Machine Learning and Speech: A Review of FPF’s Digital Data Flows Masterclass
On Wednesday, December 9, 2020, FPF hosted a Digital Data Flows Masterclass on Machine Learning and Speech. The masterclass on Machine Learning and Speech is the first masterclass of a new series after completing the VUB-FPF Digital Data Flows Masterclass series with eight topics.
Professor Marine Carpuat (Associate Professor in Computer Science at the University of Maryland) starts with an introduction on the more advanced aspects of (un)supervised learning. One of the unique takeaways of the presentation is that Prof. Carpuat’s explanation of mathematical models to an audience without a mathematical background is second to none. Dr. Prem Natarajan (VP, Alexa AI-Natural Understanding) guides us through the intricacies of Machine Learning in the context of voice assistants. As a practitioner, Dr. Natarajan brings unique examples to this class. The presenters explored the differences between supervised, semi-supervised, and unsupervised machine learning (ML) and the impact of these recent technical developments on machine translation and speech recognition technologies. In addition, they briefly explored the history of machine learning to draw lessons from the long-term development of artificial intelligence and put new advancements in context. FPF’s Dr. Sara Jordan and Dr. Rob van Eijk moderated the discussion following expert overviews.
The recording of the class can be accessed here.
Machine Translation – An Introduction
As a sub-field of computational linguistics, machine translation studies the use of software to translate text or speech from one language to another. Applications that use machine translation find the best fit for a translation based on probabilistic modelling. This means that for any given sentence in a language, translation models will find the highest probability of resemblance to a human translation and use that sentence in a translation.
Machine translation has made considerable progress over the years. Previous models would break down simple sentences into individual words without taking into account the context of the sentence itself. This often led to incomplete, simplistic, or wholly incorrect translations. The introduction of deep learning and neural networks to machine translation greatly increased the quality and fluency of these translations by allowing translation tools to put the meaning of each word within the overall context of the sentence.
Yet for all the progress, many challenges lay ahead. Deep learning requires very large datasets and paired translation examples (e.g., English to French), which might not exist for certain languages. Even when there is a large pool of data, sentences often have multiple correct translations, which poses additional problems for machine learning. In addition, the deployment of these models in the real world has also raised concerns, as translation errors can sometimes have severe consequences.
Machine translation tools generally use sequence-to-sequence models (Seq2Seq) that share architecture with word embedding and other representation models. Seq2Seq models convert sequences from one language (e.g., English) to generate text in another (e.g., French). Seq2Seq models form the backbone of more accurate natural language processing (NLP) tools due to their use of recurrent neural networks (RNN), which allow models to take into account the context of the former input word when processing the next output word. Developers use Seq2Seq models for multiple use cases including dialogue construction, text summarization, question answering, image captioning, and style transfer.
Word embedding refers to language processing models that map words and phrases onto vector space of real numbers through neural networks or other probabilistic models. This allows translation models to reduce confusion arising from a large dimension of possible outputs and better represent the context of a sentence in which words appear. These tools generally increase the performance of Seq2Seq models and NLP generally because they help models understand the context in which words appear.
Figure 1. How to Train a Machine Learning Model?
How to Train a Machine Learning Model – Supervised, Unsupervised, and Semi-Supervised Learning
Training neural models with limited translation data poses multiple problems (see also, Figure 1). For instance, situations calling for a more formal translation need plenty of formal writing data to achieve accuracy and fluency. But issues may arise if the model must account for different writing styles or more informal contexts. Fortunately, developers can apply different training paradigms, including supervised, unsupervised, and semi-supervised learning, to better train models with diverse and limited translation data.
Supervised learning is a process of learning from labeled examples. Developers feed the model with instances of previous tests and answer keys to improve the model’s accuracy and precision. Supervised learning allows the model to match input source and output target sequences with correct translations through parallel sampling, which refers to sampling a limited subset of data for one language against a whole body of data for another. In other words, the translation model can learn from examples of text in one language to better calculate the probability of a correct translation in another. Under this type of learning, it is important to create parameters that give a high probability of success to avoid overfitting and make the model generalizable across contexts.
On the other end of the spectrum, unsupervised learning gives previous tests to the model without answer keys. Under this type of training, models learn by making connections between unpaired monolingual samples in each language. Put simply, machine translation models study individual words in a language (e.g., through a dictionary) and draw connections between those words. This helps the model find similarities or patterns in language across the data and predict the next word in a sentence from the previous word in that sentence.
Unsupervised learning is a simple yet powerful tool. It works extremely well when the developer has a large pool of data to help the model reinforce its understanding of the syntactic or grammatical structures between languages. For example, deep learning encodes an English sentence and plugs it into the French output model which then generates a translation based on the cross-lingual correspondences it learned through the data. While many applications of unsupervised learning are still at the proof of concept stage, this learning technique offers a promising avenue for language processing developers.
Finally, semi-supervised learning combines elements of both supervised and unsupervised learning and is the primary training method for translation models. The model learns from a multitude of unpaired samples (unsupervised learning) but then receives paired samples (supervised learning) to reinforce cross-lingual connections. Put simply, unsupervised training helps the model learn syntactic patterns in languages, while supervised training helps the model understand the full meaning of a sentence in context. Combinations of both training techniques strengthen syntactic and semantic connections simultaneously.
Limitations and Challenges of Machine Translation
While the accuracy and quality of machine translation have increased through supervised, unsupervised, and semi-supervised learning, there are still many obstacles to scale the 7,111 languages spoken in the world today. Indeed, while the lack of data poses its own challenges for training purposes, machine translation still runs into problems with adequacy, accuracy, and fluency in languages where plenty of data exists.
Developers have addressed these problems by attempting to quantify adequacy and compute the semantic similarity between machine translation and human translation. One common method is BLEU, which counts the exact matches of word sequences between human translation and the machine output. Another, BVSS, combines word pair similarity into a sentence score to measure a translation against a real-world output. In practice, developers need to use both metrics at the same time in order to make machine translation more adequate and fluent.
From a high-level perspective, neural models employing machine learning produce more fluent translations than older statistical models. Forward-looking models are beginning to build systems that adapt to different audiences and can incorporate other metrics of translation such as formality and style. While much work is needed in both supervised and unsupervised learning, case studies have already revealed a promising ground for future improvements.
Machine Learning and Speech
Many of the lessons learned in recent advancements of machine translation also apply to the area of speech recognition. The introduction of deep learning and automatic features in both fields has accelerated development, bringing more complexity and new challenges to training and refining machine learning models than what came before. As the application of machine translation and speech recognition become more prevalent in the economy, it is important to understand where the field came from and where it is going.
Like machine translation, speech recognition has a long history that stretches back to the invention of artificial intelligence (AI) as a formal academic discipline in the 1950s. The introduction of neural networks and statistical models in the 1980s and 1990s marked a watershed moment in the development of machine learning and speech. Inputting human interaction directly into the machine helped create trainable models and gave impetus to a variety of speech recognition projects.
Yet while the idea of machine learning through neural networking became widespread in the discipline, the lack of computing power and data inhibited its development. With widespread increases in computational power in the 1990s and 2000s, researchers were able to introduce automatic machine learning tools, which greatly accelerated the development of speech recognition and machine translation. But as automatic models became more sophisticated in identifying recognizing inputs and reducing recognition errors, these models also led to decreased interpretability.
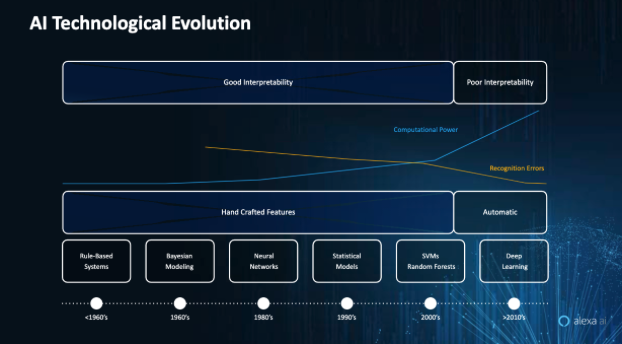
Figure 2. Historical overview of the technological evolution of AI/ML.
Since then, correcting for poor interpretability in these models has involved a range of training methods, including supervised and unsupervised learning. The widespread availability of data has helped this process because developers can now find novel ways to make automatic features more reliable and accurate.
As speech recognition technology begins to interface with humans through conversational AI, the competency of these models may greatly improve. This is because engaging with data in real time allows machine learning models to adapt to novel situations when presented with new information or new vocabulary that it did not previously know. To this end, research is currently moving in the direction of parameter defining and error evaluation in order to make training more accurate and effective.
To be sure, advancements in human-computer interface have a history going back to the era of Markov Models in the 1980s (see, Figure 2). However, today the proliferation of practical speech recognition applications fueled by automatic features has underscored a change in the pace of research. In addition, the role of data, including less labelled data, has also become increasingly important in the process of training models.
Advancements in Training Models
Indeed, present speech recognition technology utilizes a range of learning methods at the cutting edge of deep learning, including active learning, transfer learning, semi-supervised learning, learning to paraphrase, self-learning, and teaching AI.
Active learning refers to a training process where different loss functions divide training data in different ways to test the models adaptability to new contexts with the same data. Transfer learning data takes data-rich domains and finds ways to transfer learning to new domains that lack corresponding data. For instance, in the context of language learning, this type of learning takes lessons learned from one language and transfers them to another.
As discussed above, semi-supervised learning trains large models with a combination of supervised and unsupervised learning and uses such models to train smaller models and filter unlabeled data. Indeed with semi-supervised training, the current trend is moving away from supervised learning and reducing reliance on annotated data for training purposes.
Learning to paraphrase refers to a learning process where a model will take a first pass at guessing the meaning of an input, receive a new paraphrased version of the input, and then attempt again at decoding a correct output. Related to this, self-learning takes signals from the real-world environment and makes connections between data, without requiring any human intervention in the process. Finally, teaching AI allows models to integrate natural language with common-sense reasoning and learn new concepts through direct and interactive teaching from customers.
Each of these training methods marks a departure from past learning paradigms that required direct supervision and labelled data from human trainers. While limitations in the overall architecture of training models still exist, major areas of research today focus on approximating the performance of supervised learning models with less labelled data.
Self-Learning in New Applications and Products
These advancements are coinciding with the proliferation of consumer products designed and optimized for conversational translation. Speech recognition converts audio into sequences of phonemes and then uses machine translation to select the best output between alternate interpretations of those phonemes. New applications on the consumer market can directly learn through their interaction with the consumer by combining traditional machine translation models with neural language models that apply AI and self-learning.
Learning models that can act more independently and filter unlabelled data will become more effective in adapting to novel contexts and processing language more accurately and fluently. Already, developers are improving the level of fluency in these products by incorporating conversational-speech data that includes tone of voice, formality, and colloquial expressions in the training.
The recording of the class can be accessed here.
Digital Data Flows Masterclass Archive
The Digital Data Flows Masterclass Archive with the recordings and resources for previous classes can be accessed here.
To learn more about FPF in Europe, visit https://fpf.org/eu.


