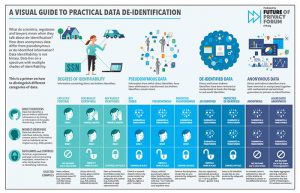
One key method for ensuring privacy while processing large amounts of data is de-identification. De-identified data refers to data through which a link to a particular individual cannot be established. This often involves “scrubbing” the identifiable elements of personal data, making it “safe” in privacy terms while attempting to retain its commercial and scientific value.
In the era of big data, the debate over the definition of personal information, de-identification and re-identification has never been more important. Privacy regimes often rely on data being considered Personal in order to require the application of privacy rights and protections. Data that is anonymous is considered free of privacy risk and available for public use.
Yet much data that is collected and used exists somewhere on a spectrum between these stages. FPF’s De-ID Project has examined practical frameworks for applying privacy restrictions to data based on the nature of data that is collected, the risks of de-identification, and the additional legal and administrative protections that may be applied.

The Curse of Dimensionality: De-identification Challenges in the Sharing of Highly Dimensional Datasets
The 2006 release by AOL of search queries linked to individual users and the re-identification of some of those users is one of the best known privacy disasters in internet history. Less well known is that AOL had released the data to meet intense demand from academic researchers who saw this valuable data set as essential […]

Twelve Privacy Investments for Your Company for a Stronger 2025
FPF has put together a list of Twelve Privacy Investments for Your Company for a Stronger 2025 that reflects on new perspectives on the work that privacy teams do at their organizations. We hope there is something here that’s useful where you work, and we’d love to hear other ideas and feedback. Privacy Investments for Your […]

FPF’s Year in Review 2024
With contributions from Judy Wang, Communications Intern 2024 was a landmark year for the Future of Privacy Forum, as we continued to grow our privacy leadership through research and analysis, domestic and global meetings, expert testimony, and more – all while commemorating our 15th anniversary. Expanding our AI Footprint While 2023 was the year of […]

Knowledge is Power: The Future of Privacy Forum launches FPF Training Program
“An investment in knowledge always pays the best interest”–Ben Franklin Let’s make 2023 the year we invest in ourselves, our teams, and the knowledge needed to best navigate this dynamic world of privacy and data protection. I am fortunate to know many of you who will read this blog post, but for those who I […]
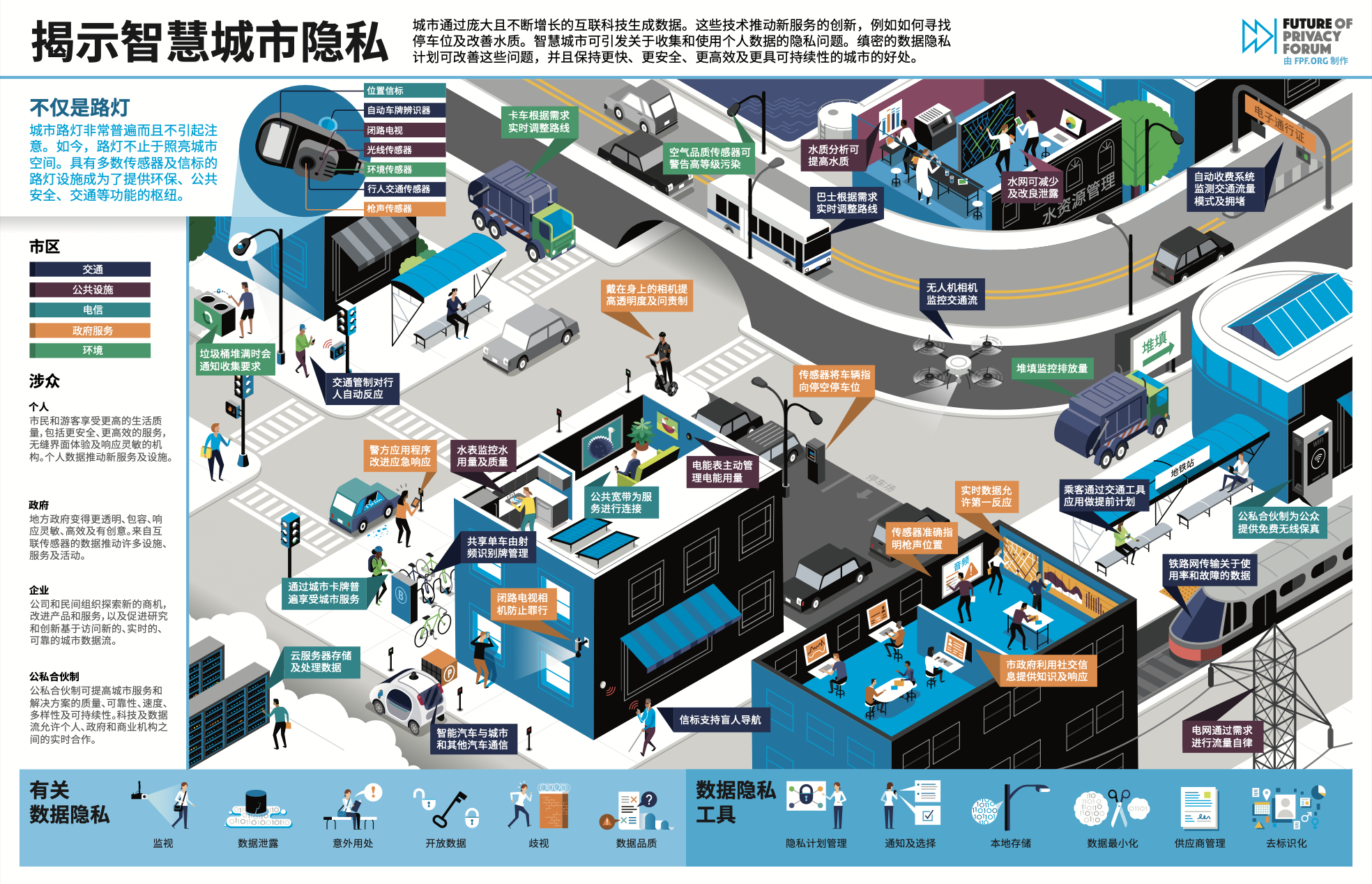
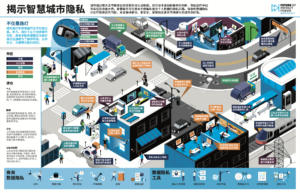
FPF Launches Infographics in Chinese
As FPF’s work expands to include an international audience, we are pleased to relaunch FPF’s popular infographics in various languages. Because conversations around data protection have become more global, the need for high-quality information and new forms of communication in different languages continues to increase. The infographics translation project aims to help FPF provide a […]

A New Era for Japanese Data Protection: 2020 Amendments to the APPI
The recent amendments to Japan’s data protection law contain a number of new provisions certain to alter – and for many foreign businesses, transform – the ways in which companies conduct business in or with Japan.
CCPA 2.0? A New California Ballot Initiative is Introduced
Introduction On September 13, 2019, the California State Legislature passed the final CCPA amendments of 2019. Governor Newsom is expected to sign the recently passed CCPA amendments into law in advance of his October 13, 2019 deadline. Yesterday, proponents of the original CCPA ballot initiative released the text of a new initiative (The California Privacy […]
The Right to Be Forgotten: Future of Privacy Forum Statement on Decisions by European Court of Justice
WASHINGTON, DC – September 24, 2019 – Statement by Future of Privacy Forum CEO Jules Polonetsky regarding two European Court of Justice decisions announced today in its cases with Google: Key decisions about the balance of privacy and free expression still remain to be settled by the European Court of Justice (ECJ). Although the ECJ’s […]

California’s AB-1395 Highlights the Challenges of Regulating Voice Recognition
Under the radar of ongoing debates over the California Consumer Privacy Act (CCPA), the California Senate Judiciary Committee will also soon be considering, at a July 9th hearing, an unusual sectoral privacy bill regulating “smart speakers.” AB-1395 would amend California’s existing laws to add new restrictions for “smart speaker devices,” defined as standalone devices “with […]

FPF Comments on the California Consumer Privacy Act (CCPA)
On Friday, the Future of Privacy Forum submitted comments to the Office of the California Attorney General (AG), Xavier Becerra. Read FPF’s Full Comments (11-page letter) See Attachment 1: Comparing Privacy Laws: GDPR vs. CCPA See Attachment 2: A Visual Guide to Practical De-identification In FPF’s outreach to the AG, we commended the office for its […]