If You Can't Take the Heat Map: Benefits & Risks of Releasing Location Datasets
Strava’s location data controversy demonstrates the unique challenges of publicly releasing location datasets (open data), even when the data is aggregated.
This weekend, the Washington Post reported that an interactive “Global Heat Map,” published by fitness data company Strava, had revealed sensitive information about the location and movements of servicemen and women in Iraq, Syria, and other conflict zones. The data in Strava’s Global Heat Map originates from individual users’ fitness tracking data, although the company took steps to de-identify and aggregate the information. The resulting controversy has highlighted some of the serious privacy challenges of publicly releasing open data sets, particularly when they are based on sensitive underlying information (in this case, geo-location).
Until recently, almost all conversations around open data related to the risks of re-identification, or the possibility that individual users might be identified from within an otherwise anonymous dataset. The controversy around Strava demonstrates clearly that risks of open data can go far beyond individual privacy. In addition to the identity of any individual user, location data can also reveal: the existence of – or activities related to – sensitive locations; group mobility patterns; and individual mobility patterns (even if particular people aren’t identified).
As we recommended in our recent privacy assessment for the City of Seattle, companies should thoroughly analyze the range of potential unintended consequences of an open data set, including risks to individual privacy (re-identification), but also including societal risks: quality, fairness, equity, and public trust.
What happened?
Strava is a San Francisco-based company that provides location-based fitness tracking for runners and cyclists (calling itself the “social network for athletes”). Users can download Strava’s free app and use it to directly map their workouts, or pair it with a fitness device, such as a FitBit. In this sense, Strava is very similar to dozens of other popular fitness tracking apps, such as MapMyRun, RunKeeper, or Nike + Run Club.
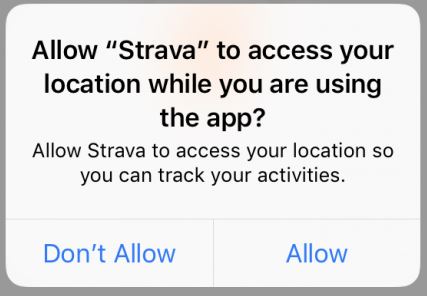
In providing this service, Strava collects precise location data from users’ smartphones as they run or cycle. Like many fitness apps, Strava makes this data “public” by default, but provides adjustable privacy controls for its community-based features, such as public leaderboards, visibility to nearby runners, and group activities. In fact, Strava deserves some credit for providing more granular privacy controls than most fitness apps — they allow users to selectively hide their activities from others, or to create “Privacy Zones” around their home or office. While there is undoubtedly work to be done to align defaults with users’ expectations (we note, for example, that Strava’s request for access to location data does not mention public sharing, but asks for location “so you can track your activities”), many users of fitness apps will be familiar with this kind of setup, and able to exercise informed privacy choices.
Apart from users’ privacy controls with respect to other athletes, Strava itself maintains users’ historical location data that it collects in the process of providing its fitness tracking. Like nearly all location-based apps, Strava states in its Privacy Policy that it has the right to use de-identified and aggregated location information for its own purposes, including selling or licensing it, or using it for research or commercial purposes. Because de-identified information is considered by some to present fewer privacy risks (or none at all), this is a common statement that can be found in many privacy policies.
Facing Heat for Heat Maps
Beginning in 2017, Strava began publishing an updated “Global Heat Map” of the aggregated jogging and cycling routes of its 27 million users. As far as we can tell, the Heat Map is comprised of the anonymous location data collected and aggregated from all users, even when they have enabled the app’s primary privacy controls vis a vis other athletes — although according to Strava’s support page, the Heat Map excludes “private activities” (activities that users have set to be totally private) and “zones of privacy” (users’ activities within areas that they have specifically submitted to Strava to be excluded, such as home and work addresses).
Per Strava, the aggregated patterns of its users are meant to be used to “improve bike- and pedestrian-friendly infrastructure in your area . . . [including for] departments of transportation and city planning groups to plan, measure and improve infrastructure for bicyclists and pedestrians.”
Strava is not alone in this endeavor — there is a growing industry for location data from a wide variety of sources, including fitness trackers and location-based mobile apps. For example, Uber Movement promises to harness the power of its user base by providing “anonymized data from over two billion trips to help urban planning around the world.” Similarly, many state and local governments are partnering with Waze to share mobility data and reduce traffic.
Strava allows users to opt out of contributing to the Global Heat Map, although the option is only available in the online dashboard (not the app).
Despite Strava’s removal of personal information from the data, and their aggregation (to the level of the street grid), careful observers noticed last week that the Heat Map contained location patterns from within U.S. military bases in active conflict zones, including Syria and Afghanistan. While the existence of many of these military installations are already known, others have noted that the Heat Map revealed other “airstrips and base-like shapes in places where neither the American-led military forces nor the Central Intelligence Agency are known to have personnel stations.” (NYTimes)
Perhaps more importantly, the Heat Map reveals mobility patterns between and within military installations that give rise to security and safety concerns. Accordingly, the U.S. coalition against the Islamic State has stated that it is “refining” its existing rules on fitness tracking devices (WP), and a spokesperson for US Central Command has noted that the military is looking “into the implications of the map.” (The Verge)
Addressing Open Data Challenges (Aggregating is Not Always Enough)
While there is certainly an important conversation to be had about individual users having a better understanding of the information they share, it is equally important to consider the responsibilities that are involved with any public release of a large dataset. In Strava’s case, the company was under no obligation to make the data they held available to the public. They did so in order to provide an interesting, useful feature, and perhaps to demonstrate their powerful mapping capabilities. Once they decided to release the data, however, they had a responsibility to thoroughly review it for potential risks (no easy task).
These kinds of challenges are by no means new. As FPF’s Jules Polonetsky, Omer Tene, and Kelsey Finch described in Shades of Grey: Seeing the Full Spectrum of Practical Data De-Identification, some of the most (in)famous examples of “re-identification” arose from the public release of AOL search data, a Massachusetts medical database, Netflix recommendations, and an open genomics database. In each of these cases, “even though administrators had removed any data fields they thought might uniquely identify individuals, researchers . . . unlocked identity by discovering pockets of surprising uniqueness remaining in the data.” Repeatedly, researchers have shown that in a big data world, even mundane data points, such as the battery life remaining on an individual’s phone, can serve as potent identifiers singling out an individual from the crowd.
Until recently, however, almost all conversations around open data related to the risks of re-identification, or the possibility that individual users might be identified from within an otherwise anonymous dataset. However, risks of open data can go far beyond individual privacy. In addition to the identity of any individual user, location data can also reveal:
individual mobility patterns, including sensitive behavior (Supreme Court Justice Sotomayor wrote in 2012 that location data “generates a precise, comprehensive record of a person’s public movements that reflects a wealth of detail about her familial, political, professional, religious, and sexual associations. . . .”);
group mobility patterns (in the case of Strava, it was quickly noticed that supply routes and exercise habits of overseas servicemen and women could be detected in the data, facts which hold implications for safety and security); and
existence or activities related to sensitive location (while some locations, such as abortion clinics or mosques, may only be sensitive in their relation to individual visitors, other locations, such as secret military installations, may be sensitive in their very existence).
In our recent work with the City of Seattle, we explored risks related to Seattle’s Open Data Program, in which the local government releases a variety of useful data about city activities (such as 911 calls, building permits, traffic flow counts, public parks and trails, and food bank locations). While Seattle’s civic data is “open by preference,” the city recognized that “some data elements, if released, could cause privacy harms, put critical infrastructure at risk, or put public safety personnel and initiatives at risk.”
In our Open Data Privacy Risk Assessment, we recommended that any entity deciding whether (or how) to publicly release a large dataset should undergo a privacy benefit-risk assessment. Specifically, we recommended a thorough analysis of several areas of risk:
#1. Re-identification. As we describe in the Open Data Risk Assessment, one of the principal risks of open datasets is the possibility that the data might reveal sensitive information about a specific individual. Once information has been published publicly, it is difficult or impossible to retract — and as a result, (per our Program Maturity Assessment) data holders should:
Utilize technical, legal, and administrative safeguards to reduce re-identification risk;
Have access to disclosure control experts to evaluate re-identification risk;
Use appropriate tools to de-identify unstructured or dynamic data types (e.g., geographic, video, audio, free text, real time sensor data);
Have policies and procedures for evaluating re-identification risk across databases (e.g., risk created by intersection of databases; county, state, or federal open databases; and commercial databases).
Although initial reports indicated that the Strava Heat Map did not reveal individual information, combining the aggregate Heat Map data and the Strava’s leaderboards can potentially reveal individual users and the details of their top runs. Reportedly, a computer scientist has already developed a programmatic method for accessing individual names directly from the Heat Map datasets without relying on outside information.
#2.Data Quality. If data is going to be released publicly, the data should be (as far as possible) accurate, complete, and current. Although this is certainly more important in the context of government-held data, it is applicable to companies like Strava in the sense that the data should reliably inform future decisions. Companies can take steps to check for inaccurate or outdated information, and institute procedures for individuals to submit corrections as appropriate.
#3. Equity and Fairness. Another key aspect of open data — equally applicable to private datasets as to government-held datasets — is equity and fairness. If data is going to be released publicly to be used by others, it should be collected fairly and assessed for its representativeness. For example, Strava permits its users to opt out of contributing to the open dataset (although many may have been unaware), an important aspect of fairness.
Equally, though, datasets should be representative. In his comments to the Washington Post, the Australian researcher who first noticed problems with Strava’s Heat Map mentioned that his father had suggested he check it out as “a map of rich white people.” Although the comment was likely offhand, the issues are serious — particularly in “smart” systems that use algorithmic decision-making, bad data can lead to bad policies. For example, both predictive policing and criminal sentencing have repeatedly demonstrated racial bias in both the inputs (historic arrest and recidivism data) and their outputs, leading to new forms of institutional racial profiling and discrimination.
#4. Public Trust. Although we might typically think of “public” trust as a government issue, trust is critical in the private sector as well. As we have seen in the resulting discussions of Strava and the collection of location data from fitness trackers, there is concern both in the military and amongst average consumers around the use of connected devices. Particularly in the absence of baseline privacy legislation, trust is critical for the growth of new technologies, including Internet of Things (IoT) devices, fitness trackers, Smart Cities, and connected cars.
Conclusion
Beyond individual privacy, the Strava Heat Map demonstrates that there are societal risks that inhere in sensitive datasets. In particular, geo-location data can reveal individual and group patterns of movement, as well as information related to sensitive locations that must be taken into account. As technology advances and we address the challenges of connected Internet of Things (IoT) devices in our homes, on our bodies, and embedded in our cities, it is more important than ever to address the privacy challenges of location and open data.
FPF Publishes Model Open Data Benefit-Risk Analysis
FPF recently released its City of Seattle Open Data Risk Assessment. This Report provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs.
Given the risks described in the report, FPF developed a Privacy Maturity Assessment in order to help municipalities around the United States better evaluate their organizational structures and data handling practices related to open data privacy.
This Report first describes inherent privacy risks in an open data landscape, with an emphasis on potential harms related to re-identification, data quality, and fairness. To address these risks, the Report includes a Model Open Data Benefit-Risk Analysis (“Model Analysis”). The Model Analysis evaluates the types of data contained in a proposed open dataset, the potential benefits – and concomitant risks – of releasing the dataset publicly, and strategies for effective de-identification and risk mitigation. This holistic assessment guides city officials to determine whether to release the dataset openly, in a limited access environment, or to withhold it from publication (absent countervailing public policy considerations). The Report methodology builds on extensive work done in this field by experts at the National Institute of Standards and Technology, the University of Washington, the Berkman Klein Center for Internet & Society at Harvard University, and others,[2] and adapts existing frameworks to the unique challenges faced by cities as local governments, technological system integrators, and consumer facing service providers.[3]
New Future of Privacy Forum Study Finds the City of Seattle’s Open Data Program a National Leader in Privacy Program Management
FOR IMMEDIATE RELEASE
January 25, 2018
Contact: Melanie Bates, Director of Communications, [email protected]
New Future of Privacy Forum Study Finds the City of Seattle’s Open Data Program a National Leader in Privacy Program Management
Washington, DC – Today, the Future of Privacy Forum released its City of Seattle Open Data Risk Assessment. The Assessment provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs.
“Although there is a growing body of research on open data privacy, open data managers and departmental data owners need to be able to employ a standardized methodology for assessing the privacy risks and benefits of particular datasets,” said Kelsey Finch, FPF Policy Counsel and lead author of the Assessment.
“The City of Seattle made the decision to be ‘Open by Preference,’ making it possible for problem solvers outside of government to help us find solutions to civic challenges and improve our community’s quality of life. At the same time, we must honor the privacy of those reflected in our data. We are proud to have partnered with the Future of Privacy Forum on this effort to make sure we can both open our data and maintain the public’s trust in how we collect and use their data,” said Michael Mattmiller, Chief Technology Officer, City of Seattle.
To address inherent privacy risks in the open data landscape, the Assessment includes a Model Open Data Benefit-Risk Analysis, which evaluates the types of data contained in a proposed open dataset, the potential benefits – and concomitant risks – of releasing the dataset publicly, and strategies for effective de-identification and risk mitigation. This holistic assessment guides city officials to determine whether to release the dataset openly, in a limited access environment, or to withhold it from publication (absent countervailing public policy considerations).
“By optimizing its internal processes and procedures, developing and investing in advanced statistical disclosure control strategies, and following a flexible, risk-based assessment process, the City of Seattle – and other municipalities nationwide – can build mature open data programs that maximize the utility and openness of civic data while minimizing privacy risks to individuals and addressing community concerns about ethical challenges, fairness, and equity,” Finch said.
“The City of Seattle is very grateful to the Future of Privacy Forum for their comprehensive privacy risk assessment of our open data program, and for providing a framework within which we can enhance our existing privacy protections when releasing open data to the public,” said David Doyle, Open Data Manager, City of Seattle. “We are excited to be continually improving our open data program maturity levels where needed, and to continue to act as a role model for other municipal governments when mitigating for privacy risk during the process of releasing open data.”
FPF found that the City of Seattle Open Data Program has developed and managed robust and innovative policies around data quality, public engagement, and transparency. Specifically:
The City of Seattle is a national leader in privacy program management.
The Seattle Open Data Program has developed and managed robust and innovative policies around data quality, public engagement, and transparency.
The Seattle Open Data Program is working to enhance its policies and procedures for consistently assessing the benefits and risks of releasing particular datasets and for assessing and mitigating re-identification risks in open data.
Currently, both Seattle’s Open Data and Privacy programs are already collaborating on a number of initiatives related to recommendations called out in the report. Additionally, the programs are also implementing an updated internal process for reviewing new open datasets for privacy risks based on the Model Open Data Benefit Risk Analysis framework. The City of Seattle is committed to this work as part of the 2018 Open Data Plan. In the coming weeks, both Open Data and Privacy programs will assess what additional recommendations to commit to addressing in 2018 and beyond.
“The City of Seattle is one of the most innovative cities in the country, with an engaged and civic-minded citizenry, active urban leadership, and a technologically sophisticated business community,” said Finch. “By continuing to complement its growing Open Data Program with robust privacy protections and policies, the City of Seattle will be able to fulfill that program’s goals, supporting civic innovation while protecting individual privacy.”
###
The Future of Privacy Forum (FPF) is a non-profit organization that serves as a catalyst for privacy leadership and scholarship, advancing principled data practices in support of emerging technologies. Learn more about FPF by visiting www.fpf.org.
Examining the Open Data Movement
The transparency goals of the open data movement serve important social, economic, and democratic functions in cities like Seattle. At the same time, some municipal datasets about the city and its citizens’ activities carry inherent risks to individual privacy when shared publicly. In 2016, the City of Seattle declared in its Open Data Policy that the city’s data would be “open by preference,” except when doing so may affect individual privacy.[1] To ensure its Open Data Program effectively protects individuals, Seattle committed to performing an annual risk assessment and tasked the Future of Privacy Forum with creating and deploying an initial privacy risk assessment methodology for open data.
Today, FPF released its City of Seattle Open Data Risk Assessment. This Report provides tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs. Although there is a growing body of research regarding open data privacy, open data managers and departmental data owners need to be able to employ a standardized methodology for assessing the privacy risks and benefits of particular datasets internally, without access to a bevy of expert statisticians, privacy lawyers, or philosophers. By optimizing its internal processes and procedures, developing and investing in advanced statistical disclosure control strategies, and following a flexible, risk-based assessment process, the City of Seattle – and other municipalities – can build mature open data programs that maximize the utility and openness of civic data while minimizing privacy risks to individuals and addressing community concerns about ethical challenges, fairness, and equity.
This Report first describes inherent privacy risks in an open data landscape, with an emphasis on potential harms related to re-identification, data quality, and fairness. To address these risks, the Report includes a Model Open Data Benefit-Risk Analysis (“Model Analysis”). The Model Analysis evaluates the types of data contained in a proposed open dataset, the potential benefits – and concomitant risks – of releasing the dataset publicly, and strategies for effective de-identification and risk mitigation. This holistic assessment guides city officials to determine whether to release the dataset openly, in a limited access environment, or to withhold it from publication (absent countervailing public policy considerations). The Report methodology builds on extensive work done in this field by experts at the National Institute of Standards and Technology, the University of Washington, the Berkman Klein Center for Internet & Society at Harvard University, and others,[2] and adapts existing frameworks to the unique challenges faced by cities as local governments, technological system integrators, and consumer facing service providers.[3]
FPF published a draft report and proposed methodology for public comment in August, 2017. Following this period of public comment and input, FPF assessed the City of Seattle as a model municipality, considering the maturity of its Open Data Program across six domains:
Privacy leadership and management
Benefit-risk assessments
De-identification tools and strategies
Data quality
Data equity and fairness
Transparency and public engagement
In our analysis, we found that the Seattle Open Data Program has largely demonstrated that its procedures and processes to address privacy risks are fully documented and implemented, and cover nearly all relevant aspects of these six domains. Specifically:
The City of Seattle is a national leader in privacy program management.
The Seattle Open Data Program has developed and managed robust and innovative policies around data quality, public engagement, and transparency.
The Seattle Open Data Program is working to enhance its policies and procedures for consistently assessing the benefits and risks of releasing particular datasets and for assessing and mitigating re-identification risks in open data.
Although most aspects of Seattle’s programs are documented and implemented, some aspects are not as developed. This is unsurprising, given the novel challenges posed by the intersection of open government equities and privacy interests with emerging technologies and data analysis techniques.
The Report concludes by detailing concrete technical, operational, and organizational recommendations to enable the Seattle Open Data Program’s approach to identify and address key privacy, ethical, and equity risks, in light of the city’s current policies and practices. For example, we recommend that the City of Seattle and the Open Data Program:
Document potential benefits and risks for each published dataset, both prospectively and retroactively for those that have not yet had a benefit-risk assessment conducted.
Develop policies and procedures for conducting additional screening of datasets and elevating the review of risky or sensitive datasets to disclosure control experts or a disclosure review board when appropriate.
Engage governmental decision-makers at the data collection stage with decision-makers at the data release stage (such as open data and public records staff), so that the full lifecycle of data collected by and for the city can be better understood, managed, and communicated to the public.
The City of Seattle is one of the most innovative cities in the country, with an engaged and civic-minded citizenry, active urban leadership, and a technologically sophisticated business community. By continuing to complement its growing Open Data Program with robust privacy protections and policies, the City of Seattle will be able to fulfill that program’s goals, supporting civic innovation while protecting individual privacy.
[1]Exec. Order No. 2016-01 (Feb. 4, 2016), available at http://murray.seattle.gov/wp-content/uploads/2016/02/2.26-EO.pdf.
[2]See infra Appendix A for a full list of resources.
[3]See Kelsey Finch & Omer Tene, The City as a Platform:Enhancing Privacy and Transparency in Smart Communities, Cambridge Handbook of Consumer Privacy (forthcoming).
Public comments on proposed Open Data Risk Assessment for the City of Seattle
The Future of Privacy Forum requested feedback from the public on its proposed Draft Open Data Risk Assessment for the City of Seattle. In 2016, the City of Seattle declared in its Open Data Policy that the city’s data would be “open by preference,” except when doing so may affect individual privacy. To ensure its Open Data program effectively protects individuals, Seattle committed to performing an annual risk assessment and tasked FPF with creating and deploying an initial privacy risk assessment methodology for open data.
This report is intended to provide tools and guidance to the City of Seattle and other municipalities navigating the complex policy, operational, technical, organizational, and ethical standards that support privacy-protective open data programs. In the spirit of openness and collaboration, FPF invited public comments from the Seattle community, privacy and open data experts, and all other interested individuals and stakeholders regarding its proposed framework and methodology for assessing the privacy risks of a municipal open data program. The public comment period extended from April 18, 2017 to October 2, 2017.
Following this period of public comment, a Final Report was published that assessed the City of Seattle as a model municipality and provided detailed recommendations to support the Seattle Open Data Program’s ability to identify and address key privacy, ethical and equity risks, in light of the city’s current policies and practices.
PUBLIC COMMENTS:
FPF wishes to thank all of those who provided public comments to this draft report for their thoughtful feedback and active participation in this process. FPF received the following timely and responsive public comments via email and Madison:
From cross-border transfers to privacy engineering, check out all panels and events FPF will be a part of at CPDP2018
Computers Privacy and Data Protection conference (CPDP) kicks off this week in Brussels, and the theme this year is “The Internet of Bodies”. The conference will gather 400 speakers for 80 panels to set the stage for the privacy and data protection conversation in Europe for 2018. And this is such an important year for data protection – not only the General Data Protection Regulation becomes applicable in May, but also the text of the new ePrivacy Regulation will likely be finalized.
Given the global impact of developments in EU data protection and privacy regulation, the Future of Privacy Forum is taking part in the conversation, aiming to drive understanding between the privacy cultures in the US and the EU.
If you’re in Brussels this week, don’t miss out the panels and events we’ll take part in, listed chronologically:
Cross-border data transfers: effective protection and government access, in particular in the transatlantic context
Tuesday, January 23, 18.00, Petite Halle
The Brussels Privacy Hub and the Privacy Salon will be hosting an exclusive launch event for the 11th edition of CPDP on 23 January 2018. This year’s launch will be an Evening Roundtable on “Cross-border Data Transfers” starting at 18.00, which will be followed by a cocktail.
The EU data protection regime claims that cross-border data transfers should not prejudice the level of protection individuals are entitled to. However, enforcing this claim in a cross-border context is not evident, especially since the EU data protection rules should also give effective remedies against governments of third countries, where EU jurisdiction is only indirect. This problem is widely recognised and in the last years the CJEU has set high standards in Schrems I, C-362/14 and Opinion 1/15 PNR Canada. The roundtable will address the latest developments and relevant court cases and discuss the contributions of the various actors, including Privacy Advocates, Data Protection Authorities, Companies and Governments.
Renate Nikolay, Head of Cabinet of Commissioner Vĕra Jourová, DG JUST, European Commission, Max Schrems, noyb and Gabriela Zanfir-Fortuna, FPF EU Policy Counsel, will discuss about the latest developments in cross-border transfers and the outlook for 2018. The discussion will be moderated by Omer Tene, VP of IAPP and FPF Senior Fellow.
Physical tracking
Wednesday January 24, 8.45, Grand Halle
FPF CEO, Jules Polonetsky, is speaking in a panel on “Physical tracking” together with Anna Fielder, Trans Atlantic Consumer Dialogue (UK), Mathieu Cunche, INSA Lyon (FR), Monica McDonnell, Informatica (UK). The panel is organized by INRIA, Chaired by Daniel Le Métayer, INRIA and moderated by Gloria González Fuster, VUB (BE).
Tracking people in the physical world, through a variety of sensors, cameras, and mobile devices, is now common but it is becoming increasingly controversial. Knowing human dynamics such as crowd sizes, paths or visit durations are extremely valuable information for many applications. It offers great prospects to retailers or for urban planning. More generally, the extension to the physical world of the tracking already in place on the internet and the lack of control or even awareness of individuals raise serious questions. The goal of this panel is to discuss in a multidisciplinary way the issues raised by physical tracking, including the following questions:
Is it possible to enhance individuals’ control over their information (including information, consent and “do not track” options) in the context of physical tracking?
What recommendations could be made regarding the ePrivacy Regulation and the implementation of the GDPR to ensure better protection against physical tracking?
Can self-regulation initiatives such as the Future of Privacy Forum code of conduct help improve the situation?
Privacy engineering, lingua franca for transatlantic privacy
Wednesday, January 24, 11.45, La Cave
The Future of Privacy Forum is organizing a panel that aims to contribute to the essential transatlantic privacy debate by focusing on privacy engineering and the role it could play as “lingua franca” between the US and the EU privacy and data protection worlds. Privacy engineering is more important than ever in a time where accountability is significantly transferred to the creators of data centric systems. The state of the art of privacy engineering will be discussed with leading experts from the US and Europe, focusing on the latest solutions for embedding privacy safeguards in processing systems from their design stage, but also for quintessential issues such as de-identification, data portability, encryption, user control over data.
How big of a role does privacy engineering have for enhancing privacy of individuals/ users/consumers/digital citizens? Should it bear most of the “burden”? With whom else should privacy engineering share the “burden”?
Could privacy engineering become a lingua franca of the US and EU privacy worlds? Is it already in this position?
Is privacy by design achievable on a mass scale? Which are the factors that would facilitate the overall adoption of privacy by design?
The guest speakers are Simon Hania, Tomtom (NL), Naomi Lefkovitz, NIST (US), Seda Gürses, KU Leuven (BE), Ari Ezra Waldman, New York Law School (US). The panel is Chaired by Achim Klabunde , EDPS (EU) and moderated by Gabriela Zanfir-Fortuna.
Data processing beneficial to individuals: the use of legitimate interests
Wednesday, January 24, 14.15, Area 42 Grand
In today’s age of the Internet of Things, Artifi cial Intelligence (AI), cloud computing, mobile devices, advanced analytics and profi ling, it is becoming ever more diffi cult to obtain valid consent to process an individual’s personal data. More organisations are therefore looking to use the legitimate interest ground to process personal data, while at the same time struggling with its correct application. The balancing test needs to be completed, a good overview of potential benefi ts to individuals when processing their personal data needs to be produced and an ethical assessment needs to be maintained. All this to ensure that the risks of the data processing for the individual are minimised. This panel will discuss various approaches to the use of legitimate interest and the pros and cons of leveraging the benefi ts to individuals to process personal data.
What needs to be done to use legitimate interest as a ground for processing personal data under GDPR?
How do you balance benefi ts to individuals against risks to their rights and freedoms?
How does the balancing test contribute to ethical data processing?
Paul Breitbarth, Nymity (NL), Dominique Hagenauw, Considerati (NL), Leonardo Cervera Navas, EDPS (EU), and Gabriela Zanfir-Fortuna, FPF (US) will speak about using legitimate interests of a controller or a third party as lawful ground for processing under EU data protection law. The panel is organized by Nymity, Chaired by Raphaël Gellert, Tilburg University (NL) and moderated by Aurélie Pols, Mind Your Privacy (ES).
Can citizenship of the target ever be a justified basis for different surveillance rules?
Thursday, January 25, 8.45, Grande Halle
This panel, organized by Georgia Institute of Technology, will examine the topic of whether the nationality of an individual under surveillance (the “target”) is and should be relevant to the legal standards for surveillance.
Legislation in effect today, in countries including the United States and Germany, applies stricter protections for national security surveillance of a nation’s own citizens than for foreigners. To date, there has been no systematic discussion of whether and on what basis those stricter standards might be justified. Some writers have asserted a “universalist” position, that national security surveillance must apply identically to both citizens and non-citizens. This panel will provide a description of current law and practice. It will then discuss and debate whether, and in what circumstances if any, it may be justified to apply different surveillance standards based on whether the individuals under surveillance have citizenship or other significant connections to the country undertaking the surveillance
Peter Swire, Georgia Institute of Technology and FPF Senior Fellow, Joseph Cannataci, UN Special Rapporteur on the Right to Privacy (INT), Mario Oetheimer, Fundamental Rights Agency (EU) and Thorsten Wetzling, Stiftung NV (DE) will discuss, in a panel moderated by Amie Stepanovich, Access Now (US) and Chaired by Wendy Grossman, Independent Journalist (US).
SIDE EVENT
Privacy by Design, Privacy Engineering
Thursday, January 25, 19.30 (preceded by a cocktail at 18.30), Grande Halle
“Privacy by Design, Privacy Engineering” is a side event organized by the European Data Protection Supervisor and supported by FPF and Qwant, that will explore the role of privacy by design in the current privacy landscape.
Giovanni Buttarelli, EDPS, Jules Polonetsky, CEO, Future of Privacy Forum, Marit Hansen, Data Protection Commissioner, ULD Schleswig-Holstein, Eric Léandri, Co-founder and CEO Qwant will discuss privacy by design in a panel moderated by Seda Gurses, KU Leuven.
The GDPR introduces the obligation of data protection by design and by default. This is a very important step ahead and a challenge for many organisations, but it cannot be the end of the road. For technology to serve humans, a broader view on privacy and ethical principles must be taken into account in its design and development. The panel will discuss the perspectives of businesses and regulators which are the principles that they see as important in this context, and which are the approaches of their own organisations, and their demands and recommendations for other stakeholders.
PLSC EUROPE
Saturday, January 27, 9.15
Peter Swire, Georgia Institute of Technology and FPF Senior Fellow, and Jesse Woo, Georgia Institute of Technology, will have their paper discussed at PLSC Europe, “Understanding Why Nationality Matters for Surveillance Rules”.
If you would like to discuss FPF’s expanding activities in Europe, please contact us at [email protected].
New US Dept of Ed Finding: Schools Cannot Require Parents or Students to Waive Their FERPA Rights Through Ed Tech Company’s Terms of Service
By Lindsey Barrett and Amelia Vance
Policymakers, parents, and privacy advocates have long asked whether FERPA is up to the task of protecting student privacy in the 21st century. A just-released letter regarding the Agora Cyber Charter School might signal that a FERPA compliance crack-down – frequently mentioned as their next step after providing extensive guidance by the U.S. Department of Education (USED) employees at conferences throughout 2017 – has begun. The Agora letter provides crucial guidance to schools – both K-12 and Higher Ed – and ed tech companies about how USED interprets FERPA’s requirements regarding parental consent and ed tech products’ terms of service, and it may predict USED’s enforcement priorities going forward.
FERPA compliance can be complicated; the statute was first passed in 1974 and has been occasionally updated to add additional protections and exceptions, some of which include ambiguous language. USED’s Privacy Technical Assistance Center (PTAC) – a program that has received nearly universal praise from state and local officials over the past four years – has spent significant time and effort providing practical guidance, training, and resources for state and local education agencies to clarify FERPA’s requirements for the use of ed tech products.
The Agora letter, issued by the FERPA family policy compliance office in USED, clarifies the Department’s position regarding several key issues. It is sure to attract the attention of schools and ed tech providers seeking to better understand the interaction of FERPA, school requirements regarding technology in the classroom, and the data use policies and practices of ed tech providers. Moreover, this finding letter may signal increased interest by USED in investigating and sanctioning practices that are inconsistent with FERPA.
“A parent or eligible student cannot be required to waive the rights and protections accorded under FERPA as a condition of acceptance into an educational institution or receipt of educational training or services.”
USED investigated two allegations made by a parent of a student in Agora Cyber Charter School, an online public charter K-12 school based in Pennsylvania. The first allegation is based on a long-established FERPA principle that “a parent or eligible student cannot be required to waive the rights and protections accorded under FERPA as a condition of acceptance into an educational institution or receipt of educational training or services.”
In 2012, an Agora parent complained that the school forced her to accept the terms and conditions of its third-party online learning platforms in order to enroll her child at Agora. Agora’s learning platform, K12 Inc., had a “Terms of Use” policy that stated:
by posting or submitting Member Content to this Site, you grant K12 and its affiliates and licensees the right to use, reproduce, display, perform, adapt, modify, distribute, have distributed, and promote the content in any form, anywhere and for any purpose.
“Member content” was defined as information the child posted on certain areas of the site, registration data, and other forms of student personally identifiable information (PII).
According to USED, the Terms of Use allowed “near universal use and distribution by K12 and various third party affiliates and licensees of information that could have constituted her child’s PII from education records,” an outcome that constituted an unlawful “forfeiture of [the parent’s] rights under FERPA to protect against the unauthorized disclosure of PII from her child’s education records.” Because the Terms of Use would have allowed K12 to freely re-disclose FERPA-protected information without consent (including, as stated in the letter, to “future employers of the student”), the Terms of Use constituted a waiver of FERPA rights. And because the child could not enroll at Agora without the parent agreeing to the Terms of Use, USED found that Agora violated FERPA.
Requiring the parent to accept the K12 Inc. Terms of Use when she signed up her child for the school constituted a forced waiver of parental rights under FERPA.
Agora noted that, as a charter school, parents were free to enroll their children elsewhere. Further, Agora argued that parents’ choice to enroll their children at Agora meant that acceptance of the K12 Terms of Use was not truly “forced.” USED rejected this logic, concluding that requiring the parent to accept the K12 Inc. Terms of Use when she signed up her child for the school constituted a forced waiver of parental rights under FERPA.
USED also investigated a parental allegation that Agora violated the requirements of FERPA’s school official exception. This exception allows schools to disclose PII from students’ educational records without parental consent subject to certain requirements: among others, the school must:
maintain “direct control” over third parties with respect to the use and maintenance of the child’s PII; and
ensure that the third party only uses that PII for the purposes for which the school made the disclosure.
The parent alleged that, since K12’s Terms of Use allowed such liberal sharing of student personal information, the school was not in compliance with FERPA.
USED found that the school had not violated FERPA’s school official requirements in 2012, but indicated that schools and ed tech providers must proceed with greater caution in 2018. USED stated that when the complaint was filed, USED had not yet released guidance regarding how schools should establish direct control over third parties and ensure the limited use of personal information under FERPA’s school official exception. Such guidance was issued in 2014 and 2015; USED is likely to hold schools to a higher standard today, in light of its conclusion that the guidance documents:
provide substantial clarity to the education community on best practices for effectively establishing direct control over the use and maintenance of education records and the PII from such education records by third parties acting as school officials with legitimate educational interests in the online educational service context.
The Agora letter has a number of implications for stakeholders. While USED exerts meaningful influence over schools and industry through advisory letters, policy guidance, and other “soft law” measures that shape behavior, this is the first time that the agency has issued a finding letter that directly finds fault with the policies and practices of an ed tech company.
When a school requires that an ed tech service be used as a condition of enrollment, that service must either comply with FERPA’s school official exception requirements or parents must be given the right to opt out of its use.
Ed tech companies should review their privacy policies and terms of service (pro tip: we’ll help you do that for free if you apply to join the Student Privacy Pledge!) and ensure that terms governing school-required services do not contain language similar to the broad language in the K12 Terms of Use.
Most importantly, the key stakeholders protected here are the parents and student themselves. FERPA was written to provide express controls for parents over their child’s educational record, and this letter shows that while the technology may change, the underlying right is sound and strong.
Certain issues raised by the Agora letter may have murkier implications. This letter makes it clear that, when schools require students to use ed tech services, those services can only be used under FERPA’s school official exception. How this may play out in schools is difficult to predict: there are some ed tech services, required by schools, which are offered directly to students, and so it is common practice for parents or eligible students to be directed to sign up for an account that requires them to agree to a Terms of Service that may not align with FERPA’s requirements. This finding letter may encourage more ed tech companies to allow schools to sign students up for the product directly, or schools may even begin to require independent contracts or clauses in company Terms of Service that align with FERPA’s school official requirements.
A parent cannot be directed to consent to an account for their child with insufficient privacy or TOS terms as a workaround to the standards required if the school was directly contracting with the provider.
The underlying issue of the letter – that schools retain the responsibility to ensure any mandatory ed tech product is used only in compliance with FERPA protections – extends beyond the particular example of Agora. In many cases, schools may direct parents to directly download, sign up for, or otherwise enroll their child in a particular platform, educational product, or online service, without the school operating as an intermediary. As this letter makes clear, however, even when the school doesn’t directly own or manage the student account, any ed tech use mandated as part of the student’s educational process must comply with FERPA under the school official exception. A parent cannot be directed to consent to an account for their child with insufficient privacy or TOS terms as a workaround to the standards required if the school was directly contracting with the provider.
This letter may also encourage more enforcement actions from states. While 124 new student privacy laws have passed in 40 states since 2013, no enforcement actions have been brought yet under any of those laws. Now that states have this findings letter from USED, they might look for similar Terms of Service language in ed tech products used in their states to bring an enforcement action.
The USED letter to Agora makes clear that the stakes are high. While financial penalties against schools are rare – USED is required to attempt to bring schools into compliance with FERPA before withholding federal funding – the Department has other enforcement options, including the imposition of a five-year ban on data transfers from an offending school to the ed tech provider.
Privacy and the Connected Vehicle: Navigating the Road Ahead (January 23, 2018 in Washington, DC)
Join Hogan Lovells and FPF for an event focused on data issues related to connected cars and the future of mobility on January 23, 2018, from 9:45 AM – 2:00 PM at Hogan Lovells (555 13th Street, NW Washington, DC). This half-day event will highlight industry privacy practices, regulatory developments, and emerging uses of mobility data.
This event has been approved for the following CLE credits:
California, general: 3.25 credit
New York, professional practice: 4.0 credit
Attendees licensed in other states will receive Uniform Certificates of Attendance, which they may use to request credit from their respective state bars. Approval guidelines and credit hours vary by state.
Our panelists will explore:
Privacy landscape and implementation
—
What types of data do today’s cars collect?
—
What are best practices for privacy in connected cars and autonomous vehicles?
—
Are there any unique considerations for privacy in the mobility context as compared to other technologies?
—
What kinds of steps are companies taking to adopt the Auto Alliance and Global Automakers Consumer Privacy Protection Principles?
Hilary Cain, Director of Technology and Innovation Policy, Toyota North America
David Friedman, Director of Cars and Product Policy and Analysis, Consumers Union
David Schwietert, Executive Vice President of Federal and Government Relations and Public Policy, Auto Alliance
Lauren Smith, Policy Counsel, Future of Privacy Forum (Moderator)
Regulatory developments
—
How have legislative efforts in the House and Senate touched on privacy in connected vehicles?
—
What role will federal agencies play?
—
What relevant regulation has advanced at the state level?
—
What international considerations and practices should be considered?
Sarah Arnett, Senior Analyst, Physical Infrastructure Team, Government Accountability Office
Claire Barrett, Chief Privacy Officer, Department of Transportation
Peder Magee, Senior Staff Attorney, Division of Privacy and Identity Protection, Federal Trade Commission
Tim Tobin, Partner, Hogan Lovells (Moderator)
Innovation and disruption
—
What emerging technologies in this space will make new uses of data?
—
How do we ensure best practices for privacy are integrated into new mobility-related technologies?
—
What unique questions do autonomous vehicle technologies raise around ethics and privacy?
—
How do you manage privacy in a distributed ecosystem?
Mo Al-Bodour, Senior Connected Car Specialist, SBD Automotive
Leo Fitzsimon, Government Relations – Americas, HERE
Justin Erlich, Head of Policy, Autonomous Vehicles & Urban Aviation
Uber
Yael Weinman, Associate General Counsel, Privacy, Verizon
W. James Denvil, Senior Associate, Hogan Lovells (Moderator)
This event takes place the week of the opening of the D.C. Auto Show. Our session will end in time for the first session of MobilityTalks International on Capitol Hill, which starts at 3 p.m.