The Draghi Dilemma: The Right and the Wrong Way to Undertake GDPR Reform
The following is a guest post to the FPF blog authored by Christopher Kuner, Visiting Fellow at the European Centre on Privacy and Cybersecurity at Maastricht University and FPF Senior Fellow. The guest post reflects the opinion of the author only and does not necessarily reflect the position or views of FPF and our stakeholder communities. FPF provides this platform to foster diverse perspectives and informed discussion.
There has been much interest in the report on European competitiveness issued in September 2024 by former Italian Prime Minister and European Central Bank President Mario Draghi at the request of European Commission President Ursula von der Leyen, which calls for reform of the EU General Data Protection Regulation (“GDPR”). Draghi’s views have led to discussion about whether fundamental changes to the GDPR are needed, particularly to improve the EU’s position as a global leader in artificial intelligence (AI). In order to protect fundamental rights, maintain legal certainty, and continue to ensure a high level of protection, any reform should be evidence-based, targeted, transparent, and further the EU’s values.
Draghi’s criticisms
In his report, Draghi makes valid criticisms of the inconsistent and fragmented implementation of the GDPR in the Member States (see p. 69). However, his more recent remarks have been more pointed. In a speech at a high-level Commission conference on 16 September 2025, Draghi not only denounced “heavy gold-plating” by Member States in GDPR implementation, but also called for a “radical simplification” of “the primary law” of the GDPR (p. 4). Under Article 97 GDPR, the Commission must prepare an evaluation of it every four years. Its last evaluation, issued in 2024, identified several challenges to the effective operation of the GDPR, but did not call for large-scale reform.
Under pressure following Draghi’s report, the Commission proposed without any consultation a “GDPR Omnibus” on 21 May 2025 containing targeted amendments that eliminate record-keeping requirements for some categories of smaller data controllers. The Commission’s proposal was accompanied by sensationalist claims in the press (such as that the GDPR is on an EU “hit list” and will be consumed in a “red tape bonfire”) and incoherent political statements (such as claims by the Danish Digital Minister that there are “a lot of good things about the GDPR” but that it regulates “in a stupid way”), which seemed to raise the political temperature and push onto the public agenda the idea of radical change of the GDPR.
Later this year the Commission is set to announce a “Digital Omnibus” with proposals for simplification of its data legislation “to quickly reduce the burden on businesses”. It seems possible that political pressure in the EU as well as criticism from the Trump Administration could lead to further proposals for GDPR reform as well.
The politics of reform
Despite Draghi’s claims (see p. 4 of his speech), so far there has been no widespread public pressure for “radical simplification” of the GDPR. The participants at a Commission Implementation Dialogue on application of the GDPR held on 16 July 2025, which included stakeholders from business, civil society, and academia (including myself), concluded that there should be no major changes to the GDPR, while identifying some targeted reforms that could be considered. Anyone who has been involved in EU data protection law for the past few decades can remember claims similar to Draghi’s going back to the entry into force of the EU Data Protection Directive 95/46/EC in the 1990s that data protection law throttles economic growth, all of which have proved to be hyperbolic.
Thus far, GDPR reform has been dealt with on the technocratic level, and the Commission has demonstrated no desire to open up discussion about it to a wider audience. For example, its call for evidence with regard to the Digital Omnibus proposal expected later this year does not mention the GDPR, suggesting that any further proposals for its reform may be announced without public consultation. The text of the GDPR is finely-balanced, and changes to one provision that on the surface seem minor may create uncertainties or conflicts with other provisions, unless they are carefully considered. Pushing through reforms hastily can lead to unintended consequences that exacerbate existing problems and increase public cynicism of the EU legislative process.
Efficiency vs. values
One would expect that an experienced European leader and outstanding public servant such as Draghi would mention that the GDPR protects fundamental rights set out in the TFEU and the EU Charter of Fundamental Rights. However, he has not done this, while giving the impression that the GDPR is little more than red tape that the EU can change at will. His call for simplification of the “primary law” of the GDPR seems to advocate changes to its fundamental principles, but this could bring any reform into conflict with the TFEU and the Charter and lead to challenges before the Court of Justice.
In his report and speech, Draghi fails to buttress his criticism with any European scholarship on the GDPR, and refers only to a study published by the National Bureau of Economic Research (NBER), a US-based economic research organisation, concluding that the GDPR creates economic inefficiencies (see p. 4, footnote 6 of his speech). This conclusion is not a surprise, since, like other forms of regulation designed to protect fundamental rights and human dignity, economic efficiency is not one of the GDPR’s primary goals. Draghi thus fails to recognise, as Leff argued in his famous review of Posner’s Economic Analysis of Law, that it is useless to evaluate activities using criteria of economic efficiency when they pursue other overriding values that go beyond economics.
The place of data protection in the EU legal order has been better recognised by President of the Court of Justice Koen Lenaerts, who stated concerning EU data protection law in an interview in 2015 (paywall) that “Europe must not be ashamed of its basic principles: The rule of law is not up for sale. It is a matter of upholding the requirements in the European Union, of the rule of law, of fundamental rights”. The enthusiastic reception of Draghi’s pronouncements by EU leaders (see, for example, the lavish praise of von der Leyen) seems to indicate that not all European politicians share this view.
The right way to undertake GDPR reform
No legislation is perfect, and discussion of whether the GDPR could be improved should not be taboo. However, any reform must recognise the status of data protection as a fundamental right in the EU legal order; failing to do so would create legal uncertainty for companies and undermine the trust of individuals and thus be counterproductive. Von der Leyen herself recognised the importance of data protection in furthering the data economy in her speech at the World Economic Forum on 22 January 2020, where she called it “the pillar” of the EU’s data strategy, and stated that “with the General Data Protection Regulation we set the pattern for the world”. If the EU wants the GDPR to continue to be a model that other legal systems strive to emulate, then it must ensure that any reform is based on the following principles.
Decisions about reform of the GDPR should be subject to an evidence-based assessment grounded on criteria such as effectiveness, efficiency, relevancy, and coherency as set out in the Commission’s Better Regulation Guidelines. This should include consultations with stakeholders, thorough review of research on the GDPR (in particular that conducted by European scholars), and public hearings or conferences. It must clearly articulate its goals and proceed where the evidence leads it, and not rely on anecdotes or political pronouncements.
If further reform is found necessary, it should be targeted at a few specific areas, and not open the GDPR to wide-ranging changes. Draghi makes some valid points by criticising the current situation as not meeting the objectives of the GDPR to eliminate barriers to economic activities between the Member States (GDPR Recital 9) and to create legal certainty for economic operators (Recital 17). As he argues, there is too much fragmentation in the implementation of the GDPR in the Member States. However, reform should focus not only on the need to remove burdens on business but also on making the GDPR work better for individuals, which Draghi does not mention at all.
The EU institutions, with input from the European Data Protection Board, should agree on a limited number of clearly-defined priorities to be dealt with in any reform. Any changes that affect the fundamental principles of the GDPR or reduce the level of protection should be off-limits. It should be remembered that the original passage of the GDPR resulted in thousands of amendments in the European Parliament and took several years, so that any radical reform would take so much time that it would fail to attain the goal of rapidly improving EU competitiveness. Thoughtful suggestions for targeted reform of the GDPR have already been made by Padova and Thess (my colleagues, in the interest of full disclosure!) and by Voss and Schrems.
It must be conducted transparently in order to ensure legitimacy. Only an open and transparent evaluation of the GDPR can maintain the trust of citizens, ensure a high level of data protection, and advance European competitiveness. There should not be a repetition of the procedure used to rush through the Commission’s amendments to the GDPR proposed in May 2025.
Finally, reform must further the EU’s values. As Article 2 and 3(1) TEU set out, the EU was founded on values such as “human dignity, freedom, democracy, equality, the rule of law and respect for human rights”, which are also at the heart of the GDPR (see Recital 4). Any reform must respect these values and ensure that the protection the GDPR provides is not reduced. Improvement of competitiveness is an important goal, particularly in light of the many geopolitical challenges the EU faces, but cannot override the values set out in the EU constitutional treaties.
GDPR reform should not be a “Brussels bubble” exercise conducted at a technocratic level. Only an open and transparent process allowing for input by citizens and other relevant stakeholders can ensure a result that is in line with the EU’s values and protects the fundamental rights of individuals, while making a contribution to improving the EU’s competitiveness.
FPF Releases Issue Brief on New CCPA Regulations for Automated Decisionmaking Technology, Risk Assessments, and Cybersecurity Audits
Since the California Consumer Privacy Act (CCPA) was enacted in 2018, business obligations under the law have continued to evolve due to several rounds of rulemaking by both the Attorney General and the California Privacy Protection Agency (CPPA). The latest regulations from the CPPA are some of the most significant yet. Starting January 1, 2026, businesses will be subject to extensive new obligations concerning automated decisionmaking technology (ADMT), risk assessments, and cybersecurity audits. Today, the Future of Privacy Forum released an issue brief covering these extensive new regulations, providing stakeholders a comprehensive overview of these new legal requirements and context on how they fit into the existing state privacy law landscape.
(1) Businesses using ADMT to make significant decisions about consumers must (a) provide pre-use notice to consumers, and comply with consumer requests to opt-out of the use of ADMT and to access information about the business’s ADMT use;
(2) Businesses whose processing of personal information presents significant risk to consumers’ privacy must (a) Conduct a risk assessment before initiating the high-risk activity, (b) regularly submit information about conducted risk assessments to the CPPA, and (c) disclose completed risk assessment reports to the Attorney General or the CPPA upon demand; and (3) Businesses whose processing of personal information presents significant risk to consumers’ security must (a) conduct an annual cybersecurity audit, and (b) a qualified member of the business’s executive management team must submit a written attestation that an audit has been conducted.
Future of Privacy Forum Appoints Four New Members to Its Board of Directors
Julie Brill and Jocelyn Aqua also join FPF as senior fellows
Washington, D.C.— The Future of Privacy Forum (FPF), a global non-profit focused on data protection, AI, and emerging technologies, is pleased to announce the election of Anne Bradley, Peter Lefkowitz, Nuala O’Connor, and Harriet Pearson to its Board of Directors. These accomplished leaders bring decades of experience at the intersection of technology, law, business, and public policy, further strengthening FPF’s mission to advance principled and pragmatic data practices in support of emerging technologies.
“FPF is fortunate to welcome Anne, Peter, Nuala, and Harriett to our board,” said Jules Polonetsky, FPF CEO. “Their collective experience will be invaluable in guiding FPF’s work at a time when data, privacy, and emerging technologies are reshaping every sector of society.” Alan Raul, FPF’s Board President, added, “Our stellar new members will complement the Board’s existing luminaries, and support FPF’s outstanding professionals who provide global thought leadership in our new era of digital governance.”
Anne Bradley, a lawyer, technologist, and business leader, currently serves as Chief Customer Officer at Luminos.ai. Anne built the privacy programs for two major global brands, serving as the first in-house privacy counsel at Hulu and as Chief Privacy Officer for Nike. She also serves as a Senior Fellow at FPF, providing staff and members guidance on a range of issues.
Peter Lefkowitz, a leading attorney and data protection executive, previously served as Chief Privacy Officer at Oracle, GE, and Citrix. A past Chairman of the Board for the IAPP, he has advocated for balanced data protection regulation with legislators in the U.S. and EU and has extensive experience engaging with cybersecurity agencies and privacy regulators.
Nuala O’Connor has spent her pioneering career working at the intersection of emerging technologies, digital rights, and ethics across the public and private sectors. She was the first Chief Privacy Officer of the U.S. Department of Homeland Security; served as President and CEO of the Center for Democracy and Technology; and held senior roles at Walmart, Amazon, GE, and DoubleClick. O’Connor is a senior advisor to EqualAI, serves on the advisory board of Kekst CNC, and is a life member of the Council on Foreign Relations.
Harriet Pearson brings more than 30 years of experience at the intersection of IT, business, and law. Prior to founding her consultancy, Axia Advisory, she served as Executive Deputy Superintendent and head of the Cybersecurity Division at the New York Department of Financial Services. Earlier in her career, she founded and led the global cybersecurity practice at Hogan Lovells and served as IBM’s first Chief Privacy Officer. She helped found the IAPP and Georgetown Cybersecurity Law Institute, and has served on numerous boards and advisory councils.
Composed of leaders from industry, academia, and civil society, the input of FPF’s Board of Directors ensures that FPF’s work is expert-driven and independent.
FPF has also added two Senior Fellows to its roster of experts, Julie Brill and Jocelyn Aqua. Currently leading Brill Strategies, Brill was former Chief Privacy Officer, Corporate Vice President for Privacy, Safety and Regulatory Affairs, and Corporate Vice President for Global Tech and Regulatory Policy at Microsoft. Brill was a Commissioner of the US Federal Trade Commission from 2010-2016. Jocelyn Acqua, is Co-Chair of the Data, Privacy and Cybersecurity Practice at HWG, LLP, and a former partner at PwC. .
To learn more about the Future of Privacy Forum, visit fpf.org.
###
California’s SB 53: The First Frontier AI Law, Explained
California Enacts First Frontier AI Law as New York Weighs Its Own
On September 29, Governor Newsom (D) signed SB 53, the “Transparency in Frontier Artificial Intelligence Act (TFAIA),” authored by Sen. Scott Wiener (D). The law makes California the first state to enact a statute specifically targeting frontier artificial intelligence (AI) safety and transparency. SB 53 requires advanced AI developers to publish governance frameworks and transparency reports, establishes mechanisms for reporting critical safety incidents, extends whistleblower protections, and calls for the development of a public computing cluster.
In his signing statement, Newsom described SB 53 as a blueprint for other states, arguing on behalf of California’s role in shaping “well-balanced AI policies beyond our borders—especially in the absence of a comprehensive federal framework.” Supporters view the bill as a critical first step toward promoting transparency and reducing serious safety risks, while critics argue its requirements could be unduly burdensome on AI developers, potentially inhibiting innovation. These debates come as New York considers its own frontier AI bill–A 6953 or the Responsible AI Safety and Education (RAISE) Act, which could become the second major state law in this space–and as Congress introduces its own frontier model legislation. Understanding SB 53’s requirements, how it evolved from earlier proposals, and how it compares to New York’s RAISE Act is critical for anticipating where U.S. policy on frontier model safety may be headed.
SB 53 regulates developers of the most advanced and resource-intensive AI models by imposing disclosure and transparency obligations, including the adoption of written governance frameworks and reporting of safety incidents. To target this select set of developers, the law specifically scopes the definitions of “frontier model,” “frontier developer,” and “large frontier developer.”
Scope
The law regulates frontier developers, defined as entities that “trained or initiated the training” of high-compute frontier models. It separately defines large frontier developers, or those with annual gross revenues above $500 million, targeting compliance towards the largest AI companies. SB 53 applies to frontier models, defined as foundation models trained with more than 10^26 computational operations, including cumulative compute from both initial training and subsequent fine-tuning or modifications.
Notably, SB 53 is focused on preventing catastrophic risk, defined as a foreseeable and material risk that a frontier model could:
Contribute to the death or serious injury of 50 or more people or cause at least $1 billion in damages;
Provide expert-level assistance in creating or releasing a chemical, biological, radiological, or nuclear weapon;
Engage in criminal conduct or a cyberattack without meaningful human intervention; or
Evade the control of its developer or user.
Other proposed bills, like New York’s RAISE Act, set a narrower liability standard: harm must be a “probable consequence” of the developer’s activities, the developer’s actions must be a “substantial factor,” and the harm could not have been “reasonably prevented.” SB 53 lacks these qualifiers, applying a broader standard for when risk triggers compliance.
Requirements:
SB 53 establishes four major obligations, dividing some responsibilities between all frontier developers and the narrower subset of “large frontier developers.”
Frontier AI Framework: Large frontier developers must publish an annual Frontier AI framework describing how catastrophic risks are identified, mitigated, and governed. Among other items, the framework must include documentation of governance structures, mitigation processes, cybersecurity practices, and a developer’s alignment with national/international standards. The framework must also assess catastrophic risk from internal use of models, raising the scope of compliance obligations. Frontier developers may make redactions to the framework to protect trade secrets, cybersecurity, and national security.
Transparency Report: Before deploying a frontier model, all frontier developers (not only “large” developers) must publish a transparency report. Reports must include model details (intended uses, modalities, restrictions), as well as summaries of catastrophic risk assessments, their results, and the role of any third-party evaluators.
Disclosure of Safety Incidents: Frontier developers are required to report critical safety incidents to the Office of Emergency Services (OES). OES must also establish a mechanism for the public to report critical safety incidents. Covered incidents include unauthorized tampering with a model that causes serious harm, the materialization of a catastrophic risk, loss of control of a frontier model that results in injury or major property damage, or a model deliberately evading developer safeguards. Frontier developers are required to report any critical safety incident within 15 days of discovery, shortened to 24 hours if the incident poses imminent danger of death or serious injury.
Whistleblower Protections: SB 53 prohibits retaliation against employees or contractors who report activity from catastrophic risks. Employers must provide notice of employee rights and maintain anonymous reporting channels.
Enforcement:
SB 53 authorizes the Attorney General to bring civil actions for violations, with penalties of up to $1 million per violation, scaled to the severity of the offense. The law also empowers the California Department of Technology to recommend updates to key statutory definitions, such as “frontier model” or “large frontier developer,” to reflect technological change. Any updates must be adopted by the Legislature, but this mechanism offers definitional adaptability. Notably, earlier drafts of SB 53 would have provided the Attorney General (AG) direct rulemaking authority over these definitions. However, the final version of the bill removes the AG rulemaking authority in favor of the Department of Technology recommendations to the Legislature.
From SB 1047 to SB 53: How the Bill Narrowed
SB 53 is a pared-down successor to last year’s SB 1047, which Governor Newsom vetoed. In his veto statement, Newsom called for an approach to frontier model regulation “informed by an empirical trajectory analysis of AI systems and capabilities,” leading to the creation of the Joint California Policy Working Group on AI Frontier Models. The group released a report offering regulatory best practices, which emphasized whistleblower protections and alignment with leading safety practices.
When the bill returned in 2025, it passed without many of SB 1047’s most controversial provisions, including:
Mandating full shutdown capabilities (or “kill switch”) for covered models, criticized as technically infeasible and a barrier to open-source development;
Imposing pre-training requirements, obligating developers to implement safety protocols, cybersecurity protections, and full shutdown capabilities before beginning initial training of a covered model;
Requiring annual audits by independent third-party assessors;
Strict 72-hour reporting window for safety incidents; and
Steep penalties tied to compute cost, up to 10% for first violations and 30% for subsequent ones.
By contrast, SB 53 focuses on deployment-stage obligations, lengthens reporting timelines to 15 days, caps penalties at $1 million per violation, and streamlines the information required in transparency reports and frameworks (removing, for example, testing disclosure requirements). These changes produced a narrower bill with reduced obligations for frontier developers, satisfying some but not all critics.
Comparison with New York’s RAISE Act
With SB 53 now law, attention turns to New York and the Responsible AI Safety and Education (RAISE) Act, which is pending on Governor Hochul’s desk. Like SB 53, the RAISE Act was inspired by last year’s SB 1047 and seeks to regulate frontier AI models. Hochul has as late as January 1, 2026, to sign, veto, or issue chapter amendments, a process that allows the governor to negotiate substantial changes with the legislature at the time of signature. Given Newsom’s signature of SB 53, a central question is whether RAISE will be amended to more closely align with the California law.
To help stakeholders track these dynamics, we’ve created a side-by-side comparison of the two bills. Broadly, SB 53 is more detailed in content—requiring frameworks, transparency reports, and whistleblower protections—while RAISE is stricter in enforcement, with higher penalties and liability provisions. Both bills share core elements, such as compute thresholds, catastrophic risk definitions, and mandatory frameworks/protocols. Key differences include:
Strict Liability: RAISE prohibits deployment of frontier models that pose an “unreasonable risk of critical harm,” a standard absent from SB 53.
Scope: SB 53 uses broader definitions of catastrophic risk and distinguishes between “frontier developers” and “large frontier developers,” which are those with $500M+ annual revenue. RAISE applies only to “large developers,” defined as those spending $100M+ on compute, which could bring a distinct group of companies into scope when compared to SB 53.
Requirements: SB 53 imposes additional obligations, including employee whistleblower protections and public transparency reports. Where requirements overlap, such as safety incident reporting, SB 53 allows public reporting and offers a longer timeline (15 days), while RAISE sets a 72-hour window and uses stricter qualifiers.
Enforcement: SB 53 caps penalties at $1 million per violation and empowers the California Department of Technology to recommend definitional updates. RAISE authorizes significantly higher penalties (up to $10 million for a first violation and $30 million for subsequent ones).
The bills highlight how state legislators are experimenting with comparable, yet distinct, approaches to AI frontier model regulation–California’s highlighting transparency and employee protections, with New York’s emphasizing stronger penalties and liability standards.
Conclusion
SB 53 makes California the first state to enact legislation focused on frontier AI, establishing transparency, disclosure, and governance requirements for high-compute model developers. Compared to last year’s broader SB 1047, the new law takes a narrower approach, scaling back several of the compliance obligations.
Attention now turns to New York, where the RAISE Act awaits action by the governor. Whether signed as written or amended through the chapter amendment process to reflect aspects of SB 53, the bill could become a second state-level framework for frontier AI. Other states, including Michigan, have introduced proposals of their own, illustrating the potential for a patchwork of requirements across jurisdictions.
As detailed in FPF’s recent report, State of State AI: Legislative Approaches to AI in 2025, this year’s legislative landscape highlights ongoing state experimentation in AI governance. With SB 53 enacted and the RAISE Act under consideration, state-level activity is moving from proposal to implementation, raising questions about how divergent approaches may shape compliance expectations and interact with future federal efforts.
The State of State AI: Legislative Approaches to AI in 2025
State lawmakers accelerated their focus on AI regulation in 2025, proposing a vast array of new regulatory models. From chatbots and frontier models to healthcare, liability, and sandboxes, legislators examined nearly every aspect of AI as they sought to address its impact on their constituents.
To help stakeholders understand this rapidly evolving environment, the Future of Privacy Forum (FPF) has published The State of State AI: Legislative Approaches to AI in2025.
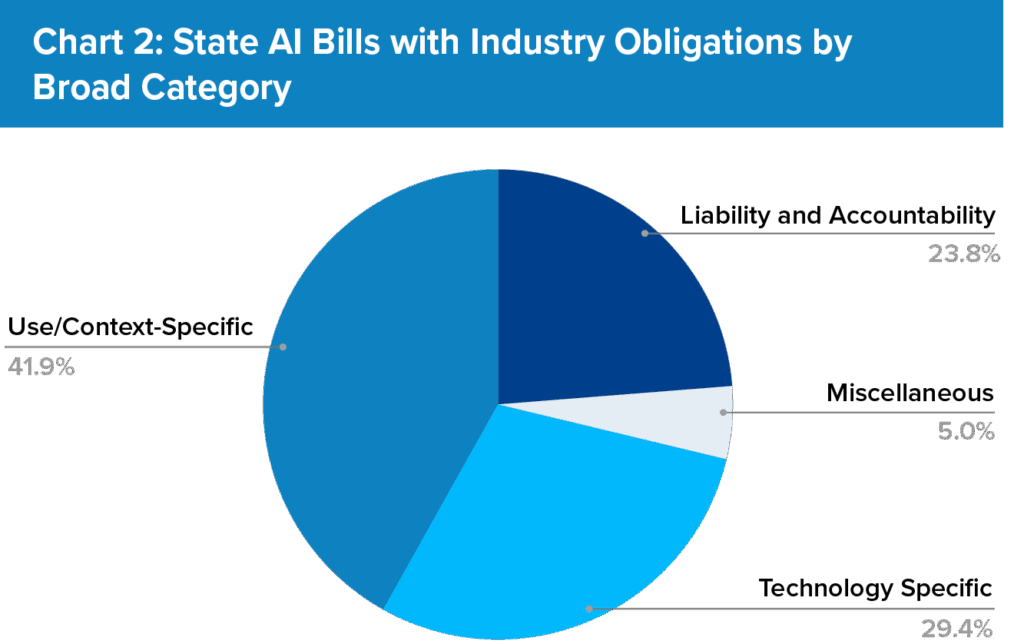
This report analyzes how states shaped AI legislation during the 2025 legislative session, spotlighting the trends and thematic approaches that steered state policymaking. By grouping legislation into three primary categories: (1) use- and context-specific measures, (2) technology-specific bills, and (3) liability and accountability frameworks, this report highlights the most important developments for industry, policymakers, and other stakeholders within AI governance.
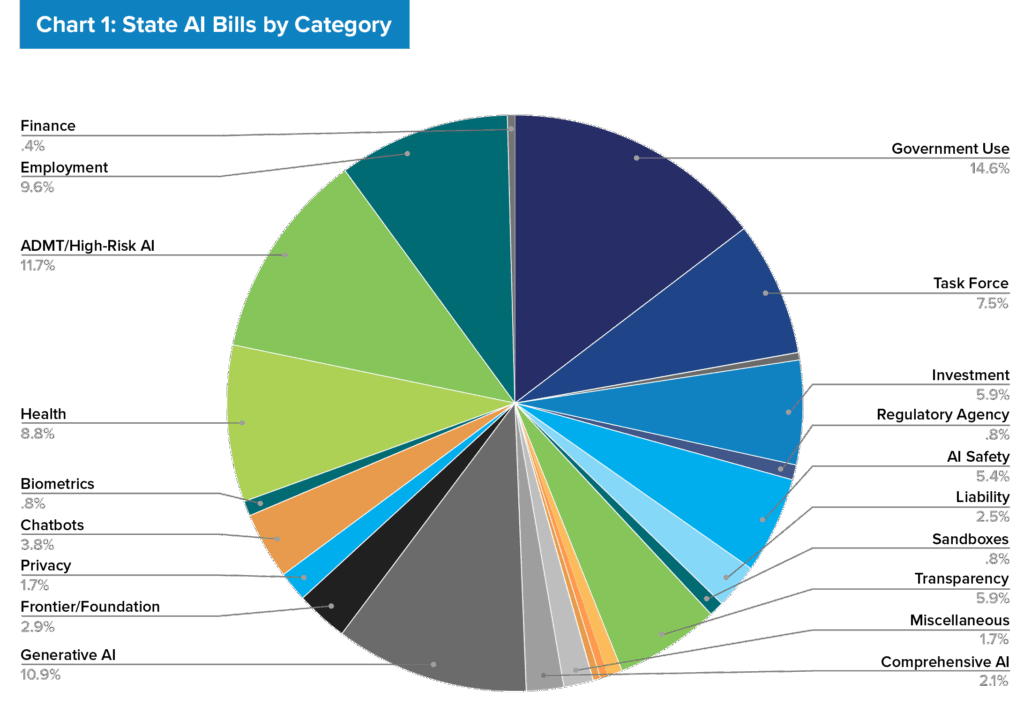
In 2025, FPF tracked 210 billsacross 42 states that could directly or indirectly affect private-sector AI development and deployment. Of those, 20 bills (around 9%) were enrolled or enacted.1 While other trackers estimated that more than 1,000 AI-related bills were introduced this year, FPF’s methodology applies a narrower lens, focusing on measures most likely to create direct compliance implications for private-sector AI developers and deployers.2
Key Takeaways
State lawmakers moved away from sweeping frameworks regulating AI, towards narrower, transparency-driven approaches.
Three key approaches to private sector AI regulation emerged: use and context-specific regulations targeting sensitive applications, technology-specific regulations, and a liability and accountability approach that utilizes, clarifies, or modifies existing liability regimes’ application to AI.
The most commonly enrolled or enacted frameworks include AI’s application in healthcare, chatbots, and innovation safeguards.
Legislatures signaled an interest in balancing consumer protection with support for AI growth, including testing novel innovation-forward mechanisms, such as sandboxes and liability defenses.
Looking ahead to 2026,issues like definitional uncertainty remain persistent while newer trends around topics like agentic AI and algorithmic pricing are starting to emerge.
Classification of AI Legislation
To provide a framework to analyze the diverse set of bills introduced in 2025, FPF classified state legislation into four categories based on their primary focus. This classification highlights whether lawmakers concentrated on specific applications, particular technologies, liability and accountability questions, or government use and strategy. While many bills touch on multiple themes, this framework is designed to capture each bill’s primary focus and enable consistent comparisons across jurisdictions.
Table I.
Use / Context-Specific Bills
Focuses on certain uses of AI in high-risk decisionmaking or contexts–such as healthcare, employment, and finance–as well as broader proposals that address AI systems used in a variety of consequential decisionmaking contexts. These bills typically focus on applications where AI may significantly impact individuals’ rights, access to services, or economic opportunities. Examples of enacted frameworks: Illinois HB 1806 (AI in mental health), Montana SB 212 (AI in critical infrastructure)
Technology-Specific Bills
Focuses on specific types of AI technologies,such as generative AI, frontier/foundation models, and chatbots. These bills often tailor requirements to the functionality, capabilities, or use patterns of each system type. Examples of enacted frameworks: New York S 6453 (frontier models), Maine LD 1727 (chatbots), Utah SB 226 (generative AI)
Bills Focused on Liability and Accountability
Focuses on defining, clarifying, or qualifying legal responsibility for use and development of AI systems utilizing existing legal tools, such as clarifying liability standards, creating affirmative defenses, or authorizing regulatory sandboxes. These aim to support accountability, responsible innovation, and greater legal clarity. Examples of enacted frameworks: Texas HB 149 (regulatory sandbox), Arkansas HB 1876 (copyright ownership of synthetic content)
Government Use and Strategy Bills
Focuses on requirements for government agencies’ use of AI that have downstream or indirect effects on the private sector, such as creating standards and requirements for agencies procuring AI systems from private sector vendors. Examples of enacted frameworks: Kentucky SB 4 (high-risk AI in government), New York A 433 (automated employment decision making in government)
Table II. Organizes the 210 bills tracked by FPF’s U.S. Legislation Team in 2025 across 18 subcategories.
Table III. Organizes the 210 bills tracked by FPF’s U.S. Legislation Team in 2025 into overarching themes, excluding bills focused on government use and strategy that do not set direct industry obligations. Bills in the “miscellaneous” category primarily reflect comprehensive AI legislation.
Use or Context-Specific Approaches to AI Regulation
In 2025, nine laws were enrolled or enacted and six additional billspassed at least one chamber that sought to regulate AI based on its use or context.
Focus on health-related AI applications: Legislatures concentrated on AI in sensitive health contexts, especially mental health and companion chatbots, often setting disclosure obligations. These health-specific laws primarily focus on limiting or guiding AI use by licensed professionals, particularly in mental health contexts. Looking beyond enrolled or enacted measures, nearly 9% of all introduced AI-related bills tracked by FPF in 2025 focused specifically on healthcare. From a compliance perspective, most prohibit AI from independently diagnosing patients, making treatment decisions, or replacing human providers, and many impose disclosure obligations when AI is used in patient communications.
High-risk frameworks arose only through amendments to existing law: In contrast to 2024, when Colorado enacted the Colorado Artificial Intelligence Act (CAIA), an AI law regulating different forms of “high-risk” systems used in consequential decision making, no similarly broad legislation was passed in 2025. Several jurisdictions advanced “high risk” approaches through amendments to existing laws or rulemaking efforts–many of which predate Colorado’s AI law but reflect a similar focus on automated decision-making systems across consequential decisionmaking contexts. These include amendments to existing data privacy laws’ provisions on automated decision making under the California Privacy Protection Agency’s (CPPA) regulations, Connecticut’s SB 1295 (enacted), and New Jersey’s ongoing rulemaking.
Growing emphasis on disclosures: User-facing disclosures became the most common safeguard, with eight of the enrolled or enacted laws and regulations requiring that individuals be informed when they are interacting with, or subject to, decisions made by an AI system.
Shift toward fewer governance requirements: Compared to 2024 proposals, 2025 legislation shifted away from compliance mandates, like impact assessments, in favor of transparency measures. For the few laws that did include governance-related processes, the obligations were generally “softer,” such as being tied to an affirmative defense (e.g. Utah’s HB 452, enacted) or satisfied through adherence to federal requirements (e.g. Montana’s SB 212, enacted).
Technology-Specific Approaches to AI Regulation
In 2025, ten laws were enrolled or enacted and five additional billspassed at least one chamber that targeted specific types of AI technologies, rather than just their use contexts.
Chatbots as a key legislative focus: Several new laws focused on chatbots—particularly “companion” and mental health chatbots—introducing compliance requirements for user disclosure, safety protocols to address risks like suicide and self-harm, and restrictions on data use and advertising. Chatbots drew heightened legislative attention following recent court cases and high-profile incidents involving chatbot that allegedly promoted suicidal ideation to youth. As a result, several of these bills, like New York’s S-3008C (enacted), introduce safety-focused provisions, including directing users to crisis resources. Additionally, six of the seven key chatbot bills include a requirement for chatbot operators to notify users that the chatbot is not human, in efforts to promote user awareness.
Frontier/foundation models regulation reintroduced: California and New York revived frontier model legislation (SB 53 and the RAISE Act, enrolled), building on 2024’s California’s SB 1047 (vetoed) but with narrower scope and streamlined requirements for written safety protocols. Similar bills were introduced in Rhode Island, Michigan, and Illinois, centered on preventing “catastrophic risks” from the most powerful AI systems, like large-scale security failures that could lead to human injury or harms to critical infrastructure.
Generative AI proposals centered on labeling:A majority of generative AI bills in 2025 focused on content labeling—either required disclosures visible to users at the time of interaction, or a more technical effort of tagging of provenance or training data to enhance content traceability—to address risks of deception and misinformation. Bills include: California’s AB 853 (enrolled), New York’s S 6954 (proposed), California’s SB 11 (enrolled), and New York’s S 934 (proposed).
Liability and Accountability Approaches to AI Regulation
This past year, eightlaws were enrolled or enacted and ninenotable bills passed at least one chamber that focused on defining, clarifying, or qualifying legal responsibility for use and deployment of AI systems. State legislatures tested different ways to balance liability, safety, and innovation.
Clarifying liability regimes for accountability:Across numerous states, lawmakers looked to affirmative defenses, or legal claims that allow defendants to dismiss lawsuits based on certain grounds, as a solution for incentivizing responsible AI practices while maintaining flexibility and reducing legal risks for businesses. Examples include: Utah’s HB 452 (enacted) allowing an affirmative defense if a provider maintained certain AI governance measures and California’s SB 813 (proposed) allowing AI developers to use certified third-party audits as an affirmative defense in civil lawsuits. Legislators also sought to update privacy and tort statutes to address AI-specific risks, such as Texas’ TRAIGA amendment (enacted) of the Texas biometric privacy law to account for AI training.
Prioritization of innovation-focused measures: States experimented with regulatory sandboxes that allow controlled AI development, with the enactment of new regulatory sandboxes in Texas and Delaware, along with the first official sandbox agreement under Utah’s 2024 AI Policy Act (SB 149). Other legislation, such as Montana’s SB 212 (enacted), introduced “right to compute” provisions to protect AI development and deployment.
Enforcement tools and defense strategies: Legislatures expanded Attorney General investigative powers (such as civil investigative demands) in bills including Texas’ TRAIGA (enacted) and Virginia HB 2094 (vetoed). A variety of other defense mechanisms were introduced, including specific protections for whistleblowers, as represented in California’s SB 53 (enrolled).
Looking Ahead to 2026
As the 2026 legislative cycle begins, states are expected to revisit unfinished debates from 2025 while turning to new and fast-evolving issues. Frontier/foundation models, chatbots, and health-related AI will remain central topics, while definitional uncertainty, agentic AI, and algorithmic pricing signal the next wave of policy debates.
Definitional Uncertainty: States continue to diverge in how they define artificial intelligence itself, as well as categories like frontier models, generative AI, and chatbots. Definitional variations, such as compute thresholds for “frontier” systems or qualifiers in generative AI definitions, are shaping which technologies fall under regulatory scope. These differences will become more consequential as more bills are enrolled, expanding the compliance landscape.
Agentic AI: Legislators are beginning to explore “AI agents” capable of autonomous planning and action, systems that move beyond generative AI’s content creation and towards more complex functions. Early governance experiments include Virginia’s “regulatory reduction pilot” and Delaware’s agentic AI sandbox, but few bills directly address these agents. Existing risk frameworks may prove ill-suited for agentic AI, as harms are harder to trace across agents’ multiple decision nodes, suggesting that governance approaches may need to adapt in 2026.
Algorithmic pricing: States are testing ways to regulate AI-driven pricing tools, with bills targeting discrimination, transparency, and competition. New York enacted disclosure requirements for “personalized algorithmic pricing” (S 3008, enacted), while California (AB 446 and SB 384, proposed), Colorado, and Minnesota floated their own frameworks. In 2026, lawmakers may focus on more precise definitions or stronger disclosure or prohibition measures amid growing legislative activity on algorithmic pricing.
Conclusion
In 2025, state legislatures sought to demonstrate that they could be laboratories of democracy for AI governance: testing disclosure rules, liability frameworks, and technology-specific measures. With definitional questions still unsettled and new issues like agentic AI and algorithmic pricing on the horizon, state legislatures are poised to remain active in 2026. These developments illustrate both the opportunities and challenges of state-driven approaches, underscoring the value of comparative analysis as policymakers and stakeholders weigh whether, and in what form, federal standards may emerge. At the same time, signals from federal debates, increased industry advocacy, and international developments are beginning to shape state efforts, pointing to ongoing interplay between state experimentation and broader policy currents.
Upon publication of this report, bills in California and New York are still awaiting gubernatorial action. This total is limited to bills with direct implications for industry and excludes measures focused solely on government use of AI or those that only extend the effective date of prior legislation. ↩︎
This report excludes: bills and resolutions that merely reference AI in passing; updates to criminal statutes; and legislation focused on areas like elections, housing, agriculture, state investments in workforce development, and public education, which are less likely to involve direct obligations for companies developing or deploying AI technologies. ↩︎
Call for Nominations: 16th Annual Privacy Papers for Policymakers Awards
The 16th Privacy Papers for Policymakers call for submissions is now open until October 30, 2025. FPF’s Privacy Papers for Policymakers Award recognizes leading privacy research and analytical scholarship relevant to policymakers in the U.S. and internationally. The award highlights important work that analyzes current and emerging privacy issues and proposes achievable short-term solutions or means of analysis that have the potential to lead to real-world policy solutions.
FPF welcomes privacy scholars, researchers, and students to submit completed papers focusing on privacy or AI governance, specifically emphasizing data protection, and be relevant to policymakers in this field. Submissions may include academic papers, books, empirical research, or other longer-form analyses from any region completed, accepted, or published within the last 12 months. Submissions should be submitted in English as a PDF, DOC, or DOCX, or a publicly available link, with a one-page Executive Summary or Abstract, and the author’s complete contact and affiliation information.
Submissions are evaluated by a diverse team of FPF staff members based on originality, applicability to policymaking, and overall quality of writing. Summaries of the winning papers will be published in a digest on the FPF website, and winning authors will have the opportunity to present their work during a virtual event in 2026 in front of top policymakers and privacy leaders. All winners are also highlighted during the event and in a press release to the media.
FPF Submits Comments to Inform Colorado Minor Privacy Protections Rulemaking Process
On September 10th, FPF provided comments regarding draft regulations for implementing the heightened minor protections within the Colorado Privacy Act (“CPA”). Passed in 2021, the CPA, a Washington Privacy Act style-framework, provides comprehensive privacy protections to consumers in Colorado that are enforced by the state Attorney General’s office, which also has rulemaking authority. In 2024, the Colorado legislature passed an amendment to the CPA providing heightened protections to minors in the state by establishing a duty of care owed to minors and special obligations for controllers collecting and processing minor data. In July 2025, the Colorado Attorney General’s office launched a formal rulemaking to provide additional guidance to entities obligated to provide heightened protections to minors under this CPA amendment, specifically providing rules on system design features, consent within these obligations, and factors to consider under the “wilfully disregards” portion of the “actual knowledge or wilfully disregards” knowledge standard.
FPF seeks to support balanced, informed public policy and equip regulators with the resources and tools needed to craft effective regulation. In response to the Attorney General’s public comment on the proposed rules, FPF addressed two parts of the rulemaking for the Department’s consideration:
The Department’s proposal to apply a COPPA-style “directed to minors” factor within the CPA’s “actual knowledge” standard, combined with expanding protection to all minors under 18, risks conflating distinct frameworks. Under COPPA, the “directed to children” and “actual knowledge” assessments are separate tests for applicability under the statute. The proposed rule seeks to provide factors for determining the “wilfully disregards” portion of the “actual knowledge standard,” which includes a factor introducing a “directed to minors” assessment framed similarly to COPPA. Nesting a “directed to minors” assessment within the actual knowledge standard as a factor for determining actual knowledge risks conflating COPPA’s applicability tests with the goals of these CPA amendments while simultaneously relying on inferences about potential users to assess a covered entities “actual knowledge” as to a particular user’s age. Additionally, the CPA’s directed to minors standard covers minors under the age of 18; encompassing a broader age range than COPPA, which applies to children under the age of 13. Accordingly, interests, services, and content enjoyed by older teens may also be of interest to younger adults. Additional guidance on how to make such determinations in the CPA in light of this distinction would be beneficial to stakeholders.
We provide questions for the Department to consider regarding which types of features may be subject to the law’s system design requirements. The proposed rules give two factors using the language “whether a system design feature has been shown to…” cause particular conditions, and our comments are intended to guide the Department’s evaluation of system design features. There is a growing trend within online safety legislation in the United States to target, regulate, or restrict certain design features to minors. Despite this trend, the implementation of safety requirements related to system design features, such as those envisioned in the proposed rule, is still relatively nascent. As a result, there is not a currently established process for uniformly determining whether system design features may be shown to increase “engagement beyond reasonable expectation” or increase “addictiveness.” The Department should consider providing greater clarity regarding definitions of addictiveness and engagement beyond reasonable expectation, alongside metrics for assessing these two conditions in this context, to benefit stakeholder compliance efforts.
Concepts in AI Governance: Personality vs. Personalization
Conversational AI technologies are hyper-personalizing. Across sectors, companies are focused on offering personalized experiences that are tailored to users’ preferences, behaviors, and virtual and physical environments. These range from general purpose LLMs, to the rapidly growing market for LLM-powered AI companions, educational aides, and corporate assistants.
There are clear trends among this overall focus: towards systems with greater personalization to individual users through the collection and inferences of personal information, expansion of short- and long-term “memory,” and greater access to systems; and towards systems that have more and more distinct “personalities.” Each of these trends are implicating U.S. law in novel ways, pushing on the bounds of tort, product liability, consumer protection, and data protection laws.
This issue brief defines and provides an analytical framework for distinguishing between “personalization” and “personality”—with examples of real-world uses, concrete risks, and potential risk management for each category. In general, in this paper:
Personalization refers to features of AI systems that adapt to an individual user’s preferences, behavior, history, or context. As conversational AI systems’ abilities to infer and retain information through a variety of mechanisms (e.g., larger context windows and enhanced memory) expand, and as they are given greater access to data and content, these systems raise critical privacy, transparency, and consent challenges.
Personality refers to the human-like traits and behaviors (e.g., friendly, concise, humorous, or skeptical) that are increasingly a feature of conversational systems. Even without memory or data-driven personalization, the increasingly human-like qualities of interactive AI systems can evoke novel risks, including manipulation, over-reliance, and emotional dependency, which in severe cases has led to delusional behavior or self-harm.
Future of Privacy Forum Honors Julie Brill with Lifetime Achievement Award
Washington, D.C. – September 12, 2025 — The Future of Privacy Forum, a global non-profit focused on data protection, AI and emerging technologies today announced that it has honored Julie Brill with its Lifetime Achievement Award. The award recognizes Brill’s decades of leadership and profound impact on the fields of consumer protection, data protection and digital trust in her public and private sector roles. Brill has been a long time Advisory Board member of FPF.
The award was presented Thursday evening at the Privacy Executive Summit in Berkeley, California, an event convening FPF’s senior Chief Privacy Officer members to discuss critical issues in AI, data policy, and consumer privacy.
“Julie Brill has been one of the most influential and thoughtful voices in digital policy and information governance and has been a mentor to me and so many in our field,” said Jules Polonetsky, CEO of the Future of Privacy Forum. “Julie has consistently been at the forefront of the most complex challenges in the digital age. Her career is a testament to the power of principled leadership in advancing privacy protections for consumers around the world.”
Alan Raul, President of the Future of Privacy Forum Board of Directors, added, “Julie Brill’s distinguished career at the FTC and Microsoft has left an indelible mark on the worlds of privacy policy and practice. The Future of Privacy Forum is grateful for her contributions and delighted to recognize her exceptional career advancing data protection with this well-deserved honor.”
Julie Brill, LifetimeAchievement Award
Julie Brill is one of the world’s foremost thought leaders in technology, governance, geopolitics, and global regulation. After being unanimously confirmed by the U.S. Senate and serving for six years as a Commissioner for the U.S. Federal Trade Commission, Julie joined Microsoft in 2018 as a senior executive, serving as Microsoft’s Chief Privacy Officer, Corporate Vice President for Privacy, Safety and Regulatory Affairs, and Corporate Vice President for Global Tech and Regulatory Policy.
In her leadership roles at Microsoft, Julie was a central figure in global internal and external regulatory affairs, covering a broad set of issues that are central to building trust in the AI era, including regulatory governance, privacy, responsible AI, and data governance and use strategy. She advised Microsoft’s top executives and customers about some of the most important strategic geopolitical issues facing businesses today.
At the FTC, Julie helped drive the broad agenda of one of the world’s most powerful regulatory agencies. She achieved thoughtful and lasting outcomes on issues of critical importance to industry, governments and consumers – including competition, global data flows and geopolitical concerns around data, privacy, health care, and financial fraud.
Brill was also a partner at Hogan Lovells and served on staff of the Vermont Attorney General where she was a pioneer on some of the first internet law enforcement cases.
Julie is now channeling her vision and formidable expertise into her consultancy, Brill Strategies, by providing strategic guidance to global enterprises navigating the rapidly shifting landscape of technology policy and regulation. Leveraging her decades at the forefront of digital innovation, Julie’s consultancy will empower leaders to navigate the complexities of geopolitics, responsible innovation, and regulatory change — and help their organizations thrive in the AI-driven era. Brill will also serve as a Senior Fellow at the Future of Privacy Forum.
To learn more about the Future of Privacy Forum, visit fpf.org.
###
About Future of Privacy Forum (FPF)
FPF is a global non-profit organization that brings together academics, civil society, government officials, and industry to evaluate the societal, policy, and legal implications of data use, identify the risks, and develop appropriate protections. FPF believes technology and data can benefit society and improve lives if the right laws, policies, and rules are in place. FPF has offices in Washington D.C., Brussels, Singapore, and Tel Aviv. Follow FPF on X and LinkedIn.
“Personality vs. Personalization” in AI Systems: Responsible Design and Risk Management (Part 4)
This post is the fourth and final blog post in a series on personality versus personalization in AI systems. Read Part 1 (exploring concepts), Part 2 (concrete uses and risks), and Part 3 (intersection with U.S. law).
Conversational AI technologies are hyper-personalizing. Across sectors, companies are focused on offering personalized experiences that are tailored to users’ preferences, behaviors, and virtual and physical environments. These range from general purpose LLMs, to the rapidly growing market for LLM-powered AI companions, educational aides, and corporate assistants. Behind these experiences are two distinct trends: personality and personalization.
Personality refers to the human-like traits and behaviors (e.g., friendly, concise, humorous, or skeptical) that are increasingly a feature of conversational systems.
Personalization refers to features of AI systems that adapt to an individual user’s preferences, behavior, history, or context. Conversational AI systems can expand their abilities to infer and retain information through a variety of mechanisms (e.g., larger context windows and memory).
Responsible Design and Risk Management
The management of personality- and personalization-related risks can take varied forms, including general AI governance, privacy and data protection, and elements of responsible design. There is overlap between risk management measures relevant to personality-related risks and those that organizations should consider for addressing AI personalization issues, but there are also some differences between the two trends.
For personality-related risks (e.g., delusional behavior and emotional dependency), measures might include redirecting users away from harmful perspectives, and making disclosures about the system’s AI status and incapability at experiencing emotions. Meanwhile, risks related to personalization (e.g., access to, use, and transfer of more data, intimacy of inferences, and addictive experiences) may be best served through setting retention periods and defaults for sensitive data, exploring benefits of on-device processing, countering output of biased inferences, and limiting data collection to what is necessary or appropriate.
General AI Governance
Proactively Manage Risk by Conducting AI Impact Assessments: AI impact assessments can help organizations identify and address potential risks associated with AI models and systems, including those associated with AI companions and chatbots. Organizations typically take four common steps when conducting these assessments, including: (1) initiating an AI impact assessment; (2) gathering model and system information; (3) assessing risks and benefits; and (4) identifying and testing risk management strategies. However, there are various barriers to assessment efforts, such as difficulties with obtaining relevant information from model developers and chatbot and AI companion vendors, anticipating pertinent AI risks, and determining whether they have been brought within acceptable levels.
Accounting for an Array of Human Values and Interests and Consulting with Experts: Achieving alignment entails that the AI system reflects human interests and values, but such efforts can be complicated by the number and range of these values that a system may implicate. In order to obtain a holistic understanding of the values and interests an AI companion or chatbot may implicate, organizations should consider the characteristics of the use case(s) these systems are being put towards. For example, AI companions and chatbots should account for the chatbot’s specific user base (e.g., youth). Consultations with experts, such as those in the fields of psychology or human factors engineering, during system development can help organizations identify these values and ways in which to balance them. The amount of outside expertise continues to grow, making it important to follow emerging expertise on the psychological impacts of chatbot use.
Privacy and Data Protection
Establishing User Transparency, Consent, and Control: Systems can include privacy features that inform users about whether a chatbot will customize its behavior to them, provide them with control over this personalization via opt-in consent and the ability to withdraw it, and empower users to delete memories. Testing of these features is important to ensure a chatbot is not merely temporarily suppressing information. Transparency and control can also apply to giving users insight into whether a chatbot provider may use data gathered to enable personalization features for model training purposes. Chatbot and companions’ conversational interfaces create new opportunities for users to understand what data is gathered about them, for what purposes, and take actions that can have legal effects (e.g., requesting that data about them is deleted). However, these systems’ non-deterministic nature means that they might inaccurately describe the fulfillment of a user’s request. From a consumer protection and liability standpoint, the accuracy of AI systems is particularly important when statements have legal or material impact.
Countering Output of Biased Inferences: Chatbots and AI companions may personalize experiences by making inferences based on past user behavior. Post-model training exercises, such as red teaming to determine whether and under what circumstances an AI companion will attribute sensitive traits (e.g., speaker nationality, religion, and political views) to a user, can play an important role in lowering the incidence of biased inferences.
Setting Clear Retention Periods and Appropriate Defaults: Personalization raises questions about what data is retained (e.g., content from conversations, inferences made from user-AI companion interactions, and metadata concerning the conversation), for how long, and for what purposes. These questions become increasingly important given the potential scale, breadth, and amount of data gathered or inferred from interactions between AI companions or chatbots and users. Organizations can establish data collection, use, and disclosure defaults for this data, although these defaults may vary depending on a variety of factors, such as data type (e.g., conversation transcripts, memories and file uploads), the kind of user (e.g., consumer, enterprise and youth), and the discussion’s subject (e.g., a chat about the user’s mental health versus restaurant recommendations). In addition to establishing contextual defaults, organizational policies can also address default settings for particularly sensitive data that limit the processing of this information irrespective of context (e.g., that the organization will never share a person’s sex life or sexual orientation with a third party).
Being Clear Around Monetization Strategies: As AI companions and chatbot offerings develop, organizations are actively evaluating revenue and growth strategies, including subscription-based and enterprise pricing models. As personalized AI systems increasingly replace, or are integrated into, online search, they will impact online content that has largely been free and ad-supported since the early Internet. However, it is not clear that personalized AI systems can, or should, adopt compensation strategies that follow the same historical trajectory as existing advertising-based online revenue models. As systems develop, transparency around how personalization powers ads or other revenue strategies may be the only way to maintain user trust in chatbot outputs and manage expectations around how data will be used, given the sensitive nature of user-companion interactions.
Determining Norms and Practices for Profiling: Personalization could be the basis for profiling users based on information the user wants the system to recall going forward and that which the system observes or infers from interactions with the user. Third parties, including law enforcement, may have an interest in these profiles, which could be particularly intimate given users’ trust in these systems. Organizational norms and practices could address interest from outside actors by imposing internal restrictions on with whom and under what circumstances the organization can provide these profiles.
Limiting Data Collection to What is Necessary or Appropriate: If a chatbot or AI companion has agentic features, it may make independent decisions about what data to collect and process in order to perform a task, such as booking a restaurant reservation. Designing these systems to limit data processing activities to what is appropriate to the context can reduce the likelihood that the chatbot or AI companion will engage in inappropriate processing activities.
Responsible Design of AI Companions
Disclosures About the System’s AI Status and Incapability at Experiencing Emotions: Prominent discloses to users that the chatbot is not a human and is unable to feel emotions (e.g., lust) may counter users’ propensity to anthropomorphize chatbots. Laws and bills specifically targeting chatbots have codified this practice. Removal of use of certain pronouns, such as “I,” and modulating the output of other words that can contribute to users’ misconception about a system’s human qualities, can also reduce the likelihood of users placing inappropriate levels of trust in a system.
Redirecting Users Away From Harmful Emotional States and Perspectives: Rather than indulging or being overly agreeable towards a user’s harmful perspectives of the world and themselves, systems can react to warning signs by (i) modulating its outputs to encourage the user to take a healthy approach to topics (e.g., push back on users rather than kowtowing to their beliefs); (ii) directing users towards relevant resources in response to certain user queries, such as providing the suicide hotline’s contact information when an AI companion detects suicidal thoughts or ideation in conversations; and (iii) refusing to respond when appropriate or modifying the output to reflect the audience’s maturity (e.g., in response to a minor user’s request to engage in sexual dialogue). This risk management measure may take the form of system prompts—developer instructions that guide the chatbot’s behavior during interactions with users—and output filters.
Instituting Time Limits for Users: Limiting the amount of time a user can spend interacting with an AI chatbot may reduce the likelihood that they will form inappropriate relationships with the system, particularly for minors and vulnerable populations that are more susceptible to forming these bonds with AI companions. Age assurance may help determine which users should be subject to time limits, although common existing and emerging methods pose different privacy risks and provide different levels of assurance.
Testing and Red Teaming of Chatbot Behavior During Development: Since many of the policy and legal risks described above flow from harmful anthropomorphisation, red teaming exercises can play an important role in identifying which design features trigger users to identify human qualities in chatbots and AI companions and modify these features to the extent they encourage the user to engage in unhealthy behaviors and reactions at the expense of their autonomy.
Looking Ahead
The lines between personalization and personality will increasingly blur in the future, with an AI companion’s personality becoming tailored to reflect a user’s preferences and characteristics. For example, when a person onboards to an AI companion experience, it may prompt the new user to connect the service to other accounts and answer “tell me about yourself” questions. The experience may then generate an AI companion that has the personality of a US president or certain political leanings based on the inputs from these sources, such as the user’s social media activity.
AI companions and chatbots will evolve to offer more immersive experiences that feature novel interaction modes, such as real-time visuals, where AI characters react with little latency between user queries and system outputs. These technologies may also combine with augmented reality and virtual reality devices, which are receiving renewed attention from large technology companies as they aim to develop new user experiences that feature more seamless interaction with AI technologies. But this integration may further decrease users’ ability to distinguish between digital and physical worlds, exacerbating some of the harms discussed above by enabling the collection of more intimate information and reducing barriers to user anthropomorphization of AI. The sensors and processing techniques underpinning these interactions may also cause users to experience novel harms in the chatbot context, such as when an AI companion utilizes camera data (e.g., pupil responses, eye tracking, and facial scans) to make inferences about users.