As you go through your day, everyone wants to know something about you. The bouncer at a bar needs to know you are over 21, the park ranger wants to see your fishing license, your doctor has to review your medical history, a lender needs to know your credit score, the police must check your driver’s license, and airport security has to confirm your ticket and passport. In the past, you would have a separate piece of paper or plastic for each of these exchanges, but the Information Revolution has caused a dramatic shift to digital and virtual channels. Shopping, banking, healthcare, gaming, even therapy and exercise, are all activities that can now be performed partially or entirely using online platforms and services. However, systems using digital transactions struggle to establish trust around personal identification because personal login credentials vary for every account and passwords are forgettable and frequently insecure. Largely because of this “trust gap,” the equivalent of personal identity credentials like a passport and driver’s license have notably lagged other services in moving to an online format. That is starting to change.
Potentially, all these tasks can be accomplished with a single “digital identity,” a system of electronically stored attributes and/or credentials that uniquely identify an individual person. Digital identity systems vary in complexity. At its most basic, a digital ID would simply recreate a physical ID in a digital format. For instance, digital driver’s licenses are coming to augment, and possibly eventually replace, the physical driver’s license or state-issued ID we carry now. Available via an app that provides the platform for verification and security, these digital versions can be used in the same way as a physical ID, to provide for authentication of our individual attributes like a unique ID number (Social Security number), birthdate (Driver’s License), citizenship (passport) or other government-issued, legal aspects of personhood.
At the other end of the spectrum, a fully integrated digital identity system would provide a platform for a complete wallet and verification process, usable both online and in the physical world. That is, it would authenticate you as an individual, as above, but also tie to all the accounts and access rights you hold, including the credentials represented by those attributes. Such a system would enable you to share or verify your school transcripts or awarded degrees, provide your health records, or access your online accounts and stored data. This sort of credentialing program can also act as an electronic signature, timestamp, or seal for financial and legal transactions.
There are a variety of technologies being explored to provide this type of platform, although there is no clear consensus or standard at this time. There are those who advocate for “self-sovereign identity,” wherein a blockchain-based platform allows individuals to directly control the release of their own information to designated recipients. There are also mobile-based systems that use a combination of cloud and local storage via a mobile device in conjunction with an app to offer a single identity verification platform.
These proposed identification systems are being designed for use in commercial circumstances as well as for accessing government systems and benefits. In countries with national identification cards (most countries other than the U.S and the UK), the national ID may come to be issued digitally even sooner. Estonia has the most advanced example of such a system, and everyone there who has been issued a government ID can provide digital signatures and authentication via their mobile platform as well as use it as a driver’s license, a health service identifier, a pass to public transport, a travel document, to vote, or for banking.
The concept of named spaces and creating unique identifiers is older than the internet itself. Started in 1841, and fully computerized by the 1970s, Dun and Bradstreet operate a database containing detailed credit information on over 285 million businesses, making them one of the key providers of analytics and other services for over a century of commercial data. Their unique 9-digit identifier is the foundation of their entire system.
The UK’s Companies House, the state registrar for public companies, traces back to the Joint Stock Companies Act of 1844, and the formation of shareholder enterprises. Like D&B, companies are recorded on a public register, but with the added requirement to include the personal data that the Registrar maintains on company personnel; for example, Directors must record name, address, occupation, nationality, and date of birth. The advent of mandatory passports in the twentieth century, along with pseudonymous identification of individuals by governments, such as with Social Security numbers, furthered this trend of personal records based on unique individual identities (and not without controversy).
With the advent of the internet, online identities exploded into every facet of financial, commercial, entertainment, and educational or professional lives, and today many people have tens, if not hundreds, of personal accounts and affiliations, each with a unique, numbered, or assigned digital record. Maintaining awareness of all our accounts has become almost impossible, much less having adequate and accurate oversight as to the security of each vendor, site, or set of login credentials. The possibility of transitioning these accounts to be interoperable with a single, secure digital ID is now becoming more feasible due to advances in mobile technology, faster and less expensive biometric systems, and the availability of cloud services and fast processing capabilities.
How Digital Identity Works
In the past, a new patient at the doctor’s office must have provided at least three separately sourced documents: a driver’s license, a health insurance card, and medical history. Even now, many offices take a physical license or insurance card and make a digital copy for their file. A digital wallet would allow a new patient to identify themselves, provide proof of insurance, and medical history all at once, via their smartphone or other access option.
Importantly, by digitally sending a one-time identity token directly to the vendor or health provider, these systems can be designed to provide the authentication or verification of a status or credential (e.g., an awarded degree), without physically handing over a smartphone and without providing the underlying data (the full transcript). By granularly releasing identity data as necessary for authorization, an ID holder will not have to include or provide more information than is needed to complete the transaction. That bouncer at the bar simply must know you are “over 21,” not your actual birthdate, much less your name and address.
An effective digital ID must be able to perform at least four main tasks:
authentication – ensure that a person is the “true” owner of an identity,
verification – verify specific identity attributes or determine the authenticity of credentials,
authorization – determine what actions may be performed or services accessed on the basis of the authenticated identity, and lastly,
federation – a process for the conveyance of authentication credentials and subscriber attributes across networked systems without sharing excess or unnecessary information.
To authenticate an individual, the system must ensure that a person is who they claim to be, protecting sufficiently against both false negatives – not allowing access to the legitimate account holder, as well as false positives – wrongly allowing access to unauthorized individuals. Security best practices require that authentication be accomplished via a multi-factor system, requiring two of the three options: something you know (password or pin code, security question), something you have (a smart card, specific mobile device, or USB token), or something you are (a biometric).
[NOTE: a biometric is a unique, measurable physical characteristic which can be used to recognize or identify a specific individual. Facial images, fingerprints, and iris scans samples are all examples of biometrics. For authentication purposes, such as in the digital identity systems under discussion, biometrics are matched on a 1:1 or 1:few process against an enrolled template. The template, specific to the system provider and not interoperable with other systems, may be stored locally on the device, or in cloud storage. However, since operational or circumstantial considerations may preclude the use of biometrics in all cases, systems intended for mass access must offer alternatives as well. The details of biometric systems and the particular risks and benefits thereof are beyond the scope of this article, but while not all digital identity systems are based on biometrics, most will likely include some form of biometric within their authentication processing.]
Once an ID holder is authenticated, the specific attributes or credentials must be verified. This involves confirming that the ID holder has earned or been issued the credentialed attributes they are claiming, whether from a financial institution, an employer, an educational institution, or a government agency.
Authentication and verification may be all that is required for some transactions, but where needed, the system must also be able to confirm authorization, that is, to determine what the person is allowed to see or do within a given system. Successful privacy and security for businesses, organizations, and governments require the enforcement of rigorous access controls. Who can see certain data is not always the same as the person authorized to change or manipulate it. The person authorized to manipulate or process it may not be entitled to share it or delete it. Successfully setting and enforcing these controls is one of the most challenging features for any organization which collects and uses personal data.
While the first three steps in digital identity systems exist in various forms already, a truly universal digital identity is likely to be successful at a mass scale only if it is federated, meaning that the ID must be usable across institutional, sectoral, and geographic boundaries. A federated identity system would be the most significant departure from every account-specific login or access process that exists today. To accomplish such wide-ranging compatibility will require a common set of open standards that institutions, sectors, and countries establish collaboratively and implement globally. A digital wallet will need to seamlessly grant access across many networks, from a movie theater verifying over-17 aged entrants, banks processing loan applications, hospitals establishing patient status and access records, airports for boarding, or amusement parks and stadiums providing scheduled performances and perks.
Global banking and financial services are leading the way on this sort of broad implementation. Therefore, online banking is a constructive digital ID use case:
Authenticate – yes, this is Samir,
Verify – Samir has an account at this bank,
Authorize – Samir has a credit line authorizing him to borrow, which he accesses and e-signs, and
Federate – Samir’s mortgage lender accepts the money transfer from the bank via the digital ID platform.
Banks are motivated to forge ahead on such digital identity systems to improve fraud detection, streamline “know your customer” compliance processes, increase their ability to stop money-laundering and other finance-related crimes, and offer superior customer experiences. But by creating secure, standardized digital identity access for online banking, they may also offer engagement to the large portions of the globe that are currently un- or under-banked, and/or who have minimal governmental infrastructure around legal identity systems.
The Challenges and Opportunities
Privacy, security, equity, data abuse, and user control all raise unique challenges and opportunities for digital ID.
Digital identity, if not deployed correctly, may undermine privacy rights. If not implemented responsibility, and carefully controlled with both technical and legal safeguards, digital IDs might allow for increased location-tracking and user profiling, already a concern with cell phone technology. Blockchain technology, if not designed carefully, creates a public, immutable record of information exchanges, regarding where, when, and why a digital ID was requested. And a given digital ID provider may have too much power, with the ability to suppress ID holders from accessing their digital accounts. However, digital IDs also offer the possibility of increased privacy protection if systems are effectively designed to share only the minimum, necessary information, and identification is only established up to the level necessary for the particular exchange or transaction. “Privacy by design,” as well as appropriate defaults and system controls, can prohibit any of the network participants, including the operator, from complete access to the users’ transactions, particularly if accompanied by appropriate legislative or regulatory boundaries.
Digital ID likewise has both pros and cons for security. While not perfect, Digital IDs are generally harder to lose or be counterfeited than a physical document; and offer significantly greater security than an individual’s hundreds of separate login credentials across sites of uncertain levels of protection. However, poor adherence to best practices may result in a centralized location of personal and sensitive information, which may become a more appealing target for hackers, and increase the risk of a mass compromise of information. Centralized databases can be minimized by local storage of authenticating factors like biometrics, and distributed storage of other data with appropriate security measures and controls.
Inequities can occur along a number of different axes. Since digital identity designs may reflect society’s biases, it is important to mandate and continually measure inclusion and performance. For instance, the UK’s digital ID framework requires the ID issuers to submit an annual exclusion report. In addition, because not everyone has a smartphone or internet access, digital IDs risk increasing inequities among those with limited connectivity. Without reliable digital access, groups that have traditionally struggled may continue to lack the privileges that digital IDs promise to provide. On the other hand, according to the World Bank, an estimated 1.1 billion people worldwide cannot officially prove or establish their legal identity. In countries or situations without clear legal processes, or lacking information infrastructures, digital identity systems have the potential to provide people who do have smartphones or internet access the ability to receive healthcare, education, finance, and other essential services. Even those without access to a digital device could use a secure physical form, like a barcode, to maintain their digital identity.
Policy Impacts and Conclusion
Individuals are used to the ability to easily control the use of their physical documents. When you hand your passport to a TSA agent, you observe who is seeing it and how it is being used. A digital ID holder will need these same assurances, understanding, and trust. Therefore, ideally, users should be able to identify every instance that their identity was accessed by a vendor. Early systems, like the Australian Digital License App, give citizens some control over their credentials by enabling users themselves to specify the information to share or display. Legislative bodies and regulatory agencies designing or controlling such systems should work closely with industry representatives, security experts, consumer protection organizations, civil rights advocates, and other stakeholders to ensure fair systems are established and monitored appropriately.
Transparency of development, and public adoption processes and procurement systems will be vital to public trust in any such systems, whether privately or publicly operated. In some cases, such systems may even help educate and increase awareness among users of the information that is already collected and held about them, and where and how it is being used, as well as make it easier for them to exert control easily for the necessary sharing of their information.
Digital identification, integrated to greater or lesser degrees, seems an almost inevitable next step in our digital lives, and overall offers promising opportunities to improve our access and controls over the information already spanning the internet about us. But it is crucial that moving forward, digital ID systems are responsibly designed, implemented, and regulated to ensure the necessary privacy and security standards, as well as prevent the abuse of individuals or the perpetuation of inequities against vulnerable populations. While there are important cautions, digital identity has the potential to transform the way we interact with the world, as our “selves” take on new dimensions and opportunities.
At the intersection of AI and Data Protection law: Automated Decision-Making Rules, a Global Perspective (CPDP LatAm Panel)
On Thursday, 15th of July 2021, the Future of Privacy Forum (FPF) organised during the CPDP LatAm Conference a panel titled ‘At the Intersection of AI and Data Protection law: Automated Decision Making Rules, a Global Perspective’. The aim of the Panel was to explore how existing data protection laws around the world apply to profiling and automated decision making practices. In light of the European Commission’s recent AI Regulation proposal, it is important to explore the way and the extent to which existing laws already protect individuals’ fundamental rights and freedoms against automated processing activities driven by AI technologies.
The panel consisted of Katerina Demetzou, Policy Fellow for Global Privacyat the Future of Privacy Forum; Simon Hania, Senior Director and Data Protection Officer at Uber; Prof. Laura Schertel Mendes, Law Professor at the University of Brasiliaand Eduardo Bertoni, Representative for the Regional Office for South America, Interamerican Institute of Human Rights.The panel discussion was moderated by Dr. Gabriela Zanfir–Fortuna, Director for Global Privacy at the Future of Privacy Forum.
Data Protection laws apply to ADM Practices in light of specific provisions and/or of their broad material scope
To kick-off the conversation, we presented preliminary results of an ongoing project led by the Global Privacy Team at FPF on Automated Decision Making (ADM) around the world. Seven jurisdictions were presented comparatively, among which five already have a general data protection law in force (EU, Brazil, Japan, South Korea, South Africa), while two jurisdictions have data protection bills expected to become laws in 2021 (China and India).
For the purposes of this analysis, the following provisions are being examined: the definitions of ‘processing operation’ and ‘personal data’ given that they are two concepts essential for defining the material scope of the data protection law; the principles of fairness and transparency and legal obligations and rights that relate to these two principles (e.g., right of access, right to an explanation, right to meaningful information etc.); provisions that specifically refer to ADM and profiling (e.g., Article 22 GDPR).
The preliminary findings are summarized in the following points:
All seven jurisdictions have very broad definitions of both “processing operations” and “personal data”. Therefore, processing operations that use automated means (ADM included) fall under the protective scope of these laws.
Not all laws and draft laws analyzed contain ADM-specific provisions. 4 out of 7 jurisdictions have a specific ADM provision: EU (GDPR), Brazil (LGPD), South Africa (POPIA), China (draft PIPL). However, any automated processing, including ADM, is regulated by the examined laws and bills in light of their very broad material scope.
3 out of 7 laws and bills have a specific provision defining “profiling”: EU (GDPR), Brazil (LGPD), India (draft PDPB).
2 out of 7 laws and bills analyzed have a specific provision on Facial Recognition: South Korea (PIPA), China (draft PIPL).
All laws and bills analyzed have rights and obligations related to the principle of transparency (e.g., right of access) even if they do not have an explicit principle of transparency.
Fairness appears in the EU (GDPR), South Korea (PIPA), India (draft PDPB). However, the LGPD (Brazil) has a ‘non-discrimination’ principle and the draft PIPL (China) provides for a ‘principle of sincerity’.
Uber, Ola and Foodinho Cases: National Courts and DPAs decide on ADM cases on the basis of existing laws
In recent months, Dutch national Courts and the Italian Data Protection Authority have ruled on complaints brought by employees of the ride-hailing companies Uber and Ola and the food delivery company Foodinho challenging the companies’ decisions reached with the use of algorithms. Simon Hania summarised the key points of these court decisions. It is important to mention that all cases appeared in the employment context and were all submitted back in 2019. That means that more outcomes of ADM cases may be expected in the near future.
The first Uber case referred to the matching between drivers and riders which, as the Court judged, qualifies as an ADM based solely on automated means that however does not lead to any ‘legal or similarly significant effect’. Therefore, Article 22 GDPR is not applicable. The second Uber case referred to the deactivation of drivers’ accounts due to signals of potentially fraudulent behaviour or misconduct of the drivers. There, the Court judged that Article 22 is not applicable because, as the company proved, there is always human intervention before an account is deactivated and the actual final decision is made by a human.
The third example presented was the Ola case, whereby the Court decided that the company’s decision of withholding drivers’ money as an act of penalizing their misconduct qualifies as an automated decision based solely on automated means , producing a ‘legal or similarly significant effect’, and therefore Article 22 GDPR applies.
In the last example of Foodinho, the decision-making on how well couriers perform was indeed deemed by the Court to be based solely on automated means and it produced a significant effect on the data subjects (the couriers). The problem was highlighted to be the way that the performance metrics were established and specifically on the accuracy of the profiles created. They were not sufficiently accurate for the significance of the effect they would bring.
This last point spurs the discussion on the importance of the principle of data accuracy which is an often overlooked principle. Having accurate data as the basis for decision making is crucial in order to avoid discriminatory practices and achieve fairer AI systems. As Simon Hania emphasised, we should have information available that is fit for purpose in order to reach accurate decisions. This suggests that the data minimisation principle should be understood as data rightsizing and not as requiring to purely minimise information processed for a decision to be reached.
LGPD: Brazil’s Data Protection Law and its application to ADM practices
The LGPD, Brazil’s recently passed data protection law, is heavily influenced by the EU GDPR in general, but also specifically on the topic of ADM processing. Article 20 of the LGPD protects individuals against decisions that are made only on the basis of automated processing of personal data, when these decisions “affect their interests”. The wording of this provision seems to suggest a wider protection than the relevant Article 22 of the GDPR which requires that the decision “has a legal effect or significantly affects the data subject”. Additionally, Article 20 LGPD provides individuals with a right to an explanation and with the right to request a review of the decision.
In her presentation, Laura Mendes highlighted two points that require further clarification: first of all, it is still unclear what the definition of “solely automated” is. Secondly, it is not clear what the degree of the review of the decision should be and also whether the review shall be performed by a human. There are two provisions core to the discussion on ADM practices:
(a) Art 6 IX LGPD, which introduces the principle of non-discrimination as a separate data protection principle. According to it, processing of data shall not take place for “discriminatory, unlawful or abusive purposes”.
(b) Article 21 LGPD reads “The personal data relating to the regular exercise of rights by the data subjects cannot be used against them.” As Laura Mendes suggested, Article 21 LGPD is a provision with great potential regarding non-discrimination in ADM.
Latin America & ADM Regulation: there is no homogeneity in Latin American laws but the Ibero-American Network seems to be setting a common tone
In the last part of the panel discussion, a wider picture of the situation in Latin America was presented. It should be clear that Latin America does not have a common, homogenous approach towards data protection. For example, while Argentina has had a data protection law since 2000 for which it obtained an adequacy decision with the EU, Chile is in the process of adopting a data protection law but still has a long way to go, while Peru, Ecuador and Colombia are trying to modernize their laws.
The American Convention of Human Rights recognises a right to privacy and a right to intimacy, but there is still no interpretation by the Interamerican Court of Human Rights neither on the right to data protection nor specifically on the topic of ADM practices. However, it should be kept in mind that as was the case with Brazil’s LGPD, the GDPR has highly influenced Latin America’s approach to data protection. Another common reference for Latin American countries is the Ibero-American Network which, as Eduardo Bertoni explained in his talk, while it does not produce hard law, it publishes recommendations that are followed by the respective jurisdictions. Regarding specifically the discussion on ADM, Eduardo Bertoni mentioned the following initiatives taken in the Ibero-American space:
In 2017, the Ibero-American Standards for data protection were released. Article 29 of these Standards is a provision specific to ADM (“right not to be the subject of automated decisions”) that in content is very similar to Article 22 GDPR. Although these standards are only guidelines and not hard law, it is crucial to mention that the various jurisdictions in Latin America take them into account.
Another document published by the Ibero-American network are the ‘General recommendations for processing of personal data in AI’. An obligation to perform Privacy Impact Assessments and the principle of accountability seem to be important aspects of these recommendations.
The Argentinian DPA published a Resolution to interpret the Argentinian Data Protection Law.
The Interamerican Juridical Committee passed a set of principles for personal data protection, without including something specific on ADM. However Eduardo Bertoni highlighted that again the idea is to give the data subject the possibility to request explanation and to oppose the data processing when the processing could significantly affect or harm him/her.
Main Takeaways
While there is an ongoing debate around the regulation of AI systems and automated processing in light of the recently proposed EU AI Act, this panel brought attention to existing data protection laws which are equipped with provisions that protect individuals against automated processing operations. The main takeaways of this panel are the following:
Data protection laws around the world either have provisions that specifically regulate ADM practices (such as EU, Brazil, South Africa) or that apply to such practices in light of their broad material scope that protects individuals against processing operations also performed by automated means (such as South Korea, Japan, India).
In Europe, national Courts and Data Protection Authorities have already started ruling on cases with a specific focus on ADM practices. It is expected that more rulings will appear in the months / years to come.
Brazil provides a robust network of provisions for protection against ADM practices, not only in light of Article 20 LGPD (which highly resembles Article 22 GDPR), but also because it provides for a specific non-discrimination principle. However, there are elements that need to be clarified such as whether the review of an automated decision is required to be performed by a human.
The principles of accuracy and data minimisation should form part of the discussion around fair decision making either by humans or by algorithms. The data upon which a decision is based need to be accurate and need to also be as much as needed for the purposes of the specific decision. In that sense, the data minimisation principle should be understood as a “data rightsizing” principle.
Jurisdictions in Latin America have neither a common approach towards data protection nor a common pace in adopting or modernising their national data protection laws.
The Ibero-American Network can be seen as setting the common denominator in data protection standards for Latin American jurisdictions. While the Network does not produce hard law and its decisions are not binding, it publishes Standards and recommendations which are followed by the respective jurisdictions. It is thus important to keep an eye on the initiatives taken by this Network given that they will most probably be adopted by the LatAm jurisdictions.
Looking ahead, the debate around the regulation of AI systems will continue to be heated and the protection of fundamental rights and freedoms in light of automated processing operations will still appear as a top priority. In this debate we should keep in mind that the proposed AI Regulation is being introduced in an already existing system of laws, as is data protection law, consumer law, labour law, etc. It is important to have clear what is the reach and the nature of these laws so as to be able to identify the gap that the AI Regulation or any other future proposal comes to fill. This panel highlighted that ADM and automated processing is not unregulated. On the contrary, current laws protect individuals by putting in place binding overarching principles, legal obligations and rights. At the same time, Courts and national authorities have already started enforcing these laws.
Insights into the Future of Data Protection Enforcement: Regulatory Strategies of European Data Protection Authorities for 2021-2022
The Future of Privacy Forum released a report that brings “Insights into the future of data protection enforcement: Regulatory strategies of European Data Protection Authorities for 2021-2022”.
The European Data Protection Authorities (DPAs) are arguably the most powerful data protection and privacy regulators in the world, having been granted by the European Union’s General Data Protection Regulation (GDPR) broad powers and competences, in addition to independence. With GDPR enforcement visibly ramping up in the past year, it is important to get insight into the key enforcement areas targeted by regulators, as well as understanding what are those complex or sensitive personal processing activities where DPAs plan to provide compliance guidelines or to shape public policy.
Last year, FPF released a report called New Decade, New Priorities: A summary of twelve European Data Protection Authorities’ strategic and operational plans for 2020 and beyond. It outlined EU DPAs’ regulatory priorities for 2020 and the ensuing years, based on the documents of a strategic nature released by such authorities in the first half of last year. Since then, most DPAs have published their 2020 annual reports, as well as novel short or long-term strategies. These shed light on the areas to which DPAs are likely to devote significant regulatory efforts and resources, with a broad scope: guidance, awareness-raising, corrective measures, and enforcement actions.
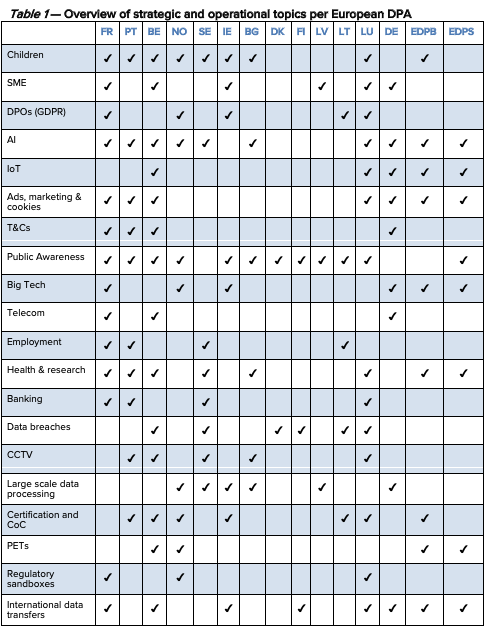
We have compiled and analyzed these novel strategic documents, describing where different DPA strategies have touchpoints and noteworthy particularities. The report contains links to and translated summaries of 15 DPAs’ strategic documents from DPAs in France (FR), Portugal (PT), Belgium (BE), Norway (NO), Sweden (SE), Ireland (IE), Bulgaria (BG), Denmark (DK), Finland (FI), Latvia (LV), Lithuania (LT), Luxembourg (LU) and Germany (Bavaria). The analysis also includes documents published by the European Data Protection Board (EDPB) and the European Data Protection Supervisor (EDPS). These documents complement or replace the ones that were included in our 2020 report.
Some of our main conclusions include:
DPAs tend to rely on a risk-based approach when using their investigative and corrective powers, promising to focus on areas that have the potentially most negative impacts on data subjects.
DPAs seem to be on a trend to modernize their regulatory approach, several of them proposing sandboxes (e.g., the CNIL and the Norwegian DPA), and pushing for more self-regulation, like the adoption of Codes of Conduct.
DPAs also plan on dedicating efforts to make GDPR compliance work in practice on a large scale by targeting the empowerment of DPOs and by adopting tailored guidance for SMEs;
Regulators seem to be responding to recent CJEU case law on online tracking and international data transfers by planning to ramp up their enforcement action in these areas.
DPAs seem committed to tackling the privacy and data protection risks posed by the uptake of AI/ML technologies across society, in a sign that the AI Regulation proposed by the European Commission will merely complement protections that are already in place for individual rights. The Bulgarian DPA will focus on ensuring facial recognition and profiling techniques comply with legal standards, while the EDPS promises to develop oversight, audit and assessment capabilities for such technologies.
The protection of personal data of children is identified as a near term priority by a majority of DPAs, with plans for both guidance and enforcement actions being announced (9 of the 15 regulators included children data as a priority).
The EDPB will continue to work for a consistent application of privacy and data protection instruments across the EU, by issue guidance on key concepts (e.g., data subjects’ rights, legitimate interests, scientific research, children’s data) and on data protection compliance aspects of new technologies (e.g. blockchain, PETs, AI/ML, Digital Identity, IoT and payment methods)
DPAs across the bloc also seem to be aligned with the European Commission’s and the French Government’s plan to achieve a European “digital sovereignty” in the new decade. As such, enhanced enforcement of data protection rules against large foreign tech players may be expected.
Spotlight on the Emerging Chinese Data Protection Framework: Lessons Learned from the Unprecedented Investigation of Didi Chuxing
As China is making headlines with its ramped up efforts to build a comprehensive data protection, privacy and cybersecurity legal framework with broad extraterritorial effects, a recent landmark enforcement action of the Cyberspace Administration of China (CAC) against one of the largest tech companies in the country shines a light on how the future privacy regulator and the Chinese government are approaching enforcement of data-related laws.
On July 2, 2021, CAC announced the launch of a cybersecurity review of Didi Chuxing (Didi), two days after the Chinese ride-hailing leader’s $4 billion IPO in New York. This is the first time the CAC has publicly initiated this type of review, likely making the Didi investigation the highest profile case launched under China’s emerging data protection framework.
The “cybersecurity review” is a relatively new enforcement tool in CAC’s regulatory toolbox, introduced by the Cybersecurity Review Measures (CRM) in June 2020. It addresses “critical information infrastructure operators”, who must anticipate potential national security risks of network products and services. If the operator determines that these products and services influence national security, the operator must submit a cybersecurity review to the CAC. Upon receiving the review, the CAC then determines whether to launch a formal administrative audit to test for compliance and security – and this is the first time it publicly decided to do so.
The consequence? The CAC demanded that Didi prevent new users from signing up to its service until completion of the review. Following this, regulators also issued a notice requesting the company remove its 25 related apps from the app-store and announced reviews of three more Chinese companies. These measures were imposed before the investigation is completed, making them some of the toughest preliminary measures in data-related investigations from digital regulators around the world.
Below we consider the high level takeaways of the decision and its implications for data protection in China going forward, considering that the CAC is designated as the enforcer of the future Personal Information Protection Law (PIPL) which is at its second reading and is expected to pass by the end of this year, and of the 2017 Cybersecurity Law (CSL).
1. “Critical Information Infrastructure Operators” could mean any tech company, including ride hailing service providers
Some of the most consequential provisions of the CSL and of the future PIPL are applicable to “Critical Information Infrastructure Operators”, a notion that has been surrounded by certain ambiguity since it was introduced in China’s legal framework. Article 37 of the Cybersecurity Law (CSL) requires these operators to store in China personal information and “important data” collected and generated by their operations within China. If they need to send such data abroad due to business necessity, they must additionally undergo a security assessment by competent authorities.
Since the enactment of the CSL in 2017, the vague wording of the article has generated a lot of confusion as to what constitutes “critical information infrastructure”, as many have raised concerns that the open-ended nature of the definition could theoretically encompass all types of data processing activities. In part, the CRM aims to streamline this process and provide a mechanism for these operators to undergo mandatory security reviews under the CSL.
Additionally, the draft PIPL also includes specific rules for Critical Information Infrastructure Operators, in particular with regard to international data transfers. The draft law requires that where such operators need to provide personal information abroad, they must “pass a security assessment organized by the State cybersecurity and informatization department” (Article 40), softening thus the strict data localisation requirement. This seems to be the same type of security audit performed in the Didi investigation, making this case relevant to understand how the CAC and Chinese authorities approach such an assessment.
The fact that Didi, a ride-hailing company, is treated as a Critical Information Infrastructure Operator indicates that the authorities indeed take a broad view of what “critical infrastructure” means, creating more uncertainty with regard to what entities are subject to this enhanced level of scrutiny.
2. There is a link between mobility data, including location data, and national security, making it an ideal candidate for “important data”
While a detailed motivation for the “cybersecurity review” of Didi has not been published beyond announcing that it is happening pursuant to the CRM, considering the nature of data processed by a ride hailing company like Didi indicates that the authorities see a link between mobility data, data localization requirements and national security.
Chinese regulators have recently published draft rules for privacy and security in the connected vehicles industry through theDraft Several Provisions on the Management of Automobile Data Security, which require operators to block cross-border data transfers when the “management and legal systems are imperfect.” While ambiguous, this provision leaves open the possibility that insufficient compliance provides a ground for strict localization. Because access to data is critical for success in this industry, the Chinese government has attached significant importance to mobility relevant data.
In fact, through this investigation, the authorities may also be signaling to the market that such data could qualify as “important data” — a concept used in many data protection laws in China to refer to information that implicates national security. Indeed, the intertwining of national security with personal information protection is becoming one of the key features of China’s data protection regime.
The use of the CRM process to crack down on Didi indicates that Beijing is taking the disclosure of such information very seriously. Reports indicate that the CAC requested Didi to alter its mapping function prior to its IPO in the United States. Didi’s mapping function is primarily responsible for organizing complex location data, including pickup and drop-off locations of rides. Given some mandatory disclosure requirements under U.S. securities law for companies that want to be publicly traded, particularly the recently enacted Holding Foreign Companies Accountable Act (HFCAA), the Chinese government may have been overcautious in wanting to prevent disclosing any sensitive information to US authorities – even though, in fact, US law does not require Didi to disclose this type of user information.
3. The new data protection framework will likely not be a paper tiger
Removing all connected apps from the app store and preventing any new users from registering with the company are measures that have very serious consequences on a tech company and its business. These measures have been requested by the CAC as preliminary measures to be implemented for the duration of the review concerning Didi. They also confirm a radical turn in the government’s attitude towards enforcement and compliance in the digital market, following a trend that has been visible already for a while.
The increased pressure to comply stands in contrast with the previous approach the Chinese government took towards the growth of Internet companies. In the past, emerging tech firms were allowed to adopt a laissez-faire approach to their growth strategies and often pursued aggressive data collection and processing methods to compete with other tech giants and their global competitors while downplaying the importance of compliance. With the emergence of broad cybersecurity and data protection measures like the Data Security Law (DSL) – which will enter into force this September, the draft PIPL and the 2017 CSL, Chinese regulators are signaling that non-compliance will result in real penalties.
The Didi decision also exposes some ambiguity in China’s regulatory system and in the way it is enforced. Particularly, it is difficult to pinpoint exactly where the review was initiated in China’s complex administrative bureaucracy. 12 ministries help coordinate cybersecurity reviews under the CRM, each with their own offices, personnel, and regulatory competences. In many instances, these competences may conflict as regulators attempt to assert their own prerogatives and priorities over particular tech companies. The CAC announced in mid-July that more than six Chinese agencies had initiated investigations into Didi regarding its planned IPO. While Internet regulation is largely centralized through the CAC, specific decisions are carried out by a range of other government bodies, sometimes in coordination with each other and sometimes not.
Administrative clarification could help produce more certainty in the system but without guidance from the very top, agencies and government offices within China’s bureaucracy often take their own initiative to demarcate regulatory boundaries. Domestic backlash in China against large tech companies has also fueled recent regulatory developments and provided the Chinese government a popular mandate to strengthen national control over the platform economy.
4. Data protection, understood broadly, seems to be used as a lever to effectuate broader policy goals
Data protection seems to be understood broadly in China as encompassing cybersecurity, data governance, data localization as much as, or even more than privacy considerations and fair information practices with regard to personal information.
As stated above, the Didi review is the first public announcement of an investigation under the CRM since its formal enactment in June 2020. In many ways unprecedented, the Didi investigation is a consolidating step in China’s emerging data protection framework. This framework includes a range of regulatory tools designed to strengthen control over the digital economy and reign in the influence of large platforms in China. Chinese regulators view the solidification of these regulatory tools as the next stage in the evolution of data governance and the digital economy more broadly.
It also looks like this consolidated regulatory regime is becoming a tool for Chinese regulators to assert their economic interests both at home and abroad and toeffectuate broader policy goals in the geopolitical arena. For example, Didi’s cybersecurity review may be more directly related to other regulatory goals, such as incentivizing Chinese tech companies to host public offerings in Hong Kong or Shanghai rather than foreign markets. Indeed, in the past few weeks, many Chinese companies have followed suit and halted their IPO prospects in the face of cybersecurity audits.
This cybersecurity probe complements recent actions taken by the Chinese government to impose more oversight on overseas listings. For instance, the Data Security Law, which will go into effect in September, requires that Chinese entities not provide data stored within China to “foreign justice or law enforcement bodies” without permission from regulatory authorities. The CAC seems to be taking an active role in monitoring the oversea foreign listings of Chinese tech firms through its cybersecurity competences and the CRM process.
The broader policy goals pursued by the data security requirements, cybersecurity review measures and the new personal information protection regime are becoming increasingly visible. On July 10 the CAC issued a notice to solicit comments for a revision of the CRM — only just one week after the public announcement of Didi’s review under the same legal regime. The revisions include:
Harmonizing the CRM process with the expected Data Security Law — an indication that the concept of “important data” will play a more fundamental role in the cybersecurity audits of Chinese firms,
Expanding the scope of operators under the scope of the CRM review process to include “data handlers conducting data handling activities that may influence national security” – with the mention that “data handlers” are the entities expected to comply with the personal information protection obligations under the future PIPL (the equivalent of a “data controller” under EU’s General Data Protection Regulation); and
Adding a bright line threshold to require any operator holding personal information of over 1 million users who list stock abroad to make a mandatory cybersecurity filing under the CRM. The provision notably does not apply to listings in Hong Kong.
In particular, the inclusion of this bright line threshold is significant because it indicates that Chinese regulators are strengthening the country’s personal information protection system even before the solidification of the PIPL. Internet companies in China now must make a correlation between their processing of personal information and internal cybersecurity audits both before and after offering these services abroad.
With the newly revised CRM and recent Didi investigation, cybersecurity audits are becoming a central feature of China’s data protection ecosystem – one that turns on both the protection of personal and non-personal information. The formal adoption of the DSL and PIPL this year will add to this but in many respects Chinese regulators have already begun laying the groundwork of a new, far reaching, regulatory regime for data and the tech sector.
Uniform Law Commission Finalizes Model State Privacy Law
This month, the Uniform Law Commission (ULC) voted to approve the Uniform Personal Data Protection Act (UPDPA), a model bill designed to provide a template for uniform state privacy legislation. After some final amendments, it will be ready to be introduced in state legislatures in January 2022.
The ULC has been engaged in an effort to draft a model state privacy law since 2019, with the input of advisors and observers, including the Future of Privacy Forum. First established in 1892, the ULC has a mission of “providing states with non-partisan, well-conceived and well-drafted legislation that brings clarity and stability to critical areas of state statutory law.” Over time, many of its legislative efforts have been very influential and become law in the United States — for instance, the ULC drafted the Uniform Commercial Code in 1952. More recently, the ULC drafted the Uniform Fiduciary Access to Digital Assets Act (2014-15), which has been adopted in at least 46 states.
The UPDPA departs in form and substance from existing privacy and data protection laws in the U.S., and indeed internationally. The law would provide individuals with fewer, and more limited, rights to access and otherwise control data, with broad exemptions for pseudonymized data. Further, narrowing the scope of application, UPDPA only applies to personal data “maintained” in a “system of records” used to retrieve records about individual data subjects for the purpose of individualized communication or decisional treatment. The Prefatory Note of a late-stage draft of the UPDPA notes that it seeks to avoid “the compliance and regulatory costs associated with the California and Virginia regimes.”
Central to the framework, however, is a useful distinction between “compatible,” “incompatible,” and “prohibited” data practices, which moves beyond a purely consent model based on the likelihood that the data practice may benefit or harm a data subject. We also find that the model laws’ treatment of Voluntary Consensus Standards offers a unique approach towards implementation that is context and sector-specific. Overall, we think the ULC model bill offers an interesting alternative for privacy regulation. However, because it departs significantly from existing frameworks, it could be slow to be adopted in states that are concerned with interoperability with recent laws passed in California, Virginia, and Colorado.
The summary below provides an overview of the key features of the model law, including:
Scope
Maintained Personal Data
Rights of Access and Correction
Pseudonymized Data
Compatible, Incompatible, and Prohibited Data Practices
Responsibilities of Collecting Controllers, Third-Party Controllers, and Processors
Voluntary Consensus Standards
Enforcement and Rulemaking
Read More:
Read the approved Uniform Personal Data Protection Act here.
UPDPA applies to controllers and processors that “conduct business” or “produce products or provide services purposefully directed to residents” in the state of enactment. Government entities are excluded from the scope of the Act.
To be covered, businesses must meet one of the following thresholds:
during a calendar year maintains personal data about more than [50,000] data subjects who are residents of the state, excluding data subjects whose data is collected or maintained solely to complete a payment transaction;
earns more than [50] percent of its gross annual revenue during a calendar year from maintaining personal data from data subjects as a controller or processor;
is a processor acting on behalf of a controller the processor knows or has reason to know satisfies paragraph (1) or (2); or
maintains personal data, unless it processes the personal data solely using compatible data practices.
The effect of threshold (4) is that UPDPA applies to smaller firms that maintain personal data, but relieves them of compliance obligations as long as they use the personal data only for “compatible” purposes.
Maintained Personal Data
UPDPA applies to “personal data,” which includes (1) records that identify or describe a data subject by a direct identifier, or (2) pseudonymized data. The term does not include “deidentified data.” UPDPA also does not apply to information processed or maintained in the course of employment or application for employment, and “publicly available information,” defined as information lawfully made available from a government record, or available to the general public in “widely distributed media.”
“Direct identifier” is defined as “information that is commonly used to identify a data subject, including name, physical address, email address, recognizable photograph, telephone number, and Social Security number.”
“Deidentified data” is defined as “personal data that is modified to remove all direct identifiers and to reasonably ensure that the record cannot be linked to an identified data subject by a person that does not have personal knowledge or special access to the data subject’s information.”
Narrowing the scope of application, UPDPA only applies to personal data “maintained” in a “system of records” used to retrieve records about individual data subjects for the purpose of individualized communication or decisional treatment. The committee has commented that the definition of “maintains” is pivotal to understanding the scope of UPDPA. To the extent that data collected by businesses related to individuals is not maintained as a system of records for the purpose and function of making individualized assessments, decisions, or communications, it would not be within the scope of the Act (for instance, if it were maintained in the form of emails or personal photographs). According to the committee, the definition of “maintains” is modeled after the federal Privacy Act’s definitions of “maintains” and “system of records”. 5 U.S.C. §552a(a)(3), (a)(5).
“Maintains” with respect to personal data, means “to retain, hold, store, or preserve personal data as a system of records used to retrieve records about individual data subjects for the purpose of individualized communication or decisional treatment.”
“Record” is defined as information: (A) inscribed on a tangible medium; or (B) stored in an electronic or other medium and retrievable in perceivable form.
Rights of Access and Correction
Access and Correction Rights: UPDPA grants data subjects the rights to access and correct personal data, excluding personal data that is pseudonymized and not maintained with sensitive data (as described below). Controllers are only required to comply with authenticated data subject requests. “Data subject” is defined as an individual who is identified or described by personal data. According to the committee, the access and correction rights extend not only to personal information provided by a data subject, but also commingled personal data collected by the controller from other sources, such as public sources, and from other firms.
Non-Discrimination: UPDPA prohibits controllers from denying a good or service, charging a different rate, or providing a different level of quality to a data subject in retaliation for exercising one of these rights. However, controllers may still make a data subject ineligible to participate in a program if the corrected information requested by them makes them ineligible, as specified by the program’s terms of service.
No Deletion Right: Notably, UPDPA does not grant individuals the right to delete their personal data. The ULC committee has enumerated various reasons for taking this approach, including: (1) the wide range of legitimate interests for controllers to retain personal data, (2) difficulties associated with ensuring that data is deleted, given how it is currently stored and processed, and (3) compatibility with the First Amendment of the U.S. Constitution (free speech). The committee has also stated that UPDPA’s restrictions on processing for compatible uses or incompatible uses with consent should provide sufficient protection.
Pseudonymized Data
“Pseudonymized data” is defined as “personal data without a direct identifier that can be reasonably linked to a data subject’s identity or is maintained to allow individualized communication with, or treatment of, the data subject. The term includes a record without a direct identifier if the record contains an internet protocol address, a browser, software, or hardware identification code, a persistent unique code, or other data related to a particular device.”
Pseudonymized data is subject to fewer restrictions than more identifiable forms of personal data. Generally, consumer rights contained in UPDPA (access and correction) do not apply to pseudonymized data. However, these rights do still apply to “sensitive” pseudonymized data to the extent that it is maintained in a way that renders the data retrievable for individualized communications and treatment.
“Sensitive data” includes personal data that reveals: (A) racial or ethnic origin, religious belief, gender, sexual orientation, citizenship, or immigration status; (B) credentials sufficient to access an account remotely; (C) a credit or debit card number or financial account number; (D) a Social Security number, tax-identification number, driver’s license number, military identification number, or an identifying number on a government-issued identification; (E) geolocation in real time; (F) a criminal record; (G) income; (H) diagnosis or treatment for a disease or health condition; (I) genetic sequencing information; or (J) information about a data subject the controller knows or has reason to know is under 13 years of age.
In practice, the ULC committee has stated that a collecting controller that stores user credentials and customer profiles can avoid the access and correction obligations if it segregates its data into a key code and a pseudonymized database so that the data fields are stored with a unique code and no identifiers. The separate key will allow the controller to reidentify a user’s data when necessary or relevant for their interactions with the customers. Likewise, a collecting controller that creates a dataset for its own research use (without maintaining it in a way that allows for reassociation with the data subject) will not have to provide access or correction rights even if the pseudonymized data includes sensitive information. Additionally, a retailer that collects and transmits credit card data to the issuer of the credit card in order to facilitate a one-time credit card transaction is not maintaining this sensitive pseudonymized data.
Compatible, Incompatible, and Prohibited Data Practices
UPDPA distinguishes between “compatible,” “incompatible,” and “prohibited” data practices. Compatible data practices are per se permissible, so controllers and processors may engage in these practices without obtaining consent from the data subject. Incompatible data practices are permitted for non-sensitive data if the data subject is given notice and an opportunity to withdraw consent (an opt-out right). However, opt-in consent is required for a controller to engage in incompatible data processing of “sensitive” personal data. Controllers are prohibited from engaging in prohibited data practices.
UPDPA’s distinctions between “compatible,” “incompatible,” and “prohibited” data practices are based on the likelihood that the data practice may benefit or harm a data subject:
Compatible data practices: A controller or processor engages in a compatible data practice if the processing is “consistent with the ordinary expectations of data subjects or is likely to benefit data subjects substantially.”
Per se compatible practices: UPDPA includes a list of 9 data practices that are per se compatible, such as the effectuation of a transaction to which the data subject is a participant, compliance with legal obligations, research, and processing that is “reasonably necessary to create pseudonymized or deidentified data.”
Factors: The list of compatible data practices is not exhaustive, and UPDPA also contains 6 factors to determine whether a processing activity is a compatible data practice, such as the data subject’s relationship with the controller, the type and nature of the personal data to be processed, and the risk of negative consequences to the data subject associated with the use or disclosure of the personal data. This catch-all provision aims to allow controllers and processors to create innovative data practices that are unanticipated and unconventional, so long as data subjects substantially benefit from the practice.
Targeted advertising: The Act specifies that a controller may use personal data, or disclose pseudonymized data to a third-party controller “to deliver targeted advertising and other purely expressive content to a data subject.” However, the Act distinguishes between “purely expressive content” and “differential treatment,” the latter of which does not constitute a compatible data practice (as it is unanticipated, and does not substantially benefit the data subject). For instance, it excludes the use of personal data to offer terms relating to price or quality to a data subject that are different from those generally offered.
Incompatible data practices: A controller or processor engages in an incompatible data practice if the processing:
(1) is not a compatible data practice and is not a prohibited data practice; or
(2) is otherwise a compatible data practice but is inconsistent with a controller or processor’s privacy policy.
In other words, an incompatible data practice is an unanticipated use of data that is likely to cause neither substantial harm nor substantial benefit to the data subject. The ULC committee has stated that an example of an incompatible data practice is a firm that develops an app that sells user data to third party fintech firms for the purpose of creating novel credit scores or employability scores.
Prohibited data practices: Processing personal data is a prohibited data practice if the processing is likely to:
(1) subject a data subject to specific and significant: (A) financial, physical, or reputational harm; (B) embarrassment, ridicule, intimidation, or harassment; or (C) physical or other intrusion on solitude or seclusion if the intrusion would be highly offensive to a reasonable person;
(2) result in misappropriation of personal data to assume another’s identity;
(3) constitute a violation of other law, including federal or state law against discrimination;
(4) fail to provide reasonable data-security measures, including appropriate administrative, technical, and physical safeguards to prevent unauthorized access; or
(5) process personal data without consent in a manner that is an incompatible data practice.
The collection or creation of personal data by reidentifying or causing the reidentification of pseudonymized or de-identified data is considered to be a “prohibited data practice,” unless: (a) the reidentification is performed by a controller or processor that previously pseudonymized or de-identified the personal data, (b) the data subject expects the personal data to be maintained in identified form by the controller performing the reidentification, or (c) the purpose of the reidentification is to assess the privacy risk of deidentified data and the person performing the reidentification does not use or disclose reidentified personal data except to demonstrate a privacy vulnerability to the controller or processor that created the de-identified data.
Responsibilities of Collecting Controllers, Third-Party Controllers, and Processors
UPDPA creates different obligations for “controllers” and “processors,” and further distinguishes between “collecting controllers” and “third party controllers.”
“Controller” is defined as a person that, alone or with others, determines the purpose and means of processing.
“Collecting controller” is defined as “a controller that collects personal data directly from a data subject.” Collecting controllers are responsible for providing means for data subjects to access and correct their personal data, including establishing a procedure to authenticate the identity of the data subject. They are also required to transmit credible requests to downstream third-party controllers and processors who have access to the personal data, and to make reasonable efforts to ensure that these third parties have made the requested change.
“Third party controller” is defined as “a controller that receives from another controller authorized access to personal data or pseudonymized data and determines the purpose and means of additional processing.” Third-party controllers are under most of the same obligations as collecting controllers. However, they are not obliged to respond to access or correction requests directly, but rather to make a reasonable effort to assist the collecting controller to satisfy a data subject request. Any third-party controller that receives a request from a collecting controller must transmit the request to any processor or other third-party controller that it has engaged so that the entire chain of custody of personal data is corrected.
“Processor” is defined as “a person that processes personal data on behalf of a controller.” Processors are responsible for providing the controller, upon their request, with a data subject’s personal data or enabling them to access the personal data, correct inaccuracies in a data subject’s personal data upon request of the controller, and abstain from processing personal data for a purpose other than the one requested by the controller.
If a person with access to personal data engages in processing that is not at the direction and request of a controller, that person becomes a controller rather than a processor, and is therefore subject to the obligations and constraints of a controller.
Aside from complying with access and correction requests, controllers have a number of additional responsibilities, such as notice and transparency obligations, obtaining consent for incompatible data practices, abstaining from engaging in a prohibited data practice, and conducting and maintaining data privacy and security risk assessments. Processors are also required to conduct and maintain data privacy and security risk assessments.
Voluntary Consensus Standards
UPDPA enables stakeholders representing a diverse range of industry, consumer, and public interest groups to negotiate and develop voluntary consensus standards (VCS’s) to comply with UPDPA in specific contexts. VCS’s may be developed to comply with any provision of UPDPA, such as the identification of compatible practices for an industry, the procedure for securing consent for an incompatible data practice, or practices that provide reasonable security for data. Once established and recognized by a state Attorneys General, any controller or processor can explicitly adopt and comply with it. It is also worth noting that compliance with a similar privacy or data protection law, such as the GDPR or CCPA, is sufficient to constitute compliance with UPDPA.
Enforcement and Rulemaking
UPDPA grants State Attorneys General rulemaking and enforcement authority. The “enforcement authority, remedies, and penalties provided by the [state consumer protection act] apply to a violation” of UPDPA. However, notwithstanding this provision, “a private cause of action is not authorized for a violation of this Act or under the consumer protection statute for violations of this Act.”
What’s Next for the UPDPA?
The future of the UPDPA is, as yet, unclear. The drafting committee is currently developing a legislative strategy for submitting the Act to state legislatures on a state-by-state basis. It remains to be seen whether state legislators will have an appetite to introduce, consider, and possibly pass the UPDPA during the legislative session of 2022 and beyond. As an alternative, legislators may wish to adapt certain elements of the model law, such as the voluntary consensus standards (VCS), flexibility for research, or the concept of “compatible,” “incompatible,” or “prohibited” data practices based on the likelihood of substantial benefit or harm to the data subject, rather than purely notice and consent.
What the Biden Executive Order Means for Data Protection
Last week, President Biden signed an Executive Order on “Promoting Competition in the American Economy” (“the Order” or “the EO”), published together with an explanatory Fact Sheet. The Order outlines a sweeping agenda for a “whole of government” approach to enforcement of antitrust laws in nearly every sector of the economy. Although there is a focus on particular markets, such as agriculture and healthcare, the Order includes a number of provisions with clear implications for data protection and privacy.
In our view, the overarching theme of the Order is a concern with large platforms and the accumulation of data as an aspect of market dominance. This is an approach that aligns with growing developments in the European Union, and will have continued consequences for all sectors of the economy. In addition, the Order has implications for upcoming enforcement and privacy rulemaking at the Federal Trade Commission (FTC). Finally, we note a number of other federal agencies that are tasked with, or encouraged, to pursue particular goals that impact privacy or data protection. These include: drone privacy (DOT/FAA); studying the mobile app ecosystem (Dept. of Commerce); the right to repair (FTC, DoD); Net Neutrality (FCC); and financial data portability (CFPB).
Most of the Executive Order provisions do not have immediate effect for the collection of consumer data, but instead, call for federal agencies to study, take future action, incorporate the administration’s policy in procurement and enforcement decisions, or consider engaging in rulemaking to the extent of their statutory authority. Independent commissions, which do not report directly to the President, are “encouraged” to consider rulemaking and other actions.
(1) An Overall Focus on Accumulation of Data as Relevant to Market Dominance
Although the intersection of privacy and competition law has been discussed for many years, this Order represents an important development insofar as it explicitly frames data collection as a key aspect of market dominance. The Order specifically highlights the impact of serial mergers in the technology sector on user privacy, identifying privacy and competition among “free” products as factors that should be considered as part of the enhanced scrutiny of mergers. The Fact Sheet explains that this is particularly relevant in the case of “dominant internet platforms” and acquisition of nascent competitors.
The EO states in Section 1 the policy of the administration, which all federal agencies are required to follow, and independent commissions are encouraged to pursue:
“[It is] the policy of my Administration to enforce the antitrust laws to meet the challenges posed by new industries and technologies, including the rise of the dominant Internet platforms, especially as they stem from serial mergers, the acquisition of nascent competitors, the aggregation of data, unfair competition in attention markets, the surveillance of users, and the presence of network effects.”
This framing of privacy and data protection as core elements of competition aligns not only with growing movement in the United States, but also with clear trends in the European Union. In the United States, both the FTC and state Attorneys General have brought lawsuits in recent years against Facebook, as well as state Attorneys General against Google, for alleged violations of antitrust laws. Two such claims were recently dismissed, although they could be followed by further actions from the FTC.
A key development in Brussels is the legislative proposal for a Digital Markets Act – a draft regulation published by the European Commission last year that targets “gatekeepers”, or online intermediaries providing a “core platform service”. The DMA proposes a series of ex ante rules, including a prohibition to combine personal data from different sources in the absence of valid GDPR consent.
(2) Enforcement and Rulemaking Ahead for the Federal Trade Commission (FTC)
The Executive Order “encourages” the Chair of the FTC, as well as other agencies with authority to enforce the Clayton Act, to “enforce the antitrust laws fairly and vigorously,” including in oversight of mergers, but also in areas such as protecting workers from wage collusion or unfair non-compete clauses. In addition, the Chair of the FTC is “encouraged” to exercise the Commission’s statutory rulemaking authority in a number of specific areas to promote competition, including to address “unfair data collection and surveillance practices that may damage competition, consumer autonomy, and consumer privacy” and “unfair competition in major Internet marketplaces.” Sec. 5(h).
With respect to ongoing enforcement of antitrust laws, this language aligns with recent developments in the FTC, most significantly the appointment of antitrust expert Lina Khan as the Chair, who has already indicated that the FTC will take a greater role in antitrust cases. The FTC’s Bureau of Competition, working with the Bureau of Economics, enforces antitrust laws in the United States, including the Sherman Act (15 U.S.C. 1 et seq) and the Clayton Act (15 U.S.C. 12 et seq).
Earlier statements from the previous Acting Chair Rebecca Kelly-Slaughter have also indicated that the Commission would be focused on bringing more cases under the “unfairness” prong of Section 5 of the FTC Act, followed by the announcement of a new Rulemaking Group. This rulemaking, which is set to commence under “Magnuson-Moss Procedures,” is far slower than typical agency rulemaking, but could be used to promulgate federal rules on what types of data collection and use are “unfair” under the FTC Act. For example, the agency recently noted in an FTC staff blog that the sale or use of “racially biased algorithms” is unfair under Section 5 of FTC Act. Rulemaking could codify or further elaborate on this and other data collection issues.
(3) Other Agencies to Watch: Drones, Mobile Apps, Right to Repair, Net Neutrality, and Financial Data Portability
Consistent with the EO’s “whole-of-government” approach, the order outlines tasks and recommendations for a long list of other federal agencies, noting that each agency has the ability to influence market competition through both the procurement process and through rulemaking. Agencies that are under the direct control of the President (such as the Departments of Transportation or Defense) are expressly required to engage in particular tasks, such as conducting studies or commencing rulemaking. In contrast, independent federal agencies (such as the FTC, FCC, and CFPB) are “encouraged to consider” particular courses of action.
In order to help direct and coordinate the efforts of all agencies, the Order establishes a White House Competition Council in the Executive Office of the President, to monitor the implementation of the Order and to coordinate the government agencies’ response to “the rising power of large corporations in the economy.”
Drone Privacy (DoT/FAA). The Department of Transportation “shall . . . ensure that the Department of Transportation takes action” with respect to “the emergence of new aerospace-based transportation technologies, such as low-altitude unmanned aircraft system deliveries, advanced air mobility, and high-altitude long endurance operations . . .”. Specifically, the action taken by the Department of Transportation should “facilitate innovation . . . while also ensuring safety, providing security and privacy, protecting the environment, and promoting equity.” Sec. 5(m).
Mobile App Ecosystem Study (DoC). The Department of Commerce “shall” conduct a “study, including by conducting an open and transparent stakeholder consultation process, of the mobile app ecosystem.” The study, which must be conducted within 1 year in consultation with the Attorney General and the Chair of the FTC, and will conclude with a report submitted to the White House Competition Council on findings and recommendations for “improving competition, reducing barriers to entry, and maximizing user benefit with respect to the mobile app ecosystem.” Sec. 5(r).
Right to Repair (FTC, DoD). In addition to the privacy issues described above, the FTC is encouraged to address in its rulemaking “unfair anticompetitive restrictions on third-party repair or self-repair of items, such as the restrictions . . . that prevent farmers from repairing their own equipment.” Sec. 5(h). A consumer protection issue that often runs parallel to many privacy and data protection debates, the “right to repair” has already been codified (twice) in Massachusetts, and was the subject of a recent FTC Report to Congress on Repair Restrictions. Similarly, the Department of Defense is tasked with submitting a plan to avoid procurement practices that “make it challenging or impossible . . . for service members to repair their own equipment, particularly in the field.” Sec. 5(s).
Net Neutrality (FCC). The Federal Communications Commission (FCC) is “encouraged . . . to consider” reviving through rulemaking “Net Neutrality” rules similar to those previously adopted under Title II of the Communications Act of 1934. Sec. 5(l).
Financial Data Portability (CFPB). The Director of the Consumer Financial Protection Bureau (CFPB) is “encouraged to consider” rulemaking under the Section 1033 of the Dodd-Frank Act to “facilitate the portability of consumer financial transaction data so consumers can more easily switch financial institutions and use new, innovative financial products.” Sec. 5(t). The CFPB has been engaged since at least 2020 in rulemaking under Section 1033 with respect to consumer access to financial records. Similar approaches to Open Banking and the role of data portability are currently advancing also in the EU, with the PSD2 Directive, and in India. Of note, the FTC has already been exploring the benefits and challenges of data portability more broadly for consumers and competition.
Conclusion
Overall, the Executive Order represents a leveraging of the enormous power of the US executive branch towards the promotion of competition in every sector, including taking into account privacy and data protection. The Order frames this approach as a return to the policies reflected in the Sherman Act, the Clayton Act, and other laws passed in the 19th and early 20th centuries. Among other things, this ensures that competition law in the United States must now incorporate notions of power and fairness that arise from data collection, use, and privacy.
Finally, the Administration’s argument that privacy should be a factor for competition policy would be far stronger if the United States, like other countries, had a comprehensive federal legislative standard for privacy. Proliferating state privacy laws are particularly unhelpful as a point of reference, as many of the larger or more dominant platforms can point to the fact that they do not “share or sell” data as defined by the recent state laws, while smaller companies do. We hope the administration will lend its weight to efforts to break the Capitol Hill logjam on data protection legislation.
Event Recap: Dublin Privacy Symposium 2021, Designing for Trust: Enhancing Transparency & Preventing User Manipulation
Key Takeaways
The biggest challenge to increase UX transparency may be encouraging people to make deliberate decisions from a UX design perspective.
Even designers’ color and shape choices in UI can be subtle ‘dark patterns’ that might even prevent, e.g., color-blind users from understanding the options at hand.
Organizations should ask themselves whether they should be collecting certain data in the first place, in line with the minimization principle.
Organizations need to take steps to prevent user manipulation, both by UX/UI (e.g., cookie banners) and by algorithms.
On June 23, 2021, The Future of Privacy Forum (FPF) hosted the first edition of its annual Dublin Privacy Virtual Symposium: Designing for Trust: Enhancing Transparency & Preventing User Manipulation. FPF organized the event in cooperation with the Dublin Chapter of Women in eDiscovery. Participants zoomed in on the question: What elements and design principles generally make user interfaces clear and transparent? Experts also discussed web design examples regarding user information and control, including what scholars increasingly refer to as ‘manipulative design’ or ‘dark patterns.’
The symposium included two keynote speakers and a panel discussion. Graham Carroll, Head of Strategy at The Friday Agency addressed the first keynote, followed by a keynote by Dr. Lorrie Cranor (researcher at Carnegie Mellon University’s Cylab). The keynote speakers joined the panel discussion with six other panelists: Diarmaid Mac Aonghusa (Founder and Managing Director at Fusio.net), Dylan Corcoran (Assistant Commissioner at the Irish Data Protection Commission, or ‘DPC’), Stacey Gray (Senior Counsel at FPF), Dr. Denis Kelleher (Head of Privacy EMEA at LinkedIn), Daragh O Brien (Founder and Managing Director at Castlebridge), and Dr. Hanna Schraffenberger (researcher at Radboud University’s iHub). Dr. Rob van Eijk (FPF’s Managing Director for Europe) moderated the symposium.
Below we provide a summary of (1) the first keynote on dark patterns, (2) the second keynote on how (not) to convey privacy choices with icons and links, and (3) the panel discussion.
Keynote 1: ‘Dark patterns’: from mere annoyance to deceitfulness
Graham Carroll explained that his work involved assisting Friday’s corporate clients in understanding and implementing best practices around improving user experience (UX) design for consent and transparency. He underlined that being transparent about privacy and data processing is crucial for user trust. Furthermore, he stressed the importance of understanding the motivations in online interactions, e.g., publishers, advertisers, and users.
Carroll defined ‘dark patterns’ as deceptive UX or user interface (UI) interactions designed to mislead users when making online choices—for example, leading users to consent for ancillary personal data processing when subscribing to a newsletter.
While companies wish to increase revenue while remaining compliant, their users want to complete their goals and feel secure while doing it quickly. Carroll’s research shows that users tend to take a path of least resistance when they are asked to make a choice online. A key element of Carroll’s presentation was a scale by Nagda, Y. (2020) depicting consequences for users, i.e., going from annoying to deceiving (Figure 1). Carroll argued that forcing users to close a pop-up upon entering a website may be considered less disruptive than a more complicated account cancelation process.
Therefore, Carroll stated that some manipulative designs would be more deserving of a legal ban than others, which would make it easier for regulators to enforce and for companies to comply with the law. He also mentioned an online resource listing and advancing a definition of different types of ‘dark patterns.’
Carroll then devoted a particular focus to the online advertising sector, stating that the latter was prolific in creating ‘dark patterns’ in cookie consent banners. In that context, he offered several examples, such as banners without a ‘reject’ option and others where the ‘manage cookies’ or ‘more options’ button was smaller or used a less prominent color than the ‘accept’ or ‘agree’ button.
Carroll conducted some user testing to understand users’ behaviors around cookie consent and ultimately improved their banners’ design and UX. The results showed that were only presented with ‘accept’ and ‘manage cookies’ options, 92% of users accepted. Even when offered a ‘reject’ button, 85% did so. When the cookie banner was made unobtrusive during the website browsing, many users (36%) ignored it. Remarkably, in a separate qualitative test, the results shown by Carroll were quite different. When users were asked what they would do if they were offered a cookie banner, a significant number stated that they always rejected non-essential cookies. This demonstrates that, verbally, people were more willing to err on the side of privacy caution, which was not aligned with the study’s quantitative results.
In Carroll’s view, such results show that users tend to take the ‘path of least resistance’ when browsing. Therefore, design practices involve offering clear and transparent notices that give users real options. We also learned that the needs of the visually impaired should be taken into account, e.g., using contrast.
In closing, Carroll briefly touched upon transparency and consent designs in IoT devices, e.g., smart TVs and virtual voice assistants.
Keynote 2: Toggles, $ Signs, and Triangles: How (not) to Convey Privacy Choices with Icons and Links
Dr. Cranor, presented the results of her research group’s work on privacy icons under the California Consumer Privacy Act (CCPA). The research showed that icons are not often great at clarity, language, and cultural independence. Furthermore, icons have shown not to be intuitive, especially when describing abstract concepts such as privacy. They may, then, require a short explanation to accompany them .
The group’s research stemmed from Chapter 20 of the initial California Consumer Privacy Act (CCPA) proposal. Section 999.315 on opt-out requests from personal information sales mentions an optional button, allowing users to exercise such rights. Therefore, Cylab decided to send the California Attorney General (AG) some design proposals for the button. Theproject started with the icon ideation phase, including testing different word combinations next to the icons. Three concepts for icon design were tested: choice/consent (checkmarks/checkboxes), opting-out (usually involving arrows, movement, etc.), and do-not-sell (with money symbology). In this exercise, the group sought to avoid overlap with the Digital Advertising Alliance’s (DAA) privacy rights icons.
Initially, the first icons were tested with 240 MTurks. The first half was shown icons with accompanying words, while the other half was presented only with icons. When asked what they thought would happen if they clicked each button, the second half showed difficulty interpreting several icons in the absence of words. In this respect, opt-out signs were generally confusing, while only a few consent and do-not-sell icons were intelligible for some participants.
After refining the initial icons, notably by adding color (e.g, red opt-out icons, blue consent toggle), the team conducted a second test. This time the blue toggle was the top performer (Figure 2).
Figure 2: Participants’ interpretation of Cylab’s privacy icons, by Dr. Lorrie Cranor
Then, the group conducted another study, testing 540 MTurk participants’ comprehension of taglines (words). In that context, participants showed more understanding of more extended taglines, like ‘Do Not Sell My Info Choices’, than shorter ones, like ‘Do Not Sell’. Afterward, the team performed some even more extensive user testing of icon and tagline combinations. The tests revealed some user misconceptions, like users assuming that the ‘Personal Info Choices’ would allow them to choose their preferred payment method in an online store.
In the end, the researchers concludedthat none of the icons were very good at conveying the intended layered privacy messages. However, they found that icons increased the likelihood that users noticed the link/text next to them. They recommended the California AG to adopt the same blue toggle for both ‘Privacy Options’ and ‘Do Not Sell my Personal Info.’ After the California legislature included a different toggle in the draft CCPA, the team conducted a new study demonstrating that the latest toggle was not as clear to users as the one proposed by Cylab. Eventually, the initial blue toggle suggestion was included in the final text of the CCPA, even if it remains optional and generally not adopted by websites developed in California.
Finally, Dr. Cranor made some closing remarks and outlined the research’s key takeaways. The team concluded that privacy icons should be accompanied by text to increase their effectiveness. It also recommended incorporating user testing, for which Cylab is currently developing guidelines, into the policy-making process. Dr. Cranoralso expressed a desire to achieve globally recognizable privacy icons, albeit it looks like a complex endeavor. Outside of the policy-making sphere, she identified three priorities for increasing user transparency: (i) creating a habit of evaluating the effectiveness of transparency mechanisms before roll-out; (ii) defining standards and best practices around tested mechanisms, putting aside the need for each website to decide by itself; and (iii) incorporating automation, to reduce the users’ burden and choice fatigue (e.g., centralizing choices in the browser or device settings).
Panel discussion: Analyzing trends to increase UX transparency
Dr. Hanna Schraffenberger started by saying that the biggest challenge is encouraging people to make deliberate decisions from a UX design perspective. According to the researcher, users should not be forced to stop and think about each step they take online, especially given that they invariably take the same options (e.g., accepting or rejecting cookies). To make her point, Dr. Schraffenberger shared that her team invited research participants to a test in which they would be given no good reason to click ‘agree’, but still did. To the team’s surprise, this happened even when the ‘reject’ was made the most prominent option. According to the panelist, this shows that users are overwhelmingly prone to agree without questioning their options. Dr. Schraffenberger’s team’s goal is to make users slow down before proceeding with their browsing in a given website, notably by introducing design friction. An example of such friction would be forcing users to drag an icon to their preferred option on the screen. However, the speaker revealed challenges in measuring the user deliberation process in this context.
Daragh O Brien suggested that designers’ color and shape choices in UI can be subtle ‘dark patterns.’ He added that such choices might even prevent, e.g., color-blind users from understanding the options at hand. O Brien offered the European Data Protection Supervisor’s website as a bad example in that regard, given that all buttons were displayed in the same blue color. Therefore, the panelist called upon designers to question their user perception assumptions before implementing UI. O Brien also pointed to text-to-speech capabilities and succinct and straightforward explanations of the purpose of the processing as tools to account for the needs of all users. In reply to the speaker’s observations, both Dr. Cranor and Carroll stepped in. The former acknowledged research does not always consider user accessibility needs. The latter admitted that such requirements are challenging for UX designers and companies due to their cost implications. O Brien mentioned that organizations need to understand that not considering vulnerable audiences’ needs is a deliberate choice that can have consequences. He reminded the audience that intelligibility is a legal requirement that stems from data protection law.
Diarmaid Mac Aonghusa started off by stating that most cookie management solutions providers should redesign their products from scratch. On that note, the panelist argued that users should not be pushed to make online decisions out of frustration or consent fatigue by being constantly asked whether they accept being tracked all over the web. By asking the audience to imagine how the same experience would feel every time they changed TV channels, Mac Aonghusa argued that current privacy regulations are well-intentioned but not fit for the digital sphere. The speaker suggested reaching a consensus around a globally applicable setting for all websites at the browser level. This should aim to respect users’ choices, even if that could disappoint individual website providers.
Dylan Corcoran focused on data processing transparency towards users of IoT devices. In that respect, Corcoran mentioned that it is the controllers’ responsibility to determine the best practical way to inform their customers, considering user psychology in reaction to UX design. According to the panelist, articles 12 to 14 General Data Protection Regulation (GDPR) should not be taken as a checklist, as controllers should also account for the target audience’s cognition and understanding. That ultimately allows the former to determine whether the information passed on to data subjects is presented in a clear, concise, and understandable manner. Providers should also ensure users understand non-primary data processing purposes (e.g., integrations with third-party services, analytics, Software Development Kits used by developers, etc.). Data Privacy Officers and compliance teams are expected to engage with their appointers’ designers and programmers to embed transparency into their products and services.
Dr. Denis Kelleher started by aligning with Carroll’s earlier remarks, stating that transparency is key to obtaining and retaining customer trust. This is particularly true on what concerns data handling practices. With the maturing of the data protection field, companies are being pushed to increase their levels of transparency. According to Dr. Kelleher, this is corroborated by European Union (EU) Data Protection Authority’s (DPAs) decisions during the first three years of application of the GDPR and by disclosure requirements in the European Commission’sArtificial Intelligence Act proposal. He mentioned the EDPS’ and the European Data Protection Board’s (EDPB) recent comments to such a proposal. The speaker also talked about the industry’s eagerness to see what the final text of the ePrivacy Regulation will end up mandating on transparency. Dr. Kelleher said organizations need to understand better what level of detail users want in clear and concise privacy notices. The panelist also stressed that the industry is expecting to see EDPB guidance on transparency. The Board’s 2021-2022 Work Programme lists Guidelines and practical recommendations on data protection in social media platform interfaces as upcoming work.
Stacey Gray remarked whether and to what extent US consumer protection laws provide legal boundaries and transparency standards for potentially manipulative UX design practices. She stressed that the US had an opportunity going forward to learn from the EU’s successes and failures in this sphere. She also observed that legal obligations on interface design might not prevent users from making irrational decisions. There are some consumer protections under US law against ‘dark patterns,’ as remedies against deception, coercion, and manipulation are provided by federal and state laws. Gray also stated that the relevant literature seems to agree that users are given a choice to decline. However, it may be burdensome, and users are nudged to accept that online players’ practices would not be forbidden. Levels of tolerance for nudging in the law tend to depend on different factors, including: (i) users’ awareness of the choices they can make; (ii) users’ ability to avoid making a choice entirely; (iii) the content of the actual choice. Currently, two US states have passed omnibus privacy laws banning dark patterns: the California Privacy Rights Act and Colorado Privacy Act (which will come into effect in 2025) if signed by the Governor. Lastly, Gray pointed to the CCPA’s requirement that companies do not engage in ‘dark patterns’ to disincentivize people from exercising their opt-out right.
During a final round of interventions, all speakers were given a chance to react to each others’ remarks and to reply to the audience’s questions. Dr. Cranor highlighted that research on nudging had shown a fine line between legitimate persuasion and pressure/bullying in the online world. Nonetheless, she admitted that the persuasion’s end goal (e.g., pushing people to get vaccinated v. to accept tracking) is not neutral.
On a different note, but agreeing with the points made by Dr. Cranor during her earlier presentation, Corcoran took the view that organizations should test the effectiveness of their transparency measures before implementing them. This should also allow them to comply with the GDPR’s accountability principle. For that purpose, Corcoran mentioned MTurks and A/B testing as valuable tools.
Dr. Schraffenberger reinforced her earlier position, stressing that designers should develop interfaces that help users make good choices online. This, according to the panelists, may involve engaging with experts from other domains, such as psychology and ethics.
Both Dr. Kelleher and Mac Aonghusa agreed that organizations need to take steps to prevent user manipulation, both by UX/UI (e.g., cookie banners) and by algorithms. For users, what companies seek their consent for and what happens to their data after collection should be more precise, albeit there are limitations regarding the amount of information that can be delivered on a screen. Dr. Kelleher also mentioned that a change in the data protection paradigm, shifting from strict transparency to controller accountability and responsible data use, may be in order.
To wrap up, O Brien called for considering data subjects’ concerns and expectations regarding the processing of their personal data when building UI. According to the panelist, organizations should first ask themselves whether they should be collecting certain data in the first place, in line with the minimization principle. On a bright note, O Brien stressed that, sometimes, less is more, especially when it comes to more fine-grained datasets. In the speaker’s view, it should be the privacy community’s duty to convey such a message to their boards and clients.
Lessons for a Federal Private Right of Action in US Privacy Law after TransUnion LLC v. Ramirez
In June 2021, the Supreme Court handed down TransUnion v. Ramirez, 594 U.S. ___ (2021), its latest decision concerning Article III standing, which determines a plaintiff’s eligibility to sue in federal court. Even when a federal law expressly creates a private right of action to enforce a federal right or other violation of the law, Article III of the Constitution requires plaintiffs to demonstrate that they have “standing to sue,” which necessitates proof that plaintiffs suffered a real and individualized harm.
What are the implications of TransUnion for a private right of action in a federal omnibus privacy law? Often, federal proposals for a comprehensive privacy law do not contain a private right of action, instead relying solely on expanding the enforcement powers of the Federal Trade Commission (FTC). However, many proposals, such as The Consumer Online Privacy Rights Act (COPRA) or The Children and Teens’ Online Privacy Protection Act, would define privacy harms broadly and allow individuals to bring lawsuits to challenge most or all violations of the law.
Policymakers considering such proposals should: (1) be aware that after TransUnion, Congressional intent will hold less sway in the current Court when it comes to articulation of privacy harms; (2) consider how statutory privacy and data protection harms may or may not align with harms traditionally recognized by American courts; and (3) note that “material risk of future harm” may provide standing to sue for injunctive relief even when it does not provide standing to sue for financial damages.
Case Background
The origins of the TransUnion controversy lie in the TransUnion credit reporting agency’s “OFAC Name Screen Alert” product, which matches consumer credit reports with names on the U.S. Treasury’s Office of Foreign Asset Control’s (OFAC) list of terrorists, drug traffickers, and other criminals with whom US entities should not do business. During the time period at issue in this litigation, TransUnion used consumers’ first and last names, but not any of the other consumer data available to them–such as birth dates and social security numbers–to check for matches on the OFAC list.
If a consumer’s first and last name matched a name on the list, TransUnion flagged that consumer as a possible match to a name on the OFAC list on their credit report. For example, the named plaintiff in TransUnion, Sergio Ramirez, had his credit report pulled by a car dealership at which he was shopping. When the dealership saw that TransUnion had (improperly) flagged Ramirez as a possible match, they refused to sell him a car.
Ramirez sued on behalf of himself and other consumers, alleging violations of the Fair Credit Reporting Act (FCRA), and TransUnion challenged plaintiffs’ standing to bring the claim. To establish Article III standing, “a plaintiff must show (i) that he suffered an injury in fact that is concrete, particularized, and actual or imminent; (ii) that the injury was likely caused by the defendant; and (iii) that the injury would likely be redressed by judicial relief” (a standard from Lujan v. Defenders of Wildlife). The class plaintiffs in the TransUnion suit were all individuals whose names had been wrongly matched with names on the OFAC list, although only a subset of them ever had their reports indicating this “potential match” disclosed to a third party business checking their credit.
Prior to the case reaching the Supreme Court, two lower courts found that both of these groups had standing to sue TransUnion for failing to use reasonable procedures to ensure the accuracy of their “match” to names on the OFAC list, as well as for defects in the format of TransUnion’s written communications with them, both causes of action granted by Congress in FCRA. However, a majority of the Supreme Court in TransUnion found that only those plaintiffs whose reports with the faulty flag had actually been shared had suffered an intangible (non-financial and non-physical), concrete harm of the sort that gave them Article III standing to sue TransUnion for financial damages. What lessons does TransUnion provide for how policymakers should structure a private right of action in a comprehensive privacy law?
1. Be aware that after TransUnion, Congressional intent with respect to harms will hold less sway in the current Supreme Court.
After TransUnion, the current Supreme Court is much less likely to defer to Congressional intent in the articulation of procedural or other novel harms. Prior to TransUnion, the (differently made up) Court’s decision in Spokeo v. Robins, 578 U.S. 330 (2016) represented its most current thinking on standing. In Spokeo, the Court proposed a two-part inquiry for determining whether an intangible injury is concrete, noting that, “both history and the judgment of Congress play important roles” in this determination. Justice Kavanaugh, writing for the majority in TransUnion, appears to narrow this inquiry, emphasizing that “an injury in law is not an injury in fact;” and noting that, if Congress could statutorily authorize “unharmed” plaintiffs to sue, this would violate separation of powers principles between the Executive and Legislative branches. Kavanaugh focuses instead almost solely on the history inquiry, which holds that intangible inquiries are concrete when they are related to harms historically recognized by courts.
Thus, after TransUnion, the primary focus of the concreteness inquiry will likely be on an asserted harm’s relatedness to historically recognized harms. Put more bluntly, Kavanaugh’s opinion emphasizes that unharmed plaintiffs do not have Article III standing, no matter what Congress has to say about it. This may represent a shift from Spokeo, and could mean that Congressionally-granted private rights of action for intangible harms face greater scrutiny than they have previously. TransUnions’s holding suggests that the legislative text is not the last word on what privacy harms are legally cognizable, even if such harms are statutorily defined.
2. Consider how privacy and data protection harms align (or don’t align) with traditionally recognized harms.
TransUnion makes clear that intangible harms can be concrete when they have a “close relationship to harms traditionally recognized as providing a basis for lawsuits in American courts.” Justice Kavanaugh provides a series of examples of intangible concrete harms, many of them traditional privacy harms, including: reputational harms, disclosure of private information, intrusion upon seclusion, and infringement of free exercise. The Court then concludes that the subset of the class who had the false information about them disclosed had suffered a reputational injury, a type of concrete, intangible injury analogous to the harm suffered by victims of defamation.
If a federal omnibus privacy law includes a private right of action, it will be important to consider how it may apply to the wide variety of individual rights and business obligations that must be enforced. Most federal omnibus privacy bills provide individual rights to access, delete, and correct personal data held about them by companies analogous to those provided by FCRA. In addition, these bills typically grant rights to opt-out or opt-in to the collection, use, sharing, or sale of certain types of data and impose business obligations such as: transparency, fair processing, data minimization, the obligation to avoid secondary uses. TransUnion suggests that the cognizability of such rights and obligations will be dependent on the nature of the data at issue and how individualized this data is, as well as the nature of any disclosures.
For example, improper collection or sharing of sensitive health data, or data from the home may align with historically recognized harms such as defamation, public disclosure of private facts, intrusion upon seclusion, or trespass. In contrast, although standards are evolving, the historical analog for rights such as data minimization rights, especially when for data that is not sensitive or harmful, is less clear. Thus, drafters of a comprehensive federal privacy law should recognize that plaintiffs may not have standing to enforce broad data access, minimization, deletion, and correction rights in federal court. As such, they should conceive of alternate enforcement mechanisms for these rights, including robust agency enforcement.
Notably, linking causes of action to historical violations may constrain the drafting of such a law in significant ways. For example, because the tort of defamation requires sharing or publication of information, TransUnion demonstrates that the mere existence of inaccurate first-party data may never provide sufficient standing for financial damages. Similarly, the torts of “intrusion upon seclusion” and “publicity given to private life” in the 2nd Restatement of Torts are constrained by the “highly offensive” standard, meaning that, unless a disclosure of personal data would have been highly offensive to the reasonable person, plaintiffs may not have standing.
3. Note that, even absent concrete harm in the context of a suit for damages, “material risk of future harm” may still provide standing for injunctive relief.
The Court in TransUnion held that plaintiffs whose designation as a “potential match” to a person on the OFAC list had not been disclosed did not have standing to sue, because they had not been concretely harmed. Objecting to the notion that they did not have standing, these plaintiffs argued that TransUnion’s misflagging of their reports, even without disclosure, had exposed them to “material risk of future harm.” The court rejected the argument that risk of future harm was a sufficiently concrete injury to sue for damages, but noted that it could have been grounds for an injunction “to prevent the harm from occurring.”
Noting this, drafters of federal omnibus privacy legislation should be mindful that injunctive relief, even without statutory damages, may provide a powerful tool in situations where the statutory violation increases individual risk of future harm. This might include, for example, collection of biometric data, or other violations of collection limits. Congress could thus provide a private right of action for injunctive relief individuals exposed to “material risk of future harm” through data collection, even if that data had not yet been used for anything. To have standing to sue for damages, such plaintiffs will have to establish that they have suffered some concrete harm, such as emotional distress (an example Kavanaugh raises in dicta), in addition to being exposed to future harm.
4.What else?
The TransUnion opinion might impact class certification analysis, could influence judicial interpretation of other longstanding federal privacy laws, such as the Telephone Consumer Protection Act (TCPA), and could mean that certain plaintiffs begin to favor state court forums that do not require plaintiffs to show that they have Article III standing. Furthermore, Justice Thomas and Justice Kagan’s strong dissents in TransUnion suggests a different, and more plaintiff-friendly, way forward. There will doubtlessly be many who push for the view expressed in Justice Thomas’ dissent to become the law, and this case will likely have influence in the privacy space for decades to come.
FPF and Data Privacy Brasil Webinar: Understanding ‘Legitimate Interests’ as a lawful ground under the LGPD
Author: Katerina Demetzou
On Thursday, 20th of May 2021, the Future of Privacy Forum (FPF) and Data Privacy Brasil (DPB) co-hosted an online event for launching the English translation of a Report on Legitimate Interests as a lawful ground for processing personal data under Brazil’s Data Protection Law, the Lei Geral de Proteção de Dados (LGPD). The Report explores the role of this lawful ground through use cases and a theoretical framework.
Miriam Wimmer, one of the Directors of the Brazilian Data Protection Authority, gave the keynote address, followed by a panel discussion with Bruno Bioni, Director of DPB and co-author of the Report; Lara Kehoe-Hoffman, VP Privacy and Security Legal and Data Protection Officer of Netflix; Marcela Mattiuzzo, Partner at VMCA Advogados; and Hielke Hijmans, Member of the Board of Directors of the Belgian Data Protection Authority. The event was moderated by Gabriela Zanfir-Fortuna, Director for Global Privacy at the Future of Privacy Forum.
Below you will find the most important points that were raised during the discussion, starting with an overview of how the LGPD absorbed legal concepts from the GDPR, including that of “legitimate interests” (LI) as a lawful ground for processing personal data, while molding them on the Brazilian legal culture (Section 1). A brief presentation of the Report on Legitimate Interests under the LGPD follows, including an explanation of what is the “normative equation” of LI under the LGPD and examples of processing scenarios where LI is usually relied on lawfully (Section 2). The summary continues with mapping out misconceptions and current key points of debate about relying on LI as they emerged from the panel discussion (Section 3), to end with a list of the main takeaways (Section 4).
1. Legitimate Interests under the LGPD: inspired by the GDPR, but developing under their own rhythm in Brazil
In her keynote address, Miriam Wimmer highlighted two important aspects that should be taken into consideration when looking at the data protection legal landscape in Brazil. First of all, only recently did Brazil adopt a Data Protection Law, which ultimately came into force in September 2020. It was not before 2018 that the debate around the right to data protection opened up to the broader stakeholder community that also included business representatives, academics, and civil society groups. The recent history of the LGPD suggests that various topics remain unexplored and immature, therefore explanatory guidelines are required.
A second aspect is the fact that the LGPD has been very strongly influenced by the GDPR and the European approach to the right to data protection. More specifically, in Brazil, the right to data protection is associated with the protection of fundamental rights and it relates to the idea of informational self determination & control over the way that processing of personal data takes place.
Similarly to the GDPR, the LGPD has embraced an ex ante approach by requiring the data controller to abide by certain legal obligations before proceeding to any processing operations. Additionally, the LGPD enumerates data protection principles which have drawn inspiration from the OECD guidelines and the GDPR and has in place data subject rights that empower individuals to exercise control over their data. Most importantly, the LGPD, as is the case for the GDPR, aims to enable and not restrict data flows while simultaneously guaranteeing a high level of personal data protection.
Ten lawful grounds for processing
After laying out this background, the Director of the ANPD made some important points specifically relating to the LI ground. To begin with, having LI as a legal ground for processing shifts the focus away from consent as the only ground that ensures self determination and control of individuals over processing operations.
The LGPD provides for ten legal bases for processing. According to Wimmer, data controllers should not treat the LI basis either as a last resort or as a preferred option. On the contrary, and given that there is no hierarchy among the ten legal bases, data controllers should decide on the most appropriate legal ground according to the concrete circumstances of each case. However, Wimmer considers that further analysis and a better understanding is needed with regard to the meaning and the circumstances under which each basis shall be chosen over the others.
Under the LGPD, the LI ground is about balancing the legitimate interests of the data controller or a third party and the fundamental rights and freedoms of the data subjects. It consists of three tests, namely the purpose test, the necessity test and the balancing test. Under Article 10 LGPD, the personal data that are to be processed need to be strictly necessary for the defined purposes and there is a requirement of enhanced transparency.
The relationship between “Legitimate Interests” and Data Protection Impact Assessments
Additionally, the law gives the ANPD the possibility to require a Data Protection Impact Assessment (DPIA) from the data controller that processes data on the basis of the LI ground. This last requirement has spurred a debate on whether a DPIA is the most appropriate type of assessment given that it is complex and that not all processing operations based on the LI ground present significant risks. Instead, a legitimate interest assessment appears to be the preferred option.
Miriam Wimmer also mentioned that while the LI is a mature concept in the EU, this is not the case for Brazil and therefore there is still need for guidance on what exactly are legitimate interests under the LGPD and in which cases would they serve as an appropriate legal basis. One of the most heated debates around LI during the legislative process of the LGPD was around whether LI will end up being a carte blanche for data controllers. The ANPD aims to ensure that the LI legal ground will not be abused and will be used appropriately.
2. Exploring use cases and practical tests: the Report on Legitimate Interests under the LGPD
Bruno Bioni, one of the co-authors of the Report whose translation into English was launched during the event (together with Mariana Rielli and Marina Kitayama), introduced its structure and content. The Report begins by presenting the history behind the introduction of the LI ground in the LGPD, followed by a detailed analysis of its singular normative design under the law.
Article 7 enumerates LI as one of the lawful grounds for processing, Article 10 specifies the requirements for application of the LI ground and Article 37 requires the keeping of records when the LI is used as the basis for processing. In the Report, the combination of these articles is considered to be the ‘normative equation of Legitimate Interests under the LGPD’.
The policy paper takes the view that the Legitimate Interest Assessment is a four-step process consisting of: a legitimacy test, a necessity test, a balancing test and the assessment of safeguards.
The Report then analyzes the possibility that the ANPD has to request the controller to perform a DPIA in cases where the LI ground is used. According to DPB, the process of performing a DPIA should not be triggered by the legal ground used in each case, but by the high risk profile of each specific processing operation.
In the last part, the Report presents ten case studies in order to help practitioners apply the LI ground in practice.
There were multiple scenarios mentioned by the speakers whereby the use of LI as a ground is prima facie appropriate. Some examples are: fraud detection and prevention systems security, employment data processing (e.g. company directory, ethics reporting hotlines), general corporate operations (e.g. conducting audits), analytics for product and service improvement.
Speakers also discussed why LI is a necessary legal ground to be included as an option in sophisticated, comprehensive data protection legislation meeting the demands of the digital economy, while also aiming to provide safeguards for the protection of both individual and collective rights and interests. In practice, lawfully relying on LI demands thoughtfulness from data controllers.
They need to perform at least three separate tests (legitimacy, necessity, balancing), carefully assess whether LI is indeed the most appropriate legal ground in the case at hand, and they have to take into consideration the data subject’s expectations and interests. Among these, as Hijmans pointed out, the balancing test is very challenging because by its very nature it is a subjective exercise that needs to be further objectified if possible.
3. Misconceptions and Key Points of Debate about relying on LI
There were several misconceptions about relying on LI identified during the panel discussion, common to the LGPD and the GDPR, but primarily emerging from the longer practice under the GDPR.
Panelists agreed that a common misunderstanding is that there is a hierarchy among the different lawful grounds for processing. In both jurisdictions, all lawful grounds for processing are equal and their application should depend on the specific circumstances of each case. For instance, consent should not be considered the main legal basis for processing data, as it is often the case in practice, with the other lawful grounds seen as exceptions.
The question of whether a purely commercial interest can serve as a legitimate interest was mentioned not as much as a misconception, but as the subject of current lively debate around LI and a challenging issue to be solved in the upcoming updated guidance of the European Data Protection Board on LI.
Another misconception was identified around the question of whether processing personal data on the basis of legitimate interests is less protective for the rights of individuals compared to other lawful grounds. Speakers commented that this is not the case, especially where controllers are diligent about the necessary assessment and balancing of interests required to lawfully rely on LI for processing personal data, and about complying with all the rights individuals have even in relation with personal data processed on the basis of LI.
It surfaced from the panel discussion that what is very important, from a practical point of view, is the ability to understand first of all what personal data controllers are collecting. Secondly, it is important to precisely identify what they intend to do with the personal data, or the purpose of processing. Then, the basic filter through which every decision on whether to rely on LI should pass through is that of the individual’s reasonable expectations and the filter of fairness. This is why both the principle of accountability and the principle of fairness are key in being able to lawfully rely on LI as a lawful ground for processing.
4. Main Takeaways
The Report on Legitimate Interests under the LGPD published by Data Privacy Brasil and translated into English with support from FPF is a significant contribution to develop the theory and practice of the new data protection legal framework in Brazil. The launch of the English version of the Report prompted an engaging discussion that furthered the understanding of how LI should be applied in practice to take into account both the rights and interests of individuals on one hand, and the interests of controllers and third parties on the other hand. These are the key takeaways that emerged from the keynote and panel discussion:
All discussants agreed that LI should neither be the preferred nor the last option for legitimising processing of personal data. There is no hierarchy among the possible lawful grounds for processing.
It is crucial that data controllers understand what personal data they are processing and why they are processing that data. Having this clear, organizations can make the choice for the most appropriate legal ground, complying with the principle of accountability.
The principle of fairness should be central to the discussion on the LI ground. Along with reasonable expectations of the individuals, fairness should constitute the filter through which the decision to rely on LI must pass.
The obligation to perform a DPIA should not be attached to the choice of applying the LI ground as the appropriate legal basis. However, a legitimate interest assessment that follows the structure and reasoning of a proportionality test, should instead be performed.
More guidance from the ANPD is expected to clarify how the tests for lawfully relying on LI should be performed.
Navigating Preemption through the Lens of Existing State Privacy Laws
This post is the second of two posts on federal preemption and enforcement in United States federal privacy legislation. See Preemption in US Privacy Laws (June 14, 2021).
In drafting a federal baseline privacy law in the United States, lawmakers must decide to what extent the law will override state and local privacy laws. In a previous post, we discussed a survey of 12 existing federal privacy laws passed between 1968-2003, and the extent to which they are preemptive of similar state laws.
Another way to approach the same question, however, is to examine the hundreds of existing state privacy laws currently on the books in the United States. Conversations around federal preemption inevitably focus on comprehensive laws like the California Consumer Privacy Act, or the Virginia Consumer Data Protection Act — but there are hundreds of other state privacy laws on the books that regulate commercial and government uses of data.
In reviewing existing state laws, we find that they can be categorized usefully into: laws that complement heavily regulated sectors (such as health and finance); laws of general applicability; common law; laws governing state government activities (such as schools and law enforcement); comprehensive laws; longstanding or narrowly applicable privacy laws; and emerging sectoral laws (such as biometrics or drones regulations). As a resource, we recommend: Robert Ellis Smith, Compilation of State and Federal Privacy Laws (last supplemented in 2018).
Heavily Regulated Sectoral Silos. Most federal proposals for a comprehensive privacy law would not supersede other existing federal laws that contain privacy requirements for businesses, such as the Health Insurance Portability and Accountability Act (HIPAA) or the Gramm-Leach-Bliley Act (GLBA). As a result, a new privacy law should probably not preempt state sectoral laws that: (1) supplement their federal counterparts and (2) were intentionally not preempted by those federal regimes. In many cases, robust compliance regimes have been built around federal and state parallel requirements, creating entrenched privacy expectations, privacy tools, and compliance practices for organizations (“lock in”).
Laws of General Applicability. All 50 states have laws barring unfair and deceptive commercial and trade practices (UDAP), as well as generally applicable laws against fraud, unconscionable contracts, and other consumer protections. In cases where violations involve the mis-use of personal information, such claims could be inadvertently preempted by a national privacy law.
State Common Law. Privacy claims have been evolving in US common law over the last hundred years, and claims vary from state to state. A federal privacy law might preempt (or not preempt) claims brought under theories of negligence, breach of contract, product liability, invasions of privacy, or other “privacy torts.”
State Laws Governing State Government Activities. In general, states retain the right to regulate their own government entities, and a commercial baseline privacy law is unlikely to affect such state privacy laws. These include, for example, state “mini Privacy Acts” applying to state government agencies’ collection of records, state privacy laws applicable to public schools and school districts, and state regulations involving law enforcement — such as government facial recognition bans.
Comprehensive or Non-Sectoral State Laws. Lawmakers considering the extent of federal preemption should take extra care to consider the effect on different aspects of omnibus or comprehensive consumer privacy laws, such as the California Consumer Privacy Act (CCPA), the Colorado Privacy Act, and the Virginia Consumer Data Protection Act. In addition, however, there are a number of other state privacy laws that can be considered “non-sectoral” because they apply broadly to businesses that collect or use personal information. These include, for example, CalOPPA (requiring commercial privacy policies), the California “Shine the Light” law (requiring disclosures from companies that share personal information for direct marketing), data breach notification laws, and data disposal laws.
Congressional intent is the “ultimate touchstone” of preemption. Lawmakers should consider long-term effects on current and future state laws, including how they will be impacted by a preemption provision, as well as how they might be expressly preserved through a Savings Clause. In order to help build consensus, lawmakers should work with stakeholders and experts in the numerous categories of laws discussed above, to consider how they might be impacted by federal preemption.