Let’s Look at LLMs: Understanding Data Flows and Risks in the Workplace
Over the last few months, we have seen generative AI systems and Large Language Models (LLMs), like OpenAI’s ChatGPT, Google Bard, Stable Diffusion, and Dall-E, send shockwaves throughout society. Companies are racing to bake AI features into existing products and roll out new services. Many Americans are worrying whether generative AI and LLMs are going to replace them in the workforce, and teachers are downloading ChatGPT specific software to ensure their students are not plagiarizing homework assignments. Some have called for a pause to AI development. But organizations and individuals are adopting LLMs more quickly, and the trend shows no signs of abating.
Organizations have quickly seen employees using generative AI and LLM tools in their workstreams. Few workers are waiting for permission to use the technologies to speed up complex tasks, get tailored answers to full-sentence questions, or draft content like marketing emails. However, the growing use of LLMs creates risks, such as privacy concerns, content inaccuracies, and potential discrimination. Use of LLMs can also be deemed inappropriate in certain contexts and create discontent–students recently criticized their university for lacking empathy when the school used ChatGPT to draft an email notice about a nearby mass shooting.
As organizations navigate these uncertainties, they are asking whether, or when, employees should be permitted to use LLMs for their work activities. Many organizations are establishing or considering internal policies and guidelines for when employees should be encouraged, permitted, discouraged, or prohibited from using such tools. As organizations create new policies, they should be aware that:
1. When workers share personal information with LLMs, it can create legal obligations for data protection and privacy, including regulatory compliance;
2. Many organizations will need to establish norms for originality and ownership, including when it is appropriate for employees to use LLMs or other generative AI systems to create novel content;
3. Organizations need to carefully evaluate any uses for potential bias, discrimination, and misinformation while also considering other potential ethical concerns.
What are LLMs?
In late 2022, OpenAI released its AI chatbot, ChatGPT, which has now undergone several versions and is available as ChatGPT-4. ChatGPT is both a generative AI and a large language model (LLM), which are two distinct but similar AI terms. A “generative AI system” is a type of AI that has been trained on data so that it can produce or generate content similar to what it has been trained on, such as new text, images, video, music, and audio. For example, a growing number of AI tools are available for generating artwork and some even create videos based on text. A “large language model” (LLM) is a type of generative AI that generates text. LLMs can perform a variety of language-related tasks, including translations, text summarization, question-answering, sentiment analysis, and more. They can also generate text that mimics human writing and speech, which have been used in various applications such as chatbots and virtual assistants. To produce human-like responses, LLMs are trained on vast quantities of text data. In ChatGPT’s case, it was trained on vast amounts of data from the internet.
#1. Legal Obligations.
a. Data protection and privacy.
In general, users of generative AI and LLMs should avoid inputting personal or sensitive information into ChatGPT or similar AI tools. ChatGPT uses the data that is input by many users to generate individual responses and further train its model for future responses to all users. If an employee inputs data that contains confidential information, such as trade secrets, medical records, or financial data, then that data may be at risk, especially if there is a data breach of the AI system that results in authorized access or disclosure. Similarly, if an individual puts personally identifiable information or sensitive data into the model, and that data is not properly protected, it could also be improperly accessed or used by unauthorized individuals.
Furthermore, personal information disclosed to LLMs could be used in additional ways that violate the expectations of the people to whom the information relates. For example, ChatGPT also continues to use and analyze this data. Thus, the sensitive information that an employee inputs about a customer or patient could potentially be revealed to another user if they pose a similar question or prompt. Further, every engagement with ChatGPT has a unique identifier–there is a login trail of people who are using it. Therefore, an individual’s use of ChatGPT is not truly anonymous, raising questions about the retention of sensitive data by OpenAI.
b. Regulatory Compliance.
LLMs are subject to the same regulatory and compliance frameworks as other AI technologies, but as LLMs become more common, they can raise novel questions of how such tools can be used in ways that comply with the General Data Protection Regulation (GDPR) and other regulations. Since ChatGPT processes user data to generate responses, OpenAI or the entities relying on ChatGPT for their own purposes may be considered data controllers under the GDPR, which means they should secure a lawful ground to process users’ personal data (such as users’ consent) and users must be informed about the controller’s ChatGPT-powered data processing activities.
OpenAI and companies relying on ChatGPT’s capabilities also need to consider how overarching GDPR principles like data minimization and fairness curtail certain data processing activities, including decisions made on the basis of algorithmic recommendations. Additionally, under the GDPR, data subjects have certain rights regarding their personal data, including the right to access, rectify, and delete their data. But can users really exercise these rights in practice? In regard to data erasure, OpenAI offers users the ability to delete their accounts, but OpenAI has stated that conversations with ChatGPT can be used for AI training. This presents challenges because while it seems that the original input can be deleted, the input can be used to shape and overall improve ChatGPT. Removing a user’s complete digital footprint and its effects on ChatGPT may be unfeasible and risks offending the GDPR’s “right to be forgotten.” Moreover, the repurposing of prompts to train OpenAI’s algorithm may raise issues relating to the GDPR’s purpose limitation principle, as well as the applicable lawful ground for service improvement after a recent restrictive binding decision from the European Data Protection Board (EDPB) concerning the lawfulness of processing for service improvement purposes.
There are questions about the future regulation of ChatGPT and similar technologies under the European Union (EU) Artificial Intelligence Act (AI Act), which is currently under review by the European Parliament. Proposed in 2021, the regulation is designed to ban certain AI uses such as social scoring, manipulation and some instances of facial recognition. However, recent developments regarding LLMs and related AI services have caused the European Parliament to reassess “high-risk” use cases and how to implement proper safeguards that were not previously accounted for in today’s rapidly developing tech environment. EU lawmakers have proposed different ways of regulating general purpose and generative AI systems during their discussions on the text of the AI Act. The consensus at the EU Council is that the European Commission should regulate such systems at a later stage via so-called ‘implementing acts’; at the European Parliament, lawmakers may include such systems in the AI Act’s high-risk list, therefore subjecting them to strict conformity assessment procedures before they are placed on the market.
#2. Ownership and Originality.
Depending on context, organizations should determine when it is appropriate or ethical for individuals or organizations to use, or take credit for, work generated by LLMs. In education, for example, some teachers are adapting their approaches (e.g., from written to oral presentations) to avoid plagiarism. Schools have even banned ChatGPT due to concerns that the technology will cause students to take shortcuts when writing or forgo doing their own research.
In many cases, these issues raise novel questions about legal rights and liability. For example, software developers have used ChatGPT to write and improve existing code. Yet LLMs, including ChatGPT, have been shown to regularly produce inaccurate content. If an employee uses the code generated by ChatGPT in a product that interacts with the public, organizations may have liability if something goes wrong. In a related issue, if employees input copyrighted, patented, or confidential information (e.g. trade secrets), into a generative AI tool, the resulting output could infringe on intellectual property rights or breach confidentiality obligations.
#3. Ethical Concerns, Bias, Discrimination, and Misinformation.
Finally, organizations must carefully consider all uses of AI, including LLMs, for possible discriminatory outcomes and effects. In general, LLMs reflect the underlying data that they are trained on, which is often incomplete, biased, or outdated. For example, AI training datasets often exclude information from marginalized and minority communities, who have historically had less access to technologies such as the internet, or had fewer opportunities to have their writings, songs, or culture digitized. ChatGPT was trained on internet data, and as a result is likely to reflect and perpetuate societal biases that exist in websites, online books, and articles.
For example, a Berkeley professor asked ChatGPT to create code to determine which air travelers pose a safety risk. ChatGPT assigned a higher “risk score” to travelers who were Syrian, Iraqi, Afghan, or North Korean. A predictive algorithm used for medical decision-making was biased against black patients because it was trained on data that reflected historical bias. Even though the deployers of the algorithm excluded race as a metric when running the system, the algorithm still perpetuated bias against black patients because it took economic factors and healthcare costs into account.
Furthermore, it is clear that generative AI and LLMs can be potentially disruptive and change the way we consume and create information. ChatGPT has demonstrated its ability to write news articles, essays, and television scripts. Supplied with a prompt loaded with disinformation or misinformation, LLMs can produce convincing content that could mislead even thoughtful readers. Audiences are at risk of consuming vast amounts of misinformation if they are not able to fact-check the information given to them or know that content was generated by an LLM or AI. Organizations that use LLMs should be aware that LLMs can generate inaccurate or misleading information, even when prompts are not intended to mislead. Vigilance is required when organizations ask LLMs or generative AI to give clients, customers, or users information solely based on the LLM.
To address ethical concerns, bias, discrimination, and misinformation, organizations have a responsibility to scrutinize their use of generative AI and LLMs. Ethical considerations are incredibly important and progress is being made on transparency in generative AI models, though complete solutions remain elusive. Ethical considerations are especially important when the AI is used in an outcome-determinative way, such as in hiring or healthcare. In some cases, such uses will risk running afoul of employment or other civil rights laws. Organizations must determine the different contexts that this type of AI use can be particularly susceptible to bias and discrimination, and will want to avoid those situations. Organizations should engage and talk to the communities that are most affected in these cases and get stakeholder input when drafting internal policies.
Conclusion
Recent developments concerning LLMs and generative AI demonstrate substantial technological advancements while also presenting many uncertainties. There are many unanswered questions and yet to be discovered risks that may result from use of AI in the workplace. However, these harms can be mitigated if organizations take the time to address these issues internally and develop best practices. We encourage organizations to be inclusive and cross-collaborative when engaging in these conversations with lawyers, engineers, customers, and the public.
FPF Report: Not-So-Standard Clauses – An Examination of Three Regional Contractual Frameworks for International Data Transfers
On March 30, the Future of Privacy Forum launched a new report comparing three regional model contractual frameworks for cross-border data transfers. The report compares the EU’s Standard Contractual Clauses (SCCs), the ASEAN Model Contractual Clauses (MCCs), and the Iberoamerican Network’s Model Transfer Agreement (MTA). The three frameworks cover a total of 62 jurisdictions on three continents – this report seeks to identify overlaps and key differences among the three, while also reflecting on the question of their potential interoperability. Notably, this report does not evaluate contractual frameworks created by individual countries (such as the recently released Chinese Standard Contract Provisions) or frameworks that are still in the development process, like the recently-amended draft Convention 108+ Model Contractual Clauses for the Transfer of Personal Data still being developed by the Council of Europe.
International transfers of personal information are an increasingly contentious space in the privacy and data protection world. As more jurisdictions pass laws and develop regulations governing the collection and processing of personal data, necessarily more limitations on the transfer of that information from one jurisdiction to another follow. Exceptions to those restrictions go hand-in-hand with those generalized restrictions on cross-border data transfers; in that context, pre-approved contractual frameworks between transferor and transferee have emerged as critical components of the modern cross-border data transfer environment.
These contractual frameworks set out the responsibilities of the parties to a data transfer, mandating to a greater or lesser extent what information those parties must provide to one another, members of the public, and relevant government authorities while also covering issues ranging from the distribution of liability to the parties’ responsibility to evaluate the laws of destination jurisdictions. This Report outlines how the three chosen frameworks are similar and where they are different in a number of key areas, including:
Underlying Legal Basis for Use of Contractual Framework
Core Party Obligations
Data Subject and Third Party Rights
Response to Government Requests
Relevance to Cross-Border Enforcement
Permissibility of Modifications
This Report also includes a number of Annexes that seek to set summaries of particularly important provisions side-by-side, organized by the type of provision or the specific party it binds.
Our analysis has determined that while the international space for cross-border transfers has begun to converge on some core concepts (such as classifying parties as “controllers” and “processors” as well as “importers” and “exporters”) and on some key obligations for parties (such as requiring a certain degree of transparency regarding each transfer, and imposing basic security requirements on parties) there remain significant areas where data transfer contracts diverge. As a baseline, the most critical element of any model contractual framework is how it interacts with the underlying legal obligations imposed on the parties it binds. Here, the EU SCCs and their relationship to the GDPR by necessity have a different structure than either the Ibero-American MTA or the ASEAN MCCs, designed as they are to interact with multiple jurisdictions governed by different (or lacking entirely) data protection laws. Additional issues include whether and how contracts should acknowledge third party rights, whether contracts should treat different types of processing or personal data differently, the parties’ responsibilities in the event of government requests for data, and whether specific concepts like the use of automated decision-making or the processing of children’s information should be addressed.
On July 28, 2022, the African Union (AU) released its Data Policy Framework (Framework) following extensive multi-stakeholder engagements. The Framework aims to provide a multi-year blueprint for how the AU will accomplish its goals for Africa’s digital economy. It also sets forth the AU’s vision, scope, and priorities for Africa’s data ecosystem, the regulatory policies underpinning the digital economy, and the creation of the African Digital Single Market (DSM). Broadly, the Framework provides data governance guidance for Africa’s data market by helping Member States navigate complex regulatory issues. The goal of the Framework is to bolster intra-African digital trade, entrepreneurship, and digital innovation while safeguarding against risks and harms of the digital economy.
The Framework builds off the work of the Digital Transformation Strategy (DTS), which the AU adopted in 2020 to spur digital development across the continent, as well as other prior initiatives such as the Africa Continental Free Trade Agreement (AfCTFA) and the Policy and Regulatory Initiative for Digital Africa (PRIDA). African leaders created the Framework to respond to identified needs, opportunities, and risks of the digital economy, including the need to re-think policy around data and its relationship to larger social goals and institutions. In particular, the Framework recognizes that while data may create value, it also brings harms that regulators must address. The AU acknowledges the vast ongoing transformations to regional and global data policies and the need for African leadership to promote harmonization of legal frameworks across the continent.
Notably, the Framework contains many features that align with international approaches to data protection such as the need to root data policy in the rule of law, protect fundamental rights, and strike an appropriate balance between innovation and privacy. However, it also conveys unique and nuanced views on key emerging issues, including:
Separating data sovereignty (a principle it generally supports) from data localization under the guise of data security, and taking a stance against using security policies to undermine human rights;
Dissuading Member States from adopting broad data localization requirements. Rather, focus on localization for certain categories of data to ensure broad flow of data in line with policies such as the African Free Continental Free Trade Area Agreement.
Highlighting areas where Member States can take novel approaches that fit the context of Africa, including prioritizing collective privacy rights and the need for data stewardships and other forms of data trusts; and
Contextualizing the Framework within the larger process of creating a digital single market to assert Africa’s voice in ongoing global policy conversations and indicate that Member States will no longer be “standard takers” of data protection policy but rather “standard makers” in the future.
This blog post provides a descriptive analysis of the Data Policy Framework to draw attention to key data protection proposals under it. It does not identify challenges of the Framework or delve into specific policy priorities. Rather, we summarize the scope of the Framework and offer a reference guide to understand its contents.
The Framework consists of six sections, each detailing a core feature of how regulators should balance policy harmonization across Member States with respect to digital policy. These sections include: (i) guiding principles, (ii) definitions and categorization of data, (iii) value enablers, (iv) data governance, (v) international and regional governance, and (vi) an implementation framework.
1. Guiding Principles: From Sovereignty, to Fairness and Inclusiveness
The Framework sets forth high-level principles to guide data policy creation and harmonization across Africa. These principles primarily apply to African Union Member States but extend to other stakeholders such as public-private partnership bodies, civil society organizations, regional cooperation fora, and other entities engaging in the digital economy. The principles aim to ensure that the creation and adoption of digital rules aligns with international law and standards and remains balanced. These principles include:
Cooperation –Stakeholders (including private, public, and civil society bodies) should cooperate to foster exchange and interoperability of data systems within the African Digital Single Market, as well as promote coherence and harmonization of policies;
Integration –Policies should remove legal barriers to intra-African data flows subject to necessary data protection, human rights, and security considerations;
Fairness and Inclusiveness –Benefits and opportunities of the digital economy should be equitable and inclusive to redress national and global inequalities to those marginalized by technological developments;
Trust, Safety, and Accountability –Policies should promote a trustworthy data ecosystem that is safe, secure, accountable, and ethical to stakeholders;
Sovereignty –Stakeholders shall cooperate to enable Member States to self-manage, govern, and utilize data;
Comprehensive and Forward-Looking –Policies should strive to create an environment that promotes investment and innovation through the development of infrastructure, human capacity, and harmonized regulations and legislations; and
Integrity and Justice –Member States must ensure the collection, processing, and usage of data is just, lawful, and not used to discriminate or infringe on individual rights.
2. (Not) Defining and Categorizing Data
The Framework does not define data, stating that the variety of uses and types of data pose practical constraints to formulating a comprehensive definition. However, the drafters highlight that a better understanding of how data functions within the larger technological and digital ecosystem will help support policymaking.
The Framework proposes that Member States—and their data protection authorities (DPAs) in particular—categorize data to clarify and differentiate between different types of data, including personal and non-personal information. This clarification will aid companies’ compliance strategies to align their collection, storage, and use of data with data protection regulations. Furthermore, specifying the types of data, especially personal data, could help DPAs to more efficiently protect and uphold data subject rights.
3. Driving Value in the Digital Economy
Recognizing the power of data to transform economies and facilitate development, the Framework recommends Member States to create an environment that captures the value of the data economy while also preventing harms. In particular, the Framework encourages the creation of dependable regulatory systems to facilitate trust and enhance human, institutional, and technical capabilities to create value from data. The Framework highlights five areas of focus: (i) foundational infrastructure and trustworthy systems, (ii) institutional arrangements for complex regulation, (iii) the need to rebalance the legal system, (iv) create public value, and (v) promote coherent sectoral policies.
Enhanced research and development (R&D) plays a prominent role in the Framework, which encourages further investment in fields such as big data analytics, artificial intelligence, blockchain, and quantum computing. For each of these areas, the Framework stresses the need to place the digital economy within the wider complexities of the digital ecosystem, giving special attention to the role of the state in processing data.
The AU recognizes that digital infrastructure is the backbone of the data-driven economy and stresses the need for Member States to coordinate on investment and development. The Framework proposes policy recommendations for deploying broadband, enabling information communication technology (ICT) architectures, and creating trustworthy digital ID systems through public-private partnerships to spur entrepreneurship and public data reuse. Member states are encouraged to build stakeholder engagement at all levels to ensure organizations use data to further public interests. Specific foundational infrastructures identified include:
Cloud computing, including cloud services and cloud-based services, to spur system efficiency and reduce capital expenditure on IT equipment, internal servers, storage resources, and software;
Big data services for both the public and private sector to improve decision-making, forecasting, and consumer segmentation; and
“Platformization” for new business models and e-commerce services to facilitate trade across geographical borders.
Additionally, the Framework identifies the importance of creating trustworthy data systems to underpin the larger political, economic, and societal environment. AU policymakers stress that a key aspect of this system includes safeguarding basic human rights through the rule of law. The continental challenge is to ensure Member States have all the necessary tools and legal requirements to adapt to rapidly evolving technological challenges. To this end, the Framework proposes a comprehensive benchmarking policy centered around five interrelated considerations:
Cybersecurity – The Framework recognizes that while regulatory tools to strengthen cybersecurity can mitigate vulnerability threats, they can also if misused, undermine fundamental rights of equity, dignity, and security. Policies should therefore be proportional and limit infringement on online human rights;
Cybercrime – The Framework stresses that governments must tailor policies to implement regional and global conventions on cybercrime.
Data Protection – According to the AU, data protection forms the backbone of any data framework as it helps ensure that organizations do not harm individuals when processing their personal data. Data protection policies must fit particular contexts and be adaptive to user interaction and capability online. The Framework cautions against relying too heavily on consent as a regulatory mechanism and promotes other concepts like data stewardships;
Data Justice – The Framework states that in order to expand the safeguarding of rights from the individual to the collective level, Member States should promote data justice in their policies. Data justice extends to social and economic rights to redress inequalities resulting from historical, structural, and discriminatory injustice that have been reproduced through digital technologies; and
Data Ethics – Codes of ethics developed by all stakeholder groups can guide the use and design of systems that run on data. The Framework recommends leveraging such codes to mitigate harm in particular technological contexts. The creation of such codes must be as inclusive as possible.
The Framework recommends Member States establish policies that bolster these five considerations to foster trust and safeguard basic human rights through rule of law at the regional and continental levels.
Highlighting that data economies require future-facing, agile regulatory systems, the Framework specifies areas where regulators can work proactively and recommends Member States to prioritize building regulatory capacity and avoiding regulatory silos.
Of note, a key recommendation is for Member States to enable data regulators – Member States should create conditions that build institutional capacity and capabilities to optimize the potential use of data for enforcement mechanisms across sectors. Regulators that have wide authority and competence over data generally may also help to address issues resulting from competition and consumer protection law. Member States should also create a transparency portal to monitor data breaches and consumer data flows.
The Framework proposes concrete recommendations for each of these considerations and recognizes that data regulation cannot happen unless authorities have capacity both internally within Member States and externally on the regional and continental level in collaboration with other regulators. As a result, the AU places special emphasis on regional harmonization mechanisms.
The Framework also identifies key challenges for regulatory coordination including incoherent sectoral policies and incompatible regulatory goals. After outlining these areas and analyzing where regulatory tension could arise, it provides recommendations for overcoming challenges in competition, trade, data flows, and e-commerce policy. Notably, it specifies the privacy and data protection considerations in each of these policies and charts emerging variations in regulatory approaches to data transfers.
Member States are encouraged to harmonize sectoral policies and coordinate in regional fora on these regulatory issues. Complementary policy design choices can help regulators foster intra-African digital trade and data-enabled entrepreneurship while weighing trade-offs of data governance. The Framework recommends coordination in the following areas:
Competition policy instruments that address anti-competitive behaviors;
Data portability regulations, provisions, and other enabling activities for open data.;
Collaboration with international bodies like the OECD and the WTO;
Regional data infrastructures and data systems including human, technical, and institutional capacity; and
International harmonization of AI and big data technical standards, ethics, governance, and best practices.
4. Data Governance
The Framework sets forth a multi-prong strategy for data governance on the continent to enable data access and use while encouraging data combination and repurposing to limit the harms and risks of processing. The strategy prioritizes using data for its greatest economic and social value but recognizes that restricting data flows will be necessary in some circumstances to ensure societal protection.
The Framework recognizes that narrowly defining data governance to just encompass data protection is a risk within most African countries. Rather it acknowledges that data governance interacts with other disciplines including competition, cybersecurity, electronic transactions, and intellectual property. For this reason, the Framework proposes a multi-prong strategy for understanding and tackling these related policy areas. The prongs of this strategy include: data control, processing and protection, access and interoperability, security, cross-border flows, data demand, and special categories of data.
Data Control
The Framework recognizes the importance of facilitating the control of data for individuals, firms, and government and the need for policy to clarify the obligations and responsibilities of parties to find an appropriate balance that governs when entities may control data. The AU stresses that Member State policies should at a minimum design data subject rights to provide personal data control, but the AU also points towards emerging ownership models such as data trusts and stewardships as alternatives to the individual-rights focused model.
On the national level, the Framework recognizes data sovereignty and localization as two mechanisms through which states currently exert control over data, but cautions against pursuing both without specifically tailored reasons.
Data Sovereignty – The Framework recognizes that AU Member States have a right to formulate digital rules in line with their national interests and that such states should prioritize politically neutral partnerships to avoid foreign interference into domestic affairs. Exertion of domestic sovereignty should be based on multilateral agreements with recourse avenues for cases of infringement.
Data Localization – The Framework states that localization must be evaluated against potential harms to human rights and generally cautions against adopting such measures. Localization requirements, if adopted, should be as specific as possible and involve multi-stakeholder engagement to avoid over-restrictive policies.
Data Processing and Protection
The AU stresses the need to construct robust data protection mechanisms for the processing of personal data, including the promulgation of data subject rights. Such mechanisms are encouraged to realize privacy, foster trust in digital technologies, and create a sound digital economy. The Framework recognizes the need to ensure that constraints to personal information processing do not impede data flows and for Member States to harmonize policies across regions.
Additionally, the Framework urges Member States to implement a privacy-by-design approach that incentivizes organizations to incorporate privacy into new technology by default via design and development processes. The Framework identifies de-identification (including anonymization and pseudonymisation) in its outline, but also acknowledges that such techniques must be accompanied by strong legal rights for data subjects and regulatory capacity to enforce data protection. Specific recommendations in the Framework include:
Creating independent, funded, and effective data protection authorities (DPAs) that are accountable and cover all relevant data processing entities. DPAs should drive multi-stakeholder partnerships across the continent;
Requiring data protection risk assessments (DPIA) for the deployment of new technologies; and
Promulgating codes of conduct to promote sector-specific needs and ensure best practices in mitigating risks and harms associated with processing.
Data Access and Interoperability (Open Data)
The Framework stresses the need for Member States and regional institutions to take proactive measures to spur data access through open government data, as well as broader data portability to facilitate access and consumer benefits. In particular, the Framework recommends creating open data standards for public data, strengthening data portability rights and policies, promoting data partnerships, and facilitating data categorization. It also urges Member States to establish open data policies, DPAs to issue codes of conduct, and multi-sectoral bodies to implement open data initiatives. Policymakers should make use of regulatory sandboxes and other data hubs to promote data use and management.
Data Security
Throughout the Framework, AU policymakers acknowledge the importance of data security for preserving privacy, confidentiality, and integrity, as well as building trust in the larger digital ecosystem. Data security refers not only to the physical security of hardware systems but also the logical security of networks, applications, and software and the norms and regulations underpinning such systems. The Framework points to the following areas of focus:
Data Security and Localization – The Framework highlights the importance of not allowing data security to serve as a barrier to the free flow of data or a justification for data protectionism. Data security may positively enhance integrity and trust but also undermine other values if used for negative ends;
Transparency Challenges – The Framework also specifies the difficulties of upholding transparency via data security policies. To promote transparency, policymakers should increase efforts to coordinate on incident and vulnerability reporting, adhere to international cybersecurity standards, and create mature markets for cybersecurity and data processing. DPAs and policymakers should especially focus on building capacity and specify data processing roles for security protection; and
Regional Coordination – The Framework recommends Member States establish a joint sanction regime for cyber-attacks across Africa to promote interoperability and coordination of cybersecurity regimes.
Cross-Border Data Flows
The Framework stresses the importance of aligning national personal data regulations with other African jurisdictions’ regulations to foster trust and data exchange. The Framework acknowledges emerging tensions in cross-border data flows, like the relationship between data sovereignty and cross-border data flows, as well as the regulation of data flows in environments that lack comprehensive data protection laws. Specific recommendations to Member States to facilitate cross-border data flows include:
Providing minimum standards for cross-border data flows;
Enshrining reciprocity as a central principle for permitting such flows;
Prioritizing data specificity to avoid unintended restrictions;
Incorporating law enforcement considerations into policymaking; and
Building enforcement capacity and regional coordination.
Data Demand, Sectoral Governance, and Special Categories of Data
The Framework acknowledges the need to bolster data demand across sectors and avoid creating data silos that render data less usable. To promote access to data, the Framework recommends Member States to clearly identify special categories of data and employ codes of conduct for specific sectors to help organizations comply with regulatory expectations. Special data regimes should be integrated into national data regimes to avoid regulatory distortion. To address potential risk of harm to specific groups, the Framework stresses the need to identify and include different data communities into the policymaking process when crafting special categories of data. Although the AU recognizes that special treatment of data based on its particular characteristics is necessary, the Framework stresses that such policies should be in harmony with general data governance principles.
5. International and Regional Governance
The AU recognizes the importance of promoting cooperation between countries to increase dialogue and enforcement coordination. Over the next few years, the AU will develop a consultation framework for interstate collaboration, strengthen links with other regions such as the EU and APAC to coordinate Africa’s common position on data in international negotiations and support the creation of a continental data infrastructure to enable data-driven technologies.
The Framework acknowledges the importance of aligning Africa’s technical standards with internationally-recognized best practices but also states that such standards may not be sufficient for the continent’s unique needs. Rather, regional engagement on standards should take priority. One area outlined in the document where African policymakers can exert leadership is open data arrangements. The Framework specifies initiatives such as the African Development Bank’s central open-data portal, institutional data portals, and volunteer-driven community data sharing initiatives as unique examples of facilitating data sharing and creating a collaborative digital ecosystem.
Continental Instruments and Regional Institutions
The AU stresses the need to develop and bolster continental instruments and institutions to accomplish core goals, such as facilitating data flows while ensuring data protection and safety online.
The Framework calls for the creation of a regional cross-border data flow mechanism, the ratification of the Malabo convention, and the implementation of the African Continental Free Trade Agreement. The Framework also gives priority to the RECs and various human rights courts in Africa to coordinate governance and identifies other bodies like the African Network of Data Protection Authorities, ICT regulatory associations, and the African Competition Forum that could likewise play a role in fostering cross-border transfer rules.
6. Implementation Framework and Stakeholder Mapping
Finally, the Framework proposes an implementation framework divided into five phases and identifies important stakeholders for each phase of implementation.
Phase 1: Member States would adopt the Framework and work with the AU to develop mechanisms to monitor and centralize regional engagement;
Phase 2: to establish buy-in, the policy recommends ensuring alignment with continental instruments, engaging continental and regional structures like the RECs, and assessing international frameworks.
Phase 3: institutions would work towards developing broadband infrastructure and regulatory frameworks before engaging with stakeholders from all sectors
Phase 4: institutions would evaluate domestic policy instruments; and
Phase 5: the AU will prioritize intra-African collaboration with RECS and other continental institutions.
Conclusion
As the most ambitious policy document on data regulation in Africa to date, the Framework represents the AU’s desire to form a lasting roadmap for how African nations can safely and responsibly leverage the power of data through the creation of an African Digital Single Market. The Framework attempts to instill broad principles of transparency and accountability of institutions and actors into the fabric of national and regional approaches to data regulation. It prioritizes the inclusion of multiple stakeholders from both the public and private sectors, equity among citizens, and fair competition amongst market players. It also focuses on regional processes, mechanisms, and instruments that stakeholders can leverage to develop a cohesive data policy framework across the continent.
Particularly for data protection and privacy on the continent, the Framework is significant because it centers part of the proposed solutions on data protection that is recognized as the “backbone” of any data framework, while at the same time advancing ideas such as the prioritization of collective privacy rights, fit for the African context. Data justice and data ethics are other pillars proposed for advancing digital policies, in recognizing that economic growth and value from digital markets must not come at the expense of the rights of people and communities.
Concerns about a coherent cross-border data transfers policy for the continent add to the focus on data protection and privacy of the Framework. A significant contribution made is also separating the concept of “data sovereignty” from that of “data localization” under the guise of data security, and taking a stance against using security policies to undermine human rights. The Framework recognizes there is value in data-sovereignty-inspired policies, but understood as a more complex concept and different than mere data localization mandates, which may in fact be more harmful to the rights of individuals and communities.
At its heart the Framework calls on Member States in Africa to collaborate through regional institutions such as the Network of African Data Protection Authorities and relevant stakeholders towards regional and continental harmonization of digital policies. Like African Continental Free Trade Area Agreement and other initiatives, the Framework is designed to spur the creation of a common digital market. The AU stresses that collaboration between national and regional stakeholders is necessary for African countries in their aim to become more competitive in global policy fora. As such, the Framework attempts to set the foundation for African policymakers to engage with stakeholders on a broad set of data regulation issues and prioritizes intra-Continental collaboration through regional institutions.
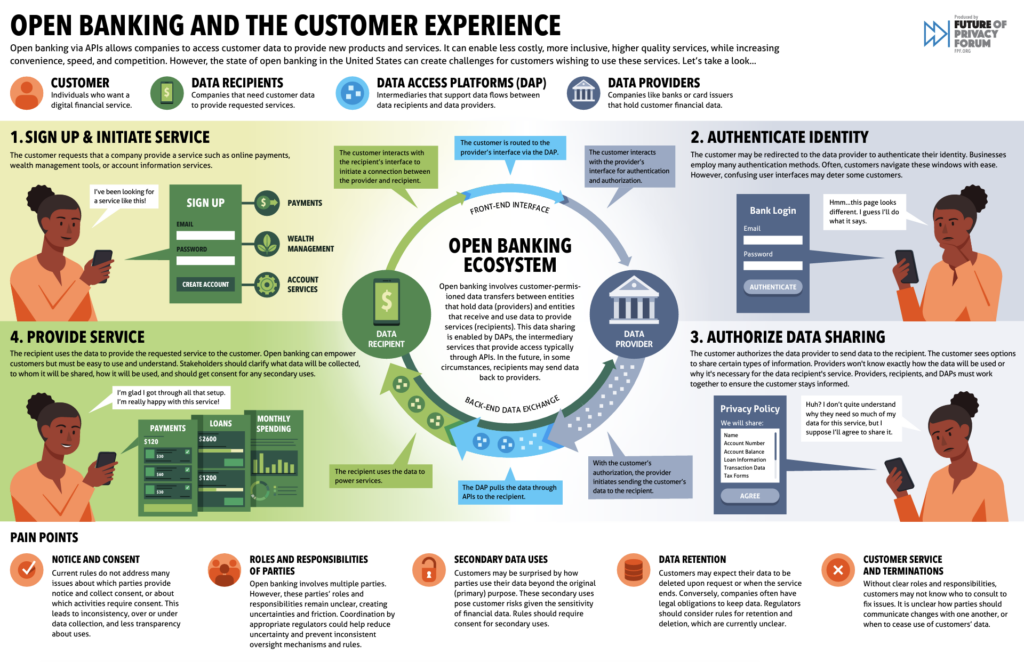
FPF Releases Infographic to Explore Implications of Open Banking Data Flows and Security for Individuals
Today, the Future of Privacy Forum (FPF), a global non-profit focused on privacy and data protection, is pleased to release an infographic, “Open Banking And The Customer Experience,” visualizing the US open banking ecosystem. FPF’s open banking infographic is supported by over a year of meetings and outreach with leaders in banking, credit management, financial data aggregators, and solution providers to comprehensively understand the developing industry of open banking.
Open banking involves customer-permissioned data transfers between organizations holding data and entities that provide financial products and services (e.g., wealth management, payments, and loan access). Open banking is organized around four main steps, including (i) signing up and initiating a service; (ii) authenticating identity; (iii) authorizing data sharing; and (iv) provision of the product or service.
Open banking can be a catalyst for greater competition by enabling new products and services that depend on the sharing of personal data. While the sharing of personal data is integral to realizing these benefits, it is not without privacy and security risks, including the risk of data breaches and unauthorized transactions. The US open banking ecosystem can also be confusing for customers wishing to use these products and services as well as the organizations that provide them, including in areas related to:
Parties’ roles and responsibilities: Open banking involves multiple parties, each with overlapping roles and responsibilities, creating uncertainties and friction for users. Coordination by appropriate regulators could prevent inconsistent oversight mechanisms and rules.
Notice and consent: Current rules are unclear about which activities in open banking require consent, and from whom. This may lead to inconsistency in data collection and less transparency about uses of personal data.
Secondary data uses: While companies may want to use customer data for purposes other than providing the requested product or service, misuse of financial data can cause harm, including financial loss, loss of account access, and disparate impact. To give customers greater understanding and control over the secondary use of their personal data, companies could be required to segregate secondary use consents from the primary use opt-in.
Data retention: Individuals seeking to have their data deleted by an organization may not understand why they are unable to do so. Greater transparency and clarity is required for organizations in the open banking ecosystem that are subject to legal requirements about retaining user information.
Customer service and terminations: Without clear roles and responsibilities, people engaged in open banking may not know who to consult to fix issues they encounter. Rules can help to clarify how parties should communicate changes with one another, or when to cease use of personal data.
The Consumer Financial Protection Bureau (CFPB) sought comments this year regarding data portability for financial products and services, which is a prerequisite to issuing a proposed rule later in 2023 to update Section 1033 of the Dodd-Frank Wall Street Reform and Consumer Protection Act. Subject to rules created by the CFPB, Section 1033 requires covered entities to make certain information related to a person’s requested products and services available to the person upon request.
In response to the CFPB request regarding data portability for financial products and services, FPF submitted comments in January 2023, which address the main pain points raised in this infographic in greater detail. FPF has also released a paper, Data Portability in Open Banking: Privacy and Other Cross-Cutting Issues, detailing how different jurisdictions’ laws impacted open banking activities and intersected with data protection law, including issues surrounding consent, security, and data subject portability rights. The paper provided grounds for discussion at an event FPF organized in 2022 with the Organization for Economic Co-Operation and Development (OECD). In February 2023, the OECD issued a paper of the same name about the event.
If you wish to speak with FPF about this infographic or would like to learn more about the organization’s Open Banking Working Group, please reach out to Zoe Strickland ([email protected]) and Daniel Berrick ([email protected]). For media inquiries, please reach out to [email protected].
This infographic would not have been made possible without the work of Hunter Dorwart, former FPF Policy Counsel, who devoted significant hours to this project during his time at FPF.
On November 15, 2022, the Future of Privacy Forum (FPF) and the Brussels Privacy Hub (BPH) of Vrije Universiteit Brussel (VUB) jointly hosted the sixth edition of the Brussels Privacy Symposium on the topic of “Vulnerable People, Marginalization, and Data Protection.” Participants explored the extent to which data protection and privacy law including the EU’s General Data Protection Regulation (GDPR) and other data protection laws like Brazil’s General Data Protection Law (LGPD) safeguard and empower vulnerable and marginalized people. Participants also debated balancing the right to privacy with the need to process sensitive personal information to uncover and prevent bias and marginalization. Stakeholders discussed whether prohibiting the processing of personal data related to vulnerable people serves as a protection mechanism or, on the contrary, whether it potentially deepens bias.
The event also marked the launch of VULNERA, the International Observatory on Vulnerable People in Data Protection, coordinated by the Brussels Privacy Hub and the Future of Privacy Forum. The observatory aims to promote a mature debate on the multifaceted connotations surrounding the notions of human “vulnerability” and “marginalization” existing in the data protection and privacy domains.
The Symposium was started with short introductory remarks by Jules Polonetsky, FPF’s CEO, and Gianclaudio Malgieri, Associate Professor at Leiden eLaw and BPH’s Co-Director. Polonetsky stressed the importance of understanding that privacy increasingly intersects with other rights and issues. Malgieri offered an overview of VULNERA and incentivized participants to reflect on important questions, such as whether data protection law could serve as a means to address human vulnerabilities and marginalization.
Throughout the day, there were two keynote addresses by Scott Skinner-Thompson, Associate Professor at the University of Colorado Boulder and Hera Hussain, Founder and CEO of Chayn, a nonprofit providing online resources for survivors of gender-based violence, followed by three panel discussions, a brainstorming exercise with the Symposium’s attendees in four different breakout sessions, and closing remarks delivered by FPF’s Vice President for Global Privacy, Gabriela Zanfir- Fortuna, and the European Data Protection Supervisor (EDPS), Wojciech Wiewiórowski.
This Report outlines some of the most noteworthy points raised by the speakers during the day-long Symposium. It is divided into seven sections: the above general introductions; the ensuing section, which covers the remarks made during the Keynote Speeches; the next three that summarize the content of the discussions held during the panels; the sixth one that touches on the exchanges audience members had during the breakout sessions; and the seventh and final one that provides highlights of the EDPS’s closing remarks.
Iowa Senate Advances Comparatively Weak Consumer Privacy Bill
By Keir Lamont & Mercedes Subhani
Update: On March 28, Governor Kim Reynolds signed SF 262 into law, making Iowa the 6th state to enact a baseline consumer privacy framework.
Lawmakers in Iowa are considering the adoption of a new consumer privacy framework that would fall far short of comparable state privacy laws in terms of consumer rights, business obligations, and enforcement. On Monday, March 6th, the Iowa Senate passed SF 262, an Act relating to consumer data protection, by a 47-0 vote. Companion legislation, HF 346 is currently eligible for a vote in the Iowa House.
Iowa is one of several states that are currently seriously considering the enactment of privacy legislation, demonstrating a commendable focus on the protection of consumer data. However, the Iowa bill, while modeled after frameworks adopted in other states, nevertheless diverges significantly from the most protective state privacy laws.
In order to help stakeholders and policymakers assess Iowa’s privacy proposal, the Future of Privacy Forum is releasing a chart comparing SF 262 to the Connecticut Data Protection Act, which currently stands as one of the strongest and most interoperable state approaches for establishing privacy rights and protections.
At a high level, Iowa’s privacy proposal contains the following protections and notable omissions as compared to bills with similar models:
Instead of requiring that controllers obtain affirmative, opt-in consent for the collection and processing of consumers’ sensitive personal data, Iowa businesses would only need to provide notice and an opportunity to opt-out.
The Iowa bill would establish consumer rights to access, delete, and in certain cases, port their personal information, but does not grant a right to correct inaccurate personal information or to exercise these rights through authorized agents.
The Iowa bill creates a consumer right to opt-out of the “sale” of personal data (narrowly defined as exchanges for “monetary consideration”). It does not create an opt-out right for significant profiling decisions or clearly establish a right to opt-out of targeted advertising.
The Iowa bill would require businesses to disclose their data processing practices and to protect the security of consumer data, but it would not require businesses to conduct risk assessments or adhere to data minimization and use limitation standards.
The Iowa bill would provide for exclusive enforcement authority by the State Attorney General; businesses would have a 90-day right to “cure” any and all alleged violations of the Act.
FPF Files Comments with the National Telecommunications and Information Administration (NTIA) on Privacy, Equity, and Civil Rights
On March 6, the Future of Privacy Forum filed comments with the National Telecommunications and Information Administration (NTIA) in response to their request for comment on privacy, equity, and civil rights.
NTIA’s “Listening Sessions on Privacy, Equity, and Civil Rights,” drew attention to the well-documented and ongoing history of data-driven discrimination in the digital economy. When the digital economy functions properly, all individuals, regardless of race, gender, or other historically discriminated-against attributes, are able to equally access the benefits of technology, including better access to education and employment opportunities, while trusting that their personal data is protected from misuse. Individuals and communities can benefit from digital tools that provide important services regarding education, employment, housing, credit, insurance, and government benefits. In addition, society as a whole benefits from diverse individuals contributing different perspectives, ideas, and objectives without cause to fear discrimination or harm.
But when the digital economy reinforces human bias rather than combats discrimination, individuals suffer concrete harms, including artificially limited educational opportunities, reduced access to jobs and financial services, and more. At the same time, misuse of personal information can contribute to biased outcomes, undermine trust in digital services, or both.
FPF’s comments urge NTIA to include these three recommendations in its forthcoming report to advance protections for data privacy, equity, and civil rights in the US:
1. Support for Congressional efforts to pass a comprehensive federal privacy law that includes limitations on data collection, heightened safeguards for sensitive data use, support for socially beneficial research, and protections for civil rights, including protections regarding automated decision-making that has legal or similarly significant effects.
2. Support the administration to promote a common approach to privacy, AI, and civil rights among executive agencies in the agencies’ guidance to private entities and internally on the processing of personal information, and tech procurement processes.
3. Continue proactive engagement and meaningful consultation with marginalized groups in conversations regarding privacy and automated decision-making across the administration and federal agencies.
Race Equity, Surveillance in the Post-Roe Era, and Data Protection Frameworks in the Global South are Major Topics During This Year’s Privacy Papers for Policymakers Event
Author: Randy Cantz, U.S. Policy Intern, Ethics and Data in Research and former Communications Intern at FPF
The Future of Privacy Forum (FPF) hosted a Capitol Hill event honoring 2022’s must-read privacy scholarship at the 13th annual Privacy Papers for Policymakers Awards ceremony. This year’s event featured an opening keynote by FTC Commissioner Alvaro Bedoya as well as facilitated discussions with the winning authors: Anita Allen, Anupam Chander, Eunice Park, Pawel Popiel, Laura Schwartz-Henderson, Rebecca Kelly Slaughter, and Kate Weisburd. Experts from academia, industry, and government, including Olivier Sylvain, Neil Chilson, Amanda Newman, Gabriela Zanfir-Fortuna, Maneesha Mithal, and Chaz Arnett, moderated these policy discussions.
Stephanie Wong, FPF’s Elise Berkower Fellow, provided welcome remarks and emceed the night, noting this was the first time the award ceremony has met in-person after two years of virtual events due to the pandemic. Ms. Wong noted she was excited to present leading privacy research relevant to Congress, federal agencies, and international data protection authorities (DPAs).
FPF’s Stephanie Wong
In his keynote, Commissioner Bedoya was excited to celebrate privacy by highlighting some of the finest minds working on relevant technology policy issues. Commissioner Bedoya noted that events like Privacy Papers for Policymakers bring together the “brightest minds in technology speaking with the brightest minds in Congress” to determine which issues deserve special sectoral treatment. Commissioner Bedoya concluded his remarks by highlighting the aspects of the winning authors’ work that he finds most salient, stating that Professor Park’s work forces us to reckon with the reality that our health information cannot be confined to a neat box that lives at our doctor’s office; that Professor Weisburd’s work answers the fallacy that surveillance is passive, not a physical, lived experience and that surveillance is a form of punishment; that Professor Allen is a luminary who underscores the importance of seeing surveillance not as data collection, but rather by tracing the differential use of surveillance; that Professor Popiel and Laura Schwartz-Henderson grapple with challenges faced by DPA regulators; that Professors Anupam Chander and Paul Schwartz reveal a divergence between international trade and privacy norms; and that Commissioner Slaughter’s paper describes the harms of algorithmic bias and how to protect consumers from algorithmic harms.
FTC Commissioner Alvaro Bedoya
Following Commissioner Bedoya’s keynote address, the event shifted to discussions between the winning authors and expert discussants. The 2022 PPPM Digest includes summaries of the papers and more information about the authors.
Professor Anita Allen (University of Pennsylvania Carey Law School) kicked off the first discussion of the night with Olivier Sylvain (Senior Advisor at the Federal Trade Commission) by talking about her paper, Dismantling the “Black Opticon”: Privacy, Race Equity, and Online Data-Protection Reform. Professor Allen’s paper analyzes how African-Americans endure discriminatory oversurveillance, discriminatory exclusion, and discriminatory predation, which she calls the “Black Opticon,”and also highlights the role of privacy’s unequal distribution. During her conversation, Professor Allen discussed discriminatory surveillance and oversurveillance of the poor, why race-neutral policies aren’t enough to address discrimination, how commercial practices and reforms are unequally distributed along racial lines, and how the right to privacy emerged in the U.S.’s founding era when the concept of one’s privacy was used to protect slave owners and more recently, those who commit domestic abuse under the same guise of privacy.
Professor Anita Allen and Olivier Sylvain
Next, Professor Anupam Chander (Georgetown University Law Center), discussed his paper, Privacy and/or Trade, with Neil Chilson (Stand Together). Professor Chander’s paper, co-written with Professor Paul Schwartz of the UC Berkeley School of Law, explores the conflict between international privacy and trade. At the outset, Mr. Chilson outlined the paper’s four contributions to privacy law and policy: an analysis of the long history of trade and privacy, the rapid growth of international regulation, that privacy and trade are not necessarily exclusive and can both impact humanitarian issues when we think about rights, and that the paper doesn’t merely observe the problem, but rather gives a potential path to fixing it through a regulatory regime. The conversation centered on privacy and transborder data flows, the concept that “privacy is not bananas,” and the practical effect of kicking the proverbial can down the road to other countries, amongst other salient topics.
Professor Anupam Chander and Neil Chilson
Professor Eunice Park (Western State College of Law) discussed her paper, Reproductive Health Care Data Free or For Sale: Post-Roe Surveillance and the “Three Corners” of Privacy Legislation Needed with Amanda Newman (Office of Congresswoman Sara Jacobs). Professor Park’s paper recommends placing over-due limits on state surveillance to protect the privacy of personal health data. Ms. Newman acknowledged that state criminalization has fallen hardest on marginalized communities post-Roe and that the issue of reproductive health data being available on the open market has made the issue of privacy more concrete and topical. Professor Park explained why the post-Roe era is harsher than the 1960s pre-Roe era, the disconnect between legal protection and digital reality in the context of the First Amendment, and the three corners of protections she recommends, including an inclusive definition for reproductive healthcare data, a substantive prohibition on certain practices, and procedural protections that would require a warrant for any type of information that could criminalize an individual.
Professor Eunice Park and Amanda Newman
During the next panel, Dr. Pawel Popiel (University of Pennsylvania Annenberg School for Communication) and Laura Schwartz-Henderson (Internews) discussed their paper, Understanding the Challenges Data Protection Regulators Face: A Global Struggle Towards Implementation, Independence, & Enforcement with FPF’s Dr. Gabriela Zanfir-Fortuna. Their paper examines the challenges facing DPAs in Africa and Latin America and identifies two prominent factors as key obstacles to effective data protection oversight: resource constraints and threats to independence. The co-authors discussed why they pursued this research and why it is valuable, how they chose the data they worked with and what the key challenges were, how lack of independence can create cross-cutting challenges across organizations, and why independence is so important. They also stated that ensuring local values and needs with baseline data protection from the European model was important.
Dr. Pawel Popiel, Laura Schwartz-Henderson, and Dr. Gabriela Zanfir-Fortuna
Next, FTC Commissioner Rebecca Kelly Slaughter discussed her paper, Algorithms and Economic Justice: A Taxonomy of Harms and a Path Forward for the Federal Trade Commission with Maneesha Mithal (Wilson Sonsini Goodrich & Rosati). Commissioner Slaughter’s paper provides a taxonomy of algorithmic harms that portend injustice, describes her view of how the Commission’s existing tools can and should be aggressively applied to thwart injustice, and explores how new legislation or an FTC rulemaking could help structurally address the harms generated by algorithmic decision-making. Commissioner Slaughter reiterated it is important that “we’re not awed by the concept of algorithmic decision making, into thinking it’s an amazing technology.” Commissioner Slaughter discussed consumer protection and “AI snake oil,” the privacy harms of regenerative AI, potential harms to kids, and the importance of transparency and explainability to consumers.
FTC Commissioner Rebecca Kelly Slaughter and Maneesha Mithal
In the evening’s final presentation, Professor Kate Weisburd (George Washington University Law School) was joined by Professor Chaz Arnett (University of Maryland Carey Law School) to discuss her paper, Punitive Surveillance. Professor Weisburd’s paper analyzes “punitive surveillance” practices, which allow government officials, law enforcement, and companies to track, record, share, and analyze the location, biometric data, and other metadata of thousands of people on probation and parole. Professor Weisburd noted how there has been a “shift to digitizing and datifying the carceral state, entrenching and deepening carceral surveillance measures.” Professor Weisburd then discussed the concept of punitive surveillance, the disconnect between how e-monitors are presented in popular culture and how it plays out in practice, and what policymakers could do to connect more with this subject matter.
Professor Kate Weisburd and Professor Chaz Arnett
FPF CEO Jules Polonetsky closed the event by thanking the audience, including a special shout-out to Professor Paul Ohm for helping inspire this conference thirteen years ago and to FPF’s Stephanie Wong for making the event happen.
FPF CEO Jules Polonetsky
Thank you to Commissioner Alvaro Bedoya and Honorary Co-Hosts Congresswoman Diana DeGette and Senator Ed Markey, Co-Chairs of the Congressional Privacy Caucus. We would also like to thank our winning authors, expert discussants, those who submitted papers, and event attendees for their thought-provoking work and support. We hope to see you next year!
ITPI Law and Technology Policy Paper Competition In Collaboration with the Israel Ministry of Justice
Last month (January 11, 2023), the Israel Tech Policy Institute held the final event of the ‘Law and Technology Policy Paper Competition’ with the presence of Adv. Sharon Afek, Deputy Attorney General (Director of the Consulting and Legislative Division), and Saar Abramovich, a patent examiner from the Patent Office, along with the participation of students from four law faculties of universities and academic colleges in Israel who have reached the final stage of the competition – Sapir Academic College, The University of Haifa, Bar-Ilan University, and the Ono Academic College.
The winning students from Sapir Academic College were awarded a prize worth NIS 5,000 by the Ministry of Justice. The winning paper was also translated into English – courtesy of the Israel Technology Policy Institute.
The research question of competition was: Should artificial intelligence be recognized as an “inventor” for the purposes of patent law, or as a “patent owner”? The question was examined against the background of dealing with legal challenges and complexities that arise from the need to regulate the encounter between smart technologies and existing law.
The competition judges included:
Adv. Ayelet Feldman, Consulting and Legislation (Economic Department) Israel Ministry of Justice
Adv. Cedric Sabbah, Director, International Cybersecurity and IT Law, Office of the Deputy Attorney General (International Law), Israel Ministry of Justice
Adv. Asa Kling, Partner at Naschitz, Brandes, Amir & Co., Chair of IP Practice
Adv. Amit Ashkenazi, Law and Technology Expert, Former Head of the Legal Department at Israel National Cyber Directorate
Dr. Asaf Weiner, Managing Director of Research, Policy, and Government Affairs at ISOC-IL | Professor of Internet Law & Policy at TAU and BGU
The competition aroused great interest among scholars, academia, and government officials and will be continued next year as well.
To read the policy papers in Hebrew of the four faculties of law that have reached the final stage of the competition, click here.
The English version of the winning paper by Sapir Academic College written by Uri Avigal, Galit Cohen, Sharon Pustilnik, and Matt Weiser with the supervision of Dr. Sharon Bar-Ziv is available here.
New Report Highlights LGBTQ+ Student Views on School Technology and Privacy
The Future of Privacy Forum and LGBT Tech outline recommendations for schools and districts to balance inclusion and student safety in technology use.
Today, the Future of Privacy Forum (FPF), a global non-profit focused on privacy and data protection, and LGBT Tech, a national, nonpartisan group of LGBT organizations, academics, and high technology companies, released a new report, Student Voices: LGBTQ+ Experiences in the Connected Classroom. The report builds on FPF and LGBT Tech research, including interviews with recent high school graduates who identify as LGBTQ+, to gather firsthand accounts of how student monitoring impacted their feelings of privacy and safety at school.
Student Voices: LGBTQ+ Experiences in the Connected Classroom
“LGBTQ+ students are at greater risk for their online activity being flagged or blocked by some content filtering and monitoring systems, and hearing first-hand about their experiences was incredibly important and informative,” said Jamie Gorosh, FPF Youth & Education Privacy policy counsel and an author of the report. “We hope that the recommendations outlined in this report can help schools and districts develop policies that better reflect the views of LGBTQ+ students and ultimately create a safe learning environment for all students.”
LGBTQ+ Experiences in the Connected Classroomanalyzes the concerns that arose in conversations with LGBTQ+ students regarding school technologies and privacy, including concerns about identity, parent/caregiver access to data, health information, and student safety. The report then outlines a series of recommendations and actionable steps for schools and districts to address those concerns and others, including to:
Improve transparency and communication with the school community about what technology is being used and how the district is using it, including by sharing with students and parents a clear monitoring policy, the name of the monitoring vendor, a list of websites that will be blocked (how a student could contest a decision to block a site), and the school officials who will have access to content flagged by monitoring technology.
Carefully consider how and when monitoring technology is deployed, and develop safeguards for how information is used and shared, including by evaluating the efficacy of the product before purchasing, considering what content the monitoring system reviews and who has access to notifications, and understanding the vendor’s policies and procedures for sharing information with law enforcement.
Consider legislative or policy reforms establishing best practices for protecting LGBTQ+ students and student data privacy, such as a student safety exception amendment to FERPA or on the state level, legislation that emulates a 2014 California law that requires students and parents to be notified and given the opportunity to publicly comment before a district can gather information from students’ social media accounts.
Invest in more robust mental health services and support for LGBTQ+ students, as well as training for administrators to ensure they are able to meet the unique needs of these students. “If schools develop programming specifically aimed at providing resources and mental health care to LGBTQ+ students and create an overall environment of acceptance and inclusivity, that may make all the difference,” the report concludes.
“Our hope would be that every young LGBTQ+ individual would have a supportive family home when it comes to their sexual orientation or gender identity, but unfortunately, over 60% of youth in a recent Trevor Project study did not feel their home was an LGBTQ+ affirming space,” said Christopher Wood, Executive Director, LGBT Tech. “Their public school, its faculty, and technology is most likely the closest line of support that young LGBTQ+ person has access to. With a wave of anti-LGBTQ legislation being passed across the US, it is more important than ever that school monitoring technology is not further inflicting harm on young LGBTQ+ individuals seeking information and support. We hope this report can help schools and districts identify areas for improvement and develop policies that create a safe, supportive learning environment for all students, especially those who might identify as LGBTQ+.”