Event Report: FPF APAC and ABLI Report Launch Event and Panel on sidelines of 58th Asia Pacific Privacy Authorities (APPA) Forum in Singapore
Edited by Josh Lee Kok Thong and Isabella Perera
On November 30, the Future of Privacy Forum (FPF) and the Asian Business Law Institute (ABLI) held a joint event to launch their new report, “Balancing Organizational Accountability and Privacy Self-Management in Asia-Pacific,” which provides a detailed comparison of the legal bases for processing personal data in 14 jurisdictions in the Asia-Pacific (APAC) region: Australia, China, India, Indonesia, Hong Kong SAR, Japan, Macau SAR, Malaysia, New Zealand, the Philippines, Singapore, South Korea, Thailand, and Vietnam. The report builds upon a series of 14 individual reports released throughout 2022 that provide an overview of the legal bases for processing personal data in each of these jurisdictions.
This launch event took place on the sidelines of the 58th APPA Forum, hosted by Singapore’s Personal Data Protection Commission (PDPC) between November 29 and 30. Many APPA members – which include privacy and data protection authorities from 18 jurisdictions in APAC and the broader Pacific region – as well as representatives from industry, civil society, and the legal community joined FPF and ABLI for this event.
The event began with introductory remarks by Dr. Gabriela Zanfir-Fortuna (Vice President for Global Privacy, FPF), Josh Lee Kok Thong (Managing Director, FPF APAC), and Rama Tiwari (Chief Executive, Singapore Academy of Law), as well as a brief presentation by Dominic Paulger(Policy Manager, FPF APAC) that outlined the scope and main finding of the report.
These remarks were followed by a panel discussion that focused on key themes from the report and considered how to promote consistency and interoperability in legal bases for processing personal data around the APAC region while also ensuring the right balance between the interests of individuals, the organizations that process their personal data, and society at large.
The discussion was moderated by Yeong Zee Kin (Deputy Commissioner, PDPC), who was joined by four expert panelists: Dr. Clarisse Girot (Head of Data Governance and Privacy Unit, OECD); Leandro Angelo Y. Aguirre (Deputy Commissioner, National Privacy Commission, Philippines); Laura Gardner (Senior Counsel, Data Protection, Microsoft); and Rajesh Sreenivasan (Partner and Head of Technology, Media, and Telecommunications Practice, Rajah and Tann Singapore).
This post summarizes this exciting discussion and the key takeaways.
Role of consent
Moderator Yeong Zee Kin commenced the discussion by asking how regulators should think about the role of consent in the digital economy.
Dr. Clarisse Girot noted that due to advances in technology and changes in how organizations process personal data, consent has ceased to be meaningful. In her view, while consent plays an important role in data protection laws, it has been overused in the APAC region. In her view, this is because organizations that process personal data and practitioners have tended to regard consent as the easiest available option to comply with regional laws, especially if regulators have not seriously considered alternatives to consent. She suggested that overuse of consent could lead to “consent fatigue” for individuals.
Dr. Girot further noted that it would be appropriate to rely on consent in situations where individuals: (1) understand and can make a genuine decision about how their personal data will be used, (2) voluntarily provide their personal data to an organization, and (3) can withdraw their consent if necessary. However, she considered that such situations would likely be rare in practice. She, therefore, proposed that it may be necessary for regulators to ensure that their data protection laws contain legal bases besides consent to protect individuals from risks of harm.
In this regard, Dr. Girot highlighted the “legitimate interest” basis in European data protection law as a viable alternative basis to consent in situations where it is inappropriate for organizations to seek consent. She explained that because consent requirements are more strictly enforced in the European Union (EU), organizations in the EU tend to rely on legitimate interests (rather than consent) as a legal basis for processing data in most situations. However, she noted that there may be challenges to adopting such an approach in APAC as only a few jurisdictions in APAC currently recognize a legal basis for processing personal data premised on legitimate interests, and that other APAC jurisdictions are unlikely to enact reforms to recognize this basis in the near future.
Laura Gardner agreed that the processes involved in obtaining consent can overwhelm individuals and lead to “consent fatigue”. She added that even where individuals give valid consent, they may not make meaningful decisions as they may not always understand how their personal data will be used, especially if they rush to give consent in order to access a product or service as quickly as possible. In this regard, Ms. Gardner highlighted the importance of providing effective notice, using appropriate user interfaces, and providing the right level of information “just in time” to enable users to make meaningful and informed decisions about how their personal data is used.
Leandro Aguirre shared the National Privacy Commission (NPC)’s experience in implementing consent requirements in the Philippines’ data protection law, the Data Privacy Act of 2012 (DPA). He explained that although the DPA provides several alternative legal bases to consent for processing personal data (including legitimate interests), the NPC initially focused on consent because conceptually, it was easier to understand and appeared to give individuals control over how their personal data would be used.
Mr. Aguirre further clarified that consent and notice are distinct concepts under the DPA: if an organization relies on consent to process personal data under the DPA, the organization would be required to notify the data subject, obtain consent in a recorded manner, and ensure that the consent is freely given, informed, and specific, and that there is an indication of will on the part of the data subject. By contrast, if the organization relies on an alternative legal basis to consent in the DPA to process personal data, then the organization would only be required to notify the data subject.
However, he added that the NPC had realized that in practice, organizations were overusing consent and were passing the burden of validating and legitimizing the processing of personal data to the data subject, causing information overload and “consent fatigue.” Hence, the NPC has been working on a set of guidelines that aims to shift the idea of consent to just-in-time notices, which Mr. Aguirre hopes will encourage companies to rely on other legal bases, such as legitimate interests, to process personal data.
Promoting complementary alternatives to consent, like legitimate interests
Moving the discussion from consent to alternatives to consent, moderator Yeong Zee Kin shared a regulator’s perspective on alternatives to consent, focusing on the PDPC’s experiences of developing alternatives like legitimate interests in the 2020 amendments to Singapore’s Personal Data Protection Act 2012 (PDPA). He explained that when the PDPC first proposed including a legitimate interest basis in the PDPA, the PDPC was guided by the legislative purpose of the PDPA, which is to govern processing of personal data in a manner that recognizes both the right of individuals to protect their personal data and the need of organizations to process personal data for reasonable purposes.
Laura Gardner observed that a benefit of the legitimate interest basis, compared with consent, is that it builds in accountability in organizations. This is because the basis requires organizations to assess the benefits and risks of processing personal data to the individual and, if necessary, take steps to mitigate risks. Nevertheless, she also noted that a difficulty with this basis is that organizations may not feel as comfortable relying on it because they may be concerned that regulators may not agree with the organization’s assessment of the balance of interests. She stressed that regulators could help organizations gain greater familiarity with the legitimate interest basis by issuing clear guidance with specific examples of use cases on where the basis could be applied.
Leandro Aguirre emphasized that when relying on legitimate interests, companies are in a better position than the data subject to assess the impact of processing on the data subject as data subjects may not be able to understand everything provided to them. As for how the NPC regards the legitimate interest basis, Mr. Aguirre explained that three things must be considered: (1) organizations have to establish the existence of a legitimate interest; (2) the processing of personal data must be necessary for this legitimate interest; and (3) the legitimate interest must not override the fundamental human rights and freedoms of data subjects. He added that in the event of a violation, the NPC would only recommend prosecution if there were gross negligence on the part of the organization. This means that as long as an organization has accountability measures in place, it would not necessarily face an enforcement action from the NPC simply because the regulator does not agree with the organization’s legitimate interest assessment. He further added that dialogue between regulators and organizations is essential to increase clarity around the use of the legitimate interest and to ensure that organizations are comfortable relying on this legal basis when processing personal data.
Rajesh Sreenivasan shared the perspective of legal practitioners who advise organizations that process personal data. He explained that despite the existence of accountability-focused alternatives to consent like legitimate interests and business improvement exception in Singapore’s PDPA and other similar laws, many lawyers today would still advise their clients to rely on consent as practitioners may believe that it is easier to demonstrate and operationalize compliance with consent requirements (e.g., by producing a completed consent form). He added that practitioners and clients may also believe that accountability approaches to processing personal data would impose greater burdens on organizations.
Nonetheless, Mr. Sreenivasan observed that there are objective measures that can be used to demonstrate accountability, such as data protection impact assessments. He also noted that accountability-focused approaches like the legitimate interest basis may prove useful in situations where it is difficult to obtain meaningful consent, such as data analytics or artificial intelligence applications where data processing is so complex and dynamic that individuals may not be well-placed to understand how their personal data will be processed.
Mr. Sreenivasan also drew attention to Singapore’s decision in the 2020 amendments to the PDPA to create a legal basis for processing personal data, known as the “business improvement exception,” to address situations where the balance of interests is more strongly weighted in favor of businesses in developing products and services.
On a final note, Mr. Sreenivasan also stressed that regulators should not compel organizations to use consent, legitimate interests, or other alternative legal bases in specific situations. Instead, he suggested that regulators should permit organizations to make choices based on their own needs.
Consistency and interoperability of regional laws
Yeong Zee Kin explained that in amending Singapore’s PDPA, the PDPC also sought to facilitate cross-border compliance by ensuring that the PDPA had similar structures to those in the EU’s General Data Protection Regulation (GDPR) and other laws in APAC that had followed the GDPR’s example, such as a legitimate interest basis for processing personal data.
Clarisse Girot stressed that consent is still the main connecting point between jurisdictions in the APAC region. She suggested that even if individual jurisdictions promoted alternatives to consent, organizations that process personal data in multiple jurisdictions would likely only start incorporating those alternatives into their compliance frameworks if there was a “critical mass” of jurisdictions with similar alternatives. Dr. Girot thus encouraged regional regulators to come together to look for similar structures within their respective laws, and issue consistent guidance on alternatives to consent.
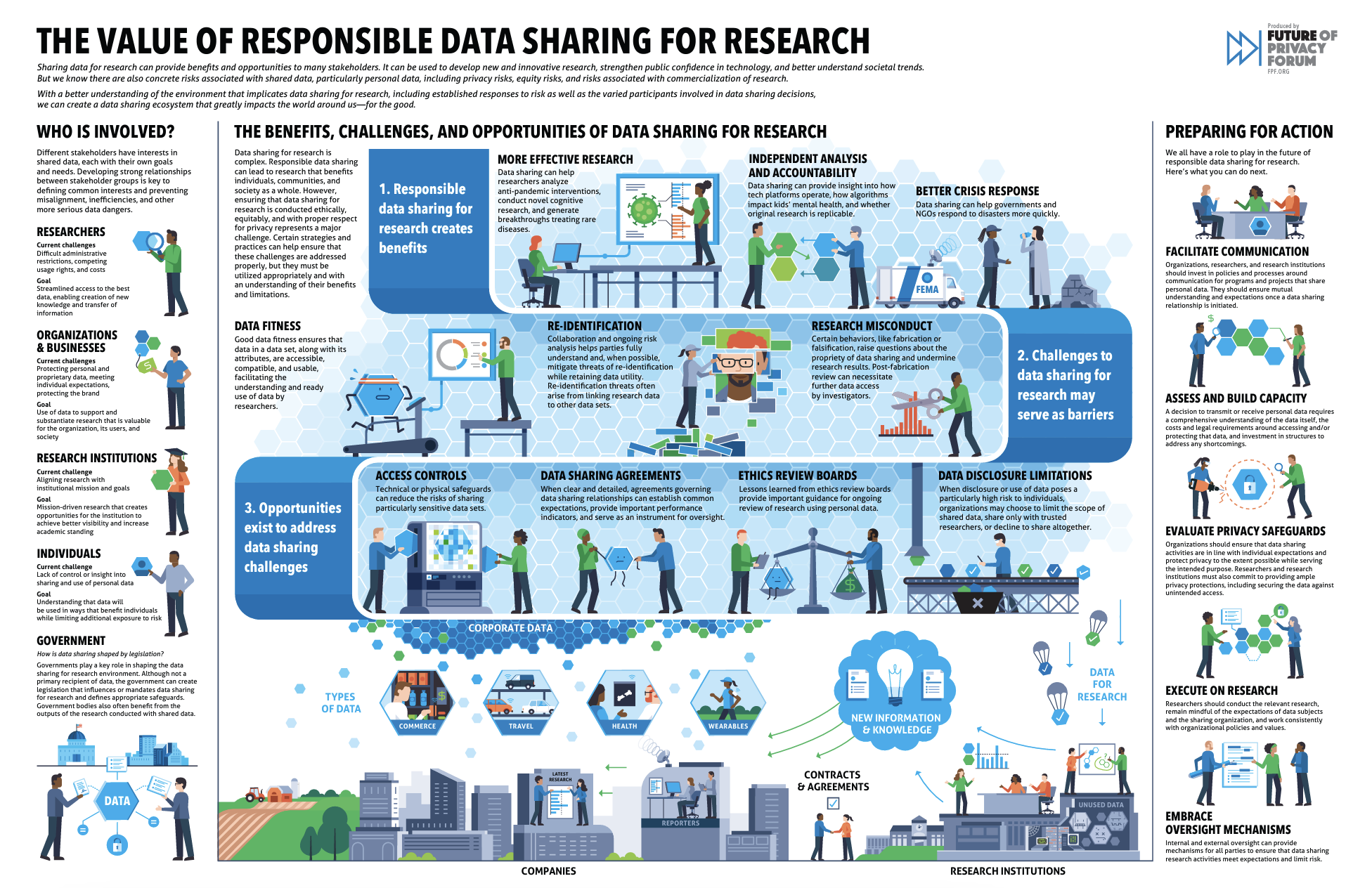
FPF Releases “The Playbook: Data Sharing for Research” Report and Infographic
Facilitating data sharing for research purposes between corporate data holders and academia can unlock new scientific insights and drive progress in public health, education, social science, and a myriad of other fields for the betterment of the broader society. Academic researchers use this data to consider consumer, commercial, and scientific questions at a scale they cannot reach using conventional research data-gathering techniques alone. This data also helped researchers answer questions on topics ranging from bias in targeted advertising and the influence of misinformation on election outcomes to early diagnosis of diseases through data collected by fitness and health apps.
The playbook addresses vital steps for data management, sharing, and program execution between companies and researchers. Creating a data-sharing ecosystem that positively advances scientific research requires a better understanding of the established risks, opportunities to address challenges, and the diverse stakeholders involved in data-sharing decisions. This report aims to encourage safe, responsible data-sharing between industries and researchers.
“Corporate data sharing connects companies with research institutions, by extension increasing the quantity and quality of research for social good,” said Shea Swauger, Senior Researcher for Data Sharing and Ethics. “This Playbook showcases the importance, and advantages, of having appropriate protocols in place to create safe and simple data sharing processes.”
In addition to the Playbook, FPF created a companion infographic summarizing the benefits, challenges, and opportunities of data sharing for research outlined in the larger report.
As a longtime advocate for facilitating the privacy-protective sharing of data by industry to the research community, FPF is proud to have created this set of best practices for researchers, institutions, policymakers, and data-holding companies. In addition to the Playbook, the Future of Privacy Forum has also opened nominations for its annual Award for Research Data Stewardship.
“Our goal with these initiatives is to celebrate the successful research partnerships transforming how corporations and researchers interact with each other,” Swauger said. “Hopefully, we can continue to engage more audiences and encourage others to model their own programs with solid privacy safeguards.”
Shea Swauger, Senior Researcher for Data Sharing and Ethics, Future of privacy Forum
Established by FPF in 2020 with support from The Alfred P. Sloan Foundation, the Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data shared with academic researchers. The call for nominations is open and closes on Tuesday, January 17, 2023. To submit a nomination, visit the FPF site.
FPF has also launched a newly formed Ethics and Data in Research Working Group; this group receives late-breaking analyses of emerging US legislation affecting research and data, meets to discuss the ethical and technological challenges of conducting research, and collaborates to create best practices to protect privacy, decrease risk, and increase data sharing for research, partnerships, and infrastructure. Learn more and join here.
Driver Impairment and Privacy: What Lies Ahead for Driver Impairment Detection?
The 2021 Infrastructure Act mandates that the US Department of Transportation issue a rule requiring the creation and implementation of monitoring systems to deter drivers impaired by alcohol, inattention, or drowsiness. The Department of Transportation (DOT) must establish a Federal mandatory motor vehicle safety standard to “passively monitor a motor vehicle driver’s performance to accurately detect if the driver may be impaired.” (“Advanced Drunk and Impaired Driving Prevention Technology,” Sec. 24220(b)(1)(A)(i)). Details in the statute are sparse; the DOT’s rule will likely establish many practical and technical details that the statute does not address.
Among the actions required under the 2021 law, the DOT is required to set a safety standardfor the use of blood alcohol detection technology within three years, after which vehicle manufacturers will have between two-three years to install the systems in all new passenger motor vehicles manufactured after the effective date. In practice, such systems will be required for all new vehicles beginning November 2026, although they could be rolled out sooner. DOT’s National Highway Traffic Safety Administration (NHTSA) will lead the rulemaking.
Today, many car makers offer different types of driver assistance technologies that can reduce crashes and improve safety for drivers, passengers, pedestrians, cyclists, and other road users. The Advanced Impaired Driving Technology mandated by the Infrastructure Act may further enhance safety, but its implementation must address its impact on drivers and passengers, including the collection and use of their personal data. Driver acceptance of auto safety measures is particularly important; previous attempts to mandate seat belt use resulted in public backlash and quick Congressional rollback. As the DOT, automakers, safety advocates, and other stakeholders think through issues raised by the Infrastructure Act’s mandate, questions must be considered regarding the accuracy of the technology, implementation by carmakers, driver acceptance, and the overall impact on the privacy of drivers and passengers:
1.Accuracy – The accuracy of the Advanced Impaired Driving Technology will be key to the proper, non-biased functioning and use by drivers.
2.Data Collection and Use – Cars already collect significant amounts of data for a variety of functional, safety, and other purposes. Policymakers tasked with establishing standards and guidelines for the Advanced Impaired Driving Technology should ensure that any personal data collected or retained is limited, reasonable, and processed safely and fairly.
3.Driver Acceptance – Stakeholders must decide what should occur in situations where the technology detects that a driver is intoxicated.
Accuracy
The accuracy of Advanced Impaired Driving Technology will be central to the proper functioning and use by drivers. The law requires that the technology must “accurately identify whether the driver may be impaired” but does not specify particular accuracy thresholds. Policymakers at DOT and NHTSA will need to encounter this issue as they conduct the rulemaking and establish the rule and should consider testing to ensure that technology is fair, targeted, and consistently highly accurate.
The concept of using technology to detect driver impairment, including blood alcohol concentration (BAC) levels, is not novel. For example, in some jurisdictions, a person with a DUI conviction can be required to use ignition interlocks – devices in vehicles that detect BAC through breath (commonly known as breathalyzers). Every time a person gets into a car, the ignition interlock device requires them to breathe into a tube. While commonly used in ignition interlocks and during traffic stops, breathalyzers are not 100% accurate and cannot achieve the same level of accuracy as blood or urine tests. Errors from breathalyzers can result from both miscalibration or human error. As DOT considers rules for Advanced Impaired Driving Technology, the agency will likely need to consider other potential sources of inaccuracy, including mischaracterization of lawful substances (such as mouthwash) as intoxicants or misattribution of passenger intoxication to an unimpaired driver.
Existing technologies used by car makers today to detect driver impairment may or may not be sufficient to meet the statute’s requirement for accuracy. For example, carmakers have available safety features that include driver-facing cameras and automated detection of erratic driving. An alert from these driver monitoring technologies may reflect that a driver is intoxicated, but not always. An alert can also result from drowsiness, distraction, or emotional stress. On the other hand, an intoxicated driver may not display typical impairment signs. As a result, it is not clear that existing technologies meet the law’s mandate of “accurately identify[ing] whether the driver may be impaired.”
Data Collection and Use
As vehicle manufacturers begin to design and implement technologies that detect blood alcohol concentration (BAC), DOT and NHTSA should ensure that guidelines for any personal data collected are clear, limited, reasonable, and require data to be processed safely and fairly.Manycars already collect significant amounts of data about drivers and passengers. This data may be collected to support safety, maintain efficient performance, increase driver or passenger convenience, or related to in-car entertainment. For instance, the “infotainment” features in a car can be connected to the radio and other apps that collect information on the music listened to or when it is turned on or off.
It is not clear whether Advanced Impaired Driving Technology will need to collect, share, or retain detailed records in order to function. For example, a vehicle could incorporate a method to delete on-device data or automatically delete data on a rotating basis when it is no longer necessary. However, there could be significant reasons to collect and retain data, including to test for and ensure accuracy or allow for a driver to dispute the interference.
Car manufacturers must also be transparent about options for data re-use or for third-party data access. Commercial entities, advocates, or government agencies may wish to obtain access to (or the ability to access) individual or aggregate information from Advanced Impaired Driver Technologies. Collecting data on a driver’s intoxication level could have implications for insurance risk scores, driver safety scores, public safety, and other purposes that impact drivers and passengers.
Driver Acceptance
Finally, stakeholders must consider what should occur in situations where the technology detects that a driver is intoxicated. The mandate states that the technology should “prevent or limit vehicle operation” but does not specify how that should or would occur. For example, when a driver is flagged as impaired, the technology may prohibit vehicle operation, but other options may include requiring extra steps to operate the vehicle, displaying warnings, limiting the speed of the vehicle, or alerting the owner or a designated contact registered to the car.
Auto manufacturers could design systems that would prevent a car from starting or limit its performance if a driver is intoxicated. This may prevent or limit impaired driving, a serious problem in the US, on average 32 people die every day in drunk driving crashes. However, a false positive could cause surprise or concern for drivers who do not expect to be prevented from driving, including in emergencies or unexpected situations. For some drivers, it could create new safety concerns if they are unable to leave situations in which they are facing threats to their physical safety. This could also impact consumer attitudes and engagement with this technology. Alternatively, a vehicle could display warnings, reduce vehicle functionality, or introduce friction at the point of starting the car.
What’s Ahead?
There are many open questions about this mandate and how the technology will work, and the effect on automakers and consumers. The DOT has two additional years to meet the Congressional deadline to establish standards for the use of blood alcohol detection technology in vehicles. Meanwhile, vehicle manufacturers should be thinking ahead and engaging with NHTSA about how they can implement such features in new vehicles. FPF will continue to monitor the regulatory process, including privacy implications of this technology and how it may be implemented in the future.
Record Set: Assessing Points of Emphasis from Public Input on the FTC’s Privacy Rulemaking
More than 1,200 law firms, advocacy organizations, trade associations, companies, researchers, and others responded to the Federal Trade Commission’s Advance Notice of Proposed Rulemaking (ANPR) on “Commercial Surveillance and Data Security.” Significantly, the ANPR initiates a process that may result in comprehensive regulation of data privacy and security in the United States, and also marks a notable change from the Commission’s historical case-by-case approach to addressing consumer data misuse. Comments received in response to the ANPR will be used to generate a public record that informs the Commission in deciding whether to pursue one or more draft rules, and will be generally available for any policymaker to utilize in future legislative proposals. The Future of Privacy Forum’s comment is available here.
Using a sample of 70 comments, excluding our own, selected from stakeholders representing various sectors and perspectives, the Future of Privacy Forum analyzed responses for common themes and areas of divergence. Below is a summary of key takeaways.
1. Areas of Agreement
a. Data Minimization
Many submissions encouraged the Commission to create a rule or standard requiring that companies engage in some form of data minimization. Data minimization is a foundational data protection principle, appearing in the Fair Information Practice Principles (FIPPs) and required by the European Union’s General Data Protection Regulation (GDPR) and other international regulations. The European Data Protection Supervisor (EDPS) emphasized that an FTC data minimization rule would help harmonize data protection standards between the European Union (EU) and the United States (U.S.), and would codify the data protection best practices established by the Commission’s history of enforcement. Several comments focused on the ability of data minimization to create “market wide” incentives that could disrupt an environment that may provide competitive advantages to organizations who are not responsible data stewards, while Palantir noted that, unlike the exercise of data subject rights, data minimization requires no extra action from users.
A small group of responses noted that data minimization has implications for machine learning (ML) and the development of artificial intelligence (AI) systems. While such systems must be trained on vast quantities of data, commenters noted that it is equally important that such data be high quality. Palantir emphasized that data minimization, insofar as it required the deletion of out-of-date or otherwise flawed data, would support this goal. EPIC noted that data minimization requirements would help ensure that businesses use of personal data is aligned with consumer expectations, observing that, “[c]onsumers reasonably expect that when they interact with a business online, that business will collect and use their personal data for the limited purpose and duration necessary to provide the goods or services they have requested,” and not retain their data beyond that duration or for other uses. Finally, Google, the Wikimedia Foundation, and other commenters emphasized that a data minimization rule would support data security objectives as well: if companies retain less personal data, data breaches, when they do occur, will be less harmful to consumers.
b. Data Security
There was also broad, though not uniform, consensus around support for a data security rule requiring businesses to implement reasonable data security programs. Many commenters noted that data security incidents are a common occurrence, are not reasonably avoidable by consumers, and pose grave risks to individuals, including that of identity theft. The EDPS underscored the role of data security in protecting core rights and freedoms under EU law and the GDPR, and recommended that the Commission require organizations to engage in data processing impact assessments as well as data protection by design and default, and use encryption and pseudonymization to protect personal data.
The Computer & Communications Industry Association (CCIA) observed that any data security rulemaking should be harmonized with standards established by the Cybersecurity and Infrastructure Security Agency (CISA) and the National Institute of Standards and Technology (NIST). In this same vein, the Software Alliance (BSA), “encourage[d] the agency…to recognize that the best way to strengthen security practices cross industry sectors is by connecting any rule on data security to existing and proposed regulations, standards, and frameworks.” The BSA also asked that the Commission recognize the “shared responsibilities of companies and their service providers” in protecting consumer data, and create rules that reflect this dual-responsibility framework, as well as the different relationships that companies versus service providers have with consumers. Some commenters discussed how the Commission’s rulemaking should interact with other agencies. For example, the Center for Democracy and Technology (CDT) emphasized that reasonable data security requirements should extend to the government services context, including to government-run educational settings, as well as to non-financial identity verification services.
2. Areas of Contention
a. The Commission’s Authority
By far, the most common disagreement among commenters was whether, and to what extent, the Commission could promulgate data privacy and security regulations through their statutory authority. Most commenters took a moderate approach–believing that the Commission had some level of limited rulemaking authority in the space. Commenters provided a variety of bases for where the Commission could and could not create rules, and why. Some entities believed that the Commission could only address practices that clearly demonstrate consumer harm, while others encouraged the Commission to focus on FTC enforcement actions that have already survived judicial scrutiny. Google noted that the “FTC rests on solid ground” for a data security rule given the Third Circuit’s decision in FTC v. Wyndham Worldwide Corp, which affirmed the agency’s authority to regulate data security as an unfair trade practice. While many commenters also argued that the Commission could only create rules that would not overlap with other regulatory jurisdictions, some advocates believed that the FTC can use its authority to regulate unfair and deceptive practices like discrimination even when other agencies have concurrent jurisdiction. The Lawyers Committee for Civil Rights noted the FTC’s extensive experience sharing concurrent jurisdiction with other agencies, where “[i]t works on ECOA with the Consumer Financial Protection Bureau, on antitrust with the Department of Justice, and on robocalls with the Federal Communications Commission.”
However, comments also existed at both ends of the spectrum in regard to the FTC’s authority to act. Some commenters, largely from civil society organizations, civil rights groups, and academia, argued that the Commission has substantial authority to address data privacy and security where data practices meet the statutory requirements for being “unfair or deceptive.” These commenters reasoned that Congress intended the Commission’s Section 5 authority to maintain dexterity to address evolving commercial practices, and thus can be easily applied to data-driven activities that cause unavoidable and substantial injury to consumers.
Other commenters, largely comprising trade associations, business communities, and some policymakers questioned the Commission’s authority to conduct this rulemaking under the FTC Act. While some, like the Developers Alliance, argued that most data collection practices do not constitute “unfair or deceptive” trade practices, the majority of commenters in opposition argued that the Commission lacks the authority to conduct this type of rulemaking because the regulation of data privacy and security is a “major question” best served through Congress. These comments focused on the Supreme Court’s 2022 ruling in West Virginia v. EPA, holding that regulatory agencies, absent clear congressional authorization, cannot issue rules on major questions that affect a large portion of the American economy. Several Republican U.S. Senators noted that “simply stating within the ANPR that within Section 18 of the FTC Act, Congress authorized the Commissionto propose a rule defining unfair or deceptive acts or practices…is hardly the clear Congressional authorization necessary to contemplate an agency rule that could regulate more than 10% of U.S. GDP ($2.1 trillion) and impact millions of U.S. consumers (if not the entire world).” The lawmakers further argued that even if the Commission could prove clear Congressional authorization, the rulemaking would likely violate the FTC Act because the ANPR failed to describe the area of inquiry under consideration with the mandated level of specificity.
b. “Commercial Surveillance”
The Commission’s framing of the ANPR regarding “commercial surveillance,” was another area that generated controversy. The ANPR defines “commercial surveillance” as “the collection, aggregation, analysis, retention, transfer, or monetization of consumer data and the direct derivatives of that information.”
Several comments supported the Commission’s framing and detailed the multitude of ways in which businesses track private individuals over time and space. The Electronic Privacy Information Center (EPIC) stated, “[t]he ability to monitor, profile, and target consumers at a mass scale have created a persistent power imbalance that robs individuals of their autonomy and privacy, stifles competition, and undermines democratic systems.” The most common examples of practices considered “commercial surveillance” by commenters included: targeted advertising, facial recognition, pervasive tracking of people across services and websites, unlimited sharing and sale of consumer information, and secondary uses of consumer information.
On the other side, commenters argued that the terminology around “commercial surveillance” was both an unfair and overly broad characterization. Trade associations like the Information Technology Industry Council argued that the term implies a negative connotation for any commercial activity that collects or processes data, even the many legitimate, necessary, and beneficial uses of data that make products and services work for users. Many comments emphasized the crucial role of consumer data in our society and how it has been used to fuel social research and innovation, including telehealth, studying the efficacy of the COVID vaccine, the development of assistive AI for disabled individuals, identifying bias and discrimination in school programs, and ad-supported services like newspapers, magazines, and television.
3. Other Notable Focuses
a. Automated Decision-Making and Civil Rights
A large contingency of advocacy organizations documented how automated decision-making systems can exacerbate discrimination against marginalized groups. Organizations including the National Urban League, Next Century Cities, CDT, Upturn, Lawyers’ Committee for Civil Rights Under Law, and EPIC provided illustrative examples of discriminatory outcomes in housing, credit, employment, insurance, healthcare, and other areas brought about by algorithmic decision-making.
Industry groups including the National Association of Mutual Insurance Companies argued that discrimination concerns are best addressed through Congressional action, given that the FTC Act does not mention discrimination and does not answer the foundational legal question of ”whether it is a regime of disparate treatment or disparate impact.” Many advocacy groups refuted this assertion and argued for the necessity of addressing algorithmic discrimination in a rule because of gaps in existing civil rights law and because of the Commission’s history of utilizing concurrent jurisdiction. For example, Upturn highlighted three major gaps, noting that current law leaves large categories of companies, such as hiring screening technology firms, uncovered; fails to address modern-day harms such as discrimination by voice assistants; and does not require affirmative steps to measure and address algorithmic discrimination.
Commenters made a variety of suggestions about how the Commission could address these problems in a rule, including through data minimization (National Urban League), greater transparency (CDT), declaring the use of facial recognition technology an unfair practice in certain settings (Lawyers’ Committee, EPIC), and implementing principles in the Biden administration’s Blueprint for an AI Bill of Rights (Upturn, Lawyers’ Committee). Google emphasized that any rulemaking on AI should be risk-based and process-based and promote transparency, adding that “a process-based approach with possible safe harbor provisions could encourage companies to continually audit their systems for fairness without fear that looking too closely at their systems could expose them to legal liability.”
b. Health Data and Other Considerations in Light of Dobbs
Responding to concerns about the risk of misuse of geolocation data specifically, Planned Parenthood called upon the Commission to write tailored regulations requiring that the retention of location data be time-bound and linked to a direct consumer request. The Duke/Stanford Cyber Policy Program emphasized that the Commission should seek to establish comprehensive regulations to govern data brokers, and that, “[i]n some cases, the policy response should include restrictions or outright bans on the sale of certain categories of information, such as GPS, location, and health data.” AG Bonta recommended that, “[t]he Commission…prohibit [the] collection, retention or use of particularly sensitive geolocation data, including…data showing that a user has visited reproductive health and fertility clinics.”
Many comments addressed questions around sensitive health-related data that is not otherwise protected by the Health Insurance Portability and Accountability Act (HIPAA). The College of Healthcare Information Management Executives (CHIME) emphasized that many consumers do not understand the scope or scale of the use of their sensitive health data, including data collected by fitness and “femtech” apps. The American Clinical Laboratory Association (ACLA), meanwhile, emphasized that the Commission should not subject entities already subject to HIPAA to new requirements, and argued that de-identified data should be exempt from privacy and security protections. Finally, algorithmic discrimination in the healthcare context was a focus area for several commenters.
c. Children’s Data
Finally, many commenters also weighed in on the particular vulnerability of children online. The Software & Information Industry Association (SIIA), for example, recognized that children deserve unique consideration, but argued that FTC rulemaking on child and student privacy would be duplicative of existing Commission efforts to update COPPA rules, as well as existing education privacy statutory provisions at the federal and state levels. Others suggested that a Commission rule could and should address child safety. Some of their most pressing concerns included:
Age verification: One of the thorniest issues surrounding protecting child privacy has been parameters for age verification. Many commenters, including the Wikimedia Foundation, Data & Society Research Institute (Data & Society), and AG Rob Bonta, outlined the limits of using biological age for age verification purposes, the harms of using biometric verification, and concerns about increasing data collection in order to verify age.
Targeted advertising: The EDPS, among other commenters, addressed unique concerns about targeted advertising to children, with EPIC, the Center for Digital Democracy, and Fairplay calling explicitly for a ban on targeted advertising to minors.
Data minimization: EPIC proposed a “strictly necessary” standard for the collection and processing of minors’ data. Data & Society highlighted the importance of data minimization for reducing privacy harms for children, but cautioned that it shouldn’t be used as a pretext to “deploy ‘strategic ignorance.”
Design: Data & Society called for some “basic floors”, such as those found in the United Kingdom’s Age-Appropriate Design Code. EPIC specifically proposed that the FTC make it “an unfair and deceptive practice for companies to make intentional design choices in order to facilitate the commercial surveillance of minors.”
Deletion rights: Data & Society advocated for an “eraser button” that would allow young people to delete “the data collected about them and the algorithms fed by that data that shape the content they see,” modeled after GDPR Articles 16 and 17. In contrast, SIIA raised concerns about an unfettered deletion right, particularly in educational contexts, noting that deletion of records like grades and attendance records could negatively impact students and school programs.
What’s Next?
The ANPR is merely one step along a lengthy and arduous rulemaking process. Should the Commission decide to move forward with rulemaking after reviewing the public record, they will need to notify Congress, facilitate another public comment process on a proposed rule, conduct informal hearings, and survive judicial review. Regardless of the outcome, the ANPR comment period has provided an ample public record to inform any policymaker about the current digital landscape, the most pressing concerns faced by consumers, and frameworks utilized by companies and other jurisdictions to mitigate privacy and security risks.
The authors would like to acknowledge FPF intern Mercedes Subhani for her significant contributions to this analysis.
FPF Provides Input on Draft Colorado Privacy Act Regulations
On September 30th, The Colorado Department of Law released draft regulations to implement the Colorado Privacy Act. The Future of Privacy Forum (FPF) filed written comments in response to the proposed rules on November 7th. Furthermore, FPF’s Keir Lamont and Felicity Slater participated in public stakeholder sessions hosted by the Colorado Attorney General’s Office as part of its regulatory process held on November 10th and November 17th.
FPF’s comments identified and provided recommendations to address areas of potential ambiguity in the draft regulations. Specifically, FPF’s contributions encouraged the Department of Law to:
Provide additional clarity for the exercise of consumer rights through Universal Opt-Out Mechanisms (UOOMs), including standards for residency authentication and the procedures by which “opt-out lists” may function as UOOMs.
Resolve apparent inconsistencies in the draft regulations for the use of on-by-default UOOMs.
Clarify the intended scope of restrictions on “Dark Patterns” in consumer interfaces.
Assess the scope and intended effect of the regulations’ novel definitions for “biometric data” and “biometric identifiers.”
Align the protections of children’s privacy and relevant definitions with the Children’s Online Privacy Protection Act (COPPA).
The comment docket for the Colorado Privacy Act draft regulations remains open. Interested parties also have an opportunity to participate in a rulemaking hearing scheduled for February 1, 2023.
FPF at IAPP’s Europe Data Protection Congress 2022: Global State of Play, Automated Decision-Making, and US Privacy Developments
Authored by Christina Michelakaki, FPF Intern for Global Policy
On November 16 and 17, 2022, the IAPP hosted the Europe Data Protection Congress 2022 – Europe’s largest annual gathering of data protection experts. During the Congress, members of the Future of Privacy Forum (FPF) team moderated and spoke at three different panels. Additionally, on November 14, FPF hosted the first Women@Privacy awards ceremony at its Brussels office, and on November 15, FPF co-hosted the sixth edition of its annual Brussels Privacy Symposium with the Vrije Universiteit Brussels (VUB)’s Brussels Privacy Hub on the issue of “Vulnerable People, Marginalization, and Data Protection” (event report forthcoming in 2023).
In the first panel for IAPP’s Europe Data Protection Congress, Global Privacy State of Play, Gabriela Zanfir-Fortuna (VP for Global Privacy, Future of Privacy Forum) moderated a conversation on key global trends in data protection and privacy regulation in jurisdictions from Latin America, Asia, and Africa. Linda Bonyo (CEO, Lawyers Hub Africa), Annabel Lee (Director, Digital Policy (APJ) and ASEAN Affairs, Amazon Web Services), and Rafael Zanatta (Director, Data Privacy Brasil Research Association) participated.
Finally, in the third panel, Perspectives on the Latest US Privacy Developments, Keir Lamont(Senior Counsel, Future of Privacy Forum) participated in a conversation focused on data protection developments at the federal and state level in the United States. Cobun Zweifel-Keegan(Managing Director, D.C., IAPP) moderated it, and Maneesha Mithal (Partner, Privacy and Cybersecurity, Wilson Sonsini Goodrich & Rosati) and Dominique Shelton Leipzig,(Partner, Cybersecurity & Data Privacy; Leader, Global Data Innovation & AdTech, Mayer Brown) also participated.
Below is a summary of the discussions in each of the three panels:
1. Global trends and legislative initiatives around the world
In the first panel, Global Privacy State of Play, Gabriela Zanfir-Fortuna stressed that although EU and US developments in privacy and data protection are in the spotlight, the explosion of regulatory action in other regions of the world is very interesting and deserves more attention.
Linda Bonyo touched upon the current movement in Africa where countries are adopting their own data protection laws, primarily inspired by the European model of data protection regulation, since they trust that the GDPR is a global standard and lack the resources to draft policies from scratch. Bonyo also added that the lack of resources and limited expertise are the main reasons why African countries struggle to establish independent Data Protection Authorities (DPAs). She then stressed that the Covid-19 pandemic revived discussions about a continental legal framework to address data flows. Regarding enforcement, she noted that for Africa, the approach looks rather “preventative” than “punitive.” Bonyo also underlined that it is common for big tech companies to operate outside of the continent and only have a small subsidiary in the African region, rendering local and regional regulatory action less impactful than in other regions.
Annabel Lee offered her view on the very dynamic Asia-Pacific region, noting that the latest trends, especially post-GDPR, include not only the introduction of new GDPR-like laws but also the revision of existing ones. Lee noted, however, that the GDPR is a very complex piece of legislation to “copy,” especially if a country is building its first data protection regime. She then focused on specific jurisdictions, noting that South Korea has overhauled its originally fragmented framework with a more comprehensive one and that Australia will implement a broad extraterritorial element in its revised law. Then Lee stated that when it comes to implementation and interpretation, data protection regimes in the region differ significantly, and countries try to promote harmonization by mutual recognition. With regards to enforcement, she stressed that it is common to see occasional audits and that in certain countries, such as Japan, there is a very strong culture of compliance. She also added that education can play a key role in working towards harmonized rules and enforcement. Lee offered Singapore as an example, where the Personal Data Protection Commission gives companies explanations not only on why they are in breach but also on why they are not in breach.
Rafael Zanatta explained that after years of strenuous discussions, there is an approved data protection legislation in Brazil (LGPD) that has already been in place for a couple of years. The new DPA created by the LGPD will likely ramp up its enforcement duties next year and has, so far, focused on building experimental techniques (to help incentivize associations and private actors to cooperate) and publishing guidelines, namely non-binding rules that will provide future interpretation for cases. Zanatta stressed that Brazil has been experiencing the formalization of autonomous data protection rights with supreme court rulings stating that data protection is a fundamental right different from privacy. He underscored that it will be interesting to see how the private sector applies data protection rights given their horizontal effect and the development of concepts like positive obligations and the collective dimension of rights. He explained that the extraterritorial applicability of Brazil’s law is very similar to the GDPR since companies do not need to operate in Brazil for the law to apply. He also touched upon the influence of Mercosur, a South American trade bloc, in discussions around data protection and the collective rights of the indigenous people of Bolivia in light of the processing of their biometric data. With regards to enforcement, he explained that in Brazil, it is happening primarily through the courts due to Brazil’s unique system where federal prosecutors and public defenders can file class actions.
2. Looking beyond case law on automated decision-making
In the second panel, Automated Decision-making and Profiling: Lessons from Court and DPA Decisions, Sebastião Barros Vale offered an overview of FPF’s ADM Report, noting that it contains analyses of more than 70 DPA decisions and court rulings concerning the application of Article 22 and other related GDPR provisions. He also briefly summarized the Report’s main conclusions. One of the main points he highlighted is that the GDPR covers automated decision-making (ADM) comprehensively beyond Article 22, including through the application of overarching principles like fairness and transparency, rules on lawful grounds for processing, and carrying out Data Protection Impact Assessments (DPIA).
Ruth Boardman underlined that the FPF Report reveals the areas of the law that are still “foggy” regarding ADM. Boardman also offered her view on the Portuguese DPA decision concerning a university using proctoring software to monitor students’ behavior during exams and detect fraudulent acts. The Portuguese DPA ruled that the Article 22 prohibition applied, given that the human involvement of professors in the decisions to investigate instances of fraud and invalidate exams was not meaningful. Boardman further explained that this case, along with the Italian DPA’s Foodhino case, shows that the human in the loop must have meaningful involvement in the process of making a decision for Article 22 GDPR to be inapplicable. She added that internal guidelines and training provided by the controller may not be definitive factors but can serve as strong indicators of meaningful human involvement. Regarding the concept of “legal or similarly significant effects” — another condition for the application of Article 22 GDPR – Boardman noted the link between such effects and contract law. For example, in the case of national laws transposing the e-Commerce Directive in which adding a product to a virtual basket counts as an offer to the merchant and not as a binding contract, no legal effects are triggered. She also added that meaningful information about the logic behind ADM should include the consequences that data subjects can suffer and referred to an enforcement notice from the UK’s Information Commissioner Office concerning the creation of profiles for direct marketing purposes.
Simon Hania argued that the FPF Report showed the robustness of the EDPB guidelines on ADM and that ADM triggers GDPR provisions that are relevant to fairness and transparency. With regards to the “human in the loop” concept, Hania claimed that it is important to involve multiple humans and ensure that they are properly trained to avoid biased decisions. Then he elaborated on a case concerning Uber’s algorithms that match drivers with clients, where Uber drivers requested access to data to assess whether the matching process was fair. For the Amsterdam District Court, the drivers did not demonstrate how the matching process could have legal or similarly significant effects on them, which meant that drivers did not have enhanced access rights that would only apply if ADM covered by Article 22 GDPR was at stake. However, when ruling on an algorithm used by another ride-hailing company (Ola) to calculate fare deductions based on drivers’ performance, the same Court found that the ADM at issue had significant effects on drivers. For Hania, a closer inspection of the two cases reveals that both ADM schemes affect drivers’ ability to earn or lose remuneration, which highlights the importance of financial impacts when assessing the effects of ADM as per Article 22. He also touched on a decision from the Austrian DPA concerning a company that scored individuals on the likelihood they would belong to certain demographic groups, as the DPA mandated the company to inform individuals about how it calculated their individual scores. For Hania, the case shows that controllers need to explain the reasons behind their automated decisions – regardless of whether they are covered by Article 22 GDPR or not – to comply with the fairness and transparency principles of Article 5 GDPR.
Gintare Pazereckaite noted that the FPF Report is particularly helpful in understanding inconsistencies in how DPAs apply Article 22 GDPR. She then stressed that the interpretation of “solely automated processing” should be done in light of protecting and safeguarding data subjects’ fundamental rights. Pazereckaite also referred to the criteria set out by the EDPB guidelines that clarify the concept of the “legal and similarly significant effects.” She added that data protection rules such as accountability and data protection by design play an important role in allowing data subjects to understand how ADM works and what consequences it may bring up. Lastly, Pazereckaite commented on Article 5 of the proposed AI Act – which contains a list of prohibited AI practices – and its importance when an algorithm does not trigger Article 22 GDPR.
3. ADPPA and regional laws re-shaping US data protection regime
In the last panel, Perspectives on the Latest US Privacy Developments, Keir Lamont offered an overview of recent US Congressional efforts to enact the American Data Privacy and Protection Act (ADPPA) and outstanding areas of disagreement. For him, the bill would introduce stronger rights and protections than those set forth in existing state-level laws; including a broad scope; strong data minimization provisions; limitations on advertising practices; enhanced privacy-by-design requirements; algorithmic impact assessments; and a private right of action. In contrast, existing state laws typically adhere to the outdated opt-in/opt-out paradigm for establishing individual privacy rights.
Maneesha Mithal explained that in the absence of comprehensive federal privacy legislation, the Federal Trade Commission (FTC) has largely taken on the role of DPA by virtue of having jurisdiction over a broad range of sectors in the economy and acting both as an enforcement and rulemaking agency. Mithal explained that the FTC enforces four existing privacy laws in the US and can also take action against both unfair and deceptive trade practices. For example, the FTC can enforce against any statement (irrespective of whether it is in a privacy policy or the context of user interfaces), material omissions (for example, the FTC has concluded that a company did not inform its clients that it was collecting second by second television data and was further sharing it), and unfair practices in the data security area. Mithal pointed out that since the FTC does not have the authority to seek civil penalties for first-time violations, it is trying to introduce additional deterrents by naming individuals (for example, in the case of an alcohol provider, the FTC named the CEO for failing to prioritize security) and is using its power to obtain injunctive relief. For example, in a case where a company was unlawfully using facial recognition systems, the FTC ordered the company to delete any models or algorithms that were used, and thus FTC applied the fruit to the poisonous tree theory. Mithal also noted that although the FTC has historically not been active as a rulemaking authority due to procedural issues along with the lack of resources and time considerations, it is initiating a major rulemaking involving “Commercial Surveillance and Lax Data Security Practices.”
Finally, Dominique Shelton Leipzig offered remarks on state-level legislation focusing on the California Consumer Privacy Act (CCPA) as amended by the California Privacy Rights Act (CPRA), adding that Colorado, Connecticut, Utah, and Virginia have similar laws. She elaborated on the CPRA’s contractual language, comparing California’s categorization of “Businesses,” “Contractors,” “Third Parties,” and “Service Providers” to the GDPR’s distinction between controllers and processors. Shelton Leipzig also explained that the CPRA introduced a highly disruptive model for the ad tech industry since consumers can opt out of both the sale of data, as well as the sharing of data. The CPRA also created a new independent rulemaking and enforcement Agency, the first in the US, focusing only on data protection and privacy. Finally, she addressed the recently enacted California Age-Appropriate Design Code Act, which focuses on the design of internet tools, and stressed that companies are struggling to implement it.
Five Big Questions (and Zero Predictions) for the U.S. State Privacy Landscape in 2023
Entering 2023, the United States remains one of the only global economic powers that lacks a comprehensive, national framework governing the collection and use of consumer data throughout the economy. Congress made unprecedented progress toward enacting baseline privacy legislation in 2022. However, the apparent impasse in the efforts to move H.R. 8152, the American Data Privacy and Protection Act (“ADPPA”) over the finish line is likely to re-center the states as the locus of continued legislative activity on consumer privacy. Stakeholders are eager to learn which (if any) states will establish new privacy rights and protections in the coming year, but it remains too early in the legislative cycle to make predictions with any confidence. So instead, this post explores five big questions about the state privacy landscape that will determine whether 2023 emerges as a pivotal year for the protection of consumer data in the United States.
1. Will any state raise the bar for comprehensive privacy protections?
In four of the past five years, a new high-water mark for American privacy protections has been set through the enactment of comprehensive legislation at the state-level. In 2018, the California Consumer Privacy Act (CCPA) emerged as the nation’s first comprehensive consumer privacy law. The 2020 California Privacy Rights Act (CPRA) ballot initiative expanded California’s privacy regime, establishing heightened protections for certain sensitive personal information and providing a right to correct inaccurate data. In 2021, Virginia (VCDPA) and Colorado (CPA) enacted laws that are notable for creating ‘opt-in’ affirmative consent requirements in addition to California-style ‘opt-out’ privacy rights. Finally, in 2022, Connecticut (CACPDPOM) adopted a privacy law that improved upon prior models by creating clear protections for facial recognition data and an explicit right to revoke consent.
Will any state continue this trend by enacting a privacy law that establishes new or stronger privacy rights and protections for its citizens in the coming year? As industry groups become increasingly insistent about the dangers of a ‘patchwork’ of divergent state privacy laws raising compliance costs for businesses, it is possible that policymakers will be reluctant to explore new approaches to privacy protection and will instead advance legislation that ‘paints inside the lines’ of the five established laws.
In considering the forthcoming state privacy landscape, one of the best places to start is with the jurisdictions that came closest to adopting new privacy laws over the past year. In 2022, five states saw privacy legislation clear one chamber of their legislature: Florida (HB 9), Indiana (SB 358), Iowa (HF 2506), Oklahoma (HB 2969), and Wisconsin (AB 957). Of these, the Midwestern proposals (Indiana, Iowa, and Wisconsin) would not have meaningfully expanded privacy rights, protections, or compliance obligations beyond what is already on the books in other states (though they would have established some important privacy rights and protections for their residents).
Alternatively, last year’s bills from Oklahoma and Florida would have significantly reshaped privacy compliance programs for covered entities. Oklahoma’s Computer Data Privacy Act includes more rigorous consent requirements than any comparable state or national law, while Florida’s proposal would have required companies to adhere to strict data retention schedules and provided for enforcement mechanisms that are absent in other state laws, including a private right of action. However, there are reasons to suspect the window of opportunity for each bill may have closed. In Oklahoma, the bill’s most prominent backer, Democratic Rep. Collin Walke, has retired. As for Florida, reports indicate that the bill’s sponsor believes that leadership changes make it unlikely that the state will prioritize privacy legislation in the coming years.
Although no state appears to have an existing-privacy framework with a demonstrated record of support at the ready to move next year, history has also shown that under the right political conditions novel privacy legislation can rapidly advance in a single legislative session. Potential candidates for similar progress in 2023 include Oregon, where an Attorney General-led multi-stakeholder task force has spent months gearing up to advance a comprehensive consumer privacy bill next legislative cycle. In New York, a set of end-of-session amendments to the 2022 version of the New York Privacy Act (S6701) brought the proposal structurally closer to existing privacy laws, suggesting this legislation could see renewed momentum in the coming year. It is also worth remembering that despite privacy’s emergence as a bipartisan issue, the only states to enact comprehensive privacy legislation to date have had the same party in power in both legislative chambers and the governor’s mansion. It will therefore be worth watching four states that have previously considered privacy legislation and emerged from the November elections with newly formed Democratic Party trifectas in government: Maryland (SB 11), Massachusetts (H 4514), Michigan (SB 1182 & HB 5989), and Minnesota (HF 1492 (2021)).
2. Will there be an ‘ADPPA Effect’?
In 2022, the American Data Privacy and Protection Act (ADPPA) advanced through the House Energy and Commerce Committee by an overwhelmingly bipartisan 53-2 vote. ADPPA appears unlikely to be enacted this Congress as the bill’s backers were unable to secure the support of either Senate Commerce Chair Cantwell or outgoing Speaker Pelosi. Nevertheless, the introduction, enthusiasm, and momentum behind ADPPA represented a seismic event for the U.S. privacy landscape and may exert significant influence on state lawmakers in the coming years.
There are two (potentially competing) theories for how ADPPA’s emergence may impact state governments considering privacy legislation. First, in introducing state privacy legislation, lawmakers have routinely asserted that they are acting in the absence of Congressional action and that they would prefer to see a unified, federal approach to the protection of consumer privacy. As a result, demonstrated bipartisan cooperation on ADPPA and the potential for further progress in the next Congress may make consumer privacy a less salient issue in state legislatures.
On the other hand, it is also possible that ADPPA will substantially drive the content of privacy bills that will be considered in 2023. The majority of state privacy proposals considered in recent years have been modeled on either the California or Washington Privacy Act legislative frameworks, both of which are rooted in the traditional, narrow privacy paradigm of ‘notice and choice.’ However, ADPPA’s framework is significantly stronger and broader than any enacted state law in rights and protections, scope, and enforcement mechanisms. For example, ADPPA would broadly cover businesses and nonprofits, establish strict data minimization requirements, create new civil rights protections, and provide for enforcement by a private right of action. The prominence of ADPPA and its record of bipartisan support make it a potential third model for state privacy legislation. There is already legislation in Michigan (SB 1182) that contains shades of ADPPA in its formulation of a private right of action. What, if any, additional language or concepts from ADPPA will gain traction at the state level?
3. Have we entered the Age of the Age-Appropriate Design Code?
While ‘comprehensive’ privacy laws and proposals continue to capture the bulk of the privacy commentariat’s attention, it is likely that the most significant U.S. consumer privacy development in 2022 was not ‘comprehensive,’ but ‘sectoral’ in nature. On September 15, California Governor Newsom signed the Age-Appropriate Design Code (AB 2273) into law. The AADC is a far-reaching children’s online safety, design, and privacy statute that is loosely modeled on an existing UK code of practice. Come 2024, the AADC will govern online services likely to be accessed by Californian users under 18 years of age and create significant new obligations. Notably, the law could also run contrary to traditional privacy interests and priorities, as it contains age-estimation requirements that will likely cause many companies to collect additional personal information on all their users. California’s AADC has been divisive – lauded by some and criticized as unworkable or unconstitutional by others. But most careful readers agree that the statute leaves many key terms undefined or vague; future rulemaking or other work to bring clarity is likely.
The ‘California effect’, where activity in California is seen to catalyze others to mimicry, is well documented in the privacy context. This means that a key question for consumer privacy in the coming years is whether other states will follow California’s lead and begin to enact their own age-appropriate design laws. Supporters of the AADC certainly intend for it to serve as a model for adoption in additional jurisdictions. However, as with breach notification statutes and comprehensive privacy laws, should other states consider and enact age-appropriate design legislation, there is no guarantee that they will follow neatly in the footsteps of California.
One AADC-style proposal that has already been introduced, the New York Child Data Privacy and Protection Act (S9563), would impose significant new obligations beyond California’s AADC. Perhaps most notably, S9563 would severely limit product development by requiring a risk assessment to be completed for any new online feature of a service targeted toward children, to be reviewed and approved by the Attorney General’s Office before such feature can be made available to the public. The California AADC also contains a broad grant of rulemaking authority, meaning that even if other states adopt identical laws, the contours of the AADC’s rights and responsibilities may continue to shift over the coming years. In sum, age-appropriate design legislation has the potential to dramatically alter online experiences for all users in the coming years; however, the ultimate impact of such frameworks is likely to come into greater focus over the coming months.
4. Will state legislatures prioritize protections for health and location data?
In June, the Supreme Court’s decision in Dobbs v. Jackson Women’s Health overturned decades of precedent to hold that the U.S. Constitution does not confer a right to receive an abortion. Following this decision, dozens of states took rapid action to either criminalize or shore up protections for receiving or providing reproductive health services. For example, California enacted AB-1242, which seeks to prohibit electronic communications providers from complying with out-of-state law enforcement inquiries relating to the investigation or enforcement of laws prohibiting abortion. However, there are indications that come 2023, some Democratic state lawmakers will pursue a new legislative response by regulating the collection, processing, and transfer of health and location data by businesses.
In New York, SB 9599 would impose strict consent requirements on companies that collect or sell personal health information for data processing, geofencing, or data brokering. The Washington State Attorney General’s office has announced that it will support similar legislation, the Consumer Health Data Privacy Act, in the coming year. Stakeholders will be watching closely to learn whether these legislative efforts converge around a shared approach to key definitions, rights, and business obligations, or move forward with diverging health privacy frameworks.
5. How effective will the laws taking effect be?
No matter what happens in state legislatures this year, 2023 will hold the distinction as the year in which the new era of state privacy laws take effect. On January 1st, California’s revised regime and Virginia’s law will become operational, followed by the Colorado and Connecticut statutes on July 1st, with Utah’s statute bringing up the rear with a December 31st effective date. In the impending shift from theory to practice, how will both public and policymaker perceptions of these various laws change?
While privacy professionals have spent years debating and preparing for these impending state laws, 2023 will mark the first time that many U.S. consumers will be legally entitled to exercise new privacy rights over the businesses that collect and share their personal information. Depending on the public perception (both immediate and over time) of these new state privacy laws, legislative efforts in other jurisdictions could be impacted in a variety of ways. For example, successful rollouts of the new state laws could prompt lawmakers in other jurisdictions to move forward on similar bills, seizing upon a popular issue. On the other hand, if the new laws kick off with a whimper, lawmaker appetite to take up consumer privacy issues might wane. If these laws take effect and consumers face difficulty in exercising their rights (as Consumer Reports argues occurred following the enactment of the CCPA), perhaps lawmakers will consider statutes with stronger enforcement mechanisms and larger penalties in order to compel compliance. Alternatively, lawmakers may also consider establishing longer ‘on-ramps’ to compliance (particularly for small businesses) or seek to draft more explicit, self-executing statutory obligations.
Conclusion
This commentary has noted several privacy proposals already under serious consideration for the 2023 legislative calendar (particularly in New York, where many bills have already been introduced). These bills and efforts should be regarded as only the narrow, visible tip of the iceberg, lawmakers and stakeholders across the country are likely already at work on new proposals that will not be officially introduced until legislative sessions formally convene. This article has posed many questions but can offer only one clear forecast: a turbulent and exciting year in the efforts to advance and secure new consumer data privacy rights and protections is on the horizon. Be sure to follow the Future of Privacy Forum for help tracking emerging trends and key developments throughout the year.
FPF Releases Comparative Analysis of California and U.K. Age-Appropriate Design Codes
The Future of Privacy Forum (FPF) today released a new policy brief comparing the California Age-Appropriate Design Code Act (AADC), a first-of-its-kind privacy-by-design law in the United States, and the United Kingdom’s Age-Appropriate Design Code. While there are distinctions between the two codes, the California AADC, which is set to become enforceable on July 1, 2024, was modeled after the UK’s version and represents a significant change in the regulation of the technology industry and how children will experience online products and services.
“Understanding the requirements of both the UK and California codes, and in particular where they differ, is critical for companies in the US and abroad who may soon be covered under one – or both – codes,” said Chloe Altieri, Youth & Education Privacy policy counsel for FPF and an author of the report. “The explanations and examples in the UK code, many of which are not yet defined in California’s version, may provide helpful compliance insights.”
The report builds on FPF’s in-depth analysis of the California AADC, published in October, and contains a side-by-side comparison of the 15 standards laid out in the UK AADC to the corresponding text of the California AADC, including the “best interests of the child” standard, age assurance, default settings, parental controls, enforcement, and data protection impact assessments.
The report also outlines several broader distinctions between the California and UK codes, including, crucially, how the underlying regulatory frameworks differ. While both codes build on the aims of their respective consumer privacy laws (the UK’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act), the California AADC is standalone legislation that will be independently enforced, while the UK AADC and GDPR are linked, and enforcement falls to the UK Information Commissioner’s Office (ICO). The UK AADC is also “rooted” in Article 3 of the United Nations Convention on the Rights of the Child (UNCRC), an international treaty ratified by 195 countries, including the UK, but not the US. While the California AADC uses a similar “best interests of children” standard, without the foundation of the UNCRC, there is much less certainty in how businesses should make that determination.
“As policymakers in other states start to consider similar age-appropriate design code legislation, understanding how and why the California and UK codes differ will be critical,” said Bailey Sanchez, Youth & Education Privacy policy counsel at FPF and an author of the report. “It is not as simple as copying and pasting the UK code in California or anywhere else. California’s version was adapted to fit the legal landscape in the US and the state, which has a unique consumer privacy landscape. Other states will need to make their own adjustments.”
FPF’s youth and education privacy team is closely monitoring the implementation of the California AADC. Catch up on previous blog posts tracking the bill’s progress and our formal analysis once the bill was signed into law. To access the Youth & Ed team’s child and student privacy resources, visit www.StudentPrivacyCompass.org and follow the team on Twitter at @SPrivacyCompass.
New Report Promotes Accountability-Based Approach to Data Protection in the APAC Region
In recent years, there has been an uptick in new (comprehensive) data protection laws in the Asia Pacific (APAC). This trend introduces challenges for cross-border compliance, particularly for the industry, legal practitioners, and the community of data protection regulators. As a result of the difficulties, these stakeholders acknowledge that there is a need for greater consistency in regional data protection frameworks.
Today, the Future of Privacy Forum (FPF) — a global non-profit focused on privacy and data protection — and experts from the Asian Business Law Institute (ABLI) — a Singapore-based think tank non-profit dedicated to providing practical guidance in the field of Asian legal development — released a report providing a detailed comparison of the requirements for processing personal data in 14 jurisdictions in the Asia-Pacific (APAC), including Australia, China, India, Indonesia, Hong Kong SAR, Japan, Macau SAR, Malaysia, New Zealand, the Philippines, Singapore, South Korea, Thailand, and Vietnam. The comparative analysis follows a months-long dissemination of individual reports on each jurisdiction.
In the movement for enhanced consistency between different jurisdictions’ data protection laws, FPF and ABLI found that many APAC jurisdictions have engaged in conversations aroundthe call to move away from consent-centric privacy practices. Consent practices are often restricted to individual jurisdictions and their legal systems. FPF and ABLI’s new report aims to elevate this discussion by promoting alternatives to consent measures, thereby increasing the accountability of organizations that process personal data.
By using various alternative legal bases other than consent and with an eye on supporting greater accountability, organizations can balance their interest in using personal data with broader societal concerns, such as developing a vibrant digital economy or preventing the harms of crime and fraud to individuals.
“The APAC region is presently undergoing a period of intensive law reform. This APAC comparative report provides an opportunity for lawmakers, governments, and regulators who draft, review or implement data protection laws to have a comprehensive overview and analysis of notice, consent, and related requirements that operate in the data protection frameworks of their respective jurisdictions, regional partners and neighbors,” saidJosh Lee Kok Thong, Managing Director of FPF APAC in Singapore. “We hope the report serves as a catalyst for initiating a regional dialogue focused on clarifying existing uncertainties and enhancing the compatibility of regional data protection laws.”
Understanding that compliance-based approaches to data privacy, such as consent, notice, and choice mechanisms, have serious limitations, FPF and ABLI propose an accountability-based approach to data protection. This new system shifts the responsibility of protection to users and controllers of personal data by utilizing data protection impact assessments (DPIAs). Assessing risk and enhancing accountability provides organizations with legal certainty, ensuring better privacy accountability across the region.
Moreover, FPF and ABLI found that this accountability approach is necessary and important as data protection developments continue advancing across the APAC region. The rise of new developments conveys a rare opportunity to clarify existing uncertainties and enhance the compatibility of Asian data protection laws on these crucial privacy issues. The report’s comparative legal analysis and input from industry, privacy professionals, and regional practitioners have demonstrated that despite divergences, commonalities exist and can be leveraged to drive convergence between jurisdictions’ different legal systems.
“ABLI is delighted to see the fruit of its partnership with FPF culminating in the release of this comparative review at a time when digitalization is driving an increase in cross-border data flows,” said Mr. Rama Tiwari, Chief Executive of the Singapore Academy of Law, ABLI’s parent organization. “With the largest economies in APAC estimated to be able to reap economic benefits of approximately US$2 trillion if they fully capture their digital potential, the release of the report provides a timely and enabling reference for policymakers and practitioners alike as they design, reform and refine policies and practices for personal data processing both domestically and across borders.”
The GDPR and the AI Act Interplay: Highlights from FPF and Ada Lovelace Institute’s Joint Event
Authored by Christina Michelakaki, FPF Intern for Global Policy
On November 9, 2022, FPF, along with the Ada Lovelace Institute (Ada), organized a closed roundtable in Brussels where experts met to discuss the lessons that can be drawn from General Data Protection Regulation (GDPR) enforcement precedents when deciding on the scope and obligations of the European Commission (EC)’s Artificial Intelligence (AI) Act Proposal. The event hosted representatives from the European Parliament, civil society organizations, Data Protection Authorities (DPAs), and industry representatives.
The roundtable discussion was based on a comprehensive Report launched by FPF in May 2022 analyzing case law under the GDPR applied to real-life cases involving Automated Decision-Making (ADM). This blog outlines the main conclusions drawn by the speakers on four main topics:
the complementarity between the AI Act and the GDPR;
the needed clarity on transparency requirements and AI training;
the difference between the risk-based approach and an exhaustive high-risk AI list; and
the need for effective enforcement and redress avenues for affected persons.
As outlined in a recent analysis on the matter published by FPF, Barros Vale highlighted that:
The AI Act and the GDPR share Article 16 of the Treaty on the Functioning of the European Union (TFEU) as a legal basis, so data protection considerations are important when it comes to regulating AI systems under the AI Act Proposal.
Regarding the AI value chain, the AI Act’s ‘users’ will generally be the ‘controllers’ under the GDPR in the deployment phase of AI systems; during the development phase, providers will likely be the GDPR controllers where they build AI systems relying on the collection, analysis, or any other processing of personal data.
Where no processing of personal data is involved, or where no GDPR breaches occur, but AI systems still significantly impact individuals, the AI Act could potentially fill redress gaps.
The existing and future GDPR case law on ADM may inspire the future enlargement of the list of high-risk AI systems (HRAIS) provided in Annex III of the AI Act.
This was followed by short interventions from the participants and a discussion.
The AI Act and the GDPR have different but complementary scopes and obligations.
Speakers seemed to agree on the fact that not following the GDPR’s distinction between data controllers and processors in the AI Act stems from the fact that the EC aims at regulating AI systems entering the EU market from a product safety perspective.
Industry representatives further explained that trying to understand the requirements of the AI Act from a data protection point of view does not make practical sense. They added that having specific types of AI systems in the Annex III list would not make them lawful per se, notably if they breach GDPR requirements.
Other panelists noted that the AI Act has a broader scope than the GDPR regarding AI systems, as it covers cases where no personal data processing is involved but that may negatively affect individuals.
Moreover, participants questioned whether the AI Act’s human oversight requirements would render Article 22 GDPR on ADM useless – notably, the rights for individuals to obtain human review of automated decisions. Some participants argued that this does not seem to be the case because users are not required by the AI Act Proposal to implement meaningful human oversight when they deploy AI systems. With regard to human oversight, the current draft of the AI Act only requires providers to embed measures into their AI systems that enable users to include human oversight in their deployment scheme.
Additionally, some experts claimed that the interplay between the AI Act and the GDPR was neglected in the original Proposal, which may raise further issues. As an example, the initial text seems to overlook the fact that users (likely controllers under the GDPR) are often very dependent on AI providers when it comes to practical GDPR compliance. Moreover, speakers worried about issues arising in the AI system’s deployment phase – where AI users are in control – and pointed to the approach proposed at the Council of Europe’s Convention on AI as more tailored to the responsibilities of each party.
For another speaker, incorporating broader fundamental rights impact assessments into the AI Act could complement Data Protection Impact Assessments (DPIAs) under the GDPR.
Transparency requirements and AI training need further clarity
With regard to certain requirements set forth by the AI Act Proposal, speakers conveyed that:
Training AI systems by using sensitive data,as allowed under Article 10(5) of the AI Act, may be challenging for Business-to-Business companies that do not usually process sensitive data since they would need to ask third parties for access to such data.
Transparency requirements under the AI Act need to ensure information is intelligible: sharing information that a well-trained expert understands will probably be useless for the average person. On the other hand, sharing too much information about how AI systems work may enable malicious actors to circumvent them (e.g., fraud detection algorithms).
The difference between the risk-based approach and an exhaustive high-risk AI list
As a pushback to having a specific set of strictly-regulated high-risk AI use cases in Annex III and prohibited practices in Article 5 of the AI Act, some voices suggested mimicking the GDPR’s open clauses and risk-based approach. More specifically, a few speakers agreed that not having a closed list but rather a set of overarching principles and risk assessment requirements would increase providers’ accountability and enable enforcers to verify compliance in a more flexible manner.
Speakers that advocated for such a solution agreed that the concept of ‘risk’ and its underlying assessment criteria should be read in line with the GDPR, which could also provide less prescriptive indications of how to mitigate detected risks.
For other experts in the room, a clear definition of AI along with the list of Annex III is preferable, as it avoids enshrining subjective risk assessment criteria. According to this point of view, relying on providers’ self-assessments to decide what is considered high-risk could benefit larger players with the financial incentives and legal resources to take a less cautious approach to AI development.
Among the participants that defended keeping a high-risk AI list, some called for the ability to easily update the list since novel risky AI use cases are constantly surfacing. One of the experts disagreed that it should fall on the EC to update the list, given the institution’s political driving factors. Instead, the speaker called for a bottom-up approach involving regulators and the public’s participation. Other voices also advocated for incorporating emotion recognition systems and the analysis of biometrics-based data in the list of high-risk AI use cases.
A need for effective enforcement and redress avenues for affected persons
Lastly, participants touched upon the AI Act’s governance mechanisms and redress avenues.
With regard to enforcement, some speakers stressed the need for cooperation between different competent regulators on AI and that DPAs should not be the sole or main enforcers of the AI Act. On the other hand, the idea that DPAs should be the main enforcers was also supported by some participants. On the previous point, some experts claimed that DPAs often lack the resources and expertise to deal with AI systems. Participants also advised against having EU Member-States choose their national authority to avoid fragmentation in regulatory approaches. Some speakers called for the centralization of enforcement of AI rules at the EU level while not excluding a potential role for DPAs.
When it comes to redress mechanisms, some speakers called for enshrining rights for individuals affected by AI systems, notably a right to complain to a supervisory authority and to file judicial claims, including class actions. Others highlighted that the recently proposed AI Liability and revised Product Liability Directives could empower individuals to obtain compensation for harms caused by AI systems.