Statement by Future of Privacy Forum CEO Jules Polonetsky on the Washington Privacy Act
WASHINGTON, DC – January 13, 2020 – Statement by Future of Privacy Forum CEO Jules Polonetsky regarding the introduction of the Washington Privacy Act (Washington State Senate Bill 6281):
“The Washington Privacy Act is the most comprehensive state privacy legislation proposed to date. The bill addresses concerns raised last year and proposes strong consumer protections that go beyond the California Consumer Privacy Act. It includes provisions on data minimization, purpose limitations, privacy risk assessments, anti-discrimination requirements, and limits on automated profiling that other state laws do not.”
ICYMI: National PTA, Future of Privacy Forum Host Student Privacy Briefing for Parents
On December 12th, the Future of Privacy Forum (FPF) and National PTA recently co-hosted a webinar for parents to learn more about the critical importance of safeguarding their child’s data privacy at school. FPF Director of Youth & Education Privacy Amelia Vance led the discussion about key student privacy laws and trends.
As school districts across the country cope with a wave of new privacy requirements – 130+ new laws specific to student privacy have passed in 41 states since 2013 – Vance highlighted the ongoing but critical challenge for states to balance access to student data with privacy and security, noting several instances where new laws have inadvertently created limitations on students’ educational opportunities.
“Oftentimes legislatures have to go back and fix the laws… because they didn’t check in with teachers, they didn’t check in with administrators, they didn’t talk to parents about what are the most important things to them,” Vance said. “[Not only about] what are the privacy protections that are important, but also what are the services being provided to your kids that are most important?”
Specifically, Vance cited examples in New Hampshire and Louisiana where strict new privacy laws raised questions about whether schools were permitted to conduct routine activities such as hanging student artwork in hallways, sharing classroom recordings with special education or homebound students, or even producing a yearbook.
Parents play a critical role in bringing these types of issues to light, and the webinar included a review of key questions for parents to ask schools to better understand their privacy policies. Additionally, parents received tips for navigating practical scenarios such as keeping photos of a child off of social media. The webinar highlighted FPF and National PTA’s Parent’s Guide to Student Data Privacy with additional tools and resources for parents.
Vance observed that policymakers’ recent focus on new restrictions for districts, schools, and edtech companies is shifting. “We now see fewer bills imposing more privacy protections, and more bills adding data sharing or ways of surveilling students that could potentially cause harm down the road,” Vance noted.
During the presentation, Vance pointed to a particularly concerning example of overly broad data sharing: Florida’s new “School Safety Portal.” In an effort to prevent school violence, the controversial portal allows school threat assessment teams to access students’ personal information, including whether a child is in foster care or has been bullied due to their disability or sexual orientation.
However, Vance cautioned: “We know that data is not relevant to whether or not a student is a threat, and so it has the potential to cause additional bias and harm students, instead of pointing out actual threats.” FPF and 32 other disability, privacy, education, and civil rights groups first sounded the alarm about this database in a July 2019 letter to Florida Governor Ron DeSantis.
Click here to watch to the full webinar, and access additional student privacy resources for parents here.
Award-Winning Paper: "Privacy's Constitutional Moment and the Limits of Data Protection"
For the tenth year, FPF’s annual Privacy Papers for Policymakers program is presenting to lawmakers and regulators award-winning research representing a diversity of perspectives. Among the papers to be honored at an eventat the Hart Senate Office Building on February 6, 2020 is Privacy’s Constitutional Moment and the Limits of Data Protection by Woodrow Hartzog of Northeastern University School of Law and Neil Richards of the Washington University School of Law. Whatever your perspective on potential federal privacy legislation, you’ll find this paper to be thought-provoking.
The authors present a case for national privacy legislation that looks beyond data protection and fair information processing (FIPs) principles – the central elements of the EU’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA).
They argue that privacy faces a “constitutional moment” that presents an opportunity to define the structure of our budding digital society. Their position is that while data-protection-focused legislation represents an important step, data protection alone is insufficient. Instead, they suggest an approach to privacy that addresses corporate matters, trustworthy relationships, data collection and processing, and personal data’s externalities.
Corporate Privacy Matters
Hartzog and Richards argue that a framework for privacy legislation should address market power and corporate structures. For example, they write: “Privacy law should be concerned with a number of corporate matters, including limiting how the corporate form is used to shield bad actors from personal liability.” By empowering privacy officers within the corporate structure with more decision-making abilities and protection from executive pushback, policymakers could promote improved corporate responsibility. Additionally, the paper proposes increased antitrust enforcement to broadly limit the power of corporations.
Relational Privacy
The authors recommend passing legislation designed to protect the trust that people place in companies when they share personal information. Legislation could foster discretion, honesty, and loyalty to create trusting relationships between data collectors and individuals. Hartzog and Richards explain that “If companies are to keep the trust they have been given, it is not enough to be merely passively ‘open’ or ‘transparent.’ Trust requires an affirmative obligation of honesty to correct misinterpretations and to actively dispel notions of mistaken trust.”
Information Collection and Processing
Though the authors argue that the GDPR alone would be inadequate in the United States, they recognize the importance of data protection. They recommend stricter limits on data collection, rigid mandatory deletion requirements, and the prioritization of obscurity to improve upon the data protection foundations present in the GDPR.
The External Impacts of Data Collection
The authors claim that the effects of data collection go far beyond the individual, impacting the environment, mental health, civil rights, and democratic values – concerns that could be addressed in privacy legislation.
If you’re interested in “outside-the-box” thinking about the foundations of potential privacy legislation, you’ll want to read the full paper.
The Privacy Papers for Policymakers project’s goal is to put diverse academic perspectives in front of policymakers to inform the development of privacy legislation. You can view all of this year’s award-winning papers on the FPF website. For more information or to RSVP, please visit this page.
Examining Industry Approaches to CCPA “Do Not Sell” Compliance
By Christy Harris and Charlotte Kress
Over the past year, the online advertising (“ad tech”) industry has grappled with the practical challenges of complying with the new California Consumer Privacy Act (CCPA). Once the new law — the first of its kind in the United States — goes into effect on January 1, 2020, businesses operating in California will be required by law to provide California residents (“consumers”) with “explicit notice” and the opportunity to opt-out of the sale of their personal information, thus establishing powerful individual rights that represent a major step forward in US privacy legislation.
Practically speaking, however, the law’s notice and “Do Not Sell” obligations present unique structural challenges for ad tech companies, many of whom operate as intermediaries, lack a direct relationship with users, and may or may not have formal contractual relationships with data supply chain partners, including publisher properties where the personal information and insights about user activity are utilized to power data-driven advertising. In light of the imminent effective date of CCPA and with an aim to address these challenges, several key ad tech players have developed approaches to comply with specific CCPA requirements that demonstrate a variety of perspectives toward viable compliance solutions.
In late November, the Digital Advertising Alliance (DAA) announced the release of new guidelines and a “Do Not Sell Tool” for publishers and third parties, including a new icon that, when clicked, provides users with access to a page where they can opt out of the “sale” of their personal information by participating companies, and access more information about how consumers can exercise their other CCPA rights with those companies. The IAB also introduced its CCPA Compliance Framework for Publishers and Technology Companies, which includes a master Limited Service Provider Agreement and technical specifications from the IAB for passing CCPA-related signals from publishers to supply chain partners. Google recently unveiled its CCPA “Restricted Data Processing” mechanism, which, when enabled by a business, restricts Google’s data processing to activities permitted to service providers under the CCPA.
In addition to these solutions, the Network Advertising Initiative (NAI) published an analysis to aid companies in determining whether a business activity may, or may not, constitute a “sale” under the CCPA.
In this blog post, FPF summarizes and compares these industry tools and approaches to advertising within the CCPA’s requirements.
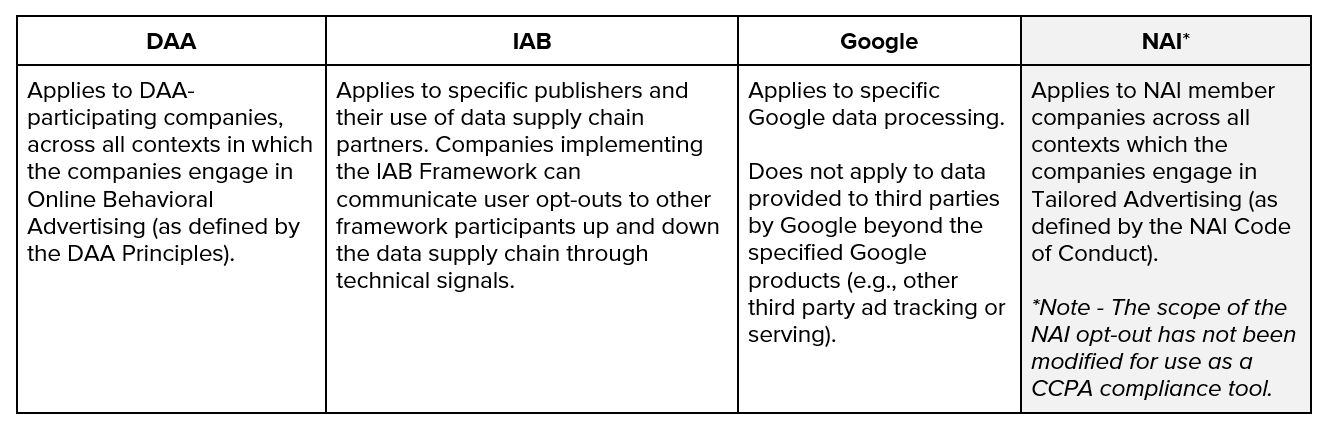
Digital Advertising Alliance (DAA):
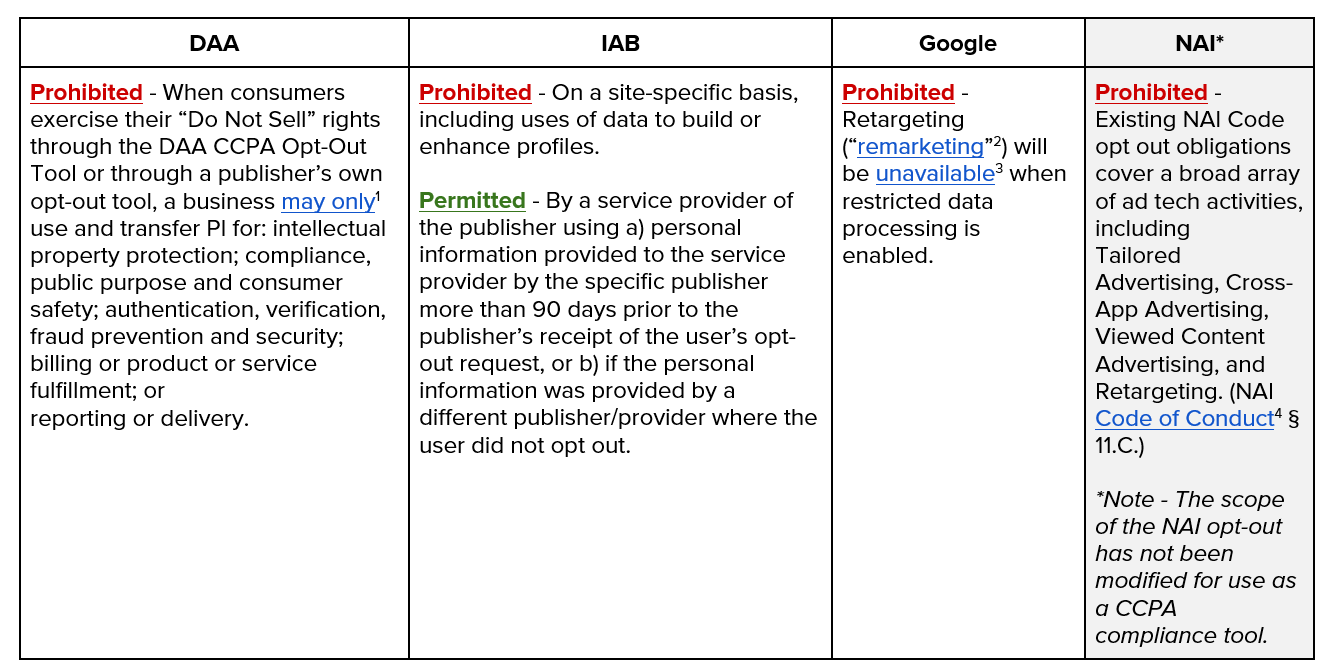
The DAA announced new voluntary guidelines and technological specifications for implementing a new icon, providing participating businesses with a mechanism to provide notice to users as well as certain options for CCPA purposes. The guidance and tools are separate and distinct from the DAA’s existing AdChoices program – an established initiative that relies on blue icons and links to inform users about third parties’ use of data for advertising, and allows users to opt out of receiving targeted ads. The familiar icon, which is green, but otherwise resembles the DAA’s existing AdChoices and political ad icons, can be implemented by businesses to take users to a page where they can access a new DAA CCPA Opt Out tool, which they can use to opt out of “sales” of personal information for CCPA purposes. Businesses using the icon should use accompanying language such as “CA Do Not Sell My Info” (recommended by the DAA), or other language that would comply with the CCPA.
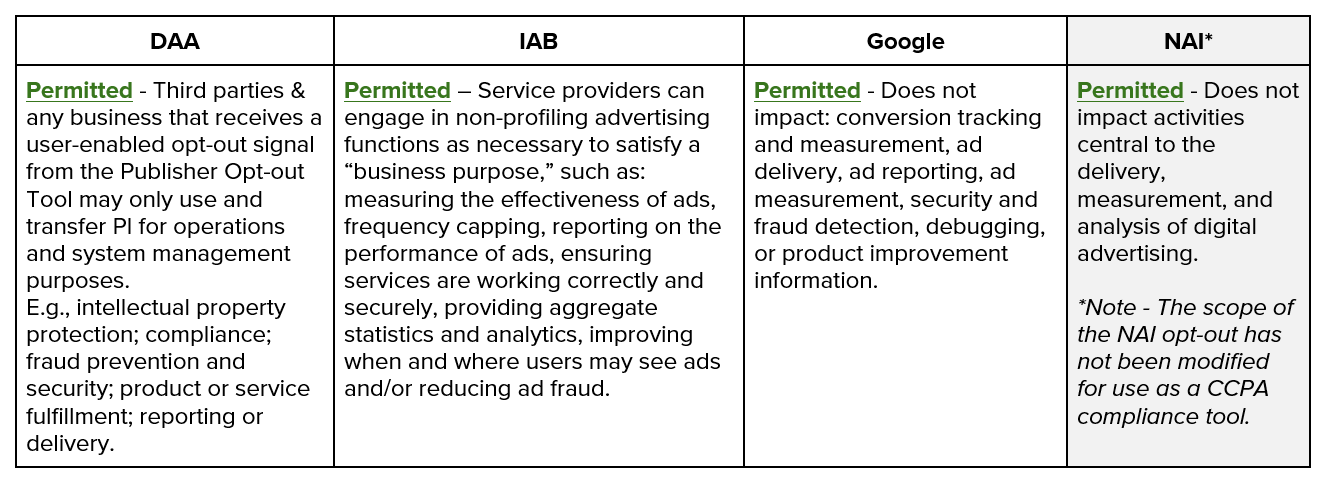
According to the DAA, the new tools “will allow users to opt out of the sale of their personal information by any or all of the participating companies…including third parties collecting and selling personal information through the publisher’s site or app.” The DAA’s guidance and opt-out tools differ from other CCPA compliance approaches in several notable respects. First, the DAA’s CCPA opt-out will apply to participating third party companies’ activity across all publishers on which those companies operate, as opposed to strictly limiting the “sale” of consumers’ personal information at the individual publisher or business level. Further, participating third party companies would not be permitted to serve targeted ads to an opted-out user, even using data the company obtained prior to a CCPA opt out request.
In addition, the DAA’s existing Self-Regulatory Principles and Guidelines require companies to commit to not processing “sensitive data” without consent, including health and financial data, regardless of users’ opt-out status, a restriction which does not yet exist in the current California law (although a feature of a proposed 2020 ballot initiative may change that).
Interactive Advertising Bureau (IAB):
In early December, the IAB unveiled the first official version of its CCPA Compliance Framework for Publishers & Technology Companies, which aims to help digital publishers and their downstream ad tech partners in the programmatic advertising environment address the challenges of the CCPA’s “Do Not Sell” obligation. The framework has an accompanying master contract, called the Limited Service Provider Agreement (LSPA), that binds supply chain partners to specific behaviors to meet the law’s provisions, and a set of corresponding technical specifications that guide companies on how to technologically implement the contract in their operations.
The LSPA requires publishers to include a “Do Not Sell My Personal Information” link or icon on their digital property (e.g., webpage) and defines what IAB framework participants (including websites, apps, and advertising partners) must do when a consumer clicks a “Do Not Sell My Personal Information” link (“DNSMPI link”). The agreement creates “service provider” relationships among publishers and third parties when California consumers opt out, thereby restricting data use to only those specific and limited business purposes that are permitted under the CCPA. Publishers’ service providers are prohibited from augmenting an existing consumer profile or creating a new profile where one did not previously exist for those consumers who have opted out. In addition, service providers are prohibited from making ad-buying decisions based on the personal information of a consumer that has clicked a DNSMPI link. Importantly, however, this prohibition does not extend to personal information that was (1) available about the Consumer before that Consumer clicked the link (i.e. available before the 90 day look-back period mentioned in the draft Regulations), (2) is/was sold to the service provider from another property where the Consumer has not opted out, or (3) constitutes “Aggregate Consumer Information” or “Deidentified” information, as defined in the CCPA. Put another way, consumers who opt out via publishers using the IAB Framework may continue to receive targeted ads from companies participating in the Framework in some circumstances. The Framework also requires publishers that “sell” personal information through programmatic ad delivery to provide “explicit” notice regarding their rights under the CCPA, to explain in clear terms what will happen to their data, and to communicate to downstream participants in an auditable manner that such disclosures were given.
The technical specifications detail a series of signals to be sent from publishers to downstream recipients that will indicate whether: (1) “explicit notice” and the opportunity to opt out has been provided (i.e., CCPA applies and proper notice was given), (2) the user has opted-out of the sale of their personal information, and (3) the publisher is a signatory to the IAB Limited Service Provider Agreement (LSPA) and the publisher declares that the transaction is covered as a “Covered Opt Out Transaction” or a “Non Opt Out Transaction” as defined in the agreement. Together, these specifications provide a common baseline for those who choose to participate in the IAB Framework for communicating between consumers, publishers, advertisers, and other ad tech companies.
In contrast to the DAA’s CCPA Opt Out Tool, which will allow consumers to opt out of a participating third party’s “sale” of their personal across all properties where the third party operates, the opt-out limitations of the IAB’s LSPA are instead applicable at the publisher level on a site-specific basis. Under the IAB Framework, a third party may use the personal information of a user provided by a publisher when the user has not opted out. In instances where a user has opted-out, the third party becomes a “service provider” to that publisher and is permitted to use personal information subject to certain limitations. Specifically, personal information that (a) was made available by the publisher more than 90 days prior to user’s opt-out or (b) is received from other publishers (or digital properties) where the user has not opted out.
Google:
Google recently expanded its “restricted data processing” setting to enable websites and apps using its advertising services to comply with the CCPA. At a publisher’s discretion, restricted data processing may be implemented to apply to all users in California or on a per-user basis when a user clicks a “Do Not Sell My Information” link. When enabled, Google will act as the publisher’s “service provider,” meaning that Google will restrict its use of the personal information it receives to only certain permissible business purposes as enumerated in the CCPA. As a result, certain features of Google Ads, including ad retargeting (or “remarketing”) and adding users to audience seed lists, will not be available to advertisers when the data comes from publishers that have enabled restricted data processing. Per an addendum to its Data Processing Terms, Google Analytics will also act as a service provider for affected businesses when they have disabled sharing with Google products and services.
Similar to the DAA and IAB solutions, the Google solution will not impact certain post-opt out data uses that are permitted under CCPA, including ad delivery, reporting, measurement, security and fraud detection, debugging and product improvement information.
Google’s solution also will not apply to “the sending or disclosure of data to third parties” that advertisers, publishers or partners may have enabled in Google’s products and services. This means that other third-party ad tracking or serving (such as data sharing or other uses integrated with, but not provided by Google) will not be affected when restricted data processing is enabled unless disabled by a publisher. Instead, ads will continue to be served on the Google Display Network and other networks. Businesses will need to independently review these practices to ensure compliance with CCPA obligations. Google will not respond to bid requests for cross-exchange display retargeting (remarketing) ads when a publisher sends an opt-out signal.
Google will also integrate certain technical components of the IAB’s CCPA Compliance Framework. Specifically, restricted data processing will be applied in response to the IAB CCPA Framework opt-out signals in certain Google advertising services. When an IAB signal indicates an opt out in AdSense, AdMob and Ad Manager, Google will not pass the bid request on to any third parties via real time bidding. When Google’s DV360 receives an IAB Framework opt-out signal as part of a bid request from third party exchanges, Google will not place a bid.
Network Advertising Initiative (NAI):
While the organizations described previously have announced various frameworks, guidance, and specific tools that companies can use to comply with CCPA requirements, the NAI has developed a high-level analysis. This resource aims to assist ad tech companies in determining whether or not a business activity may be classified as a “sale” under the CCPA, prior to determining if, or which, mechanisms (including any of the available frameworks and tools) should be employed.
The CCPA defines a “sale” as “selling, renting, releasing, disclosing, disseminating, making available, transferring, or otherwise communicating orally, in writing, or by electronic or other means, a consumer’s personal information by the business to another business or a third party for monetary or other valuable consideration.” The NAI’s analysis explains that the definition of “sale” may be broken down into three main elements, which, when satisfied, the NAI states, would make an ad tech use case a “sale.”
The use case must involve “personal information.”
The use case must involve the movement of personal information from one business to another business or third party.
The use case must involve the exchange of monetary or other valuable consideration for the personal information.
To satisfy the third element identified by the NAI, the requisite monetary or other valuable consideration “must be provided [by the recipient of the personal information] specifically for the purpose of obtaining” personal information, as opposed to having received the personal information incidental to another purpose. For that reason, the NAI points out, it would be difficult to broadly categorize all business activities involving the transfer of personal information as “sales,” because the purpose of a transaction is determined by the intent of the parties to the transaction, and not entirely by any data flows. However, the NAI cautions that whenever a company receives personal information and uses it for purposes that could be monetized independently, such as for profiling or segmenting, that would likely be seen as evidence that the purpose of the transaction was at least partly for the personal information, which could render the exchange a “sale.”
Data Protection by Design (DPbD) is a core data protection requirement introduced in Article 25 of The General Data Protection Regulation (GDPR). In the machine learning context, this obligation requires engineers to integrate data protection and privacy measures from the very beginning of a new ML model’s life cycle and then take them into account at every stage throughout the process. The requirement has frequently been criticized for being vague and difficult to implement in practice.
The paper, co-authored by Sophie Stalla-Bourdillion of Immuta, Alfred Rossi of Immuta, and Gabriela Zanfir-Fortuna of FPF, provides clear instructions on how to fulfill the DPbD obligation and how to build a DPbD strategy in line with data protection principles.
“The GDPR has been criticised by many for being too high-level or outdated and therefore impossible to implement in practice,” said Stalla-Bourdillon, senior privacy counsel and legal engineer at Immuta. “Our work aims to bridge the gap between theory and practice, to make it possible for data scientists to seriously take into account data protection and privacy requirements as early as possible. Working closely with engineers, we have built a framework to operationalise data protection by design, which should be seen by all as the backbone of the GDPR.”
The authors have released this as a working paper and welcome your comments. Please share your comments by sending an email to [email protected]. The ultimate goal of the paper is to begin shaping a framework for leveraging DPbD when developing and deploying ML models.
In November 2018, OneTrust DataGuidance and FPF partnered to publish a guide to the key differences between the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act of 2018 (CCPA).
Since then, a series of bills, signed by the California Governor on 11 October 2019, amended the CCPA to exempt from its application certain categories of data and to provide different requirements for submission of consumer requests, among other things. The Guide has been updated to take into account these amendments.
Finally, the California Attorney General issued, on 10 October 2019, Proposed Regulations under the CCPA which are intended to provide practical guidance to consumers and businesses. The Proposed Regulations were open for public consultation until 6 December 2019 and, when finalised, will provide an additional layer of regulatory requirements that companies will have to comply with.
This updated Guide aims to assist organisations in understanding and comparing the relevant provisions of the GDPR and the CCPA, to ensure compliance with both laws.
Last week, The Council of State Governments (CSG) held its annual conference in Puerto Rico, bringing together bi-partisan state lawmakers from across the country to engage in thoughtful discourse and learn about issues impacting their constituents. Policy Fellow Jeremy Greenberg shares key privacy themes that resonated through the event:
State legislators feel the need to “do something” in terms of protecting the right to privacy. Even legislators with no privacy expertise are feeling overwhelming pressure to respond to concerns from the media and their constituents. While states like California, Washington, and New York are well-staffed and well-funded, others do not have the necessary resources to develop privacy legislation.
There are poor perceptions of progress on a federal level. Most state legislators are under the impression that there is little or no agreement in Congress in terms of developing comprehensive federal privacy legislation. In actuality, we may be further along than legislators think. Senate Commerce Committee Leaders recently introduced two federal privacy bills that are closer together on most issues than they are apart. Other experts agree that we could see a bipartisan proposal capable of passage in 2020.
Policymakers are worried about elections and the microtargeting of political ads. In light of the Cambridge Analytica scandal, legislators are worried about how user data will be used to influence politics. Following the Snowden revelations and increasing data breaches and identity theft, there has been growing public discontent on the state of privacy protection in the U.S., with the Cambridge Analytica scandal seen by many as the “final straw.” The FTC recently issued an Opinion and Final Order against Cambridge Analyticafor engaging in “deceptive practices to harvest personal information from tens of millions of Facebook users for voter profiling and targeting.” However, by focusing on whether the method of data collection was deceptive to consumers, the opinion demonstrates that we currently lack the legal tools to conceptualize that the way data was used was itself harmful.
Greenberg also shared takeaways from the three panels he spoke on:
Securing the Internet of Things – Moderated by John Bowers of the Berkman Klein Center, panelists discussed a range of issues pertaining to internet-connected devices. Cheryl Hiemstra, Assistant Attorney General at the Oregon Department of Justice, provided an overview of the state’s recently-passed IoT security legislation. Going into effect on January 1, the new law requires manufacturers of connected devices to equip them with “reasonable security features.” Greenberg touched on FPF’s work in the IoT space, citing an infographic on microphone use in IoT devices, how IoT devices should deal with privacy impacts for people with disabilities, and more.
Lunch: The Landscape of Privacy Legislation – During this panel, Greenberg discussed the history of CCPA, key privacy provisions in the legislation, and The California Privacy Rights Act of 2020 (commonly referred to as CCPA 2.0). Puerto Rico Senator Carmelo Ríos Santiago mentioned that he introduced a similar bill. Although it gained little traction when initially introduced, he expressed an interest in bringing the bill back. Other states such as Washington, Maine, Utah, Nebraska, and Colorado, are also rumored to be working on their own privacy bills.
What’s Next? Embracing the Future – Joined by The Aspen Institute’s Shelly Steward, Institute for the Future’s Dylan Hendricks, and John Bowers, Greenberg addressed concerns around 5G cell technology and how it will affect individuals. Hendricks shared insights on how augmented reality and virtual reality technologies will be used for training in the workplace, while Steward discussed the future of employment as related to the gig economy.
In order to provide policy experts with tools and resources to be better informed on data privacy legislation in 2020, FPF recently launched its Privacy Legislation Series. In this series, we are exploring specific legislative aspects of comprehensive privacy laws, in an effort to provide U.S. lawmakers and other policy experts with the resources and tools needed to be prepared to evaluate the range of Federal and State efforts in 2020.
Future of Privacy Forum Submits Comments to FTC on the Children’s Online Privacy Protection Act Rule
WASHINGTON, D.C. – Yesterday, the Future of Privacy Forum (FPF), one of the nation’s leading nonprofit organizations focused on privacy leadership and scholarship, submitted comments to the Federal Trade Commission (FTC) regarding the Children’s Online Privacy Protection Act (COPPA) in response to the agency’s ongoing review of the federal statute.
“As COPPA enters its third decade, we believe it is important for the FTC to be conducting this rule review. As more technology is adopted in both the classroom and the home, the FTC has a responsibility to ensure that COPPA is keeping pace,” says Amelia Vance, Director of FPF’s Youth and Education Privacy Project.
In the letter, FPF urges the FTC to modernize COPPA in three key areas to ensure the law can continue to adapt to the rapidly-changing technology landscape and respond to the evolving ways children use the Internet:
Clarify Policies Related to Voice-Enabled Technologies. The prevalence and accuracy of voice-enabled technologies have increased rapidly as a result of powerful machine learning on large datasets. FPF recommends additional guidance regarding how COPPA’s existing privacy protections apply to voice-enabled technologies, recognizing important distinctions concerning the use of voice data. FPF also recommended codifying the existing nonenforcement policy for operators that do not obtain verifiable parental consent before collecting an audio file of a child’s voice, provided the file is collected solely to perform a verbal instruction or request and is deleted immediately after the purpose fulfillment.
Develop Guidance on COPPA’s “Actual Knowledge” Definition. Creating an internet that is safe and welcoming for children can conflict with preserving the internet that is useful and responsive for adults. The “actual knowledge” standard can be a pragmatic way to balance those interests. However, an influx of technology that analyzes large data sets from general audience websites and services raises questions about the meaning of “actual knowledge.” FPF recommends the FTC develop guidance regarding COPPA’s definition of “actual knowledge” that provide greater clarity for businesses and parents in line with reasonable public policy goals.
Encourage Greater FERPA Alignment. While the primary federal student privacy law, FERPA, has fairly clear requirements for school relationships with education technology (edtech) providers, the requirements of COPPA when edtech providers collect students’ personal information from schools are not. Schools need to know when they may exclusively exercise COPPA’s rights regarding the access and deletion of children’s data. FPF recommends that the FTC promptly clarify the circumstances in which schools may exclusively exercise COPPA rights regarding student data.
To read the FPF’s full comments to the FTC, click here. For a new “Myth Busters” blog from FPF that explains common misunderstandings about COPPA, click here.
For more information and resources from the Future of Privacy Forum, visitwww.fpf.org.
MythBusters: COPPA Edition
Following YouTube’s September settlement with the Federal Trade Commission (FTC) regarding the Children’s Online Privacy Protection Act (COPPA), YouTube released a video in late November explaining upcoming changes to their platform. The YouTube creator community responded in large numbers, with numerous explainer videos and almost two hundred thousand comments filed in response to the FTC’s just-closed call for comments on the COPPA rule. Some responses have been insightful and sophisticated. Others have indicated confusion and misunderstanding of COPPA’s requirements and scope. This blog addresses some of the most common myths circulating in YouTube videos, tweets, and Instagram posts.
Fact 1: You can’t “stop COPPA” by filing comments with the FTC
Some COPPA explainer videos call for viewers to write comments to the FTC asking them to “stop COPPA.” There are two problems with this call to action.
First, the FTC can’t stop COPPA. COPPA is a federal law, passed by Congress in 1998. The law has existed for over 20 years, and the FTC does not have the authority to get rid of COPPA. Asking the FTC to do something beyond its authority will not change the law, YouTube’s policies, or the rules that creators must follow.
Second, the FTC is reviewing the rules it created in 2013 to determine whether they need to be updated or changed. These rules describe how the FTC implements and enforces COPPA. This is an important opportunity for creators to be involved in how COPPA will shape internet video services – it’s crucial to know what comments can accomplish. Comments to the FTC will influence how the rules will be implemented and enforced in the future but are unlikely to change things that have already occurred, like the YouTube settlement.
The recent changes to YouTube occurred because the platform agreed to modify some of its practices (and pay a fine) rather than go to court against the FTC. The major change for creators involves the addition of the “made for kids” flag: all creators are required to select whether their channel or a specific video is created for kids or for a more general audience. The flag tells YouTube when they can and cannot place targeted advertising (which isn’t allowed for kids under COPPA). The settlement did not require the creation of an algorithm to look for misflagged content or the changes in viewer functionality for “made for kids” videos. YouTube did this, and the FTC can’t change the platform back to the way it was.
That doesn’t mean that creators shouldn’t engage with the FTC. The current FTC comment period will be over, but the process of creating new COPPA rules will likely take years, and there will be more opportunities to be heard. The FTC needs to know which data creators have about their users and how that data drives decision-making. Tell them about your income from advertisements, your level of control over the advertisements on your channel, and what you wish you knew about advertising on YouTube. The FTC needs to understand your business model and the business of content creators on platforms in general. So, tell them about how information from YouTube informs the content on your Twitch stream, whether it changes how you use your Patreon, or influences merchandising decisions. The best way to get useful rules that protect children’s privacy while supporting content creation on the internet is if the FTC knows how this portion of the economy works.
A note about commenting: be polite. When you make comments on a government website, a real person will read them. So don’t use all caps or profanity, and write in complete sentences. The point is not to fight the FTC but to inform them of your concerns. While asking your viewers to comment can be useful, make sure that you remind them to be kind as well. Civil, smart comments are more likely to have a positive influence.
Fact 2: COPPA is not infringing on First Amendment rights
COPPA regulates the collection, use, and sharing of data created by children. COPPA does have specific obligations for data collected from websites or online services directed to children, but those obligations do not dictate the content you can or cannot create. COPPA may make it more difficult to profit from child-directed content, but this does not mean that anyone’s rights have been infringed. YouTube’s Terms of Service and platform design have more influence than any American law over the kind of content users can create.
Fact 3: Not everything is child-directed
YouTube’s video explaining COPPA-related changes to the platform includes a list of factors that can indicate whether a video or channel is made for kids.
This has caused some confusion. Just because a channel or video may check one or two of these boxes does not mean that it is child-directed. The FTC said as much in its blog post (if you have not read it yet, please do). The blog was written specifically to answer questions about what constitutes “child-directed” content.
If you’re still confused about whether your content is child-directed, ask yourself, “Who am I speaking to?” When you create a video, you should have an idea of who will watch it. And humans use different communication strategies for different kinds of people. For example, think about sitcoms created for major TV networks like CBS, NBC, or ABC versus sitcoms created for the Disney Channel or Nickelodeon. While the two types share similarities, including the format, some of the situations, and the presence of a laugh track, there are major differences that reflect the different audiences. Some sitcoms created for children have simpler language, vivid costumes, or include extensive over-acting (for a visual explanation, watch this clip from SNL). These features make the content more engaging for children. Think about your content. Where does it belong: the Disney Channel or ABC?
After you decide whether your channel or individual video is made for kids, write down why you made that decision. There are two reasons for doing this. First, if the FTC contacts you or if YouTube changes the flag on your video, you will have already prepared your response. You won’t have to try to create responses based on decisions you may have made months or even years earlier. Second, and more importantly, this will keep your actions consistent. As you continue to work and create new videos, you may not remember why you said one video was made for kids while another wasn’t. This not only creates a record of your decision-making process but should make it easier in the long run.
Fact 4: A COPPA violation probably won’t bankrupt your channel
The FTC has stated that when it determines fines for violations, it considers “a company’s financial condition and the impact a penalty could have on its ability to stay in business.” The FTC’s mission is not to put people out of business but to protect consumers. They have limited staff and limited resources; targeting small channels or channels about which a reasonable person could disagree whether the content is child-directed is not typically a good use of their time. But this does not excuse creators from reviewing videos and flagging content as appropriate. You must comply with COPPA, but if you make a mistake, the FTC’s likely first action would be to ask you to change your flag, rather than impose a large fine.
A final piece of advice: do not panic. Panic won’t help. Take a deep breath, review your channel, and stay informed about any other changes that YouTube may announce.
Privacy Papers 2019
The winners of the 2019 Privacy Papers for Policymakers (PPPM) Award are:
by Ignacio N. Cofone, McGill University Faculty of Law
Abstract
Law often regulates the flow of information to prevent discrimination. It does so, for example, in Law often blocks sensitive personal information to prevent discrimination. It does so, however, without a theory or framework to determine when doing so is warranted. As a result, these measures produce mixed results. This article offers a framework for determining, with a view of preventing discrimination, when personal information should flow and when it should not. It examines the relationship between precluded personal information, such as race, and the proxies for precluded information, such as names and zip codes. It proposes that the success of these measures depends on what types of proxies exist for the information blocked and it explores in which situations those proxies should also be blocked. This framework predicts the effectiveness of antidiscriminatory privacy rules and offers the potential of a wider protection to minorities.
by Woodrow Hartzog, Northeastern University, School of Law and Khoury College of Computer Sciences and Neil M. Richards, Washington University, School of Law and the Cordell Institute for Policy in Medicine & Law
Abstract
America’s privacy bill has come due. Since the dawn of the Internet, Congress has repeatedly failed to build a robust identity for American privacy law. But now both California and the European Union have forced Congress’s hand by passing the California Consumer Privacy Act (CCPA) and the General Data Protection Regulation (GDPR). These data protection frameworks, structured around principles for Fair Information Processing called the “FIPs,” have industry and privacy advocates alike clamoring for a “U.S. GDPR.” States seemed poised to blanket the country with FIP-based laws if Congress fails to act. The United States is thus in the midst of a “constitutional moment” for privacy, in which intense public deliberation and action may bring about constitutive and structural change. And the European data protection model of the GDPR is ascendant.
In this article we highlight the risks of U.S. lawmakers embracing a watered-down version of the European model as American privacy law enters its constitutional moment. European-style data protection rules have undeniable virtues, but they won’t be enough. The FIPs assume data processing is always a worthy goal, but even fairly processed data can lead to oppression and abuse. Data protection is also myopic because it ignores how industry’s appetite for data is wrecking our environment, our democracy, our attention spans, and our emotional health. Even if E.U.-style data protection were sufficient, the United States is too different from Europe to implement and enforce such a framework effectively on its European law terms. Any U.S. GDPR would in practice be what we call a “GDPR-Lite.”
Our argument is simple: In the United States, a data protection model cannot do it all for privacy, though if current trends continue, we will likely entrench it as though it can. Drawing from constitutional theory and the traditions of privacy regulation in the United States, we propose instead a “comprehensive approach” to privacy that is better focused on power asymmetries, corporate structures, and a broader vision of human well-being. Settling for an American GDPR-lite would be a tragic ending to a real opportunity to tackle the critical problems of the information age. In this constitutional moment for privacy, we can and should demand more. This article offers a path forward to do just that.
by Margot E. Kaminski, University of Colorado Law and Gianclaudio Malgieri, Vrije Universiteit Brussel (VUB) – Faculty of Law
Abstract
Policy-makers, scholars, and commentators are increasingly concerned with the risks of using profiling algorithms and automated decision-making. The EU’s General Data Protection Regulation (GDPR) has tried to address these concerns through an array of regulatory tools. As one of us has argued, the GDPR combines individual rights with systemic governance, towards algorithmic accountability. The individual tools are largely geared towards individual “legibility”: making the decision-making system understandable to an individual invoking her rights. The systemic governance tools, instead, focus on bringing expertise and oversight into the system as a whole, and rely on the tactics of “collaborative governance,” that is, use public-private partnerships towards these goals. How these two approaches to transparency and accountability interact remains a largely unexplored question, with much of the legal literature focusing instead on whether there is an individual right to explanation.
The GDPR contains an array of systemic accountability tools. Of these tools, impact assessments (Art. 35) have recently received particular attention on both sides of the Atlantic, as a means of implementing algorithmic accountability at early stages of design, development, and training. The aim of this paper is to address how a Data Protection Impact Assessment (DPIA) links the two faces of the GDPR’s approach to algorithmic accountability: individual rights and systemic collaborative governance. We address the relationship between DPIAs and individual transparency rights. We propose, too, that impact assessments link the GDPR’s two methods of governing algorithmic decision-making by both providing systemic governance and serving as an important “suitable safeguard” (Art. 22) of individual rights.
After noting the potential shortcomings of DPIAs, this paper closes with a call — and some suggestions — for a Model Algorithmic Impact Assessment in the context of the GDPR. Our examination of DPIAs suggests that the current focus on the right to explanation is too narrow. We call, instead, for data controllers to consciously use the required DPIA process to produce what we call “multi-layered explanations” of algorithmic systems. This concept of multi-layered explanations not only more accurately describes what the GDPR is attempting to do, but also normatively better fills potential gaps between the GDPR’s two approaches to algorithmic accountability.
by Arunesh Mathur, Princeton University; Gunes Acar, Princeton University; Michael Friedman, Princeton University; Elena Lucherini, Princeton University; Jonathan Mayer, Princeton University; Marshini Chetty, University of Chicago;and Arvind Narayanan, Princeton University
Abstract
Dark patterns are user interface design choices that benefit an online service by coercing, steering, or deceiving users into making unintended and potentially harmful decisions. We present automated techniques that enable experts to identify dark patterns on a large set of websites. Using these techniques, we study shopping websites, which often use dark patterns to influence users into making more purchases or disclosing more information than they would otherwise. Analyzing ~53K product pages from ~11K shopping websites, we discover 1,818 dark pattern instances, together representing 15 types and 7 broader categories. We examine these dark patterns for deceptive practices, and find 183 websites that engage in such practices. We also uncover 22 third-party entities that offer dark patterns as a turnkey solution. Finally, we develop a taxonomy of dark pattern characteristics that describes the underlying influence of the dark patterns and their potential harm on user decision-making. Based on our findings, we make recommendations for stakeholders including researchers and regulators to study, mitigate, and minimize the use of these patterns.
Carpenter v. United States, the 2018 Supreme Court opinion that requires the police to obtain a warrant to access an individual’s historical whereabouts from the records of a cell phone provider, is the most important Fourth Amendment opinion in decades. Although many have acknowledged some of the ways the opinion has changed the doctrine of Constitutional privacy, the importance of Carpenter has not yet been fully appreciated. Carpenter works many revolutions in the law, not only through its holding and new rule, but in more fundamental respects. The opinion reinvents the reasonable expectation of privacy test as it applies to large databases of information about individuals. It turns the third-party doctrine inside out, requiring judges to scrutinize the products of purely private decisions. In dicta, it announces a new rule of technological equivalence, which might end up covering more police activity than the core rule. Finally, it embraces technological exceptionalism as a centerpiece for the interpretation of the Fourth Amendment, rejecting backwards-looking interdisciplinary methods such as legal history or surveys of popular attitudes. Considering all of these revolutions, Carpenter is the most important Fourth Amendment decision since Katz v. United States, a case it might end up rivaling in influence.
The 2019 PPPM Honorable Mentions are:
Can You Pay for Privacy? Consumer Expectations and the Behavior of Free and Paid Appsby Kenneth Bamberger,University of California, Berkeley – School of Law; Serge Egelman,University of California, Berkeley – Department of Electrical Engineering & Computer Sciences; Catherine Han, University of California, Berkeley; Amit Elazari Bar On, University of California, Berkeley; and Irwin Reyes, University of California, Berkeley
Abstract
“Paid” digital services have been touted as straightforward alternatives to the ostensibly “free” model, in which users actually face a high price in the form of personal data, with limited awareness of the real cost incurred and little ability to manage their privacy preferences. Yet the actual privacy behavior of paid services, and consumer expectations about that behavior, remain largely unknown.
This Article addresses that gap. It presents empirical data both comparing the true cost of “paid” services as compared to their so-called “free” counterparts, and documenting consumer expectations about the relative behaviors of each.
We first present an empirical study that documents and compares the privacy behaviors of 5,877 Android apps that are offered both as free and paid versions. The sophisticated analysis tool we employed, AppCensus, allowed us to detect exactly which sensitive user data is accessed by each app and with whom it is shared. Our results show that paid apps often share the same implementation characteristics and resulting behaviors as their free counterparts. Thus, if users opt to pay for apps to avoid privacy costs, in many instances they do not receive the benefit of the bargain. Worse, we find that there are no obvious cues that consumers can use to determine when the paid version of a free app offers better privacy protections than its free counterpart.
We complement this data with a second study: surveying 1,000 mobile app users as to their perceptions of the privacy behaviors of paid and free app versions. Participants indicated that consumers are more likely to expect that the free version would share their data with advertisers and law enforcement agencies than the paid version, and be more likely to keep their data on the app’s servers when no longer needed for core app functionality. By contrast, consumers are more likely to expect the paid version to engage in privacy-protective practices, to demonstrate transparency with regard to its data collection and sharing behaviors, and to offer more granular control over the collection of user data in that context.
Together, these studies identify ways in which the actual behavior of apps fails to comport with users’ expectations, and the way that representations of an app as “paid” or “ad-free” can mislead users. They also raise questions about the salience of those expectations for consumer choices.
In light of this combined research, we then explore three sets of ramifications for policy and practice.
First, our findings that paid services often conduct equally extensive levels of data collection and sale as free ones challenges understandings about how the “pay for privacy” model operates in practice, its promise as a privacy-protective alternative, and the legality of paid app behavior.
Second, by providing empirical foundations for better understanding both corporate behavior and consumer expectations, our findings support research into ways that users’ beliefs about technology business models and developer behavior are actually shaped, and the manipulability of consumer decisions about privacy protection, undermining the legitimacy of legal regimes relying on fictive user “consent” that does not reflect knowledge of actual market behavior.
Third, our work demonstrates the importance of the kind of technical tools we use in our study — tools that offer transparency about app behaviors, empowering consumers and regulators. Our study demonstrates that, at least in the most dominant example of a free vs. paid market — mobile apps — there turns out to be no real privacy-protective option. Yet the failures of transparency or auditability of app behaviors deprive users, regulators, and law enforcement of any means to keep developers accountable, and privacy is removed as a salient concern to guide user behavior. Dynamic analysis of the type we performed can both allow users to go online and test, in real-time, an app’s privacy behavior, empowering them as advocates and informing their choices to better align expectations with reality. The same tools, moreover, can equip regulators, law enforcement, consumer protections organizations, and private parties seeking to remedy undesirable or illegal privacy behavior.
AI – in its interplay with Big Data, ambient intelligence, ubiquitous computing and cloud computing – augments the existing major, qualitative and quantitative, shift with regard to the processing of personal information. The questions that arise are of crucial importance both for the development of AI and the efficiency of data protection arsenal: Is the current legal framework AI-proof ? Are the data protection and privacy rules and principles adequate to deal with the challenges of AI or do we need to elaborate new principles to work alongside the advances of AI technology? Our research focuses on the assessment of GDPR that, however, does not specifically address AI, as the regulatory choice consisted more in what we perceive as “technology – independent legislation.
The paper will give a critical overview and assessment of the provisions of GDPR that are relevant for the AI-environment, i.e. the scope of application, the legal grounds with emphasis on consent, the reach and applicability of data protection principles and the new (accountability) tools to enhance and ensure compliance.
Usable and Useful Privacy Interfaces(book chapter to appear in An Introduction to Privacy for Technology Professionals, Second Edition)by Florian Schaub, University of Michigan School of Informationand Lorrie Faith Cranor, Carnegie Mellon University
Abstract
The design of a system or technology, in particular its user experience design, affects and shapes how people interact with it. Privacy engineering and user experience design frequently intersect. Privacy laws and regulations require that data subjects are informed about a system’s data practices, asked for consent, provided with a mechanism to withdraw consent, and given access to their own data. To satisfy these requirements and address users’ privacy needs most services offer some form of privacy notices, privacy controls, or privacy settings to users.
However, too often privacy notices are not readable, people do not understand what they consent to, and people are not aware of certain data practices or the privacy settings or controls available to them. The challenge is that an emphasis on meeting legal and regulatory obligations is not sufficient to create privacy interfaces that are usable and useful for users. Usable means that people can find, understand and successfully use provided privacy information and controls. Useful means that privacy information and controls align with users’ needs with respect to making privacy-related decisions and managing their privacy. This chapter provides insights into the reasons why it can be difficult to design privacy interfaces that are usable and useful. It further provides guidance and best practices for user-centric privacy design that meets both legal obligations and users’ needs. Designing effective privacy user experiences not only makes it easier for users to manage and control their privacy, but also benefits organizations by minimizing surprise for their users and facilitating user trust. Any privacy notice and control is not just a compliance tool but rather an opportunity to engage with users about privacy, to explain the rationale behind practices that may seem invasive without proper context, to make users aware of potential privacy risks, and to communicate the measures and effort taken to mitigate those risks and protect users’ privacy.
Privacy laws, privacy technology, and privacy management are typically centered on information – how information is collected, processed, stored, transferred, how information can and must be protected, and how to ensure compliance and accountability. To be effective, designing privacy user experiences requires a shift in focus: while information and compliance are of course still relevant, user-centric privacy design focuses on people, their privacy needs, and their interaction with a system’s privacy interfaces.
Why is it important to pay attention to the usability of privacy interfaces? How do people make privacy decisions? What drives their privacy concerns and behavior? We answer these questions in this chapter and then provide an introduction to user experience design. We discuss common usability issues in privacy interfaces, and describe a set of privacy design principles and a user-centric process for designing usable and effective privacy interfaces, concluding with an overview of best practices.
The design of usable privacy notices and controls is not trivial, but this chapter hopefully motivated why it is important to invest the effort in getting the privacy user experience right – making sure that privacy information and controls are not only compliant with regulation but also address and align with users’ needs. Careful design of the privacy user experience can support users in developing an accurate and more complete understanding of a system and its data practices. Well-designed and user-tested privacy interfaces provide responsible privacy professionals and technologists with the confidence that an indication of consent was indeed an informed and freely-given expression by the user. Highlighting unexpected data practices and considering secondary and incidental users reduces surprise for users and hopefully prevents privacy harms, social media outcries, bad press, and fines from regulators. Importantly, a privacy interface is not just a compliance tool but rather an opportunity to engage with users about privacy, to explain the rationale behind practices that may seem invasive without proper context, to make users aware of potential privacy risks, and to communicate the measures and effort taken to mitigate those risks and protect users’ privacy.
The 2019 PPPM Student Paper Winner Is:
Privacy Attitudes of Smart Speaker Usersby Nathan Malkin, Joe Deatrick, Allen Tong, PrimalWijesekera, Serge Egelman, and David Wagner, University of California, Berkeley
Abstract
As devices with always-on microphones located in people’s homes, smart speakers have significant privacy implications. We surveyed smart speaker owners about their beliefs, attitudes, and concerns about the recordings that are made and shared by their devices. To ground participants’ responses in concrete interactions, rather than collecting their opinions abstractly, we framed our survey around randomly selected recordings of saved interactions with their devices. We surveyed 116 owners of Amazon and Google smart speakers and found that almost half did not know that their recordings were being permanently stored and that they could review them; only a quarter reported reviewing interactions, and very few had ever deleted any. While participants did not consider their own recordings especially sensitive, they were more protective of others’ recordings (such as children and guests) and were strongly opposed to use of their data by third parties or for advertising. They also considered permanent retention, the status quo, unsatisfactory. Based on our findings, we make recommendations for more agreeable data retention policies and future privacy controls.
Read more about the winners in the Future of Privacy Forum’s blog post.



 Abstract
Abstract








