New Report on Limits of “Consent” in New Zealand’s Data Protection Law
Authors: Elizabeth Santhosh and Dominic Paulger
Elizabeth Santhosh is a current law student at Singapore Management University and an FPF Global Privacy intern.
Introduction
Today, the Future of Privacy Forum (FPF) and Asian Business Law Institute (ABLI), as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific,” are publishing the fourth in a series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC).
This report provides a detailed overview of relevant laws and regulations in New Zealand, including:
notice and consent requirements for processing personal data in New Zealand’s data protection law;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in-laws and regulations.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
New Zealand’s Data Protection Landscape
New Zealand is one of the few jurisdictions in APAC which, together with Hong Kong and Australia, passed comprehensive data protection legislation before the turn of the millennium.
The Privacy Act, which was initially passed in 1993 and repealed then enacted in substantially updated form in 2020, provides the default rules for the processing of personal information under New Zealand law. These are articulated through the 13 Information Privacy Principles (IPPs) which provide, broadly, for collection, use, and disclosure of personal information, as well as storage and security, access, correction, and retention of personal information and use of unique identifiers.
This kind of “principles-based” data protection law is also seen in the data protection laws of Australia and Hong Kong, which all draw on principles from the Organisation for Economic Co-operation and Development (OECD)’s 1980 Guidelines on the Protection of Privacy and Transborder Flows of Personal Data, including collection, limitation, data quality, purpose specification, use limitation, security, openness, and individual participation.
Beyond the IPPs, the Privacy Act also contains detailed provisions which establish the Office of the Privacy Commissioner to administer and enforce the Act. The Act also empowers the Commissioner to, firstly, investigate complaints regarding entities’ privacy practices, resolve disputes, and issue binding compliance notices, and secondly, issue binding codes of practice in relation to specific sectors or classes of personal information.
In 2012, New Zealand also became one of the few jurisdictions in APAC that has received an “adequacy decision” from the European Commission. This decision recognizes that New Zealand’s data protection laws provide an adequate level of data protection compared with that provided by European law for purposes of cross-border data transfers.
Role and status of consent in New Zealand
Consent – which the Privacy Act calls “authorisation” – plays a number of roles in the Privacy Act but unlike in other major data protection laws internationally, is not a standalone legal basis for collecting, using, or disclosing personal information.
The default position under the IPPs is that collection of personal information must be: (1) by lawful, fair, and non-intrusive means; (2) from the individual data subject, rather than a third party; and (3) necessary for a purpose which is connected with the organization’s functions or activities.
Subject to exceptions, organizations must also notify individuals when their personal data is collected by providing certain information, including the purpose for collecting the personal information.
Once organizations have collected personal information, they may use and disclose the information for the purpose of collection, or another purpose that is related to it, without having to obtain consent.
Authorization functions as one of several exceptions to the default rules in the Privacy Act.
Firstly, an organization may collect personal information from a third party or use or disclose personal information for a purpose that is unrelated to the purpose of collection, if the organization reasonably believes that the individual concerned has “authorized” the collection, use, or disclosure.
Authorization functions as one of several legal bases under the IPPs for cross-border transfer of personal information under IPP 12.
Read more about the role of consent in New Zealand’s Data Protection Law in the full report.
Report Analyzes the Role of Data Protection in Safeguarding Sexual Orientation and Gender Identity Information
While digital technology has empowered LGBTQ+ individuals to find community and access services, the increasing availability and use of connected devices have also created new privacy risks for LGBTQ+ communities.
Today, the Future of Privacy Forum (FPF), a global non-profit focused on data privacy and protection, and experts from LGBT Tech — a national, nonpartisan group of LGBTQ+ organizations, academics, and technology organizations — released a report analyzing the role of data protection in safeguarding sexual orientation and gender identity information (SOGI).
LGBTQ+ communities have historically been some of the earliest adopters of technology, but they are also apt to experience more severe harm. The report encourages policymakers and organizations to learn from past privacy and LGBTQ+ history to shape what data privacy could look like today while continuing the critical work in reducing bias and risk to mitigate or even avoid individual and collective harms.
“The processing of data about an individual’s sexual orientation and gender identity can carry unique risks for LGBTQ+ individuals and communities,” said Amie Stepanovich, Vice President of U.S. Policy at FPF, who is a co-author of the report. “Organizations need to understand the impacts of processing this data on traditionally marginalized communities and to provide heightened protections, with respect for past and present context, to protect against potential harms.”
FPF and LGBT Tech’s analysis shows that while individuals within the United States population are becoming more likely to accept and identify as LGBTQ+, civil rights protections — including the right to privacy — are under attack and still lag when it comes to protecting LGBTQ+ individuals.
Moreover, FPF and LGBT Tech found that LGBTQ+ individuals are disproportionately impacted by privacy violations online. Today, LGBTQ+ communities still face significant barriers and prejudices from violence and discrimination, harming their right to equality and dignity.
“Ninety-seven percent of LGBTQ+ youth have seen content online that could be described as ‘homophobic, biphobic or transphobic,’” said Christopher Wood, Executive Director of LGBT Tech. Wood was one of the co-authors of the report. “For much of the LGBTQ+ youth, the Internet is the only place they feel safe to express their sexuality and connect with other LGBTQ+ youth. Potential violations can lead to privacy harms in the form of online outings and harassment.”
On July 20, co-authors Amie Stepanovich, FPF’s Vice President of U.S. Policy, Chris Wood, Executive Director & Co-Founder of LGBT Tech, and Katelyn Ringrose, Policy Lead for Law Enforcement and Government Access at Google, dove deeper into the report and discussed considerations for policymakers, risks and harms of SOGI data, and more. Watch the conversation by clicking here.
FPF Testifies Before House Subcommittee on Energy and Commerce, Supporting Congress’s Efforts on the “American Data Privacy and Protection Act”
This week, FPF’s Senior Policy Counsel Bertram Lee testified before the U.S. House Energy and Commerce Subcommittee on Consumer Protection and Commerce hearing, “Protecting America’s Consumers: Bipartisan Legislation to Strengthen Data Privacy and Security” regarding the bipartisan, bicameral privacy discussion draft bill, “American Data Privacy and Protection Act” (ADPPA). FPF has a history of supporting the passage of a comprehensive federal consumer privacy law, which would provide businesses and consumers alike with the benefit of clear national standards and protections.
Lee’s testimony opened by applauding the Committee on its efforts towards comprehensive federal privacy legislation and emphasized the “time is now” for its passage. As it is written, the ADPPA would address gaps in the sectoral approach to consumer privacy, establish strong national civil rights protections, and establish new rights and safeguards for the protection of sensitive personal information.
“The ADPPA is more comprehensive in scope, inclusive of civil rights protections, and provides individuals with more varied enforcement mechanisms in comparison to some states’ current privacy regimes,” Lee said in his testimony. “It also includes corporate accountability mechanisms, such as the requiring privacy designations, data security offices, and executive certifications showing compliance, which is missing from current states’ laws. Notably, the ADPPA also requires ‘short-form’ privacy notices to aid consumers of how their data will be used by companies and their rights — a provision that is not found in any state law.”
Lee’s testimony also provided four recommendations to strengthen the bill, which include:
Additional funding and resources for the FTC;
Developing a more iterative process to ensure that the bill can keep up with evolving technologies;
Clarifying the intersection of ADPPA with other federal privacy laws (COPPA, FERPA, HIPAA, etc.); and
Establishing clear definitions and distinctions between different types of covered entities, including service providers.
Many of the recommendations would ensure that the legislation gives individuals meaningful privacy rights and places clear obligations on businesses and other organizations that collect, use and share personal data. The legislation would expand civil rights protections for individuals and communities harmed by algorithmic discrimination as well as require algorithmic assessments and evaluations to better understand how these technologies can impact communities.
New Report on Limits of “Consent” in Hong Kong’s Data Protection Law
Today, the Future of Privacy Forum (FPF) and Asian Business Law Institute (ABLI) – as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific” – are publishing the third in a series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC).
This report provides a detailed overview of relevant laws and regulations in Hong Kong, a Special Administrative Region (SAR) of the People’s Republic of China, which has its own data protection law, the Personal Data (Privacy) Ordinance (PDPO). The report covers:
notice and consent requirements for processing personal data in Hong Kong’s data protection law;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in relevant laws and regulations.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
Hong Kong’s Data Protection Landscape
The PDPO – which was passed in 1995 and took effect (except for certain provisions) in 1996 – is one of the most long-standing data protection laws in both APAC and globally.
The purpose of the PDPO is to protect the privacy of individuals in relation to their personal data. The main way in which the PDPO protects such data is by giving legal effect to the six “Data Protection Principles” (DPPs) in Schedule 1 of the PDPO, which cover:
the purpose and manner of personal data collection;
accuracy and duration of data retention;
use of personal data;
security of personal data;
openness and transparency around personal data practices; and
access to and correction of personal data.
This kind of “principles-based” data protection law is also seen in the data protection laws of Australia and New Zealand, which all draw on principles from the OECD’s 1980 Guidelines on the Protection of Privacy and Transborder Flows of Personal Data, including collection limitation, data quality, purpose specification, use limitation, security, openness, and individual participation.
The PDPO’s principles are supplemented by other provisions of the PDPO which provide further protection for personal data in specific contexts. Specifically, substantial amendments to the PDPO in 2012 added, among others, a new Part 6A to the PDPO which governs processing of personal data for direct marketing and imposes strict penalties, including fines or imprisonment, on organizations that fail to obtain consent to use or disclose personal data for direct marketing purposes. Further amendments to the PDPO in 2021 added new provisions to the PDPO to combat “doxing” (i.e., publishing private personal information online to, among others, harass, harm, or damage the property of a person). These included new criminal offenses and powers to investigate and prosecute acts of doing.
The PDPO also establishes the Privacy Commissioner for Personal Data (PCPD) – an independent data protection authority which serves advisory and enforcement functions with regard to the PDPO. In its advisory role, the PCPD is tasked with, among others, promoting public awareness and understanding of the PDPO. To that end, the PCPD has issued a number of guidelines on application of the PDPO’s requirements to specific situations or sectors. In its enforcement role, the PCPD is empowered to investigate possible contraventions of the PDPO and issue recommendations or enforcement notices directing an organization to take remedial or protective actions. PCPD is also empowered to investigate and prosecute criminal offenses under the PDPO.
Role and Status of Consent
The PDPO’s data protection framework is based primarily on notification rather than consent.
Generally, before an organization may collect personal data from a data subject, DPP 1 requires that the organization must take all practical steps to ensure that the data subject is explicitly informed of:
the purpose for which the data will be used,
any parties to whom the data may be transferred,
whether it is obligatory or voluntary for the data subject to provide the data.
An organization that has provided a valid notification may use or disclose personal data collected from the data subject for the purpose stated in the notification or a purpose that is reasonably related to it without the need to obtain consent.
Consent plays a secondary role in the PDPO. DPP 3 requires an organization to obtain express opt-in consent from the data subject if the organization wishes to use personal data for a different purpose from the one stated in the notification.
Additionally, if the organization intends to use or disclose the data subject’s personal data for direct marketing purposes, Part 6A of the PDPO requires the organization to notify the data subject of its intention and provide certain prescribed information. The data subject must then give consent. However, for direct marketing purposes, it is sufficient if data subjects minimally do not opt out of use or disclosure of their data for direct marketing.
Non compliance with the above requirements may be a criminal offense under the PDPO, which is punishable with a fine or even imprisonment.
However, the PDPO provides numerous exceptions to the consent requirement in DPP 3. An organization may not need to obtain consent to use or disclose personal data for a new purpose if that purpose includes, among others, preventing or detecting a crime, engaging in legal proceedings, preparing research and statistics, or responding to an emergency involving the data subject.
FPF Releases Policy Brief Comparing Federal Child Privacy Bills
On Wednesday, July 27, 2022, the Senate Committee on Commerce, Science, and Transportation held a markup of two bills this resource highlights: The Kids Online Safety Act and the Children and Teens’ Online Privacy Protection Act (COPPA 2.0). The Committee advanced both bills with significant amendments. Both bills garnered bipartisan support, with the Kids Online Safety Act receiving a unanimous roll call vote and COPPA 2.0 passing through a voice vote with limited opposition. This brief was last updated in September 2022 to reflect the changes to the two bills.
As children’s privacy continues to be a top priority and area of interest among lawmakers, companies, and the public, the Future of Privacy Forum (FPF) today released a new policy brief that compares the child-centric privacy bills that have been introduced in the 117th Congress. The resource compares four proposed bills against each other (with additional comparisons to current law) on key elements including the age group they seek to protect, enforcement mechanisms, covered entities, notice requirements, verifiable consent, restrictions on the use of personal information (PI), and more.
“Child privacy continues to receive a lot of attention from policymakers, companies, regulators, and families. In recent months, we’ve seen the FTC, state legislatures, federal policymakers, and even the President of the United States signal an interest in enhancing the consumer privacy rights and online protections afforded to children,” said Lauren Merk, Youth & Education Privacy Policy Counsel at FPF. “The four bills outlined in this resource stand to impact the child privacy landscape in the US either by directly changing the law or influencing future legislation at the federal or state levels. Case in point, the recently released discussion draft of the American Data Privacy and Protection Act includes provisions that mirror sections from some of the child-specific privacy bills.”
The four children’s privacy bills introduced in the 117th Congress are the Protecting the Information of our Vulnerable Children and Youth Act (“Kids PRIVCY Act”), the Children and Teens Online Privacy Protection Act (“COPPA 2.0”), the Kids Internet Design and Safety Act (“KIDS Act”) and the Kids Online Safety Act. Two of the bills – COPPA 2.0 and the Kids Online Safety Act – have bipartisan support, while the KIDS Act is the only bill of the four that has been introduced in both chambers of Congress this session.
While all four bills ultimately propose greater online privacy rights for kids, they vary in key respects such as covered age ranges of minor users, enforcement measures, and verifiable consent requirements. The brief’s two comparative tables highlight these and other elements to showcase the various approaches the bills take. Table 1 compares the two bills that seek to directly amend and update the already enacted Children’s Online Privacy Protection Act (COPPA) —COPPA 2.0 and the Kids PRIVCY Act–to each other as well as the current COPPA language for reference. And Table 2 examines the key elements of the KIDS Act and the Kids Online Safety Act, which work independently of COPPA.
ViewTable 1: Federal Child Privacy Bills That Seek to Directly Amend COPPA and Table 2: Federal Child Privacy Bills Independent of COPPA in the policy brief.
“Nearly everyone agrees that protecting kids’ privacy is important, but like many issues, the proverbial devil is in the details and each of these bills goes about it in different ways,” said Miles Light, Youth & Education Privacy Policy Counsel at FPF. “For example, most nonprofit organizations would continue to be exempt from COPPA under COPPA 2.0, but are considered a covered entity under the Kids PRIVACY Act and would have to comply. And while all four bills propose creating privacy protections for older minors – kids ages 13-17 who are not currently covered under COPPA – they vary as to whether they use under 16, under 17, or under 18 as their definition.”
“As child privacy discussions continue, we hope that this comparison can serve as a helpful resource to policymakers, staffers, advocates, and so many others who are closely tracking this issue and the various proposals,” added Light.
New Report on Limits of “Consent” in South Korea’s Data Protection Law
Today, the Future of Privacy Forum (FPF) and Asian Business Law Institute (ABLI) – as part of their ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific” – are publishing a second report in their series of detailed jurisdiction reports on the status of “consent” and alternatives to consent as lawful bases for processing personal data in Asia Pacific (APAC) – this time focusing on South Korea.
This report provides a detailed overview of relevant laws and regulations in South Korea, including:
notice and consent requirements for processing personal data;
the status of alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in laws and regulations.
The first report focused on the People’s Republic of China and explained how the country’s data protection framework has evolved over the past few years from a consent-centric model to one which provides various alternatives to consent in a GDPR-type model.
The findings of this report and others in the series will inform a forthcoming comparative review paper which will make detailed recommendations for legal convergence in APAC.
South Korea’s Data Protection Landscape
South Korea’s data protection law is founded on similar principles to those of other major data protection laws internationally stemming from the Fair Information Practice Principles, including lawfulness, purpose specification, purpose limitation, data minimization, data accuracy, and security.
In fact, South Korea is one of the few jurisdictions in Asia Pacific which has received an EU adequacy decision, by which the European Commission determines that the level of personal data protection in a given jurisdiction is “essentially equivalent” to that under the GDPR. In June 2021, the European Commission published its draft adequacy decision for South Korea and transmitted the decision to the European Data Protection Board (EDPB) for consideration.
South Korea’s general law on personal data protection is the Personal Information Protection Act (PIPA), which went into effect on September 30, 2011 with the stated purpose of governing processing and protection of personal data to safeguard the rights and freedoms of individuals. The PIPA is complemented by an enforcement decree, various sector specific laws, including in the credit, telecommunications, and insurance sectors, and guidelines issued by South Korea’s data protection regulator, the Personal Information Protection Commission (PIPC).
The PIPA contains detailed provisions covering the lifecycle of personal data from the time that it is collected until it is deleted. The PIPA provides data subjects with rights over their personal data, including, notably, express rights to be informed and to decide whether and to what extent to consent when their personal data is processed. The PIPA also imposes numerous compliance obligations on data controllers including mandatory obligations to issue a privacy policy, appoint a data protection officer, and notify data subjects in the event of a breach of their personal data, with penalties for non-compliance, including specific offenses for collecting and using personal data without a legal basis, such as consent.
The latest major round of amendments to the PIPA was in 2020. These amendments introduced, among others:
specific obligations for organizations which provide commercial information and communication services online, including strict obligations to notify users of how their personal data will be processed and obtain users’ consent for processing of personal data, with very limited exceptions;
new provisions allowing pseudonymized data to be processed without consent for purposes of statistics, research, and public records;
a general principle that data controllers should endeavor to use anonymized data for processing wherever possible and where it is not possible to achieve the purposes of processing using anonymized data, to use pseudonymized data as much as possible.
reforms to the structure and powers of PIPC to establish the organization as an independent, centralized data protection authority like its counterparts in the EU.
Role and Status of Consent in South Korea’s Personal Data Protection Law
Since the PIPA took effect in 2011, it has provided several equal legal bases for collecting personal data, including consent but also alternatives to consent where collection of personal data is necessary for:
executing and performing a contract with the data subject.
complying with a legal obligation.
a public institution to carry out its legal duties.
protecting of a person’s life, body, or property interests from immediate danger, where it is not feasible to obtain consent; and
fulfillment of a legitimate interest of the data controller, where this interest clearly supersedes the rights and interests of the data subject.
The PIPA’s legal bases are similar to those recognized by other major data protection laws internationally, including, notably, the GDPR. However, the PIPA’s requirements for relying on alternative bases to consent are often stricter than those under GDPR, and there is also less guidance on the circumstance in which organizations can rely on alternative legal bases, compared with guidance on how to obtain consent. Organizations in South Korea therefore tend to rely on consent rather than other legal bases in practice.
If an organization seeks to rely on consent to process personal data, the consent must be explicit, opt-in, and informed. In the latter regard, the PIPA requires the organization to notify the data subject of certain information when seeking consent. This includes the purpose for processing the data, what data will be processed, and the data subject’s right to deny consent. If the data subject refuses to give consent after receiving this information, the controller is prohibited from denying provision of goods or services to the data subject on this basis.
Where personal data has been collected on the basis of consent, the controller may use personal data or disclose it to a third party if this use or disclosure is reasonably related to the original purpose for which the data was collected. If the processing is not reasonably related to this original purpose, then the controller must seek fresh consent. Data subjects also have a right to withdraw consent to processing of their personal data at any time.
Processing personal data without a valid legal basis, failing to provide required notifications, and processing personal data beyond the scope of the purpose of collection are all violations under the PIPA, and there have been several high-profile enforcement cases where penalties were imposed on organizations that failed to comply with the PIPA’s consent requirements. A notable example is ScatterLab, an company whose AI chatbot collected personal information from over 200,000 children under the age of 14 without obtaining parental consent.
Lastly, the PIPA imposes stricter obligations on processing of certain personal data which falls within a category of “sensitive personal information” which if revealed, would constitute a material breach of privacy. This category includes personal data regarding a person’s ideological and religious beliefs, trade union and political party membership, political views, health and genetics, sexual orientation, criminal records, and individual physiological or behavioral profile. Notice and consent are generally required for processing of this class of personal data, with limited exceptions.
Report Outlines Key Privacy Considerations for Video-Based Safety Systems in Vehicles
Despite fewer vehicle miles traveled as a result of the COVID-19 pandemic, an estimated 38,680 individuals died in motor vehicle accidents in 2020 — the largest projected number of fatalities in such accidents in over a decade. Washington, D.C.-based non-profit Future of Privacy Forum (FPF) released a report detailing the data usage and privacy implications of video-based safety systems in vehicles. The report, co-authored with Samsara Inc. (NYSE: IOT), the pioneer of the Connected Operations Cloud, describes how Advanced Driver Assistance Systems (ADAS) work in commercial fleets, identifies the data used by these systems and urges the adoption of privacy best practices that go beyond compliance with existing privacy and data processing laws.
As vehicle safety technologies grow more sophisticated and affordable to deploy, vehicle manufacturers are increasingly adopting AADAS in vehicles. ADAS technologies utilize cameras and sensors to enable adaptive cruise control, emergency braking systems, and other measures — all with the aim of increasing driver safety.
Although these technologies are increasingly commonplace, the report describes how ADAS may create privacy risks for drivers, passengers, and other road users. Privacy risks involving location data, in-cabin video, and audio recordings can be particularly acute when drivers routinely eat, sleep, or talk in their vehicles.
Recent actions by the Department of Transportation, including initiatives such as FMCSA’s Tech-Celerate Now program, anticipate that ADAS will become increasingly common in the commercial transportation industry. The Report identifies key data flows and privacy risks while emphasizing that privacy safeguards must be implemented along with ADAS tech.
Policymakers, commercial fleet operators, and their technology partners must recognize these risks and weigh data protection considerations when assessing the broader use of ADAS and related technologies.
“Policymakers, technology vendors, and commercial fleet managers must recognize and mitigate privacy risks to individuals when assessing the broader use of ADAS and related technologies,” said John Verdi, Senior Vice President of Policy at FPF. “Just as the technology will continue to develop, privacy and data processing laws must evolve as well.”
The Future of Privacy Forum and Samsara urge the adoption of privacy best practices that go beyond compliance with existing privacy and data processing laws, including:
Implementation of privacy by design principles, privacy impact assessments, data minimization strategies, and privacy-enhancing technologies;
Provision of enhanced transparency mechanisms to individuals;
Implementation of practical security safeguards appropriate for the sensitivity of the relevant data; and
Use of robust written policies and contracts to ensure that privacy protections remain attached to the data and that all parties with access to data understand their obligations.
“Technology needs to be designed and used with privacy and security in mind – it is no longer good enough to provide lip service to it,” said Lawrence Schoeb, Legal Director and Data Protection Officer at Samsara. “This is one of many reasons we strongly encourage the operation of any video-based safety systems to be consistent with and reflective of privacy best practices.”
As the annual Computers, Privacy and Data Protection (CPDP) conference took place in Brussels between May 23 and 25, several Future of Privacy Forum (FPF) staff took part in different panels and events organized by FPF or other organizations before and during the conference. In this blogpost, we provide an overview of such events, with a particular focus on the panel which FPF hosted on May 24 at CPDP, on the topic of Mobility Data Sharing under the upcoming EU Data Act: what are the data protection implications and how should the risks be mitigated?
All the below sessions were recorded by the CPDP organizers, and we will include a link to the recordings as soon as they are made available.
May 20: ADM Report Launch Event – A Discussion with Experts
On May 17, FPF launched a comprehensive Report analyzing case-law under the General Data Protection Regulation (GDPR) applied to real-life cases involving Automated Decision-Making (ADM). The Report, authored by FPF’s Policy Counsel, Sebastião Barros Vale, and FPF’s Vice President for Global Privacy, Gabriela Zanfir-Fortuna, is informed by extensive research covering more than 70 Court judgments, decisions from Data Protection Authorities (DPAs), specific Guidance and other policy documents issued by regulators.
On May 20, the authors discussed with prominent European data protection experts some of the most impactful decisions analyzed in the Report during an FPF roundtable. Speakers included Gianclaudio Malgieri, Co-director of the Brussels Privacy Hub and Associate Professor of Law at EDHEC Business School (Lille), Mireille Hildebrandt, Research Professor on ‘Interfacing Law and Technology’ at Vrije Universiteit Brussels, and Brendan van Alsenoy, Deputy Head of Unit “Policy and Consultation” at the European Data Protection Supervisor (EDPS). The expert roundtable discussion was enriched by representatives from UK’s Department for Digital, Culture, Media and Sport (DCMS), the European Consumer Organization (BEUC), and the Brussels Privacy Hub. Watch a recording of the conversation here, and download the slides here.
May 22: CPDP Opening Night – Vulnerable Data Subjects
The day before the conference program started, Gabriela Zanfir-Fortuna was part of a stellar panel organized by the Brussels Privacy Hub for the Opening Night, on the topic of “Vulnerable Individuals in the Age of Artificial Intelligence (AI) Regulation”. The panel, which was moderated by Gianclaudio Malgieri, also counted on Mireille Hildebrandt, Louisa Klingvall (European Commission), Ivana Bartoletti (University of Oxford), and Brando Benifei (co-rapporteur of the AI Act at the European Parliament). It explored how the AI Act draft proposed to protect vulnerable individuals, by prohibiting the exploitation of some forms of vulnerability (based on age, disability, economic and social conditions): could the definition of vulnerability under the text be broadened?
The occasion also served as an opportunity to announce that FPF and the Brussels Privacy Hub will set upan International Observatory on Vulnerable People in Data Protection (the ‘VULNERA’ project) and offered a preview of its website. More details to follow in the following months.
May 23: Global panel on post-COVID data protection; AI Act in the employment context
The first day of the CPDP conference was a busy one for FPF’s Gabriela Zanfir-Fortuna. She started early in a speaking role on a panel about ‘Data Protection Regulation Post-COVID: the Current Landscape of Discussions in Europe, the US, India and Brazil’, organized by Data Privacy Brasil (DPB) and moderated by DPB’s Bruno Bioni. The session, during which Gabriela offered the US perspective on the matter, also counted on the valuable inputs of FPF’s Senior Fellow for India, Malavika Raghavan, the European Data Protection Board (EDPB)’s Head of Secretariat, Isabelle Vereecken, and the Executive Director of the Africa Digital Rights Hub LBG, Teki Akuetteh Falconer. Panelists reflected on new questions for data sharing and protection that had arisen in their regions in areas such as public health (including the design of contact tracing and health passport apps), education, and welfare/social security. View a recording of the session here.
During the last slot of the day, Gabriela moderated a panel on ‘The AI Act and the Context of Employment’, which saw a lively debate on the extent to which the draft Regulation protects workers against AI-powered workplace monitoring and decisions. The panelists in this instance were Aida Ponce del Castillo (European Trade Union Institute), Diego Naranjo (Head of Policy at European Digital Rights), Paul Nemitz (Principal Advisor at the European Commission’s DG JUST), and Simon Hania (Data Protection Officer at Uber). You can read about the main points raised by the speakers in this short thread.
May 24: Cross-Continental privacy compliance and FPF’s panel on Mobility Data
The second day was packed with interesting discussions on topics such as GDPR enforcement conundrums, privacy class actions, and how data protection law can tackle manipulative web design (or ‘dark patterns’). FPF staff were involved in some of the most exciting panels and events of the day.
FPF’s Policy Analyst, Mercy King’ori, was a speaker at a panel at the CPDP Global track, on ‘Corporate Compliance with a Cross Continental Framework: the State of Global Privacy in 2022’. As Mercy elaborated on African regulatory developments, the remaining speakers focused on different jurisdictions, such as the EU, Brazil, China, and Israel. The debate, which was moderated by FPF’s Senior Fellow, Omer Tene, also counted on contributions from Renato Leite Monteiro (DPB), Barbara Li (PwC), and Anna Zeiter (Chief Privacy Officer at eBay).
Later that evening, the conference hosted the session organized by FPF, on the topic of ‘Mobility Data for the Common Good? On the EU Mobility Data Space and the Data Act’. The panel was moderated by FPF’s Managing Director for Europe, Rob van Eijk, and aimed to answer several questions, including whether the draft Data Act and the upcoming EU Mobility Data Space could address cities’ innovation and sustainability goals, while still safeguarding citizens’ privacy. The expert speakers around the table were Maria Rosaria Coduti (Policy Officer at the European Commission’s DG CNECT), David Wagner (German Research Institute for Public Administration, or “FÖV”), Laura Cerrato (DPO at the Centre d’Informatique pour la Région de Bruxelles), and Arjan Kapteijn (Senior Inspector for the department of Systemic Oversight within the Dutch DPA). View a recording of the session here.
Maria Rosaria Coduti explained that the combination of different pieces of the EU’s Data Strategy – notably, the Data Governance Act (DGA), the Data Act and the Common European Data Spaces – seeks to remove barriers to the access and sharing of data. This can be achieved through incentivizing private and public sector players, as well as data subjects, to share data on a voluntary basis (e.g., through data intermediation services and data altruism organizations), as well as compelling entities to share data where there is an imbalance of power between data holders and users, or where public interest grounds exist. An example of the latter case is the use of mobility data held by telco providers to help mapping the spread of COVID-19. However, the Data Act defines strict rules for data access requests made by public bodies to private players, and a limitation on the use of such data to public emergency situations. With regards to Business-to-Business data sharing under the Data Act, Coduti underlined that the text’s provisions on cloud switching and interoperability may force designers of connected products (such as cars, planes, and trains) to design them in a way that makes the data they generate easily accessible for users and the data recipients the latter choose.
Laura Cerrato explained that, in her role as DPO for the IT services provider of the Region of Brussels’ public authorities, she invests efforts in explaining the legal intricacies of data sharing to such authorities. According to Cerrato, the Data Act will open new possibilities for government bodies to access privately-held data, but that this requires transparency and accountability toward citizens. Moreover, as her office is piloting a Mobility-as-a-Service project in the city, there was a need to discuss the appropriate legal basis for personal data processing in that context, as public authorities cannot rely on the legitimate interest ground under Article 6 GDPR. In that respect, Cerrato underlined that the public interest legal basis can only be used if it is provided under national or EU law, which for Smart City development in Belgium was lacking.
Arjan Kapteijn closely followed Cerrato’s remarks, pointing toward the recent Dutch DPA guidance on Smart Cities. In the lead up to such recommendations, the DPA investigated the records of processing activities (ROPAs) and data protection impact assessments (DPIAs) of 12 Dutch cities carrying out Smart City-related projects and asked why they did not consult the DPA prior to the data processing, as per Article 36 GDPR. Among the DPA’s findings, there were some misconceptions among municipalities regarding the concept of “personal data” when applied to mobility datasets, and a belief that the GDPR did not apply to pilot projects, which may have led to lack of transparency toward citizens. Kapteijn stressed that data collected through sensors is often covered by the GDPR, such as data collected by connected vehicles and smart traffic lights, and in the context of wi-fi tracking in public spaces. Lastly, the speaker warned about the difficulties of making location data truly anonymous according to GDPR standards, and that certain hashing techniques, privacy-by design, and data minimization may play a valuable role in retaining data utility while protecting the data.
Lastly, David Wagner focused on the concept of anonymization under Recital (26) GDPR, and how it applies to location and mobility data. He explained that anonymising this data is hard because individual movement patterns can identify persons. To work towards anonymising the data, there is a need to suppress some data points (e.g., by adding noise), with losses for data utility. The anonymization test in Recital (26) GDPR, which considers the “means reasonably likely to be used” to identify a natural person, arguably invites controllers to evaluate potential attackers’ cost-benefit calculations, making it hard to determine a reasonable re-identification attempt. Thus, Wagner argued that the GDPR defines a threshold for anonymity, but that controllers and regulators need an effective and reliable scale to assess it. The upcoming update from the EDPB to the 2014 Article 29 Working Party guidelines on anonymization may provide such evaluation criteria.
May 25: FPF’s De-Identification Masterclass and Data Protection in China
In the morning of the conference’s closing day, FPF hosted an engaging and well-attended Masterclass on the ‘State-of-Play of De-Identification Techniques’ as an official side event. The session’s moderator, FPF’s Rob van Eijk, kicked off the discussion by presenting the 2016 FPF Infographic on data de-identification, and how this fared against the GDPR’s updated concept on anonymization. Then, expert speakers Sophie Stalla-Bourdillon (Immuta), Naoise Holohan (IBM), and Lucy Mosquera (Replica Analytics) presented on cutting-edge techniques, notably – and respectively – on Homomorphic Encryption, Differential Privacy, and Synthetic Data. View a recording of the session here.
New Report on Limits of “Consent” in China’s Data Protection Law – First in a Series for Joint Project with Asian Business Law Institute
The Future of Privacy Forum (FPF) and Asian Business Law Institute (ABLI) are publishing today the first in a series of 14 detailed jurisdiction reports that will explore the role and limits of consent in the data protection laws and regulations of 14 jurisdictions in Asia Pacific (Australia, China, Hong Kong SAR, India, Indonesia, Japan, Macau SAR, Malaysia, New Zealand, the Philippines, South Korea, Singapore, Thailand, and Vietnam), as part of FPF and ABLI’s ongoing joint research project: “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific.”
The first report focuses on the status of “consent” and alternatives to consent as lawful bases for processing personal data in the People’s Republic of China. Over the coming weeks, FPF and ABLI will continue publishing these reports, which will inform a forthcoming comparative review paper with detailed recommendations to promote legal convergence around requirements for processing personal data in the Asia Pacific region.
Background on the ABLI/FPF Project
In August 2021, ABLI and FPF concluded a cooperation agreement to understand, analyze, and support the convergence of data protection regulations and best data protection practices in the Asia Pacific region through joint research, publications, and events. This collaboration builds on the substantial work done by ABLI and FPF on data protection and privacy laws and frameworks in the Asia Pacific (APAC) region.
The starting point for FPF’s collaboration with ABLI is the understanding that as personal data protection frameworks in Asia are at a critical stage in their development – whether they are in the process of adoption or reform, or are at the early stages of their implementation – there is an urgent need for understanding where they differ and for identifying opportunities for convergence of key data protection rules and principles at the regional level.
Previous work by ABLI has demonstrated the collective benefits of legal certainty and convergence in the area of cross-border flows of personal data in APAC. As this work has proven useful for policymakers as they address these issues, ABLI and FPF launched a joint project with the same philosophy and methodology, entitled “From Consent-Centric Data Protection Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific,” to promote legal convergence around principled, accountability-based requirements for processing personal data in Asia Pacific.
In APAC as elsewhere, there is a growing conversation around the limitations of “notice and consent” and how to address them. Notice and consent requirements have long been used to justify the collection and processing of personal data. However, in recent years, this justification has increasingly been called into question:
Over-reliance on consent has led to the development of a “tick-the-box” approach to data protection for organizations and “consent fatigue” for individuals, which contradict the original purpose of data protection laws.
The requirement to obtain consent (especially where consent must be given explicitly) is increasingly proving inadequate in the era ambient of computing, the Internet of Things (IoT), and multi-stakeholder digital ecosystems and platforms.
Consent requirements are also increasingly complex for organizations to apply, and legal fragmentation has made operations across jurisdictions even more challenging, leading to unnecessary compliance costs.
Many APAC jurisdictions have already come to recognize the limitations of consent, especially in the digital space. To highlight a few examples:
In 2018, a report of a Committee of Experts on a Free and Fair Digital Economy in India described the operation of notice and consent on the internet as “broken” and questioned whether consent alone could be an effective method for protecting personal data and preventing individual harm.
In 2019, New Zealand’s then-Privacy Commissioner, John Edwards, declared in a much-cited blog post that click-to-consent was “not good enough anymore” and called for consumers and businesses alike to rethink consent and move towards Privacy by Design.
In 2020, Singapore restructured its Personal Data Protection Act from a primarily consent-based framework to permitting collection, use, and disclosure of personal data without consent in a wide range of situations, including ”vital interests of individuals,” “matters affecting the public,” “legitimate interests [of organizations],” “business asset transactions,” “business improvement purposes,” and “research.”
However, this trend is not shared by all jurisdictions. Many data protection laws in APAC (and elsewhere) still require consent by default for the collection and processing of personal data. “Tick-the-box” compliance habits or reluctance to change user experience often lead organizations to fall back on consent. In APAC, these problems are reinforced by the fragmentation of regional laws – for all its limitations, consent is still often perceived as a common denominator and the “easiest” or “safest” way to comply across borders in APAC—even where consent is not necessary or even justifiable or where accountability-focused options like legitimate interests could apply and would be better suited to the needs of both organizations and individuals.
The ABLI and FPF project aims to guide the development of data protection frameworks in APAC away from consent-centric, “tick-the-box” compliance requirements and towards responsible data practices and accountability for privacy when processing personal data. At the same time, the project recognizes that effective policies need to balance the interests of individuals in protecting their personal data and organizations in using personal data, while also promoting the interests of broader society, such as developing a vibrant digital economy and preventing crimes and fraud.
This requires frameworks to realign the role of consent by returning consent to the position that it occupied in the very first data protection frameworks as one of several, equal legal bases for processing of personal data, rather than as the default or even sole basis for processing personal data.
First Report: Consent in China’s Data Protection Law
In the first stage of this collaboration, FPF and ABLI have undertaken a comprehensive review of the role and position of “notice and consent”’ in 14 APAC jurisdictions: Australia, China, Hong Kong SAR, India, Indonesia, Japan, Macau SAR, Malaysia, New Zealand, the Philippines, South Korea, Singapore, Thailand, and Vietnam.
These reports draw on insights provided by thought leaders, regulators, and practitioners during the first event co-organized by FPF and ABLI: a virtual panel entitled “Exploring Trends: From ‘Consent-Centric’ Frameworks to Responsible Data Practices and Privacy Accountability in Asia Pacific” which was co-hosted by Singapore’s Personal Data Protection Commission in September 2021.
To that end, FPF and ABLI are delighted to announce the first publication in this joint project: a detailed jurisdiction report on the status of consent inChina’s data protection framework.
China’s data protection law has been evolving in recent years. Though China’s personal data protection framework has traditionally prioritized consent, the adoption of the Personal Information Protection Law last year was a paradigm shift which repositioned consent as one of seven equal legal bases for processing personal data in a model likely inspired by the GDPR.
This report provides a detailed overview of relevant laws and regulations in China on:
notice and consent requirements for processing personal data;
alternative legal bases for processing personal data which permit processing of personal data without consent if the data controller undertakes a risk impact assessment (e.g., legitimate interests); and
statutory bases for processing personal data without consent and exceptions or derogations from consent requirements in general and sector-specific laws and regulations.
The reports draw from the professional knowledge, experience, and opinions of a wide range of expert contributors from across the APAC region. ABLI and FPF are grateful for the invaluable contributions of these contributors, who have kindly shared detailed information, comments, and clarifications on the legal frameworks in their respective jurisdictions.
Upcoming for the ABLI/FPF Project
Over the coming weeks, FPF and ABLI will publish these reports as part of an ABLI-FPF Series on Convergence of Data Protection and Privacy Laws in APAC.
The findings presented in the reports will also inform the second stage of ABLI and FPF’s collaboration: a comparative review paper which sets out proposals as to how policymakers can not only promote legal convergence in the APAC region but also help organizations to move away from overreliance on lengthy privacy policies and often artificial consent and towards responsible data practices that strike a balance between the needs of organizations that collect and process data, the rights of individuals in protecting their data, and the interests of society at large.
FPF hopes that these publications will prove useful to lawmakers, governments, and regulators in APAC (and beyond) who are currently drafting, reviewing, or implementing data protection laws in their respective jurisdictions.
In October 2021, the White House Office of Science and Technology (OSTP) published a Request for Information (RFI) regarding uses, harms, and recommendations for biometric technologies. Over 130 entities responded to the RFI, including advocacy organizations, scientists, experts in healthcare, lawyers, and technology companies. While most commenters agreed on core concepts of biometric technologies used to identify or verify identity (with differences in how to address it in policy), there was clear division as to what extent the law should apply to emerging technologies used for physical detection and characterization (such as skin cancer detection or diagnostic tools). These comments reveal that there is no general consensus on what “biometrics” should entail and thus what the applicable scope of law should be.
Using the OSTP comments as a reference point, this briefing explores four main points regarding the scope of “biometrics” as it relates to emerging technologies that rely on human body-based data but is not used to identify or track:
Biometrics technologies range widely in purpose and risk profile (including 1:1, 1:Many, tracking, characterization, and detection).
Current U.S. biometric privacy laws and regulatory guidance largely limit the scope of “biometrics” to identification and verification (with the exception of Texas and a few caveats surrounding ongoing litigation in Illinois).
Many academics and civil society members argue the existing framework should be expanded to other emerging technologies such as detection and characterization tools because these uses can still pose risks to individuals, particularly in exacerbating discrimination against marginalized communities.
Many in industry disagree with expanding the definitional scope, and posit that identification/verification technologies pose very different types and levels of risks from detection and characterization, and thus there should be a regulatory distinction.
As policymakers consider how to regulate biometric data, they should understand the different technologies, risks associated with each, existing laws and frameworks, and take into account the policy arguments for how the law should interact with these emerging technologies (such as “characterization” and “detection”) that rely on an individual’s physical data but are not used to identify or track.
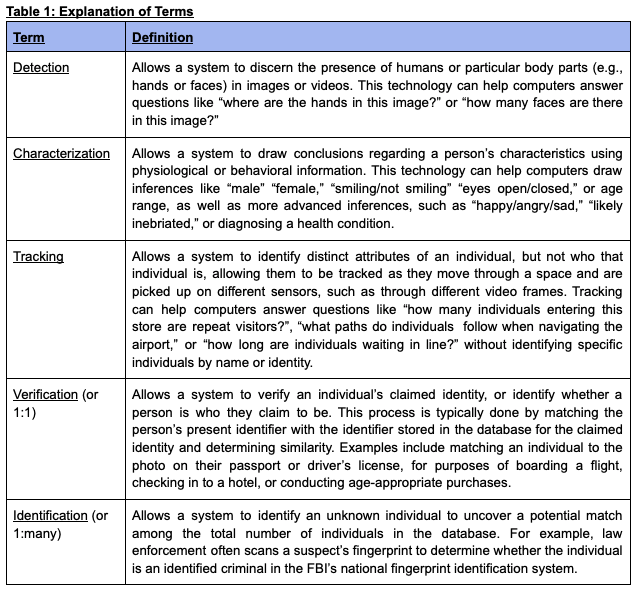
1. Types of Biometric and Body-Based Technologies
In Future of Privacy Forum’s 2018 Privacy Principles for Facial Recognition Technology in Commercial Applications, FPF distinguished between five types of facial recognition technologies: detection, characterization, unique persistent tracking, 1:1 verification, and 1:many identification. The same distinctions apply readily to the broader world of biometric data. Most notably, unlike identification and verification, detection and characterization technologies are developed to detect or infer bodily characteristics or behavior but the subject is not identifiable (meaning PII is typically not retained), unless the user actively links the data to a known identity or unique profile. A brief explanation of terms and distinctions are provided in Table 1.
In considering these distinctions, the OSTP responses broadly showcased two contrasting frameworks for which technologies should fall under the scope of “biometrics”:
Biometric data should be defined by the source of the data itself– i.e. it’s biometrics because it’s data derived from an individual’s body–therefore, any processing activity dependent on data from an individual’s body, including detection and characterization, should be regulated under biometric privacy laws.
Biometric data should be defined by the processing activity–i.e. it’s biometrics because it’s unique physical data used to identify or verify individuals–therefore only those uses should be regulated under biometric privacy laws. Since detection and characterization are not used for identification, they should not fall within the scope of the law.
2. “Biometrics” Under Existing Legal Frameworks in the U.S.
Definitions in U.S. state biometric privacy laws and comprehensive data privacy laws largely limit the scope of “biometric information” or “biometric data” to data collected for purposes related to identification, with some exceptions (including Texas, and emerging case law in Illinois) (see Table 2). Biometric data privacy laws in the U.S. were mainly passed to mitigate privacy and security risks associated with individuals’ biometric data since the data is inherently unique and cannot be altered. For example, Section 14/5 in the Illinois Biometric Privacy Act states:
Biometrics are unlike other unique identifiers that are used to access finances or other sensitive information. For example, social security numbers, when compromised, can be changed. Biometrics, however, are biologically unique to the individual; therefore, once compromised, the individual has no recourse, is at heightened risk for identity theft, and is likely to withdraw from biometric-facilitated transactions.
How U.S. policymakers and the courts have thought about the scope of these laws is heavily dependent on the Illinois Biometric Privacy Act (BIPA)–the seminal biometric privacy law in the U.S. Importantly, BIPA contains a private right of action that has allowed courts to decide the boundaries of what technologies should and should not be within the scope of the law. The technologies most targeted under the law include social media photo tagging features, employee timekeeping verification systems, and facial recognition. Thus far, there appears no state or federal court that has conclusively held that BIPA applies to purely detection-based or characterization technology that is not used for identification or verification purposes. Ongoing litigation, however, appears to be raising important questions on whether and when detection and characterization technologies overlap with terms used to define biometrics in the law. For example, in Gamboa v. The Procter & Gamble Company, the Northern District of Illinois must decide to what extent “facial geometry” can apply to uses such as the detection of a toothbrush position in your mouth.
Jurisdiction
Definition
Illinois* 740 ILCS 14
“Biometric information” means any information, regardless of how it is captured, converted, stored, or shared, based on an individual’s biometric identifier used to identify an individual. Biometric information does not include information derived from items or procedures excluded under the definition of biometric identifiers.
“Biometric identifier” means a retina or iris scan, fingerprint, voiceprint, or scan of hand or face geometry.*
“Biometric identifier” does not include: – writing samples, written signatures, photographs, human biological samples used for valid scientific testing or screening, demographic data, tattoo descriptions, or physical descriptions such as height, weight, hair color, or eye color. – donated organs, tissues, or parts as defined in the Illinois Anatomical Gift Act or blood or serum stored on behalf of recipients or potential recipients of living or cadaveric transplants and obtained or stored by a federally designated organ procurement agency. – biological materials regulated under the Genetic Information Privacy Act. – information captured from a patient in a health care setting or information collected, used, or stored for health care treatment, payment, or operations under the federal Health Insurance Portability and Accountability Act of 1996. – X-ray, roentgen process, computed tomography, MRI, PET scan, mammography, or other image or film of the human anatomy used to diagnose, prognose, or treat an illness or other medical condition or to further validate scientific testing or screening.
*The Illinois Biometric Privacy Law defines both “biometric information” and “biometric identifier,” with the substantive requirements of the law applying to both. Some emerging case law is finding that BIPA applies to processing of biometric identifiers even when a specific individual is not being identified but nonetheless is being used for facial recognition software. See, e.g. Monroy v. Shutterfly, Inc., Case No. 16 C 10984 (N.D. Ill. Sep. 15, 2017); In re Facebook Biometric Info. Privacy Litig., 185 F. Supp. 3d 1155 (N.D. Cal. 2016).
Washington Wash. Rev. Code Ann. §19.375.020
“Biometric identifier” means data generated by automatic measurements of an individual’s biological characteristics, such as a fingerprint, voiceprint, eye retinas, irises, or other unique biological patterns or characteristics that is used to identify a specific individual. “Biometric identifier” does not include a physical or digital photograph, video or audio recording or data generated therefrom, or information collected, used, or stored for health care treatment, payment, or operations under the federal health insurance portability and accountability act of 1996.
Texas RCW §19.375.020
“Biometric identifier” means a retina or iris scan, fingerprint, voiceprint, or record of hand or face geometry.”
California (“CPRA”) §1798.140(c)
“Biometric information” means an individual’s physiological, biological or behavioral characteristics, including information pertaining to an individual’s deoxyribonucleic acid (DNA), that is used or is intended to be used singly or in combination with each other or with other identifying data, to establish individual identity. Biometric information includes, but is not limited to, imagery of the iris, retina, fingerprint, face, hand, palm, vein patterns, and voice recordings, from which an identifier template, such as a faceprint, a minutiae template, or a voiceprint, can be extracted, and keystroke patterns or rhythms, gait patterns or rhythms, and sleep, health, or exercise data that contain identifying information.
Virginia §59.1-571
“Biometric data” means data generated by automatic measurements of an individual’s biological characteristics, such as a fingerprint, voiceprint, eye retinas, irises, or other unique biological patterns or characteristics that is used to identify a specific individual.
“Biometric data” does not include a physical or digital photograph, a video or audio recording or data generated therefrom, or information collected, used, or stored for health care treatment, payment, or operations under HIPAA.
Utah S.B.0227
“Biometric data” includes data described in Subsection (6)(a) that are generated by automatic measurements of an individual’s fingerprint, voiceprint, eye retinas, irises, or any other unique biological pattern or characteristic that is used to identify a specific individual.
“Biometric data” does not include: (i) a physical or digital photograph; (ii) a video or audio recording; (iii) data generated from an item described in Subsection (6)(c)(i) or (ii); (iv) information captured from a patient in a health care setting; or (v) information collected, used, or stored for treatment, payment, or health care operations as those terms are defined in 45 C.F.R. Parts 160, 162, and 164.
Connecticut SB6
“Biometric data” means data generated by automatic measurements of an individual’s biological characteristics, such as a fingerprint, a voiceprint, eye retinas, irises or other unique biological patterns or characteristics that are used to identify a specific individual.
“Biometric data” does not include (A) a digital or physical photograph, (B) an audio or video recording, or (C) any data generated from a digital or physical photograph, or an audio or video recording, unless such data is generated to identify a specific individual
Table 2. Definitions of Biometric Data in U.S. Laws
3. Arguments for Expanding Biometric Regulations to Include Detection and Characterization Technologies
The OSTP RFI demonstrates how the scope of biometric privacy laws could be expanded beyond identification-based technologies. The RFI used “biometric information” to refer to “any measurements or derived data of an individual’s physical (e.g., DNA, fingerprints, face or retina scans) and behavioral (e.g., gestures, gait, voice) characteristics.” The OSTP further noted that “we are especially interested in the use of biometric information for: Recognition…and Inference of cognitive and/or emotion state.”
Many respondents, largely from civil society and academia, discussed the risks of technologies that collected and tracked an individual’s body-based data for detection, characterization, and other inferences. Specific use cases identified in the responses included: counting the number of customers in a store (by detecting and counting faces in video footage), diagnosing a skin condition, tools used to infer human emotion, disposition, character, intent (EDCI), eye and head movement tracking, and vocal biomarkers (or medical deductions based on inflections in your voice).
In all of these examples, respondents emphasized that bodily detection and characterization technologies carry significant risks of inaccuracy and discrimination. Even if not used to identify or track, respondents argued that detection and characterization technologies are still harmful and unreliable, largely because they are built upon unverified assumptions and pseudoscience. For instance, respondents noted that:
EDCI tooling (using facial characterization to infer emotional or mental states) is not reliable because there is no reliable or universal relationship between emotional states and observable biological activity.
Video analytics that claim to detect lies or deception through eye tracking are unreliable because the link between high-level mental states such as “truthfulness” and low-level, involuntary external behavior is too ambiguous and unreliable to be of use.
The real-world performance of models used to diagnose patients based on speech and language (vocal biomarkers) are not properly validated.
As a result, many experts argued that these systems exacerbate discrimination and existing inequalities against protected classes, most notably people of color, women, and the disabled. For example, Dr. Joy Buolamwani, a leading AI ethicist, points to her peer-reviewed MIT study demonstrating how commercial facial analysis systems used to detect skin cancer exhibit lower rates of accuracy for darker-skinned females. As a result, women of color have a higher rate of misdiagnosis. In another example, the Center for Democracy and Technology notes, in examining the use of facial analysis for diagnoses:
“. . . facial analysis has been used to diagnose autism by analyzing facial expressions and repetitive behaviors, but these attributes tend to be evaluated relative to how they present in a white autistic person assigned male at birth and identifying as masculine. Attributes related to neurodivergence vary considerably because racial and gender norms cause other forms of marginalization to affect how the same disabilities present, are perceived, and are masked. Therefore, people of color, transgender and gender nonconforming people, and girls and women are less likely to receive accurate diagnoses particularly for cognitive and mental health disabilities…” (citations omitted).
Accordingly, many respondents recommended expanding the existing biometrics framework to a broader set of technologies that collect and track any data derived from the body, including detection and characterization, because they similarly carry risk that could be mitigated by federal guidelines and regulation. Specifically, some of the policy proposals set forth in RFI comments included:
Banning or severely limiting the government’s use of biometric technologies, including detection and characterization using an individual’s physical features;
Prohibiting all use of of biometric data collection without express consent; and
Requiring private entities collecting any form of biometric data to demonstrate that the system does not disparately impact marginalized communities through rigorous testing, auditing, and oversight.
4. Arguments Against Expanding Biometric Regulations to Equally Apply to Detection and Characterization Technologies
Many respondents from the technology and business communities argued against the OSTP’s broad scope of “biometrics” to include all forms of bodily measurement as inconsistent with existing laws and scientific standards. Accenture, SIIA, and MITRE cited definitions set forth by the National Institute of Science and Technology (NIST), National Center for Biotechnology Information (NCBI), Federal Bureau of Investigation, and Department of Homeland Security, as well as the U.S. state biometric and comprehensive privacy laws, which all limit “biometrics” to recognition or identification of an individual. As a result, most businesses have relied on this framework, and the guidance set forth by these entities, in developing their internal practices and procedures for processing such data.
Respondents also argued that there are distinct uses, processes, and risk-profiles between systems used for identification and verification versus those used for detection and characterization. Where identification, verification, and tracking technologies are directly tied to an individual’s identity or unique profile, and thus carry specific privacy concerns, detection and characterization technologies do not necessarily carry such risks when not employed against known individuals. Therefore, many respondents argued, implementing a horizontal standard for biometrics, such as blanket bans, that conflates all technologies may cause unintended consequences, largely by hindering the progress of low-risk and valuable applications that are relied upon in our society. Some examples presented of lower-risk use cases for bodily detection and characterization include:
Face detection for a camera to provide auto-focus features;
Skin characterization to diagnose skin conditions from images;
Video analytics to determine the number of humans in a store to abide by COVID restrictions.
Assistive technology, such as speech transcription tools or auto-captioning;
With these technologies, industry experts emphasize that applications do not necessarily identify individuals, but process physical characteristics to deliver beneficial products or services. Though many companies acknowledged risks related to accuracy, bias, and discrimination against marginalized populations, they argued that such risks should be addressed outside the framework of “biometrics” – instead addressed through a risk-based approach that distinguishes the types, uses, and levels of risk with different technologies. Because identifying-technologies often pose a higher risk of harm, respondents noted that it is appropriate that they incorporate more rigorous safeguards, however, those safeguards may not be equally necessary or valuable to other technologies.
Some examples of policy proposals provided by respondents that tailor the regulation to the specific use case or technology include:
Requiring that biometric systems operate with certain allowable limits of demographic differentials for the specified use-case(s);
Requiring that automated decisions be human adjudicated for certain intended use case(s);
Establishing heightened requirements for law enforcement use of biometric information used for identification purposes;
What’s Next?
At the end of the day, all technologies relying on data derived from our bodies carry some form of risk. Bodily characterization and detection technologies may not always carry privacy risks, but may nonetheless lead to invasive forms of profiling or discrimination that could be addressed through general AI regulations – such as requirements to conduct impact assessments or independent audits. Meanwhile, disagreements over definitions of “biometrics” may be overshadowing the key policy questions to be addressed, such as how to differentiate and mitigate current harms caused by unfair or inaccurate profiling.