Future of Privacy Forum Applauds Appointment of Senior Fellow Peter Swire to President Obama’s Review Group on Intelligence and Communications Technologies
Future of Privacy Forum Applauds Appointment of Senior Fellow Peter Swire to President Obama’s Review Group on Intelligence and Communications Technologies
Date: August 28, 2013
WASHINGTON, D.C. – The Future of Privacy Forum (FPF) today applauded FPF Senior Fellow, Professor Peter Swire, on his appointment as as a member of President Barack Obama’s Review Group on Intelligence and Communications Technologies.
“Peter brings to this task a deep passion for individual privacy rights” said Jules Polonetsky, Executive Director and Co-Chair of FPF. “The public will be well served by his commitment to ensure our intelligence activities are conducted in a manner that respects civil liberties.”
“Americans can sleep better knowing that Peter Swire will bring his great intellect and great common sense to the task of weighing privacy and national security needs,” commented Christopher Wolf, Founder and Co-Chair of the Future of Privacy Forum.
Swire brings unique government experience and substantive expertise to the newly created position. Under former President Bill Clinton, Swire served as Chief Counselor for Privacy, in the U.S. Office of Management and Budget (OMB) and was the sole principal to date to have government-wide responsibility for privacy policy, including chairing a White House Working Group on how to update wiretap laws for the Internet age. In 2009-2010, Swire served as Special Assistant to the President for Economic Policy, in the National Economic Council under Lawrence Summers.
Swire has written extensively on international intelligence and communications technology issues, including articles on “The System of Foreign Intelligence Surveillance Law” and “Privacy and Information Sharing in the War Against Terrorism.” He has testified before Congress on multiple occasions about these and related issues.
Swire also is recognized as an expert on encryption policy, which is a key issue for global Internet communications. He chaired the White House Working Group on encryption in 1999, when the U.S. government shifted policies in favor of greater exports of effective encryption. As part of a project on government access to information for FPF, he has written articles including “Encryption and Globalization” and “From Real-Time Intercepts to Stored Records: Why Encryption Drives the Government to Seek Access to the Cloud.” His essay on “Going Dark vs. a Golden Age of Surveillance” was recognized by FPF as one of its leading 2012 Privacy Papers for Policy Makers.
Professor Swire is the lead author of two 2012 books used by the International Association of Privacy Professionals (IAPP) as official texts for the Certified Information Privacy Professionals examinations.
In November, 2012, Professor Swire was named co-chair of the global “Do Not Track” process of the World Web Consortium. With his new responsibilities on the Review Group, Swire is stepping down from his role as co-chair.
FPFcast: Talking Consumer Subject Review Boards with Ryan Calo
In advance of the Future of Privacy Forum and the Stanford Center for Internet & Society’s event on “Big Data and Privacy” next month, we spoke with Professor Ryan Calo about his essay Consumer Subject Review Boards — A Thought Experiment. Professor Calo looks at how institutional review boards (IRBs) were put in place to ensure ethical human testing standards, and suggests a similar framework could be brought to bear on Big Data projects.
In this podcast, FPF’s Joseph Jerome talks to Professor Calo about “Consumer Subject Review Boards” and we also discuss Professor’s Calo recent scholarship on digital market manipulation.
It is becoming increasingly difficult to escape our past in today’s digital world. Internet experts often warn us that once you post, there’s no going back. Many of us suffer from “social sharing regrets.” Just look at the memorable case of Stacy Snyder who was fired from her teaching position after posting a “Drunken Pirate” photo on her MySpace page. Law professor Paul Ohm questions whether it is really fair for employers to know what their employees post on their social network forums: “We could say that Facebook status updates have taken the place of water-cooler chat, which employers were never supposed to overhear.”
Despite learning about the permanence of our posts, we continue to treat our online interactions as if they were only temporary. Some of us scoff at food pictures on Instagram and overly expressive Tweets, but this is the digital native way to say “hello.” Thanks to technology, we can express ourselves with whomever we want by simply sending a quick text, photo or status update. The intention is not always to scrapbook one’s entire life; rather, it is to communicate in the here and now. Social network platforms such as Facebook prompt you to share “what’s on your mind?” Twitter has been likened to a “series of ‘now’ moments”. We intensely Google chat all day long and connect with relatives around the world thanks to Skype. According to the New York Times, these mediums are “shifting the way we share our lives with one another.” Yet when all the “selfies” and #hashtags become part of our historical record, what price will we one day pay?
In his book, “delete: The Virtue of Forgetting in the Digital Age,” Viktor Mayer-Schönberger illustrates how, “with the help of widespread technology, forgetting has become the exception, and remembering the default.” Digital reality has transformed our civilization from one in which the price of remembering was costly and forgetting inexpensive, into a reversed scenario in which remembering is the default. It is standard to have a plethora of email exchanges collecting digital dust in our inboxes. Text messages make it easy to stay in touch, but they also serve as a transcript of past arguments and embarrassing admissions. We can speak our minds freely in-person, knowing that the conversation comes to a definite end, and forget the details of what was said. Yet when these same conversations take place over social platforms, we can re-read the record as many times as we want, mulling over the words typed. The limitations of memory are no longer an issue. Mayer-Schönberger thus asserts that we need to face the consequences of how our follies become permanently recorded and “forever tether us to all our past actions, making it impossible, in practice, to escape them.” The subsequent trend is to consciously curate our virtual lives at a younger and younger age. Internet guru Jared Lanier’s fear that “we are beginning to design ourselves to suit digital models of us” holds merit. Digital permanence exacerbates peer pressure; it makes use more likely to conform rather than to take risks, make mistakes and think outside the box.
Does it have to be this way? Shouldn’t technology serve we the people? Technology should distinguish between communications we want to be permanent and the communications we want to be ephemeral. In small ways, a number of new technologies seem to be steering in this direction. The success of services like Snapchat may be due to the “here and now” feeling it conveys. Snapchat, which allows users to send photos and videos that disappear after a short time, first become known for its use of sending naughty pics. However, the main draw of this service today appears to be the free-flowing dialogue it fosters without worrying about a permanent digital record. As stated on its website, “the allure of fleeting messages reminds us about the beauty of friendship – we don’t need a reason to stay in touch.” Another new app, Frankly, extends the vanishing message model into the world of text messages. The goal of these services is simple – create something impermanent in a world where data is forever.
– Heather M. Federman. Heather is a Legal & Policy Fellow at the Future of Privacy Forum.
Privacy and Big Data: The Biggest Public Policy Challenge of Our Time?
FPFcast: Talking Big Data with Professor Chris Hoofnagle
[audio
In advance of the Future of Privacy Forum and the Stanford Center for Internet & Society’s event on “Big Data and Privacy,” we spoke with Professor Chris Hoofnagle about his essay How the Fair Credit Reporting Act Regulates Big Data. In his essay, Professor Hoofnagle points out that consumer reporting achieved “big data” status decades ago, and he cautions while use-based regulations could provide more transparency and due process, they did not create adequate accountability in the context of consumer reporting.
“In the FCRA context, use based approaches produced systemic unaccountability, errors that cause people financial harm, and business externalities passed off as crimes,” he argues.
In this podcast, FPF’s Joseph Jerome talks to Professor Hoofnagle about lessons learned from the FCRA and what that means in the context of Big Data.
Big data, the enhanced ability to collect, store and analyze previously unimaginable quantities of data in tremendous speed and with negligible costs, delivers immense benefits in marketing efficiency, healthcare, environmental protection, national security and more. While some privacy advocates may dispute the merits of sophisticated behavioral marketing practices or debate the usefulness of certain data sets to efforts to identify potential terrorists, few remain indifferent to the transformative value of big data analysis for government, science and society at large. At the same time, even big data evangelists should recognize the potentially ominous social ramifications of a surveillance society governed by heartless algorithmic machines.
In Judged by the Tin Man: Individual Rights in the Age of Big Data, Omer Tene and I present some of the privacy and non-privacy risks of big data as well as directions for potential solutions. In a previous paper, we argued that the central tenets of the current privacy framework – the principles of data minimization and purpose limitation – are severely strained by the big data technological and business reality. Here, we assess some of the other problems raised by pervasive big data analysis. In their book, “A Legal Theory for Autonomous Artificial Agents,” Samir Chopra and Larry White note that “as we increasingly interact with these artificial agents in unsupervised settings, with no human mediators, their seeming autonomy and increasingly sophisticated functionality and behavior raise legal and philosophical questions.”
In this article we argue that the focus on the machine is a distraction from the debate surrounding data-driven ethical dilemmas, such as privacy, fairness and discrimination. The machine may exacerbate, enable, or simply draw attention to the ethical challenges, but it is humans who must be held accountable. Instead of vilifying machine-based data analysis and imposing heavy-handed regulation, which in the process will undoubtedly curtail highly beneficial activities, policymakers should seek to devise agreed-upon guidelines for ethical data analysis and profiling. Such guidelines would address the use of legal and technical mechanisms to obfuscate data; criteria for calling out unethical, if not illegal, behavior; categories of privacy and non-privacy harms; and strategies for empowering individuals through access to data in intelligible form.
Many of the leading academics in the U.S. will be convening on September 10 in Washington to debate strategies to reconcile Big Data and Privacy. Wish us luck!
The fallout from the NSA revelations continue to make the national headlines. But the impact isn’t simply limited to the government’s use of data. Last week, the Chairman of the Article 29 Working Party wrote to the Vice-President of the European Commission to express “great concern” about PRISM and related intelligence programs, including how these programs impact companies’ compliance with the U.S.-E.U. Safe Harbor Program. While the Safe Harbor does have a carve out for national security, the Article 29 Working Party “has doubts whether the seemingly large-scale and structural surveillance of personal data that has now emerged can still be considered an exception strictly limited to the extent necessary.” The letter goes on to remind Member States that they have authority to suspend data flows where there is substantial likelihood that the Safe Harbor principles are being violated.
This is only the latest in a growing group of voices in the E.U. to question whether the Safe Harbor is working. Germany’s data protection commissioner, for example, blogged that the United States data protection framework is lacking and that Safe Harbor “cannot compensate for these deficits.” And just last month, Vivian Reding, Vice-President of the European Commission, called the Safe Harbor “a loophole” that “may not be so safe after all,” and has requested a full review of the program by year-end.
The Safe Harbor has been criticized in the past. For example, one 2008 report found that a number of companies were falsely claiming to be in the Safe Harbor when they in fact had allowed their certifications to lapse. However, in the years since it was last seriously assessed, there have been a number of positive developments. The FTC has stepped up its enforcement efforts and settled a number of cases for Safe Harbor violations. And, the number of companies to sign up to the Safe Harbor has grown.
We think that, in light of these concerns, it may be time to take an objective look at the Safe Harbor program. As the European Commission undertakes its review, we should examine the current protections the Safe Harbor offers, as well as the compliance and enforcement efforts undertaken by both the E.U. and the U.S. Let’s see what is working, and what isn’t. And, if there are ways to make the Safe Harbor better, we should step up to the plate and offer solutions.
FPFcast: Talking Big Data with Professor Bill McGeveran
[audio
In advance of the Future of Privacy Forum and the Stanford Center for Internet & Society’s event on “Big Data and Privacy,” we spoke with Professor Bill McGeveran about his essay Revisiting the 2000 Stanford Symposium in Light of Big Data. Thirteen years ago, the Stanford Law Review convened a symposium on “Cyberspace and Privacy: A New Legal Paradigm?” which produced a volume of legal scholarship that Professor McGeveran stresses remains important today. “One encounters all the same debates that are arising new in the context of Big Data,” he writes.
Among the issues he highlights are (1) the propertization of data, (2) technological solutions like P3P, (4) First Amendment questions, and (4) the challenges posed by the privacy myopia.
In this podcast, FPF’s Joseph Jerome talks to Professor McGeveran about the lessons learned from the symposium and how they can be applied to Big Data moving forward.
FTC Provides Limited “Safe Harbor” for Users of a “Do Not Track for Kids” Flag
The new Children’s Online Privacy Protection Act (COPPA) rule that went into effect earlier this month restricts almost all forms of tracking across child-directed sites other than for a set of limited “internal operations purposes.” Child-directed sites are now strictly liable for any third party tracking on their sites that do not meet COPPA’s limited exceptions, unless they obtain verified parental consent.
Third party code providers, such as analytics companies, ad networks, or social plug-in providers, can also be liable under the new COPPA rule if they have “actual knowledge” they are dealing with children – that is, if the first party site has effectively communicated its online status to the third party or if a “representative of the online service recognizes the child directed nature of the site.” Yet for many third party code providers, who distribute their code freely to millions of web developers, there is no way to assess whether they are being used by services directed at children.
Earlier this month, the Future of Privacy Forum (FPF) announced its support for a model proposed by FTC Chief Technologist Steve Bellovin calling for a special “flag” to be passed between companies that would indicate the child directed status of a site. FPF has been working with a number of stakeholders to refine a technical proposal that could help standardize this type of communication, effectively creating a limited “Do Not Track for Kids” signal. We have urged the FTC to provide a “safe harbor” for users of this flag in order to provide more certainty in this area and to help ensure compliance from web publishers and third parties.
Last week, the FTC released updated FAQs to help businesses comply with the COPPA rule. These FAQs include a provision recognizing the COPPA flag as a viable tool for compliance; the FAQ sets forth a technical system for a site to affirmatively certify whether it is “child-directed” or “not child-directed.” According to the FAQs, companies may rely on a signal that a site is “not child-directed,” but “only if first parties affirmatively signal that their sites or services are ‘not child-directed.’” Companies cannot set this option for their clients as a default, if they wish to limit their liability. The FTC is requiring a “forced choice” or a “double flag” process, rather than the single flag that Bellovin proposed and that FPF championed.
We are pleased that the FTC recognized the COPPA flag as an effective way to both protect children and ensure that companies meet their obligations. Technology can offer a meaningful, low-cost solution that can be widely implemented across industry to encourage compliance.
The new FAQs describe stringent requirements that must be met for a COPPA signal that companies “may ordinarily rely on.” Our view is that this FTC language creates a safe harbor of sorts, providing protection for companies worried that they will be arbitrarily imputed actual knowledge.
While the FTC’s version of the flag will work for some companies, it will not be practical for many others. And for those who it will work, it will likely be feasible for their new clients only, because retroactively forcing many thousands of current clients to make a forced choice or be terminated is not realistic.
A number of leading companies, including Facebook, AdMob,Twitter,The Rubicon Project, and Yahoo!, began to roll out a single flag option to their clients even before the FTC released its new FAQs. We believe this single “Do Not Track for Kids” option still has value even though it may not meet the FTC standard for a safe harbor. The FTC has reiterated that “actual knowledge” requires a fact-specific inquiry. As a practical matter, companies that send and receive a COPPA flag as part of their compliance efforts are demonstrating a good-faith attempt to meet their obligations under the new COPPA rule. Those who implement such technology as part of a broader compliance strategy will be in a far better position should the FTC come calling than those who do not.
The next step for companies is to standardize a format for the COPPA flag signal so that it can more easily be passed along from company to company. If you are interested in learning more about the FPF’s efforts to standardize this Do Not Track for Kids signal, please email [email protected].
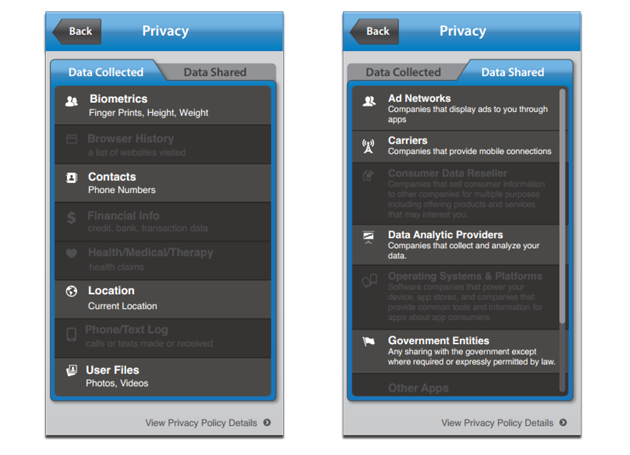
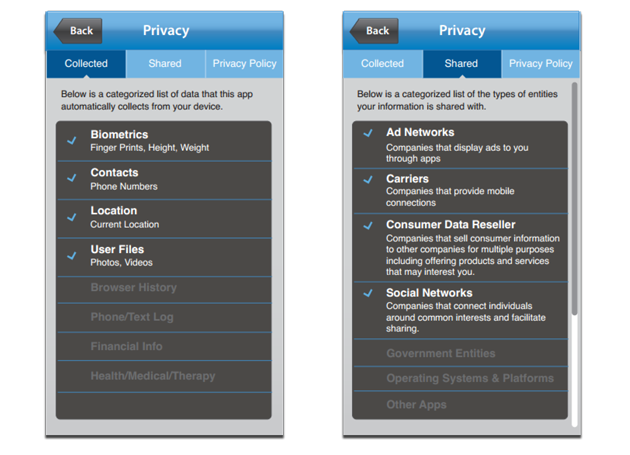
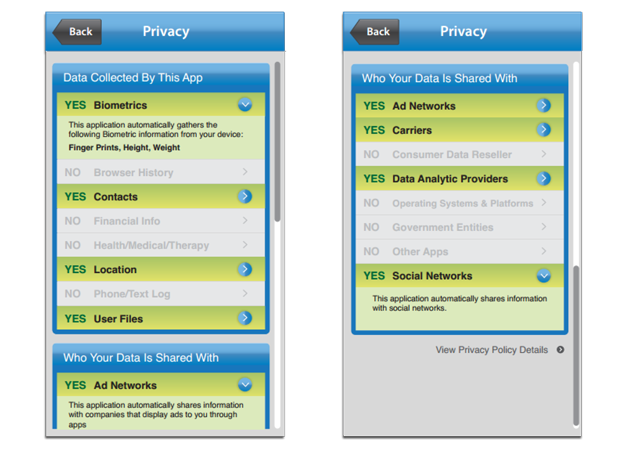
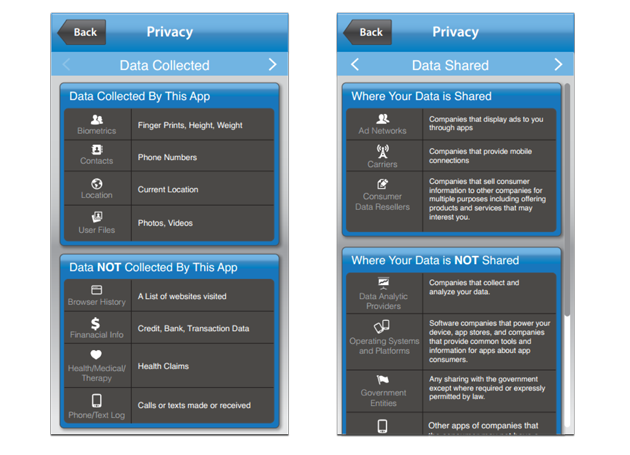
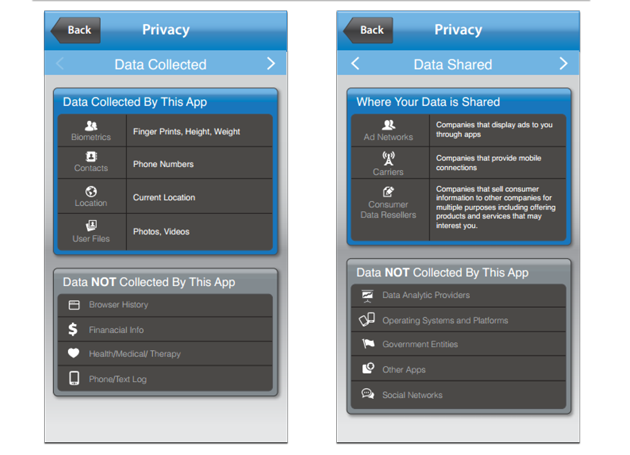
NTIA User Interface Mockups
“I am pleased to support the NTIA Short Form Notice Code of Conduct,” said Jules Polonetsky, Executive Director of the Future of Privacy Forum. “A ‘food label’ type approach to a privacy notice will give consumers a standardized way to get key privacy information at a glance and will help consumers better understand how apps collect and share data.”
The sample notices below show examples of implementations of the short notice developed by a number of the multi-stakeholders. We expect that consumer testing will lead to even better versions that will deliver easy to use information to consumers.
Example 1: Data Use Highlighted
Example 2: Data Used on Top & Data Not Used on Bottom
Please also check out the short form notice example from the Association of Competitive Technology, which demonstrates another clear way that apps can implement the code in an easy-to-use manner!