New FPF Study: More Than 250 European Companies are Participating in Key EU-US Data Transfer Mechanism
Co-Authored by: Drew Medway & Jeremy Greenberg
European Companies’ Participation in Privacy Shield Up Nearly 30% from the Past Year.
EU-US Privacy Shield Remains Essential to Leading European Companies.
From Major Employers such as Logitech and Siemens to Leading Technology Firms like Telefónicaand SAP, European Companies Depend on the EU-US Agreement.
The Privacy Shield Program Supports European Employment While Adding to Employee Data Protections—Nearly One-Third of Privacy Shield Companies Rely on the Framework to Transfer HR Information of European Staff.
With the future of the US/EU Privacy Shield framework awaiting the Court of Justice of the European Union’s (CJEU) Schrems II decision, the Future of Privacy Forum conducted a study of the companies enrolled in the cross-border privacy program and determined that 259 European headquartered companies are active Privacy Shield participants. This is a nearly 30% increase from last year’s total of 202 EU companies in the data transfer framework. These European firms rely on the program to transfer data to their US subsidiaries or to essential vendors that support their business needs. Nearly one-third of Privacy Shield companies use the mechanism to process human resources data—information that is crucial to employ, pay, and provide benefits to workers.
Thousands of major companies, many of which are headquartered or have offices in Europe, rely on the protections granted under the data transfer agreement. With a majority of companies surveyed in a recent IAPP study relying on Privacy Shield to transfer data out of the EU, and dozens of new companies joining each week to retain and pay their employees or create new job opportunities in Europe, the agreement is an integral data protection mechanism for European consumers and companies and the European marketplace as a whole.
The Numbers:
Overall, FPF found that more than 5,400 companies have signed up for Privacy Shield since the program’s inception – more than 1,000 participants joined in the last year.
Leading European companies that rely on Privacy Shield include:
– ALDI, German grocery market chain
– Eaton Corporation, Irish multinational management company
– Ingersoll-Rand, Irish globally diversified industrial company
– Jazz Pharmaceuticals, Irish biopharmaceutical company
– Lidl, German grocery market chain
– Logitech, Swiss computer peripherals manufacturer and software developer
– SAP, German multinational software corporation
– Siemens, German computer software company
– TE Connectivity, Swiss consumer electronics company
– Telefónica, Spanish mobile network provider
FPF research also determined that more than 1,700 companies, nearly one-third of the total number analyzed, joined Privacy Shield to transfer their human resources data.
The research identified 259 Privacy Shield companies headquartered or co-headquartered in Europe. Top EU locations for Privacy Shield companies include Germany, France, the Netherlands, and Ireland. This is a conservative estimate of companies that rely on the Privacy Shield framework—FPF staff did not include global companies that have major European offices but are headquartered elsewhere. The 259 companies include some of Europe’s largest and most innovative employers, doing business across a wide range of industries and countries. EU-headquartered firms and major EU offices of global firms depend on the Privacy Shield program so that their related US entities can effectively exchange data for research, to improve products, to pay employees and to serve customers.
The conclusions follow previous FPF studies, which highlighted similar increases in participation and reliance by EU firms on the Privacy Shield program over time.
Methodology:
FPF staff recorded a list of 5,348 active EU-US Privacy Shield companies as of June 2019 from https://www.privacyshield.gov.
FPF staff performed a web search for each current company by name, checking the location of the company’s headquarters on a combination of public databases such as LinkedIn, CrunchBase, Bloomberg, and companies’ own websites.
A company that listed its headquarters in an EU member state, the United Kingdom, or Switzerland was counted as a match; companies that merely had a prominent EU office or were founded in an EU member state were not counted.
259 total EU-headquartered companies were identified using this method.
Note Regarding Brexit: Given the 130-plus UK companies reliant on Privacy Shield, we encourage the continued enforcement of the framework with the UK after the conclusion of the UK-EU Transition Period on December 31st, 2020. Companies reliant on the transfer of data between the UK and US would be wise to review the Department of Commerce’s Privacy Shield and the UK FAQs for guidance on UK-US data transfer during, and after, the Transition Period.
Off to the Races for Enforcement of California’s Privacy Law
Yesterday, the California Attorney General’s office confirmed that it has begun sending a “swath” of enforcement notices to companies across sectors who are allegedly violating the California Consumer Privacy Act (CCPA), swiftly beginning enforcement right on the July 1st enforcement date. The law came into effect in January, after years of debate and amendment in the California Legislature. Additional proposed regulations, intended to clarify and operationalize the text of the statute, are not yet final.
In an IAPP-led webinar, “CCPA Enforcement: Enter the AG,” Stacey Schesser, California’s Supervising Deputy Attorney General, confirmed details about the first week of CCPA enforcement. Below, we provide 1) key takeaways from that conversation; 2) discuss the role of the draft regulations; and 3) observe that the successes or failures of AG enforcement will directly influence debates over other legislative efforts outside of California. Meanwhile, AG enforcement will almost certainly bolster public awareness and support for the California Privacy Rights Act (CPRA) or “CCPA 2.0” ballot initiative in November 2020.
Key takeaways and observations:
Alleged violations involve a “swath” of online businesses, likely based on “Do Not Sell” obligations.
Based on Deputy AG Schesser’s comments, we know that active enforcement of the CCPA began immediately on July 1st, with the office sending violation notice letters to a “swath” of online businesses. Under the law, companies have a thirty-day period to “cure” violations and come into compliance. As a result, these letters are unlikely to become public, unless any of them progress into full-blown investigations.
We do know a few key things from this discussion, however, about the type and substance of the alleged violations under scrutiny.
For example, we know that online businesses from “across sectors” were targeted, rather than, for example, retail or other “brick and mortar” establishments that collect data in-person. And although it was not directly stated, it was implied that the violations involve perceived failures to comply with the law’s “Do Not Sell” provisions. The AG has publicly held up this specific consumer right to request that a business not sell data as the most central feature of the CCPA. As a result, major online companies or publishers that do not provide a link entitled “Do Not Sell My Information” may be under particular scrutiny.
We don’t know at this point whether the AG staff identified obvious cases where observation made it clear a company was selling data. In many cases the issue of whether data that is transmitted to third parties is a sale depends on contracts and commitments made by those parties, details that can be challenging to discern based on external observation. Some companies may use the thirty-day cure period to attempt to persuade the AG’s office that their data sharing is occurring within the context of a service provider relationship or another permissible exemption that allows them to not provide a “Do Not Sell” button.
Deputy AG Schesser also confirmed that businesses were targeted based on consumer complaints and even some reports on Twitter. It would not be surprising to see that early enforcement targets were influenced by media and Twitter reports of businesses that do or do not provide a “Do Not Sell My Information” link. For example, a February 2020 Washington Post article includes a comprehensive list of top companies and notes whether they provide CCPA-related links.
Enforcement of requirements in the AG’s regulations will have to wait (for now).
For companies still interpreting and operationalizing the AG’s regulations, Deputy AG Schesser’s comments yesterday confirmed that enforcement (for now) is limited to the text of the statute. Although the CCPA has been in effect since January 1, 2020, the additional regulations promulgated by the AG’s office are not yet finalized, with the final text of the proposed regulations under review by the Office of Administrative Law.
Despite this, it would be wise for companies to carefully review the proposed regulations. Although in some cases the draft regulations appear to create new obligations or restrictions that do not exist in the text of the CCPA — such as disclosures for large data holders — in many cases the regulations are intended to clarify existing law. In such cases, the regulations provide a useful window into how the AG’s office understands the text of the CCPA. Similarly, companies seeking to understand how the AG’s office understands the CCPA and its “Do Not Sell” provision can look to the 900+ pages of responses given to commenters in the public comment periods for the draft regulations. These responses provide important insight into the AG’s analysis of what the underlying statute requires.
The AG’s successes or failures (or perceptions thereof) will directly influence federal and state legislative debates outside of California.
The role of State Attorneys General (AGs) in enforcing comprehensive privacy laws has been at the heart of many recent debates over both state and federal legislation. For example, in deliberations regarding the Washington Privacy Act (WPA), enforcement emerged as one of the most divisive issues that led to the bill failing to pass the Washington House. Advocates and even the Washington Office of the Attorney General itself argued that the Washington AG lacked the financial and other resources to meaningfully enforce the law if it were passed, and that the law needed to also include a private cause of action for individuals to bring claims directly in court.
In the context of federal legislation, it is becoming increasingly common for proposed comprehensive privacy legislation from both Democrats and Republicans to include enforcement powers for State AGs. Industry groups sometimes argue against the inclusion of State AGs, perceiving their enforcement to be politically motivated or observing that they may lack the deep expertise of their federal agency counterparts to enforce privacy laws affecting complex emerging technologies and digital platforms. However, State AGs will almost certainly play some role in a future federal privacy law, particularly if stronger government enforcement becomes part of a compromise against a robust private cause of action.
Despite these criticisms, we see this week that State AGs can act quickly and decisively. This is in line with the growing national importance of State AGs in enforcing against novel privacy harms associated with emerging technologies (for more, see Professor Danielle Citron’s 2017 exploration of The Privacy Policymaking of State Attorneys General). If the California AG’s enforcement letters and investigations over the next six months are perceived as effective, it will continue to bolster the credibility of AGs as primary enforcers of state laws, and supplementary enforcers of a federal law.
Next up: CPRA Ballot Initiative (“CCPA 2.0”)
Meanwhile, the proposed “California Privacy Rights Act” (CPRA) has qualified for the November 2020 ballot, and if passed would modify the CCPA to provide additional consumer protections. For example, it would add the consumer right to “correct inaccurate information,” and the right to limit first-party use of sensitive categories of information (rather than only being able to limit its sale). It would also provide much-needed clarifications on the consumer right to opt out of all sale or sharing of data for purposes of online behavioral advertising, and enshrine a clearer “purpose limitation” obligation into the text of the statute.
If passed, the CPRA will likely become the new de facto minimum U.S. national standard for consumer privacy, raising the bar significantly for efforts to pass federal legislation. Despite its detailed requirements, it is not finding favor with some civil society groups such as the Consumer Federation of California, which has now formally opposed the initiative. On the other hand, Common Sense Media has now endorsed the effort. The ballot initiative process in California enables groups to submit ballot arguments in support or opposition of an initiative, which may be important to help voters understand the initiative, so stay tuned for news of additional groups that support or oppose the effort.
Author: Stacey Gray is an FPF Senior Counsel and leads FPF’s U.S. federal and state legislative analysis and policymaker education efforts. Did we miss anything? Email us at [email protected].
Image Credit: Tweet from Attorney General Becerra, @AGBecerra, Twitter, July 1, 2020, https://twitter.com/AGBecerra/status/1278377943803154432?s=20.
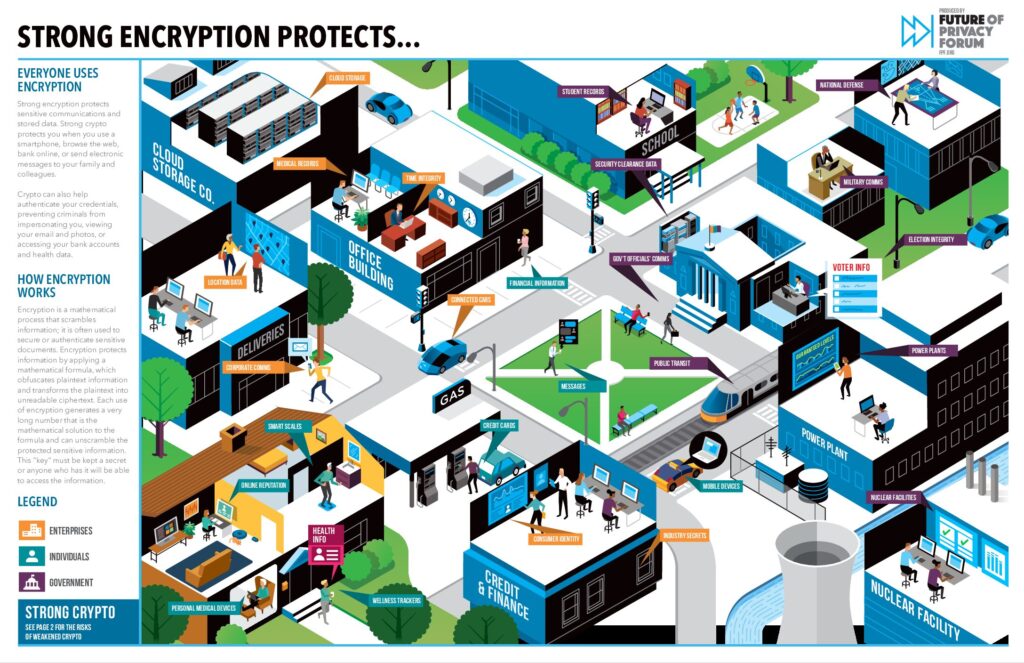
Strong Data Encryption Protects Everyone: FPF Infographic Details Encryption Benefits for Individuals, Enterprises, and Government Officials
Today, the Future of Privacy Forum released a new tool: the interactive visual guide “Strong Data Encryption Protects Everyone.” The infographic illustrates how strong encryption protects individuals, enterprises, and the government. FPF’s guide also highlights key risks that arise when encryption safeguards are undermined – risks that can expose sensitive health and financial records, undermine the security of critical infrastructure, and enable interception of officials’ confidential communications.
Encryption is a mathematical process that scrambles information; it is often used to secure or authenticate sensitive documents. Each use of encryption generates a very long number that is the mathematical solution to the formula and can unscramble the protected sensitive information. This “key” must be kept a secret or anyone who has it will be able to access the information.
Strong encryption employed by online services and connected devices protects sensitive communications and stored data. Strong encryption protects individuals when they use a smartphone, browse the web, bank online, or send electronic messages to family and colleagues. Encryption can also help authenticate credentials, preventing criminals from impersonating users, viewing confidential email and photos, emptying bank accounts, or taking control of power plants and vehicles.
Strong Data Encryption Protects Everyone demonstrates how encryption technologies protect data transmitted by smart medical devices, classroom records stored by teachers, and communications between soldiers. The infographic cites concrete examples of the ways individuals, schools, and military officers routinely use strong encryption to protect sensitive information.
FPF’s infographic highlights the protections provided by strong encryption as well as the risks presented by weakening encryption. Weakened encryption creates risks to health, safety, and privacy, and increases the possibility that criminals will infiltrate systems or intercept data. Encryption can be weakened by unintentional software flaws or by intentional decisions to provide some entities with exceptional access. There is no practical way to distinguish between public sector vs. private sector encryption; government officials typically use the same commercial software and hardware employed by corporations and individuals.
Dr. Rachele Hendricks-Sturrup Discusses Trends in Health Data
We’re talking to FPF senior policy experts about their work on important privacy issues. Today, Dr. Rachele Hendricks-Sturrup, Health Policy Counsel, is sharing her perspective on health data and privacy.
Dr. Hendricks-Sturrup has more than 12 years of experience in healthcare and biomedical research, health journalism, and engagement with digital health companies and startups. She has been a Research Fellow in the Department of Population Medicine at the Harvard Pilgrim Health Care Institute and Harvard Medical School and, as FPF’s health lead, continues to address ethical, legal, and social issues at the forefront of health policy and innovation, including genetic data, wearables, and machine learning with health data. She works with stakeholders to advance opportunities for data to be used for research and as real world evidence to improve patient care and outcomes and support evidence-based medicine.
What first attracted you to working on the privacy implications of health data?
My interest in health data began many years ago. When I finished my undergraduate degree in 2007, the world was turning on its head as far as understanding the utility and value of data. I realized that data is really running the show in academic, healthcare, business, and so many other landscapes. For this reason, I felt compelled to advocate for uses of data in ways that are purposeful, meaningful, and intentional to address specific problems in health care and health science research.
That being said, my appreciation for data and its potential, even if data might be considered a double-edged sword in some ways, has increased and I have studied how data can be used to support health care decision-making in meaningful ways.
You said that “data is running the show.” What does that mean?
Everyone in health care and policy today appreciates the value of evidence – evidence-based medicine, evidence-based policy, precision medicine, precision policy… you name it. Health data drives payment incentive structures in health services and approvals for new drugs and medical devices. Any kind of data point that you can use or leverage – be it quantitative or qualitative – to make an important decision or program is immensely valuable. With that being said, we still have a long way to go as far as figuring out how health data, especially when it’s combined with other data, should be collected and used to create actionable intelligence needed to robustly inform policy and organizational decision-making.
New types and uses of data in the health space mean that it’s really important to get the data right. If whatever you’re doing isn’t based on evidence or reliable data, then you’re likely to see a failed policy due to poor or absent evidence. Data is key to decision making in clinical care, legal settings, policy, and in research; if it’s not there or isn’t collected for intentional reasons or purposes, then how can you back up your claims?
What types and sources of data do you find yourself thinking about a lot these days?
I actually think a lot about behavioral data – mainly how that data is being combined with other types of personal data like geolocation data, genetic data, and consumer health data. Combined data is of strong interest to many, if not all, health companies and other business verticals engaged in health care. For this reason, I think it is important to be forethinking about immediate and downstream uses of such data to safeguard against possible population- or group-level discrimination, especially against populations sharing a certain health or immutable characteristic. Users and generators of that data should foremost consider how that data can be leveraged to improve health behavior in a non-coercive, fair, and transparent way. For example, I think that if I can help guide practitioners and researchers toward thinking more deeply and strategically about why and how they collect and use health data, then there is a greater chance that the data will not be used to stigmatize patients’ or health consumers’ behavior, but instead help those patients and consumers leverage resources within or new to their environments to become better stewards of their own health.
Another example is data collected to demonstrate patient medication adherence. If this sort of data is quantitative (or numbers-driven) and used or interpreted in potentially discriminatory ways to justify increased cost-sharing for a high-risk patient group, such as by stating, “these people are very non-adherent, so if we don’t see the clinical outcome that we’re looking for, then it’s their fault and they should pay instead of their insurer,” then I would argue that there are smarter ways to use that data.
One smart way to use that data is to combine it with qualitative data that can bring context as to why we see poor quantitative medication adherence data. Humans should step in to then ask – do these patients lack access to transportation and needed to refill their prescription? What can we do to eliminate that barrier for those patients? If a patient isn’t opening a smart pill bottle, is it because they forgot? What can we do to remind them or help them remind themselves? Those qualitative data points can supplement quantitative data to ensure all of the data are used to their highest potential to address or solve an actual (versus assumed) problem.
What have you been working on at FPF?
At FPF, I lead the health working group and engage with our working group and advisory board members on and to develop various projects that can inform FPF best practices. I’m currently engaging FPF’s health working group alongside our CEO, Jules Polonetsky, and Policy Fellow Katelyn Ringrose, to create draft guidance around best privacy practices for de-identified data that is shared by and with HIPAA-covered entities. The working group includes many stakeholders from academia and industry and thus attempts to garner consensus about best privacy practices across a wide range of stakeholders that present a range of use cases.
Currently, for FPF’s Privacy and Pandemics project, I help drive new and existing focuses on privacy concerns around the use of tech-driven surveillance measures, like digital contact tracing and thermal imaging, to help contain the spread of the virus and restart economies.
What do you see as the big, rising issues around uses of health data over the next few years?
It’s clear that data is critical to understanding and addressing many health challenges, including the pandemic, but certain uses of data also create a wide range of risks. We will be providing guidance around digital contact tracing and a wide range of additional technologies that are being used or proposed. Some may not be effective, some may create major risks, and others may be useful, if deployed in a proportionate and measured manner with appropriate safeguards.
I also think questions about how we collect or do not collect data to address health disparities exacerbated or exposed by COVID-19 will continue to resonate. The public has become much more exposed to toll of health disparities within the United States and across the world, especially for certain minority or low-income populations, following COVID-19. The biggest challenge to all of this will be how we collect and leverage data to actually address these disparities and help control or prevent them in the future.
Similarly, with regard to issues around social justice, racism, and police brutality that have drawn the attention of prominent health care organizations like the American Medical Association, I see the need to determine how intentional data collection, use, and interpretation fit within that equation to address these issues. Also, and broadly, how can we or are we using data to resolve conflicts or concerns in health care, genetics, and other areas? I foresee this as our greatest challenge – if we’re able to meet it, then we can say that we’ve made a quantum leap.
iOS Privacy Advances
Law and legislation take the lead in setting standards for protecting personal data, but the policies and norms established by companies also play a central role. This has been the case particularly for global platforms providing the services used by billions in the course of daily life. Apple’s 2020 Worldwide Developer Conference (WWDC) previewed a variety of privacy advances coming soon to various Apple products, including their most recent mobile operating system, iOS 14. Apple executives reiterated throughout the event that, “privacy is a fundamental human right at the core of everything we do” and a notable portion of their announcements directly reflect this perspective.
An overview of some of the notable changes include:
App Tracking Controls
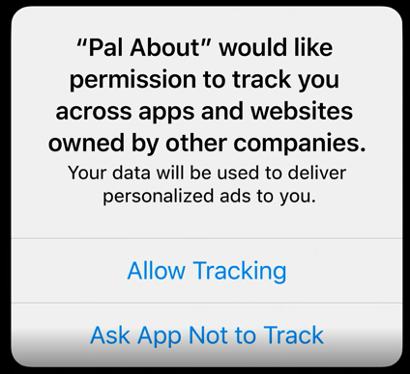
As of iOS 14, Apple will require developers to obtain consent prior to tracking users across apps and websites owned by other companies, including tracking by user ID, IDFA, device ID, fingerprinting, or profiles. Apps are currently only permitted to track users for advertising purposes by using the iOS IDFA (Identifier for Advertisers) — an ID that is available by default and can be “zeroed out” by enabling the Limit Ad Tracking setting. In iOS 14, apps will need to affirmatively request access to the IDFA via the AppTrackingTransparency framework.
This new “just-in-time notification will provide users with two options: “Allow tracking” or “Ask app not to track.”
It is our understanding that apps can ask for this permission only once and cannot discriminate against users by restricting use of the app or key features for those who decline the permission.
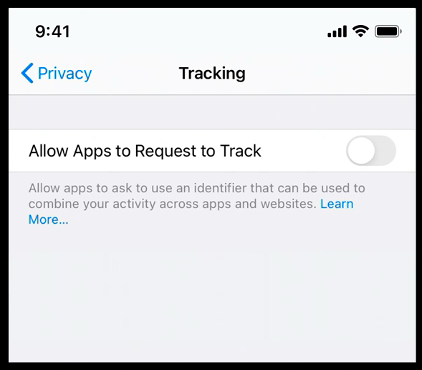
The new functionality will also allow users to view and edit this setting for each app on the device within Settings. Users can also choose not to be asked for permission to track by all apps through the Limit Ad Tracking toggle within Settings. This setting is automatically disabled for child accounts and on shared iPads.
Apps will still be permitted to track users who do not “Allow Tracking” in circumstances where the app’s data is linked to third-party data solely on the user’s device and is not sent off of the device in a way that can identify the user or device. App data may also be sent to a third-party if that third-party partner uses the data solely for fraud detection, fraud prevention, or security purposes and solely on behalf of the app developer (for example, to prevent credit card fraud).
Attributing App Installations
Apps will be able to leverage Apple’s SKAdNetwork to attribute app installations via aggregate conversion reporting. Ad networks will need to register and provide campaign IDs to the App Store, and Apple will report the aggregate results of campaigns driving installations without sharing information about individual users.
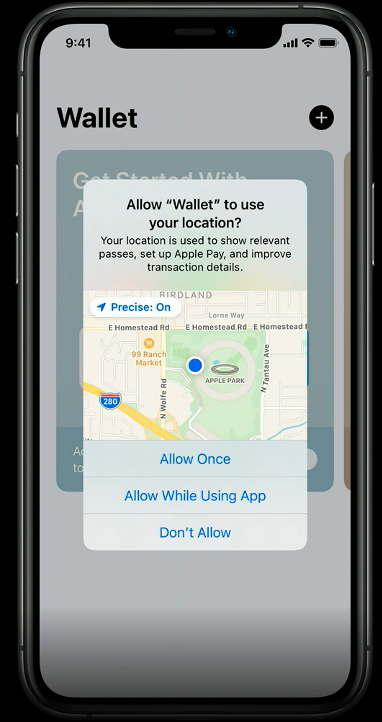
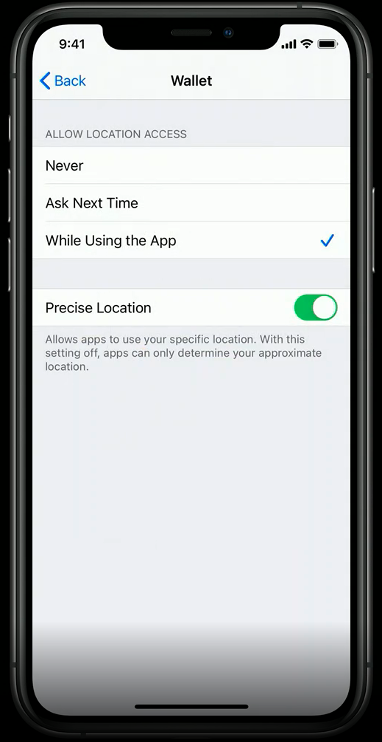
Location Updates
Currently, users are presented with several options when an app requests access to location. These options include 1) Allow While Using App, 2) Allow Once, and 3) Don’t Allow.
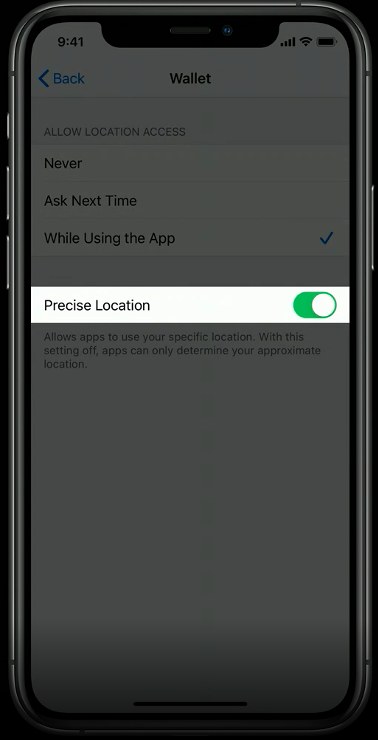
A new, more privacy-preserving option will offer users the ability to share an approximate location that reflects an area of approximately 10 square miles, allowing for a personalized experience without sharing precise location information.
To help users understand the difference and the precision of location sharing, iOS will now provide a visual representation as part of the location permission dialogue. The option to share precise location with individual apps can also be managed with the device Settings.
Apps are already required to provide a link to a privacy policy under current App Store requirements. With iOS 14, apps will need to provide specific information available for users to review prior to installation in a standardized format, similar to a nutrition label, within the App Store interface. Developers will be required to complete a questionnaire detailing what data the app collects, how the data is used, if the data is linked to a particular user or device, and if the data will be used to track users. Because SDK’s run in-process with other app code, and share the app’s access permissions, developer responses are required to reflect both the practices of the app as well as any 3rd party code within the app.
Since these declarations are effectively additional privacy disclosures provided by an app, companies will need to take care to ensure they are accurate legal representations of their practices.
.
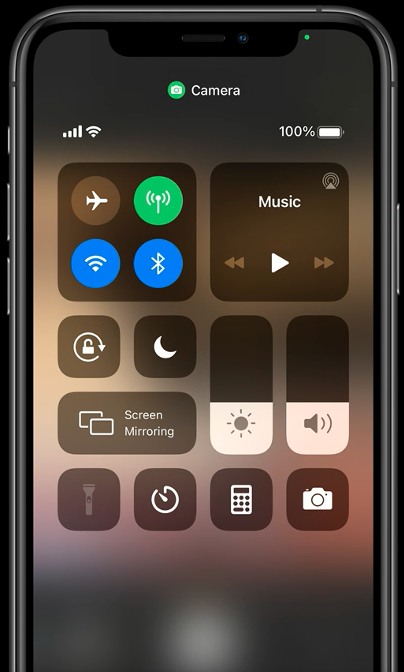
Microphone & Camera Indicators
Indicators will appear on the status bar and within the Control Center when the camera or microphone is activated by an app.
Sign-In With Apple Upgrades
Developers will now be able to offer users the option to convert existing app accounts to Sign-in with Apple, which is tied to users’ Apple IDs.
Safari Enhancements
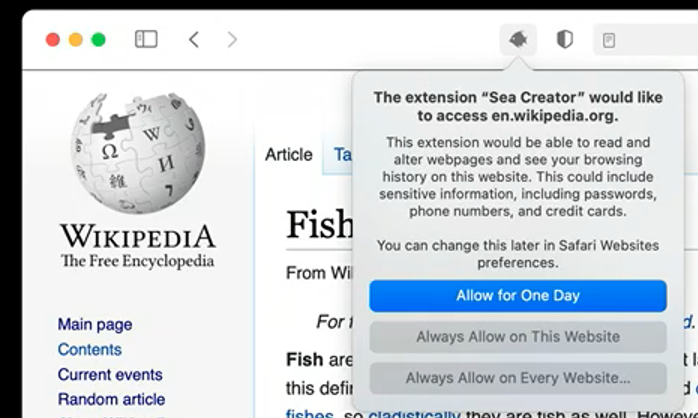
As of iOS 14, Safari will support a broader selection of extensions distributed through the App Store. Just-in-time notices within Safari will notify users when an extension accesses information about a site the user is visiting, and users can opt to “Allow for one day,” Always allow on this website,” or “Always allow on every website.”
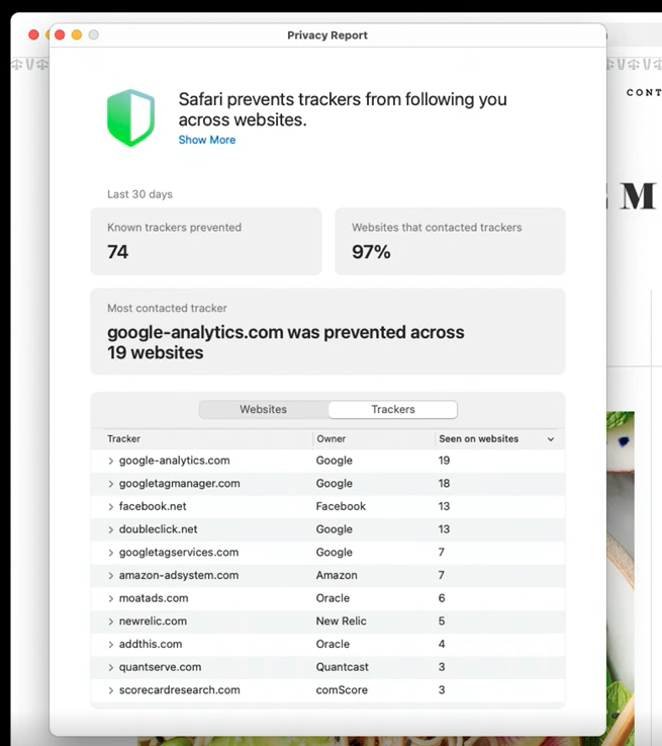
While ITP (Intelligent Tracking Protection) has been implemented in Safari for several years, new transparency enhancements will allow users to review a list of specific trackers blocked on a website through an icon in the toolbar.
In addition, a new “Privacy Report” will provide users with a summary of all cross-site trackers that have been blocked within the previous 30 days.
Photo and Contacts Library Access
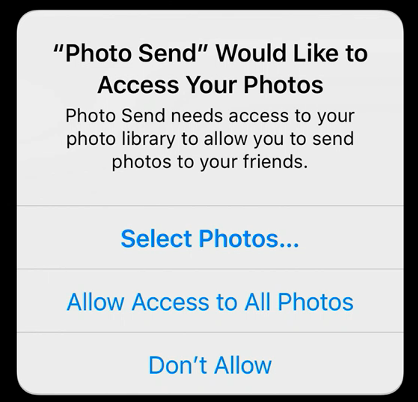
New access limits to the Photo Library will enable users to share only specific, selected items with an app, as opposed to the previous default of providing ongoing access to the user’s entire library. Similar technical controls will also be applied to apps interacting with a user’s contacts, allowing users to select individual contacts instead of providing apps with ongoing, blanket access to all of the user’s Contacts.
Network Access
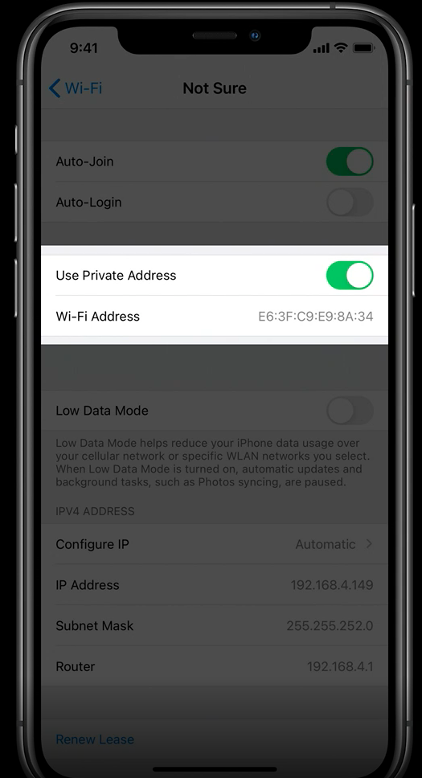
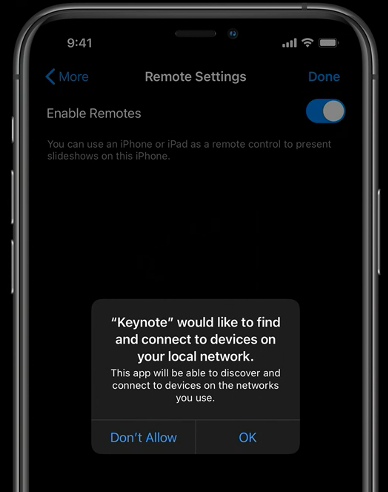
While some apps need to be able to find and connect to local devices on a network in order to provide specific, related services, some apps have used access to this information to track users for other purposes. Apps will now be required to prompt users and obtain permission for such access. In addition “Use Private Address” will be enabled by default. This will result in Apple devices providing WiFi networks with a MAC address that is uniquely-generated daily, preventing multiple WiFi networks from correlating the behaviors of an individual user presenting with the same MAC address.
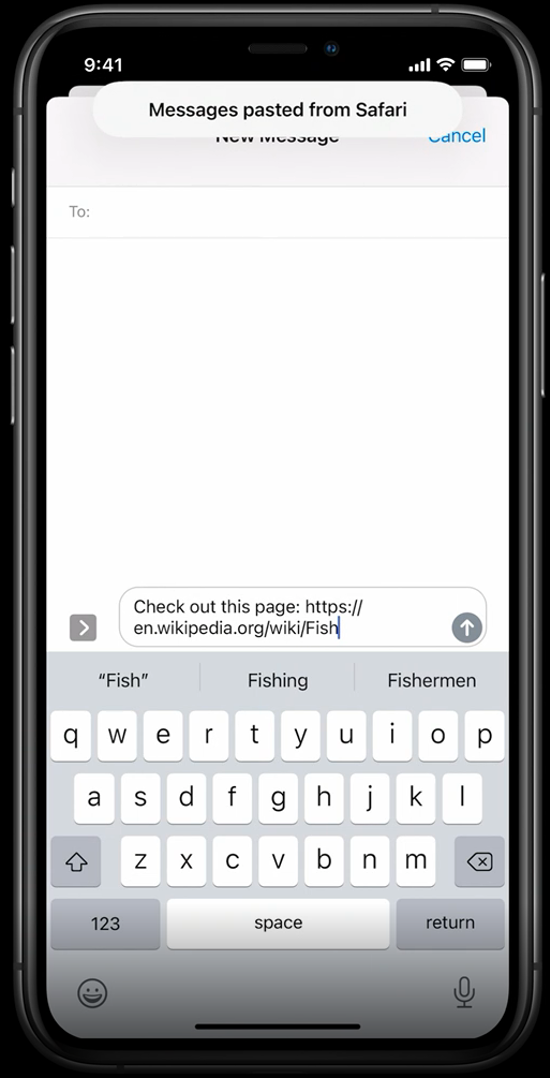
Clipboard Data
If text that has been copied to the clipboard is accessed by an app, iOS 14 will provide a notification to the user in a “Call Out” for each instance the app accesses the information, allowing users to know when and which apps are accessing the text stored on the clipboard. Previously, apps were able to access this information on demand and without any indication to users. Researchers recently flagged TikTok and other apps accessing clipboard data in this manner. Although some apps may have legitimate reasons to access clipboard data, the access by many others raises concerns.
Apple provided more detail about the changes and potential impact on existing and new apps in these videos and forums. The following two videos, in particular, provide more information regarding a number of changes which serve to encourage data minimization, reduce the likelihood of apps over-sharing data, and increase user transparency and control.
FPF Webinar Explores the Future of Privacy-Preserving Machine Learning
On June 8, FPF hosted a webinar, Privacy Preserving Machine Learning: New Research on Data and Model Privacy. Co-hosted by the FPF Artificial Intelligence Working Group and the Applied Privacy Research Coordination Network, an NSF project run by FPF, the webinar explored how machine learning models as well as data fed into machine learning models can be secured through tools and techniques to manage the flow of data and models in the ML ecosystem. Academic researchers from the US, EU, and Singapore presented their work to attendees from around the globe.
The papers presented, summarized in the associated Privacy Scholarship Reporter, represent key strategies in the evolution of private and secure machine learning research. Starting with her co-authored piece, Ms. Patricia Thaine of the University of Toronto outlined how combining privacy enhancing techniques (PETs) can lead to better, perhaps almost perfect, preservation of privacy for the personal data used in ML applications. The combination of techniques, including deidentification, homomorphic encryption, and others, draws on foundational and novel work in private machine learning, such as the use of collaborative or federated learning, pioneered by the next presenter, Professor Reza Shokri of the National University of Singapore.
Professor Shokri discussed data privacy issues in machine learning with a specific focus on “indirect and unintentional” risks such as may arise from metadata, data dependencies, and computations of data. He highlighted that reported statistics and models may provide sufficient information to allow an adversary to make use of the “inference avalanche” to link non-private information back to personal data. He elaborated on the point that models themselves may be personal data which need to be protected under data protection frameworks, such as the GDPR. To address these privacy risks from machine learning, Professor Shokri and his colleagues have developed the ML PrivacyMeter, which is an opensource tool available on GitHub. “ML Privacy Meter.. provides privacy risk scores which help in identifying data records among the training data that are under high risk of being leaked through the model parameters or predictions.”
Next, the foundational work on federated learning was applied to the domain of healthcare narrative data by Mr. Sven Festag, a speaker from Jena University Hospital who explored how collaborative privacy-preserving training of models that de-identify clinical narratives improves on the privacy protections available from de-identification run at a strictly local level. One of the reasons for the approach taken by Mr. Festag was the potential for malicious actors seeking detailed knowledge of models or data, a threat further assessed by the following speaker, Dr. Ahmed Salem from Universitaat Saarland.
Dr. Salem and his co-authors explored how machine learning models can be attacked and prompted to give incorrect answers through both static and dynamic triggers. Triggers, such as replacement of pixels in an image, can be designed to prompt machines to learn something or recommend something different from the data that does not include such triggers. When attack triggers are made dynamic, such as through use of algorithms trained to identify areas of vulnerability, the likelihood of a successful attack markedly increases.
Given the possibility that attacks against models could cause adverse outcomes, it seems likely to expect consensus that machine learning models need to be well protected. However, as Dr. Sun and his Northeastern University co-authors found, many mobile app developers do not, in fact, design or include sufficient security for their models. Failure to appropriately secure models can cost companies considerably, from reputational harm to financial losses.
Following all the presentations, the speakers joined FPF for a joint panel discussion about the general outlook for privacy preserving machine learning. They concur that the future of privacy in machine learning will necessarily include both data protections and model protections and will need to go beyond a simple compliance-focused effort. As a last question, speakers were asked their views on the most salient articles for privacy professionals to read on this topic. Those papers are listed below.
Information about the webinar, including slides from the presentation, some of the papers and GitHub links for our speakers, and a new edition of the Privacy Scholarship Reporter, can be found below.
Privacy Scholarship Research Reporter: Issue 5, July 2020 – Preserving Privacy in Machine Learning: New Research on Data and Model Privacy
Notes from FPF
In this edition of the “Privacy Scholarship Reporter”, we build on the general knowledge from the first two and then explore some of the technical research being conducted to achieve ethical and privacy goals.
“Is it possible to preserve privacy in the age of AI?”, is a provocative question asked by academic researchers and company based researchers. The answer depends on a mixture of responses that secure privacy for training data and input data, and preserve privacy and reduce the possibility of social harms which arise from interpretation of model output. Likewise, preservation of data privacy requires securing AI assets to ensure model privacy (Thain and Penn 2020, Figure 1). As machine learning and privacy researchers’ work demonstrates, there are myriad ways to preserve privacy and choosing the best methods may vary according to the purpose of the algorithm or the form of machine learning built.
Within the growing body of research addressing privacy considerations in artificial intelligence and machine learning, there are two approaches emerging — a data centered approach and a model centered approach. One group of methods to secure privacy through attention to data is “differential privacy”. Differential privacy is a type of mathematical perturbation introduced into a data set to ensure that a specific individuals’ inclusion in that data cannot be detected when summary statistics generated from either a true or differentiated data set are compared to one another. Some of the other methods for increasing the privacy protections for data prior to use in ML models include: homomorphic encryption, secure multi-party computation, and federated learning. Homomorphic encryption preserves data privacy through analysis of encrypted data. Secure multi-party computation is a protocol for collaboration between parties holding information they prefer to keep private from one another without intervention of a trusted third party actor. Federated learning allows data to be stored and analyzed locally through models or segments of models sent to the user’s device.
Data centered methods to preserve privacy introduce some possibility that models may be compromised, allowing for an attack on user’s data and on a company’s models. Conversely, research to design model centered methods to preserve privacy presently focus on ways to secure models from attack. There are two general forms of attack against models that could reduce privacy for the developers of the models or for those whose data is used by the attacked model.. “Black box” attacks against machine learning draw private information from machine learning models through malicious gains of functional access to a model without knowing its internal details, while “white-box” attacks gain access to information about an individuals contribution through use of ill-gained knowledge of details about the model itself. Both represent risks to individual data privacy that arise from challenges to a company’s model privacy. The costs from loss of privacy through machine learning may redound to individuals from privacy breaches or to companies from the associated cost from loss of proprietary assets and reputation, and can range into the millions of dollars. Working to reduce those losses is an important component of present privacy and machine learning research, such as is represented in the papers below.
As always, we would love to hear your feedback on this issue. You can email us at [email protected].
Sara Jordan, Policy Counsel, FPF
Preserving Privacy in Artificial Intelligence and Machine Learning: Theory and Practice
Perfectly Privacy-Preserving AI: What is it and how do we achieve it?
P. THAINE
Perfect preservation of privacy in artificial intelligence applications will entail significant efforts across the full lifecycle of AI product development, deployment, and decommissioning, focusing on the privacy protections implemented by both data creators and model creators. Preservation of privacy would entail focusing on:
1. Training Data Privacy: The guarantee that a malicious actor will not be able to reverse-engineer the training data.
Input Privacy: The guarantee that a user’s input data cannot be observed by other parties, including the model creator.
Output Privacy: The guarantee that the output of a model is not visible by anyone except for the user whose data is being inferred upon.
Model Privacy: The guarantee that the model cannot be stolen by a malicious party”.
A combination of the tools available may represent the best, albeit still theoretical, paths toward perfectly privacy-preserving AI.
Authors’ Abstract
Many AI applications need to process huge amounts of sensitive information for model training, evaluation, and real-world integration. These tasks include facial recognition, speaker recognition, text processing, and genomic data analysis. Unfortunately, one of the following two scenarios occur when training models to perform the aforementioned tasks: either models end up being trained on sensitive user information, making them vulnerable to malicious actors, or their evaluations are not representative of their abilities since the scope of the test set is limited. In some cases, the models never get created in the first place. There are a number of approaches that can be integrated into AI algorithms in order to maintain various levels of privacy. Namely, differential privacy, secure multi-party computation, homomorphic encryption, federated learning, secure enclaves, and automatic data de-identification. We will briefly explain each of these methods and describe the scenarios in which they would be most appropriate. Recently, several of these methods have been applied to machine learning models. We will cover some of the most interesting examples of privacy-preserving ML, including the integration of differential privacy with neural networks to avoid unwanted inferences from being made of a network’s training data. Finally, we will discuss how the privacy-preserving machine learning approaches that have been proposed so far would need to be combined in order to achieve perfectly privacy-preserving machine learning.
Privacy preservation in machine learning depends on the privacy of the training and input data, privacy of the model itself, and privacy of the models’ outputs. Researchers have demonstrated an ability to improve privacy preservation in these areas for many forms of machine learning, but doing so for neural network training over sensitive data presents persistent problems. In this (now) classic article, the authors describe “collaborative neural network training” which “protects privacy of the training data, enabled participants to control the learning objective and how much to reveal about their individual models, and lets them apply the jointly learned model to their own inputs without revealing the inputs or the outputs”. A collaborative architecture protects privacy by ensuring data is not revealed to third party, like an MLaaS provider, passive adversary, or malicious attacker, and by ensuring that data owners have control over their data assets. This is particularly useful in areas where data owners cannot directly share their data with third parties due to privacy or confidentiality concerns (e.g., healthcare).
Authors’ Abstract
Deep learning based on artificial neural networks is a very popular approach to modeling, classifying, and recognizing complex data such as images, speech, and text. The unprecedented accuracy of deep learning methods has turned them into the foundation of new AI-based services on the Internet. Commercial companies that collect user data on a large scale have been the main beneficiaries of this trend since the success of deep learning techniques is directly proportional to the amount of data available for training. Massive data collection required for deep learning presents obvious privacy issues. Users’ personal, highly sensitive data such as photos and voice recordings is kept indefinitely by the companies that collect it. Users can neither delete it, nor restrict the purposes for which it is used. Furthermore, centrally kept data is subject to legal subpoenas and extra-judicial surveillance. Many data owners—for example, medical institutions that may want to apply deep learning methods to clinical records—are prevented by privacy and confidentiality concerns from sharing the data and thus benefiting from large-scale deep learning. In this paper, we design, implement, and evaluate a practical system that enables multiple parties to jointly learn an accurate neural network model for a given objective without sharing their input datasets. We exploit the fact that the optimization algorithms used in modern deep learning, namely, those based on stochastic gradient descent, can be parallelized and executed asynchronously. Our system lets participants train independently on their own datasets and selectively share small subsets of their models’ key parameters during training. This offers an attractive point in the utility/privacy tradeoff space: participants preserve the privacy of their respective data while still benefiting from other participants’ models and thus boosting their learning accuracy beyond what is achievable solely on their own inputs. We demonstrate the accuracy of our privacy preserving deep learning on benchmark datasets.
Chiron: Privacy-preserving Machine Learning as a Service
T. HUNT, C. SONG, R. SHOKRI, V. SHMATIKOV, E. WITCHELL
Machine learning is a complex process that is difficult for all companies who might benefit to replicate well. To fill the need that groups have for machine learning, some machine learning companies now provide machine learning development and testing as a service, similar to analytics as a service. Machine learning as a service (MLaaS) is democratizing access to the powerful analytic insights of machine learning techniques. Increasing access to machine learning techniques corresponds to an increase in the risk that companies’ models, part of their intellectual property and corporate private goods, might be leaked to users of MLaaS. Uses of MLaaS also increase the risk to the privacy of individuals whose data is introduced into ML models; service platforms could be compromised by internal or external attacks. This paper proposes a model that builds on Software Guard Extensions (SGX) enclaves, which limit untrusted platform’s access to code or data, and Ryoan (distributed sandboxes that separate programs from one another to prevent unintentional transfer or contamination). Ryoan sandboxes confine code, allows it to define and train a model, while ensuring that the model does not leak data to untrusted parties, to build a MLaaS platform which protects both those providing ML services and those seeking services and supplying data.
Authors’ Abstract
Major cloud operators offer machine learning (ML) as a service, enabling customers who have the data but not ML expertise or infrastructure to train predictive models on this data. Existing ML-as-a-service platforms require users to reveal all training data to the service operator. We design, implement, and evaluate Chiron, a system for privacy-preserving machine learning as a service. First, Chiron conceals the training data from the service operator. Second, in keeping with how many existing ML-as-a-service platforms work, Chiron reveals neither the training algorithm nor the model structure to the user, providing only black-box access to the trained model. Chiron is implemented using SGX enclaves, but SGX alone does not achieve the dual goals of data privacy and model confidentiality. Chiron runs the standard ML training toolchain (including the popular Theano framework and C compiler) in an enclave, but the untrusted model-creation code from the service operator is further confined in a Ryoan sandbox to prevent it from leaking the training data outside the enclave. To support distributed training, Chiron executes multiple concurrent enclaves that exchange model parameters via a parameter server. We evaluate Chiron on popular deep learning models, focusing on benchmark image classification tasks such as CIFAR and ImageNet, and show that its training performance and accuracy of the resulting models are practical for common uses of ML-as-a-service.
Privacy Preserving Machine Learning: Applications to Health Care Information
Privacy-Preserving Deep Learning for the Detection of Protected Health Information in Real-World Data: Comparative Evaluation
S. FESTAG, C. SPRECKELSEN
A common concern about privacy in machine learning systems is that the massive amounts of data involved represent a quantitatively definable risk that is over and above the risk to privacy when smaller datasets are used. However, as researchers using small datasets of sensitive information attest, the risk may not lie in how much data is used but in how small or disparate pieces of data are aggregated for use. Researchers studying collaborative learning models propose methods for securing data against leakage when it is gathered from multiple sources. Forms of collaborative learning proposed as methods to improve integration of sensitive private information in neural network settings include “round robin techniques” and “privacy-preserving distributed selective stochastic gradient descent (DSSGD)”. DSSGD is a method for protecting private information through both use of local (on-device/ at site) training and individual restriction on the level of information shared back to a central model server.
Authors’ Abstract
Background: Collaborative privacy-preserving training methods allow for the integration of locally stored private data sets into machine learning approaches while ensuring confidentiality and nondisclosure. Objective: In this work we assess the performance of a state-of-the-art neural network approach for the detection of protected health information in texts trained in a collaborative privacy-preserving way. Methods: The training adopts distributed selective stochastic gradient descent (ie, it works by exchanging local learning results achieved on private data sets). Five networks were trained on separated real-world clinical data sets by using the privacy-protecting protocol. In total, the data sets contain 1304 real longitudinal patient records for 296 patients. Results: These networks reached a mean F1 value of 0.955. The gold standard centralized training that is based on the union of all sets and does not take data security into consideration reaches a final value of 0.962. Conclusions: Using real-world clinical data, our study shows that detection of protected health information can be secured by collaborative privacy-preserving training. In general, the approach shows the feasibility of deep learning on distributed and confidential clinical data while ensuring data protection.
An Improved Method for Sharing Medical Images for Privacy Preserving Machine Learning using Multiparty Computation and Steganography
R. VIGNESH, R. VISHNU, S.M. RAJ, M.B. AKSHAY, D.G. NAIR, J.R. NAIR
Preserving the security of data that cannot be easily shared due to privacy and confidentiality concerns presents opportunities for creativity in transfer mechanisms. Sharing digital images, which due to their rich and pixelated nature cannot be easily encrypted and decrypted without loss, represents a particularly unique challenge and opportunity for creativity. One way in which images can be shared more securely is by using secret sharing protocols, which require a combination of small pieces of secret information until a threshold of secret bits is compiled at which point a secret, such as a unique user key, is revealed and the full information rendered. Rich image data can also be used to transfer low dimensionality text data as an embedded component of the image. Steganography or insertion of small secret bits of data into an image without changing the perception of the image is one way to transfer information for use in secret sharing protocols. Uses of steganography can allow multiple machine learning uses of a single image in a privacy preserving way.
Authors’ Abstract
Digital data privacy is one of the main concerns in today’s world. When everything is digitized, there is a threat of private data being misused. Privacy-preserving machine learning is becoming a top research area. For machines to learn, massive data is needed and when it comes to sensitive data, privacy issues arise. With this paper, we combine secure multiparty computation and steganography helping machine learning researchers to make use of a huge volume of medical images with hospitals without compromising patients’ privacy. This also has application in digital image authentication. Steganography is one way of securing digital image data by secretly embedding the data in the image without creating visually perceptible changes. Secret sharing schemes have gained popularity in the last few years and research has been done on numerous aspects.
Dynamic Backdoor Attacks Against Machine Learning Models
A. SALEM, R. WEN, M. BACKES, S. MA, Y. ZHANG
Machine learning systems are vulnerable to attack from conventional methods, such as model theft, but also from backdoor attacks where malicious functions are introduced into the models themselves which then express undesirable behavior when appropriately triggered. Some model backdoors use “static” triggers which could be detected by defense techniques, but the authors of this paper propose three forms of dynamic backdoor attacks. Dynamic backdoor attacks raise specific privacy concerns as these attacks allow adversaries access to both centralized and decentralized systems. Once given access, the backdoor attack with a dynamic trigger will cause a model to misclassify any input. As a consequence, users may inadvertently adversely train machine learning models they rely upon. Likewise, backdoor attacked machine learning algorithms in users’ systems or devices may report users’ information without application of differential privacy techniques, thus compromising user privacy and personal information.
Authors’ Abstract
Machine learning (ML) has made tremendous progress during the past decade and is being adopted in various critical real-world applications. However, recent research has shown that ML models are vulnerable to multiple security and privacy attacks. In particular, backdoor attacks against ML models that have recently raised a lot of awareness. A successful backdoor attack can cause severe consequences, such as allowing an adversary to bypass critical authentication systems. Current backdooring techniques rely on adding static triggers (with fixed patterns and locations) on ML model inputs. In this paper, we propose the first class of dynamic backdooring techniques: Random Backdoor, Backdoor Generating Network (BaN), and conditional Backdoor Generating Network (c-BaN). Triggers generated by our techniques can have random patterns and locations, which reduce the efficacy of the current backdoor detection mechanisms. In particular, BaN and c-BaN are the first two schemes that algorithmically generate triggers, which rely on a novel generative network. Moreover, c-BaN is the first conditional backdooring technique, that given a target label, it can generate a target-specific trigger. Both BaN and c-BaN are essentially a general framework which renders the adversary the flexibility for further customizing backdoor attacks. We extensively evaluate our techniques on three benchmark datasets: MNIST, CelebA, and CIFAR-10. Our techniques achieve almost perfect attack performance on backdoored data with a negligible utility loss. We further show that our techniques can bypass current state-of-the-art defense mechanisms against backdoor attacks, including Neural Cleanse, ABS, and STRIP.
Mind Your Weights: A Large-Scale Study on Insufficient Machine Learning Model Protection in Mobile Apps
Z. SUN, R. SUN, L. LU
To protect privacy when using machine learning, many researchers or developers focus on securing the data of individuals whose interaction with the internet of things, mobile phones, and other data gathering devices powers much of machine learning. But, truly securing privacy in machine learning systems also means securing the models themselves. Securing models protects the privacy and security of the companies’ machine learning assets and protects users who could be subject to a higher risk for exposure due to inversion attacks by those who maliciously or surreptitiously gain access to models. This paper studies the methods that companies do and do not use when protecting machine learning in mobile apps. Importantly, these researchers also quantify the risk if models are stolen, finding that the cost of a stolen model can run into the millions of dollars.
Authors’ Abstract
On-device machine learning (ML) is quickly gaining popularity among mobile apps. It allows offline model inference while preserving user privacy. However, ML models, considered as core intellectual properties of model owners, are now stored on billions of untrusted devices and subject to potential thefts. Leaked models can cause both severe financial loss and security consequences. This paper presents the first empirical study of ML model protection on mobile devices. Our study aims to answer three open questions with quantitative evidence: How widely is model protection used in apps? How robust are existing model protection techniques? How much can (stolen) models cost? To that end, we built a simple app analysis pipeline and analyzed 46,753 popular apps collected from the US and Chinese app markets. We identified 1,468MLapps spanning all popular app categories. We found that, alarmingly, 41% of ML apps do not protect their models at all, which can be trivially stolen from app packages. Even for those apps that use model protection or encryption, we were able to extract the models from 66% of them via unsophisticated dynamic analysis techniques. The extracted models are mostly commercial products and used for face recognition, liveness detection, ID/bank card recognition, and malware detection. We quantitatively estimated the potential financial impact of a leaked model, which can amount to millions of dollars for different stakeholders. Our study reveals that on-device models are currently at high risk of being leaked; attackers are highly motivated to steal such models. Drawn from our large-scale study, we report our insights into this emerging security problem and discuss the technical challenges, hoping to inspire future research on robust and practical model protection for mobile devices.
Privacy and security in a machine learning enabled world involves protecting both data and models. As the papers reviewed here show, this will require new ways of thinking about analysis of privacy in development and deployment of machine learning models. Whether in research on healthcare applications or mobile apps, researchers are pointing to these new ways of thinking and new techniques to improve privacy in machine learning.
California Privacy Legislation: A Timeline of Key Events
Authors: Katelyn Ringrose (Christopher Wolf Diversity Law Fellow) and Jeremy Greenberg (Policy Counsel)
——-
Today, the California Attorney General will begin enforcing the California Consumer Privacy Act (CCPA). The California AG’s office may bring enforcement actions and seek penalties for violations of core provisions of the CCPA. The AG’s request for expedited review of regulations that supplement the CCPA is pending before the California Office of Administrative Law (OAL); the AG regulations provide additional detail regarding particular CCPA provisions.
The CCPA, which came into effect January 2020, is the first non-sectoral privacy law passed in the United States that contains broad consumer rights to access, delete, and opt out of the sale of their data. The CCPA has sparked major compliance efforts in the United States and globally, and the legislation was a long time in the making—beginning as a 2016 ballot initiative.
In commemoration of today’s landmark enforcement date, we look back at the events that brought us to this point, and potential future ramifications. Below is a timeline of events regarding California privacy legislation from 2016 – 2020. This timeline examines the inception of the CCPA, the various amendments and lawsuits that have shaped its scope and enforcement provisions, and the current status of the California Privacy Rights Act (CPRA), or “CCPA 2.0,” recently certified for the 2020 ballot. If passed, CPRA would become effective in 2023.
April 14, 2016 – After four years of drafting and negotiations, the General Data Protection Regulation (GDPR) isadoptedby the European Union.
October 12, 2017 – Alastair Mactaggart, Rick Arney, and Mary Stone Ross file a ballot initiative containing the preliminary language of the California Consumer Privacy Act (CCPA). Reportedly, Mactaggart’s interest in privacy was inspired by a conversation with an ex-Google engineer at a cocktail party. In California, once the requisite number of signatures are qualified by the Secretary of State, the initiative is approved to appear on an upcoming ballot, where pursuant to a majority vote, the initiative will become state law.
December 18, 2017 – California Secretary of State Alex Padilla announces that the ballot initiative proponents, now called Californians for Consumer Privacy, are cleared to begin collecting petition signatures—the group has 180 days to collect the signatures of 365,880 registered California voters.
January 3, 2018 – The 2018 California Legislative Session begins.
February 13, 2018 – Assemblymember Ed Chau introduces S.B. 1121 to the California Senate Committee on Rules, a bill containing much of the same language as the ballot initiative.
May 25, 2018 – The GDPR goes into effect. On the same day, the California Senate Committee on Appropriations passes S.B. 1121, as amended, with a vote of 5-2.
May 30, 2018 – The California Senate approves S.B. 1121 with a floor vote of 22-13, and the bill is referred to the California Assembly.
June 21, 2018 – Californians for Consumer Privacy reportedly reach a deal to withdraw the proposed ballot initiative if S.B. 1121 is passed and signed by the Governor. If the ballot initiative is not withdrawn by June 28, 2018, it will be placed on the 2018 ballot. If voted into law directly by voters through a ballot initiative, the law will be much harder to amend than if those same provisions are passed by the California Legislature.
June 25, 2018 – Secretary of State Alex Padilla confirms that his office received more than the required signatures, and will certify the initiative as qualified for the November 6, 2018 General Election ballot, unless the proponents withdraw the initiative prior to that date.
June 28, 2018 – Californians for Consumer Privacy withdraw the ballot initiative. Governor Jerry Brown signs the CCPA into law, and Assemblymember Ed Chau, who leads the California Assembly’s Privacy and Consumer Protection Committee, calls the event a “historic step” for California consumers.
August 24, 2018 – On the last day to amend legislation on the floor, amendments to S.B. 1121 are proposed. These amendments revise drafting errors, clarify the definition of personal information, and modify certain exemptions.
August 31, 2018 – On the last day for each house to pass bills, amendments to the CCPA pass the Senate floor. An urgency clause is adopted to bring the amendments to the Governor’s attention, and the legislature’s final recess begins.
September 23, 2018– Governor Jerry Brown approves the first round of CCPA amendments.
January 7, 2019 – Governor Jerry Brown leaves office, and Governor Gavin Newsom is sworn in.
September 13, 2019 – The California legislature approves five bills during the second round of CCPA amendments, including: AB 25, AB 874, AB 1146, AB 1355, and AB 1564—codifying exemptions for employee data, data broker registration requirements, and further clarifying the definition of personal information. Other amendments fail, including: AB 846, AB 1416, and AB 873—which would have provided anti-discrimination exemptions, exempted sharing personal information with government agencies, and amend the definition of deidentified data.
September 25, 2019 – On the keynote stage of International Association of Privacy Professionals’ Privacy. Security. Risk. conference, Alastair Mactaggart announces a forthcoming ballot initiative, the California Privacy Rights and Enforcement Act of 2020 (CPREA). An annotated version of the CPREA is released for public comment, and the initiative would create a sensitive data classification, add obligations on processors, and require the establishment of a California Privacy Protection Agency.
October 2, 2019– Mactaggart submits the second draft of the CPREA ballot initiative, which contains few substantive changes from the first draft.
October 10, 2019 – The California Attorney General’s Office releases the first draft of a set of proposed regulations, as required by the CCPA, which will operationalize and provide additional guidance for complying with the CCPA—triggering a 45-day public comment period.
October 11, 2019 – Governor Newsom signs the second round of CCPA amendments—including AB 25, AB 874, AB 1146, AB 1355, and AB 1564—into law.
October 16, 2019 – Californians for Consumer Privacy release findings from a poll of 777 registered California voters, finding that nearly nine out of ten voters would support a ballot measure expanding privacy protections for consumers’ personal information. 88% of all respondents said they would vote in favor of the initiative if an election were held immediately, and 4% would vote no, opposing the measure.
November 13, 2019 – Californians for Consumer Privacy submit the final draft of the new ballot initiative, now called California Privacy Rights Act (CPRA), which includes substantive changes to previous drafts. If enough signatures are collected to place it on the ballot, the CPRA will be voted on in the 2020 election.
December 6, 2019 – The California Attorney General’s Office releases the 250 pages of public comments from industry groups and civil society that it received regarding the CCPA and the Office’s proposed regulations.
January 1, 2020 – CCPA goes into effect. Covered entities have six months before enforcement begins, although actions taken (or not taken) after this date could be subject to enforcement after July 1, 2020.
February 3, 2020 – The first legal complaint citing the CCPA, Barnes v. Hannah Andersson, is filed in the Northern District of California. Plaintiffs sue retailer Hanna Andersson and Salesforce.com over a data breach suffered by Hanna Andersson, citing the CCPA.
February 10, 2020 – The California Attorney General’s Office issues its first set of modifications to the proposed enforcement regulations.
March 17, 2020 – A coalition of advertising companies sends the Attorney General a letter calling for a delay in enforcement, citing concerns related to the ongoing COVID-19 global pandemic.
March 24, 2020 – In response to requests for delays, an advisor to Attorney General Becerra is quoted saying: “We’re committed to enforcing the law starting July 1. We encourage businesses to be particularly mindful of data security in this time of emergency.”
May 4, 2020 – Californians for Consumer Privacy announce that despite the effects of the COVID-19 pandemic, they are able to submit over 900,000 signatures to qualify the California Privacy Rights Act (CPRA) for the November 2020 ballot.
June 8, 2020 – Alastair Mactaggart and other members of Californians for Consumer Privacy file a petition in state court alleging that the California Secretary of State failed to verify the signatures necessary to place the CPRA on the November 2020 ballot in a timely manner. That petition claims the “one-day delay . . . may prove fatal to the people’s right to vote on this initiative,” and requests that the court order the Secretary of State to direct local election officials to report the results of signature sampling, so that the ballot initiative may be certified in time.
June 11, 2020 – California Assemblymember Kevin Mullin proposes an amendment to the CCPA, AB 713, which would institute new contractual obligations for de-identified data and modify the research or public health exemptions.
June 19, 2020 – A California Judge grants Californians for Consumer Privacy’s petition, ordering counties to quickly finish verifying signatures to qualify the CPRA for the general ballot by June 25.
June 24, 2020 – The Elections Division of the office of the California Secretary of State reports that it received 623,212 signatures for certification of the CPRA ballot initiative, and that the Secretary of State will certify the initiative.
June 25, 2020 – The CPRA ballot initiative is officially certified to appear on the November 2020 general ballot, exactly two years after the CCPA ballot initiative was certified to appear on the November 2018 ballot. If CPRA is passed, its prospective effective date will be January 1, 2023.
June 30, 2020 – The Attorney General issues a reminder to California consumers regarding their rights under the CCPA, after tweeting that he will begin enforcement of the CCPA on July 1, 2020.
July 1, 2020 – Enforcement of the CCPA begins. Although “mindful of the challenges imposed by COVID-19,” the Attorney General remains dedicated to this enforcement date, and requests expedited review of the final proposed regulations, requesting that the Office of Administrative Law complete its review within 30 business days.
What’s next? If voters in California vote for the CPRA ballot initiative in the general election on November 3, 2020, the CPRA would become effective on January 1, 2023. The proposed law contains broader substantive protections than the CCPA, including data minimization and purpose limitation obligations, a stronger opt-out of behavioral advertising, and restrictions regarding the use of sensitive data. It would also establish a new Privacy Protection Agency in California to create additional regulations and to enforce the law.
FPF Resources on CCPA //
FPF Comments on the California Consumer Privacy Act (CCPA), FPF Staff, commending the Attorney General for a sincere and multi-faceted solicitation of feedback from diverse stakeholders and the public, as well as suggesting a number of key recommendations for later iterations of the bill.
CCPA Amendment Update June 2019—Twelve Bills Survive Assembly and Move to the Senate, co-written by Michelle Bae & Jeremy Greenberg, summary of the twelve bills that passed the Assembly and moved to the Senate for further consideration, as well as key Senate bills that failed. The blog also includes a timeline of next steps and a description of the California State Legislature’s administrative process.
Comparison Privacy Laws: GDPR v. CCPA, co-written by OneTrust DataGuidance and FPF, identifies the key differences between the General Data Protection Regulation (GDPR) and the legislative version of the California Consumer Privacy Act of 2018 (CCPA). That analysis noted that while the two laws share some similarities—the CCPA differs from the GDPR in some significant ways, particularly with regard to the scope of application; the nature and extent of collection limitations; and rules concerning accountability.
Examining Industry Approaches to CCPA “Do Not Sell” Compliance, by Charlotte Kress, summarizes and compares industry tools and approaches to advertising within the CCPA’s requirements; including: the Digital Advertising Alliance’s guidelines and new icon; Interactive Advertising Bureau’s CCPA Compliance Framework for Publishers and Technology Companies; Google’s “Restricted Data Processing” mechanism; and the Network Advertising Initiative’s analysis to aid companies in determining whether a business activity may, or may not, constitute a “sale” under the CCPA.
Child Privacy Protections Compared: California Consumer Privacy Act v. Proposed Washington Privacy Act, by Amelia Vance, compares the California Consumer Privacy Act (CCPA) with the child privacy provisions proposed within the Washington Privacy Act (SB 6281). In that post, FPF notes that the CCPA contains specific requirements regarding the sale of children’s data, while SB 6281 would place children’s data in a larger category of “sensitive data” that would enjoy heightened protection.
A New U.S. Model for Privacy? COmparing the Washington Privacy Act to GDPR, CCPA, and More, co-written by Stacey Gray, Pollyanna Sanderson, and Katelyn Ringrose, comparing noteworthy provisions in the GDPR, CCPA, CPRA, WPA 2019, and WPA 2020, including: jurisdictional scope, definitions and structure, pseudonymous data, individual rights, obligations on companies, facial recognition provisions, and preemption and enforcement.
Catalyzing Privacy Law, co-authored by Anupam Chander, Margot E. Kaminski & William McGeveran, provides a close comparison of GDPR and CCPA, and argues that CCPA, rather than GDPR, is catalyzing privacy law in the U.S.
CCPA Amendment Tracker, drafted and compiled by IAPP, includes summaries of bills that passed and failed along with key dates.
Acknowledgements to Stacey Gray, Senior Counsel (US Legislation and Policymaker Education), Polly Sanderson, Policy Counsel.