FPF and Data Privacy Brasil Webinar: Understanding ‘Legitimate Interests’ as a lawful ground under the LGPD
Author: Katerina Demetzou
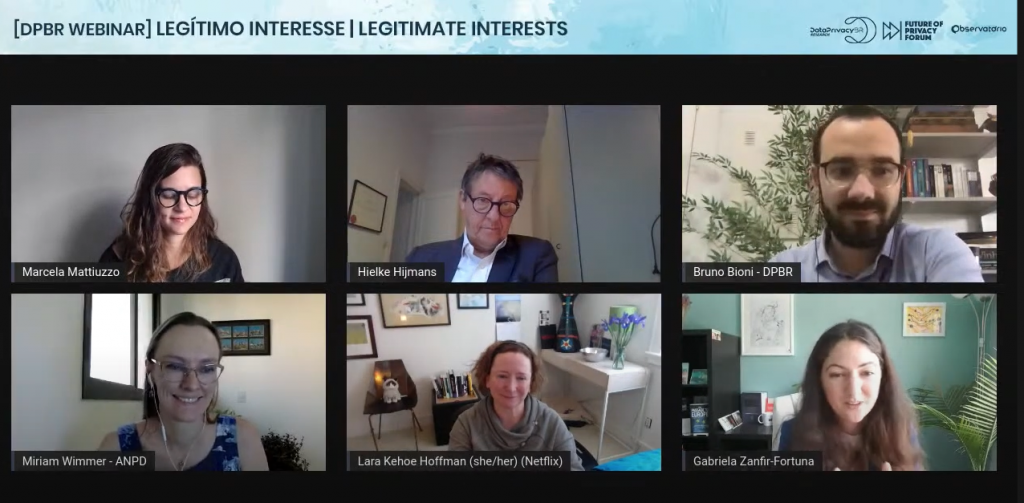
On Thursday, 20th of May 2021, the Future of Privacy Forum (FPF) and Data Privacy Brasil (DPB) co-hosted an online event for launching the English translation of a Report on Legitimate Interests as a lawful ground for processing personal data under Brazil’s Data Protection Law, the Lei Geral de Proteção de Dados (LGPD). The Report explores the role of this lawful ground through use cases and a theoretical framework.
Miriam Wimmer, one of the Directors of the Brazilian Data Protection Authority, gave the keynote address, followed by a panel discussion with Bruno Bioni, Director of DPB and co-author of the Report; Lara Kehoe-Hoffman, VP Privacy and Security Legal and Data Protection Officer of Netflix; Marcela Mattiuzzo, Partner at VMCA Advogados; and Hielke Hijmans, Member of the Board of Directors of the Belgian Data Protection Authority. The event was moderated by Gabriela Zanfir-Fortuna, Director for Global Privacy at the Future of Privacy Forum.
Below you will find the most important points that were raised during the discussion, starting with an overview of how the LGPD absorbed legal concepts from the GDPR, including that of “legitimate interests” (LI) as a lawful ground for processing personal data, while molding them on the Brazilian legal culture (Section 1). A brief presentation of the Report on Legitimate Interests under the LGPD follows, including an explanation of what is the “normative equation” of LI under the LGPD and examples of processing scenarios where LI is usually relied on lawfully (Section 2). The summary continues with mapping out misconceptions and current key points of debate about relying on LI as they emerged from the panel discussion (Section 3), to end with a list of the main takeaways (Section 4).
1. Legitimate Interests under the LGPD: inspired by the GDPR, but developing under their own rhythm in Brazil
In her keynote address, Miriam Wimmer highlighted two important aspects that should be taken into consideration when looking at the data protection legal landscape in Brazil. First of all, only recently did Brazil adopt a Data Protection Law, which ultimately came into force in September 2020. It was not before 2018 that the debate around the right to data protection opened up to the broader stakeholder community that also included business representatives, academics, and civil society groups. The recent history of the LGPD suggests that various topics remain unexplored and immature, therefore explanatory guidelines are required.
A second aspect is the fact that the LGPD has been very strongly influenced by the GDPR and the European approach to the right to data protection. More specifically, in Brazil, the right to data protection is associated with the protection of fundamental rights and it relates to the idea of informational self determination & control over the way that processing of personal data takes place.
Similarly to the GDPR, the LGPD has embraced an ex ante approach by requiring the data controller to abide by certain legal obligations before proceeding to any processing operations. Additionally, the LGPD enumerates data protection principles which have drawn inspiration from the OECD guidelines and the GDPR and has in place data subject rights that empower individuals to exercise control over their data. Most importantly, the LGPD, as is the case for the GDPR, aims to enable and not restrict data flows while simultaneously guaranteeing a high level of personal data protection.
Ten lawful grounds for processing
After laying out this background, the Director of the ANPD made some important points specifically relating to the LI ground. To begin with, having LI as a legal ground for processing shifts the focus away from consent as the only ground that ensures self determination and control of individuals over processing operations.
The LGPD provides for ten legal bases for processing. According to Wimmer, data controllers should not treat the LI basis either as a last resort or as a preferred option. On the contrary, and given that there is no hierarchy among the ten legal bases, data controllers should decide on the most appropriate legal ground according to the concrete circumstances of each case. However, Wimmer considers that further analysis and a better understanding is needed with regard to the meaning and the circumstances under which each basis shall be chosen over the others.
Under the LGPD, the LI ground is about balancing the legitimate interests of the data controller or a third party and the fundamental rights and freedoms of the data subjects. It consists of three tests, namely the purpose test, the necessity test and the balancing test. Under Article 10 LGPD, the personal data that are to be processed need to be strictly necessary for the defined purposes and there is a requirement of enhanced transparency.
The relationship between “Legitimate Interests” and Data Protection Impact Assessments
Additionally, the law gives the ANPD the possibility to require a Data Protection Impact Assessment (DPIA) from the data controller that processes data on the basis of the LI ground. This last requirement has spurred a debate on whether a DPIA is the most appropriate type of assessment given that it is complex and that not all processing operations based on the LI ground present significant risks. Instead, a legitimate interest assessment appears to be the preferred option.
Miriam Wimmer also mentioned that while the LI is a mature concept in the EU, this is not the case for Brazil and therefore there is still need for guidance on what exactly are legitimate interests under the LGPD and in which cases would they serve as an appropriate legal basis. One of the most heated debates around LI during the legislative process of the LGPD was around whether LI will end up being a carte blanche for data controllers. The ANPD aims to ensure that the LI legal ground will not be abused and will be used appropriately.
2. Exploring use cases and practical tests: the Report on Legitimate Interests under the LGPD
Bruno Bioni, one of the co-authors of the Report whose translation into English was launched during the event (together with Mariana Rielli and Marina Kitayama), introduced its structure and content. The Report begins by presenting the history behind the introduction of the LI ground in the LGPD, followed by a detailed analysis of its singular normative design under the law.
Article 7 enumerates LI as one of the lawful grounds for processing, Article 10 specifies the requirements for application of the LI ground and Article 37 requires the keeping of records when the LI is used as the basis for processing. In the Report, the combination of these articles is considered to be the ‘normative equation of Legitimate Interests under the LGPD’.
The policy paper takes the view that the Legitimate Interest Assessment is a four-step process consisting of: a legitimacy test, a necessity test, a balancing test and the assessment of safeguards.
The Report then analyzes the possibility that the ANPD has to request the controller to perform a DPIA in cases where the LI ground is used. According to DPB, the process of performing a DPIA should not be triggered by the legal ground used in each case, but by the high risk profile of each specific processing operation.
In the last part, the Report presents ten case studies in order to help practitioners apply the LI ground in practice.
There were multiple scenarios mentioned by the speakers whereby the use of LI as a ground is prima facie appropriate. Some examples are: fraud detection and prevention systems security, employment data processing (e.g. company directory, ethics reporting hotlines), general corporate operations (e.g. conducting audits), analytics for product and service improvement.
Speakers also discussed why LI is a necessary legal ground to be included as an option in sophisticated, comprehensive data protection legislation meeting the demands of the digital economy, while also aiming to provide safeguards for the protection of both individual and collective rights and interests. In practice, lawfully relying on LI demands thoughtfulness from data controllers.
They need to perform at least three separate tests (legitimacy, necessity, balancing), carefully assess whether LI is indeed the most appropriate legal ground in the case at hand, and they have to take into consideration the data subject’s expectations and interests. Among these, as Hijmans pointed out, the balancing test is very challenging because by its very nature it is a subjective exercise that needs to be further objectified if possible.
3. Misconceptions and Key Points of Debate about relying on LI
There were several misconceptions about relying on LI identified during the panel discussion, common to the LGPD and the GDPR, but primarily emerging from the longer practice under the GDPR.
Panelists agreed that a common misunderstanding is that there is a hierarchy among the different lawful grounds for processing. In both jurisdictions, all lawful grounds for processing are equal and their application should depend on the specific circumstances of each case. For instance, consent should not be considered the main legal basis for processing data, as it is often the case in practice, with the other lawful grounds seen as exceptions.
The question of whether a purely commercial interest can serve as a legitimate interest was mentioned not as much as a misconception, but as the subject of current lively debate around LI and a challenging issue to be solved in the upcoming updated guidance of the European Data Protection Board on LI.
Another misconception was identified around the question of whether processing personal data on the basis of legitimate interests is less protective for the rights of individuals compared to other lawful grounds. Speakers commented that this is not the case, especially where controllers are diligent about the necessary assessment and balancing of interests required to lawfully rely on LI for processing personal data, and about complying with all the rights individuals have even in relation with personal data processed on the basis of LI.
It surfaced from the panel discussion that what is very important, from a practical point of view, is the ability to understand first of all what personal data controllers are collecting. Secondly, it is important to precisely identify what they intend to do with the personal data, or the purpose of processing. Then, the basic filter through which every decision on whether to rely on LI should pass through is that of the individual’s reasonable expectations and the filter of fairness. This is why both the principle of accountability and the principle of fairness are key in being able to lawfully rely on LI as a lawful ground for processing.
4. Main Takeaways
The Report on Legitimate Interests under the LGPD published by Data Privacy Brasil and translated into English with support from FPF is a significant contribution to develop the theory and practice of the new data protection legal framework in Brazil. The launch of the English version of the Report prompted an engaging discussion that furthered the understanding of how LI should be applied in practice to take into account both the rights and interests of individuals on one hand, and the interests of controllers and third parties on the other hand. These are the key takeaways that emerged from the keynote and panel discussion:
All discussants agreed that LI should neither be the preferred nor the last option for legitimising processing of personal data. There is no hierarchy among the possible lawful grounds for processing.
It is crucial that data controllers understand what personal data they are processing and why they are processing that data. Having this clear, organizations can make the choice for the most appropriate legal ground, complying with the principle of accountability.
The principle of fairness should be central to the discussion on the LI ground. Along with reasonable expectations of the individuals, fairness should constitute the filter through which the decision to rely on LI must pass.
The obligation to perform a DPIA should not be attached to the choice of applying the LI ground as the appropriate legal basis. However, a legitimate interest assessment that follows the structure and reasoning of a proportionality test, should instead be performed.
More guidance from the ANPD is expected to clarify how the tests for lawfully relying on LI should be performed.
Navigating Preemption through the Lens of Existing State Privacy Laws
This post is the second of two posts on federal preemption and enforcement in United States federal privacy legislation. See Preemption in US Privacy Laws (June 14, 2021).
In drafting a federal baseline privacy law in the United States, lawmakers must decide to what extent the law will override state and local privacy laws. In a previous post, we discussed a survey of 12 existing federal privacy laws passed between 1968-2003, and the extent to which they are preemptive of similar state laws.
Another way to approach the same question, however, is to examine the hundreds of existing state privacy laws currently on the books in the United States. Conversations around federal preemption inevitably focus on comprehensive laws like the California Consumer Privacy Act, or the Virginia Consumer Data Protection Act — but there are hundreds of other state privacy laws on the books that regulate commercial and government uses of data.
In reviewing existing state laws, we find that they can be categorized usefully into: laws that complement heavily regulated sectors (such as health and finance); laws of general applicability; common law; laws governing state government activities (such as schools and law enforcement); comprehensive laws; longstanding or narrowly applicable privacy laws; and emerging sectoral laws (such as biometrics or drones regulations). As a resource, we recommend: Robert Ellis Smith, Compilation of State and Federal Privacy Laws (last supplemented in 2018).
Heavily Regulated Sectoral Silos. Most federal proposals for a comprehensive privacy law would not supersede other existing federal laws that contain privacy requirements for businesses, such as the Health Insurance Portability and Accountability Act (HIPAA) or the Gramm-Leach-Bliley Act (GLBA). As a result, a new privacy law should probably not preempt state sectoral laws that: (1) supplement their federal counterparts and (2) were intentionally not preempted by those federal regimes. In many cases, robust compliance regimes have been built around federal and state parallel requirements, creating entrenched privacy expectations, privacy tools, and compliance practices for organizations (“lock in”).
Laws of General Applicability. All 50 states have laws barring unfair and deceptive commercial and trade practices (UDAP), as well as generally applicable laws against fraud, unconscionable contracts, and other consumer protections. In cases where violations involve the mis-use of personal information, such claims could be inadvertently preempted by a national privacy law.
State Common Law. Privacy claims have been evolving in US common law over the last hundred years, and claims vary from state to state. A federal privacy law might preempt (or not preempt) claims brought under theories of negligence, breach of contract, product liability, invasions of privacy, or other “privacy torts.”
State Laws Governing State Government Activities. In general, states retain the right to regulate their own government entities, and a commercial baseline privacy law is unlikely to affect such state privacy laws. These include, for example, state “mini Privacy Acts” applying to state government agencies’ collection of records, state privacy laws applicable to public schools and school districts, and state regulations involving law enforcement — such as government facial recognition bans.
Comprehensive or Non-Sectoral State Laws. Lawmakers considering the extent of federal preemption should take extra care to consider the effect on different aspects of omnibus or comprehensive consumer privacy laws, such as the California Consumer Privacy Act (CCPA), the Colorado Privacy Act, and the Virginia Consumer Data Protection Act. In addition, however, there are a number of other state privacy laws that can be considered “non-sectoral” because they apply broadly to businesses that collect or use personal information. These include, for example, CalOPPA (requiring commercial privacy policies), the California “Shine the Light” law (requiring disclosures from companies that share personal information for direct marketing), data breach notification laws, and data disposal laws.
Congressional intent is the “ultimate touchstone” of preemption. Lawmakers should consider long-term effects on current and future state laws, including how they will be impacted by a preemption provision, as well as how they might be expressly preserved through a Savings Clause. In order to help build consensus, lawmakers should work with stakeholders and experts in the numerous categories of laws discussed above, to consider how they might be impacted by federal preemption.
Stanford Medicine & Empatica, Google and Its Academic Partners Receive FPF Award for Research Data Stewardship
The second-annual FPF Award for Research Data Stewardship honors two teams of researchers and corporate partners for their commitment to privacy and ethical uses of data in their efforts to research aspects of the COVID-19 pandemic. One team is a collaboration between Stanford Medicine researchers led by Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, and medical wearable and digital biomarker company Empatica. The other team is a collaboration between Google’s COVID-19 Mobility Reports and COVID-19 Aggregated Mobility Research Dataset projects, and researchers from multiple universities in the United States and around the globe.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award was established with the support of the Alfred P. Sloan Foundation, a not-for-profit grantmaking institution that supports high-quality, impartial scientific research and institutions.
The first of this year’s awards recognizes a partnership between a team from Stanford Medicine, consisting of Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from Stanford University’s School of Medicine’s Department of Genetics, and Empatica. The project studied whether data collected by Empatica’s researcher-friendly E4 device, which measures skin temperature, heart rate, and other biomarkers, could detect COVID-19 infections prior to the onset of symptoms.
To ensure the data sharing project minimized privacy risks, both teams took a number of steps including:
Establishing limits on the sharing and use of personal health information.
Using a researcher-friendly version of Empatica’s E4 device that prevents the collection of geolocation data, IP address, or mobile International Mobile Equipment Identity (IMEI) identifiers.
Using QR codes to link participants to specific wearable devices to ensure that participant names and study record IDs would not be shared.
The second award honors Google for its work to produce, aggregate, anonymize, and share data on community movement during the pandemic through its Community Mobility Report and Aggregated Mobility’ Research Dataset projects. Google’s privacy-driven approach was illustrated by the company’s collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. This group of researchers used the shared data from Google to assess the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories.
Google ensured the protection of this shared data in both projects by:
Anonymizing the Mobility Reports through differential privacy, which intentionally adds random noise to metrics in a manner that maintains both users’ privacy and the accuracy of the data.
Requiring that Google review all publications using these data sets to ensure the researchers describe the dataset and its limitations correctly, and that the researchers do not inadvertently re-identify any individual users.
Developing strict privacy protocols agreements and partner criteria for the Agg-epi dataset.
Google has been recognized with the second-annual FPF Award for Research Data Stewardship for its work to produce, aggregate, anonymize, and share data on community movement during the COVID-19 pandemic. Google’s Community Mobility Reports go through a robust anonymization process that employs differential privacy techniques to ensure that personal data, including an individual’s location, movement, or contacts, cannot be derived from the metrics, while providing researchers and public health authorities with valuable insights to help inform official decision making.
As part of their award submission, Google submitted details about an example research collaboration with researchers from Boston University, Harvard University, and Brown University, which evaluated the impacts of state-level policies on mobility and subsequent COVID-19 case trajectories. Ultimately, researchers found that states with mobility policies experienced substantial reductions in time people spent away from their places of residence. That was ultimately connected to decreases in COVID-19 case growth.
Google was also recognized for a related project – the Google COVID-19 Aggregated Mobility Research Dataset – centered around the same underlying anonymized data with small differences in the privacy protections and procedures used. For the purposes of this award, we have combined both Google projects to produce a series of considerations for future data-sharing projects.
“As the COVID-19 crisis emerged, Google moved to support public health officials and researchers with resources to help manage the spread,” said Dr. Karen DeSalvo, Chief Health Officer, Google Health. “We heard from the public health community that mobility data could help provide them an understanding of whether people were social distancing to interrupt the spread. Given the sensitivity of mobility data, we needed to deliver this information in a privacy preserving way, and we’re honored to be recognized by FPF for our approach.”
The Research Project
Since the beginning of the pandemic and during most of 2020, social distancing remained the primary mitigation strategy to combat the spread of COVID-19 in the United States.In responsetorequests from public health officials to provide aggregated, anonymized insights on community movement that could be used to make critical decisions to combat COVID-19, Google set up Community Mobility Reports to provide insights into what has changed in response to policies aimed at combating COVID-19. The reports chart movement trends over time by geography, across different categories of places such as retail and recreation, groceries, pharmacies, parks, transit stations, workplaces, and residential. To date, the aggregated, anonymized data sets have been heavily used for scientific research and economic analysis, as well as informing policy making by national and local governments and inter-governmental organizations.
Google’s approach to privacy was illustrated by the company’s collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. The researchers evaluated the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories using anonymized and aggregated mobility data from Google users who had opted-in to share their data for research. Then they correlated the decreases in mobility tied to state-level policies with changes in the number of reported COVID-19 cases. The project produced the following insights:
State-level emergency declarations resulted in a 9.9% reduction in time spent away from places of residence.
Implementation of one or more social distancing policies resulted in an additional 24.5% reduction in mobility the following week.
Subsequent shelter-in-place mandates yielded an additional 29% reduction in mobility.
Decreases in mobility were associated with substantial reductions in case growth two to four weeks later.
Google was also recognized for a related research project, the Google COVID-19 Aggregated Mobility Research Dataset. In addition to the COVID-19 Community Mobility Reports data, which were made publicly available online, this dataset was shared with specific, qualified researchers for the sole purpose of studying the effects of COVID-19. The research was shared with qualified individual researchers (those with proven track records in studying epidemiology, public health, or infectious disease) that accepted the data under contractual commitments to use the data ethically while maintaining privacy. Google was also able to share more detailed mobility data with these researchers while keeping strong mathematical privacy protections in place.
Data Protection Procedures and Processes in the Google COVID-19 Mobility Reports & Google COVID-19 Aggregated Mobility Research Dataset
Protocol Development, Partner Criteria, and Agreements. Given the sensitive nature of the data, Google developed strict, technical privacy protocols and stringent partner criteria for the Aggregated Mobility Research Dataset to determine how and with whom to share an aggregated version of the underlying data. Data sharing agreements were offered only to well-established non-governmental researchers with proven publication records in epidemiology, public health, or infectious disease, and the scope of research was limited to studying the effects of COVID-19.
Generating Anonymized Metrics. The anonymization process for the COVID-19 Mobility Reports involves differential privacy, a technical process that intentionally adds random noise to metrics in a way that maintains both users’ privacy and the overall accuracy of the aggregated data. Differential privacy represents an important step in the aggregation and anonymization process. The metrics produced through the differential privacy process are then used to assess relative percentage changes in movement behavior for each day from a baseline and those percentage changes are subsequently published by Google.
Aggregation of Data.The metrics are aggregated per day and per geographic area. There are three levels of geographic areas, referred to as granularity levels, including metrics aggregated by country or region (level 0), metrics aggregated by top-level geopolitical subdivisions like states (level 1), and metrics aggregated by higher-resolution granularity like counties (level 2).
Discarding Anonymized, but Geographically Attributable, Data. In addition to the privacy protections implemented through the differential privacy process, Google discards all metrics for which the geographic region is smaller than 3km2, or for which the differentially private count of contributing users (after noise addition) is smaller than 100.
Pre-Publication Review. Due to the sensitivity of the COVID-19 Aggregated Mobility Research Dataset, Google reviews all research involving this dataset prior to publication, including those without Google attribution. This is done to ensure that they describe the dataset and its limitations properly, and that researchers don’t use the dataset improperly, for example, by combining datasets that may lead to the re-identification of individual users.
Lessons for Future Data-Sharing Projects
Google’s COVID-19 Mobility Reports and Google COVID-19 Aggregated Mobility Research Dataset projects highlight a number of valuable lessons that companies and academic institutions may apply to future data sharing collaborations.
Develop Robust Partner Criteria. Upon launching the Google COVID-19 Aggregated Mobility Research Dataset project,Google established strict criteria for research partners outside of government in order to ensure that academic researchers are proven stewards of privacy-protective research with established records in epidemiology, public health, and/or infectious disease. By developing stringent protocols for their academic partners, Google worked to ensure that data is used responsibly and only for the study of the effects of COVID-19.
Consider Differential Privacy. Google’s COVID-19 Mobility Reports data sharing project employed differential privacy to provide mathematical assurances that no individual user data could be manually inspected, studied, or re-identified. The mathematical process that underlines the differential privacy process adds random noise to metrics in a manner that ensures both user privacy and the overall accuracy of the data, which are essential given the use cases of the data.
Share Aggregated Data. By aggregating data by day and geographic location, Google provided further assurances that location and behavior could not be attributed to any single individual, protecting their privacy while providing valuable insights to researchers and public health authorities. The Google team set a geographic threshold for aggregated data, such that data that has been aggregated into geographic regions smaller than 3km2 was discarded.
Tailor Formats & Privacy Protections to Your Audience. The team knew that mobility data could provide a variety of insights in different contexts. Rather than choosing a single application, they tailored their privacy protections to meet the needs of both a publicly available data set and one that could be shared under the terms of a specific agreement.
The Selection Process:
Nominees for the Award for Research Data Stewardship were judged by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. The Award Committee evaluated projects based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
FPF Issues Award for Research Data Stewardship to Stanford Medicine & Empatica, Google & Its Academic Partners
WASHINGTON, DC(June 29, 2021) – The second-annual FPF Award for Research Data Stewardship honors two teams of researchers and corporate partners for their commitment to privacy and ethical uses of data in their efforts to research aspects of the COVID-19 pandemic. One team is a collaboration between Stanford Medicine researchers led by Tejaswini Mishra, PhD, Professor Michael Snyder, PhD, and medical wearable and digital biomarker company Empatica. The other team is a collaboration between Google’s COVID-19 Mobility Reports and COVID-19 Aggregated Mobility Research Dataset projects, and researchers from multiple universities in the United States and around the globe.
“Researchers rely on data to find solutions to the challenges facing our society, but data must only be shared and used in a way that protects individual rights,” said Jules Polonetsky, CEO of the Future of Privacy Forum. “The teams at Stanford Medicine, Empatica, and Google employed a variety of techniques in their research to ensure data was used ethically – including developing strong criteria for potential partners, aggregating and anonymizing participant data, discarding data sets at risk of being re-identified, and conducting extensive ethics and privacy reviews.”
The FPF Award for Research Data Stewardship was established with the support of the Alfred P. Sloan Foundation, a not-for-profit grantmaking institution that supports high-quality, impartial scientific research and institutions.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award highlights companies and academics who demonstrate novel best practices and approaches to sharing corporate data in order to advance scientific knowledge.
Stanford Medicine and Empatica Partnership
Smartwatches and other wearable devices that continuously measure biometric data can provide “digital vital signs” for the user. Dr. Mishra’s team, consisting of Dr. Michael Snyder, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from the Stanford University School of Medicine’s Department of Genetics, received anonymized data from Empatica’s E4 wristband, including data on participants’ skin temperature, heart rate, and electrodermal activity. This data was collected by the Stanford Medicine team to study whether it could be used to detect COVID-19 infections prior to the onset of symptoms. To ensure that this data sharing project minimized potential privacy risks, both Empatica and the Stanford Medicine team took a number of steps, including:
Establishing limits on the sharing and use of personal health information.
Using a researcher-friendly device, Empatica’s E4, that prevents the collection of geolocation data, IP address, or mobile International Mobile Equipment Identity (IMEI) identifiers.
Using QR codes to link participants to specific wearable devices to ensure that participant names and study record IDs would not be shared.
“A large part of our job is to embed research and its results into products that will improve people’s lives.” Said Matteo Lai, CEO of Empatica, “Patients are always at the center of this endeavor, and so naturally are their needs: privacy, a great experience, a sense of safety, high quality are all part of our responsibility. We are honored that this approach and care is recognized as something to strive for.”
The research project is ongoing.
Google’s Community Mobility Information
Google has also been recognized with the second-annual FPF Award for Research Data Stewardship for its work to produce, aggregate, anonymize, and share data on community movement during the COVID-19 pandemic. In response to requests from public health officials, Google created Community Mobility Reports (CMRs) to provide aggregated, anonymized insights into how community mobility has changed in response to policies aimed at combating COVID-19. To ensure that personal data, including an individual’s location, movement, or contacts, cannot be derived from the metrics, the data included in Google’s CMRs goes through a robust anonymization process that employs differential privacy techniques while providing researchers and public health authorities with valuable insights to help inform official decision-making.
Google is also being recognized for a related project, the Aggregated Mobility Research Dataset. In addition to the COVID-19 CMR data, which were made publicly available online, this dataset was shared with specific qualified researchers for the sole purpose of studying the effects of COVID-19. The research was shared with qualified individual researchers (those with proven track records in studying epidemiology, public health, or infectious disease) that accepted the data under contractual commitments to use the data ethically while maintaining privacy. Google was also able to share more detailed mobility data with these researchers, while keeping strong mathematical privacy protections in place. Examples of research that utilized Google’s Aggregated Mobility Research Dataset include:
Hierarchical organization of urban mobility and its connection with city livability
Examining COVID-19 forecasting using spatio-temporal graph neural networks
“As the COVID-19 crisis emerged, Google moved to support public health officials and researchers with resources to help manage the spread,” said Dr. Karen DeSalvo, Chief Health Officer, Google Health. “We heard from the public health community that mobility data could help provide them an understanding of whether people were social distancing to interrupt the spread. Given the sensitivity of mobility data, we needed to deliver this information in a privacy preserving way, and we’re honored to be recognized by FPF for our approach.”
Google ensured the protection of this shared data in both projects by:
Anonymizing the Mobility Reports through differential privacy, which intentionally adds random noise to metrics in a manner that maintains both users’ privacy and the accuracy of the data.
Organizing information by trips taken to different types of locations, rather than providing data about granular geographic areas to protect community privacy
Requiring that Google review all publications using the Aggregated Mobility Research Dataset to ensure the researchers describe the dataset and its limitations correctly
Developing strict privacy protocols agreements and partner criteria for the Aggregated Mobility Research Dataset.
Google’s privacy-driven approach was illustrated by the company’s direct collaboration with Prof. Gregory Wellenius, Boston University School of Public Health’s Department of Environmental Health, Dr. Thomas Tsai, Brigham and Women’s Hospital Department of Surgery and Harvard T.H. Chan School of Public Health’s Department of Health Policy and Management, and Dr. Ashish Jha, Dean of Brown University’s School of Public Health. The researchers evaluated the impacts of specific state-level policies on mobility and subsequent COVID-19 case trajectories using anonymized and aggregated mobility data from Google users who had opted-in to share their data for research. The shared data resulted in an academic paper which will be published in Nature Communications. The project found that state-level emergency declarations resulted in a 9.9% reduction in time spent away from places of residence, with the implementation of social distancing policies resulting in an additional 24.5% reduction in mobility the following week, and shelter-in-place mandates yielding a further 29% reduction in mobility. Notably, these decreases in mobility were associated with significant reductions in reported COVID-19 cases two to four weeks later.
Research from Stanford Medicine and Empatica, Inc: Early Detection of COVID-19 Using Empatica Smartwatch Data
Tejaswini Mishra, PhD, Michael Snyder, PhD, Erika Mahealani Hunting, Alessandra Celli, Arshdeep Chauhan, and Jessi Wanyi Li from the Stanford University School of Medicine’s Department of Genetics, and Empatica Inc. are the recipients of the second-annual FPF Award for Research Data Stewardship. The collaboration between the research team from Stanford Medicine and Empatica, a medical wearable and digital biomarker company, assessed whether wearable devices could be used to detect COVID-19 infections prior to the onset of symptoms, producing valuable insights that have the potential to change how we monitor and address the spread of infectious diseases.
Robust privacy protections built into the project – including setting clear limits on the sharing and use of data, a third-party ethics review, the use of specially-designed research devices, and a comprehensive assessment of privacy and security practices and risks – ensured that individuals’ health information remained private throughout the data sharing and research process.
“A large part of our job is to embed research and its results into products that will improve people’s lives.” Said Matteo Lai, CEO of Empatica, “Patients are always at the center of this endeavor, and so naturally are their needs: privacy, a great experience, a sense of safety, high quality are all part of our responsibility. We are honored that this approach and care is recognized as something to strive for.”
The Research Project
Wearable devices such as consumer smartwatches continuously measure biometric data, including heart rate and skin temperature, that can act as “digital vital signs” informing the wearer about their health status.The collaboration between the research team at Stanford University, led by Michael Snyder, professor and chair of genetics, and Empatica, Inc, explored whether data from wearable devices can be used to detect COVID-19 infections prior to the onset of symptoms. To study whether digital health data from the Empatica E4 Wristband could be used to identify the onset of COVID-19, researchers received skin temperature, electrodermal activity, heart rate, and accelerometer data collected by wristbands worn by 148 study participants for 30 consecutive days. Additionally, researchers received usage compliance metrics for each participant in order to ensure participant compliance with approved study protocol. The research project is ongoing.
Data Protection Procedures and Processes in the research by Stanford Medicine and Empatica Inc.
Establish Limits on Sharing & Use of personal health information (PHI) Data. As part of its legally binding collaboration agreement, Stanford Medicine limited the Stanford PHI data shared with Empatica to COVID-19 test dates and results. Furthermore, Stanford arranged for COVID-19 lab test reporting to be delivered directly to the School of Medicine, without allowing PHI access to Empatica, even though the company paid for the COVID-19 tests.
Ethics Review. During the launch process, the Stanford and Empatica teams developed a research ethics protocol for submission to the Stanford University Institutional Review Board (IRB). The ethics protocol was approved by the Stanford IRB.
Assessment of Privacy & Security Practices. Stanford employed QR codes to link specific participants with specific wearable device serial numbers, such that participant identifiers including names and study record IDs, which are usually sequential, were not shared with Empatica.
Privacy & Security Risk Assessment. Researchers at Stanford and Empatica assessed potential security risks that could arise through their collaboration by initiating a Data Risk Assessment (DRA) by the Stanford University Privacy office (SUPO) to examine the systems set up by Empatica for privacy and security. Empatica readily provided all of the required materials and SUPO certified the project as “low risk.”
Privacy-Protective Research Tools. The project used “researcher version” Empatica devices for the study, which have privacy-enhanced functionality that prevents the Empatica mobile app from collecting geolocation data, IP address, or International Mobile Equipment Identifiers (IMEI). Additionally, Stanford employed QR codes to link specific participants with specific wearable device serial numbers to ensure that participant identifiers, including names and study record IDs, were not shared with Empatica.
Lessons for Future Data-Sharing Projects
The data-sharing collaboration between the research team at Stanford Medicine and Empatica highlights a number of valuable lessons that companies and academic institutions may apply to future data-sharing collaborations.
Work the Process. Empatica and the research team at Stanford Medicine established a clear process to obtain necessary approvals and maintain privacy protections throughout the research collaboration, including a comprehensive Data Risk Assessment, Institutional Review Board (IRB) review, and legal review processes. The research team at Stanford Medicine worked diligently to ensure that they adhered to all plans, processes, and frameworks throughout the research collaboration.
Use Technology to Enhance Privacy. The Stanford research team and Empatica took advantage of technology, where possible, to promote privacy throughout the project. Stanford employed QR codes to prevent the need to share participant identifiers, including names and study record IDs, with Empatica.
Use Privacy-Protective Research Tools. The project used Empatica’s special “researcher version” wearable devices for the study, which include privacy-enhanced functionality to prevent the Empatica mobile app from collecting unnecessary data that could negatively impact study participants’ privacy. Furthermore, Empatica’s devices store and transmit data in an encrypted manner, ensuring that participants’ data could not be accessed by unintended users.
Collaborate Constantly & Responsibly. Empatica and Stanford researchers maintained active communication throughout the study, including weekly meetings to assess the progression of their collaboration, as well as any issues or needs related to their research project. Empatica team members have proactively offered to leave meetings to avoid PHI being shared with them or discussed in their presence, even accidentally.
The Selection Process
Nominees for the Award for Research Data Stewardship were judged by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. The Award Committee evaluated projects based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
FPF Partners with Penn State and University of Michigan Researchers on Searchable Database of Privacy-Related Documents
FPF is collaborating with a team of researchers to build a searchable database of privacy policies and other privacy-related documents. The PrivaSeer project, led by researchers from Penn State and the University of Michigan, has received a $1.2 million grant from the National Science Foundation (NSF) to ease the process of collecting and utilizing privacy documents and privacy-related data.
FPF Director for Global Privacy Dr. Gabriela Zanfir-Fortuna will serve as a co-principal investigator, a first for FPF on an NSF-funded project. Dr. Zanfir-Fortuna’s expertise includes work on global privacy developments and European data protection law and policy, with a focus on de-identification, AI, mobility, ad tech, and education.
The other co-principal investigators in this project include: Dr. Shomir Wilson and Dr. Lee Giles from Penn State University, and Dr. Florian Schaub from the University of Michigan.
PrivaSeer will function as a searchable database that allows researchers to perform a host of tasks like collecting, exploring, and evaluating privacy documents such as privacy policies, terms of service agreements, cookie policies, privacy bills and laws, and regulatory guidelines.
The search engine employs Natural Language Processing (NLP), a type of artificial intelligence that is able to process large quantities of data through a combination of linguistics, AI programming, and computer science.
“One of the reasons to have a privacy policy search engine is that you can get an idea about how different companies treat their user privacy currently and over time. This can also inform users on how they may want to react to those companies.”
C. Lee Giles, the David Reese Professor of Information Sciences and Technology, Penn State & PrivaSeer Project co-principal investigator
The search engine will provide researchers insights on privacy policy trends and enable researchers to easily and securely access relevant privacy documentation online. Previous research on privacy policies has encountered issues surrounding access to suitable privacy data. PrivaSeer will help researchers navigate this problem and allow for large-scale interpretation of privacy data.
View Penn State University’s Institute for Computational and Data Sciences’ statement here.
Manipulative Design: Defining Areas of Focus for Consumer Privacy
In consumer privacy, the phrase “dark patterns” is everywhere. Emerging from a wide range of technical and academic literature, it now appears in at least two US privacy laws: the California Privacy Rights Act and the Colorado Privacy Act (which, if signed by the Governor, will come into effect in 2025).
Under both laws, companies will be prohibited from using “dark patterns,” or “user interface[s] designed or manipulated with the substantial effect of subverting or impairing user autonomy, decision‐making, or choice,” to obtain user consent in certain situations–for example, for the collection of sensitive data.
When organizations give individuals choices, some forms of manipulation have long been barred by consumer protection laws, with the Federal Trade Commission and state Attorneys General prohibiting companies from deceiving or coercing consumers into taking actions they did not intend or striking bargains they did not want. But consumer protection law does not typically prohibit organizations from persuading consumers to make a particular choice. And it is often unclear where the lines fall between cajoling, persuading, pressuring, nagging, annoying, or bullying consumers. The California and Colorado laws seek to do more than merely bar deceptive practices; they prohibit design that “subverts or impairs user autonomy.”
What does it mean to subvert user autonomy, if a design does not already run afoul of traditional consumer protections law? Just as in the physical world, the design of digital platforms and services always influences behavior — what to pay attention to, what to read and in what order, how much time to spend, what to buy, and so on. To paraphrase Harry Brignull (credited with coining the term), not everything “annoying” can be a dark pattern. Some examples of dark patterns are both clear and harmful, such as a design that tricks users into making recurring payments, or a service that offers a “free trial” and then makes it difficult or impossible to cancel. In other cases, the presence of “nudging” may be clear, but harms may be less clear, such as in beta-testing what color shades are most effective at encouraging sales. Still others fall in a legal grey area: for example, is it ever appropriate for a company to repeatedly “nag” users to make a choice that benefits the company, with little or no accompanying benefit to the user?
In Fall 2021, Future of Privacy Forum will host a series of workshops with technical, academic, and legal experts to help define clear areas of focus for consumer privacy, and guidance for policymakers and legislators. These workshops will feature experts on manipulative design in at least three contexts of consumer privacy: (1) Youth & Education; (2) Online Advertising and US Law; and (3) GDPR and European Law.
As lawmakers address this issue, we identify at least four distinct areas of concern:
Designs that cause concrete physical or financial harms to individuals. In some cases, design choices are implicated in concrete physical or financial harms. This might include, for example, a design that tricks users into making recurring payments, or makes unsubscribing from a free trial or other paid service difficult or impossible, leading to unwanted charges.
Designs that impact individual autonomy or dignity (but do not necessarily cause concrete physical or financial harm). In many cases, we observe concerns over autonomy and dignity, even where the use of data would not necessarily cause harm. For the same reasons that there is wide agreement that so-called subliminal messaging in advertising is wrong (as well as illegal), there is a growing awareness that disrespect for user autonomy in consumer privacy is objectionable on its face. As a result, in cases where the law requires consent, such as in the European Union for placement of information onto a user’s device, the law ought to provide a remedy for individuals who have been subject to a violation of that consent.
Designs that persuade, nag, or strongly push users towards a particular outcome, even where it may be possible for users to decline. In many cases, the design of a digital platform or serviceclearlypushes users towards a particular outcome, even if it is possible (if burdensome) for users to make a different choice. In such cases, we observe a wide spectrum of tactics that may be evaluated differently depending on the viewer and the context. Repeated requests may be considered “nagging” or “persuasion”; one person’s “clever marketing,” taken too far, becomes another person’s “guilt-shaming” or “confirm-shaming.” Ultimately, our preference for defaults (“opt in” versus “opt out”), and within those defaults, our level of tolerance for “nudging,” may be driven by the social benefits or values attached to the choice itself.
Designs that exploit biases, vulnerabilities, or heuristics in ways that implicate broader societal harms or values. Finally, we observe that the collection and use of personal information does not always solely impact individual decision-making. Often, the design of online platforms can influence groups in ways that impact societal values, such as the values of privacy, avoidance of “tech addiction,” free speech, the availability of data from or about marginalized groups, or the proliferation of unfair price discrimination or other market manipulation. Understanding how design choices may influence society, even if individuals are minimally impacted, may require examining the issues differently.
This week at the first edition of the annual Dublin Privacy Symposium, FPF will join other experts to discuss principles for transparency and trust. The design of user interfaces for digital products and services pervades modern life and directly impacts the choices people make with respect to sharing their personal information.
ITPI Event Recap – The EU Data Strategy and the Draft Data Governance Act
On May 19, 2021, the Israel Tech Policy Institute (ITPI), an Affiliate of The Future of Privacy Forum (FPF), hosted, together with the Tel Aviv University, The Stewart & Judy Colton Law and Innovation Program, an online event on the European Union’s (EU) Data Strategy and the Draft Data Governance Act (DGA).
The draft DGA is one of the proposed legislative measures for implementing the European Commission’s 2020 European Strategy for Data (EU Data Strategy), whose declared goal is to give the EU a “competitive advantage” by enabling it to capitalise on its vast quantity of public and private sector-controlled data. The DGA will establish a framework for using more data held by the public sector, regulating and increasing trust in data intermediaries and similar service providers that provide data sharing services, and data altruism (i.e., data voluntarily made available by individuals or companies for the “general interest”).
While speakers also addressed other proposals tabled by the European Commission (EC) for regulating players in the data economy – such as the Digital Services Act (DSA) and the Digital Markets Act (DMA) -, most of the discussion revolved around the DGA’s expected impact and underlying policy drivers.
Both Prof. Assaf Hamdani, from the Tel Aviv University’s Law Faculty, and Limor ShmerlingMagazanik, Managing Director at ITPI, assumed moderating roles during the event, which counted on the input of speakers from the EC, the Massachusetts Institute of Technology (MIT), Covington & Burling LLP, Mastercard and the Israeli Government’s ICT Authority.
Maria Rosaria Coduti, Policy Officer at the EC’s Directorate-General for Communications Networks, Content and Technology (DG CNECT), started by outlining the factors that drove the EC to put forward the EU Data Strategy. As the EC acknowledges the potential of data usage for the benefit of society, it intends to harness it through bolstering the functioning of the single market for data, with due regard to privacy, data protection and competition rules.
To attain that goal, there were questions that needed to be addressed to increase the trust in the exchange of such data. Those included a lack of clarity on the legal and technical requirements applicable to the re-use of data and the sharing of data by public bodies, as well as the creation of European-based data storage solutions. On the other hand, the EC also identified the need of further empowering data subjects through voluntary data sharing, as a complement to their data portability right under the General Data Protection Regulation (GDPR).
According to the EC official, the EU Data Strategy rests on 4 main pillars: 1) a cross-sectoral governance framework for boosting data access and use; 2) significant investments in European federated cloud infrastructures and interoperability; 3) empowering individuals and SMEs in the EU with digital skills and data literacy; 4) the creation of common European Data Spaces in crucial sectors and public interest domains, through data governance and practical arrangements.
The DGA itself, which intends to create trust in and democratise the data sharing ecosystem, also focuses on four main aspects: 1) the re-use of sensitive public sector data, by addressing “obstacles” to data sharing, complementing the EU’s Open Data Directive – together with an upcoming Implementing Act on High-Value Datasets under Article 14 of that Directive – and building on Member-States’ access regimes; 2) business-to-business (B2B) and consumer-to-business (C2B) data sharing through dedicated, neutral and duly notified service providers (“data intermediaries”); 3) data altruism, enabling individuals to share their personal data for the common good with registered non-profit dedicated organisations, notably through signing a standard to-be-developed European data altruism broad consent form; 4) the European Data Innovation Board, which shall be an expert group with EC secretariat, focused on technical standardisation and on harmonising practices around data re-use, data intermediaries and data altruism.
Specifically on the topic of data intermediaries, and replying to questions from the audience, Maria Rosaria Coduti mentioned the importance of ensuring they remain neutral. This entails that intermediaries should not be allowed to process the data they are entrusted with for their own purposes. In this respect, Recital 22 of the draft DGA excludes cloud service providers, and entities which aggregate, enrich or transform the data for subsequent sale (e.g., data brokers) from its scope of application.
It should be noted that the third Compromise Text released by the Portuguese Presidency of the Council of the EU opens the possibility for intermediaries to use the data for service improvement, as well as to offer “specific services to improve the usability of the data and ancillary services that facilitate the sharing of data, such as storage, aggregation, curation, pseudonymisation and anonymisation.”
Coduti underlined the importance of preventing any conflicts of interest for intermediaries. Data sharing services must thus be rendered through a legal entity separate from the other activities of the intermediary, notably when the latter is a commercial company. This would, in principle, mean that legal entities acting as intermediaries under the DGA would not be covered by the proposed DSA as hosting service providers, nor as “gatekeepers” under the DMA proposal. Ultimately, the EC wishes intermediaries to flourish, by becoming a trusted player and a valuable tool for businesses and individuals in the data economy.
The upcoming Data Act: facilitating B2B and B2G data sharing
Lastly, the EC official briefly addressed the upcoming EU Data Act. In parallel with the revision of the 25-year old Database Directive, this piece of legislation will focus on Business-to-Business (B2B) and business-to-government (B2G) data sharing. Its aim will be to maximise the use of data for innovation in different sectors and for evidence-based policymaking, without harming the interests of companies that invest in data generation (e.g., companies that produce smart devices and sensors).
While the Data Act will not address the issue of property rights over data, it will seek to strike down contractual and technical obstacles to data sharing and usage in industrial ecosystems (e.g., in the mobility, health, energy and agricultural spaces). Coduti stressed that the discussion around data ownership is complex, due to the proliferation of data obtained from IoT devices and the emergence of edge computing, as well as the necessary balance between keeping utility of datasets and safeguarding data subjects’ rights through anonymisation.
On the latter point, Rachel Ran, Data Policy Manager at the Israeli Government ICT Authority, echoed Coduti’s concerns, stating that data cannot be universally open. According to the Israeli official, there is a tradeoff between data utility and individual privacy that has to be accepted, but questions remain about the level of involvement that governments should have in determining this balance.
An increasingly complex digital regulatory framework in the EU
Henriette Tielemans, IAPP Senior Westin Research Fellow, offered a comprehensive overview of the EC’s data-related legislative proposals which were tabled in the last six months, other than the DGA. The trilogue work currently underway in the EU institutions on the proposed ePrivacy Regulation was also mentioned.
In the context of its Strategy for Artificial Intelligence (AI), the EC has very recently published a proposal for a Regulation laying down harmonised rules on AI. Tielemans saw this proposal as important and groundbreaking, suggesting that the EC is looking to set standards also beyond EU borders, like it did with the GDPR. She stressed that the proposal takes a cautious risk-based approach.
Tielemans highlighted the proposal’s dedicated provision (Article 5) on banned AI practices, arguing that the most contentious amongst those should be real-time remote biometric identification for law enforcement purposes in public spaces. However, she noted that the paragraph contained wide exceptions to the prohibition, allowing law enforcement authorities to use facial recognition in that context, subject to conditions. Tielemans predicted that the provision will be a “hot potato” during the Regulaiton’s negotiations, notably within the Council of the EU.
Furthermore, Tielemans stressed that “high-risk AI systems”, which are the major focus of the proposal, are not defined thereunder, as the EU intends to ensure the Regulation is future-proof. However, Annex III forwards a provisional list of high-risk AI systems, like systems used for educational and vocational training (e.g., to determine who will be admitted to a given school). Annex II is more complex, due to the interaction with other EU acts: if there are products subject to a third-party conformity assessment (under other EU laws) where the provider would like to integrate an AI component, that would be considered high-risk AI. Tielemans also noted that, once a system is qualified as high-risk, then providers acquire a number of obligations on training models, record keeping, among others.
On the DSA, Tielemans pointed out that the proposal is geared towards providers of online intermediary services. It provides rules on the liability of providers for third-party content and how they should conduct content moderation. In principle, she stressed, such providers shall not be liable for information which is conveyed or stored through their services, although they are burdened with takedown – but no general monitoring – obligations. The proposal distinguishes between different types of providers, with their respective obligations matching their role and their degree of importance in the online ecosystem. Hosting service providers have less obligations than online platforms, and the latter less so than very large ones: a sort of obligation “cascade”.
Lastly, Tielemans concisely mentioned the DMA and the revised Directive on Security of Network and Information Systems (NIS 2 Directive) as other noteworthy EC initiatives, identifying the former as a competition law toolbox and an “outlier” in the EU Data Strategy. She also pinpointed the latter’s broader scope, increased oversight and heavier penalties as important advances in the EU’s cybersecurity framework.
Reconciling “overarching” with “sectoral” regulation on data sharing
Helena Koning, Assistant General Counsel, Global Privacy Compliance Assurance & Europe Data Protection Officer at Mastercard, provided some thoughts about the draft DGA’s potential impact on the financial industry.
She started by outlining the actors involved in the data sharing ecosystem. These include: (i) individuals, who demand data protection and responsible use of data; (ii) businesses, that wish to innovate through data usage and insights drawn from data, notably by personalising their products and services; (iii) policymakers, who increasingly regulate data usage; and (iv) regulators with bolstered enforcement powers in this space.
Then, Koning stressed that companies in the financial sector are currently subject to a significant regulatory overlap when it comes to data collection and sharing, with the ePrivacy Directive applying to terminal equipment information, GDPR applying to personal data in general and the Second Payment Services Directive (PSD2) covering payment data sharing. While there is already guidance by the European Data Protection Board (EDPB) on the interplay between the GDPR and PSD2, Tielemans added that lawmakers tend to regulate in siloes, adopting overlapping and sometimes conflicting definitions and obligations. This results in financial sector players being pushed to wear very different hats under each framework (e.g. payment service providers and data controllers). In this regard, Tielemans said that the EC should place further efforts in ensuring consistency between EU acts before proposing new legislation.
Koning showed concern that instruments such as the DGA and the Data Act will add to this regulatory complexity and that SMEs and citizens will have a hard time complying with and understanding the new laws. On this point, she addressed the fact that the DGA and PSD2 have diverging models for fostering data-based innovation: as an illustration, while PSD2 mandates banks to share customer data with fintechs, free of charge and upon the customer’s contractual consent, the DGA centres around voluntary data sharing, for which public bodies may charge fees and data subjects are called to give GDPR-aligned consent.
Furthermore, Koning expressed doubts about the immediate benefit that data holders and subjects would get from sharing their data with intermediaries, often in exchange of service fees.
Alternatives to data sharing and focus on data insights
Dr. Thomas Hardjono,from MIT Connection Science & Engineering, develops research on using data to better understand and solve societal issues, including the spread of diseases and addressing inequality. Hardjono started by congratulating the direction taken by the EC with the DGA, stating that his group at MIT had been studying issues relating to commoditization of personal data since the publication of a 2011 World Economic Forum report. In Hardjono’s view, public data is a societal asset that should be treated as carefully and comprehensively as personal data.
On that point, Rachel Ranmentioned that governments should seek to encourage data sharing through data governance and to centre their policies around the needs of data subjects. She added that data products – like Application Programming Interfaces (APIs) – should be human-centered. Data should be seen as a product, but not a commodity, especially when it comes to sharing government data.
Ran continued by describing one of the Israeli ICT Authority’s major projects: creating standard APIs for G2G and G2B data sharing. But there are significant challenges to such tasks, including: (i) unstructured and fragmented data; (ii) duplicated records and gaps; and (iii) inconsistent data formats and definitions. This ultimately leads to suboptimal decision-making by government bodies, given they are not properly informed by accurate and updated data.
About data sharing services, Hardjono stated that data intermediaries regulated under the DGA may face specific hurdles, notably on the level of intelligibility of data conveyed to data users. There are questions on whether the draft DGA’s prohibition on intermediaries to aggregate and structure data could prevent them from developing services which are interesting for potential data users. Koning added that a number of data sharing collaborations are already in place and that new EU regulation should facilitate rather than prevent them.
On that topic, Hardjono mentioned communities would be more interested in accessing insights and statistics about their citizens’ activity (e.g., on transportation, infrastructure usage and spending patterns), rather than large sets of raw data. On the other hand, aggregated data could be publicly shared with the wider society.
As a solution, Hardjono proposed developing and making available Open Algorithms, allowing data users (e.g., a municipality) to access specific datasets of their interest and to directly ask questions to and obtain insights from data holders about such datasets, through APIs. This would also avoid moving the data around, by keeping it with data holders.
Then another question arises, according to Hardjono: given the commercial value of data insights, there should be business incentives, possibly via fair remuneration, to gather, structure and analyze the data. In that context, Hardjono stressed that clarifying the intermediaries’ business model is crucial and should be addressed by the DGA. He also suggested that a joint remuneration model, shared between the public sector and data users, could be devised. Moreover, this leads to novel doubts about data ownership, notably about who owns the insights (the holder or the intermediary?) and on what title: could they be considered as the provider’s intellectual property?
Upon the observation from Prof. Assaf Hamdani that some cities are now imposing or incentivising companies and citizens to share data through administrative procedures and contracts, Hardjono regretted that the DGA did not devote enough attention to so-called data cooperatives. While Article 9(1)(c) of the DGA does offer a description of the services that data cooperatives should offer to data subjects and SMEs (including assisting them in negotiating data processing terms), there is an extensive academic discussion in the US about other roles these cooperatives could play in defending citizens’ interests, that could feed into the DGA debates. On the issue of data cooperatives, Ran held that such cooperatives should address data subjects’ needs and share data for a specified purpose, praising the DGA model in that regard.
Lastly, Hardjono highlighted the fact that certain datasets may have implicit bias and that algorithms used to analyze such data may thus be implicitly biased. Therefore, he held that ensuring algorithmic auditing and fairness is key to achieving good societal results from the usage of the large volumes of data at the relevant players’ disposal.
Ran added that, besides trustworthy, data should also be discoverable, interoperable (with common technical standards) and self-describing, to facilitate its sharing and ensure its usefulness.
As federal lawmakers consider proposals for a federal baseline privacy law in the United States, one of the most complex challenges is federal preemption, or the extent to which a federal law should nullify the state laws on the books and the emerging laws addressing the collection and use of personal information.
Many recognize the benefits to businesses and consumers of establishing uniform national standards for the collection, transfer, and sale of commercial personal information, if those standards are strong and flexible enough to meet new challenges that arise. Such standards will require, to at least an extent, replacing individual state efforts. At the same time, however, there are hundreds of state privacy laws on the books. Many of these laws have a uniquely local character, such as laws governing student records, medical information, and library records. Preemption only becomes more complicated as additional states join recent leaders such as Virginia, California, and Colorado, to pass omnibus data privacy laws that apply to data collected across borders from websites, apps, and other digital services.
What can we learn from how existing federal privacy laws have addressed preemption? As a starting point, FPF staff have surveyed twelve (12) federal sectoral privacy laws passed between 1968-2003, and examined the extent to which they preempt similar state privacy laws. A comprehensive consumer privacy law would almost certainly preserve most of these sectoral laws and their state counterparts. They provide a useful insight into how Congress has addressed federal preemption in the past.
In surveying these 12 federal privacy laws, we observe a few notable features, and offer some thoughts (below) on what factors have influenced Congressional decisions about preemption:
Preemption is Not Binary. Federal preemption is not an “all or nothing,” or even a “floor or ceiling” feature of US laws. All federal laws in the United States preempt directly conflicting state and local laws, under the U.S. Constitution’s supremacy clause (Art. VI.2). Beyond direct conflicts, however, it is entirely up to Congress to decide the extent to which state laws will be permitted to complement the many different aspects of a federal framework. Thus, some laws preempt regulations over particular subject matters (FCRA); some preempt certain procedural standards while allowing local prohibitions or requirements for local conduct (TCPA); some establish federal minimum standards, while explicitly allowing a conflicting state law to supersede federal law in narrow circumstances (FERPA); some prohibit only “inconsistent” legal liability (COPPA); while still others establish fully preemptive, detailed and prescriptive regulations in which the federal government dominates a field (Cable Act). See the Discussion Draft for analysis of each law. There are many compliance factors that likely influence the case-by-case decisions Congress has made, which we discuss below.
Preemption of Definitions. At least one law (FCRA) establishes a preemptive national definition of a key term (“firm offer of credit or insurance”). FCRA provides that even in cases where a state law goes beyond federal requirements, the state is bound to use the federal definition of a key term, even in the interpretation of the state law provisions.
Agency Involvement. Several federal privacy laws explicitly authorize a relevant governing federal agency to make decisions regarding preemption of state laws, or to respond to petitions for clarification on whether a state law is preempted. For example, the HIPAA Privacy Rule contains detailed requirements for petitioners to request that a state law be expressly preserved from preemption by the Secretary of Health and Human Services. Similarly, the FCC has received numerous petitions over the years to clarify whether state telemarketing laws are preempted by TCPA. In other cases, an agency has weighed in less formally, such as when the FTC argued in an amicus brief that COPPA does not preempt state protections for teenagers. Based on this precedent, it is clear that a relevant federal agency can play a key role in assisting with challenging preemption decisions.
Factors Influencing Preemption Decisions
Given the case-by-case variability described above and in the Discussion Draft, what determines when and how Congress has chosen to preempt state and local regulations that overlap or supplement federal privacy laws?
Congress is a political body, and politics surely play a role. But our analysis suggests that Congress pursues an overall goal of balancing individual rights with practical business compliance. We suggest that Congress pursues those goals by weighing several factors aside from political considerations. This likely include, for example: (1) the existence of national consensus on harmful business practices (versus expected regional variation in what is considered harmful); (2) the comprehensiveness or prescriptive nature of the law; (3) the national versus localized nature of business practices; and (4) the localized nature of data (which is sometimes, but not always, related to identifiability of data).
For example, a key difference between the federal commercial emailing law, CAN-SPAM (very preemptive), and the federal commercial telemarketing law, the Telephone Consumer Protection Act (not preemptive except with respect to certain inter-state standards) is the relative ease with which the personal data being regulated can be localized, or have its geographic location readily inferred. Email addresses, despite being personal information, give no indication of the owner’s location, while residential phone numbers were straightforward to relate to a particular state when the law was drafted in 1991.
Thus, while differing state telemarketing laws can present compliance costs for marketing companies operating across state lines, such laws do not create impractical barriers to compliance. In addition, telemarketing represents an issue on which there may be much more regional variation than national consensus on appropriate local business practices: for example, some states ban political calls, some ban calls during certain times of day, and some maintain additional do-not-call registries (such as Texas’s do-not-call registry for businesses, to allow them to avoid commercial calls from electricity providers).
As a contrasting example, the Fair Credit Reporting Act (largely preemptive), in 1970 represented a strong national consensus on appropriate business practices applicable primarily to three dominant credit bureaus in the United States, all operating effectively nationwide. At the same time, credit reports are involved in relatively localized business practices and involve identifiable information from which location can usually be inferred (e.g. from home addresses). As a result, business compliance with different state standards may not have been impossible, but was perhaps, ultimately, not desirable due to the comprehensive and prescriptive nature of the law and the relative national consensus on appropriate norms for credit bureaus.
These factors are just some of the myriad considerations that we suggest may influence preemption decisions for a federal privacy law, if the goal is to balance consumer privacy interests against concerns about practical business compliance. Further research might include, for example, a review of Congressional histories, or learning from other, non-privacy federal laws. We welcome feedback on the Discussion Draft.