses when personal data is provided, e.g., personal data provided as part of user prompts, or when user prompts cause the LLM to reproduce personal data as part of the generated response.
When LLMs are provided with user prompts that include reference documents that provide grounding for the generated response, the documents may also contain personal data. For example, a prompt to generate a curriculum vitae (CV) in a certain format may contain a copy of an outdated resume, a link to a more recent online bio and a template the LLM is to follow when generating the CV. The LLM can be constrained by well-written prompts to generate an updated CV using the personal information provided and formatted in accordance with the template. In this example, the personal data that the LLM uses will likely be from the sources that have been provided by the user and not from the LLM’s vocabulary.
Further, the LLM will paraphrase the information in the CV that it generates. The randomness of the predicted text is controlled by adjusting the temperature of the LLM. A higher temperature setting will increase the chance that a lower probability token will be selected as the prediction, thereby increasing the creativity (or randomness) of the generated response. Even at its lowest temperature setting, the LLM may introduce mistakes by paraphrasing job titles and appointments or combining information from different work experiences. These errors occur because the LLM generates text based on learned probabilities rather than factual accuracy. For this reason, it is important to vet and correct generated responses, even if proper grounding has been provided.
A more systematic way of providing grounding is through Retrieval Augmented Generation (RAG) whereby the LLM is deployed in an AI system that includes a trusted source, such as a knowledge management repository. When a query is provided, it is processed by the AI system’s embedding model which converts the entire query into an embedding vector that captures its semantic meaning. This embedding vector is used to conduct a semantic search. This works by identifying embeddings in the vector database (i.e. a database containing document embeddings precomputed from the trusted source) that have the closest proximity (e.g. via Euclidean or cosine distance).19 These distance metrics measure how similar the semantic meanings are. Embeddings that are close together (e.g. nearest neighbour) are said to be semantically similar.20 Semantically similar passages are retrieved from the repository and appended to the prompt that is sent to the LLM for the generation of a response. The AI system may generate multiple responses and select the most relevant one based on either semantic similarity to the query or in accordance with a re-ranking mechanism (e.g. heuristics to improve alignment with intended task).
5. Concluding remarks
LLMs are not designed to store and retrieve information (including personal data). From the foregoing discussion, it may be said that LLMs do not store personal data in the same manner as information storage and retrieval systems. Data stored in the LLM’s vocabulary do not retain the relationships necessary for the retrieval of personal data completely or accurately. The contextual information embedded in the token vectors and neural network reflects patterns in the training corpus. Given how tokens are stored and re-used, the contextual embeddings are not intended to provide the ability to store the relationships between datapoints such that the collection of datapoints is able to describe an identifiable individual.
By acquiring a better understanding of how LLMs store and process data, we are able to design better trust and safety guardrails in the AI systems that they are deployed in. LLMs play an important role in providing fluency during inference, but they are not intended to perform query and retrieval functions. These functions are performed by other components of the AI system, such as the vector database or knowledge management repository in a RAG implementation.
Knowing this, we can focus our attention on those areas that are most efficacious in preventing the unintended reproduction of personal data in generated responses. During model development, steps may be taken to address the risk of the reproduction of personal data. These are steps for developers who undertake post-training, such as fine tuning and reinforcement learning.
(a) First, technical measures may be applied to the training corpus to remove, minimise, or obfuscate personal data. This reduces the risk of the LLM memorising personal data.
(b) Second, new techniques like model unlearning may be applied to reduce the influence of specific data points when the trained model generates a response.
When deploying LLMs in AI systems, steps may also be taken to protect personal data. The measures are very dependent on intended use cases of the AI system and the assessed risks. Crucially, these are measures that are within the ken of most deployers of LLMs (by contrast, a very small number of deployers will have the technical wherewithal to modify LLMs directly through post-training).
(a) First, remove or reduce personal data from trusted sources if personal data is unnecessary for the intended use case. Good data privacy practices such as pseudonymisation and data minimisation should be observed.
(b) Second, if personal data is necessary, store and retrieve them from trusted sources. Use information storage and retrieval systems that are designed to preserve the confidentiality, integrity and accuracy of stored information. Personal data from trusted sources can thus be provided as grounding for prompts to the LLM.
(c) Third, consider implementing data loss prevention measures in the AI system. For example, prompt filtering reduces the risk of including unauthorised personal data in user prompts. Likewise, output filtering reduces the risk of unintended reproduction of personal data in responses generated by the AI system.
Taking a holistic approach enables deployers to introduce appropriate levels of safeguards to reduce the risks of unintended reproduction of personal data.21
Memorisation is often also known as partial regurgitation, which does not require verbatim reproduction; regurgitation, on the other hand, refers to the phenomenon of LLMs reproducing verbatim excerpts of text from their training data. ↩︎
The Times Sues OpenAI and Microsoft Over A.I. Use of Copyrighted Work (27 Dec 2023) New York Times; see also, Audrey Hope “NYT v. OpenAI: The Times’s About-Face” (10 April 2024) Harvard Law Review. ↩︎
This paper deals with the processing of text for training LLMs. It does not deal with other types of foundational models, such as multi-model models that can handle text as well as images and audio. ↩︎
LLM model packages contain different components depending on their intended use. Inference models like ChatGPT are optimized for real-time conversation and typically share only the trained weights, tokenizer, and basic configuration files—while keeping proprietary training data, fine-tuning processes, system prompts, and foundation models private. In contrast, open source research models like LLaMA 2 often include comprehensive documentation about training datasets, evaluation metrics, reproducibility details, complete model weights, architecture specifications, and may release their foundation models for further development, though the raw training data itself is rarely distributed due to size and licensing constraints. See, e.g., https://huggingface.co/docs/hub/en/model-cards (accessed 26 June 2025). ↩︎
Configuration files are usually stored as readable text files, while parameter files are stored in compressed binary formats to save space and improve processing speed. ↩︎
An LLM that is ready for developers to use for inference is referred to as pre-trained. Developers may deploy the pre-trained LLM as is, or they may undertake further training using their private datasets. An example of such post-training is fine-tuning. ↩︎
LLMs are made up of the parameter file, runtime script and configuration files which together form a neural network: supra, fn 5 and the discussion in the accompanying main text. ↩︎
While it could pick the token with the highest probability score, this would produce repetitive, deterministic outputs. Instead, modern LLMs typically use techniques like temperature scaling or top-p sampling to introduce controlled randomness, resulting in more diverse and natural responses. ↩︎
Yekun Chai, et al, “Tokenization Falling Short: On Subword Robustness in Large Language Models” arXiv:2406.11687, section 2.1. ↩︎
Word-level tokenisation results in a large vocabulary as every word stemming from a root word is treated as a separate word (e.g. consider, considering, consideration). It also has difficulties handling languages that do not use white spaces to establish word boundaries (e.g. Chinese, Korean, Japanese) or languages that use compound words (e.g. German). ↩︎
WordPiece and Byte Pair Encoding are two common techniques used for subword tokenisation. ↩︎
To be clear, the LLM learns relationships and not explicit semantics or syntax. ↩︎
Definition of personal data in Singapore’s Personal Data Protection Act 2012, s 2 and UK GDPR, s 4(1). ↩︎
Depending on the information storage and retrieval system used, common data points could be stored as multiple copies (eg XML database) or in a code list (eg, spreadsheet or relational database). ↩︎
Note from the editor: This statement should be read primarily within the framework of Singapore’s Personal Data Protection Act. ↩︎
Masked language models (eg, BERT) are used for this, as these models are optimised to capture the semantic meaning of words and sentences better (but not textual generation). Masked language models enable semantic searches. ↩︎
The choice of distance metric can affect the results of the search. ↩︎
This paper benefited from reviewers who commented on earlier drafts. I wish to thank Pavandip Singh Wasan, Prof Lam Kwok Yan, Dr Ong Chen Hui and Rob van Eijk for their technical insight and very instructive comments; and Ms Chua Ying Hong, Jeffrey Lim and Dr Gabriela Zanfir-Fortuna for their very helpful suggestions. ↩︎
Malaysia Charts Its Digital Course: A Guide to the New Frameworks for Data Protection and AI Ethics
The digital landscape in Malaysia is undergoing a significant transformation. With major amendments to its Personal Data Protection Act (PDPA) taking effect in June 2025, the country is decisively updating its data protection standards to meet the demands of the global digital economy. This modernization effort is complemented by a forward-looking approach to artificial intelligence (AI), marked by the introduction of the National Guidelines on AI Governance & Ethics in September 2024. Together, these initiatives represent a robust attempt to build a trusted and innovative digital ecosystem.
This post will unpack these landmark initiatives. First, we will examine the key amendments to Malaysia’s PDPA, focusing on the new obligations for businesses and how they compare with the European Union (EU)’s General Data Protection Regulation (GDPR) and other regional laws. We will then delve into the National AI Ethics Guidelines, analyzing its core principles and its place within the Association of Southeast Asian Nations (ASEAN) AI governance landscape. By exploring both, it becomes visible that strong data protection serves as a critical foundation for trustworthy AI, a central theme in Malaysia’s digital strategy. Key takeaways include:
A shift towards global standards: The amendments aim to better align the PDPA with international frameworks like the EU’s GDPR, particularly through new requirements for mandatory data breach notification, the right to data portability, and the appointment of a Data Protection Officer (DPO).
A more flexible cross-border data transfer regime: The amendments replace the PDPA’s restrictive former whitelisting data transfers approach with a more flexible cross-border data transfer regime
Increased responsibilities and penalties: Businesses acting as data processors now face direct security obligations, while maximum fines for non-compliance have more than tripled to RM 1,000,000 (approximately US$235,000).
A flexible, pro-innovation approach to AI: Malaysia has opted for a voluntary, non-binding set of AI Ethics Guidelines that are closely aligned with the ASEAN Guide on AI Governance and Ethics and other international principles. The guidelines provide distinct recommendations for different stakeholders, including developers, policymakers, and end-users.
Forward-looking regulatory foresight: Ongoing consultations on Data Protection Impact Assessments (DPIAs), Privacy-by-Design, and automated decision-making show that Malaysia is proactively addressing future technological challenges.
A. Personal Data Protection (Amendment) Act 2024
1. Background
Malaysia was the first ASEAN Member State to enact comprehensive data protection legislation. Its PDPA, which was enacted in June 2010 and came into force in November 2013, set a precedent in the region.
However, for nearly a decade, the PDPA remained largely unchanged. Recognizing the need to keep up with rapid technological advancements and evolving global privacy standards (such as the 2016 enactment of the GDPR), then-Minister for Communications and Multimedia (now Digital Minister) Gobind Singh Deo revealed plans to review the PDPA in October 2018.
In February 2020, Malaysia’s Personal Data Protection Department (PDPD) took the first step by issuing a consultation paper proposing to amend the PDPA in 22 areas. Due to delays from the COVID-19 pandemic and subsequent changes in the Malaysian government, a draft bill was only finalized in August 2022, narrowing the focus to five key amendments:
Requiring the appointment of a DPO.
Introducing mandatory data breach notification requirements.
Extending the Security Principle to data processors.
Introducing a right to data portability.
Revising the PDPA’s cross-border data transfer regime.
The resulting Personal Data Protection (Amendment) Act 2024 (Amendment Act) was passed by both houses of Malaysia’s Parliament in July 2024 and was enacted in October 2024. The amendments came into effect in stages:
Phase 1 (January 2025) focused on administrative changes.
Phase 2 (April 2025) introduced the term “data controller,” included “biometric data” under sensitive personal data, and added new cross-border data transfer rules.
Phase 3 (June 2025) introduced the new DPO requirements, mandatory data breach notifications, and data portability rights.
2. The amendments align the PDPA more closely with both international and regional data protection standards
The Amendment Act brings the PDPA closer to other influential global frameworks, such as the GDPR. This carries similarities with regulatory efforts by some other ASEAN Member States, including the enactment of GDPR-like laws in Thailand (2019), Indonesia (2022) and to a lesser extent, Vietnam (2023).
It also follows a broader trend of initiatives in the Asia-Pacific (APAC) region to bring longer-established data protection laws closer to international norms. These include extensive amendments to data protection laws in New Zealand (2020), Singapore (2021), and Australia (2024), as well as an ongoing review of Hong Kong’s law, which began in 2020.
One example of how the Amendment Act brings the PDPA closer to globally recognized norms is the replacement of the term “data user” with “data controller.” While this update is primarily cosmetic and does not change the entity’s substantive obligations, it aligns the PDPA’s terminology more closely with that of the GDPR and other similar laws.
The following subsections discuss in detail the key amendments introduced by the Amendment Act, illustrating their implications and alignment with both regional and international standards.
2.1. Like the GDPR, the amendments define biometric data as sensitive
The Amendment Act classifies “biometric data” as “sensitive personal data.” The Amendment Act’s definition of “biometric data” is, in fact, potentially broader than its counterpart in the GDPR, as the former does not require that the data must allow or confirm the unique identification of that person.
Organizations processing biometric data may need to revise their compliance practices to comply with the more stringent requirements for processing sensitive personal data (such as obtaining express consent prior to processing), unless one of a narrow list of exceptions applies. However, this is unlikely to pose major challenges to organizations whose compliance strategies take the GDPR as the starting point.
2.2. Like other ASEAN data protection laws, the amendments introduce a new requirement to appoint a DPO
The Amendment Act requires data controllers to appoint a DPO, and register the appointment within 21 days of the appointment. If the DPO changes, controllers must also update registration information within 14 days of the change.
Both controllers and processors must also publish the business contact information of their DPO on official websites, in privacy notices, and in security policies and guidelines. This should include a dedicated official business email account, separate from the DPO’s personal and regular business email.
To provide guidance on this new requirement, the PDPD published a Guideline and Circular on the appointment of DPOs (DPO Guideline) in May 2025 that clarifies and in some cases substantially augments the DPO requirements under the amended PDPA. The DPO Guideline introduces a quantitative threshold for appointing a DPO. Controllers and processors are only required to appoint a DPO if they:
Process:
the personal data of more than 20,000 data subjects; or
sensitive personal data (including financial information) of more than 10,000 data subjects; or
Engage in activities requiring “regular and systemic monitoring of personal data.” While the DPO Guideline does not define this phrase, it provides several examples, such as online behavioral advertising, algorithmic recommendations on retail sites, operating telecom networks, and monitoring data from wearables or CCTV.
The DPO Guideline also outlines DPOs’ duties. These duties include serving as the primary point of contact for authorities and data subjects, providing compliance advice, conducting impact assessments, and managing data breach incidents. DPOs do not need to be resident in Malaysia but must be easily contactable and proficient in English and the national language (i.e., Bahasa Melayu). A single DPO may be appointed to serve multiple controllers or processors, provided that the DPO is given sufficient resources and is contactable by the organization, the Commissioner, and data subjects.
The DPO Guideline also prescribes skill requirements. A DPO must have knowledge of data protection law and technology, an understanding of the business’s data processing operations, and the ability to promote a data protection culture with integrity. The required skill level depends on the complexity, scale, sensitivity and level of protection required for the data being processed. The amendment aligns Malaysia’s PDPA more closely with data protection laws in the Philippines and Singapore (in this regard) than with the GDPR. Specifically, the Philippines and Singapore both require organizations to appoint at least one DPO. Conversely, Indonesia and Thailand adopt the GDPR’s approach in this regard, requiring DPO appointments only for: (1) public authorities; (2) organizations conducting large-scale systematic monitoring, and (3) those processing sensitive data.
2.3. The amendments significantly increase penalties for PDPA breaches but do not introduce revenue-based fines
The Amendment Act allows the Personal Data Protection Commissioner (Commissioner) to impose:
a fine of up to RM 1,000,000 (approximately US$235,000) – over three times the previous maximum fine; and/or
imprisonment for up to three years – a 50% increase over the previous maximum term.
Notably, the increase in the PDPA’s penalty structure was not one of the proposals raised in the PDPD’s initial consultation paper released in 2020. Nevertheless, these enhanced penalties are consistent with (albeit still lower than) those seen in other ASEAN data protection laws that have been enacted or amended since the GDPR came into effect. These amendments also follow the GDPR’s example in increasing the maximum penalty to either a substantial fine (under the GDPR, 20,000,000 EUR) or a percentage of the organization’s revenue (under the GDPR, up to 4% of its total worldwide annual turnover of the preceding financial year). In ASEAN, data protection laws that have been similarly drafted include:
Indonesia, which provides for a maximum fine of up to 2% of an organization’s annual revenue, and a maximum imprisonment term of up to 6 years.
Vietnam, which provides for a maximum administrative fine of up to 5% of the violator’s total revenue in Vietnam, and a maximum imprisonment term of or 7 years.
Singapore, which in 2022 increased the maximum fine to the greater of either: (1) S$1 million; or (2) 10% of the organization’s annual turnover in Singapore (if that organization’s annual local turnover exceeds S$10 million).
2.4. The amendments extend security obligations to data processors
Though the PDPA has always drawn a distinction between controllers (previously termed “data users”) and processors, prior to the 2024 amendments, it did not subject data processors to the PDPA’s Security Principle. This Principle requires organizations to take practical steps to protect the personal data from any loss, misuse, modification, unauthorized or accidental access or disclosure, alteration or destruction.
As amended, the PDPA now requires data processors to comply with the Security Principle and provide sufficient guarantees to data controllers that data processors have implemented technical and organizational security measures to ensure compliance with the Principle.
This amendment aligns the PDPA with the GDPR and the majority of other ASEAN data protection laws, which all impose security obligations on data processors.
Following the amendments, the PDPD began consulting on new guidelines outlining security controls to comply with the Security Principle. However, to date, these guidelines do not appear to have been finalized.
2.5. The amendments establish a significant new data portability right for data subjects in Malaysia
The Amendment Act introduces a new Section 43A into the PDPA, which provides data subjects with the right to request that a data controller transmit their personal data to another controller of their choice. The introduction of this data portability right makes Malaysia the fourth ASEAN jurisdiction to introduce such a right in their data protection law (after the Philippines, Singapore and Thailand).
However, this right is not absolute: it is “subject to technical feasibility and data format compatibility.” The PDPD has indicated that it regards this caveat as an exception that recognizes the practical challenges that controllers may face in transferring data between different systems.
However, this apparent exception risks undermining the right if interpreted too broadly. It should be noted that this flexibility in Malaysia’s data portability regime stands in contrast with the regime under the GDPR, which requires controllers to provide the data in a “structured, commonly used, and machine-readable format.”
To implement this new right, the PDPD has initiated consultations on proposals for subordinate regulations and a new set of guidelines. Key proposals under consideration focus on establishing technical standards, defining the scope of applicable data through “whitelists,” setting timelines for compliance, and determining rules for allowable fees.
The introduction of a data portability right into Malaysia’s PDPA carries potentially significant implications for individuals and businesses in Malaysia. For data subjects, this right enhances control over personal data in an increasingly digital environment. From a market perspective, it has the potential to foster competition and innovation by making it easier for individuals to switch service providers. While there are “success stories” of implementation of data portability rights in select sectors in jurisdictions like the United Kingdom and Australia, challenges remain in rolling out these rights across various sectors of the economy. In the APAC region, both Australia and South Korea have faced significant hurdles in this regard.
As Malaysia embarks on implementing data portability, it may encounter challenges due to the broad scope of its data portability rights (which are at present not limited to specific sectors). This means that businesses in all industries may need to develop effective processes and technologies to manage portability requests securely – a requirement that could lead to increased costs, especially for smaller enterprises.
2.6. The amendments introduce notifiable data breach requirements to the PDPA
Though the PDPA has imposed positive security obligations on controllers since its enactment, it notably lacked requirements for controllers to notify authorities or affected individuals of data breaches. This legislative void has been addressed through the 2024 amendments and the release of the guidelines on data breach notifications (DBN Guideline) in May 2025.
The new Section 12B in the PDPA requires controllers who have reason to believe that a data breach has occurred to notify the PDPD “as soon as practicable” and in any case, within 72 hours. Written reasons must be provided if the notification is not made within the prescribed timeframe.
Additionally, if the breach is likely to result in significant harm to data subjects, controllers must also notify affected data subjects “without unnecessary delay” and no later than 7 days after the initial notification to the PDPD. Failure to comply with the new notification requirements may result in penalties of up to RM 250,000 (approximately US$53,540) and/or up to two years’ imprisonment.
The DBN Guideline clarifies that a breach is likely to result in “significant harm” when there is a risk that the compromised personal data:
May result in physical harm, financial loss, a negative effect on credit records, or damage to or loss of property;
May be misused for illegal purposes;
Consists of sensitive personal data;
Consists of personal data and other information that could enable identity fraud; or
Is of a “significant scale” (i.e., affects more than 1,000 data subjects).
Further, the DBN Guideline also states that controllers should maintain records of data breaches in both physical and electronic formats for at least two years; implement adequate data breach management and response plans; and conduct regular training for employees.
Controllers must also contractually obligate processors to promptly notify them if a data breach occurs and to provide all reasonable assistance with data breach obligations.
These requirements, which are not subject to exceptions, will significantly affect organizations processing personal data in Malaysia. Controllers in particular will need to establish effective processes for detecting, investigating, and reporting data breaches.
Such requirements are already established in most other major ASEAN jurisdictions, including Indonesia, the Philippines, Singapore, Thailand, and Vietnam. While details vary, most jurisdictions require notifications within 72 hours of discovering a breach, with some mandating public disclosure for large-scale incidents.
The PDPA’s provisions on data breach requirements are largely similar to those in the GDPR. In fact, the PDPA’s breach notification provisions are arguably more expansive, as they do not provide an exception (as does the GDPR) for breaches unlikely to result in a risk to the rights and freedoms of natural persons.
2.7. The amendments replace the PDPA’s restrictive former whitelisting data transfers approach with a more flexible cross-border data transfer regime
Prior to the amendments, the PDPA contained a transfer mechanism permitting transfers of personal data to destinations that had been officially whitelisted by a Minister. However, this provision was never implemented, and no jurisdictions were ever whitelisted.
The amendments replaced this with a new provision allowing controllers to transfer personal data to jurisdictions with laws that: (1) are substantially similar to the PDPA; or (2) ensure an equivalent level of protection to the PDPA. This provision shifts responsibility to controllers to evaluate whether the destination jurisdiction meets the above requirements.
In May 2025, the PDPD issued a guideline clarifying the requirements under this provision. Specifically, the controller must conduct a Transfer Impact Assessment (TIA), evaluating the destination jurisdiction’s personal data protection law against a series of prescribed factors. The TIA is valid for three years but must be reviewed if there are amendments to the destination’s personal data protection laws.
Notably, in adopting this new mechanism, Malaysia appears to have moved away from the GDPR centralized adequacy model, while maintaining other transfer mechanisms interoperable with the GDPR. The former “whitelist” mechanism more closely resembled the “adequacy” mechanism in Article 45 of the GDPR, which makes the EU Commission responsible for determining whether a jurisdiction or international organization provides an adequate level of protection and issuing a so-called “adequacy decision.” Malaysia’s new cross-border data transfer provision is more adaptable but in the absence of strong enforcement by the PDPD may potentially be open to abuse as the proposed criteria for the TIA are high-level and could easily be satisfied by any jurisdiction that has a data protection law “on the books.”
Notably, the Guideline also introduces new guidance on other existing transfer mechanisms under the PDPA, such as the conditions for valid consent and determining when transfers are “necessary.” Additionally, the Guideline allows the use of binding corporate rules (BCRs) for intra-group transfers, standard contractual clauses (SCCs) for transfers between unrelated parties, and certifications from recognized bodies as evidence of adequate safeguards in the receiving data controller or processor.
3. Ongoing consultations show Malaysia is preparing for future technological challenges
In March 2025, the PDPD concluded consultations on its DPIA, DPbD, and ADM guidelines. The adoption of these guidelines, though requiring organizations to take on additional responsibilities, reflects Malaysia’s interest in embracing new standards and addressing emerging technological challenges.
3.1 Malaysia is aligning with regional peers by proposing detailed DPIA requirements
While the amended PDPA does not explicitly mandate DPIAs, the responsibility to conduct them has been introduced through the new DPO Guidelines. To clarify this obligation, the PDPD has also started consultations on a detailed DPIA framework. This move brings Malaysia closer to APAC jurisdictions like the Philippines, Singapore, and South Korea, which already provide detailed guidance on conducting DPIAs.
Under the proposals, a DPIA would be required whenever data processing is likely to result in a “high risk” to data subjects. The draft guidelines propose a two-tier approach to assess this risk, considering both quantitative factors (like the number of data subjects) and qualitative ones (such as data sensitivity). Notably, if a DPIA reveals a high overall risk, organizations may be required to notify the Commissioner of the risk(s) identified and provide other information as required. If passed in their current form, these rules would give Malaysia some of the most stringent DPIA requirements in the APAC region as no other major APAC jurisdictions impose such a proactive notification requirement on all types of controllers.
3.2 Malaysia’s proposed DPbD requirement aligns its laws closer to international standards
To further align with international standards like the GDPR, the PDPD is consulting on draft guidelines on implementing a “Data Protection by Design” (DPbD) approach. While the amended PDPA does not explicitly mandate DPbD, this proposed guideline aims to clarify how organizations can proactively embed the PDPA’s existing Personal Data Protection Principles into their operations.
The proposed approach would require integrating data protection measures throughout the entire lifecycle of a processing activity, from initial design to final decommissioning. Adopting such a guideline would mark a significant shift of Malaysia’s data protection regime from reactive to proactive data protection, helping organizations ensure more effective compliance and better protect the rights of data subjects. However, implementing and encouraging a DPbD approach goes beyond providing guidelines on DPbD. Such guidelines should be complemented by training and educational workshops for DPOs and organizations, as well as incentive schemes such as domestic trust-mark certification, to better familiarize organizations with the notion and benefits of DPbD.
3.3 Proposed guidelines anticipate the impacts of AI and machine learning
Looking ahead to the challenges posed by AI, the PDPD recently concluded a consultation on regulating ADM and profiling. Although the PDPA does not specifically touch on ADM and profiling, the PDPD’s consultation demonstrates an intent to follow in the footsteps of several other major jurisdictions, including the EU, UK, South Korea, and China, that have already implemented requirements in this area.
The Public Consultation Paper highlighted (see, for instance, para 1.2) the growing risk of AI and machine learning being used to infer sensitive information from non-sensitive data for high-impact automated decisions, such as credit scoring. To address this, the PDPD is considering issuing a dedicated ADM and Profiling (ADMP) Guideline. The ADMP Guideline would regulate ADMP if “its use results in legal effects concerning the data subject or significantly affects the data subject”, and would provide a data subject with (subject to exceptions): (a) the right to refuse to be subject to a decision based solely on ADMP which produces legal effects concerning the data subjects or significantly affects the data subject; (b) a right to information on the ADMP being undertaken; and (c) a right to request a human review of the ADMP.
As consultation on the ADMP Guideline concluded on 19 May 2025, it will be several more months before the ADMP Guideline is expected to be finalized. Nonetheless, this presents another instance of an APAC data protection regulator acting as a de facto (albeit partial) regulator of AI-augmented decision-making.
B. National Guidelines on AI Governance & Ethics
1. Background
In parallel with the updates to its data protection law, Malaysia has taken strides in AI governance. On 20 September 2024, the Ministry of Science, Technology, and Innovation (MOSTI) released its “National Guidelines on AI Governance & Ethics” (AI Ethics Guidelines, or Guidelines) – a comprehensive voluntary framework for the responsible development and use of AI technologies in Malaysia.
2. At its core, the Guidelines establish seven fundamental principles of AI
The Guidelines were designed for international alignment, explicitly benchmarking their seven core AI principles against a wide range of global standards. Section 4 details this comparison, referencing frameworks from the OECD, UNESCO, the EU, the US, the World Economic Forum, and Japan.
2.1. The Guidelines establish specific roles, responsibilities, and recommended actions for three key stakeholder groups in the AI ecosystem
The Guidelines assign responsibilities across the AI ecosystem.
End users are encouraged to engage responsibly by staying informed and exercising their rights, such as the right to human intervention.
Policymakers in the public and private sectors are tasked with creating governance frameworks that balance innovation with public interest, promoting AI literacy, and facilitating international cooperation.
Entities in the AI value chain (e.g., developers, suppliers) are responsible for ensuring AI systems are ethical and safe by integrating privacy throughout the AI lifecycle, conducting impact assessments, and maintaining transparency.
2.2. The Guidelines introduce consumer protection principles for AI that could be a precursor to regulatory requirements
While the AI Ethics Guidelines are voluntary and primarily aimed at encouraging stakeholders to reflect on key AI governance issues, certain provisions in the Guidelines may offer insight into how the Malaysian Government is considering potential future regulation of AI.
The Guidelines encourage businesses in Malaysia to prioritize transparency by clearly informing consumers about how AI uses their data and makes decisions. The Guidelines also encourage such businesses to provide consumers with rights concerning automated decisions, which are comparable to those in data protection laws such as the GDPR. These include the rights to information and explanation about such decisions, to object and request human intervention, and have one’s data deleted (i.e., a “right to be forgotten”).
Part A.2.3 outlines tentative suggestions for the development of future regulations of AI (whether through existing laws or new regulations), while acknowledging that regulation of AI is at an early stage of development. The suggestions include:
Amending current laws to define “generative AI;”
Establishing mandatory disclosure requirements, quality and accuracy standards, and liability for AI-generated consent;
Strengthening data protection requirements, such as explicit consent for using personal data in AI training, and
Enhancing monitoring and enforcement, including by establishing specialized units in government agencies, and conducting regular audits of AI systems.
3. Malaysia is the latest in a series of APAC jurisdictions that have released voluntary AI ethics and governance frameworks
Other APAC jurisdictions that have released voluntary AI governance guidelines in recent years include Indonesia (December 2023), Singapore (in 2019, 2020, and 2024), Hong Kong (June 2024), and Australia (October 2024).
Malaysia’s AI Ethics Guidelines align with regional trends toward voluntary, principle-based AI governance, yet differ in focus and approach when compared to its neighbours and the broader ASEAN framework. To understand Malaysia’s position within ASEAN, a brief comparison is provided between Malaysia’s Guidelines and: (1) Singapore’s Model AI Governance Framework (Second Edition); (2) Indonesia’s Circular on AI Ethics (Circular), and (2) ASEAN’s AI Guide).
Singapore: In contrast to Malaysia’s broad, stakeholder-focused guidelines, Singapore’s framework is more practical and operational, aimed specifically at organizations deploying AI systems. While both guidelines are voluntary, Malaysia’s seven principles emphasize alignment with international norms, whereas Singapore’s five high-level principles are applied in the context of the AI deployment lifecycle and are meant for direct implementation by organizations deploying AI systems.
Indonesia: Malaysia’s guidelines offer more specific recommendations than Indonesia’s circular, which outlines general principles. While both frameworks are non-binding, Indonesia’s takes a more directive tone and is more directly rooted in existing laws, creating the potential for sanctions for non-compliance. Further, Malaysia’s guidelines explicitly reference international standards, whereas Indonesia’s circular appears to be more domestically focused.
ASEAN: Malaysia’s guidelines appear to be aligned with the two ASEAN-level AI guides. Both guides share core principles and emphasize a voluntary approach. The key difference lies in the level of detail: the ASEAN AI Guide provides more comprehensive operational guidance on topics like internal governance structures, while Malaysia’s framework concentrates on high-level principles.
Malaysia’s recent developments in data protection and AI governance represent a concerted effort to build a modern and trusted digital regulatory framework. The comprehensive amendments to the PDPA bring the nation’s data protection standards into closer alignment with global benchmarks like the GDPR, while the AI Ethics Guidelines establish a foundation for responsible AI innovation nationally. Viewed together, these are not separate initiatives but two pillars of a cohesive national strategy designed to foster a trusted digital ecosystem and position Malaysia as a competitive player in the region.
For businesses operating in Malaysia, these developments have significant and immediate implications. Organizations should aim to move beyond basic compliance and adopt a strategic approach to data governance. Key actions include:
Undertaking a comprehensive review of data protection policies and procedures to align with the enhanced PDPA requirements, particularly concerning data subject rights and breach notifications.
Developing robust and defensible mechanisms for cross-border data transfers under the new assessment-based regime.
Integrating the principles of the voluntary AI Ethics Guidelines into the design, development, and deployment of AI systems to ensure ethical practices and prepare for potential future regulations.
In closing, two observations may be made. First, these developments – especially the amendments to Malaysia’s PDPA – come as Malaysia sits as ASEAN’s Chair in 2025. They come as the country hopes to position itself as a mature leader in digital innovation and governance in the region, and potentially, to provide a boost just as Malaysia is hoping to conclude negotiations on the ASEAN Digital Economy Framework Agreement under its watch this year.
Second, it should be recalled that prior to the Amendment Act, regulatory activity on data protection in Malaysia has been on a low ebb. Additionally, the PDPD has thus far not been highly active in regional and international data protection and digital regulation fora. Nevertheless, with the reconstitution of the Ministry of Communications and Multimedia into the Digital Ministry, and the re-formulation of the PDPD into an independent Commissioner’s Office (as shared by Commissioner Nazri at FPF’s Second Japan Privacy Symposium in Tokyo last year), there is an expectation that more engagement can be expected from Malaysia on data protection and AI regulation in the years to come.
Note: The information provided above should not be considered legal advice. For specific legal guidance, kindly consult a qualified lawyer practicing in Malaysia
Understanding Japan’s AI Promotion Act: An “Innovation-First” Blueprint for AI Regulation
The global landscape of artificial intelligence (AI) is being reshaped not only by rapid technological advancement but also by a worldwide push to establish new regulatory regimes. In a landmark move, on May 28, 2025, Japan’s Parliament approved the “Act on the Promotion of Research and Development and the Utilization of AI-Related Technologies” (人工知能関連技術の研究開発及び活用の推進に関する法律案要綱) (AI Promotion Act, or Act), making Japan the second major economy in the Asia-Pacific (APAC) region to enact comprehensive AI legislation. Most provisions of the Act (except Chapters 3 and 4, and Articles 3 and 4 of its Supplementary Provisions) took effect on June 4, 2025, marking a significant transition from Japan’s soft-law, guideline-based approach to AI governance to a formal legislative framework.
This blog post provides an in-depth analysis of Japan’s AI Promotion Act, its strategic objectives, and unique regulatory philosophy. It further develops on our earlier analysis of the Act (during its draft stage), available exclusively for FPF Members in our FPF Members Portal. The post begins by exploring the Act’s core provisions in detail, before placing the Act in a global context by drawing detailed comparisons between the Act and two other pioneering omnibus AI regulations: (1) the European Union (EU)’s AI Act, and South Korea’s Framework Act on AI Development and Establishment of a Foundation for Trustworthiness (AI Framework Act). This comparative analysis of these three regulations reveals three distinct models for AI governance, creating a complex compliance matrix that companies operating in the APAC region will need to navigate going forward.
Part 1: Key Provisions and Structure of the AI Promotion Act
The AI Promotion Act establishes policy drivers to make Japan the world’s “most AI-friendly country”
The Act’s primary purpose is to establish foundational principles for policies that promote the research, development, and utilization of AI in Japan to foster socio-economic growth.
The Act implements the Japanese government’s ambition, outlined in a 2024 whitepaper, to make Japan the world’s “most AI-friendly country.” The Act is specifically designed to create an environment that encourages investment and experimentation by deliberately avoiding the imposition of stringent rules or penalties that could stifle development.
This initiative is a direct response to low rates of AI adoption and investment in Japan. A summary of the AI Promotion Act from Japan’s Cabinet office highlights that from 2023 to 2024, private AI investment in Japan was a fraction of that seen in other major markets globally (such as the United States, China, and the United Kingdom), with Stanford University’s AI Index Report 2024 putting Japan in 12th place globally for this metric. The Act is, therefore, a strategic intervention intended to reverse these trends by signaling strong government support and creating a predictable, pro-innovation legal environment.
The AI Promotion Act is structured as a “fundamental law” (基本法), establishing high-level principles and national policy direction rather than detailed, prescriptive rules for private actors.
While introducing a basis for binding AI regulation, the Act also builds on Japan’s longstanding “soft law” approach to AI governance, relying on non-binding government guidelines (such as the 2022 “Governance Guidelines for the Implementation of AI Principles” and 2024 “AI Business Operator Guidelines”), multi-stakeholder cooperation, and the promotion of voluntary business initiatives over “hard law” regulation. The Act’s architecture therefore embodies the Japanese Government’s broader philosophy of “agile governance” in digital regulation, which posits that in rapidly evolving fields like AI, rigid, ex-ante regulations are likely to quickly become obsolete and may hinder innovation.
The AI Promotion Act adopts a broad, functional definition of “AI-related technologies.”
The primary goal of the AI Promotion Act (Article 1) is to establish the foundational principles for policies that promote the research, development, and utilization of “AI-related technologies” in Japan. This term refers to technologies that replicate human intellectual capabilities like cognition, inference, and judgment through artificial means, as well as the systems that use them. This non-technical definition appears to be designed for flexibility and longevity. Notably, the law proposes a unique approach to defining the scope of covered AI technologies and does not adopt the OECD definition of an AI system which served as inspiration for that in the EU AI Act.
The Act provides a legal basis for five fundamental principles to guide AI governance in Japan
Under Article 3 of the Act, these principles include:
Promotion: AI should be promoted as a foundational technology for Japan’s economic and social development, with consideration for national security.
Comprehensive advancement: AI promotion should be systematic and interconnected across all stages, from basic research to practical application.
Transparency: Transparency in AI development and use is necessary to prevent misuse and the infringement of citizens’ rights and interests.
International leadership: Japan should actively participate in and lead the formulation of international AI norms and promote international cooperation.
The AI Promotion Act adopts a whole-of-society approach to promoting AI-related technologies
Broadly, the Act assigns high-level responsibilities to five groups of stakeholders:
The National Government bears the primary responsibility for formulating and implementing comprehensive AI policies. It is mandated to use AI to improve its own administrative efficiency, strengthen stakeholder collaboration, and take all necessary legislative and financial measures to promote AI.
Local Governments are responsible for formulating and implementing independent AI policies tailored to their local contexts in cooperation with the national government.
Research and Development (R&D) Institutes are expected to actively engage in AI research, disseminate findings, foster talent, and cooperate with government policies.
Business Operators (defined in the Act as individuals or organizations planning to develop, offer, or incorporate artificial intelligence technologies into their products, services, or business operations) are encouraged to actively utilize AI to improve efficiency and innovate, and to cooperate with government policies.
Citizens are expected to deepen their understanding of AI and cooperate with government policies.
To fulfill its responsibilities, the National Government is mandated to take several Basic Measures, including:
promoting R&D for practical applications;
developing and promoting shared access to essential infrastructure like computing power and datasets;
creating guidelines in line with international standards;
fostering a skilled workforce;
promoting public education and awareness,
monitoring AI trends and analyzing cases of rights infringement, and
promoting international cooperation.
The Act adopts a cooperative approach to governance and enforcement
The Act’s approach to governance and enforcement diverges significantly from overseas legislative frameworks.
The centerpiece of the new governance structure established under the Act is the establishment of a centralized AI Strategy Headquarters within Japan’s Cabinet. Chaired by the Prime Minister and including all other Cabinet ministers as members, this body ensures a whole-of-government, coordinated approach to AI policy.
The AI Strategy Headquarters’ primary mandate is to formulate and drive the implementation of a comprehensive national Basic AI Plan, which will provide more substantive details on the government’s AI strategy.
The AI Promotion Act contains no explicit penalties, financial or otherwise, for non-compliance with its requirements or, more broadly, for misusing AI. Instead, its enforcement power rests on a unique cooperative and reputational model.
A “Duty to Cooperate”: The sole direct obligation imposed on private sector businesses is to “endeavor to cooperate” with measures implemented by the government. This is a non-binding “reasonable efforts” (努力義務) obligation common in Japanese legislation.
“Name and Shame” Enforcement: The government is empowered to gather information, analyze cases of rights infringement, and provide guidance or advice to businesses. Japanese news outlets have reported that in cases of significant infringement, it is likely that the government would have the authority to publicly disclose the names of non-compliant businesses. This “name and shame” mechanism leverages the high premium placed on corporate reputation in Japanese business culture. While it may appear toothless compared to the significant fines provided by laws like the EU’s AI Act, the brand damage from being publicly identified as an irresponsible actor may nevertheless serve as a powerful deterrent within the Japanese industry context.
Part 2: A Tale of Three AI Laws – Comparative Analysis of Japan’s AI Promotion Act, the EU’s AI Act, and South Korea’s AI Framework Act
To fully appreciate Japan’s approach, it is useful to compare it with the other two prominent global AI hard law frameworks, the EU AI Act and South Korea’s Framework AI Act.
The EU AI Act is a comprehensive legal framework for AI systems. Officially published on July 12, 2024, it became effective on August 2, 2024, but it is becoming applicable in multiple stages, beginning in January 2025 and trickling down until 2030. Its primary aim is to regulate AI systems placed on the EU market, balancing innovation with ethical considerations and safety. The Act proposes a risk-based approach whereby a few uses of AI systems are prohibited as they are considered to have unacceptable risk to health, safety and fundamental rights; some AI systems are considered “high-risk” and bear most of compliance obligations for their deployers and providers; while others are either low risk, facing mainly transparency obligations, or they are simply outside of the scope of the regulation. The AI Act also has a separate set of rules applying only to General Purpose AI models, with enhanced obligations linked to those that have “systemic risk.” See here for a Primer on the EU AI Act.
The stated purpose of the AI Framework Act is to protect citizens’ rights and dignity, improve quality of life, and strengthen national competitiveness. The Act aims to promote the AI industry and technology while simultaneously preventing associated risks, reflecting a balancing act between innovation and regulation. For a more detailed analysis of South Korea’s AI Framework Act, you may read FPF’s earlier blog post here.
Like the EU’s AI Act, South Korea’s AI Framework Act adopts a risk-based approach, introducing specific obligations for “high-impact” AI systems utilized in critical sectors such as healthcare, energy, and public services. However, a key difference between the two laws is that South Korea does not include any prohibition of practices or AI systems. It also includes specific provisions for generative AI. Notably, AI systems used solely for national defense or security are expressly excluded from its scope, and most AI systems not classified as “high-impact” are not subject to regulation under the AI Framework Act.
AI Business Operators, encompassing both developers and deployers, are subject to several specific obligations. These include establishing and operating a risk management plan, providing explanations for AI-generated results (within technical limits), implementing user protection measures, and ensuring human oversight for high-impact AI systems. For generative AI, providers are specifically required to notify users that they are interacting with an AI system.
The AI Framework Act establishes a comprehensive governance framework, including a National AI Committee chaired by the President of the country tasked with deliberating on policy, investment, infrastructure, and regulations. The AI Framework Act also establishes other governance institutions, such as the AI Policy Center and AI Safety Research Institute. The Ministry of Science and ICT (MSIT) holds the responsibility for establishing and implementing a Basic AI Plan every three years. The MSIT is also granted significant investigative and enforcement powers, with enforcement measures including corrective orders and fines. The AI Framework Act also includes extraterritorial provisions, extending its reach beyond South Korea.
Commonalities and divergences across jurisdictions
The regulatory philosophies across Japan, South Korea, and the EU present a spectrum of approaches.
Japan: The primary goal of the AI Promotion Act is to drive economic growth. It acknowledges AI as a foundational technology for Japan’s socioeconomic development and seeks to enhance the country’s competitiveness and efficiency through AI. Its regulatory approach minimizes regulatory burdens, rejecting express penalties in favor of governmental guidance and voluntary cooperation
EU: The AI Act is precautionary, and its primary goal is to protect fundamental rights, health, and safety. Functioning primarily as a product safety regulation, it imposes strict and detailed ex-ante compliance obligations with severe penalties.
South Korea: South Korea’s AI Framework Act charts a middle course between promoting innovation to enhance South Korea’s global competitiveness and addressing the potential societal risks posed by the misuse of AI. It, therefore, combines strong promotional measures with targeted, EU-style regulations for “high-impact” AI systems, representing a pragmatic attempt to balance innovation with risk management.
Differences are also evident in scope, risk classification, and enforcement severity. Japan’s AI Promotion Act and South Korea’s AI Framework Act are both foundational laws that allocate responsibilities for AI governance within the government and establish a legal basis for future regulation of AI. However, Japan’s AI Promotion Act does not impose any direct obligations on private actors and does not include a “risk” or “high-impact” classification of AI technologies. By contrast, South Korea’s AI Framework Act imposes a range of obligations on “high-impact” and generative AI, without going so far as to prohibit AI practices. The latter also has specific carve-outs for national defense, similar to how the EU AI Act excludes AI systems for military and national security purposes from its scope.
The EU AI Act has the broadest and most detailed scope, categorizing all AI systems into four risk levels, with strict requirements for high-risk and outright prohibitions for unacceptable risk systems, in addition to specific obligations for General Purpose AI (GPAI) models.
In terms of enforcement powers, Japan’s AI Promotion Law notably lacks any penalties for noncompliance or misuse of AI more broadly. South Korea’s AI Framework Act, by contrast, has enforcement powers, including fines and corrective orders, but its financial penalties are comparatively lower than those in the EU’s AI Act. For instance, the maximum fine under South Korea’s AI Framework Act is set at KRW 30 million (approximately USD 21,000), whereas, under the EU AI Act, fines can range from EUR 7.5 million to EUR 35 million (approximately. USD 7.8 million to USD 36.5 million), or 1% to 7% of the company’s global turnover.
Despite these divergences, there are some commonalities. All three laws establish central governmental bodies (Japan’s AI Strategy Headquarters, South Korea’s National AI Committee, and the EU’s AI Office/NCAs) to coordinate AI policy and strategy. All three also emphasize international cooperation and participation in norm-setting. Notably, all three frameworks explicitly or implicitly reference the core tenets of transparency, fairness, accountability, safety, and human-centricity, which have been developed in international forums like the OECD and the G7 Hiroshima AI Process.
The divergence is not in the “what” – ensuring the responsible development and deployment of AI – but in the “how.” The EU chooses comprehensive, prescriptive regulation; Japan opts for softer regulation building on existing voluntary guidelines; and South Korea applies targeted regulation to specific high-risk areas. This indicates a global consensus on the desired ethical outcomes for AI, but a deep and consequential divergence on the most effective legal and administrative tools to achieve them.
Access here a detailed Comparative Table of the three AI laws in the EU, South Korea and Japan, comparing them on 11 criteria, from definitions and scope, to risk categorization, enforcement model and support for innovation.
The future of AI regulation: A new regional and global landscape
The distinctly “light-touch” approach to AI regulation in Japan suggests a minimal compliance burden for organizations in the immediate term. However, the AI Promotion Act is arguably the beginning, not the end, of the conversation, as the forthcoming Basic AI Plan has the potential to introduce a wide range of possible initiatives.
Regionally, Japan’s “innovation-first” strategy likely aims to draw investment by offering a less burdensome regulatory environment. The EU, conversely, is attempting to set a high standard for ethical and safe AI, aiming to foster sustainable and trustworthy innovation. South Korea’s middle-ground approach attempts to capture benefits from both strategies.
The availability of a full spectrum of regulatory models on a global scale aimed at the same technology could lead to regulatory arbitrage. It remains to be seen whether companies prioritize development in less regulated jurisdictions to minimize compliance costs, or, conversely, whether there will be a global demand for “EU-compliant” AI as a mark of trustworthiness. This dynamic implies that the future of AI development might be shaped not just by technological breakthroughs but by the attractiveness of regulatory environments as well.
Nevertheless, it is also worth noting that a jurisdiction’s regulatory model alone does not determine its ultimate success in attracting investments or deploying AI effectively. Many other factors, such as the availability of data, compute and talent, as well as the ease of doing business generally, will also be critical.
With two significant jurisdictions in the APAC region having adopted now innovation-oriented AI laws, it appears that the region is starting a trend in innovation-first AI regulation and a contrasting model to the EU AI Act. At the same time, it is notable that both Japan and South Korea have comprehensive national data protection laws, which offer safeguards to people’s rights in all contexts where personal data is being processed, including through AI systems.
Note: Please note that the summary of the AI Promotion Act below is based on an English machine translation, which may contain inaccuracies. Additionally, the information should not be considered legal advice. For specific legal guidance, kindly consult a qualified lawyer practicing in Japan.
The author acknowledges the valuable contributions of the APAC team’s interns, Darren Ang and James Jerin Akash, in assisting with the initial draft of this blog post.
The Connecticut Data Privacy Act Gets an Overhaul (Again)
Co-Authored by Gia Kim, FPF U.S. Policy Intern
On June 25, Governor Ned Lamont signed SB 1295, amending the Connecticut Data Privacy Act (CTDPA). True to its namesake as the “Land of Steady Habits,” Connecticut is developing the habit of amending the CTDPA. Connecticut has long been ahead of the curve, especially when it comes to privacy. In 1788, Connecticut became the fifth state to ratify the U.S. Constitution. In 2022, it similarly became the fifth state to enact a comprehensive consumer privacy law. In 2023, it returned to that law to add heightened privacy protections for minors and for consumer health data. In 2024 and 2025, the Attorney General issued enforcement reports that included recommendations for changes to the law (some of which were ultimately included in SB 1295). Now, a mere two years since the last major amendments, Connecticut has once again passed an overhaul of the CTDPA.
This fresh bundle of amendments makes myriad changes to the law, expanding its scope, adding a new consumer right, heightening the already strong protections for minors, and more. Important changes include:
Significantly expanded scope, through changes to applicability thresholds, narrowed exemptions, and expanded definitions;
Changes to consumer rights, including modifying the right to access one’s personal data and a new right to contest certain profiling decisions;
Modest changes to data minimization, purpose limitation, and consent requirements;
New impact assessment requirements headline changes to profiling requirements; and
Protections for minors, including a ban on targeted advertising.
These changes will be effective July 1, 2026 unless stated otherwise.
1. The Law’s Scope Is Expanded Through Changes to Applicability Thresholds, Narrowed Exemptions, and Expanded Definitions
A. Expanded Applicability
Some of the most significant changes these amendments make to the CTDPA are the adjustments to the law’s applicability thresholds, likely bringing many more businesses in scope of the law. Prior to SB 1295, controllers doing business in Connecticut were subject to the CTDPA if they controlled or processed the personal data of (1) at least 100K consumers (excluding personal data controlled or processed solely for completing a payment transaction), or (2) at least 25K consumers if they also derived more than 25% of their gross revenue from the sale of personal data. The figures in those thresholds were already common to the state comprehensive privacy laws when the CTDPA was enacted in 2022, and those same thresholds have been included in numerous additional state privacy laws enacted after the CTDPA. In recent years, however, several new privacy laws have opted for lower thresholds. SB 1295 continues that trend and goes further.
Under the revised applicability thresholds, the CTDPA will apply to entities that (1) control or process the personal data of at least 35K consumers, (2) control or process consumers’ sensitive data (excluding personal data controlled or processed solely for completing a payment transaction), or (3) offer consumers’ personal data for sale in trade or commerce. Although the lowered affected consumer threshold aligns with other states such as Delaware, New Hampshire, Maryland, and Rhode Island, the other two applicability thresholds are unique and more expansive. Given the broad definition of “sensitive data,” expanding the law’s reach to any entity that processes any sensitive data is significant as it likely implicates a vast array of businesses that were not previously in scope. Similarly, expanding the law’s reach to any entity that offers personal data for sale may implicate a wide swath of small businesses engaged in targeted advertising, given the broad definition of “sale” which includes the exchange of personal data for monetary or other valuable consideration.
In addition to the changes to the applicability thresholds, these amendments also adjust some of the law’s exemptions. Most notably, SB 1295 replaces the entity-level Gramm-Leach-Bliley Act (GLBA) exemption with a data-level exemption. This follows an emerging trend in favor of a data-level GLBA exemption, and it was one of the requested legislative changes in the Connecticut Attorney General’s 2024 and 2025 reports on CTDPA enforcement. As the GLBA entity-level exemption is removed, that change is counterbalanced by new entity-level exemptions for some other financial institutions such as insurers, banks, and certain investment agents as defined under various federal and state laws. Shifting away from the GLBA entity-level exemption is responsive to concerns that organizations like payday lenders and car dealerships were avoiding applicability under state privacy laws, which was not lawmakers’ intent.
B. New and Modified Definitions
Expanding the law’s applicability to any entity that processes sensitive data is compounded by the changes SB 1295 makes to the definition of sensitive data, which now includes mental or physical health “disability or treatment” (in addition to “condition” or “diagnosis”), status as nonbinary or transgender (like in Oregon, Delaware, New Jersey, and Maryland), information derived from genetic or biometric data, “neural data” (defined differently than in California or Colorado), financial information (focusing largely on account numbers, log-ins, card numbers, or relevant passwords or credentials giving access to a financial account), and government-issued identification numbers.
Another minor scope change in SB 1295 is the new definition of “publicly available information,” which now aligns with the California Consumer Privacy Act (CCPA) by excluding biometric data that was collected without the consumer’s consent.
2. Changes to Consumer Rights, Including Modifying the Right to Access One’s Personal Data and a New Right to Contest Certain Profiling Decisions
A. Access
Drawing from developments in other states, SB 1295 makes several changes to the law’s consumer rights. First, SB 1295 expands the right to access one’s personal data to include (1) inferences about the consumer derived from personal data and (2) whether a consumer’s personal data is being processed for profiling to make a decision that produces any legal or similarly significant effect concerning the consumer. This is consistent with requirements under the Colorado Privacy Act regulations (Rule 4.04), which specify that compliance with an access request must include “include final [p]rofiling decisions, inferences, derivative data, marketing profiles, and other [p]ersonal [d]ata created by the [c]ontroller which is linked or reasonably linkable to an identified or identifiable individual.” The CCPA similarly specifies that personal information includes inferences derived from personal information to create a profile about a consumer, bringing such information within the scope of access requests.
Since 2023, new privacy laws in Oregon, Delaware, Maryland, and Minnesota have included a consumer right to know either the specific third parties or the categories of third parties to whom the consumer’s personal data are disclosed. Continuing that trend, SB 1295 adds a right to access a list of the third parties to whom a controller sold a consumer’s personal data, or, if that information is not available, a list of all third parties to whom a controller sold personal data. While this closely resembles the provisions in the Oregon Consumer Privacy Act and the Minnesota Consumer Data Privacy Act, SB 1295 differs from those laws in a few minute ways. First, SB 1295 concerns the third parties to whom personal data was sold, as opposed to the third parties to whom personal data was disclosed. This difference may not be consequential if the amount of third parties to whom personal data are disclosed but not “sold” (given the broad definition of “sell”) is near zero. Furthermore, unlike in Oregon’s law where the option to provide a non-personalized list of third party recipients is at the controller’s discretion, SB 1295 only allows controllers to provide the broader, non-personalized list if the controller does not maintain a list of the third parties to whom it sold the consumer’s personal data.
While the above changes expand the right to access, SB 1295 also narrows the right to access by prohibiting disclosure of certain types of personal data. Under the amendments, a controller cannot disclose the following types of data in response to a consumer access request: social security number; government-issued identification number (including driver’s license number); financial account number; health insurance or medical identification number; account password, security question or answer; and biometric data. Instead, the CTDPA now requires a controller to inform the consumer “with sufficient particularity” that the controller collected these types of personal data. Minnesota became the first state to include this requirement in its comprehensive privacy law in 2024, and Montana amended its privacy law earlier this year to include a similar requirement. This change is likely an attempt to balance a consumer’s right to access their personal data with the security risk of erroneously exposing sensitive information such as SSNs to third parties or bad actors.
B. Profiling
In addition to the changes to the access right, SB 1295 makes important amendments to profiling rights. The existing right to opt-out of profiling in furtherance of decisions that produce legal or similarly significant effects is expanded. Previously it was limited to “solely automated decisions,” whereas now the right applies to “any automated decision” that produces legal or similarly significant effects. Similarly, the reworked definition of “decision that produces any legal or similarly significant effect” now includes any decision made “on behalf of the controller,” not just decisions made by the controller. This likely expands the scope of profiling protections to intermediate and non-final decisions.
SB 1295 also adds a new right to contest profiling decisions, becoming the second state to do so after Minnesota. Under this new right, if a controller is processing personal data for profiling in furtherance of any automated decision that produced any legal or similarly significant effects concerning the consumer, and if feasible, the consumer will have the right to:
Question the result of the profiling;
Be informed of the reason why the profiling led to such decision;
Review the personal data used for the profiling; and
If the decision concerned housing, correct the inaccurate data and have the profiling decision reevaluated with corrected data.
These requirements diverge from Minnesota’s approach in a few ways. First, Connecticut’s right only applies “if feasible,” which arguably removes any implicit incentive to design automated decisions based on profiling to accommodate such rights. For example, Minnesota’s law does not have this caveat, so controllers will have to design their profiling practices to be explainable. Although this differs from Minnesota’s right, it is not wholly new language. Rather, Connecticut’s “if feasible” qualifier mirrors language in the right to appeal an adverse consequential decision under Colorado’s 2024 law regulating high-risk artificial intelligence systems (allowing for human review of adverse decisions “if technically feasible”). Second, the right to correct inaccurate personal data and have the profiling decision reevaluated is limited to decisions concerning housing. Third, SB 1295 does not include the right to be informed of actions that the consumer could have taken, and can take in the future, “to secure a different decision.”
3. Modest Changes to Controller Duties, Including Data Minimization, Purpose Limitation, and Sensitive Data Consent Requirements
Data minimization has become a hotly contested policy issue in privacy legislation in recent years, as states explore more “substantive” requirements that tie the collection, processing, and/or sharing of personal (or sensitive) data to what is “necessary” to provide a requested product or service. At various points this year, Connecticut, Colorado, and Oregon all considered amending their existing privacy laws to include Maryland-style substantive data minimization requirements. None of these states ended up following that path, although Connecticut did rework the data minimization, purpose limitation, and consent requirements in the CTDPA.
It is not immediately clear whether these changes are more than trivial, at least with respect to data minimization and the sensitive data requirements. Changing the limit on collecting personal data from what is “adequate, relevant, and reasonably necessary” for a disclosed purpose to what is “reasonably necessary and proportionate” for a disclosed purpose may not be operationally significant. “Proportionality” is a legal term of art that is beyond the scope of this blog post. It is sufficient to say that it is doubtful that in this context “proportionate” means much more than to limit collection to what is adequate and relevant, which was the original language. Similarly, for sensitive data, controllers now have the added requirement to limit their processing to what is “reasonably necessary in relation to the purposes for which such sensitive data are processed,” in addition to getting consent for processing. This change may be trivial at best and circular at worst, depending on whether one believes that it is even possible to process data for a purpose that is not reasonably necessary to the purpose for which the data are being processed. Similarly, the law now specifies that controllers must obtain separate consent to sell sensitive data. This change is likely intended to prevent controllers from bundling requests to sell sensitive data with other consent requests for processing activities that are essential for the functionality of a product or service.
The changes are more significant with respect to purpose limitation. The core aspects of the rule remain unchanged—obtain consent for secondary uses of personal data (subject to various exceptions in the law, such as bias testing for automated decisionmaking). New in SB 1295 is (1) a new term of art (a “material new purpose”) to describe secondary uses that are not reasonably necessary to or compatible with the purposes previously disclosed to the consumer, and (2) factors to determine when a secondary use is a “material new purpose.” These factors include the consumer’s reasonable expectations at the time of collection, the link between new purpose and the original purpose, potential impacts on the consumer, the consumer-controller relationship and the context of collection, and potential safeguards. These factors are inspired by, but not identical to, those in Rule 6.08 of the Colorado Privacy Act regulations and § 7002 of the CCPA regulations, which were themselves inspired by the General Data Protection Regulation’s factors for assessing the compatibility of secondary uses in Art. 6(4).
There are other minor changes to controller duties, including a new requirement for controllers to disclose whether they collect, use, or sell personal data for the purpose of training large language models (LLMs).
4. New Impact Assessment Requirements Headline Changes to Profiling Requirements
SB 1295 expands and builds upon many of the CTDPA’s existing protections and business obligations with respect to profiling and automated decisions, affecting consumer rights, transparency obligations, exceptions to the law, and privacy by design and accountability practices. As discussed above, SB 1295—
Expands the existing profiling opt-out right to apply to decisions other than those that are “solely automated”;
Adds a new right to contest certain profiling decisions;
Requires controllers disclose whether they are collecting, using, or selling personal data for the purpose of training LLMs; and
Adds a new exception to the law, providing that nothing in the CTDPA shall restrict a controller’s ability to collect, use, or retain data for internal use to detect or correct any bias that may result from profiling, subject to certain safeguards and restrictions on reuse.
Another significant update with respect to profiling is the addition of new impact assessment requirements. Like the majority of state comprehensive privacy laws, the CTDPA already requires controllers to conduct data protection assessments for processing activities that present a heightened risk of harm, which includes profiling that presents a reasonably foreseeable risk of substantial injury (e.g., financial, physical or reputational injury). SB 1295 adds a new “impact assessment” requirement for controllers engaged in profiling for the purposes of making a decision that produces any legal or similarly significant effect concerning a consumer. An impact assessment has to include, “to the extent reasonably known by or available to the controller,” the following:
A statement disclosing the profiling’s “purpose, intended use cases and deployment context of, and benefits afforded by,” the profiling;
Analysis as to whether the profiling poses any “known or reasonably foreseeable heightened risk of harm to a consumer”;
A description of the main categories of personal data processed as inputs for the profiling and the outputs the profiling produces;
An overview of the “main categories” of personal data used to “customize” the profiling, if any;
Any metrics used to evaluate the performance and known limitations of the profiling;
A description of any transparency measures taken, including measures taken to disclose to the consumer that the profiling is occurring while it is occurring; and
A description of post-deployment monitoring and user safeguards provided (e.g., oversight, use, and learning processes).
These requirements are largely consistent with similar requirements under Colorado’s 2024 law regulating high-risk artificial intelligence systems. Impact assessments will be required for processing activities created or generated on or after August 1, 2026, and they will not be retroactive.
These new provisions raise several questions. First, it is unclear whether an obligation to include information that is “reasonably known by or available to the controller” implies an affirmative duty for a controller to seek out facts and information that may not be known already but which could be identified through additional testing. Second, it is not clear when and how impact assessments should be bundled with data protection assessments, to the extent that they overlap. The law provides that a single data protection assessment or impact assessment can address a comparable set of processing operations that include similar activities. This could be read either as saying that one assessment total can cover a set of similar activities, or that one data protection assessment or impact assessment can be conducted to cover a set of similar activities but an activity (or set of activities) subject to both requirements must receive two assessments.
Impact assessments will be relevant to enforcement. Like with data protection assessments, the AG can require a controller to disclose any impact assessment relevant to an investigation. In an enforcement action concerning the law’s prohibition on processing personal data in violation of state and federal antidiscrimination laws, evidence or lack of evidence regarding a controller’s proactive bias testing or other similar proactive efforts may be relevant.
With respect to minors, there are additional steps and disclosures that must be made. If a controller conducts a data protection assessment or impact assessment and determines that there is a heightened risk of harm to minors, the controller is required to “establish and implement a plan to mitigate or eliminate such risk.” The AG can require the controller to disclose a harm mitigation or elimination plan if the plan is relevant to an investigation conducted by the AG. These “harm mitigation or elimination plans” shall be treated as confidential and exempt from FOIA disclosure in the same manner as data protection assessments and impact assessments.
5. Protections for Minors, Including a Ban on Targeted Advertising
The last major update to the CTDPA in 2023 added heightened protections for minors, including certain processing and design restrictions and a duty for controllers to use reasonable care to avoid “any heightened risk of harm to minors” caused by their service. Colorado and Montana followed Connecticut’s lead and added similar protections to their comprehensive privacy laws in recent years. SB 1295 now adjusts those protections for minors again and makes them stricter.
Under the revised provisions, a controller is entitled to a rebuttable presumption of having used reasonable care if they comply with the data protection assessment and impact assessment requirements under the law. More significant changes have been made to the processing restrictions. Previously, the law imposed several substantive restrictions (e.g., limits on targeted advertising or the sale of personal data) for minors, but allowed a controller to proceed with those activities if they obtained opt-in consent. As noted in FPF’s analysis of the 2023 CTDPA amendments, it is atypical for a privacy law to allow for consent as an alternative to certain baseline protections such as data minimization and retention limits. In narrowing the role of consent with respect to minors, SB 1295 imposes strongline baselines and privacy by design requirements with respect to children and teens:
Processing Personal Data. Controllers cannot: (A) process minors personal data for targeted advertising or any sale of personal data; (B) process minors personal data unless the processing is reasonably necessary to provide the online service, product, or feature (“service”); (C) process minors personal data for any processing purpose other than that disclosed at the time of collection or what is reasonably necessary for and compatible with the initial purpose; or (D) process minors personal data for longer than is reasonably necessary to provide the service (with an exception for education technology).
Collecting Precise Geolocation Data. Controllers cannot collect precise geolocation data unless (A) the data are strictly necessary for the service (if so, the collection must be limited to the time necessary to provide the service); and (B) the controller provides a signal indicating to the minor that it is collecting precise geolocation data during the collection.
Consent is not entirely excised. The revised law still allows controllers to obtain opt-in consent to process minors’ personal data for purposes of profiling in furtherance of any automated decision made by the controller that produces legal or similarly significant effect concerning the provision or denial of certain enumerated essential goods and services (e.g., education enrollment or opportunity). Allowing minors to opt-in to such profiling may open up opportunities that would otherwise be foreclosed, especially in areas like employment, financial services, and educational enrollment which older teenagers are likely encountering for the first time as they approach adulthood. For example, some career or scholarship quizzes may rely on profiling to tailor opportunities to a teen’s interests.
Meet Bianca-Ioana Marcu, FPF Europe Managing Director
FPF is pleased to welcome our colleague Bianca-Ioana Marcu to her new role as Managing Director of FPF Europe. With extensive experience in privacy and data protection, she takes on this responsibility at a pivotal moment for digital regulation in Europe. In this blog, we will explore her perspectives on the evolving privacy landscape, her approach to advancing discussions on data protection in Europe and Africa, and her vision for strengthening FPF’s leadership in addressing emerging challenges. Her insights will be key in navigating the complex intersection of privacy, innovation, and regulatory development in the years ahead.
You’ve been part of FPF for some time now, but this new role brings fresh responsibilities. What are you most excited to lead as Managing Director of the European office, and how do you see your work promoting the privacy dialogue in the region?
Stepping into this new role at FPF has given me a renewed sense of energy and opportunity that I hope to bring to the brilliant team on the ground. We are at a crossroads in Europe where existential questions are being asked with regard to the effectiveness and malleability of the existing digital regulatory framework. The privacy question is and will remain essential in this ongoing dialogue, as the GDPR is recognized as both the foundation and the cornerstone of the broader EU digital rulebook.
Within the FPF Europe office we will continue to contribute actively to this dialogue, acting as a source of expert, practical, and measured analysis and ideas for identifying ways in which respect for fundamental rights can coexist alongside technological development.
As you step into the role of Managing Director, you will also continue coordinating FPF’s growing presence in Africa. What are your top three priorities for the coming year?
With the expert knowledge and support of our Policy Manager for Africa, Mercy King’ori, this year we successfully launched FPF’s Africa Council. The basis for our work in the region is to advance data protection through collaboration, innovation, and regional expertise, focusing on thought leadership and regionally grounded research. We were delighted to be an official partner of the Network of African Data Protection Authorities (NADPA) Conference hosted in Abuja, Nigeria, with an event on securing safe and trustworthy cross-border data flows.
Over the next years, FPF Africa will sustain its support for data practices that drive innovation, protect privacy, and uphold fundamental rights while being rooted in the diverse legal, social, and economic contexts of the continent.
FPF is known as a trusted platform where senior leaders come to test ideas, share solutions, and learn from one another. As Managing Director, how do you plan to strengthen these connections further while supporting members navigating emerging challenges?
Now in my third year of bringing to life FPF’s flagship event in Europe – the Brussels Privacy Symposium – I am continually inspired by the openness and commitment of the senior leaders in our community in ensuring strong data protection practices globally.
Our dedication to delivering high-quality legal research and policy analysis to our members remains strong, as well as opportunities to come together with intellectual curiosity.
Innovation and data protection are often seen at odds. In your view, what are the most promising opportunities for advancing privacy and innovation in the EU?
As the regulatory dialogue in Europe evolves, there is certainly an opportunity for advancing privacy protection as well as for supporting the region’s ambitions for economic growth. The current momentum for European legislators to streamline the EU’s digital rulebook brings promising opportunities for gathering all stakeholders around the same table, with a focus on clarifying legal uncertainties or points of tension between the rulebook’s different elements, and with an eye on the type of future we want to co-design.
On a more personal note, what inspires your commitment to privacy, and how has your perspective evolved through your work at FPF and beyond?
My commitment to privacy is fueled not only by the belief that the fulfillment of this right is conducive to the enjoyment of other fundamental rights, including non-discrimination, but also by the support and dedication I have found within a privacy community that extends far beyond Brussels. My work at FPF, particularly on Gabriela Zanfir-Fortuna’s brilliant Global Privacy team, has exposed me to the rich and diverse practices and understandings of privacy and data protection around the world. My ambition is to bring this valuable global perspective to FPF Europe’s work, finding ways for continued cooperation and alignment rather than distance and isolationism.
Annual DC Privacy Forum: Convening Top Voices in Governance in the Digital Age
FPF hosted its second annual DC Privacy Forum: Governance for Digital Leadership and Innovation on Wednesday, June 11. Staying true to the theme, this year’s forum convened key government, civil society, academic, and corporate privacy leaders for a day of critical discussions on privacy and AI policy. Gathering an audience of over 250 leaders from industry, academia, civil society and government, the forum featured keynote panels and debates on global data governance, youth online safety, cybersecurity, AI regulation, and other emerging digital governance challenges.
Cross-Sector Collaboration in Digital Governance
FPF CEO Jules Polonetsky began the day by delivering opening remarks emphasizing the importance of cross-sector collaboration among senior leaders in privacy, AI, and digital governance. His message was clear: supporting valuable, societal uses of data requires voices from across industries and sectors working together.
After welcoming the audience, Polonetsky turned to the opening panel “The Path to U.S. Privacy Legislation: Is Data Protection Law the Real AI Regulator?” featuring Dr. Gabriela Zanfir-Fortuna, FPF’s Vice President of Global Privacy, and Keir Lamont, FPF’s Senior Director for U.S. Legislation, Meredith Halama, Partner at Perkins Coie, and Paul Lekas, Senior Vice President and Head of Global Public Policy and Government Affairs at the Software Information Industry Association (SIIA). The discussion explored how existing data protection laws function as de facto AI regulators, highlighting renewed bipartisan efforts toward federal U.S. privacy legislation, navigating persistent challenges like preemption and private rights of action, and how the evolving global landscape shapes U.S. approaches.
Global Leadership in Data Flows and AI
Continuing the conversation about the U.S.’s approach to regulating global data flows, Ambassador Steve Lang, U.S. Coordinator for International Communications and Information Policy at the U.S. Department of State, provided the opening remarks for the next panel, “Advancing U.S. Leadership on Global Data Flows and AI.” In his speech, Ambassador Lang emphasized the importance of cross-border data flows, arguing that trust depends on protecting data wherever it moves.
From there, Morning Tech Reporter at Politico, Gabby Miller, moderated an insightful discussion between Kat Duffy, Senior Fellow for Digital & Cyberspace Policy at the Council on Foreign Relations, Maryam Mujica, Chief Public Policy Officer at General Catalyst, and Pablo Chavez, Adjunct Senior Fellow, Technology and National Security Program at the Center for a New American Security (CNAS). Focusing specifically on how the United States’ role in global data flows and AI has shifted under the new administration, the panel examined how different strategies in digital governance between past and present administrations have had varied impacts on innovation.
The State of AI Legislation: Federal vs. State Approaches
Following a coffee break, FPF Director for U.S. AI Legislation, Tatiana Rice, moderated “AI Legislation – What Role for the States,” with participants Dr. Laura Caroli, Senior Fellow, Wadhwani AI Center, at the Center for Strategic and International Studies (CSIS), Travis Hall, State Director at the Center for Democracy & Technology, Jim Harper, Nonresident Senior Fellow at the American Enterprise Institute, and Shaundra Watson, Senior Director, Policy at the Business Software Alliance. The panelists explored states’ differing roles in regulating AI, from acting as a laboratory of democracy, as Wall argued, to upholding constitutional separation of powers between federal and state law, as Harper noted. The panelists agreed that transparency and accountability remain top of mind for businesses and regulators alike.
Diving Deep into AI Agents: Opportunities and Challenges
Staying on the topic of AI, the next panel, moderated by Bret Cohen, Partner at Hogan Lovells Privacy and Cybersecurity Practice, unpacked the subject of AI agents. The panel featured industry experts including Jarden Bomberg, U.S. Policy Lead for Privacy and Data Strategy at Google, Leigh Feldman, Senior Vice President and Chief Privacy Officer at Visa, Lindsey Finch, Executive Vice President of Global Privacy and Product Legal at Salesforce, and Pamela Snively, Chief Data and Trust Officer at TELUS Communications.
The conversation began by discussing the immense opportunities that agentic AI will make possible before moving into a more nuanced discussion about the privacy, governance, and policy considerations developers must address. The panelists agreed that risk management remains a top priority when developing agentic AI at their organizations. However, as Snively noted, the rewards will likely outweigh the risks.
Competition Meets Privacy in the AI Era
After a networking lunch, attendees retook seats for the event’s second half. Moderator Dr. Gabriela Zanfir-Fortuna, FPF’s Vice President for Global Privacy, welcomed back everyone for “Competition/Data Protection in an AI World.” Joined by Maureen Ohlhausen, Partner at Wilson Sonsini and Peter Swire, FPF Senior Fellow, and J.Z. Liang Chair at the Georgia Institute of Technology, this panel asked discussants to consider the key intersection between privacy and competition in the age of AI, focusing specifically on how regulators can empower users to protect privacy and ensure fair competition.
The discussion highlighted a key regulatory challenge –while antitrust policy often favors openness, this approach can create privacy and security risks. Swire argued that regulators must find ways to make privacy enforcement a dimension of market competition. Ohlhausen then noted that sometimes privacy protection laws can unintentionally affect competition. AI, she added, is like the “pumpkin spice of privacy,” referring to the trend of inserting AI into privacy conversations even where it might not directly apply.
The Big Debates: Experts Go Head to Head
No Caption
No Caption
The energy in the room lifted as FPF’s Senior Director for U.S. Legislation, Keir Lamont, revved up the crowd for “The Big Debates.” This event’s debate-style formatallowed the audience to participate via real-time voting before, during, and after the debaters’ presentations.
Debate 1: “Current U.S. Law Provides Effective Regulation for AI”
Will Rinehart, Senior Fellow at the American Enterprise Institute, argued in favor of the statement, stating that existing U.S. law comprises adaptable legal frameworks, sector-specific expertise, and enforcement grounded in legal principles. He argued that the U.S. needs better enforcement complemented by additional resources for enforcers instead of creating a more robust law.
Leah Frazier, Director of the Digital Justice Initiative at Lawyers’ Committee for Civil Rights Under Law, disagreed, arguing that current U.S. law does not address various risks that AI poses, including privacy, security, and surveillance risks associated with collecting massive amounts of data used to train AI models.
The audience strongly opposed the general premise in the initial vote, but the debate’s winner was determined based on the percentage of votes each debater lost or gained throughout the discussion. Rinehart emerged victorious, increasing support for the premise from 25% to 34% of the audience votes.
Debate 2: “Sensitive Data Can and Should Be Strictly Regulated”
Paul Ohm, a Professor of Law at Georgetown University Law Center, supported the statement, arguing that building laws around sensitive data reflects societal values and civil rights. Ohm continued, stating that U.S. law should target specific data categories previously unprotected for more inclusive and effective policymaking and to best protect marginalized groups.
Mike Hintze, Partner at Hintze Law PLLC, was charged with arguing the negative, highlighting that the effectiveness of laws focused on sensitive data is particularly flawed due to problems around definition and scope. What data is considered sensitive is context-dependent, making regulation over-inclusive for some and under-inclusive for others.
Again, the audience was in strong support of the general resolution, but Hintze won decisively, advancing the vote from 22% to 39% in support and earning an FPF Goat trophy.
Protecting Youth in Digital Spacesand Balancing Privacy and Cybersecurity
After refueling at another quick coffee break, audience members returned to the Waterside Ballroom for two final panels.
Moderated by Bailey Sanchez, FPF’s Deputy Director for U.S. Legislation, the “Youth Privacy, Security, and Safety Online Panel” invited key industry professionals in online youth entertainment to discuss the key protections being advanced worldwide to protect children and teens online.
Panel members included Stacy Feuer, Senior Vice President, Privacy Certified at The Entertainment Software Rating Board (ESRB), David Lieber, Head of Privacy Public Policy for the Americas at TikTok, Tyler Park, Privacy Counsel at Roblox, Nick Rossi, Director of Federal Government Affairs at Apple and Kate Sheerin, Head of Americas Public Policy at Discord. The discussion centered on the importance of built-in privacy defaults and age-appropriate design experiences. The panelists agreed that the future of protecting kids and teens online requires shared responsibility, flexible approaches, ongoing innovation, and collaboration between industry, policymakers, and youth themselves.
The day’s final panel, “Privacy/Cyber Security,” focused on the key points of conflict between online privacy and security values in regulations and at organizations. Moderated by Jocelyn Aqua, Data, Privacy & Ethics Leader at PwC, this discussion featured panelists occupying professional positions in the intersection of cybersecurity and privacy, including Emily Hancock, Vice President and Chief Privacy Officer at Cloudflare, Stephenie Gosnell Handler, Partner at Gibson, Dunn & Crutcher LLP, and Andy Serwin, Executive Committee Member at DLA Piper.
Looking Ahead
FPF’s Senior Vice President for Policy, John Verdi, delivered closing remarks, thanking attendees for a full day of thoughtful and inspiring conversations. The forum successfully demonstrated that addressing digital governance challenges requires diverse perspectives, collaborative approaches, and ongoing dialogue between all stakeholders.
Thank you to those who participated in our Annual DC Privacy Forum: Governance for Digital Leadership and Innovation! This year’s DC Privacy Forum was made possible thanks to our sponsors RelyanceAI, ObservePoint, and Perkins Coie.
We hope to see you next year. For updates on FPF work, please visit FPF.org for all our reports, publications, and infographics, follow us on LinkedIn, Instagram, Twitter/X, YouTube, and subscribe to our newsletter for the latest.
Written by Celeste Valentino, FPF Comms Intern
Future of Privacy Forum Announces Annual Privacy and AI Leadership Awards
New internship program established in honor of former FPF staff
Washington, D.C. – June 12, 2025 — The Future of Privacy Forum (FPF), a global non-profit focused on data protection, AI and emerging technologies, announced the recipients of the 2025 FPF Achievement Awards, honoring exceptional contributors to AI and privacy leadership in the public and private sectors.
FPF presented the Global Responsible AI Leadership Award to Brazil’s National Data Protection Authority (ANPD) in recognition of its comprehensive and forward-thinking approach to leadership in AI governance.
Barbara Cosgrove, Vice President, Chief Privacy and Digital Trust Officer for Workday and a longtime privacy leader and mentor, was honored with the Career Achievement Award.
“It is a privilege to honor Barbara Cosgrove and the Brazilian National Data Protection Authority for their respective contributions to the fields of data protection and AI regulation,” said Jules Polonetsky, CEO of the Future of Privacy Forum. “This year’s awardees have all demonstrated the thoughtful leadership, bold vision, and creative thinking that is essential to advancing the responsible use of data for the benefit of society.”
2025 FPF Achievement Award Recipients include:
Brazil National Data Protection Authority, Global Responsible AI Leadership Award Accepted by Miriam Wimmer
Brazil’s National Data Protection Authority (ANPD) is this year’s recipient of the Global Responsible AI Leadership Award, which honors pioneers operating in the complex and rapidly evolving space where data protection and artificial intelligence intersect.
The Award recognizes ANPD’s comprehensive and forward-thinking approach to governing AI responsibly, most notably through initiatives like the Sandbox for AI and its influential work in developing thoughtful frameworks around generative AI. With a strong emphasis on public engagement, transparency, and international collaboration, ANPD is helping set a global benchmark for how innovation can advance while safeguarding privacy and individual rights.
Barbara Cosgrove, Vice President, Chief Privacy and Digital Trust Officer, Workday, Career Achievement Award
Barbara Cosgrove serves as Vice President, Chief Privacy and Digital Trust Officer at Workday. During her tenure at Workday, Barbara has advocated for Workday globally on data protection matters, championed the company’s global data privacy strategy, implemented technology compliance standards, and developed privacy-by-design and machine learning ethics-by-design frameworks. Barbara has played a key role in establishing the company’s privacy fundamentals and fostering a culture of data protection, including serving as Workday’s chief security officer and leading the development of Workday’s initial AI governance program. Barbara is Vice-Chair of the International Association of Privacy Professionals (IAPP), and a member of FPF’s AI Leadership Council and Advisory Board.
The awards were presented at a reception Wednesday evening following FPF’s Annual DC Privacy Forum, which brought together more than 250 government, civil society, academic, and corporate privacy leaders to for a series of discussions about AI policy, kids online safety, AI agents, and other topics top of mind to the administration and policymakers.
At the event, Melissa Maalouff, a shareholder with ZwillGen, also made a special announcement regarding a new internship that will be housed in FPF’s D.C. office. The Hannah Schaller Memorial Internship by ZwillGen honors the life and legacy of Hannah Schaller, a beloved friend, colleague, and talented privacy attorney who passed away earlier this year.
Hannah started her career as a policy intern in FPF’s D.C. Office. She was a valuable contributor during her time at FPF and a rising star at ZwillGen, a boutique law firm specializing in technology and privacy law. Hannah remained closely connected to FPF following her internship, and was a valuable source of guidance and counsel to FPF members and staff. Hannah was also co-chair of the IAPP DC region KnowledgeNet Chapter.
The candidate selected for the Hannah Schaller Memorial Internship by ZwillGen will work in FPF’s D.C. office, directly with the organization’s policy staff, as Hannah did at the start of her career. Learn more about the internship and opportunities to support the program’s sustainability here. ZwillGenn firm has also created a post-graduate fellowship in Hannah’s honor.
“Hannah’s expertise and abilities as an attorney will leave a lasting impact on the privacy community, and she will be missed personally and for the professional and civic accomplishments that were in her future,” added Polonetsky. “This internship is a wonderful way to celebrate and honor her legacy by helping provide an on-ramp to students seeking a career in privacy.”
To learn more about the Future of Privacy Forum, visit fpf.org.
##
About Future of Privacy Forum (FPF)
FPF is a global non-profit organization that brings together academics, civil society, government officials, and industry to evaluate the societal, policy, and legal implications of data use, identify the risks, and develop appropriate protections. FPF believes technology and data can benefit society and improve lives if the right laws, policies, and rules are in place. FPF has offices in Washington D.C., Brussels, Singapore, and Tel Aviv. Follow FPF on X and LinkedIn.
Brazil’s ANPD Preliminary Study on Generative AI highlights the dual nature of data protection law: balancing rights with technological innovation
Brazil’s Autoridade Nacional de Proteção de Dados (“ANPD”) Technology and Research Unit (“CGTP”) released the preliminary study InteligênciaArtificial Generativa (“Preliminary Study on GenAI”, in Portuguese) as part of its Technological Radar series, on November 29, 2024.1 A short English version of the study was also released by the agency in December 2024. This analysis provides information for developers, processing agents, and data subjects on the potential benefits and challenges of generative AI in relation to the processing of personal information under existing data protection rules.
Although this study does not offer formal legal guidance, it provides important insight into how the ANPD may approach future interpretation of the Lei Geral de Proteção de Dados (“LGPD”), Brazil’s national data protection law. As such, it aligns with a global trend of data protection regulators examining the impact of generative AI on privacy and data protection.2 The study sets up the framework for analyzing data protection legal requirements for Generative AI in the Brazilian context by acknowledging that balancing rights with technological innovation is a foundational principle of the LGPD.
The analysis further takes into account that processing of personal data occurs during multiple stages in the life cycle of generative AI systems, from development to refinement of models. It addresses the legality of web scraping under the LGPD at the training stage, specifically considering that publicly available personal data falls under the scope of the law. The study proposes “thoughtful pre-processing practices”, such as anonymisation or collecting only necessary data for training. It then emphasizes “transparency” and “necessity” as two core principles of the LGPD that need enhanced attention and tailoring to the unique nature of Generative AI systems, before concluding that this technology should be developed from an “ethical, legal, and socio-technical” perspective if society is going to effectively harness its benefits.
Balancing Rights with Technological Innovation: An LGPD Commitment
The study acknowledges the relevance of balancing rights with technological innovation under the Brazilian framework. Article 1 of the LGPD identifies the objective of the law as ensuring the processing of personal data protects the fundamental rights of freedom, privacy, and the free development of personality.3 At the same time, Article 2 of the LGPD recognizes data protection is “grounded” on economic and technological development and innovation.
The study recognizes that advances in machine learning enable generative AI systems beneficial to key fields, including healthcare, banking, and commerce and highlights three use cases likely to produce valuable benefits for Brazilian society. For instance, the Federal Court of Accounts is implementing “ChatTCU”, a generative model to assist the Court’s legal team in producing, translating, and examining legal texts more efficiently. Munai, a local health tech enterprise, is also developing a virtual assistant that will automate the evaluation, interpretation, and application of hospital protocols and support decision-making in the healthcare sector. Finally, Banco do Brasil is developing a Large Language Model (LLM) to assist employees in providing better customer service experiences. The study also highlights the increasing popularity of commercially available generative AI systems such as OpenAI’s ChatGPT and Google’s Gemini among Brazilian users.
In this context, the study emphasizes that while generative AI systems can produce multiple benefits, it is necessary to assess their potential for creating new privacy risks and exacerbating existing ones. For the ANPD, “the generative approach is distinct from other artificial intelligence as it possesses the ability to generate content (data) […] which allows the system to learn how to make decisions according to the data uses.”4 In this context, the CGTP identifies three fundamental characteristics of generative AI systems that are relevant in the context of personal data processing:
The need for large volumes of personal and non-personal data for system training purposes;
The capability of inference that allows the generation of new data similar to the training data; and
The adoption of a diverse set of computational techniques, such as the architecture of transformers for natural language processing systems.5
For instance, the study mentions LLMs as examples of models trained on large volumes of data. LLMs capture semantic and syntactic relationships and are effective at understanding and generating text across different domains. However, they can also generate misleading answers and invent inaccurate “hallucinations.” Another example are foundational models, which are trained on diverse datasets and can perform tasks in multiple domains, often including some for which the model was not explicitly trained.
The document underscores that the technical characteristics and possibilities of generative AI significantly impact the collection, storage, processing, sharing, and deletion of personal data. Therefore, the study holds, LGPD principles and obligations are relevant for data subjects and processing agents using generative AI systems.
Legality of web scraping, impacted by the fact the LGPD covers publicly accessible personal data
The study notes that generative AI systems are typically trained with data collected through web scraping. Data scraped from publicly available sources may include identifiable information such as names, addresses, videos, opinions, user preferences, images, or other personal identifiers. Additionally, if there is an absence of thoughtful pre-processing practices in the collection phase (i.e. anonymizing or collecting only necessary data), it can increase the likelihood of including more personal data for training purposes, including sensitive and children’s data.
The document emphasizes that the LGPD covers publicly accessible personal data, and consequently, processors and AI developers must ensure compliance with personal data principles and obligations. Scraping operations that capture personal data must be based on one of the LGPD’s lawful bases for processing (Articles 7 and 11) and comply with data protection principles of good faith, purpose limitation, adequacy, and necessity (Article 7, par. 3).
Moreover, the study warns that web scraping reduces data subjects’ control over their personal information. According to the CGTP, users generally remain unaware of web scraping involving their information and how developers may use their data to train generative AI systems. In some cases, scraping can result in a data subject’s loss of control over personal information after the user deletes or requests deletion of their data from a website, as prior scraping and data aggregation may have captured the data and made it available in open repositories.
Allocation of responsibility depends on patterns of data sharing and hallucinations
The ANPD also takes note of the processing of personal data during several stages in the life cycle of generative AI systems, from development to refinement of models. The study explains that generative AI’s ability to generate synthetic content extends beyond basic processing and encompasses continuous learning and modeling based on the ingested training data. Although the training data may be hidden through mathematical processes during training, the CTGP warns that vulnerabilities to the system, such as model inversion or membership inference attacks, could expose individuals included in training datasets.
Furthermore, generative AI systems allow users to interact with models using natural language. Depending on the prompt, context, and information provided by the user, these interactions may generate outputs containing personal data about the user or other individuals. A notable challenge, according to the study, is to allocate responsibility in scenarios where i) personal data is generated and shared with third parties, even if a model was not specifically trained for that purpose; and ii) where a model creates a hallucination – false, harmful, or erroneous assumptions about a person’s life, dignity, or reputation, harming the subject’s right to free development of personality.
The study identifies three example scenarios in which personal data sharing can occur in the context of generative AI systems:
Users sharing personal data through prompts
This type of sharing occurs through the input of prompts by users, which can allow users to share information in diverse formats such as text, audio, and images, all of which may contain personal, confidential, and sensitive data. In some instances, users may not be aware of the risks involved in sharing personal information or, if aware, they might choose to “trust the system” to get the answers and assistance they need. In this scenario, the CGTP points out that safeguards should be developed to create privacy-friendly systems. One way to achieve this is to provide users with clear and easily accessible information about the use of prompts and the processing of personal data by generative AI tools.
The study highlights that users sharing the personal data of other individuals through prompts may be considered processing agents under the LGPD and consequently be subject to its obligations and sanctioning regime. Nonetheless, the CGTP cautions that transferring responsibility exclusively to users is not enough to safeguard personal data protection or privacy in the context of generative AI.
Sharing AI-generated outputs containing personal data with third parties
Under this scenario, output or AI-generated content can contain personal data, which could be shared with third parties. The CGTP notes this presents the risk of the personal data being used for secondary purposes unknown to the initial user that the AI developer is unlikely to control. Similar to the previous scenario and data processing activities in general, the study notes the relevance of establishing a “chain of responsibility” among the different agents involved to ensure compliance with the LGPD.
Sharing pre-trained models containing personal data
A third scenario is sharing a pre-trained model itself, and consequently, any personal data present in the model. According to the CGTP, “since pre-trained models can be considered a reflection of the database used for training, the popularization of the creation of APIs (Application Programming Interfaces) that adopt foundational models such as pre-trained LLMs, brings a new challenge. Sharing models tends to involve the data that is mathematically present in them”6 (translated from the Portuguese study). Pre-trained models, which contain a reflection of the training data, make it possible to adjust the foundational model for a specific use or domain.
The CGTP cautions that the possibility of refining a model via the results obtained through prompt interaction may allow for a “continuous cycle of processing” of personal data.7 According to the technical Unit, “the sharing of foundational models that have been trained with personal data, as well as the use of this data for refinement, may involve risks related to data protection depending on the purpose8.”
Relatedly, the document highlights the relevance of the right to delete personal data in the context of generative AI systems. The study emphasizes that the processing of personal data can be present through diverse stages of the AI’s lifecycle, including the generation of synthetic content, through prompt interaction – which allows new data to be shared – and the continuous refinement of the model. In this context, the study points out that this continuous processing of personal data presents significant challenges in (i) delimiting the end of the processing period; (ii) determining whether the purpose of the intended processing was achieved, and (iii) the implications of revoking consent, if the processing relied on this basis.
Transparency and Necessity Principles: Essential for Responsible Gen-AI under the LGPD
Some LGPD principles have special relevance for the development and use of generative AI systems. The report takes the view that these systems typically lack detailed technical and non-technical information about the processing of personal data. The CGTP warns that this absence of transparency begins in the pre-training phase and extends to the training and refinement of models. The study suggests developers may fail to inform users about how their personal information could be shared under the three scenarios identified above (prompt use, outputs, or foundational models). As a result, individuals are usually unaware their information is used for generative AI training purposes and are not provided with adequate, clear, and accessible information about other processing operations such as sharing their personal information with third parties.
In this context, the ANPD emphasizes that the transparency principle is especially relevant in the context of the responsible use and development of AI systems. Under the LGPD, this principle requires clear, precise, and easily accessible information about the data processing. The CGTP proposes that the existence and availability of detailed documentation can be a starting point for compliance and can help monitor the development and improvement of generative AI systems.
Similarly, the necessity principle limits data processing to what is strictly required for developing generative AI systems. Under the LGPD, this principle requires the processing to be the minimum required for the accomplishment of its purposes, encompassing relevant, proportional, and non-excessive data. According to the ANPD, AI developers should be thoughtful about the data to be included in their training datasets and make reasonable efforts to limit the amount and type of information necessary for the purposes to be achieved by the system. Determining how to apply this principle to the creation of multipurpose or general-purpose “foundation models” is an ongoing challenge in the broader data protection space.
Looking Into the Future
The study concludes that generative AI must be developed from an “ethical, legal, and socio-technical” perspective if society is going to effectively harness its benefits while limiting the risks it poses. The CGTP acknowledges that generative AI may offer solutions in multiple fields and applications, however, society and regulators must be aware that generative AI may also entail new risks or exacerbate existing ones concerning privacy, data protection, and other freedoms. The CGTP highlights that this first report includes preliminary analysis and that further studies in the field are necessary to guarantee adequate protection of personal data, as well as the trustworthiness of the outputs generated by this technology.
The ANPD’s “Technological Radar” series address “emerging technologies that will impact or are already impacting the national and international scenario of personal data protection” with an emphasis on the Brazilian context. “The purpose of the series is to aggregate relevant information to the debate on data protection in the country, with educational texts accessible to the general public”. ↩︎