Looking Back to Forge Ahead: Challenges of Developing an “African Conception” of Privacy
In this post for the FPF Blog, Mercy King’ori explores the cultural and societal underpinnings of “privacy” in Africa, looking throughout history, from pre-colonial times, and beyond the modern external influences on the legislative processes resulting in general data protection laws across the continent. The first essential point to start off from is understanding that Africa is not a monolith, it is multi-cultural and context differs across communities. Thus any generalizations in this blog post should be read in this light.
Introduction
Few things depend on context, like privacy, which strongly hinges on how people within various communities and other social organizations perceive it. While the need for privacy may be universal, the particularities of its social acceptance and articulation differ depending on cultural norms that vary among communities. Whitman succinctly captured the cultural cause of the diverse forms of privacy when he posited that “culture informs greatly the different intuitive sensibilities that cause people to feel that a practice is privacy invasive while others do not feel that way”. 1
For example, in delineating the root cause of the differences in privacy expectations among Americans and Europeans, Whitman traces the emergence of the need for privacy among Europeans to the need for dignity, while for Americans, such a need emerged from the desire to express their freedom. By contrast, cultural practices in communities in other parts of the world may take a different view of privacy, such as the Japanese, who historically regarded privacy as a symbol of self-centeredness2.
In Africa, the formal understanding of privacy is still evolving. Given the influential nature of European and American cultures and institutions to the current world order, their conceptions of privacy have been greatly relied on to characterize the need for privacy in Africa.
This has not been without consequences for the recipient societies. In Africa, where the recognition of privacy did not emerge from the need to achieve dignity and liberty (two values that are elusive in most of Africa’s history), scholars3 who use the European or American concept of the term as an implicit frame of reference have concluded that the need for privacy was largely absent on the continent, especially when contrasted with communal concepts such as Ubuntu of South Africa which place the community before the individual. However, as privacy discussions continue to grow in prominence in Africa, the question of whether an African conception of privacy that takes into account the cultural nuances such as strong kinship bonds continue to emerge.
This blog seeks to explore the cultural underpinnings and evolution of privacy in Africa both by examining the historical and modern challenges to fully developing a notion of privacy that takes into account the distinctiveness of the communities in the continent and whether such a conception can exist.
To do so, it begins with a discussion and critique of the dominant notion that was strongly held regarding the existence of privacy in Africa as well as the societal and historical context under which such a notion may have emerged. This is followed by an account of the events (historical and current) that have influenced the development (or lack thereof) of an African conception of privacy. Such an examination provides two key insights:
There is anecdotal evidence that privacy historically existed in Africa, albeit in a subtle form. However, its full emergence may have been encumbered by external and internal influences that the continent was and continues to be subjected to.
As a result, this context allowed for the dominant position (that privacy was largely absent in Africa) to take root. This, in turn, provided a vacuum that made adopting Western conceptions of privacy possible until now.
To conclude, the blog discusses whether a conception of privacy from an African perspective is even possible at this point and whether such a conception is needed given the previous hindered attempts at developing an African conception of privacy.
Dominant Discourse on Privacy in Africa
For a long time, it was claimed that privacy was not valued in Africa. This dominant position can be attributed to the misperception that the communal and collectivist nature of most traditional African communities that marked the pre-colonial era meant that there was no privacy. This stance implied that an individual could not order their lives without the consent of the community.4 In most traditional African societies, the idea of personhood based on individualism was seen as conflicting with accepted social norms, especially those that involved a shared sense of interdependence. For most communities, a person’s identity depended on the community identity. From this lens, the close kinship in most African societies appears from the most mundane aspects of life to the most complex issues such as communal land ownership.
This understanding of communal life (and the secondary place of individualism) in Africa has influenced how privacy is understood in Africa. Indeed, when individualism forms the basis of the conceptualization of privacy, it is clear why many who adopt such a framework accept as true that privacy did not meaningfully exist in Africa. Privacy in a communal way of life was still not imagined and played a negligible role in how the early discourse around privacy and data protection evolved, which solidified the dominant discourse about Africa that still shapes some perceptions today.
However, the idea that African societies lacked individualism (as one of the determinants of the need for privacy) and therefore did not meaningfully articulate a concept of privacy needs to be challenged. While it is still unclear on the extensive role individualism played in structuring social relations in these societies, there is evidence that it did exist in some form in pre-colonial Africa. For example, when communities grew and different interests emerged, the individual began to isolate against the collective. Family members would leave their communal ways of living in pursuit of self-reliance and personal initiatives. 5 6
Furthermore, the absence of information on the definitive nature of privacy in this era may also follow from how communities primarily passed down knowledge. In pre-colonial Africa, oral traditions held a major place7 as a means of disseminating information and communal customs. Traditionally, messages were passed down orally from one generation to another, often in the form of proverbs, songs, folktales and other narrations. Such messages helped people make sense of the world and were used to teach children and adults about important aspects of their culture, including privacy. For instance, the Agikuyu, an ethnic community in East Africa, have a proverb that speaks to the need to preserve privacy for matters of the home (“Cia mucii itiumaga ndira” – Home affairs must not go into the open).
However, weaknesses in record-keeping due to the dominance of oral traditions8 may have limited the availability of anecdotal evidence of privacy in traditional African communities and hampered efforts to formalize it into a more nuanced account of its evolution in the continent. Notably, such limitations in written evidence have also affected many other aspects of African society beyond privacy. One effect of this may be that certain cultural values were elevated beyond others, with the former being translated into laws. This could explain the absence of the right to privacy in the African Charter on Human and People’s Rights, while collective rights form a unique aspect of the Charter.9 Because of this, while African social order manifested features of individuality, communal living became more discernible than individualism to outside observers and consequently led to perceptions that privacy played little role in pre-colonial Africa. The arrival of colonialism reinforced these views, albeit in a different way, and greatly altered the indigenous development of privacy on the continent.
Colonialism, Post-Colonialism, Independence, and Privacy
The colonial era was and remains an impactful period of time for most African communities in many ways, including privacy. The events of this period adversely affected any efforts to recognize privacy as a fundamental societal value. Colonialism began with the partition of Africa that gave rise to the formal geographical boundaries that currently exist. This gave new shape, meaning, and direction to the inherent kinship bonds within communities, which began to disintegrate as a result of colonial strategies such as divide and rule.
There was resistance to the colonial practices that set out to tear down the communal structures of the time.10 As the focus was on protecting the communal way of living, aspects of individualism discussed above seem to have remained intact within many communities.11 From a privacy perspective, this was a conducive condition–as individualism among disrupted communities remained intact. However, the imperialistic circumstances of the time made it unlikely that privacy and its related value of autonomy would be asserted. The power imbalances that existed between the indigenous communities and colonial governments created an unconducive environment for the development of a shared understanding and rights-respecting notion of privacy.
Colonial administrations contributed to many gross violations towards the dignity of community members. For example, in Kenya, the British introduced in 1920 through the Native Registration Amendment Ordinance, a means of identification, the Kipande system.12 This involved the use of an identity document that contained the personal details, fingerprints, area of residence, and employment records of the holder–categories of information that modern privacy and data protection law considers personal and sensitive personal data. The identity document was issued to male Africans who worked in settler farms to administer a labor registration system. Holders of a kipande were required to wear it around their necks, clearly identifying their information and status as a farm worker to colonial administrators.
At the time of its use, this paternalistic system caused an uproar and generated much resentment –both towards the oppressive means it embodied and the larger relationship between the settlers and Africans it represented.13 The holders viewed it as a symbol of humiliation and a loss of self-identity14, and many political associations of the time denounced it as a form of repression and control.15 Indeed, the Kipande system was a true reflection of the modern understanding of a surveillance system, one that could have generated concerns based on modern-day privacy principles.16 The fact that its opponents did not articulate their resentment around a conception of privacy reflects a missed opportunity for communities at the time to develop their own expectations of privacy. Intrusive identification systems still pose privacy challenges in many parts of the continent.
Fast forward to when most African countries gained independence around the 1960s and 1970s. Independence created new legal structures such as Constitutions and Bill of Rights that were not indigenous to African communities. Prior to 1950, colonial administrations in many colonies did not consider Bills of Rights seriously, especially in those under British rule.17 This was primarily due to the official policy of rejecting a rights-based approach in constitutional ordering.18 For example, Ghana’s 1957 independence Constitution did not include a Bill of Rights. Nevertheless, there was emerging international consensus regarding human rights which began to create an atmosphere that was conducive to the adoption of Bills of Rights in the colonies post independence.19 Thus when the British government granted independence to these countries, the Constitutions were created with a Bill of Rights.20 At the time Europe was ratifying conventions such as the European Convention on Human Rights and transposing similar principles to their colonies.21 The introduction of human rights to colonial dependencies saw the introduction of the right to privacy making it the initial formal reference to privacy in most African countries.
Privacy Interlude: The fall of Independence Constitutions, rise of authoritarian governments and the revival of constitutional arrangements
Soon after independence, the reins of leadership were handed over to the founding fathers of Africa. Under political pressure, these leaders abrogated the independence Constitutions on grounds that Western forms of government couldn’t flourish in Africa as they are based on alien principles.22 To be sure, the ambitions of those in power and the general geopolitical conditions of the time aggravated the failure of the Constitutions more than any intrinsic flaws in the Constitutions themselves.23 Regardless, this saw parts of Constitutions, such as those guaranteeing privacy rights, eliminated.
Later on, in the 1970s and 1980s, when economic crises hit Africa, Structural Adjustment Programs (SAPs) and stabilization policies for the purpose of economic development were introduced. SAPs involved the transfer of funds to different African economies tied to the fulfillment of certain conditions.24 One of the conditions concerned the reinstatement of Bills of Rights, which in turn saw the reintroduction of the right to privacy in many Constitutions.25
An African Conception of Privacy in the face of Globalization?
The period that followed has been crucial for privacy and data protection in Africa. As African societies became more active participants in the globalized world order, legal efforts to shape the perceptions of the need for privacy have increased in frequency and importance, as seen in the growing number of privacy and data protection laws. Privacy in Africa is now not only viewed through the lens of individualism (seen as gaining prominence over collective living).
There are two main motivating factors for the expanded need for privacy. First, privacy is crucial to protect people from human rights violations resulting from technological advances. Second, privacy has emerged as a key requirement for Africa’s participation in the global digital economy. This desire to participate in global trade facilitated by information technology has influenced many countries to adopt a regulatory system that reduces legal hurdles and uncertainty.26 In order to accomplish this, many African states have been inspired by privacy laws that have grown to represent internationally accepted best practices such as the OECD Guidelines on the Protection of Privacy and Transborder Data Flows, the defunct EU Data Protection Directive of 1995, and its modern version, the EU General Data Protection Regulation (GDPR), or Council of Europe’s Convention 108 and 108+. Bearing in mind the difference between privacy and data protection, information privacy in many countries is now protected under comprehensive data protection laws, while a handful of countries have made the distinction between privacy and data protection directly in their laws. This process has been aided by development partners such as the EU Commission under the HIPSSA-ITU project, which sought to harmonize information and communication laws in Sub-Saharan Africa and saw at least two regional data protection frameworks modeled from the EU Directive of 1995.
This process of transplanting the language and body of foreign privacy and data protection laws has dealt a serious blow to attempts to develop an African conception of privacy, notwithstanding the challenges of implementing such a transplanted structure. On the one hand, the source of the challenges of implementation is not clear. Could it be the introduction of laws that do not reflect our knowledge of and commitment to the underlying values or a mere lack of political will? Arguably, it may be too early to determine this as most laws are still nascent. On the other hand, transplanting can be defended in light of changing perceptions of privacy, as more Africans become aware of the need for privacy protection as a means to protect their dignity and defend their freedoms, especially from the excesses of governments. It is on this basis that many criticize existing privacy and data protection laws as containing illusory and ineffective safeguards.27
Nonetheless, the infusion of indigenous aspects into privacy and data protection laws indicates that perhaps all is not lost. The Malabo Convention, the continental treaty on data protection and cybersecurity, contains provisions that mandate the recognition of communal rights in the creation of data protection laws.28 Similarly, indications of class action suits (pointing to recognition of privacy violations affecting groups of people) that permit communities to assert their right to privacy can be found under SADC Model law of Southern Africa29 as well as the ECCAS Model Law/CEMAC Directive of Central Africa30. Such efforts elucidate the types of African cultural aspects that should be considered when implementing a privacy and data protection framework. However, this has not cascaded down into many national frameworks, which mostly rely on legal instruments adopted from Europe.
Given the evolution of privacy in Africa, whether Africa will ever develop its own foundation of privacy or whether an African conception of privacy is necessary at this point remain open questions. Can the external and internal influences that Africa has experienced help define the socio-political foundations of privacy, like Europe and the U.S., whose values of privacy were founded on ideals with histories reaching back to the revolutionary era of the 18th century? Or has Africa leapfrogged into a conception of privacy that actually suits the stringent privacy requirements of the time? The jury is still out.
1 James Q. Whitman, The Two Western Cultures of Privacy: Dignity Versus Liberty https://www.yalelawjournal.org/article/the-two-western-cultures-of-privacy-dignity-versus-liberty
2 Hiroshi Miyashita, The evolving concept of data privacy in Japanese law https://academic.oup.com/idpl/article/1/4/229/731520
3 Hanno Olinger, Western Privacy and/or Ubuntu? Some Critical Comments on the Influences in the Forthcoming Data Privacy Bill in South Africa, 2016 https://www.tandfonline.com/doi/abs/10.1080/10572317.2007.10762729 “Ubuntu can be described as a community-based mindset in which the welfare of the group is greater than the welfare of a single individual in the group.”
5 Ibrahim Anoba, A Libertarian Thought on Individualism and African Morality, https://www.africanliberty.org/2017/05/21/a-libertarian-thought-on-individualism-and-african-morality-by-ibrahim-anoba/
FPF Addresses ‘Opt-Out Preference Signals’ in Comments on California Draft Privacy Regulations
Yesterday, the Future of Privacy Forum (FPF) filed comments with the California Privacy Protection Agency regarding the Agency’s initial set of draft regulations to implement the California Privacy Rights Act amendments to the California Consumer Privacy Act.
FPF’s comments are directed towards ensuring that both individuals and businesses have clarity for the implementation and exercise of consumer rights through an emerging class of privacy tools known as ‘opt-out preference signals.’
Specifically, FPF recommended that the Agency’s final regulations governing preference signals and the mechanisms that transmit signals (such as web browsers and plug-ins) include the following clarifications:
Resolve questions for the exercise of opt-out signals directed to websites while encouraging innovation in privacy controls for emerging digital and physical contexts.
Clarify business disclosures in response to signals to ensure that individuals have access to relevant information about the exercise of their privacy rights.
Encourage the development of signal mechanisms that allow consumers to exercise granular control of their privacy rights with respect to specific businesses.
Ensure that the use of preference signals objectively represents an individual’s intent to invoke their privacy rights.
Establish a multistakeholder process for ongoing Agency approval and review of preference signals and signal mechanisms.
New Report on Limits of “Consent” in Macau’s Data Protection Law
Introduction
Today, the Future of Privacy Forum (FPF) and Asian Business Law Institute (ABLI), as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific,” are publishing the twelfth in a series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC).
This report provides a detailed overview of relevant laws and regulations in the Special Administrative Region of Macau, China (Macau SAR), including:
notice and consent requirements for processing personal data;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in laws and regulations.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
Macau’s Data Protection Landscape
The main data protection legislation in Macau SAR is the Personal Data Protection Act (Law No. 8/2005) (PDPA), which was significantly influenced by European data protection legislation, including Portugal’s Law No. 68/98 on the Protection of Personal Data, which implemented EU Directive 95/46/EC.
As such, the PDPA’s legal bases for processing personal data closely resemble those in the GDPR. These include consent, but also where processing is necessary:
for the performance of a contract to which the data subject is a party;
to take steps at the request of the data subject when negotiating a contract;
to comply with a legal obligation to which the controller is subject;
to protect the vital interests of a data subject who is physically or legally incapable of giving consent;
to carry out a task in the public interest or in the exercise of official authority;
for pursuing the legitimate interests of the controller or a third party to whom the data is disclosed, subject to a “balancing test” between such interests and the fundamental rights, freedoms, and guarantees of the data subject.
The PDPA also empowers a public authority, the Office of Personal Data Protection (OPDP), to issue guidance on the PDPA, investigate possible breaches of the PDPA, and perform certain administrative duties, such as identifying jurisdictions which provide an adequate standard of data protection for purposes of cross-border data transfer. The OPDP has issued a number of guidelines on interpretation of the PDPA in different contexts, including several concerning the use of biometrics, as well as a large number of case notes from its enforcement actions.
Role and Status of Consent as a Basis for Processing Personal Data in Macau
Under the PDPA, consent of the data subject is one of several legal bases for processing both personal data and sensitive personal data. “Sensitive personal data,” refers to personal data:
revealing a person’s philosophical or political beliefs, political association or trade-union membership, religion, privacy, and racial or ethnic origin;
concerning a person’s health or sex life; or
including a person’s genetic data.
Consent also functions as one of several legal bases for transferring personal data out of Macau SAR and can be used to legitimize transfer to a jurisdiction which does not ensure an adequate level of data protection as determined by the OPDP.
The PDPA defines consent of the data subject as any freely given, specific, and informed indication of the data subject’s wishes by which the data subject signifies agreement to processing of personal data relating to him/her.
For consent to qualify as informed, the data controller must provide certain information to the data subject either at the time that the data subjects’ personal data is collected or, if the personal data is to be disclosed to a third party, no later than the first time that the data is disclosed. This information includes:
the identity of the data controller or its representative;
the purpose of processing the personal data;
any third parties to whom the personal data may be disclosed;
whether the data subject is required to provide the data, and the consequences if the data subject does not provide the data; and
the data subjects’ rights under the PDPA and how to exercise them.
Failure to comply with these notice requirements may give rise to an administrative fine under the PDPA.
In addition to these definitional requirements, the PDPA also requires that consent for processing and cross-border transfer of personal data should be “unambiguous” and that consent for processing sensitive personal data should be “explicit.” Failure to comply with requirements to obtain consent before transferring personal data out of Macau SAR may be subject to an administrative fine.
The PDPA imposes criminal sanctions on persons who access personal data without authorization or disclose personal data to third parties in breach of confidentiality obligations. These sanctions increase if certain aggravating factors are present, including where the wrongdoer benefits from such breaches.
ETSI’s consumer IoT cybersecurity ‘conformance assessments’: parallels with the AI Act
In early September 2021, the European Telecommunications Standards Institute (ETSI) published its European Standard to lay down baseline cybersecurity requirements for Internet of Things (IoT) consumer products (ETSI EN 303 645 V2.1.1). The Standard is a recommendation to manufacturers to develop IoT devices securely from the outset. It also provides an internationally recognized benchmark – informed by several external sources, such as the interactive tool of the European Union Agency for Cybersecurity (ENISA) – to assess whether such devices have a minimum level of cybersecurity.
ETSI’s Standard takes an outcomes-focused approach, providing manufacturers with the flexibility to implement the most appropriate security solutions for their products instead of being overly-prescriptive in terms of specific security measures. It aims to protect IoT devices against elementary attacks on fundamental design weaknesses, such as the use of easily guessable passwords.
A technical ETSI specification complements the Standard, providing manufacturers, developers, suppliers, and implementers with a methodology to conduct conformance assessments of their IoT products against the baseline requirements (ETSI TS 103 701 V1.1.1). According to the German Federal Office for Information Security (BSI), the specification “ensures that test results are comparable to the security characteristics of IoT devices. In this way, IoT-experienced persons are enabled to make a corresponding security assessment.” Testing according to the specification may serve as a pathway for manufacturers and providers to obtain security labels on their products, such as Germany’s IT Security Label, a process which the BSI opened for applications in December 2021 for two categories of products: broadband routers and email services.
Moreover, the framework published by ETSI may come to serve as the basis for a technical specification that the European Commission has requested ETSI to develop for “internet-connected radio equipment” under the Radio Equipment Directive (RED) and its recent Delegated Act, notably on what concerns the incorporation of network security, privacy, data protection, and fraud prevention features.
In this piece, we first summarize the Standard’s narrow approach to data protection requirements (Section 1). We then describe ETSI’s conformance assessment methodology (Section 2). Lastly, we explore whether we can draw a parallel or find synergies with the “conformity assessment” in the proposed AI Act (Section 3). In answering this question, this blogpost deems to highlight how the ETSI’s overall framework for IoT security conformance assessments compare with the AI systems conformity assessment requirements laid down in the European Commission proposal for an AI regulation. Such analysis is particularly relevant in light of the standardization request that the Commission has made to ETSI to operationalize certain requirements of the AI Act, and the latter’s calls for leaving important parts of the regulation – like the definition of Artificial Intelligence itself and the list of high-risk use cases – to technical standards.
This piece follows a previously published deep dive analysis of the “conformity assessment” in the AI Act and how it compares to the Data Protection Impact Assessment provided by the GDPR.
1. A narrow approach to data protection requirements
The Standard starts by non-exhaustively listing the categories of IoT products to which it applies. It is focused on consumer IoT devices that are connected to network infrastructure (such as the Internet or a home network) and their interactions with associated services, such as connected children’s toys and baby monitors, smart cameras, TVs and speakers, wearable health trackers, connected home automation systems, connected appliances (e.g., washing machines and fridges), and smart home assistants. Products that are primarily intended to be used in manufacturing, healthcare, or other industrial applications are excluded.
We remark that the references to personal data protection in ETSI’s framework are somewhat limited, even if it covers consumer-facing IoT products. The Standard takes a more comprehensive approach to device and information security. Regarding the security, lawfulness, and transparency of personal data processing through consumer IoT devices, the Standard recommends manufacturers to focus on deploying appropriate best practice cryptography to transfers of personal data between the device and associated services (e.g., cloud). On this point, particular emphasis is given to cases where the processed data is sensitive (e.g., video streams of security cameras, payment information, location and content of communications data). Note that the examples given of “sensitive” data in the Standard do not align with the types of data that are considered “special categories” under Article 9 GDPR. For instance, images captured by security cameras, payment, and location data do not inherently fall under said provision, unless they reveal or may reveal particularly sensitive data (e.g., a person’s health conditions, sexual orientation or political leanings).
Manufacturers are expected to inform users clearly about different data protection aspects. We mention six of them: the external sensing capabilities of the device (e.g., optic or acoustic sensors); what personal data is processed (including telemetry data, which should be restricted to the minimum necessary for service provision); and – for each device and service – how the device or service is being used, by whom (e.g., by third parties, such as advertisers), and for what purposes.
Where consent is necessary for specific processing purposes, there should be a mechanism to seek valid consent from users and to allow them to withdraw such consent (e.g., through the device’s user configurations). Users should also be given an easy way (with clear instructions) to delete their data, including their details, personalized configurations, and access credentials. If users use this functionality, they should receive confirmation that their data has been deleted from services, devices, and apps. The confirmation is particularly important in cases of transfer of ownership, temporary usage, or disposal of the device.
Beyond the limited data protection-focused provisions, the Standard mainly recommends technical and organizational measures for manufacturers to attain an appropriate level of cybersecurity in the consumer IoT devices they design. These measures can include:
Examining telemetry data (e.g., usage and measurement data) and validating input data to detect security anomalies and prevent potential gaps and weaknesses;
The use of unique per-device password authentication mechanisms or even multi-factor authentication (MFA);
Creating suitable policies and procedures for vulnerability reporting, monitoring, and timely response;
Enabling secure software updates, which should be simple for the user to apply and automatically triggered whenever needed to prevent vulnerabilities;
Implementing secure storage of sensitive security parameters and secure communications (e.g., through best practice cryptography and authentication); and/or
Minimizing exposures to attacks, notably by reducing the unauthenticated disclosure of security-relevant information (e.g., software version) and only enabling software services that are used or required for the devices’ intended use.
2. ETSI’s “conformance assessment” methodology
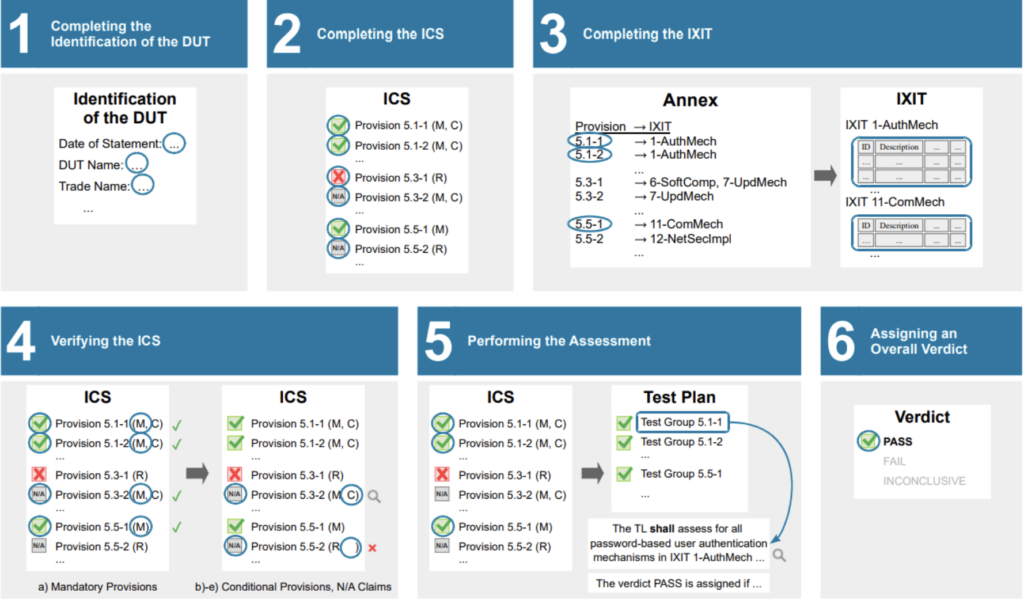
ETSI’s August 2021 specification provides developers, manufacturers, vendors, distributors (i.e., Supplier Organisations, or ‘SOs’) with test scenarios that they can leverage for testing their new IoT products (“DUTs”, which stands for Device Under Test) against the baseline requirements set out in the Standard.
SOs are required to request Test Laboratories (TL) – entities such as independent testing authorities, user organizations, or an identifiable part of a SO that carries out conformance assessments – to test the relevant product against the Standard. This means that the conformity assessment can either be led by a third-party (testing authority), second-party (user organization) or the SO itself (self assessment). Moreover, SOs should provide TL with all necessary information, including the Implementation Conformance Statement (ICS) and the Implementation eXtra Information for Testing (IXIT). Test Laboratories must operate competently to be able to generate valid results. The requirements for competence of TLs and independence of testing authorities acting as TLs are not developed under the ETSI framework.
Figure 1 contains a visual summary of the assessment procedure according to the specification. For brevity, we refer to the specification for the terminology.
Figure 1. A visual summary of the assessment procedure according to the specification (page 18)
Existing security certifications or third-party evaluations of the IoT device and/or its parts may be used partially as conformity evidence to complement or inform the assessment under the Specification. In this regard, the SO shall provide all necessary information (e.g., certification, certification details, and test reports) to verify the evidence to the TL.
3. Can we draw a parallel with Conformity Assessments under the AI Act?
In Section 3 we explore whether a conformity assessment performed under the proposed AI Act can be used to inform the conformance assessment of a consumer IoT device, or the other way around. For that, we first need to clarify the scope of the two assessments.
The AI Act conformity assessment refers to high-risk AI systems, which we analyze in more detail in another dedicated blog post). ETSI’s conformance assessment refers to consumer IoT devices which are non-exhaustively listed under the Standard (ETSI EN 303 645 V2.1.1).
Under the AI Act proposal, a high-risk AI system is assessed in terms of its conformity to the requirements listed under Chapter 2 of Title III. These relate to the quality of used datasets, technical documentation, record-keeping, transparency, human oversight, robustness, accuracy and cybersecurity. Under ETSI’s conformance assessment, a consumer IoT device is assessed against the Standard (ETSI EN 303 645 V2.1.1), which is mainly cybersecurity-oriented.
While the conformity assessment under the AI Act for high-risk AI systems will become legally mandatory for the systems’ providers once the final text is passed, ETSI’s conformance assessment is optional for IoT consumer products’ SOs, as it merely serves to attest the security and reliability of such products to consumers and other players on the market, and to obtain security labels on their products.
With regards to the latter distinction, it is worth noting that the requirement to carry out a conformity assessment applies to manufacturers of certain connected products. Manufacturers of “internet-connected radio equipment” under the RED’s Delegated Act are required thereunder to carry out a conformity assessment (Article 17), draw up an EU declaration of conformity, and affix a CE-marking (Article 10). Manufacturers can follow harmonized standards for conformity assessments to the extent these have been published in the Official Journal of the EU (see also, the European Commission’s standardization request). ETSI’s methodology remains optional for manufacturers of internet-connected radio equipment, even if it can be seen as a good guideline for the upcoming standards, and give them an advance start towards compliance with the RED and its Delegated Act. For completeness, we remark that the Delegated Act entered into force in January 2022 and will be enforceable by mid-2024.
A consumer IoT device under the ETSI framework and a high-risk AI system under the AI Act could co-exist if the following conditions are cumulatively met:
An IoT device which belongs to one of the devices non-exhaustively listed under the Standard is also covered by the Union harmonization legislation listed in Annex II of the AI Act Proposal (e.g., connected children’s toys);
The IoT device embeds an AI system which functions as a safety component of the device; and
The device as a whole requires a third-party conformity assessment under the New Legislative Framework legislation listed in Annex II of the proposed AI Act.
We further note that, in theory, high-risk AI systems “intended to be used for the ‘real-time’ and ‘post’ remote biometric identification of natural persons” – covered by the AI Act’s list of high-risk AI systems under Annex III (point 1) – can be integrated into a consumer IoT device (e.g., authentication through iris scan in a smart TV, or through voice recognition in smart home assistants).
In these cases, the provider of the AI system shall either: (i) carry out a first-party conformity assessment, provided it has applied harmonized standards referred to in Article 40, or, where applicable, common specifications referred to in Article 41 AI Act; or (ii) involve a third-party (notified body) in its conformity assessment. This means that where “the provider has not applied or has applied only in part harmonized standards referred to in Article 40, or where such harmonized standards do not exist and common specifications referred to in Article 41 are not available, the provider shall follow” the third-party conformity assessment route. Thus, until such approved harmonized standards or common specification become available, third-party conformity assessments will remain the rule for ‘real-time’ and ‘post’ remote biometric identification AI systems which are not strictly prohibited under Article 5 of the AI Act Proposal.
For more details on when a high-risk AI system is subject to a first- or third-party conformity assessment, you can read our earlier blog post here.
FPF Training: GDPR Data Protection by Design and by Default
Interested in learning more about the GDPR’s Article 25? Join us October 25 for an upcoming training session on Data Protection by Design and by Default (DPbD&bD) to hear more from FPF experts about responsibilities when engaging service providers, the role of technical and organizational measures, and Article 25’s intersection with AI and privacy enhancing technologies.
If the above conditions are met, the IoT device embeds a high-risk AI system and thus both assessments (under the AI Act and the Standard) are triggered, even if – as previously mentioned – ETSI’s conformance assessment is optional for SOs. Then the question of how the two assessments relate becomes relevant. According to the AI Act, compliance of the high-risk AI system with specific requirements should be assessed as part of the conformity assessment already foreseen for the IoT device (see Recital 63 and Art 43(3) AI Act). Furthermore, according to Article 24 and Recital 55 of the AI Act, it is the manufacturer of the IoT device that needs to ensure that the AI system embedded in the IoT device complies with the requirements of the AI Act.
It is possible that a device manufacturer may use a high-risk AI system already placed on the market by another supplier. In case the AI system has gone through a conformity assessment, then the IoT device manufacturer could use the existing assessment as a building block to perform the conformance assessment of the IoT device under ETSI’s methodology. This becomes particularly relevant given the fact that the proposed AI Act contains requirements for high-risk AI systems that resemble some of the ones contained in the ETSI European Standard. Most notably, these include requirements relating (1) to the automatic recording of events (‘logs’), (2) the transparency towards users, and (3) ensuring an appropriate level of accuracy, robustness, and cybersecurity. The latter requirement includes ensuring that the AI system is:
resilient as regards errors, faults, or inconsistencies that may occur within the system or the environment in which the system operates;
robust, which may be achieved through technical redundancy solutions, including backup or fail-safe plans; and
tamper-proof, in the sense of protected against attempts by unauthorized third parties to alter their use or performance by exploiting the system vulnerabilities.
In a different perspective, what is the practical effect on compliance with the AI Act’s requirements if a provider of a high-risk AI system embedded into a consumer IoT product passes the ETSI conformance assessment before it fulfills its conformity assessment obligations under the AI Act Proposal? By using the ETSI Standard, the manufacturer can benefit from the partial presumption of compliance with the Article 15 cybersecurity requirements set by Article 42(2) AI Act, as the Standard’s statement of conformity covers part of those requirements, as we have explained above.
Moving forward, it will be interesting to see whether more standards bodies will work on technical specifications that may be leveraged when carrying out conformity assessments under the proposed AI Act, as ETSI did for manufacturers of consumer IoT products. It will also be relevant to see whether the ETSI framework’s requirements are transposed into a technical standard for internet-connected radio equipment’s conformity assessments under the RED, and to keep up with the developments in the European Commission’s intention to propose a Cyber Resilience Act for IoT products that fall outside of the RED’ Delegated Act. The latter initiative intends to protect consumers “from insecure products by introducing common cybersecurity rules for manufacturers and vendors of tangible and intangible digital products and ancillary services”.
New Report on Limits of “Consent” in India’s Data Protection Law
Today, the Future of Privacy Forum (FPF) and the Asian Business Law Institute (ABLI), as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific,” are publishing the eleventh in a series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC).
This report provides a detailed overview of relevant laws and regulations in India, including:
notice and consent requirements for processing personal data;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in laws and regulations.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
Developments in India’s Data Protection Landscape
To date, India has not enacted comprehensive data protection legislation.
In 2017, against the backdrop of the Supreme Court of India’s landmark decision on the right to privacy in Justice KS Puttaswamy v. Union of India, India’s Ministry of Electronics and Information Technology established a Committee of Experts to study issues relating to data protection in India and draft personal data protection legislation. In July 2018, this Committee of Experts released draft legislation, which was tabled in the lower house of India’s Parliament as the “Personal Data Protection Bill 2019” (“PDP Bill”).
Between 2019 and 2021, the PDP Bill underwent review by a Joint Parliamentary Committee (“JPC”), which released a report (“JPC Report”) in December 2021 recommending numerous changes to the draft PDP Bill.
However, on August 3, 2022, India’s Government withdrew the PDP Bill and announced that it was working on a new and comprehensive framework of data protection legislation, which it aimed to release for public comment in early 2023.
India’s Existing Data Protection Landscape: The IT Act and its Subsidiary Legislation
Now that the PDP Bill has been withdrawn, India’s existing personal data protection framework will continue for the foreseeable future to be found in the Information Technology Act 2000 (“IT Act”) as amended in 2008 and its subsidiary legislation, including the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules 2011 (“IT Rules”).
The IT Rules apply to private-sector entities that possess and handle “sensitive personal data or information” (“SPDI”). The IT Rules define SPDI as personal information which consists of information relating to a person’s:
password;
financial information;
physical, physiological, or mental health condition;
sexual orientation;
medical records and medical history; or
biometric information;
as well as any information relating to the above, which is provided to a private-sector entity for providing a service received, or received by a private-sector entity for processing. This definition does not include information that is freely available, is in the public domain, or has been provided under India’s right-to-information laws.
The IT Rules require private-sector entities to implement certain practices to protect SPDI from unauthorized access and interference. These include requirements for private-sector entities to obtain consent for collecting SPDI and disclosing SPDI to third parties under certain circumstances, to provide a privacy policy, to notify data subjects that their SPDI is being collected, to provide data subjects with the option not to provide their SPDI or withdraw consent to collection of their SPDI, and observe certain data protection principles, such as purpose limitation. Private-sector entities which do not implement such requirements and thereby cause wrongful loss or gain are liable to pay damages to the affected party. Additionally, the IT Act prescribes various penalties for breaches of confidentiality and privacy obligations.
By default, the IT Rules require private-sector entities to obtain consent from data subjects before collecting their SPDI or disclosing SPDI to a third party. However, these requirements are subject to exceptions where:
there is a contract between the entity and the data subject, which provides for disclosure of SPDI;
it is necessary to disclose the SPDI to comply with a legal obligation; or
there is a legal request in writing from a relevant government agency for the purpose of identity verification, investigating crimes, and enforcing criminal law.
The IT Rules require that consent to collection of SPDI must be obtained in writing through letter, facsimile, or email from the provider of such data, potentially making collection of valid consent difficult in practice.
The IT Rules also enable private-sector entities to transfer SPDI out of India to a jurisdiction which provides the same level of protection to the SPDI as that provided under the IT Rules if a data subject consents to the transfer or if the private-sector entity has a contract with the data subject which provides for cross-border transfer of SPDI.
The Future of Data Protection Law in India
As stated above, the Indian Government is now working on new personal data protection legislation to replace the PDP Bill. At this stage, it remains unclear what shape this new legislation may take. However, it is possible that the new legislation will draw on the provisions of the erstwhile PDP Bill and the recommendations in the JPC Report, which were the result of years-long debates and consultations.
To that end, ABLI and FPF’s report on consent in India’s data protection framework outlines the key provisions of the PDP Bill and JPC Report on consent and alternative legal bases for processing personal data which provide a window into Indian regulators’ perspectives on these topics and may still be relevant in future legislation.
The PDP Bill provided a number of different legal bases for processing personal data, including consent but also several alternative bases which apply when processing of personal data is necessary for:
compliance with various legal obligations;
responding to emergencies;
employment-related purposes (including recruitment or termination of data subjects, verifying the data subject’s attendance, and assessing the data subject’s performance); and
“reasonable purposes” – which appear similar to the EU’s “legitimate interests,” but whose scope still remains uncertain.
The PDP Bill would have required consent for processing of personal data to be free, informed, specific, clear, and capable of being withdrawn. For consent to qualify as “informed” under the PDP Bill, the data controller would have to provide certain prescribed information at the time of data collection or a reasonable time thereafter.
Where the personal data to be processed consists of “sensitive personal data” (which is defined more broadly than SPDI under the IT Rules), PDP Bill would have required a data controller to inform the data subject of any purpose or operation of processing that is likely to cause significant harm to the data subject.
Finally, under the PDP Bill, consent for cross-border transfer of sensitive personal data would have to be “explicit.” The PDP Bill did not specify the conditions for explicit consent, though the wording of the relevant provision suggested that minimally, the data principal would have had to clearly and specifically consent to the transfer of his/her personal data out of India.
The PDP Bill proposed penalties for data controllers that process personal data in breach of the Bill’s consent requirements, which could extend to 4% of the data controllers total worldwide turnover in some cases. Data controllers who violate the PDP Bill’s consent requirements would also have been liable to pay compensation to data subjects who suffer harm as a result of such violations.
FPF Report: Developments in Open Banking, Key Issues from a Global Perspective
Authors: Hunter Dorwart, Daniel Berrick, Lee Matheson, and Dale Rappaneau
Dale Rappaneau was a former FPF Policy Intern.
In FPF’s report, Developments in Open Banking, Key Issues from a Global Perspective, explores how ten different jurisdictions have approached open banking regulation, including questions related to privacy and data protection. The report was developed as part of the joint open banking conference FPF co-hosted with the OECD in March 2022.
Mobile peer-to-peer payments are now ubiquitous. These and other services do or will exist and are part of a large trend called “open banking.” Policymakers across the world have leveraged open banking tools to accomplish a wide range of goals, from promoting competition in the banking sector to facilitating innovation in financial technology services. Open banking tools, when implemented, may allow users to import account data into a tax return easily or to link and aggregate all their accounts for clear financial planning.
Efforts to realize open banking’s benefits must navigate the complex market and regulatory factors. At the heart of open banking lies the sharing of personal information, which creates a plethora of data protection and security risks. If unaddressed, these risks may inadvertently hinder open banking policies or implementation, create tension between different legal obligations, or result in harm to vulnerable individuals and organizations. As governments grapple with such challenges, the implementation of open banking frameworks remains a daunting task that could create significant costs and burdens for businesses and governments across the world.
FPF’s report explores the key similarities and differences between the ten identified jurisdictions across several topics. Each topic represents a fundamental component of open banking in these jurisdictions around the world and includes:
A definition of “open banking.”
The three general approaches to open banking regulation
What entities, services, and categories of data do regulations cover?
Variations in regulatory power and technical specification
Open banking’s interaction with data protection and privacy law
The FPF hopes that this report will help stakeholders better understand the key issues that generate confusion and hinder open banking practices, therefore providing the impetus for solutions.
Introduction to the Conformity Assessment under the draft EU AI Act, and how it compares to DPIAs
The proposed Regulation on Artificial Intelligence (‘proposed AIA’ or ‘the Proposal’) put forward by the European Commission is the first initiative towards a comprehensive legal framework on AI in the world. It aims to set rules on specific AI applications in certain contexts and does not intend to regulate AI technology in general. The proposed AIA includes specific provisions applicable to AI systems depending on the level of risk to the health, safety, and fundamental rights of individuals that they pose. These scalable rules vary from banning certain AI applications to providing heightened obligations related to high-risk AI systems – such as strict quality rules for training, validation, and testing datasets, to setting in place transparency rules for certain AI systems.
A key obligation imposed on high-risk AI systems are Conformity Assessments (CA), which providers of such systems must perform before they are placed on the market. But what are Conformity Assessments? What do they review and how do they compare to Data Protection Impact Assessments (DPIAs)? In this blogpost, and after a short contextual introduction (1), we break down the CA legal obligation into its critical characteristics (2), aiming to understand: when is a CA required, who is responsible for performing a CA, in what way should the CA be performed, and whether there are other actors involved in the process. We then explain the way that the CA relates to the General Data Protection Regulation’s (GDPR) DPIA obligation (3) and we conclude with 4 key takeaways on the AIA’s CA (4).
1. Context: The EU AI Act and the universe of existing EU law it has to integrate with
The proposed AIA, according to its Preamble, is a legal instrument primarily targeted at ensuring a well functioning internal market in the EU that respects and upholds fundamental rights. 1 Being a core part of the EU Digital Single Market Strategy, the drafters of the AIA explain in a Memorandum accompanying it that the Act aims to avoid fragmentation of the internal market by setting harmonised rules on the development and placing on the market of ‘lawful, safe and trustworthy AI systems’. One of the announced underlying purposes of the initiative is to ensure legal certainty for all actors in the AI supply chain.
The proposed AIA is built on a risk-based approach. The legal obligations of responsible actors depend on the classification of AI systems based on the risks they present to health, safety, and fundamental rights. Risks vary from ‘unacceptable risks’ (that lead to prohibited practices), ‘high risks’ (which trigger a set of stringent obligations, including conducting a CA), ‘limited risks’ (with associated transparency obligations), to ‘minimal risks’ (where stakeholders are encouraged to build codes of conduct).
The draft AIA is being introduced in an already existing system of laws that regulate products and services intended to be placed on the European market, as well as laws that concern the processing of personal data, the confidentiality of electronic communications or intermediary liability legal regimes.
For instance, the proposed AIA and its obligations aim to align with the processes and requirements of laws that fall under theNew Legislative Framework (NLF) in order to ‘minimize the burden on operators and avoid any possible duplication’ (Recital 63). The application of the AIA is intended to be without prejudice to other laws and its drafters state in the Preamble that it is laid down consistently with the Regulations that are explicitly mentioned.
In the EU context, the CA obligation is not new. CAs are also part of several EU laws on product safety. For example, in cases where the AI system is a safety component of a product which falls under the scope of NLF laws, a different CA may have already taken place.
1.1 The definition of an AI system
The proposed AIA defines an AI system as ‘software that is developed with one or more of the techniques and approaches listed in its Annex I and can, for a given set of human-defined objectives, generate outputs such as content, predictions, recommendations, or decisions influencing the environments they interact with’ (Article 3(1)).
Whether a software qualifies as an AI system under the Proposal depends on if it falls under Annex I of the draft Regulation, which includes a finite list of software such as machine learning approaches, logic- and knowledge-based approaches, and statistical approaches. According to Article 4 AIA, this Annex can be amended by the European Commission following the adoption of delegated acts in light of market and technological developments.
An AI system can be designed to operate with varying levels of autonomy and be used on a stand-alone basis or as a component of a product, irrespective of whether the system is physically integrated into the product (embedded) or serves the functionality of the product without being integrated therein (non-embedded).
1.2 High-risk AI systems
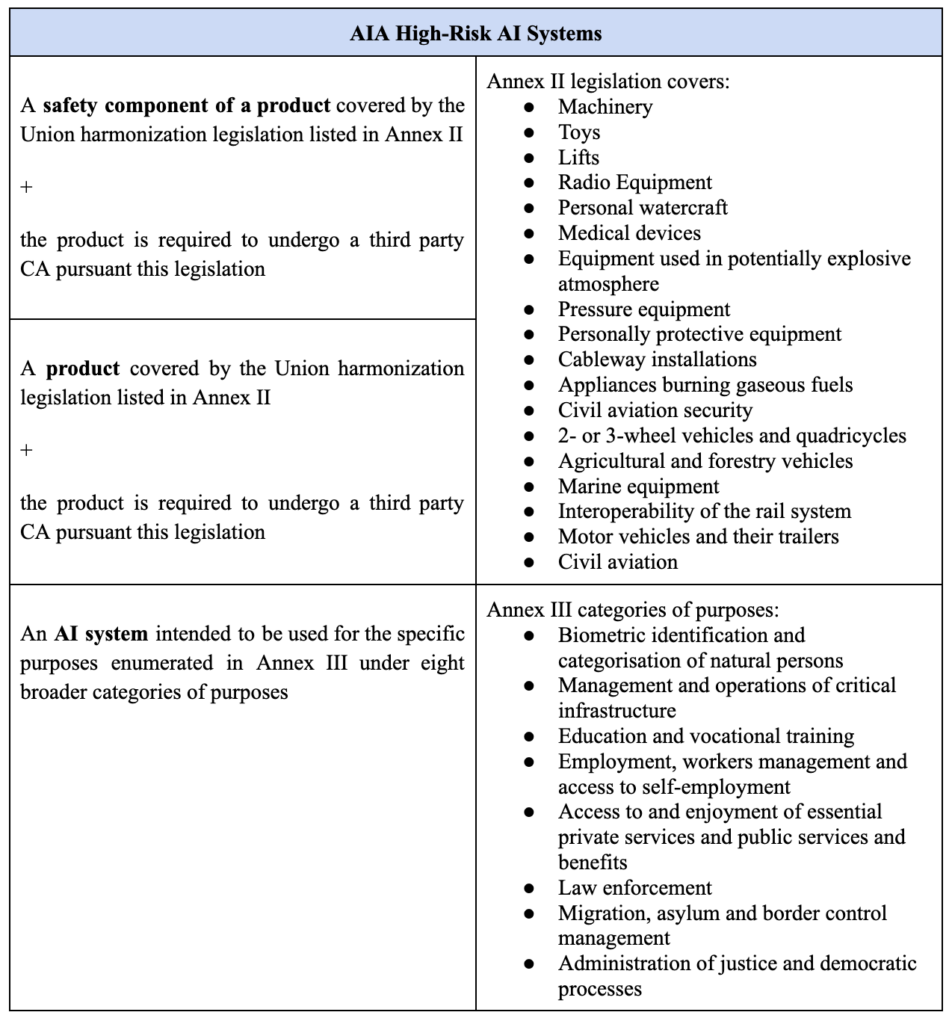
The AIA offers no definition of a ‘high-risk AI system’, but it classifies specific AI uses as high-risk and enumerates them in relation to Annexes II and III of the Proposal (see Table 1 below).
Table 1. High-risk AI systems as included in EU’s AI Act proposal.
Annex III to the AIA, which details high-risk AI systems, can be amended by the European Commission following the conditions set by Article 7. For example, where an AI system poses a risk of harm to health and safety, or a risk of adverse impact on fundamental rights, the Annex could be amended.
The current Presidency of the Council, held by the Czech Republic, has proposed to narrow down the list of high-risk AI systems as part of the current legislative negotiations on the text of the AIA.
2. The Conformity Assessment obligation, explained
The Conformity Assessment (CA) is a legal obligation designed to foster accountability under the proposed AIA that only applies to AI systems classified as ‘high-risk’. According to its AIA definition, CA is the ‘process of verifying whether the requirements set out in Title III, Chapter 2of this Regulation relating to an AI system have been fulfilled’, with Title III containing provisions that only apply to high-risk AI systems.
2.1 Requirements for High-risk AI systems that also form the object of the CA
The requirements the AIA provides for high-risk AI systems are ‘necessary to effectively mitigate the risks for health, safety and fundamental rights, as applicable in the light of the intended purpose of the system’ (Recital 43). They relate to:
a) The quality of data sets used to train, validate and test the AI systems; the data sets have to be ‘relevant, representative, free of errors and complete’, as well as having ‘the appropriate statistical properties (…) as regards the persons or groups of persons on which the high-risk AI systems is intended to be used’ (Recitals 44 and 45, and Article 10),
b) Technical documentation (Recital 46, Article 11, and Annex IV),
c) Record-keeping in the form of automatic recording of events (Article 12),
d) Transparency and the provision of information to users (Recital 47 and Article 13),
e) Human oversight (Recital 48 and Article 14), and
f) Robustness, accuracy and cybersecurity (Recitals 49 to 51, and Article 15).
Importantly,most of these requirements must be embedded in the design of the high-risk AI system. Except for the technical documentation that should be drawn up by the provider, the other requirements need to be taken into consideration from the earliest stages of designing and developing the AI system. Even if the provider is not the designer/developer of the system, they still need to make sure that requirements under that Chapter are embedded in the system to achieve conformity status.
The AIA also establishes a presumption of compliance with the requirements for high-risk AI systems, where a high-risk AI system is in conformity with relevant harmonised standards. In case harmonised standards do not exist or are insufficient, the European Commission may adopt common specifications, conformity with which also leads to such a presumption of compliance. In cases where a high-risk AI system has been certified or for which a statement of conformity has been issued under a cybersecurity scheme pursuant to the Cybersecurity Act, there is a presumption of conformity with the AIA’s cybersecurity requirements, as long as the certificate or statement covers them.
2.2 When should the CA be performed?
A CA has to be performed priortoplacing an AI system on the EU market, which means prior to making it available (i.e., supplying for distribution or use), or prior to putting an AI system into service, which means prior to its first use in the EU market, either by the system’s user or for [the provider’s] own use.
Additionally, a new CA has to be performed when a high-risk AI system is substantially modified, which is when a change affects a system’s compliance with the requirements for high-risk AI systems or results in a modification to the AI system’s intended purpose. However, there is no need for a new CA when a high-risk AI system continues to learn after being placed on the market or put into service as long as these changes are pre-determined at the moment of the initial CA and are described in the initial technical documentation.
The proposed AIA introduces the possibility of derogating from the obligation to perform a CA ‘for exceptional reasons of public security or the protection of life and health of persons, environmental protection and the protection of key industrial and infrastructural assets’, under strict conditions (see Article 47).
2.3 Who should perform the CA?
The CA is primarily performed by the ‘provider’ of a high-risk AI system, but it can also be performed in specific situations by the product manufacturer, the distributor, or the importer of a high-risk AI system, as well as by a third party.
The ‘provider’ is ‘a natural or legal person, public authority, agency, or other body that develops an AI system or that has an AI system developed with a view to placing it on the market or putting it into service under its own name or trademark, whether for payment or free of charge’ (Article 3(2)). The provider can be, but does not have to be the person who designed or developed the system.
There are two cases where the provider is not the actor responsible for performing a CA, where instead it is the duty of:
a) the Product Manufacturer, if, cumulatively:
the high-risk AI system relates to products for which the laws in Annex II section A apply,
the system is placed on the market or put into service together with the product, AND
under the name of the product manufacturer (Article 24, and Recital 55).
b) The ‘Distributor’, ‘Importer’ or ‘any other third-party’, if:
they place on the market or put into service a high-risk AI system under their name or trademark,
they modify the intended purpose (as determined by the provider) of a high-risk AI system already placed on the market or put into service, in case of whichthe initial provider is no longer considered the provider for the purposes of the AIA, OR if
they make a substantial modification to the high-risk AI system. In this case,the initial provider is also no longer considered the provider (Article 28).
2.4 The CA can be conducted internally or by a third party
There are two ways in which a CA can be conducted – either internally, or by a third party.
In the internal CA process, it is the provider (or the distributor/importer/other third-party) who performs the CA. The third-party CA is performed by an external ‘notified body’. These ‘notified bodies’ are conformity assessment bodies that satisfy specific requirements provided by AIA in Article 33 and have been designated by the national notifying authorities.
Typically, the rule is to have an internal CA, with the drafters of the AIA arguing that providers are better equipped and have the necessary expertise to assess AI systems’ compliance. (Recital 64). A third party CA is required only for AI systems intended to be used for the real-time and post remote biometric identification of people that are not applying harmonized standards or the common specifications of Article 41. Additionally, if the high risk AI system is the safety component of a product and specific laws enumerated in Annex II, Section A apply to it, the provider must follow the type of CA process stipulated in the relevant legal act.
FPF Training: The EU’s Proposed AI Act
The EU’s Artificial Intelligence (AI) Act is in the final stages of adoption in Brussels, and will be the first piece of legislation worldwide regulating AI. Join us for an FPF Training virtual session to learn about the act’s extraterritorial reach, the legal implications for providers and deployers of AI, and more.
In the case of the internal CA process, the provider/distributor/importer/other third-party has to:
verify that the established quality management system is in compliance with the requirements depicted in Article 17 (entitled ‘Quality Management System’),
examine the information in the technical documentation to assess whether the requirements for high risk AI systems are met, and
verify that the design and development process of the AI system and its post-market monitoring (Article 61) is consistent with the technical documentation.
After the responsible entity performs an internal CA, it draws up a written EU declaration of conformity for each AI system (Article 19(1)). Annex V of the AIA enumerates the information to be included in the EU declaration of conformity. This declaration should be kept up-to-date for 10 years after the system has been placed on the market or put into service and a copy of it should be provided to the national authorities upon request.
The provider or other responsible entity also has to affix a visible, legible, and indelible CE marking of conformity according to the conditions set in Article 49. This process must also abide by the conditions set out in Article 30 of Regulation (EC) No 765/2008, notably that the CE marking shall be affixed only by the provider/other entity responsible for the conformity of the system. To conclude the process, the provider has to draw up an EU declaration form – containing, inter alia, a description of the conformity assessment procedure performed (Article 19(1)).
In the case of a third-party CA, the notified body assesses the quality management system and the technical documentation, according to the process explained in Annex VII. The third-party CA process is activated after the responsible entity applies to the notified body of their choice (Article 43(1)). Annex VII enumerates the information that should be included in the application to the notified body. Both the quality management system and the technical documentation must be in the provider’s application.
If the notified body finds the high-risk AI system to be in conformity with the requirements, it will issue an EU technical documentation assessment certificate (Article 44), which has limited time validity and can be suspended or withdrawn by the notified body. Similarly to the internal CA, under the third-party CA process, the provider then has to draw up the EU declaration of conformity and affix the CE marking of conformity. To conclude the process, the provider has to draw up an EU declaration form – containing, inter alia, a description of the conformity assessment procedure performed (Article 19(1)).
In case the notified body assesses that the high-risk AI system is not in conformity with the requirements for high-risk AI systems, this has to be communicated and explained in detail to the provider or other responsible entity. Article 45 grants the provider (or any actor with a legitimate interest) the right to appeal against the decision of the notified body. In this case, the responsible actor must take the necessary corrective actions. These actions may vary from bringing the system back to conformity with the requirements, to withdrawing or recalling the system from the market (Article 61).
2.6 The CA is not a one-off exercise
Providers must establish and document a post-market monitoring system, which aims to evaluate the continuous compliance of AI systems with the AIA requirements for high-risk AI systems. The post-market monitoring plan can be part of the technical documentation or the product’s plan. Additionally, in the case of a third-party CA, the notified body must carry out periodic audits to make sure that the provider maintains and applies the quality management system.
3. Conformity Assessment & Data Protection Impact Assessment (DPIA)
This section analyzes comparatively the proposed AIA’s CA and the DPIA as introduced in the GDPR. Although both obligations require an assessment to be performed on high risk processing operations (in the case of a DPIA) and AI systems (in the case of the CA), there are both differences and commonalities to be highlighted.
The DPIA is a legal obligation under the GDPR which requires that the entity responsible for a personal data processing operation (the ‘controller’) carry out an assessment of the impact of the envisaged processing on the protection of personal data, particularly where the processing in question is likely to result in a high risk to the rights and freedoms of individuals, prior to the processing taking place (Article 35 GDPR).
Under the GDPR, the data controller is the actor that determines the purposes and the means of the data processing operation. The data controller is responsible for compliance with the law, for assessing whether a DPIA shall be performed, and for performing any DPIA it determines is necessary. Under the AIA, and as explained in Section 2.3, the CA is primarily conducted by the ‘provider’ of a high-risk AI system (or by the product manufacturer, the distributor or the importer, or a third party, when specific conditions are met).
Notably, in the context of AI systems, it will likely often be the case that the AIA’s ‘user’ will qualify as a ‘data controller’ under the GDPR, and when this is the case the ‘user’ will be responsible for any required DPIA, including those on the qualifying processing operations underpinning an AI system, even if a different entity is the ‘provider’ responsible for the CA required by the AIA. In these situations, it may be the case that the relevant parts of the CA conducted by the provider of the AI system (such as those related to the compliance with the data quality and cybersecurity requirements) may inform the DPIA the user has to conduct detailing the risks posed by the processing activity and the measures taken to address those risks.
In their Joint Opinion on the AIA, the European Data Protection Supervisor (EDPS) and the European Data Protection Board (EDPB) recommend that the ‘provider’ should perform an initial risk assessment on an AI system paying due regard to the technical characteristics of the system – so ‘providers’ do retain some responsibility even if they are not a given system’s GDPR ‘data controller’. If an actor is both the AIA ‘provider’ and the GDPR ‘data controller’ with regard to an AI system that will process personal data, then that actor will perform both the CA and the DPIA.
3.1 Conditions that trigger the CA and DPIA legal obligations
The DPIA is triggered in cases where an activity qualifies as ‘processing of personal data’ and is ‘likely to result in a high risk to the rights and freedoms of natural persons’. Whether processing is likely to result in a high risk or not, a preliminary assessment (otherwise called ‘screening test’) needs to be made by the data controller. The law itself, as well as the European Data Protection Board, have provided guidance as to the types of processing that require a DPIA under the GDPR, but they are not overly prescriptive. Additionally, national supervisory authorities have published lists (so called ‘blacklists’) of processing operations that always require a DPIA to be conducted (see, for example, the lists of the Polish and Spanish DPAs). These lists often include processing operations which can be associated with an AI system as defined under the proposed AIA, such as ‘evaluation or assessment, including profiling and behavioral analysis’, or ‘processing that involves automated decision-making or that makes a significant contribution to such decision-making’.
In return, the proposed AIA specifies which AI systems qualify as ‘high-risk’ and therefore require a CA under the AIA. It does not leave it to the discretion of the responsible entity to assess whether a CA is required. Importantly, for a CA to be triggered it does not matter whether personal data is processed, even though it might be processed as part of the training and use of the AI system; it suffices that an AI system falls under the scope of AIA and qualifies as ‘high-risk’.
In situations where a high-risk AI system involves processing personal data, it likely requires a DPIA as well as a CA. In these situations, depending on whether the responsible entity to conduct a CA is also a controller under the GDPR, then both a DPIA and a CA will be conducted by the same entity, and the question of whether there is any overlap between the two assessments arises. Both processes are risk-based assessments of particular systems with separately enumerated requirements; in order to avoid unnecessary duplication of work or contradictory findings, it is likely that one can feed into the other.
3.2 Scope of the assessments
Each assessment has a different scope. For a DPIA, the data controller must assess the ‘processing operation’ in relation to the risks it poses to the rights and freedoms of natural persons. More specifically, the data controller must look into the nature, scope, context, and purposes of the processing, and its necessity and proportionality to its stated aim.
For the CA, the provider must assess whether a system or product has been designed and developed according to the specific AIA requirements imposed on high-risk AI systems. Some of these requirements have data protection implications, particularly those related to the quality of the data sets when the data used for training, validation and testing are personal data. Among other obligations, for all high-risk AI systems such data must be examined in view of possible biases, must be subjected to a prior assessment of ‘availability, quantity, and suitability’, and must also be ‘relevant, representative, free of errors, and complete’.
These bias analysis requirements also implicate the GDPR, which specifically imposes additional restrictions on the processing of special category data (for example, data related to religious beliefs, racial or ethnic origin, health, sexual orientation) via Article 9. Processing special category data is generally prohibited by the GDPR unless the processing meets one of a closed list of exemptions; the AIA’s requirement to examine training, validation, and testing data for biases brings instances where processing to detect bias requires the use of such data within the GDPR exemption authorizing “processing … necessary for reasons of substantial public interest, on the basis of Union or Member State law” so long as that the AIA’s requirements that it include ‘state-of-the-art security and privacy-preserving measures such as pseudonymisation, or encryption where anonymisation may significantly affect the purpose’ are also followed. The AIA further requires that high risk training, validation, and testing data include, to the extent required by the intended purpose, ‘the characteristics or elements that are particular to the specific geographical, behavioral or functional setting within which the high-risk AI system is intended to be used’.
These requirements are intertwined with the lawfulness, fairness, purpose limitation, and accuracy principles of the GDPR. Additionally, requirements for high-risk AI systems broadly intended to impose ‘appropriate data governance and management practices’ on such systems such as those related to transparency and to human oversight may draw parallels with some of the requirements imposed by the GDPR on solely automated decision-making requiring the provision of information about the logic involved therein, and the right to human intervention.
These requirements for high-risk AI systems are part of the scope of a CA. They are demonstrably intertwined with GDPR provisions insofar the training, validation, and testing data are personal data. As a result, there will likely be instances where a CA and a DPIA are relevant for each other – and where both are required, both must be conducted affirmatively (either prior to the processing activity or prior to the placement of a high-risk AI system on the market).
3.3 Content of the assessment
When conducting a DPIA, the data controller has to identify risks to rights and freedoms, assess the risks in terms of their severity and the likelihood of them being materialized, and to finally decide on the appropriate measures that will mitigate the high risks. In contrast, a CA requires examining whether an AI system meets specific requirements set by the law: (1) whether the training, validation, and testing of data sets meet the quality criteria referred to in Article 10 AIA, (2) whether the required technical documentation is in place, (3) whether the automatic recording of events (‘logs’) while the high-risk AI systems is operating is enabled, (4) whether transparency of the system’s operation is ensured and enables users to interpret the system’s output and use it appropriately, (5) whether human oversight is possible, and (6) whether accuracy, robustness and cybersecurity are guaranteed.
3.4 Aim of the legal obligations
The DPIA is a major tool for accountability that forces data controllers to make decisions on the basis of risks. It also forces them to report on the decision-making process. The ultimate goal of the DPIA is to hold data controllers accountable for their actions and to guarantee a more effective protection of individuals’ rights. The CA, on the other hand, is of a somewhat different nature. The CA aims to guarantee compliance with certain requirements which, according to Recitals 42 and 43, constitute mitigation measures for systems that introduce high risks. The CA aims to guarantee that the mitigation measures (so the requirements) set by the law are complied with.
Key Takeaways
The proposed AIA is currently being reviewed separately by the EU co-legislators– the European Parliament and the Council of the EU – as part of the legislative process. In that context, the CA process as proposed by the Commission may suffer changes. For instance, Brando Benifei, the Act’s co-rapporteur in the European Parliament, has revealed a preference for enlarging the cases where a third-party CA would be required. Nonetheless, we note that the CA is a well-established process with a long history in the EU, and an important EU internal market practice, which may prevent misalignment with other EU legal instruments where CA are mandatory. Having this background in mind, here are our key takeaways:
The AIA aims to uphold legal certainty and avoid fragmentation and confusion for actors involved in the AI supply chain. This becomes clear when looking at how the proposed AIA: (a) builds on existing laws (e.g., by requiring CE marking and referring to legal acts under the NLF); and (b) aligns most of its definitions with other relevant legal acts (e.g., ‘conformity assessment’, ‘provider’, and ‘placing on the market’). The structure and the content of the proposed AIA reminds us that it is part of a system of laws that regulate products and services placed on the EU market.
While the DPIA and the CA obligations are different in scope, content, and aims, there are also some areas in which they are connected and might even overlap, whenever high-risk AI systems involve processing of personal data. One of the essential questions is who is the entity responsible for conducting each of them. The ‘provider’ is usually the entity responsible for conducting CAs, and providers of high-risk AI systems that process personal data are more likely to have the role of ‘processors’ under the GDPR in relation to the ‘user’ of an AI system, as indicated by the EDPS and EDPB in their Joint Opinion. Only GDPR controllers have the obligation to conduct DPIAs. Controllers are more likely to be ‘users’ of high-risk AI systems under the AIA. Processors would thus have to assess their datasets against bias, for accuracy, and against whether they account for relevant characteristics for a specific geographical, behavioral, and functional context as part of the CA process, which goes beyond the obligations that they have under the GDPR in relation to the same personal data. CAs of high-risk AI systems involving processing of personal data can complement or be relied on by controllers conducting DPIAs. The AIA and its CA obligation might thus fill in a gap with regard to the responsibilities of providers of systems and data controllers who use these systems to process personal data. However, as we showed in Section 3 above, if an actor is both the AIA ‘provider’ and the GDPR ‘data controller’ with regard to an AI system that will process personal data, then that actor will perform both the CA and the DPIA.
Although the CA process may not change, some other elements of the AIA are highly contentious. The definition of what an AI system is and the final classification of AI systems as ‘high-risk’ are at the heart of the current debates around the proposed AIA. In addition, there have been calls for clarifying the role of each actor under the AIA, with some stakeholders calling for increased obligations of AI systems’ users. Due to the complexity of the AI supply chains, it is crucial to identify the actors and their relevant responsibilities.
Making good use of the existing resources in order to avoid duplication of processes and efforts is among the AIA’s aims. Except for the requirement to align the CA processes applicable to safety components of a product and to the product itself, the proposed AIA encourages internal CA more than third-party CA, due to the arguably stronger expertise of AI systems’ providers. It also encourages the adoption of standards or common technical specifications that could lead to presumption of compliance of high-risk AI systems with mandatory requirements.
1 Article 114 of the Treaty on the Functioning of the European Union (TFEU) – the so-called internal market legal basis – constitutes the primary legal basis of the proposed AIA. Article 16 TFEU – the right to the protection of personal data – also constitutes a legal basis for the future regulation, but only as far as specific rules on the protection of individuals with regard to the processing of their personal data are concerned.
FPF and Singapore PDPC Event: “Data Sovereignty, Data Transfers and Data Protection – Impact on AI and Immersive Tech”
On July 21, the Future of Privacy Forum (FPF) and Singapore’s Personal Data Protection Commission (PDPC) co-hosted a workshop as part of Singapore’s Personal Data Protection Week, titled “Data Sovereignty, Data Transfers and Data Protection – Impact on AI and Immersive Tech” at Marina Bay Sands Expo and Convention Center in Singapore.
The event focused on international data transfers and their importance to new and emerging technologies.
FPF moderated two panel discussions, bringing together experts and thought leaders from academia, government, industry, and law:
The first panel, titled “Data Localization vs International Data Transfers,” compared and analyzed the different international data transfer frameworks and data localization requirements that exist around the world today. This panel was moderated by Dr. Gabriela Zanfir-Fortuna (Vice President for Global Privacy, FPF), and attended by panelists Yeong Zee Kin (Deputy Commissioner, PDPC), Lara Kehoe Hoffman (Vice President, Data Privacy and Security (Legal) and Global Data Protection Officer, Netflix), Takeshige Sugimoto (Managing Director and Partner, S&K Brussels LLP; Director, Japan DPO Association), Tobias Judin (Head of International Office, Norwegian Data Protection Authority), and David Hoffman (Steed Family Professor of the Practice of Cybersecurity Policy, Duke University).
The second panel, titled “Old Challenges of New Technologies – AI and Immersive Tech,” explored how the landscape of international data transfer laws and regulations impacts artificial intelligence (AI) and immersive technology, including augmented reality (AR), virtual reality (VR), and the “metaverse.” This panel was moderated by Josh Lee (Director, FPF APAC) and attended by panelists Raina Yeung (Head of Privacy and Data Policy Engagement, Meta), Simon Chesterman(Dean, Faculty of Law, National University of Singapore), Marcus-Bartley Johns (Asia Regional Director, Government Affairs and Public Policy, Microsoft), Eunice Lim (Director for Corporate Affairs, Asia Pacific, Workday), and Jules Polonetsky (Chief Executive Officer, FPF).
This post summarizes the exciting discussions from these two panels and presents the key takeaways.
Panel 1: “Data Localization vs International Data Transfers”
The first panel stressed the need to distinguish data localization measures from transfer obligations, as both have different goals and use different mechanisms to accomplish those aims. Yeong Zee Kin explained that data localization and data transfer obligations are two separate but overlapping issues. From a regulatory perspective, data localization measures either prohibit data flows or enforce local storage and processing, while data transfer obligations allow data to flow in a protected and safe manner. Data localization measures may appear in privacy laws as well as sectoral regulations, and target different types of data (including non-personal data in some circumstances). Data transfer mechanisms also come in many forms such as certification, standard contractual clauses (SCCs), and binding corporate rules (BCRs), each with their own method of ensuring data protection. The range of transfer mechanisms provide solutions that can be tailored for different use cases and scale of data transfers.
Yeong stressed that global stakeholders need to reset the conversation around data flows in a way that respects different cultures and promotes global consensus around key issues like supervisory and law enforcement access to data. This resonated with Tobias Judin who said that the EU can continue to play a strong role to promote consensus around data transfers. He stressed that while countries pass their own rules, there are still options to facilitate data flows and that governments can accomplish data protection goals without passing localization requirements. Judin also highlighted how the EU has created incentives for other countries to adopt privacy laws that make sense in their own legal and cultural contexts. While the standard for adequacy is strict, other countries have been able to pass laws that meet the requirements.
Landscape of Data Localization
Takeshige Sugimoto presented an overview of the scattered landscape of data localization. He stressed that tensions in cross-border data flows have become more global and now involve numerous bilateral, country-to-country cases. For instance, beyond the transatlantic data transfers debate, tensions are emerging in data flows in the context of EU-Russia and EU-China relations. Sugimoto indicated that if European or American regulators restrict data transfers to China, the latter could retaliate in kind. This is becoming a real possibility, as regulators in both the EU and the U.S. have shown willingness to take enforcement actions against Chinese companies and have even begun to promote their own localization requirements.
Sugimoto highlighted how some international developments may help mitigate the risk of fragmentation, including the Global Cross-Border Privacy Rule (CBPR) certification system, but that such developments will not completely alleviate tensions in global data transfer rules. He stressed that on the one hand, if the U.K. loses adequacy from the EU and in turn participates in the CBPR system, the EU may be left behind. On the other hand, even if alternative frameworks become a global standard and mitigate risks of fragmentation, China’s data localization regime will continue to exist and exert influence abroad.
Despite this, Sugimoto indicated that there are positive developments. Beyond the U.S., the EU, and China, other countries are playing a strong role in shaping conversations around data flows. Both Japan and South Korea have demonstrated that it is possible to promote an international standard for data protection while maintaining unique legal systems and cultures.
The panel also explored the perspective of the private sector with respect to data localization and the challenges companies face when responding to such measures.
Cybersecurity and Localization
Data localization also raises security concerns, as organizations and governments rely on information sharing to monitor and respond to security incidents and threat vulnerabilities. As David Hoffman indicated, governments are adopting data localization measures not only for privacy reasons but also for other legitimate government purposes such as promoting law enforcement, ensuring national security, and having enough data available to assist with tax collection.
Hoffman stressed that there is a need for the data protection community to address each of these motivations separately while recognizing and reiterating that privacy and security mutually reinforce each other. Indeed, as Hoffman explained, safeguarding security was one of the primary goals of the 1980 Privacy Guidelines from the Organization for Economic Cooperation and Development (OECD). Security threats can undermine privacy because they increase the risk that personal information will be exposed.
At the same time, cross-border data flows are a core component of how companies and governments address and mitigate such threats through the sharing of threat and attack indicators that often include IP addresses that can fall under the definitions of “personal data”. While collecting and transferring personal data can put privacy at risk, if that use of data substantially increases cybersecurity, it may have a net positive privacy effect. That net positive effect may then be increased with effective use limitations and accountability measures, instead of reliance on collection limitations and/or data localization. Hoffman affirmed that one step towards realizing this involves understanding the rationales and motivations behind data localization and determining other methods to satisfy those government interests while still allowing for the transfer of data that is necessary to promote effective cybersecurity.
Panel 2: “Old Challenges of New Technologies – AI and Immersive Tech”
The second panel focused on the risks and opportunities presented by new and emerging technologies, like AI, AR/VR, and the “metaverse,” which often involve the collection and processing of personal data. Panelists also considered how these technologies could be regulated in the future and how measures to regulate international data transfers may impact the development and deployment of these technologies.
Artificial Intelligence (AI)
Marcus Bartley-Johns explained that AI is not a future possibility but rather a present reality as people regularly interact with AI systems in their professional and personal lives through email, social media, spell checkers, and security and threat protection, among others. Raina Yeung explained that AI is already an essential component in Meta’s system and is used for a wide range of purposes, from polling, to serving advertisements, to taking down misleading and harmful content. She highlighted that AI is an area of strategic importance both for governments and industry as it drives economic development and helps to find solutions to global challenges. Eunice Lim reiterated that AI impacts, and will continue to impact, the way that we live and work. However, she also noted that AI is not meant to replace human workers, but rather to augment us and make life easier for us by taking away repetitive tasks.
Jules Polonestky noted that AI may also present new challenges in terms of deception and discrimination. Polonetsky explained that both the societal data used to train AIs, and how AIs are deployed in practice, can reflect social inequalities and prejudices. Yeung agreed and added that although AI may bring benefits, it also raises the risk of potential harms and therefore must be developed and deployed responsibly. Bartley-Johns stressed that it is important to look at the context of AI deployments as not all applications impact privacy or rights. To illustrate this, Bartley-Johns drew a comparison between AI-based facial recognition systems, which process personal data and could impact data subjects’ privacy and legal rights if used, for example, to deny data subjects access to a service or cause them to be suspected of a crime, and AI-based malware detection systems, which may not process personal data but instead focus only on telemetry from attempts to access devices and systems.
Bartley-Johns explained that a common challenge is viewing responsible AI as a purely technical issue. In his view, implementing responsible AI is a socio-technical challenge: how the technology functions is only the beginning; broader concerns are how humans will interact with, have oversight over, and (where necessary) exercise decision-making power over the AI. Limexplained that the main risk from irresponsible use of AI is loss of trust and called on the public and private sectors to co-create standards and principles for AI. In this respect, Lim highlighted that Workday is working with developers to test and implement procedures for identifying and mitigating instances of AI bias. Yeung shared that Meta’s dedicated and cross-disciplinary Responsible AI (RAI) team builds and tests approaches to help ensure that their machine learning (ML) systems are designed and used responsibly.
Panelists all stressed that regulation has an important role to play in building citizens’ confidence in the technology and setting a baseline for companies’ responsibilities. Bartley-Johns highlighted that the difficulty is in getting the regulation right – ensuring that the technology is available to companies of all sizes and that data is not locked up with a minority of companies. Lim stressed that regulation should be risk-based, identifying the AI use cases which present the highest risks and directing resources to mitigate unintended consequences, and should recognize the different actors in the AI ecosystem, including those who develop AI, and those who deploy AI. Though there is ongoing debate about who is best placed to address these challenges, Polonetsky suggested that privacy professionals could play a role by, for example, undertaking data protection impact assessments, raising issues internally when they arise, and engaging proactively with affected communities to understand their positions and give them a voice. At the same time, Polonetsky also considered that expectations and norms around AI will change over time.
Simon Chesterman explained that conversations around AI regulation tend to assume that new laws would have to be drafted to regulate AI while overlooking the significant challenge that implementing these laws would present in practice. In Chesterman’s view, the central question in regulating AI is not whether to pass new laws but rather, how to apply existing laws to new use cases involving AI. He explained that on a fundamental level, “AI systems” cannot be treated as a discrete regulatory category as they encompass many different technologies and methods. Additionally, Chesterman said it would be a misstep for regulators to grant AI systems legal personality as this may make it easier for humans who misuse AI to avoid liability for their actions. He emphasized that there can always be a human-in-the-loop and that some decisions, such as when to fire a weapon or find a person liable in the judicial system, rightly belong with human decision-makers who have been appointed within a politically accountable framework.
Immersive Technologies and the Metaverse
Yeung explained that the metaverse is the next logical evolution of the internet and social networking platforms, which were initially text-based, but evolved to include photo sharing as mobile telephones became more common, and later, video sharing, as internet speeds increased around the globe. In Yeung’s view, technology – especially videoconferencing during the COVID-19 pandemic – has already done much to bring people together, but the metaverse will revolutionize current 2D online social interaction and enable a more immersive and 3D experience. Yeung also shared the value the metaverse will bring beyond gaming and entertainment, including the significant transformation to education, workforce training, and healthcare, as well as creating economic opportunities for digital creators, small businesses, and brands. Bartley-Johnsexplained how immersive technologies will bridge the gap between the physical and digital worlds in a range of different contexts, such as creating an “industrial metaverse” combining Internet-of-Things (IoT) devices with “digital twins” and using AR to provide training and technical support remotely.
Chesterman mentioned that improvements in technology over the last decade have raised two major regulatory issues. Firstly, consent no longer makes sense in the context of ubiquitous, large-scale data collection coupled with high-speed computing. Chesterman highlighted Singapore as an example of a jurisdiction that has started to move away from consent towards an alternative, accountability-based model. Secondly, privacy expectations around use of immersive technologies like AR and VR may be different from those that apply to conventional photography in public spaces. Chesterman also added that the metaverse may give rise to disputes over ownership of a person’s visual identity, which may become valuable and require additional protection. Bartley-Johns highlighted additional potential privacy concerns for inferences drawn from data collected in the metaverse, especially in the employment context. He raised the example of if the technology can be used to track employees’ eye movements while their supervisor is talking, and then, that data is used in the employees’ performance assessments. Yeung explained that Meta is focused on a few areas where there are hard questions that do not have easy answers, such as economic opportunity, privacy, safety and integrity, and equity and inclusion. It is critical to get these areas right to realize the potential benefits of the metaverse; as such Meta is investing in research in these areas through partnerships with researchers and academic institutions.
Cross-Border Data Flows
Polonetskycalled for deeper dialog on data localization between national leaders, policymakers, and developers of products and services using emerging technologies, highlighting the challenges presented by the spectrum of interests across different stakeholders. Polonetsky stressed that the task for privacy professionals is to present effective and viable alternatives to data localization that enable government and industry to achieve their respective aims. Bartley-Johnsconcurred with Polonetsky on the need to reframe the conversation around international data flows. Bartley-Johns highlighted that the conversation in APAC has increasingly focused on what legal and technical means exist to assure regulators and data subjects that data will be protected to the same standard as if it had remained in its source jurisdiction when transferred.
New Report on Limits of “Consent” in Thailand’s Data Protection Law
Today, the Future of Privacy Forum (FPF) and the Asian Business Law Institute (ABLI), as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific,” are publishing the tenth in a series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC).
This report provides a detailed overview of relevant laws and regulations in Thailand, including:
notice and consent requirements for processing personal data;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in laws and regulations.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
Thailand’s Data Protection Landscape
Thailand’s Personal Data Protection Act (PDPA) provides the main requirements under Thai law relating to the collection, use, and disclosure of personal data and establishes Thailand’s Personal Data Protection Commission (PDPC), a government agency tasked with supporting the development of personal data protection in Thailand.
Though the PDPA was passed in May 2019, it did not take effect immediately, and there have been a number of major developments in relation to the PDPA throughout 2022. In January 2022, the Thai government officially announced the appointment of the PDPC’s chairperson and members, and in February 2022, the PDPC held its first meeting. In June 2022, the PDPA entered into effect, and PDPC issued a number of subordinate regulations to the PDPA as well as more general guidelines on the rights and requirements under the PDPA for citizens and small business.
This first round of subordinate regulations did not touch on the PDPC’s consent requirements and instead, focused on rules, procedures and exemptions for recording personal data processing, security measures, and administrative penalties. However, it is expected that the PDPC will issue a second round of subordinate regulations specifically regarding consent and notification as PDPC’s parent ministry, the Ministry of Digital Economy and Society (MDES) has released a number of draft guidelines on consent and notification for public consultation between 2021 and 2022.
In addition to the PDPA, several other laws and regulations provide for protection of personal data in specific contexts, including the public sector, healthcare, and credit. Under the PDPA, any other law which provides for the protection of personal data in specific scenarios or specific areas takes precedence over the PDPA, except in relation to the PDPA’s requirements for collection, use, and disclosure of personal data.
Consent in the PDPA
The PDPA adopts a similar model to the EU GDPR in which consent is one of several, equal bases for processing personal data under the PDPA.
Generally, under the PDPA, a data controller may not collect, use, or disclose personal data unless the data controller has obtained consent from the data subject or where an alternative legal basis applies, i.e., where the processing of personal data is:
for the purpose of preparing historical documents or archives in the public interest or in the interests of education, research, or statistics, subject to safeguards prescribed by the PDPC;
to prevent or suppress danger to a person’s life, body, or health;
necessary for:
performing a contract to which the data subject is a party;
taking steps at the request of the data subject when negotiating a contract;
performing a task in the public interest;
exercising official authority that has been vested in the data controller;
pursuing the legitimate interests of the data controller or a third party, unless such interests are overridden by the fundamental rights of the data subject; or
complying with a law to which the personal data controller is subject.
If the personal data in question falls within any of the categories of sensitive personal data under the PDPA, then the data controller must either obtain “explicit consent” from the data subject or satisfy one of a number of narrower alternative legal bases under the PDPA in which the processing of sensitive personal data is strictly necessary (such as in emergencies, for medical care or legal claims, or where there is another substantial public interest) or where the risk to the data subject is circumscribed (for example, where the data is only processed within a single, non-commercial organization for legitimate activities and subject to appropriate safeguards).
Under the PDPA, consent must be obtained prior to or at the time of collection, use, or disclosure of the personal data in question. By default, a request for consent must be made explicitly in writing in a format that separates the request for consent from other matters and that is easy for the data subject to understand. The request must also be accompanied by information on the purpose of the collection, use, or disclosure of the personal data.
Data subjects must also be given the option to withdraw consent and an explanation of the effect of doing so. The procedure for withdrawing must not be more difficult than the procedure by which the data controller initially obtained consent.
FPF at CPDP LatAm 2022: Artificial Intelligence and Data Protection in Latin America
This summer the first-ever in-person Computers, Privacy and Data Protection Conference – Latin America (CPDP LatAm) took place in Rio de Janeiro on July 12 and 13. The Future of Privacy Forum (FPF) was present at the event, titled Artificial Intelligence and Data Protection in Latin America, participating in two panels and submitting a paper for publication. In this blog post, we provide an overview of both the panels, as well as a brief summary of the accepted research paper.
CPDP LatAm is a relatively new event on the international privacy conference circuit, designed to provide a Latin American platform to discuss privacy, data protection, and technology. All the below sessions were recorded by the CPDP organizers, and we will include a link to the recordings as soon as they are made available. Currently, only the opening and closing plenary sessions are available online.
Photo: CPDP LatAm Closing Plenary Session on 7/13/2022Photo: Panel on Research Data, AI and Data Protection Law: What Research ‘Exceptions’ Mean for the Development and Use of AI Technologies, 7/12/2022Photo: Panel on Algorithmic Transparency, Accountability, and Trade Secrets, 07/13/2022
Research Data, AI and Data Protection Law: What Research ‘Exceptions’ Mean for the Development and Use of AI Technologies:
On the first day of CPDP LatAm, FPF got off to a roaring start – hosting a deep-dive panel on how general data protection regulations treat processing personal data for research purposes in the context of AI technologies. Moderated by FPF Policy Counsel Katerina Demetzou, the panel featured contributions from:
Pablo Palazzi, Partner, Allende & Brea; adjunct professor at the School of Law of UdeSA
Nelson Remolina Angarita, Associate Professor, Universidad de los Andes; former Superintendent for the Protection of Personal Data, Colombia;
Marcela Mattiuzzo, Partner, VMCA;
Lucas Borges de Carvalho, Project Manager/Advisor, Board of Directors, ANPD;
Lee Matheson, Senior Counsel, Future of Privacy Forum.
The panel explored how “general scope” data protection regimes often treat processing personal data for research purposes differently, sometimes exempting personal data processed for qualifying purposes from other provisions, such as individuals’ rights to request access to or the deletion of such data. The panel discussed how in the AI context, where high quality datasets containing personal data are critical to train and develop core algorithms and to continuously improve them, these exceptions are particularly crucial to the development of new technologies – but may also represent a significant increase in risk to the individuals concerned.
Panelists identified a number of areas where regulators in Latin America are currently working to issue more specific guidance on the subject of research exceptions – particularly in defining the scope of what kinds of processing activity “count” as acceptable “research” – and whether “research exceptions” should include research activities carried out by the private sector. Such an example is the Brazilian regulator, the ANPD, who recently issued a technical study titled “The LGPD and personal data processing for academic purposes and studies by research organisations” (the original title is “LGPDe o tratamento de dados pessoais para fins acadêmicos e para a realização de estudos por órgão de pesquisa”, original available in Portuguese). The panel also discussed the role of the Ibero-American Network of Data Protection (RIPD) in the matter, as well as how the emerging regulatory regimes in Latin America dealing with the use of personal information for research purposes compare to, and differ from, the European Union’s approach to this issue under the General Data Protection Regulation.
Algorithmic Transparency, Accountability, and Trade Secrets
On the second day of CPDP LatAm, FPF Policy Counsel Katerina Demetzou also spoke on a panel regarding Algorithmic Transparency, Accountability, and Trade Secret Preservation (original title ‘Transparência algorítmica, accountability e preservação do segredo de negócio’). This panel, moderated by Danilo Doneda,CEDIS-IDP, featured contributions from:
Monica Tiemy Fujimoto, CEDIS-IDP;
Flavia Mitri, Privacy Director for Latin America, Uber;
Rafael Zanatta, Director, Data Privacy Brazil;
Katerina Demetzou, Policy Counsel, Future of Privacy Forum.
The panel focused on how to balance transparency obligations core to effective data protection laws with the need to maintain trade secrecy central to much commercial development of artificial intelligence, and how to structure data protection laws such that trade secrecy claims are not able to prevent individuals from effectively exercising their privacy rights. Panelists discussed issues such as the necessity of disclosing application or software source code when providing “explainability” of decision-making to data subjects, and debated the level of detail necessary in disclosures required under transparency obligations. Ms. Demetzou focused on how this tension is treated under the EU’s General Data Protection Regulation, and discussed several examples of EU Member State enforcement actions that balanced the substantive rights granted to individuals by the GDPR with the confidentiality rights created by other national laws regarding trade secrets.
FPF Paper Accepted for Publication
In addition to the above panels, FPF also submitted an academic paper to CPDP LatAm 2022. Titled “Thin Red Red Line: Refocusing Data Protection Law on ADM, A Global Perspective with Lessons from Case-Law” and co-authored by FPF Vice President Gabriela Zanfir-Fortuna, Policy Counsel Katerina Demetzou, and Policy Counsel Sebastião Barros Vale, the paper focuses on how existing data protection laws in the EU and a selection of six global jurisdictions (Brazil, Mexico, Argentina, Colombia, China and South Africa) are currently being applied in the context of automated decision-making (ADM). The paper successfully completed the conference double blind peer review process and will be published in a CPDP LatAm special issue of the Computer Law & Security Review, edited by FGV Professors Luca Belli and Nicolo Zingales.