Understanding Interconnected Local and Global Data Flows
International data flows have been top of mind in the past year for digital rights advocates, companies and regulators, particularly international transfers following the Schrems II judgment of the Court of Justice of the EU from last July. As data protection authorities assess how to use technical safeguards and contractual measures to support data flows while ensuring the protection of rights and freedoms of individuals, it’s essential to understand the interconnectedness that exists today in a highly digitized environment and globalized relationships, so that guidance can be most effective.
Here, we explore the issue of the complexity of international data flows in two distinct contexts that affect daily lives of people regardless of where they live, especially during a pandemic that has moved most of daily lives remote: (I) how they shop (retail) and (II) how they engage with education services (education technology, or EdTech). We provide an infographic for each with notes to better understand the actors and the complexities of data flows between them, while having an understanding that the systems being used and the actors involved are very often established within different jurisdictions.
Click here to download the 4-page (PDF) Infographic.
I. Understanding Retail Data Flows
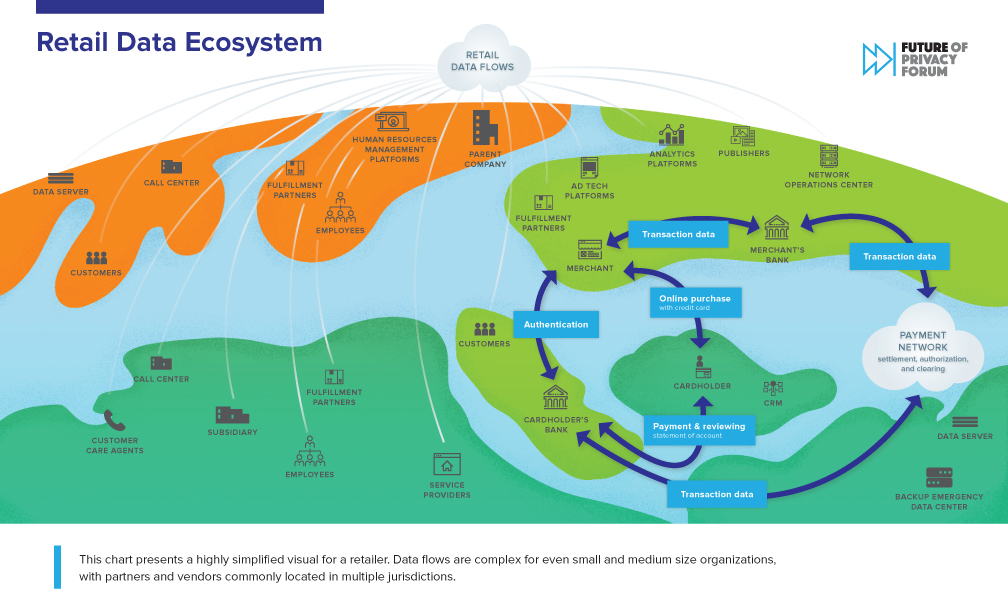
The first infographic presents a highly simplified visual for a retailer. Data flows are complex for even small and medium size organizations, with partners and vendors commonly located in multiple jurisdictions. A retailer is likely to use a number of different cloud-based service providers to support consumer transactions. Many of these service providers may only be located in a single jurisdiction and be geographically dispersed. These service providers often use other service providers, and are themselves geographically distributed and interconnected.
One of the essential services provided to a retailer is payment processing which will involve:
An individual makes an online purchase with a credit card at a merchant via its online shop.
Authentication checking before a payment is authorized.
Authorization is the process shown with the transaction data that ultimately is presented to the cardholder bank and they either approve or decline (authorize) the transaction initiated by the cardholder.
Authentication is the process whereby the issuer requests certain information from the cardholder to have a higher assurance that they are in fact who they say they are.
Payment of the bill by the cardholder’s bank.
Facilitating the routing of the payment authorizations and the transaction, clearing, and settlement of funds between banks.
Settlement of a transaction through a network that includes the merchant’s bank, the cardholder’s bank, and the payment network, i.e., credit card companies.
Monitoring network, database, application, and other critical services from a Network Operations Center (NOC) in a centralized location.
Global fraud detection and cybersecurity monitoring which consolidate both domestic and cross-border fraud data to identify patterns of fraud and to create and improve global fraud models.
Click here to download the 4-page (PDF) Infographic.
II. Understanding EdTech Data Flows
The second infographic presents a highly simplified visual of the data flows for education technology for schools and universities. Cloud based services support a wide range of programs used by teachers, students and administrators in this sector.
Schools and universities increasingly rely on EdTech applications to help educate their students. This includes online classroom/video call collaboration tools, applications to inform parents and students about important developments, learning management systems and learning content providers. Most of these providers rely on a global network of subsidiaries to support, maintain and secure their product 24/7 as well as on other service providers that deliver hosting and other specialist services. While applications and personal data of students are often hosted regionally, these subsidiaries and vendors will require access to the data for the delivery of the service.
Universities and schools will also often rely on (cloud-based) vendors to fulfill their tasks. For example:
Messaging and communications tools to stay in contact with their students, parents and the wider community as well as promoting their activities.
Specialist applications for conducting and facilitating research with international collaborators.
Online collaboration tools, e.g., video conferencing, to collaborate with other schools and universities.
For further information or to provide comments or suggestions, please contact Dr. Rob van Eijk ([email protected]) or Dr. Gabriela Zanfir-Fortuna ([email protected]).
To learn more about FPF in Europe, please visit fpf.org/eu.
Acting FTC Chairwoman Slaughter Highlights Priorities in Privacy Papers for Policymakers Event Keynote
The Future of Privacy Forum’s 11th-annual Privacy Papers for Policymakers event – the first event in the series to take place virtually – was a success! This year’s event featured a keynote speech by Acting FTC Chairwoman Rebecca Kelly Slaughter and facilitated discussions between the winning authors – Amy B. Cyphert, Clarisse Girot, Brittan Heller, Tiffany C. Li, Kenneth Propp, Peter Swire, and Lauren H. Scholz – and leaders from the academic, industry, and policy landscape, including Elana Zeide, Anupam Chander, Joan O’Hara, Jared Bomberg, Alex Joel, and Syd Terry.
Acting FTC Chairwoman Rebecca Kelly Slaughter provided the keynote address at PPPM 2021.
In her keynote address, which was also her first major speech as acting chair of the Federal Trade Commission, Acting FTC Chairwoman Slaughter outlined three of her major privacy-related priorities for the Commission:
1. Making enforcement more efficient and effective. Acting Chairwoman Slaughter observed how the COVID-19 pandemic has “only amplified the need for strong legislation at the federal level, as it has pushed more of our work, our children’s education, and even our personal interactions online, exacerbating data risks.” She explained that the FTC would need to “think creatively” to make enforcement efforts more effective without benefit of a federal privacy law. She posed the following guiding questions to center the discussion around enforcement:
Are we doing everything we can to deter future violations, both by the particular company at issue and by others in the market?
Are we doing everything we can to helped wronged consumers?
Are we using all the tools in the FTC’s toolbox to fully charge offenses and pursue misconduct?
She specifically flagged two types of relief that she believes the FTC is well-positioned to seek and achieve: meaningful disgorgement and effective consumer notice. She also stated that the FTC needs to “think carefully about the overlap between our work in data privacy and in competition,” arguing that the FTC’s dual missions to protect privacy and maintain competitive markets “can and should be complementary” as the Commission looks at problems that arise in digital markets through both privacy and competition lenses.
2. Protecting privacy during the pandemic. Acting FTC Chairwoman Slaughter acknowledged that responding the COVID requires an “all-hands approach” and that the FTC has several important roles to play as part of the solution, including addressing “COVID-related scams to privacy and security issues to an economic crisis.” She identified three key focus areas:
Ed-tech. The ubiquity of distance learning during the pandemic means that the ed-tech industry has exploded. She noted that the FTC has released guidance for parents, schools, and ed-tech providers on protecting privacy. She also stated that the Commission is conducting an industry-wide study of social media and video streaming platforms, in which they ask about the ed-tech services that those platforms provide. Finally, she noted that the FTC is currently reviewing the COPPA Rule and how it applies to the ed-tech space, stating: “We don’t need to complete our rulemaking to say that COPPA absolutely applies to ed-tech, and companies collecting information from children need to abide by it.”
Health apps. She asked FTC staff to take a close look at “all health apps, including telehealth and contact tracing apps,” acknowledging the growth of telehealth apps during the COVID-19 pandemic.
Transparency around ISPs’ privacy practices. Shenoted that the pandemic has made the importance of reliable Internet much greater, as businesses, schools, governments, and communities have struggled to find new models for staying open. She called on the FTC to issue a report on the privacy practices of ISPs in 2021.
3. Racial equity concerns in data use and abuse. Acting FTC Chairwoman Slaughter asked: “How can we at the FTC engage in the ongoing nationwide work of righting the wrongs of four hundred years of racial injustice?” She identified four key areas where the FTC could approach racial equity from the consumer protection angle:
Overlap between equity and COVID-19 privacy issues. She observed that the pandemic has exacerbated equity gaps including the “digital divide,” observing that many children lack the necessary equipment or Internet access needed to participate in distance learning. She also noted that digital services “sometimes target vulnerable communities with unwanted content and that vulnerable communities suffer outsized consequences from data privacy violations. She stated: “we need to be wary about the ways in which lower-income communities are asked to pay with their data for expensive services they cannot afford.”
Algorithmic discrimination. She said that as sophisticated algorithms are deployed in ways that impact people’s lives, “it is vital to make sure that they are not used in discriminatory ways.” She stated that the FTC has begun engaging on this issue, citing a recent report that included guidance for businesses on illegal uses of big data algorithms, including discrimination. She stated that she has “asked staff to actively investigate biased and discriminatory algorithms, and I am interested in further exploring the best ways to address AI-generated consumer harms.”
Development and deployment of facial recognition technologies. She noted that there is “clear and disturbing evidence that these technologies are not as accurate in identifying non-white individuals,” citing wrongful arrests based on faulty facial recognition matches. She stated that the Commission will “redouble our efforts to identify law violations” in the facial recognition space.
Misuse of location data. She cited articles that emerged last summer about mobile apps’ use of location data to identify characteristics of Black Lives Matter protesters and stated that she is particularly concerned about the misuse of location data as it applies to tracking Americans engaged in constitutionally protected speech.
You can read Acting FTC Chairwoman Slaughter’s full remarks at PPPM 2021 on the FTC website.
Following Acting Chairwoman Slaughter’s keynote address, the event turned to moderated discussions between the authors of the award-winning papers and leaders from the academic, industry, and policy landscapes. Click the links below to read each of the winning papers, or read the 2021 PPPM Digestto read summaries of the papers and learn more about the authors and judges.
Reimagining Reality: Human Rights and Immersive Technology, by Brittan Heller, Carr Center for Human Rights, Harvard University. For PPPM 2021, Brittan was joined by Joan O’Hara, Senior Director of Public Policy at the XR Association, who served as a discussant for the event.
After Schrems II: A Proposal to Meet the Individual Redress Challenge, by Kenneth Propp, Georgetown University Law Center; and Atlantic Council & Peter Swire, Georgia Tech Scheller College of Business; Alston & Bird LLP; and Future of Privacy Forum. For PPPM 2021, Kenneth and Peter were joined by Alex Joel, Project Lead for Privacy, Transparency, and Trust at the American University Washington College of Law, who served as a discussant for the event.
Fiduciary Boilerplate, by Lauren Henry Scholz, Florida State University College of Law. For PPPM 2021, Lauren was joined by Syd Terry, Legislative Director and Policy Coordinator for the U.S. House Committee on Energy and Commerce, who served as a discussant for the event.
Thank you to Acting FTC Chairwoman Slaughter and to Honorary Co-Hosts Senator Edward Markey and Congresswoman Diana DeGette for their support and work around this event. We would also like to thank our winning authors, discussants, everyone who submitted papers, and our event attendees for thought-provoking work and support. Learn more about the event on the FPF website and watch a recording of the event on the FPF YouTube channel.
Images from the 2021 Privacy Papers for Policymakers Event
FPF Law & Policy Fellow Marcus Dessalgne, the FPF lead on the PPPM project and emcee for the event.
Amy B. Cyphert presents her paper, Tinker-ing with Machine Learning: The Legality and Consequences of Online Surveillance of Students.
Clarisse Girot presents her paper, Transferring Personal Data in Asia: A Path to Legal Certainty and Regional Convergence.
Brittan Heller presents her paper, Reimagining Reality: Human Rights and Immersive Technology.
Tiffany C. Li presents her paper, Privacy in Pandemic: Law, Technology, and Public Health in the COVID-19 Crisis.
Kenneth Propp and Peter Swire present their paper, After Schrems II: A Proposal to Meet the Individual Redress Challenge.
Lauren Henry Scholz presents her paper, Fiduciary Boilerplate.
Emerging Patchwork or Laboratories of Democracy? Privacy Legislation in Virginia and Other States
Stacey Gray, Pollyanna Sanderson & Samuel Adams
In the absence of federal privacy legislation, U.S. states are weighing in. In Virginia, the “Consumer Data Protection Act” (“CDPA”) (HB 2307 / SB 1392) could be signed into law within weeks, and if passed, would take effect on Jan. 1, 2023. If the law passes, it would become the second comprehensive (non-sectoral) data protection law in the United States, making it a potential model for other states and federal legislation.
At present, the Virginia CDPA is about 50% of the way through Virginia’s bicameral, citizen legislature. Both bills have passed in their own chambers (in the House on Jan. 29, 89-9, and in the Senate on Feb. 5, 36-0). Either bill must now pass in the other chamber, a process that will likely involve additional hearings and opportunity for debate. Assuming either the House or Senate version passes in the other chamber without further amendment, it would then be sent to the Governor for veto, signature, or amendment. In light of the rapid speed and near-unanimous legislative support, businesses, law firms, and privacy advocates alike are beginning to pay close attention.
We provide a summary below of the key features of Virginia’s CDPA, including (1) the scope of covered entities & covered data; (2); consumer rights & pseudonymised data; (3) sensitive data and risk assessment; (4) consent standard and use limitations; (5) non-discrimination; (6) controllers, processors & third parties; (7) limitations and commercial research; and (8) enforcement.
Overall, we observe many similarities to the structure and provisions in the Washington Privacy Act (SB 5062), although there are notable differences, in particular in the scope of covered entities and personal data. Both likely go further than the California Consumer Privacy Act (CCPA) and the California Privacy Rights Act (CPRA), which do not require opt-in consent for sensitive data or mandated risk assessments – although California has made notable changes through Attorney General rulemaking. We also note some differences between these leading state legislative efforts and the EU General Data Protection Regulation (GDPR), the most notable being that US proposals rely primarily on downstream limitations on sale, sharing, and use (including through opt-outs), while the GDPR restricts all data processing for government, companies and non-profits unless one of six lawful bases are available.
Finally, we note the broader landscape of emerging state privacy legislation, including Washington State, Oklahoma, New York, Connecticut, Minnesota, and others. As more and more state models emerge, the pressure will continue to increase on Congress to pass a federal comprehensive baseline privacy law.
Watch FPF ‘s educational briefing before the Virginia Data Protection & Privacy Advisory Committee on existing and emerging US privacy laws (November 24, 2020).
1. Scope of Covered Entities & Covered Data
The Consumer Data Protection Act (CDPA) would apply to businesses “that conduct business in the Commonwealth or produce products or services that are targeted to residents of the Commonwealth” and that process “personal data” of (i) at least 100,00 consumers per year, or (ii) at least 25,000 consumers and deriving over 50% of gross revenue from the sale of personal data. It would create rights for residents of Virginia acting only in an individual or household context, and not acting in a commercial or employment context.
The CDPA has a broad definition of personal data: “any information that is linked or reasonably linkable to an identified or identifiable natural person.” This excludes “de-identified data,” as well as “publicly available information,” a broad term that encompasses information “lawfully made available through federal, state, or local government records” and “information that a business has a reasonable basis to believe is lawfully made available to the general public through widely distributed media, by the consumer, or by a person to whom the consumer has disclosed the information, unless the consumer has restricted the information to a specific audience.”
In addition, a number of exemptions are currently drafted in the bill, including for:
government entities;
non-profits;
data collected in the employment context;
covered entities in regulated sectors, including: data and covered entities governed by Health Insurance Portability and Accountability Act (HIPAA), and financial institutions and data subject to the Gramm-Leach-Bliley Act (GLBA);
information governed under the Fair Credit Reporting Act (FCRA), the Driver’s Privacy Protection Act (DPPA), the Family Educational Rights and Privacy Act (FERPA), the Farm Credit Act (FCA), and the Children’s Online Privacy Protection Act (COPPA); and
identifiable private information for purposes of the federal policy for the protection of human subjects under 45 C.F.R. Part 46; identifiable private information that is otherwise information collected as part of human subjects research pursuant to the good clinical practice guidelines issued by The International Council for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use; the protection of human subjects under 21 C.F.R. Parts 6, 50, and 56, or personal data used or shared in research conducted in accordance with the requirements set forth in this chapter, or other research conducted in accordance with applicable law.
As a result, the Virginia bill’s jurisdictional scope of “covered entities” and “personal data” is both similar and in some ways narrower than other US laws and the GDPR. It would apply to a broad definition of “personal information,” which is similar to leading US and EU law, but apply to a narrower scope of covered entities. For example, while the WPA and CCPA contain similar exemptions (for data governed by the Fair Credit Reporting Act), they do not totally exclude “entities” governed by HIPAA or GLBA. Similarly, unlike the WPA, Virginia’s bill would not apply to non-profits. The exclusions for publicly available information also differ – with the WPA containing a narrower exclusion for lawfully available government records – in contrast to information made available to the general publicly through distributed media. Given the variety of existing sectoral privacy regulatory environments in the United States (such as HIPAA and GLBA), all leading US laws and proposals so far have been narrower in scope than the GDPR – which applies broadly to all legal persons that process personal data, including non-profits, employers, and government entities.
2. Consumer Rights & Pseudonymised Data
The CDPA would grant consumers in Virginia the rights to request (1) access to their personal data; (2) correction, (3) deletion, (4) the obtainment of a copy in a “portable” and “readily usable” format; and (5) an opt-out of sale, targeted advertising, and “profiling in furtherance of decisions that produce legal or similarly significant effects concerning the consumer.” Profiling is defined as: “any form of automated processing performed on personal data to evaluate, analyze, or predict personal aspects related to an identified or identifiable natural person’s economic situation, health, personal preferences, interests, reliability, behavior, location, or movements.”
The CDPA provides a narrow limitation for “pseudonymous data,” for which companies would be required to comply with the bulk of the bill’s requirements – including opt-out rights – but not access, correction, deletion, or portability. Pseudonymous data is defined as “data that cannot be attributed to a specific natural person without the use of additional information, provided that such additional information is kept separately and is subject to appropriate technical and organizational measures to ensure that the personal data is not attributed to an identified or identifiable natural person.” Providing flexibility for “pseudonymous data” is a shared feature of the CDPA and the WPA. The approach recognizes challenges involving authentication and verification of consumer requests involving pseudonymous data, and creates an incentive for covered entities to maintain personal information in less readily identifiable formats. The treatment of pseudonymous data also has some similarities with the GDPR’s flexibility for data that cannot be identified (Article 11), recognition of pseudonymization as a risk minimizing safeguard (Recital 28), and inclusion in Privacy by Design requirements (Article 25).
When combined with the opt-in requirement for sensitive data (discussed below), this approach goes further than the California Consumer Privacy Act, which currently only requires that consumers be able to opt out of “sale.” When the California Privacy Rights Act (CPRA) goes into effect in 2023, it will add the right of correction, clarify that the opt-out of “sale” applies to all targeted advertising, and add an opt-out for limiting certain uses of sensitive data. On the other hand, Attorney General rulemaking in California has bolstered existing law by requiring compliance with “user-enabled global privacy controls” (including, arguably, new tools such as the Global Privacy Control). Other states, including Washington and Virginia, have not adopted such a “global opt-out” requirement.
3. Sensitive Personal Data & Risk Assessments
The CDPA would require “freely given, specific, informed, and unambiguous” consent (a standard discussed below) for controllers to collect or process sensitive data, defined as: “(1) personal data revealing racial or ethnic origin, religious beliefs, mental or physical health diagnosis, sexual orientation, or citizenship or immigration status; (2) the processing of genetic or biometric data for the purpose of uniquely identifying a natural person; (3) the personal data collected from a known child; and (4) precise geolocation data.” “Child” means a person younger than 13, which aligns with COPPA.
This definition roughly aligns with WPA, with a few notable differences, such as the WPA’s inclusion of “health condition” in addition to “diagnosis.” The CDPA’s definition also roughly aligns with the definition of sensitive data in the California Privacy Rights Act (CPRA), which will create an “opt-out” for sensitive data uses when it comes into effect in 2023. In contrast to California, however, both the WPA and CDPA would require affirmative opt-in consent prior to any collection of data – a much higher standard than the CPRA’s right to opt-out or limit the use and disclosure of sensitive personal information.
In addition, the CDPA (like the WPA) would create a new requirement that controllers conduct data protection assessments if engaged in any of the following:
processing of sensitive data;
targeted advertising;
sale of personal data;
“profiling” that creates a “reasonably foreseeable risk of (i) unfair or deceptive treatment of, or unlawful disparate impact on, consumers; (ii) financial, physical, or reputational injury to consumers; (iii) a physical or other intrusion upon the solitude or seclusion, or the private affairs or concerns, of consumers, where such intrusion would be offensive to a reasonable person; or (iv) other substantial injury to consumers”; or
any other processing activities involving personal data that present a “heightened risk of harm” to consumers.
These data protection assessments would be required to be made available to the Attorney General upon request, pursuant to an investigative civil demand.
4. Consent Standard & Use Limitations
The CDPA would define consent as “freely given, specific, informed, and unambiguous,” a strong opt-in standard that aligns with the GDPR and WPA. The CDPA does lack the “dark patterns” language found in the current WPA, which would specifically outlaw controllers and processors from providing deceptive user interfaces to obtain consent from individuals. We note that many of these dark patterns may already be illegal under state and federal consumer protection law, as University of Chicago’s Lior Strahelivits observes in a recent paper, “Shining a Light on Dark Patterns.”
The CDPA would require controllers to obtain opt in consent to process personal data for incompatible secondary uses, “as disclosed to the consumer.” This is likely to be less restrictive in practice for businesses than the current WPA, which removed this language in the version of the bill introduced in 2021. Under the WPA, collection of personal data must be limited to what is reasonably necessary in relation to the purposes for which the data is processed; and adequate, relevant, and limited to what is reasonably necessary in relation to the purposes for which the data is processed. In comparison, the GDPR’s principle of purpose limitation requires all data collection to be only for a specified, explicit, and legitimate purpose, which includes compatible purposes.
5. Non-Discrimination
The CDPA would prohibit a controller from discriminating against a consumer for exercising any of their consumer privacy rights, including denying goods or services, charging different rates, or providing a different level of quality of goods and services. However, similar to California law, it provides a broad exception for “voluntary participation in a bona fide loyalty, rewards, premium features, discounts, or club card program.” In contrast, the current WPA contains a narrower exemption for such programs that would require additional disclosures and limits the sale and secondary uses of personal information.
In addition, the CDPA would prohibit controllers from processing personal data in violation of state and federal laws that prohibit unlawful discrimination against consumers. A similar requirement is in the WPA. In comparison, while the GDPR does not contain a specific provision stating that a data subject must not be discriminated against on the basis of their choices to exercise rights, other principles of the GDPR require that individuals must be protected from discrimination on these grounds (Article 5, Article 13, Article 22, and elements of “freely given” consent and fair processing).
6. Controllers, Processors & Third Parties
The CDPA follows the GDPR and WPA structure of dividing responsibilities between “controllers” and “processors,” rather than using the CCPA/CPRA terminology of “businesses” and “service providers”:
“Controller” is defined as “the natural or legal person that, alone or jointly with others, determines the purpose and means of processing personal data.” Controllers would be required to comply with transparency obligations, consumer requests, data protection assessments, and data security practices.
“Processor” is defined as “a natural or legal entity that processes personal data on behalf of a controller.” Processors would be responsible for adhering to the instructions of the controller, and assisting the controller to meet its obligations under the Act involving responding to consumer requests to exercise their rights, fulfilling security obligations, and providing the information necessary to enable the controller to conduct and document data protection assessments. Processors would be subject to a duty of confidentiality, and would themselves be required to contractually obligate subcontractors to adhere to the same obligations.
“Third party” is defined as “a natural or legal person, public authority, agency, or body other than the consumer, controller, processor, or an affiliate of the processor or the controller.” Controllers would be required to provide consumers with a reasonably accessible, clear, and meaningful privacy notice that includes the categories of personal data that the controller shares with third parties, if any; the categories of third parties, if any, with whom the controller shares personal data; and if a controller sells personal data to third parties or processes personal data for targeted advertising, the controller would be required to “clearly and conspicuously” disclose such processing, as well as the manner in which a consumer may exercise the right to opt out of such processing. Of note, if a third party recipient processes data in violation of the Act, controllers and processors would not be liable to the extent that they did not have “actual knowledge” that the recipient intended to commit a violation.
7. Limitations and Commercial Research
The CDPA would not limit a controller or processor’s ability to provide a product or service specifically requested by a consumer, perform a contract to which the consumer is a party; comply with existing laws; cooperate with civil, criminal, or regulatory investigations; cooperate with law enforcement agencies; defend legal claims; to protect an interest that is essential to the life or physical safety of the consumer or another natural person; or protect against fraud, theft, or harassment.
In addition, the CDPA would not restrict the ability of controllers and processors to engage in public or peer-reviewed scientific or statistical research in the public interest that is approved, monitored, and governed by an institutional review board (IRB) or a “similar independent oversight entity.” This aligns provides greater flexibility for commercial research than the CCPA, and aligns with broader trends in U.S. privacy legislation, including the WPA, Sen. Cantwell’s (D-WA) COPRA, and Sen. Wicker’s (R-MS) SAFE DATA Act.
The requirements of the CDPA would also not limit the ability of controllers and processors to “collect, use, or retain data” to: 1) conduct internal research to “develop, improve, or repair products, services, or technology”; 2) effectuate product recalls, identify and repair technical errors; or 3) to perform internal operations that are reasonably aligned with the “reasonable expectations” of the consumer or “reasonably anticipated” based on the consumer’s existing relationship with the controller.
8. Enforcement
The CDPA, which contains a 30-day cure period, would be enforced by the Attorney General, with civil fines capped at $7,500. The legislation would establish a Consumer Privacy Fund within the Office of the Attorney General in order to establish funding in future years.
A right to cure period is a current feature in the CCPA that will be removed by the California Privacy Rights Act, and is currently being debated in Washington State. In Virginia, several stakeholders have testified that the cure period would promote faster and less costly results for consumers, and may be useful as businesses adapt to compliance. Others, such as Consumer Reports, have advocated for it to be removed as unduly limiting on enforcement. At a recent hearing on the WPA in Senate Ways & Means Committee, the WA Attorney General Office suggested sunsetting the cure period once affected entities had time to adjust their data practices.
Recognizing the Broader Landscape of Emerging State Laws
Virginia is not alone – many, if not most, U.S. states are considering or introducing consumer privacy legislation in 2021. The CDPA shares a similar framework with the WPA and the Minnesota Consumer Data Privacy Act (HF3936). Some align more closely with the CCPA, e.g., Michigan (HB6457), Connecticut (SB156), New York (Data Accountability and Transparency Act). These bills generally place a greater focus on privacy self-management, business-consumer relationships, and enabling consumers to “opt-out” of having their personal data “sold.” In contrast, Oklahoma (OK 1602) is actively considering a proposal that would provide individuals with a right to “opt-in” to sales of their personal data. If passed, the CDPA would be the second comprehensive (non-sectoral) data protection law in the United States after the CCPA. As more and more states weigh in, however, significant issues are already beginning to arise about interoperability for companies handling data across state lines. For now, legislation in Virginia, Washington, and Minnesota are in some ways interoperable with the GDPR and the CCPA, but will clearly require companies to customize practices to match key differences in each state. As additional laws pass, and if further conflicts emerge, it will certainly increase the pressure on Congress to pass a federal comprehensive baseline privacy law. At a Nov. 24 hearing, Virginia legislators generally expressed a preference for federal legislation, but recognized that in its absence, Virginia residents deserve data protection rights already enjoyed in California, by everyone in Europe, and by an increasing number of people around the world.
Schrems II: Article 49 GDPR derogations may not be so narrow and restrictive after all?
by Rob van Eijk and Gabriela Zanfir-Fortuna
On January 28, 2021, the German Federal Ministry of the Interior organized a conference celebrating the 40th Data Protection Day, the date on which the Council of Europe’s data protection convention, known as “Convention 108”, was opened for signature. One of the invited speakers and panelists was Prof. Dr. Dr. von Danwitz, the judge-rapporteur in the CJEU Schrems I Case (C‑362/14), the CJEU Schrems II Case (C‑311/18), and the CJEU Case La Quadrature du Net and Others (C-511/18). He spoke at length about the Schrems II judgment and its significance for cementing the importance of the fundamental right to personal data protection, as well as generously replied to specific questions about the options available now to companies to lawfully transfer personal data from the European Union to the United States. In particular, his comments on the possibility to rely on Article 49 GDPR derogations were noteworthy, as they seemed to contradict the narrow approach taken by the European Data Protection Board in its interpretation.
The recording of the keynote by Prof. Dr. Dr. von Danwitz starts here (1h12m). The recording of the panel intervention by von Danwitz starts here (2h17m).
Please note that all quotes used in this article are a translation from German.
The broader context: A fundamental right that still needs to be taken seriously
In his introductory remarks providing context to the Schrems II judgment of the CJEU, judge von Danwitz admitted that he had “quite a lot of sleepless nights over this case”. He added that, “however, it is not the task of a court to find the least problematic solution to a case”.
According to the judge, the awe that the judgment created for some comes from the fact that the consequences of having the right to the protection of personal data elevated as fundamental right in the EU Charter and in the Treaty of Lisbon “are still not fully understood and recognized today”. He added that “the EU attaches great importance to the protection of these rights (respect for private life under Article 7 and protection of personal data under Article 8 of the Charter – n.), especially in comparison to the partial or rudimentary textual references in national constitutions”.
Judge von Danwitz showed that he is fully aware of the breadth and the pervasiveness of cross-border data transfers in today’s digitalized society: “data transfers to third countries are not rare incidents. It is common practice to outsource certain data-based services to third countries. This may be economically useful and desirable for enterprises, but it should not compromise the level of protection of personal data”.
He explained that “the necessary balance between the legitimate interests of economic operators and the promotion of international trade on the one hand, and the right to the protection of personal data on the other, is reflected in the legal requirements that an essentially equivalent level of protection of personal data must be ensured when data is transferred to third countries”.
The judge also acknowledged that some countries may not ensure at all this high level of protection of personal data and this fact “may have economic disadvantages for companies in individual cases”. He explained that “nevertheless, this is the necessary consequence of the fundamental decision taken by the European Union to ensure a high level of protection of personal data”. As he ultimately framed it, the entire discussion “is about the much more fundamental question of what is the society we want to live in and our aspiration to shape this society in line with European law and values”.
No legal void: The Court saw Article 46 safeguards and Article 49 derogations as filling the gap
First in his keynote and later on in the panel, judge von Danwitz explained that the Court decided to annul the Privacy Shield with immediate effect – as opposed to allowing for a grace period, because there was no legal void in its absence. He mentioned that GDPR Article 46 safeguards and Article 49 derogations “cover the absence of an adequacy decision”.
During the panel, the discussion centered around the following question: “How, for example, am I as an entrepreneur supposed to implement these requirements in data transfer after Schrems II? Which guidelines apply?”
In response to the question, von Danwitz remarked: “The question is very legitimate. The question is this, as an enterprise, do I have to transfer data to third countries for which there is no adequacy decision by the European Commission? Yes or no? That’s the fundamental question.”
“And if this question is to be answered to the effect that [transfers] are absolutely necessary, then I need to use, e.g., standard contractual clauses. At least that’s the standard approach. (…) If standard contractual clauses are not possible, because my process in the third country cannot comply with these clauses under the applicable national law, then, of course, there’s the question of the transfer of data by relying on [the derogations for specific situations in] Article 49 GDPR.”
Von Danwitz mentioned that Article 49 derogations are in particular an option for intra-group transfers and that they should be more attentively explored. “(…) In my opinion, the opportunities granted by Article 49 have not been fully explored yet. I believe they are not so narrow that they restrict any kind of transfer, especially when we’re talking about transfers within one corporation or group of companies.”
Von Danwitz indicated that the conditions from the text of the GDPR in any case must be met. For example, in the case of the derogation relying on necessity to enter a contract or for the performance of a contract, the first test is to ask “is the transfer of that data really required? Is it really necessary to fulfill the contract?” He added: “In my opinion, this gives people sufficient scope of action”.
The judge didn’t go into further details and also clarified that questions related to the scope of Article 49 derogations might be posed to the court in the future, and he doesn’t want to “preempt any judgments by making a statement now”.
Although von Danwitz made the observations in a personal capacity, they mark a new opening in the discussion on data transfers which some refer to as a proverbial Gordian Knot. Furthermore, the remarks are important against the background of the European Data Protection Board (EDPB) Recommendations 01/2020 on measures that supplement transfer tools to ensure compliance with the EU level of protection of personal data. The public consultation period for the recommendations has ended and the EDPB has started processing the comments submitted by stakeholders.
You can find the recordings here: in German, English, and French. The intervention in German by Prof. Dr. Dr. von Danwitz on the exploration of the Article 49 derogations starts at this bookmark: 02h23m12s.
To listen to the keynote by Prof. Dr. Dr. von Danwitz, click here (1h12m). To listen to the panel intervention by von Danwitz, click here (2h17m).
Photo credit: arbyreed CC BY-NC-SA 2.0.
To learn more about FPF in Europe, please visitfpf.org/about/eu.
CPDP2021 Event Recap: Bridging the Standards Gap
On January 27, 2021, the Institute of Electrical and Electronics Engineers (IEEE) hosted a panel at the 14th Annual International Computers, Privacy, and Data Protection Conference (CPDP2021). The theme for this year’s online conference was “Enforcing Rights in a Changing World.” Rob van Eijk, FPF Managing Director for Europe, moderated the panel “Technical Standards Bringing Together Data Protection with Telecommunications Regulation, Digital Regulations, and Procurement.”
The panelists discussed the role of technical standards in ensuring the systematic application of data protection principles across policy areas. Two examples are Article 25 GDPR and Recital 78, which stipulate data protection by design and by default. Another example is Article 21(5) of the GDPR, which stipulates that in the context of the use of information society services, and notwithstanding Directive 2002/58/EC, the data subject may exercise his or her right to object by automated means using technical specifications.
Technical standards seek to ensure that engineers can effectively apply privacy and data protection principles in the design and the (default) configuration of technology placed on the market. Therefore, a key question for the panel discussion was: How to bridge the gap between releasing technical standards and embedding them into products and services available on the market?
Facilitating Dialogue and Collaboration Between Policymakers and Technologists
Paul Nemitz, Principal Advisor in the Directorate-General for Justice and Consumers at the European Commission, started the discussion with a precise observation. He argued that building a closer, collaborative relationship between engineers and policymakers is a critical step to bridge the gap between data protection policies, technical standards, and practical application. He called on the technical intelligentsia to bring their knowledge to the policymaking process, stating that democracy needs the engagement of the engineers. Paul also expressed that policymakers should hold out their hands and open their doors to bring in those who know the technology. He identified convincing those with the technical knowledge to also engage in the formal lawmaking process as one of the challenges of our time.
He clarified that he was not claiming engineers know how to make policies better than policymakers. Instead, he defined specific roles for each group based on their areas of expertise and working languages. The technologists’ part is to inform and educate policymakers to be able to shape laws that are technology-neutral and do not have to be updated every two months. According to Paul, while engineers are adept at writing code, code is written for machines that cannot think for themselves. However, the law is written for people, not computers, and policymakers are best equipped for this language. Paul also sees the relationship as a two-way street where technologists can bring their technological knowledge to the rulemaking process then go back to their spaces with a better understanding of democracy.
Clara Neppel, Senior Director of IEEE European Business Operations, shared that all IEEE standardization bodies have a government engagement program where governments can inform the IEEE standardization organization about their policy priorities. That allows software engineers to take into account upcoming legislative measures.
Amelia Andersdotter, Dataskydd.net and Member of the European Parliament 2011-2014, stressed the importance of ensuring that standards – once set – are transparent and effectively communicated to everyone in the ecosystem, i.e., from procurement bodies to end-users. For instance, when the public sector seeks to build a public WiFi network or a company designs a website, those demanding the products should be aware of the frameworks in place that protect human rights and data as well as the right questions to ask of those further up in the value chain (See also the FPF & Dataskydd.net Webinar – Privacy in High-Density Crowd Contexts). The IEEE P802E working group has been drafting Recommended Practices for Privacy Considerations for IEEE 802 Technologies (P802E). P802E contains recommendations and checklists for IEEE 802 technologies developers).
Panelists left to right, top row: Rob van Eijk, Paul Nemitz, Clara Neppel; bottom row: Amelia Andersdotter, Mikuláš Peksa. We remark that Francesca Bria (President of the Italian National Innovation Fund) contributed to the preparation of the panel discussion.
Privacy versus utility
According to Clara, key challenges faced when implementing privacy include the lack of common definitions, the tradeoff between privacy and functionality of the products or services, and reaching the right balance between social values embedded in data governance and technical measures. Clara pointed out that privacy can have different meanings for different parties. For example, a user may understand privacy as meaning no data is shared, only anonymous data is shared, or being able to define different access levels for different types of data. On the other hand, companies may interpret privacy as solely being compliant with relevant laws or as a true value proposition for their customers.
Amelia also identified the lack of specification of data protection principles or requirements in legislation as leading to confusion and inefficiencies for engineers and companies. She cited the case of the European Radio Equipment and Telecommunications Terminal Equipment Directive (R&TTE), adopted in 1999, which includes data protection as an essential requirement for radio technologies. However, what this requirement actually means has never been specified, resulting in companies being unable to assess whether their technologies meet the requirement. She expressed that Europe is good at establishing both the high-level values and low-level practical architectures, but could improve if regulators filled the gap and created a framework for assessing privacy.
Amelia also suggested that the diversity and flexibility of technical standards may encourage more experimentation and optimization as organizations choose which standards work best for their specific technologies and in their specific contexts.
Rob added that technologists need bounded concepts with definitions embedded in law, so they are clear and no longer open-ended. Then, the real work of figuring out how the technology should be designed to protect privacy can take place.
Rulemaking: Looking to the Future Rather Than in the Rear Mirror
Mikuláš Peksa, Member of the European Parliament, expressed skepticism with the European Parliament micromanaging technical standards. Instead, he leaned towards Parliament conveying basic values that protect human rights but not shaping the standards themselves.
Mikuláš contended that politicians may talk about past problems and, due to structural and procedural factors, politics always reacts with a certain delay. He stated that human society is in another Industrial Revolution where all human activities are changing. Therefore, society needs to adapt to be able to absorb and digest the changes. He referred to the example of online spaces for conversations being monopolized by a single company. He questioned whether this is the model society really wants and suggested exploring the idea of a decentralized architecture for social networks, like that of other mail services, to protect against centralized control.
Paul explained that data protection faces the classic syndrome of an ‘invisible risk’ due to the fact that people are unable to see themselves as victims. Where people fail to see the ‘invisible risk’, such as with atomic power, smoking, or data processing, politics arrives far too late. Looking forward, Mikuláš acknowledges that there is no single silver bullet to solve all of the problems. Therefore, Europe needs the political organization to incorporate the technical intelligentsia and find a desirable general direction to drive towards.
Next steps
In a tour-de-table, the panelists presented their answer and next steps on how to bridge the gap between releasing technical standards and embedding these into products and services available on the market.
Clara remarked that we may need policymakers to engage in technical considerations like standard setting as well as provide legal certainty clarifying questions around data control and correction. We may also need new standards, certifications, and good mechanisms to address special needs for specific contexts. For instance, when it comes to synthetic data, which is estimated to be 40 percent of all training data in two years, we lack metrics on how to measure the quality in terms of privacy, in terms of accuracy.
Amelia argued that in addition to work done by consumer protection authorities, data protection authorities, and telecommunications regulations, one could also just take the initiative in a company or a space. There are already industry efforts to ensure technologies are more privacy-sensitive and robust. Rome wasn’t built in a day and she doesn’t think our infrastructures will be either, but we can take small steps in the right direction and we will be in a better place in two or three years than we are now.
Mikuláš stated that there is no one silver bullet that will resolve all of the problems. He argued that we need a political organization that will incorporate technical intelligentsia, an organization that will be able to steer the general direction of building this new information society. Without it, we will not be able to introduce the standards in a proper way.
In closing, Paul called upon people who deeply understand the intricacies of technology to engage with the democratic legislative process of law making. In this way, they may be able to not only bring technological knowledge to the rulemaking process but also incorporate a better understanding of the realities of democracy into code.
FPF contributions to the privacy debate at CPDP2021
To learn more about FPF in Europe, please visit fpf.org/about/eu.
Snap into Data Privacy Day
Data is increasingly the lifeblood of commerce, research, and government. Data analysis is providing new insights into our health, making transportation safer, and increasing the usefulness of online services. It is a key to developing medical breakthroughs, educating students during the pandemic, and combating inequity and discrimination.
But if society is going to enjoy the benefits of data, we need to empower individuals and ensure that businesses respect privacy, safeguard data, and earn trust. That’s our message for Data Privacy Day, celebrated yearly on January 28. To bring the message to a broad audience, we’re pleased to be partnering with Snapchat to provide a privacy-themed Snap filter for Data Privacy Day 2021.
Scan here to access the filter – it’s only available on Jan. 28, 2021!
The Future of Privacy Forum (FPF) is a non-profit organization that brings together privacy scholars, researchers, advocates, and industry leaders around the world to explore solutions and advance principled data practices in support of emerging technologies.
If you’re interested in exploring the issues that are driving the future of privacy, sign up for our monthly briefing or check out one of our virtual events. You’ll find some of the smartest minds in privacy, discussing how best to ensure society benefits from the insights gained from data, while respecting individual choice and autonomy.
P.S.
Why are we and many others around the world marking Data Privacy Day on January 28? It’s the anniversary of an important global data protection treaty known as Convention 108, a standard that has influenced the development of data protection laws around the world. We are hoping that 2021 will be the year the United States steps up and joins the many nations that have passed a comprehensive data protection law!
FPF Seeks Nominations for 2021 Research Data Stewardship Award
The Call for Nominations for the 2021 FPF Award for Research Data Stewardship is now open. You can find the nominations forms here. We ask that nominations be submitted by Monday, March 1, 2021.
The FPF Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data that is shared with academic researchers. The award highlights companies and academics who demonstrate novel best practices and approaches to sharing corporate data in order to advance scientific knowledge.
The 2020 Research Data Stewardship Award was given to Lumos Labs and Professor Mark Steyvers for their path breaking work using data to model human attention and cognition. We look forward to reading submissions of innovative work in cognitive science and any other scientific field this year. We are keenly interested in multidisciplinary work that shows the power of shared data to answer questions that span multiple fields of inquiry.
Academics and their corporate partners are invited to nominate a successful data-sharing project that reflects privacy protective approaches to data protection and ethical data sharing. Nominations will be reviewed and selected by an Award Committee comprised of representatives from FPF, leading foundations, academics, and industry leaders. Nominated projects will be judged based on several factors, including their adherence to privacy protection in the sharing process, the quality of the data handling process, and the company’s commitment to supporting the academic research.
The nominations form will be open until February 19th. If you have questions about the nomination form, the process of review, or any other information about the award, please contact Dr. Sara Jordan at sjordan at fpf dot org.
FPF in 2020: Adjusting to the Unexpected
With 2020 fast coming to a close, we wanted to take a moment to reflect on a year that forced us to re-focus our priorities, along with much of our lives, while continuing to produce engaging events, thought-provoking analysis, and insightful reports.
Considering Privacy & Ethics at the Dawn of a New Decade
Early in the year, our eyes were on the future – at least through the rest of the decade – and how privacy and ethical considerations would impact our lives and new and upcoming technologies over the next ten years.
The Privacy 2020: 10 Privacy Risks and 10 Privacy Enhancing Technologies to Watch in the Next Decade white paper, co-authored by FPF CEO Jules Polonetsky and hacklawyER Founder Elizabeth Renieris, helped corporate officers, nonprofit leaders, and policymakers better understand the privacy risks that will grow to prominence during the 2020s, as well as rising technologies that will be used to help manage privacy through the decade.
In February, we hosted the 10th-annual Privacy Papers for Policymakers event. The yearly event recognizes the year’s leading privacy research and analytical work that is relevant for policymakers in the United States Congress, federal agencies, and international data protection authorities. We were honored to be joined by FTC Commissioner Christine S. Wilson, who keynoted the event, and leading privacy scholars and policy and regulatory staff.
FPF CEO Jules Polonetsky delivered a keynote address at RSA Conference 2020 in San Francisco, Navigating Privacy in a Data-Driven World: Treating Privacy as a Human Right. In his speech, Jules outlined the limitations of consumer protection laws in protecting individuals’ privacy and explored how to best safeguard data to protect human rights.
“Are corporations having too much power over individuals because of how much data they have? Are foreign countries interfering in our elections? Are automated decisions being made where I’ll be turned down for healthcare, I’ll be turned down for insurance, my probation will be extended? These are not [only] privacy issues, right? These are issues of power. These are issues of human rights at the end of the day.”
Adjusting to a One-in-a-Century Pandemic
By March, it was clear that the COVID-19 pandemic would impact every aspect of our lives, and we moved nimbly to respond and re-assess our immediate priorities. FPF launched the Privacy and Pandemicsseries, a collection of resources published throughout the year that explores the challenges posed by the COVID-19 pandemic to existing ethical, privacy, and data protection frameworks, seeking to provide information and guidance to governments, companies, academics, and civil society organizations interested in responsible data sharing to support the public health response. Some of the initial materials published in the spring as part of this series included:
A Closer Look at Location Data: Privacy & Pandemics. In light of COVID-19, interest grew in harnessing location data held by major tech companies to track individuals affected by the virus, better understand the effectiveness of social distancing, and send alerts to individuals who might be affected. FPF addressed a range of privacy and ethics concerns in a brief explainer guide covering (1) what is location data, (2) who holds it, and (3) how it is collected.
Privacy & Pandemics: The Role of Mobile Apps (Chart). Multiple apps and software development kits (SDK) were deployed to help both privacy and public entities tackle the COVID-19 pandemic. In order to better understand these technologies, FPF created a comparison chart to contrast the objectives and methods of specific SDK apps.
In April, FPF Senior Counsel Stacey Gray provided the Senate Committee on Commerce, Science, and Transportation with written testimony, including recommendations based on how experts in the U.S. and around the world are currently mitigating the risks of using data to combat the COVID-19 pandemic.
Experts have used machine learning technologies to study the virus, test potential treatments, diagnose individuals, analyze the public health impacts, and more. In early May, FPF Policy Counsel Dr. Sara Jordan and FPF Senior Counsel Brenda Leong published a resource covering leading efforts, data protection and ethical issues related to machine learning and COVID-19.
As part of our ongoing Privacy and Pandemics series, FPF, Highmark Health, and Carnegie Mellon University’s CyLab Security and Privacy Institute, hosted a virtual symposium that took an in-depth look at the role of biometrics and privacy in the COVID-19 era. During the virtual symposium, expert discussants and presenters examined the impact of biometrics in the ongoing fight against the novel coronavirus. Discussions about law and policy were enhanced by demonstrations of the latest facial recognition and sensing technology and privacy controls from researchers at CMU’s CyLab.
On October 27 and 28, FPF hosted a workshop titled Privacy & Pandemics: Responsible Uses of Technology and Health Data During Times of Crisis. Dr. Lauren Gardner, creator of Johns Hopkins University’s COVID-19 Dashboard, and UC Berkeley data analytics researcher Dr. Katherine Yelick were keynote speakers. The workshop – held in collaboration with the National Science Foundation, Duke Sanford School of Public Policy, SFI ADAPT Research Centre, Dublin City University, OneTrust, and the Intel Corporation – also featured wide-ranging conversations with participants from the fields of data and computer science, public health, law and policy. Following the workshop, FPF prepared a report for the National Science Foundation to help speed the transition of research into practice to address this challenge of national importance.
Global Expertise & Leadership
FPF’s international work continued to expand in 2020, as policymakers around the world are focused on ways to improve privacy frameworks. More than 120 countries have enacted a privacy or data protection law, and FPF both closely followed and advised upon significant developments in the European Union, Latin America, and Asia.
We were proud to announce our new partnership with Dublin City University (DCU), which will lead to joint conferences and workshops, collaborative research projects, joint resources for policymakers, and applications for research opportunities. DCU is home to some of the leading AI-focused research and scholarship programs in Ireland. DCU is a lead university for the Science Foundation Ireland ADAPT program, and hosts the consortium leadership for the INSIGHT research centre, two of the largest government funded AI and tech-focused development programs. Notably, the collaboration has already resulted in a joint webinar, The Independent and Effective DPO: Legal and Policy Perspectives, and we’re excited about further collaboration in 2021 and beyond.
Following the Prime Minister of Israel’s announcement that the government planned to use technology to address the spread of COVID-19, Limor Shmerling Magazanik, Managing Director of the Israel Tech Policy Institute, published recommendations to ensure a balance between civilian freedoms and public health. Specifically, her recommendations centered around ensuring transparency, limits on the length of time that data is held, requiring a clear purpose for data collection, and robust security.
The Schrems II decision from the Court of Justice of the European Union held serious consequences for dataflows coming from the EY to the United States, as well as to most of the other countries in the world. In advance of the decision, FPF published a guide called, What to Expect from the Court of Justice of the EU in the Schrems II Decision This Week by FPF’s Dr. Gabriela Zanfir Fortuna. FPF also conducted a study of the companies enrolled in the cross-border privacy program called Privacy Shield, finding that 259 European-headquartered companies are active Privacy Shield participants.
Leveraging our growing focus on the international privacy landscape, and as part of our growing work related to education privacy, we published a report titled The General Data Protection Regulation: An Analysis and Guidance for US Higher Education Institutions, authored by FPF Senior Counsel Dr. Gabriela Zanfir-Fortuna. The report contains analysis and guidance to assist U.S.-based higher education institutions and their edtech service providers in assessing their compliance with the European Union’s General Data Protection Regulation.
We hosted several events and roundtables in Europe. On December 2, 2020, the fourth iteration of the Brussels Privacy Symposium, Research and the Protection of Personal Data Under the GDPR, took place as a virtual international meeting where industry privacy leaders, academic researchers, and regulators discussed the present and future of data protection in the context of scientific data-based research and in the age of COVID. The virtual event is the latest aspect of an ongoing partnership between FPF and Vrije Universiteit Brussel (VUB). Keynote speakers were Malte Beyer-Katzenberger, Policy Officer at the European Commission; Dr. Wojciech Wiewiórowski, the European Data Protection Supervisor; and Microsoft’s Cornelia Kutterer. Their presentations sparked engaging conversations on the complex interactions between data protection and research as well as the ways in which processing of sensitive data can present privacy risks, and also unearth covert bias and discrimination.
Scholarship & Analysis on Impactful Topics
The core of our work is providing insightful analysis on prevailing privacy issues. FPF convenes industry experts, academics, consumer advocates, and other thought leaders to explore the challenges posed by technological innovation, and develop privacy protections, ethical norms, and workable business practices. In 2020 – through events, awards, infographic guides, papers, studies, or briefings – FPF provided thoughtful leadership on issues ranging from corporate-academic data sharing to encryption.
In mid-May, the Future of Privacy Forum announced the winners for the first-ever FPF Award for Research Data Stewardship: Professor Mark Steyvers, University of California, Irvine Department of Cognitive Sciences, and Lumos Labs. The first-of-its-kind award recognizes a privacy protective research collaboration between a company and academic researchers, based on the notion that when privately held data is responsibly shared with academic researchers, it can support significant progress in medicine, public health, education, social science, and other fields. In October, FPF hosted a virtual event honoring the winners, featuring – in addition to the awardees – Daniel L. Goroff, Vice President and Program Director at the Alfred P. Sloan Foundation, which funded the award, as well as FPF CEO Jules Polonetsky and FPF Policy Counsel Dr. Sara Jordan.
FPF published an interactive visual guide, Strong Data Encryption Protects Everyone, illustrating how strong encryption protects individuals, enterprises, and the government. The guide also highlights key risks that arise when crypto safeguards are undermined – risks that can expose sensitive health and financial records, undermine the security of critical infrastructure, and enable interception of officials’ confidential communications.
Over the summer, we published interviews with senior FPF policy experts about their work on important privacy issues. As part of this series of internal interviews, we spoke with FPF Health Policy Counsel Dr. Rachele Hendricks-Sturrup, FPF Director of Technology and Privacy ResearchChristy Harris, FPF Managing Director for Europe Rob van Eijk, and FPF Policy Counsel Chelsey Colbert.
FPF Policy Fellow Casey Waughn, supported by Anisha Reddy and Juliana Cotto from FPF, and Antwan Perry, Donna Harris-Aikens, and Justin Thompson at the National Education Association, released new recommendations for the use of video conferencing platforms in online learning. The recommendations ask schools and districts to reconsider requiring students to have their cameras turned on during distanced learning. These requirements create unique privacy and equity risks for students, including increased data collection, an implied lack of trust, and conflating students’ school and home lives.
Following the 2020 election, FPF has hosted several events looking ahead to the policy implications of a new Administration and Congress in 2021, including a roundtable discussion where Jules was joined by Jonathan Baron, Principal of Baron Public Affairs, a leading policy and political risk strategist, as well as FPF’s Global and Europe leads, Dr. Gabriela Zanfir-Fortuna and Rob Van Eijk. In addition, Jules; FPF Senior Fellow Peter Swire; VP of Policy John Verdi; and Senior Counsel Stacey Gray also held a briefing with members of the media to discuss expectations on what the Biden administration, FTC, and states will accomplish on privacy in the coming year. IAPP published an article summarizing the briefing.
Linking Equity & Fairness with Privacy
Alongside a pandemic that forced us to shift our priorities, 2020 saw a needed national reckoning with issues related to diversity and equity. From racial justice and the LGBTQ+ community to child rights, FPF took conscious steps to reflect on, understand, and address essential questions related to equity and fairness in the context of privacy.
The data protection community has particular challenges as we grapple with the many ways that data can be used unfairly. In response, our team has focused on listening and learning from leaders with diverse life and professional experiences to help shape more careful thinking about data and discrimination. As part of that project, we published remarkson diversity and inclusion from Macy’s Chief Privacy Officer and FPF Advisory Board member Michael McCullough delivered at the WireWheel Spokes 2020 conference. We also discussed Ruha Benjamin’s Race After Technology: Abolitionist Tools for the New Jim Code as part of our ongoing book club series and were honored to be joined by the author for the discussion.
LGBTQ+ rights are, and have always been, linked with privacy. Over the years, privacy-invasive laws, practices, and norms have been used to oppress LGBTQ+ individuals by criminalizing and stigmatizing individuals on the basis of their sexual behavior, sexuality, and gender expression. In honor of October as LGBTQ+ History Month, FPF and LGBT Tech explored three of the most significant privacy invasions impacting the LGBTQ+ community in modern U.S. history: anti-sodomy laws; the “Lavender Scare” beginning in the 1950s; and privacy invasions during the HIV/AIDS epidemic. These examples and many more were discussed as part of a LinkedIn Live event on International Human Rights Day, featuring LGBT Tech Executive Director Christopher Wood, FPF Founder and Board Chair Christopher Wolf, LGBT Tech Deputy Director and General Counsel Carlos Gutierrez, FPF Policy Counsel Dr. Sara Jordan, and FPF Christopher Wolf Diversity Law Fellow Katelyn Ringrose.
FPF submitted feedback and comments to the United Nations Children’s Fund (UNICEF) on the Draft Policy Guidance on Artificial Intelligence (AI) for Children, which seeks “to promote children’s rights in government and private sector AI policies and practices, and to raise awareness of how AI systems can uphold or undermine children’s rights.” FPF encouraged UNICEF to adopt an approach that accounts for the diversity of childhood experiences across countries and contexts. Earlier in October, FPF also submitted comments to the United Nations Office of the High Commissioner for Human Rights Special Rapporteur on the right to privacy to inform the Special Rapporteur’s upcoming report on the privacy rights of children. FPF will continue to provide expertise and insight on child and student privacy, AI, and ethics to agencies, governments, and corporations to promote the best interests of children.
This post is by no means an exhaustive list of our most important work in 2020, but we hope it give you a sense of the scope of our impact. On behalf of everyone at FPF, best wishes for 2021!
FPF Health and AI & Ethics Policy Counsels Present a Scientific Position at ICML 2020 and at 2020 CCSQ World Usability Day
Drs. Hendricks-Sturrup and Jordan gave their position that patient reported outcomes (PROs) data requires special privacy and security considerations, due to the nature of the data, if used within on-device or federated machine learning constructs as well as in the development of artificial intelligence platforms. Patient reported outcomes, being a raw form of patient expression and feedback, help clinicians, researchers, medical device and drug manufacturers, and governmental stakeholders overseeing medical device and drug development, distribution, and safety monitor, understand, and document, in a readable format, patients’ symptoms, preferences, complaints, and/or experiences following a clinical intervention. Gathering and using such data requires careful attention to security, data architecture, data use, and machine-readable consent tools and privacy policies.
Even so, on-device patient reported outcome measurement tools, like patient surveys within third-party mobile apps that use machine learning, may employ the best machine-readable privacy policies or consent mechanisms, but may ultimately leave key components of privacy protections up to the patient-user. Keeping data in the hands of users opens those users up to unanticipated vectors of attack from adversaries striving to identify the valuable machine learning models or seeking to uncover data about a specific patient.
Drs. Hendricks-Sturrup and Jordan recommended that developers of patient reported outcome measurement systems leveraging federated learning architectures:
Intentionally design user device security, as well as security for transmission of either data (raw or processed) or model gradients, to the highest level of protections that do not degrade essential performance for critical health and safety monitoring procedures (e.g. remote monitoring for clinical trials, post-market drug safety surveillance, hospital performance scores, etc.);
Ensure that models are not compromised and that valuable machine learning spending is not lost to competitors;
Design systems to operate atop a federated machine learning architecture, both when model components are sent or gradients received, to ensure privacy of users’ data; and
Design learning algorithms with algorithmic privacy techniques, such as including differential privacy, which is essential to secure valuable and sensitive PRO data.
Drs. Hendricks-Sturrup’s and Jordan’s paper, poster, and presentation can be found at these links:
To learn more about FPF’s Health & Genetics and AI & Ethics initiatives, contact Drs. Hendricks-Sturrup and Jordan, respectively, at: [email protected] and [email protected].
Workshop Report: Privacy & Pandemics – Responsible Use of Data During Times of Crisis
In October 2020, the Future of Privacy Forum (FPF) convened a virtual workshop entitled “Privacy and Pandemics: Responsible Uses of Technology and Health Data During Times of Crisis” with invited computer science, privacy law, public policy, social science, and health information experts from around the world to examine benefits, risks, and strategies for the collection and use of data in support of public health initiatives in response to COVID-19 and for consideration of future public health crises. With support from the National Science Foundation, Intel Corporation, Duke Sanford School of Public Policy, and Dublin City University’s SFI ADAPT Research Centre, the workshop identified research priorities to improve data governance systems and structures in the context of the COVID-19 pandemic.
To learn more about FPF’s work related to privacy and pandemics, please visit the Privacy & Pandemics page.
Drawing on the expertise of workshop participant submissions and session discussions, FPF prepared a workshop report which was submitted to the National Science Foundation for use in planning the Convergence Accelerator 2021 Workshops. This NSF program aims to speed the transition of convergence research into practice to address grand challenges of national importance. The final submitted workshop report is also available on our website.
Based on analysis of expert positions reflected in the workshop, FPF recommends NSF consider the following roadmap for research, practice improvements, and development of privacy-preserving products and services to inform responses to the COVID-19 crisis and in preparation for future pandemics or other public crises:
Support the refinement and application of existing privacy-preserving and privacy- enhancing technologies that can support public health goals while mitigating privacy risks, including: decentralized contact tracing, homomorphic encryption, and differential privacy;
Support the development of emerging privacy-enhancing technologies that hold promise in the public health sphere, including: synthetic data, controlled access environments, digital twins, and simulations;
Support cross-disciplinary research into privacy-protective approaches to key emerging technologies, including: Wireless Sensor Networks and data processing strategies for on- device and/or centralized analysis of personal health information;
Explore mechanisms to balance the need for increased access to data that allows researchers to understand the differential impacts of crises on certain communities by not obscuring critical community characteristics with privacy-enhancing technologies;
Convene cross-disciplinary experts to create and refine guidance for implementation of privacy protections suited to crisis situations;
Identify top-priority updates to laws and regulations pertaining to public health;
Explore mechanisms that promote data interoperability while promoting privacy;
Promote the development of promising de-identification technologies and mitigation strategies to address re-identification risks;
Promote practical, implementable ethical frameworks that go beyond the FAIR principles; and
Identify practical lessons learned during the COVID-19 pandemic regarding publication ethics and norms for research in a time of crisis that can apply to future crises.
To learn more about the Privacy & Pandemics conference, including information about the topics, participants, sessions, presentations, and to read the final workshop report, head to the event page.