The Future of Privacy Forum and The Providence Group invite you to participate in the inaugural Privacy War Games event on November 12th, from 8:30 am – 4:00 pm, in San Jose, California. The event will take place at Cisco’s Headquarters, located at 255 West Tasman Drive, Building J, San Jose, CA 95134. Click here for a list of preferred hotels.
In recent years, many leading companies have introduced war games in cybersecurity and other strategic areas as a way to ensure that they are fully prepared for key challenges and unexpected risks. Similarly, the national security community has used war games to provide senior leaders deeper insights into issues, assumptions, and often counterintuitive understandings of decision-making that are not usually available from other qualitative research techniques. War games also provide participants an opportunity to participate in activities and wrestle with issues that are not part of their day-to-day experiences or particular fields of specialty.
Why Privacy War Games?
For privacy professionals who are tasked with managing privacy risk, privacy war games can be an effective way to practice strategic decision making in a risk free environment – before choices have to be made in the real world.
The Future of Privacy Forum and The Providence Group have collaborated to develop and conduct an analytical privacy war game designed to gain insights that will help privacy professionals manage future privacy risk – an increasingly complex task that is made more difficult by: the increasing number of state and sectoral privacy laws; evolving regulatory and compliance requirements; and the regulatory and legal ambiguity of the European General Data Protection Regulation (GDPR).
What is the difference between a table-top exercise and our Privacy War Game?
A table-top exercise usually is a discussion-based game that allows participants, sitting around tables, to interact with one another from their current professional perspective. Table-top games engage players with a set of topics, sometimes in narrative form, and allow specific decisions to be considered. A facilitator will often add new information to spur players into exploring the relationship between their decisions or actions.
Our privacy war game, on the other hand, is a multi-player, scenario-based game with multiple game turns. In a scenario-based game, players are presented with a specific scenario starting point and then play the game through a series of game turns in which each of the game teams must react to and is influenced by the other player’s moves. This dynamic environment adds complexity to the game and forces players to think about both their decisions and the likely impact of the other teams in the game.
Additionally, because it is a multi-player game, game participants assume player roles on the game teams that do not necessarily comport with their current job. This provides game players a unique opportunity to explore a scenario from different perspectives, enabling deeper (and sometimes counter-intuitive) understandings of relevant privacy challenges.
What you’ll take away:
Benefit from an opportunity to “step into the shoes” of another stakeholder, ranging from business executives, regulators, legislators, courts, civil society groups, and consumers.
Learn what to watch out for as you: analyze and navigate a complex privacy scenario; and react to strategic responses and decisions made by other stakeholders who are playing the game.
Take home industry-specific best practices for managing privacy risk.
This Nov. 12 Privacy War Games event will be the beta version of this effort, so we are offering it at a discounted price to our FPF members. We will be using the feedback from this exercise to develop a program that we hope to replicate and offer more broadly.
Mobile Platforms Address Data Privacy with 2018 Updates (iOS 12, Mojave, & Android P)
Authors: Gargi Sen, Stacey Gray *
In light of recent debates over Facebook’s role in protecting users’ privacy against third-party app developers, many are recognizing the importance of mobile platforms in safeguarding user data. As the General Data Protection Regulation (GDPR) takes effect in Europe, and initiatives like the California Consumer Privacy Act are debated in America, we will likely continue to see a strong focus on the privacy protections of technology platforms, intermediaries, and operating systems.
Apple emphasized privacy in its Worldwide Developers Conference (June 4-8, 2018), highlighting several privacy-related updates to the upcoming macOS and iOS 12 (described below). The company has also recently updated its App Review Guidelines, clarifying that app developers must respect user privacy – for example, by adhering to a principle of purpose limitation (data collected for one purpose may not be repurposed without further consent) and avoiding certain kinds of behavioral advertising using sensitive information. Google also made privacy a focus of their newest mobile operating system, Android P, with several key software updates that will restrict app developers’ access to user data.
Apple’s Fall Updates
Privacy upgrades coming to iOS 12 and macOS Mojave include:
Significant Updates to App Store Guidelines:Following the WWDC 2018 conference in early June, Apple made significant changes to its existing App Store Review Guidelines to safeguard user privacy. For example, the updated guidelines bar developers from creating databases from users’ address book information (contact lists and photos). Apps must also have privacy policies, and must request explicit user consent and provide a “clear visual indication when recording, logging, or otherwise making a record of user activity.”
iOS-Style Permissions for DesktopApps: MacOS apps will now be required to request the user’s permission to access certain device sensors, such as the camera or microphone.
Browser Consent Notifications: Safari will prompt browser consent notifications upon detecting website tracking from “Share” and “Like” buttons and website comment feeds. If enabled by default, this will affect social media plugins as well as other interactive features of many websites.
Prevention of Device Fingerprinting: Safari in macOS Mojave will contain updates designed to prevent device fingerprinting. As FPF described in a 2015 report on cross-device tracking, devices and browsers can be identified with a degree of probability through metadata sent in web traffic – such as the system fonts, screen size, installed plug-ins, etc. This kind of digital “fingerprinting,” often referred to as server-side recognition, is often used for short-term advertising attribution and measurement. In Mojave, the Safari web browser will present websites with a “simplified system configuration,” in order to prevent server-side recognition by making each browser appear more standardized.
USB Restricted Mode: Although not discussed in the WWDC keynote, an upcoming feature may require iPhone users to input their passcode to unlock the phone when connecting it to a USB accessory if the phone has been locked for an hour or more. This feature would make it much more difficult for an outside entity, such as a government or law enforcement vendor, to unlock a user’s phone without permission.
Google’s Android Fall Updates
Android P, the newest version of Google’s Android mobile operating system, will also bring ambitious updates for user privacy. Many of these updates were announced in May at Google I/O, Google’s annual developer festival. The Android P operating system, which will be available in the Fall, can currently be downloaded in beta form for those who are interested and have compatible devices.
Restricted Background Access to Sensitive Sensors: If an app is running in the background on an Android P device, the operating system will restrict the apps’ access to the user’s microphone and camera, and will generate an error if an application tries to access them. If an application does need to access these sensors on the phone, it will have to use a foreground service and show a persistent notification on the phone to notify the user of the app’s activity.
Restricted Access to Call Logs and Phone Numbers: Apps running on Android P can no longer read phone numbers or the user’s call log without first obtaining the user’s in-app permission (similar to location, microphone, or other sensitive sensors).
Per-Network MAC Address Randomization: Android P has introduced an experimental feature that will generate a different MAC (media access control) address for every Wi-Fi network that the user connects to, making it harder to track individual users. The MAC address is a unique hardware identifier that devices must broadcast in order to connect to Wi-Fi networks. In many physical locations – such as retail spaces, airports, and stadiums – they are used to count and analyze pedestrian traffic. However, because the MAC address cannot be readily changed, privacy concerns around tracking individual users emerged in recent years. In response, operating systems have begun to randomize MAC addresses sent in Wi-Fi “probe requests” (to automatically connect when nearby to a known network). Android P improves on this default and offers users more anonymity by randomizing the identifier even when they are connected to different Wi-Fi networks.
Location Permission Required for Wi-Fi Scanning: Android P will require apps to obtain the user’s permission to access location information (“ACCESS_COURSE_LOCATION” or “ACCESS_FINE_LOCATION”) before the app may scan for nearby Wi-Fi networks or read Wi-Fi connection information. Many apps facilitate Wi-Fi connections (such as hotspot finders), and in addition, signals from nearby Wi-Fi networks can be used to enhance the accuracy of GPS-based location information. In 2016, the Federal Trade Commission brought an enforcement action against Inmobi, a mobile advertising network, after it was found to be inferring users’ location based on nearby networks even if the users’ had disabled location services.
Protection of a Unique Identifier: Every Android phone has a unique hardware serial number known as an IMEI, which stays the same through any number of factory resets. Following changes made last year in Android O, app developers can no longer access the IMEI without using a new API (Build.getSerial()), which will provide the serial number only if the developer has obtained the user’s permission to read the phone state.
Importantly, we have seen both Apple and Google take concrete steps this year to enforce their existing developer guidelines. For example, Apple began removing apps from the App Store last month for violations of policies against sharing location data with third party advertisers without users’ consent. Similarly, when security researchers found 36 apps on Google Play that inappropriately collected user data, including geo-location and device information, these apps were removed from the Google Play Store.
These updates to iOS 12 and Android P are an important part of ongoing efforts by mobile platforms to safeguard user privacy and enhance user control. Although operating systems primarily act as data intermediaries – facilitating the user’s interactions with mobile apps of his or her choice – they are also well-positioned to protect users’ expectations. For example, most users prefer that apps be restricted from accessing their geo-location without permission, or using it for secondary purposes beyond what they agreed to or expected. Mobile operating systems can provide these protections and assurances through technical measures and app developer license agreements.
Authors:
Gargi Sen is a Legal Fellow at the Future of Privacy Forum, with 10+ years of experience in technology contracts, compliance, and risk assessments.
Stacey Gray is a Policy Counsel at the Future of Privacy Forum, specializing in Internet of Things, Ad Tech, and geo-location data privacy issues.
Beyond Explainability: A Practical Guide to Managing Risk in Machine Learning Models
FPF and Immuta released the first-ever framework for practitioners to manage risk in artificial intelligence and machine learning (ML) models. The joint whitepaper, Beyond Explainability: A Practical Guide to Managing Risk in Machine Learning Models, provides business executives, data scientists, and compliance professionals with a strategic guide for governing the legal, privacy, and ethical risks associated with this technology.
Beyond Explainability aims to provide a template for effectively managing this risk in practice, with the goal of providing lawyers, compliance personnel, data scientists, and engineers a framework to safely create, deploy, and maintain ML, and to enable effective communication between these distinct organizational perspectives. The ultimate aim of this paper is to enable data science and compliance teams to create better, more accurate, and more compliant ML models.
Immuta and the Future of Privacy Forum Release First-Ever Risk Management Framework for AI and Machine Learning
Immuta and the Future of Privacy Forum Release First-Ever Risk Management Framework for AI and Machine Learning
New Guidelines Provide Global Enterprises with a Practical Approach to Managing the Legal and Ethical Challenges of Artificial Intelligence and Machine Learning
College Park, MD – June 26, 2018 – Immuta and the Future of Privacy Forum (FPF) today announced the first-ever framework for practitioners to manage risk in artificial intelligence (AI) and machine learning (ML) models. Their joint whitepaper, Beyond Explainability: A Practical Guide to Managing Risk in Machine Learning Models, provides business executives, data scientists, and compliance professionals with a strategic guide for governing the legal, privacy, and ethical risks associated with this technology.
New risks are emerging as AI and ML are increasingly adopted by enterprises across industries. In Beyond Explainability, Immuta and FPF provide compliance personnel and data scientists with concrete steps for minimizing these risks at scale, leveraging Immuta’s experience managing and deploying models and the FPF’s expertise with applying privacy principles and responsible data policies.
“While algorithms are never free from risk, there are concrete steps that we can take to thoroughly document and monitor machine learning models throughout their lifecycle,” said Andrew Burt, chief privacy officer and legal engineer, Immuta. “Future of Privacy Forum continues to show leadership and foresight to help commercial organizations navigate the new privacy challenges of machine learning. By partnering with the FPF on this whitepaper, we are able to provide clear guidance and best practices to data scientists and compliance teams for designing, using, and maintaining more accurate and more responsible machine models.”
The FPF is a leading non-profit organization for guidance on privacy and data governance issues, working in partnership with industry, leading academics, and other civil society stakeholders. Together, Immuta and FPF have created a comprehensive framework to help govern machine learning models, establishing effective communication between the two, independent organizational perspectives represented by compliance departments and data science programs. These perspectives must be aligned now more than ever for machine learning models to be successfully developed and used across the enterprise.
“Rapid technological innovation associated with AI and machine learning has created new ethical and governance challenges,” said Brenda Leong, senior counsel and director of strategy, Future of Privacy Forum. “Through our partnership with Immuta, we seek to clarify those challenges and provide practical solutions by developing a workable business template for enterprises using machine learning models and AI technologies.”
Download a copy of the Beyond Explainability whitepaper today, including a “Model Management Checklist” to aid practitioners as they build, test, and monitor machine learning models at: www.immuta.com/beyond. This link also features a video of Andrew Burt and Brenda Leong discussing the goals of this whitepaper and Immuta’s partnership with FPF.
Immuta is the fastest way for algorithm-driven enterprises to accelerate the development and control of machine learning and advanced analytics. The company’s hyperscale data management platform provides data scientists with rapid, personalized data access to dramatically improve the creation, deployment and auditability of machine learning and AI. Founded in 2014, Immuta is headquartered in College Park, Maryland. For more information, visit www.immuta.com and follow us on Twitter (www.twitter.com/ImmutaData) and LinkedIn (www.linkedin.com/company/immuta/).
About Future of Privacy Forum
Future of Privacy Forum is a nonprofit organization that serves as a catalyst for privacy leadership and scholarship, advancing principled data practices in support of emerging technologies. FPF brings together industry, academics, consumer advocates, and other thought leaders to explore the challenges posed by technological innovation and develop privacy protections, ethical norms, and workable business practices. For more information about FPF, visit www.fpf.org and follow us on Twitter (www.twitter.com/futureofprivacy), Facebook (www.facebook.com/FutureofPrivacy), and LinkedIn (www.linkedin.com/company/the-future-of-privacy-forum).
Last week, we launched the Israel Tech Policy Institute, an incubator for tech policy leadership and scholarship, advancing ethical practices in support of emerging technologies. Co-founded by Jules Polonetsky, CEO of the Future of Privacy Forum, and Omer Tene, an Israeli law professor and VP and Chief Knowledge Office at the International Association of Privacy Professionals, the Israel Tech Policy Institute is a new think tank established to provoke, convene and lead policy discussions and support research on privacy, cybersecurity and ethical use of technologies. Liron Tzur-Neumann, a Senior Fellow at the Institute, is an associate at HFN with experience at the Israeli Antitrust Authority. The Israel Tech Policy Institute Advisory Board provides guidance to ITPI staff on major policy initiatives.
In a recent interview with the International Association of Privacy Professionals’ Privacy Tech, Jules expressed that he is betting on Israel to continue its surge upwards, hoping that a country known for being a cybersecurity leader will also end up emerging as a privacy-technology leader. He explains:
“For us, it really made sense since we are the Future of Privacy Forum, and we constantly look at the new technologies and what impact they can have on people and society and how can we put the right rules in place to help privacy leaders and policymakers figure out the right way to engage.”
Custom Audiences and Transparency in Online Advertising
By Stacey Gray and Gargi Sen*
This morning, Facebook announced that they will begin rolling out new requirements for its “Custom Audiences” targeting tool for advertisers. These updates are a useful step towards creating better user understanding of data flows both on Facebook and in the broader web, and enhancing the accountability of advertisers who use custom marketing lists.
What is Custom Audiences?
Facebook’s Custom Audiences is a tool that allows advertisers to upload their own marketing lists of users’ contact information — typically, email addresses or phone numbers — and to target advertisements to those same users on Facebook. In order to protect privacy, the uploaded list is first “hashed” or encrypted (Facebook supports SHA 256). The platform then compares the advertisers’ encrypted data with its own encrypted data from users’ profiles to see who can be added to the advertiser’s “audience.” This is done without the advertiser knowing which users from their own list were a “match,” or whether they even have Facebook profiles. Instead, advertisers receive a report from Facebook with a rough estimate of how many people they are reaching.
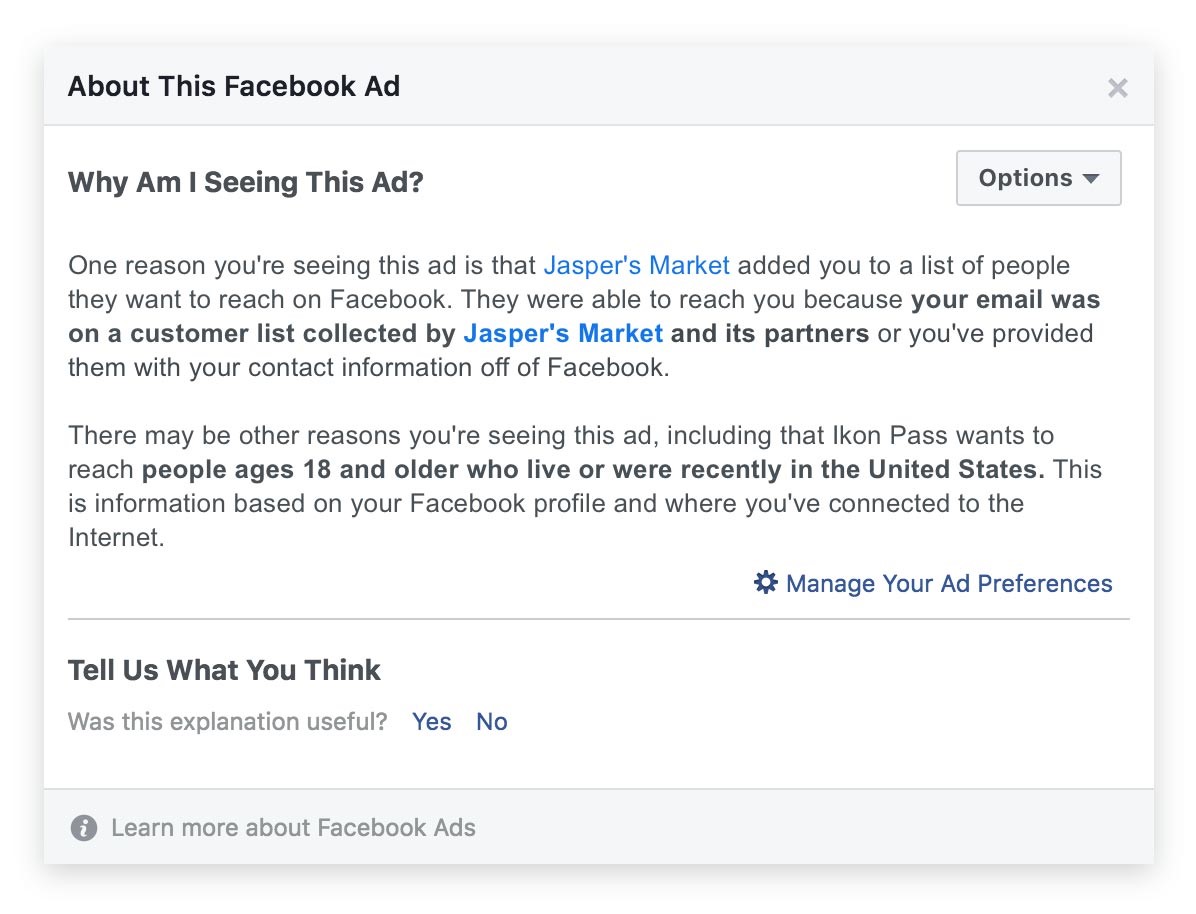
For Facebook users, clicking “Why Am I Seeing This Ad?” at the top of an advertisement results in a pop-up that provides more information about how an ad was targeted. For example, the disclosure may say that the user was targeted based on his or her “Interests,” which are informed by activities such as liking certain pages on Facebook. It may also provide other information about parameters used, such as age or geographical location. With the upcoming new requirements (described below), it will now also provide information about the source of the information, and a disclosure if the advertiser was able to reach them through their phone number or email address.
What’s new for advertisers and Facebook users?
Following todays’ updates, when an advertiser uploads a customer file to create an advertising “audience,” Facebook will now require them to state if they got their information (1) directly from people, (2) from data partners, or (3) a combination of both. When users click “Why Am I Seeing This Ad?”, they will now see this information, along with a disclosure if an advertiser used their email address or phone number in order to target the ad.
As before, users can subsequently choose to stop seeing ads from that particular advertiser, or manage their preferences for targeted ads in Ad Preferences.
Facebook’s “Why Am I Seeing This Ad” feature. Source: https://www.facebook.com/business/news/introducing-new-requirements-for-custom-audience-targeting
Where does the data come from?
Advertisers can obtain marketing lists from many different sources, including from their own customers (for example, through loyalty cards, newsletters, or email subscription lists). They might also be working with a Customer Relationship Management (CRM) system, such as Salesforce, that helps handle data about clients, customers, or prospective customers.
In addition, many advertisers obtain customized lists of “audiences” from online behavioral targeting and marketing companies, such as Acxiom, Experian, or Oracle Data Cloud. For example, as we described in a 2015 cross-device tracking report, Oracle’s BlueKai links 80+ sources of data to “audience categories” based on purchasing intents—e.g. “Back to School Shopper” or “Graduation Gift Buyer.” Although Facebook is winding down its direct integration with these third-party data providers, it remains a common industry practice for advertisers to obtain marketing lists from third-party providers and use them elsewhere (subject to contractual limits).
According to Facebook’s Custom Audiences Terms of Service, it is the advertisers that are ultimately responsible for having permission to share and use the data they hold. Advertisers must promise that their data was obtained legally and appropriately — for example, they must promise to adequately encrypt the data, and to honor any users’ Opt Outs that they have committed to honoring. According to Facebook, advertisers will also now start seeing more regular, detailed reminders of these obligations to help protect users’ privacy.
Implications for AdChoices and Broader Personalized Advertising
Transparency in online advertising–i.e. showing users who placed an ad, and what kind of information was used to inform the placement of the ad– is challenging even in a controlled environment like Facebook. In the broader web, mobile apps, and Smart TVs, it becomes even more challenging, because the infrastructure and protocols must exist for hundreds or thousands of advertising platforms to communicate with users through consistent tools.
In the online environment, the most common method of providing transparency around personalized (behavioral) online advertisements is the Digital Advertising Alliance’s AdChoices icon and opt-out tool. Developed as a self-regulatory program for online advertising, it provides a way for advertisers to share information about data that is being collected about their customers while providing users with a centralized tool to opt out of seeing such ads. The system isn’t perfect–for example, most users do not recognize the icon, and different ad networks may provide different amounts of information, from fairly detailed (“this ad is based on your general location and the time of day”), to very broad (“this ad is based on “information about your online activities”).
Most advertisers have to strike a balance–too broad and the information is not useful, but too detailed, and it may become confusing or inaccessible. Last month, researchers at the Harvard Business School explored ways in which greater transparency may even lead to lowered ad effectiveness, if users are surprised by unexpected information flows.
Looking Ahead
We applaud Facebook’s efforts towards building the necessary infrastructure for robust advertising transparency. Will Facebook users click through to view the new disclosures in targeted advertisements? If so, what will their reactions be? Much of the benefit depends on how the platform raises awareness about the new disclosures, and whether the disclosures are tied to meaningful user choices to better control their data. Following months of news about data privacy and the influence of platforms that enable personalized content, we have seen an enhanced focus on transparency and better understanding of online data flows.
Here are a few things on the horizon:
Better User Education. For users who might not have known that they could be reached using their email addresses or phone numbers, these new requirements are an opportunity for Facebook users to become more aware of online data flows.
More Robust User Controls. Transparency through privacy disclosures is primarily useful when it provides users with accessible tools to control the use of their data. We look forward to seeing not only Facebook but the broader ecosystem of online advertisers continue to improve and iterate on user Opt Outs and controls.
Political Advertisements and Self-Regulation. In the last year, there has been a growing awareness of the specific role of targeted political content in shaping political views. The Honest Ads Act, introduced in 2017, aimed to address these issues by requiring those who purchase and publish such ads to disclose information about the advertisements to the public. Self-regulatory efforts have also emerged, with the Digital Advertising Alliance recently launching an industry-wide initiative to label political ads. Facebook also recently began requiring political advertisers to verify their identity and location for election-related and political issue ads, and making this information available to users with clear labels. The effectiveness of these efforts will help inform efforts around broader advertising transparency.
We look forward to continuing to engage with industry, academics, and advocates on these issues to work towards better consumer education and controls for online advertising.
* Stacey Gray is a Policy Counsel at the Future of Privacy Forum, specializing in Internet of Things, Ad Tech, and geo-location data privacy issues. Gargi Sen is a Legal Fellow at the Future of Privacy Forum, with 10+ years of experience in technology contracts, compliance, and risk assessments.
Facebook, Acxiom, and Salesforce are supporters of the Future of Privacy Forum.
Thanks to Facebook for their proactive engagement with the privacy community on these updates.
Free Student Privacy Bootcamp in Chicago on June 26
FPF has partnered with the Software and Information Industry Association (SIIA) to continue our series of free privacy bootcamps for ed tech companies during the ISTE conference in Chicago. Slots are limited, so RSVP to attend now!
When: Tuesday, June 26th in Chicago from 9am-5:30pm
Where: @1871, 222 W. Merchandise Mart Plaza Suite 1212, Chicago, IL 60654
Need a fast and furious intro to what it takes to do privacy – and security – right as a player in the ed tech market? Want to know why forty states have passed new student privacy laws since 2013? Curious about what other laws apply to your company? Have you had districts ask you to sign privacy contracts, and don’t know why? Want to learn how to get free resources to help you improve your privacy practices and build trust with schools and parents?
Then this event is for you!
This free Student Privacy Bootcamp is co-hosted by SIIA and FPF, the co-founders of the Student Privacy Pledge. We are able to offer this event for free through the support of the Bill & Melinda Gates Foundation.
Speakers include the Director of the Student Privacy Policy and Assistance Division from the US Department of Education, states and districts leading the way on student privacy issues, and education and student privacy experts from itslearning, InnovateEDU, and Orrick.
For the complete agenda and to register, click here.
Please reach out to Sara Collins ([email protected]) with any questions.
We hope you can join!
Empirical Research in the Internet of Things, Mobile Privacy, and Digital Advertising
In the world of consumer privacy, including the Internet of Things (IoT), mobile data, and advertising technologies (“Ad Tech”), it can often be difficult to measure real-world impact and conceptualize individual harms and benefits. Fortunately, academic researchers are increasingly focusing on these issues, leading to impressive scholarship from institutions such as the Princeton Center for Information Technology Policy (CITP), Carnegie Mellon University School of Computer Science, UC Berkeley School of Information, and many others, including non-profits and think tanks.
At events like the Privacy Law Scholars Conference, recently held in Washington, DC (PLSC 2018, May 30-31), privacy-minded scholars from around the world and across disciplines meet to share their research and new ideas each year. Many other conferences sponsor and call for technical privacy research, such as the Privacy Enhancing Technologies Symposium (PETS), which recently announced its accepted papers for 2018. Empirical studies from privacy researchers such as these are an invaluable part of having reasonable and concrete policy debates.
Here is some of the latest in technical and empirical privacy research from 2018:
Researchers conducted semi-structured interviews with owners of smart homes, to explore “privacy awareness, concerns, and behaviors.” They found that: “first, convenience and connectedness are priorities for owners of smart homes, and these values dictate their privacy opinions and behaviors. Second, user opinions about who should have access to their smart home data depend on the perceived benefit. Third, users assume their privacy is protected because they trust the manufacturers of their IoT devices. Our findings bring up several implications for IoT privacy, which include the need for design for privacy and evaluation standards.”
In this study, the authors set up six common IoT devices, and observed network traffic in order to assess privacy and security risks of home devices, as well as study their effects on bandwidth and power consumption. Readers interested in this topic should also check out an oft-cited paper presented at FTC’s 2016 PrivacyCon: A Smart Home is No Castle: Privacy Vulnerabilities of Encrypted IoT Traffic, by Noah Apthorpe, Dillon Reisman, and Nick Feamster (Princeton University).
Based on workshops and interviews with 40 experts, practitioners and scholars (including from Future of Privacy Forum), this report explores the privacy challenges of connected devices and the emerging strategies to address them, including issues of transparency, consent, identifiability, emotional and bodily privacy, and the destabilization of boundaries. UC Berkeley’s Center for Long-Term Cybersecurity published a short white paper version of the research.
The authors explore “device fingerprinting” in the mobile environment, where mobile apps typically rely on non-cookie tracking tools (advertising identifiers), and users of mobile browsers can be more difficult to distinguish from each other than users of web browsers. Among other things, the authors “collect measurements from several hundred users under realistic scenarios and show that the state-of-the-art techniques provide very low accuracy in these settings.”
In this paper, similar to the one above, the authors demonstrate a 90%+ success rate for re-identifying users on the basis of their mobile gestures. As we learn more about the use of mobile sensors for inferring behavior (for example, whether a user is intoxicated), fingerprinting of sensor data from mobile devices may become one of the next major considerations for consumer privacy.
“Won’t Somebody Think of the Children” Privacy Analysis at Scale: A Case Study With COPPAby Irwin Reyes (International Computer Science Institute), Primal Wijesekera (University of British Columbia), Joel Reardon (University of Calgary), Amit Elazari (University of California – Berkeley), Abbas Razaghpanah (Stony Brook University), Narseo Vallina Rodriguez (International Computer Science Institute, IMDEA Networks), and Serge Egelman (International Computer Science Institute, University of California – Berkeley)
Researchers from UC Berkeley and International Computer Science Institute, and University of British Columbia, have demonstrated a way to efficiently analyze network traffic for mobile privacy implications in 80,000 Android apps in the Google Play store.
Email marketers’ uses of third-party tracking tools is often less well understood than online and mobile advertising technology. In order to better understand and describe it, Englehardt et al created a body of emails by signing up for hundreds of commercial mailing lists, and monitored the subsequent web traffic upon opening those emails. Their work describes a complex email marketing ecosystem, stating: “Email tracking is pervasive. We find that 85% of emails in our corpus contain embedded third-party content, and 70% contain resources categorized as trackers by popular tracking-protection lists. There are an average of 5.2 and a median of 2 third parties per email which embeds any third-party content, and nearly 900 third parties contacted at least once.”
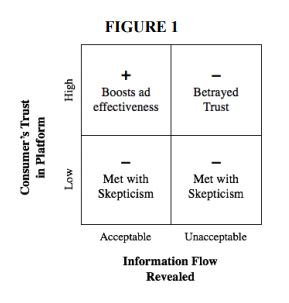
This research, published by the Harvard Business School and based off the lead author’s dissertation, investigates how and why ad transparency — the disclosure of ways in which personal data is used to generate personalized or behaviorally targeted ads — impacts the effectiveness of those online ads. The authors predict that “ad transparency undermines ad effectiveness when it exposes marketing practices that violate consumers’ beliefs about ‘information flows’–how their information ought to move between parties.” (p.2). Through experiments, the authors find supporting evidence that whether information flows are deemed acceptable depends on “the extent to which the ad is based on 1) consumers’ activity tracked within versus outside of the website on which the ad appears and 2) attributes explicitly stated by the consumer versus inferred by the firm (the latter of each pair is deemed less acceptable.” (p.38)
Predicted outcomes for ad effectiveness, according to Tami Kim, et al, based on whether the consumer trusts the platform and finds the underlying data flows acceptable. Source: Figure 1, p. 15 of “Why Am I Seeing This Ad? The Effect of Ad Transparency on Ad Effectiveness” by Tami Kim et al.
In this paper, Stacia Garlach and Professor Daniel D. Suthers investigate a small sample of smartphone users, and explore whether and how they notice, understand, and use the “AdChoices” icon in typical mobile advertisements.
Discrimination in Online Advertising A Multidisciplinary Inquiry – by Amit Datta, Carnegie Mellon University, Anupam Datta, Carnegie Mellon University, Jael Makagon, UC Berkeley, Dierdre K. Mulligan, UC Berkeley, and Michael Carl Tschantz, International Computer Science Institute, Proceedings of Machine Learning Research 81:1–15, 2018
In this paper, Datta et al explore the ways in which discrimination may arise in the targeting of job-related advertising. Under Section 230 of the Communications Decency Act, which provides interactive computer services with immunity for providing access to information created by a third party, the authors argue that “such services can lose that immunity if they target ads toward or away from protected classes without explicit instructions from advertisers to do so.”
Did we miss anything? Send us your recommended research and scholarship at [email protected]
Several papers listed above are accepted papers for the 2018 Privacy Enhancing Technologies Symposium (PETS) (July 24-27, 2018).
EDITED 6/13/18 to add a recent report, Clearly Opaque: Privacy Risks of the IoT (May 2018), by The Internet of Things Privacy Forum
A Toast to Privacy: Celebrating Day 1 of the GDPR
On May 24, the Future of Privacy Forum was honored to co-host a “Toast to Privacy” with the European Union Delegation to the United States to mark the implementation of GDPR and celebrate those who have been working on related projects. The event was held at the Delegation of the European Union’s offices and was attended by public and private sector, government, and civil society leaders from Europe and the United States.
A “midnight” toast to data protection and privacy at 6pm (midnight in Brussels) featured remarks from key stakeholders representing EU institutions, industry, academia, and more via video conference. Speakers included Ambassador David O’Sullivan (European Union Ambassador to the United States), Jules Polonetsky (CEO of The Future of Privacy Forum), and Terrell McSweeny (former FTC Commissioner).
By Sara Collins, Stacey Gray, Tyler Park, and Amelia Vance
Privacy advocates have long feared that student data can be used to inappropriately market to students or limit their future opportunities. In the United States, information about students is often used to send them mail or emails about educational opportunities, scholarships, or after-school activities such as tutoring services or sport leagues. Access to student data is heavily regulated when it comes from schools, teachers, or school surveys. But what about when that same data can be collected from other sources, like public records, commercial sources, or the students themselves? This is the topic of a new study by Fordham University’s Center on Law and Information Policy (Fordham CLIP), “Transparency and the Marketplace for Student Data.”
In the study, the authors present findings from years of research into the commercial ecosystem for data about students, with a particular focus on the practices of “data brokers.” In general, data brokers are companies that buy and sell information about consumers from a wide variety of sources, often from public records or commercial sources. This information may be used for many purposes, such as analyzing trends, or buying and selling lists of contact information for various categories of consumers for commercial advertising or direct marketing. Data sharing such as this is common: as we described in our 2015 cross-device report, Oracle’s BlueKai links more than 80 sources of data to online IDs that can be used to target consumers based on categories or purchasing intents—e.g. “Back to School Shopper” or “Graduation Gift Buyer.” Many companies provide similar services, as personalized or targeted offers are more valuable to advertisers than generic content.
When commercial data involves categories of people known or inferred to be “students” — for example, because they might be shopping for new electronics — it raises understandable concerns from parents and advocates. For example, one seller contacted by Fordham CLIP was willing to sell a marketing list for “‘fourteen and fifteen year old girls for family planning services.'” Elana Zeide, Visiting Assistant Professor at Seton Hall University’s School of Law, remarked that the study’s findings “reflect the broader trend to score and credential human beings as an integral part of our data-driven society.”
Legal frameworks exist to protect student information, but when data does not come from teachers or schools, it will fall outside of the strict requirements of the Family Educational Rights and Privacy Act (FERPA) and most state laws, such as the California Student Online Personal Information Protection Act (SOPIPA). Nonetheless, schools must abide by the Protection of Pupil Rights Amendment (PPRA) when administering surveys that could be used for secondary commercial purposes. The Fair Credit Reporting Act (FCRA) and Children’s Online Privacy Protection Act (COPPA) may already be able to address some of the problems raised by the study.
FERPA and State Student Privacy Laws Governing Schools
“One bright spot in the report is that, among the small number of school districts that responded to the researcher’s requests for information, none appeared to be selling or sharing student information to advertisers,” noted Bill Fitzgerald, Project Director at InnovateEDU, on his personal blog. “However, even this bright area is undermined by the small number of districts surveyed, and the fact that some districts took over a year to respond, and with at least one district not responding at all.”
Under FERPA, schools and teachers are prohibited from sharing information from a student’s educational record — such as contact information, demographics, educational goals, or performance — unless there is parental consent or the disclosure falls within one of FERPA’s exceptions. Similarly, the 121 state student privacy laws passed since 2013 place strict requirements around student information held by local and state education agencies (LEAs or SEAs, respectively), or data that third parties obtain in order to fulfill a school function for an LEA or SEA. As a result, schools typically cannot be used as a source of commercial information for things like advertising and marketing.
However, as this study notes, FERPA and state student privacy laws only apply to personally identifiable information collected by a school or a third party acting on behalf of the school. As a result, if similar data can be collected from outside sources like public records, websites, or mobile games, the information can typically be used for commercial purposes (although not without restrictions, as we describe below).
PPRA and Surveys Administered in Schools
When schools administer surveys to students, a lesser-known federal law applies: the Protection of Pupil Rights Amendment (PPRA). In the research presented in this study, the authors describe how information about students can inadvertently become commercially available through surveys that students fill out online or in schools. For example, some schools are likely giving out surveys from the National Research Center for College and University Admissions (NRCCUA), an organization listed in the study as a “Student Data Broker.” NRCCUA says on its website that it obtains its information from surveys of high school students given by “teachers, guidance counselors, and online.”
PPRA requires schools and districts to have a policy, created in consultation with parents, that establishes a parental right to inspect any survey created by a third party before the survey is administered. If the survey asks about certain sensitive topics – such as family income, religion, political beliefs, or anti-social behaviors – PPRA requires even more: parents must be told about the survey and given the opportunity to opt their child out of taking it. The Department of Education has recently released guidance on administration of third party surveys, reiterating that the PPRA requires consent from parents, not students.
PPRA also has a little-known provision that covers student information marketers: the policy that schools and districts must develop must include specific policies regarding:
[t]he collection, disclosure, or use of personal information collected from students for the purpose of marketing or for selling that information (or otherwise providing that information to others for that purpose), including arrangements to protect student privacy that are provided by the agency in the event of such collection, disclosure, or use. 20 U.S.C. § 1232h(c)(1)(E).
If a survey is found to violate PPRA, it is the school, not the entity that created the survey, that faces liability. As a result, schools and districts should carefully review their PPRA policies and ensure that all school staff know the restrictions of the law. Schools should also review how the school as a whole or individual teachers decide which surveys to administer, to whom the survey authors are releasing the data, and for what purposes.
Existing Enforcement Opportunities
While the study mentioned the Fair Credit Reporting Act (FCRA) as a potential model for regulations that should be created to regulate student data brokers, the law itself may already cover certain limited uses of this data under some the most concerning circumstances. FCRA has a broad definition of “consumer report” which includes “any information” related to “general reputation, personal characteristics, or mode of living” used to make decisions regarding credit, employment, housing, or another benefit. For example, if data brokers provide information to colleges or universities with the knowledge that those institutions are using the information provided to make admissions decisions, they will be considered a “consumer reporting agency” and subject to the strict requirements under FCRA. The FTC has previously issued warning letters to a variety of data brokers in different fields regarding their obligations under FCRA.
Schools should also be aware that the FTC has stated that COPPA applies to any data collected from children under the age of 13, even if it is collected through surveys administered in schools or online. If a school or parent believes that data is being collecting information from children under the age of thirteen for secondary or inappropriate purposes, they may file a complaint with the FTC.
Conclusions
In light of this study, we may see greater regulatory attention to data about student consumers from the Federal Trade Commission (FTC) or the states’ Attorneys General. It is also possible that local, state, or federal policymakers will introduce legislation to regulate data about students that falls outside of FERPA, COPPA, and PPRA. For example, Vermont recently passed legislation requiring “data brokers” to post information about their data practices and opt-outs with the Vermont Secretary of State. These state and sectoral laws may prove to be imperfect solutions, and highlight the growing importance of crafting a baseline privacy law in the United States that would provide more consistent protections for all consumers.
Amidst calls for greater transparency and parental control over this type of data, it is important to ensure that strong privacy protections are balanced against legitimate educational uses of student data, such as providing more educational opportunities to students. Companies who provide these kinds of opportunities for direct marketing can help build trust by establishing clear policies around how data is collected, how it may be used in fair and non-discriminatory ways, and how it will be safeguarded.
Note: One of the CLIP study’s authors, Joel Reidenberg, is an FPF Advisory Board Member. Elana Zeide, quoted in this post, is also an FPF Advisory Board Member.