FPF Report: Automated Decision-Making Under the GDPR – A Comprehensive Case-Law Analysis
On May 17, the Future of Privacy Forum launched a comprehensive Report analyzing case-law under the General Data Protection Regulation (GDPR) applied to real-life cases involving Automated Decision Making (ADM). The Report is informed by extensive research covering more than 70 Court judgments, decisions from Data Protection Authorities (DPAs), specific Guidance and other policy documents issued by regulators.
The GDPR has a particular provision applicable to decisions based solely on automated processing of personal data, including profiling, which produces legal effects concerning an individual or similarly affects that individual: Article 22. This provision enshrines one of the “rights of the data subject”, particularly the right not to be subject to decisions of that nature (i.e., ‘qualifying ADM’), which has been interpreted by DPAs as a prohibition rather than a prerogative that individuals can exercise.
However, the GDPR’s protections for individuals against forms of automated decision-making (ADM) and profiling go significantly beyond Article 22. In this respect, there are several safeguards that apply to such data processing activities, notably the ones stemming from the general data processing principles in Article 5, the legal grounds for processing in Article 6, the rules on processing special categories of data (such as biometric data) under Article 9, specific transparency and access requirements regarding ADM under Articles 13 to 15, and the duty to carry out data protection impact assessments in certain cases under Article 35.
This new FPF Report outlines how national courts and DPAs in the European Union (EU)/European Economic Area (EEA) and the UK have interpreted and applied the relevant EU data protection law provisions on ADM so far – before and after the GDPR became applicable -, as well as the notable trends and outliers in this respect. To compile the Report, we have looked into publicly available judicial and administrative decisions and regulatory guidelines across EU/EEA jurisdictions and the UK. It draws from more than 70 cases – 19 court rulings and more than 50 enforcement decisions, individual opinions, or general guidance issued by DPAs, – from a span of 18 EEA Member-States, the UK, and the European Data Protection Supervisor (EDPS). To complement the facts of the cases discussed, we have also looked into press releases, DPAs’ annual reports, and media stories.
Some examples of ADM and profiling activities assessed by EU courts and DPAs and analyzed in the Report include:
School access and attendance control through Facial Recognition technologies
Online proctoring in universities and automated grading of students
Automated screening of job applications
Algorithmic management of platform workers
Distribution of social benefits and tax fraud detection
Automated credit scoring
Content moderation decisions in social networks
FPF Training: Automated Decision-Making under the GDPR
Ready to get an in-depth understanding of the GDPR’s Automated Decision-Making requirements? Register for our upcoming virtual training session on November 9, where FPF experts will cover the critical elements of Article 22, recent DPA decisions, consent requirements, and more.
Our analysis shows that the GDPR as a whole is relevant for ADM cases and has been effectively applied to protect the rights of individuals in such cases, even in situations where the ADM at issue did not meet the high threshold established by Article 22 GDPR. Among those, we found detailed transparency obligations about the parameters that led to an individual automated decision, a broad reading of the fairness principle to avoid situations of discrimination, and strict conditions for valid consent in cases of profiling and ADM.
Moreover, we found that when enforcers are assessing the threshold of applicability for Article 22 (“solely” automated, and “legal or similarly significant effects”), the criteria they use are increasingly sophisticated. This means that:
Courts and DPAs are looking at the entire organizational environment where ADM is taking place, from the controller’s organizational structure, to reporting lines and the effective training of staff, in order to decide whether a decision was “solely” automated or had meaningful human involvement; and
Similarly, when assessing the second criterion for the applicability of Article 22, enforcers are looking at whether the input data for an automated decision includes inferences about the behavior of individuals, and whether the decision affects the conduct and choices of the persons targeted, among other multi-layered criteria.
A recent preliminary ruling request sent by an Austrian court in February 2022 to the Court of Justice of the European Union (CJEU) may soon help clarify these concepts, as well as other related to the information which controllers need to give data subjects about ADM’s underlying logic, significance and envisaged consequences for the individual.
The findings of this Report may also serve to inform the discussions about pending legislative initiatives in the EU that regulate technologies or business practices that foster, rely on,or relate to ADM and profiling, such as the AI Act, the Consumer Credits Directive, and the Platform Workers Directive.
On May 20, the authors of the report discussed with prominent European data protection experts some of the most impactful analyzed decisions during an FPF roundtable. These include cases related to the algorithmic management of platform workers in Italy and the Netherlands, the use of automated recruitment and social assistance tools, and creditworthiness assessment algorithms. The discussion also covered pending questions sent by national courts to the CJEU on matters of algorithmic transparency under the GDPR. View a recording of the conversation here, and download the slides here.
Diverging fining policies of European DPAs: is there room for coherent enforcement of the GDPR?
The European Union’s (EU) General Data Protection Regulation (GDPR) puts forward a non-exhaustive list of criteria in Article 83 that Data Protection Authorities (DPAs) need to consider when deciding whether to impose administrative fines and in determining their amount in specific cases. Notoriously, the ceiling for administrative fines put forward by the GDPR is high – up to 20M EUR or 4% of a company’s worldwide annual turnover for breaching specific rules (e.g. the rights of the data subject), and up to 10M or 2% of the same turnover for breaching the rest of the provisions (e.g. data security requirements), leaving ample room to calibrate the fines to the facts of a case.
While it was expected that independent DPAs would give the criteria different weight in their enforcement proceedings, depending on their own legal and cultural context, the past four years of enforcement experience have shown that fining policies and practices vary considerably among EU DPAs.
Some DPAs decided to formulate fining policies and publish them, while others merely built their own body of case-law and created practice around how these criteria are applied without formalizing such policies. The DPA of the German State of Bavaria was one of the first to publish non-binding guidance on the matter: in September 2016, it revealed it would devote particular attention to previous data protection infringements and the degree of collaboration the investigated parties offer during the proceedings.
To avoid having DPAs taking diverging approaches to setting fines under the new framework, the old Article 29 Working Party published its 2018 guidelines early on, before the GDPR became applicable, which were later endorsed by the European Data Protection Board (EDPB). They quote directly Recital 11 of the GDPR, stating that “it should be avoided that different corrective measures are chosen by the [DPAs] in similar cases.” Indeed, administrative fines are only one among several corrective measures in DPAs’ toolbox, which also includes the issuance of reprimands, compliance orders, suspension of data flows to recipients in third countries, and even temporary or definitive limitations or bans on data processing (Article 58(2) GDPR). Thus, the EDPB further clarified that fines should not be seen as the last resort available to DPAs and that it is not always necessary to supplement fines with other corrective measures.
While the EDPB guidelines provided inspiration for a few fining policies adopted by national DPAs, the authorities do not shy away from taking innovative approaches to standardize their fining procedures, as will be shown below. Other regulators (such as the Irish and the Belgian DPAs) have announced they plan to provide clarity and predictability to organizations about their sanctioning standards by publishing their own methodologies in this regard. Nonetheless, it is possible that some DPAs are waiting for the approval of upcoming EDPB guidance on the calculation of administrative fines to adopt their stance. As the publication is bound to happen in the coming days, FPF’s new piece outlines the similarities and differences between the few national fining policies published by European DPAs since 2018. This analysis and the differences it outlines show why it was necessary for the EDPB to adopt new guidance on this matter.
This blog post provides an overview of the only comprehensive fining methodologies that were published so far by EU DPAs (specifically, by the Dutch, Danish, and Latvian DPAs), as well as the relevant draft Statutory guidance issued by the UK DPA (ICO) in 2020. Therefore, this analysis will also show how the approach of the ICO in this matter will likely continue to differ from that of the EDPB and EU DPAs. It is divided into two sections that take a deep dive into (i) how those DPAs propose to apply the criteria set out in Article 83(1) to (3) GDPR in practice – highlighting where they diverge from the 2018 EDPB guidelines – and (ii) how they propose to standardize the amounts of the fines imposed against controllers or processors in their jurisdictions.
1. Balancing the same criteria with different scales
According to Article 83(2) GDPR, all DPAs need to consider the same non-exhaustive list of criteria when deciding whether to sanction controllers or processors with administrative fines for breaches of the GDPR, instead of or in addition to other corrective measures. These criteria also guide DPAs’ decisions on the determination of the amounts of the fines they impose in individual cases.
However, the analysis of the published DPA fining methodologies shows that different regulators attribute varying degrees of importance to these factors in both those exercises, sometimes deviating from the EDPB guidelines.
The Dutch DPA guidance does not generally provide indications as to how the regulator proposes to weigh in such factors nor the financial circumstances of the infringer in specific cases.
Article 83(2)(a) GDPR:Nature, gravity and duration of the infringement, including the nature, scope or purpose of the processing, the number of data subjects affected and the damage suffered by them
On this criteria, the EDPB guidelines from 2018 state that, in case of “minor infringements” or infringements carried out by natural person controllers, DPAs may generally opt for reprimands instead of fines as suitable corrective measures. The guidelines add that damages suffered by data subjects and the long duration of infringements should count as aggravating circumstances in DPAs’ assessments regarding the need for imposing and increasing the value of fines.
The ] recent (September 2021) Danish DPA (Datatilsynet) guidance on the determination of fines for natural persons seems to contradict the EDPB approach that fines may be dismissed by DPAs in these cases. The Datatilsynet guidance complements its January 2021 guidelines on the determination of fines for legal persons and proposes a table of standardized fines for natural person controllers who commit certain GDPR breaches (such as publishing others’ sensitive personal data in social media outlets). Regarding this criterion, the guidelines applicable to the sanctioning of legal persons establish that the DPA must have due regard to several factors, including whether the processing purpose is purely profit-seeking (e.g. marketing) or benevolent (e.g. calculating an early retirement pension), and whether data subjects’ rights have been breached (i.e., the concept of “damage” should be interpreted broadly).
Concerning the latter criterion mentioned by the Danish DPA, the ICO’s Regulatory Action Policy illustrates that the UK regulator takes a different approach. The Policy states that, for “damages” to count as an aggravating circumstance, a degree of damage or harm (which may include distress and/or embarrassment) must have been suffered by data subjects.
Lastly, the Latvian DPA’s guidance stresses that the criteria listed under Article 83(2)(a) GDPR may carry more weight than others when it comes to determining fines. As an example, the Latvian watchdog states that the duration of the breach and the number of data subjects affected is generally more important than the financial benefits obtained by the controller. This is also reflected in the table of points that the DPA shall use to determine the amounts of fines in individual cases, which is explored below.
Article 83(2)(b) GDPR:the intentional or negligent character of the infringement
Again, DPAs consider this factor in different ways and at different moments of the process of determining a fine. Nonetheless, they seem to agree that the higher the degree of imputation (negligence -> gross negligence -> intent), the higher the fine should be. It also surfaces from EDPB guidance that controllers and processors cannot justify breaches of data protection law by claiming a shortage of resources.
When assessing the infringer’s degree of culpability, the ICO takes into account the technical and organizational measures that had been implemented by the controller of processor, notably whether a lack of appropriate measures may reveal gross negligence. Additionally, the UK regulator will consider more severely cases of wilful action or inaction of the infringer with a view to obtain personal or financial gains.
The EDPB and the Danish DPA, on the other hand, are quite aligned when it comes to giving examples of negligent and intentional infringements, including:
Negligent breaches: non-compliance with existing policies, human error, lack of control of published information, lack of timely technical updates; and
Intentional breaches:decisions taken by the company’s Board against a DPO’s correct advice/despite existing internal policies, purposely amending personal data to make it inaccurate, and selling personal data without consent.
Of note, after the UK left the EU in 2020 the ICO is not bound anymore by EDPB guidance. Therefore, this may be one area where divergence in approaches to implement the GDPR and the UK GDPR will remain.
Article 83(2)(c) GDPR:any action taken by the controller or processor to mitigate the damage suffered by data subjects
The EDPB stresses that DPAs should look into whether the infringer did everything it could to reduce the consequences of a breach for data subjects. In that case – and also where the infringer admits its infringements and commits to limit its impacts -, this should count as a mitigating factor when determining the fine. As for national DPAs:
For the Datatilsynet, collecting evidence that unauthorized recipients of personal data have deleted the information is an example of relevant mitigating action.
The Latvian DPA highlights that it shall only consider damage control actions taken by the controller as a mitigating factor where such actions have been taken in due time (i.e. if they were actually effective).
Failure to adopt any such measures could also be considered as an aggravating circumstance by the ICO.
Article 83(2)(d) GDPR:the degree of responsibility of the controller or processor taking into account technical and organizational measures implemented by them
Once again, the EDPB and the Danish DPA seem to be in sync regarding the interpretation and the application of this criterion. In essence, DPAs must ask themselves whether the infringer has implemented the protective measures that it was expected to, considering the nature, purposes, and extent of the processing, but also current best practices (industry standards and codes of conduct). If so, this should be taken as a mitigating circumstance in the fine’s calculation.
Article 83(2)(e) GDPR:any relevant previous infringements by the controller or processor
On this criterion, there is some degree of divergence between approaches of the DPAs. The EDPB has tried to set the baseline by recommending DPAs focus on whether the entity committed the same infringement earlier or different infringements in the same manner, whereas prior breaches which are different in nature may still be included in the assessment.
The Danish DPA commits to a deeper analysis under this criterion, stating that it shall weigh breach findings made by other DPAs against the infringer, as well the latter’s breaches of the data protection framework which was in place prior to the GDPR. However, it also stresses that:
breaches of the GDPR should be considered more relevant than breaches of the previous law;
the longer the time that has elapsed between a previous infringement and the current one, the less weight it must have in determining the fine; and that
infringements that occurred more than 10 years prior to the infringement at stake become irrelevant.
In a rare indication of the degree of importance it attributes to specific factors listed under Article 83(2) GDPR, the Dutch DPA reveals that, in case the infringer breaches the same provision that it previously had, the DPA should increase the standard fine by 50% (see the DPAs’ methodology below).
The ICO mentions that it is more likely to impose a higher fine in case of a failure by the infringer to rectify a problem which was previously identified by the regulator, or to follow previous ICO recommendations. Lastly, for the Latvia DPA, the existence of past breaches counts as an aggravating circumstance when determining the fine, whereas a lack of past offenses does not put the infringer in a more favorable position.
Article 83(2)(f) GDPR:the degree of cooperation with the supervisory authority, in order to remedy the infringement and mitigate the possible adverse effects of the infringement
Under this criterion, the EDPB guidelines invite DPAs to consider whether the entity responded in a particular manner (that was not strictly required by law) to their requests during the investigation phase, in a manner that has significantly limited the impact on individuals’ rights. The Danish DPA’s take on the matter is again very aligned with the EDPB, adding that an admission or confession of the infringement by the infringer should count as a mitigating circumstance.
It should be noted that a refusal to cooperate can, in itself, constitute a breach of the GDPR, as it is an obligation applicable to controllers and processors alike, under Article 31. In this regard, the Danish DPA considers such failure to cooperate as one of the less serious infringements that fall under Article 83(4) GDPR, while the Dutch DPA frames it as one of the gravest. In Chapter 2 below, we analyze how this framing translates into standardized basic amounts for each of both DPAs’ fines.
Article 83(2)(g) GDPR:the categories of personal data affected by the infringement
According to the EDPB, DPAs should carefully look into whether the GDPR infringement at stake affected special categories of data or other particularly sensitive data that could cause damage or distress to individuals. Such sensitive data could include data subjects’ social conditions and personal identification numbers, as stated by the Danish DPA. For the Datatilsynet and the Dutch DPA, unlawful processing of special categories of data counts as one of the gravest infringements under Article 83(5) GDPR, which may lead the former to maximize the basic amount of the fine in a given case.
For the EDPB, it is also important that DPAs understand the format in which the data was compromised: was it identified, identifiable, or subject to technical protections (such as encryption or pseudonymisation)? The ICO intends to issue higher fines in cases involving a high degree of privacy intrusion. With a different focus, the Latvian DPA highlights that a significant number of affected data categories can justify imposing a higher fine, in particular when it comes to children’s data.
Article 83(2)(h) GDPR:the manner in which the infringement became known to the supervisory authority, in particular whether, and if so to what extent, the controller or processor notified the infringement
In this context, DPAs should in principle more critically assess infringements of which they become aware through means other than a notification from the infringer. According to the EDPB, the fact that a breach is uncovered via an investigation, a complaint, an article in the press or an anonymous tip should not aggravate the fine. However, the fact that an infringer actively tries to conceal a breach can increase the amount of the fine set by the DPA in Denmark, according to the latter’s policy.
On the other hand, a notification delivered by the infringer to the DPA to make it aware of an infringement may count as a mitigating circumstance, as stressed by the EDPB. The Latvian DPA’s list of criteria mentions that the more timely and encompassing the notification of the infringer is, the more it will help decrease the amount of the fine.
Article 83(2)(i) GDPR:compliance with previously-ordered measures against the controller or processor concerned with regard to the same subject-matter
The Danish DPA has stressed that it shall assess infringements more severely where it has previously warned the perpetrator that its conduct constituted a violation of data protection law or ordered it to align its practices with legal standards. The Latvian DPA may issue an aggravated fine in case the infringer refused to correct its data processing pursuant to a DPA order.
Article 83(2)(j) GDPR:adherence to approved codes of conduct pursuant to Article 40 or approved certification mechanisms pursuant to Article 42
Both the Danish and the Latvian DPAs mention that adherence to those frameworks could demonstrate the willingness of the infringer to comply with data protection law. In some cases, adherence to codes of conduct or certification mechanisms may even exclude the need of imposing an administrative fine altogether: the EDPB stresses that DPAs may find that enforcement or action taken by monitoring or certification bodies in certain cases is effective, proportionate, and dissuasive enough.
Lastly, it should be noted that DPAs have the power to sanction codes of conduct’s monitoring bodies for a failure to properly monitor and enforce compliance with such codes, under Article 83(4) GDPR. In this respect, the analyzed fining policies show that the Danish DPA views such failure as one of the less serious breaches listed under the provision, while the Dutch DPA frames it as one of the gravest.
Article 83(2)(k) GDPR: any other aggravating or mitigating factor applicable to the circumstances of the case, such as financial benefits gained, or losses avoided, directly or indirectly, from the infringement
The wording of this criterion opens the door for DPAs to consider any other factors in their fine determination exercise, also hinting that the criteria set out under Article 83(2) are not exhaustive. As an example of how to consider the criterion in a specific case, the EDPB guidelines state that the fact that the infringer profited from the conduct “may constitute a strong indication that a fine should be imposed.” The ICO also commits to focus on removing any financial gains obtained from data protection infringements.
In Denmark, this may entail confiscating the profits which were illegally obtained as a result of the data protection breach, or the inclusion of such profits in the amount of the imposed fine. However, the Danish DPA’s policy states that it may be challenging and quite resource-intensive to determine such profits, regardless of the chosen avenue.
Fines must be effective, proportionate and dissuasive: How do DPAs make sure they are as such?
Article 83(1) GDPR requires DPAs to ensure that administrative fines are effective, proportionate, and dissuasive in each individual case. The EDPB specifies that, although this exercise requires a case-by-case assessment, a consistent approach should eventually emerge from DPA enforcement practice and case law.
Regardless of the fact that this criterion shows up first in the text of the GDPR, both the UK, Latvian and Danish DPAs prefer to check their determined fine amounts against those factors only at the end of the process. For example, the Datatilsynet states that a fine that would jeopardize the finances of the infringer and leave it close to bankruptcy could be considered effective and dissuasive, but likely not proportionate. In such circumstances, the DPA may consider whether to impose more moderate payment terms (e.g., deferral of payment) or even to reduce the amount of the fine.
The ICO also considers the infringer’s financial means when deciding on the fine: if the determined fine would cause financial hardship for the infringer, the regulator may reduce the fine. Additionally, the ICO is bound by national law to assess the fine’s broader economic impact, as it must consider the desirability of promoting economic growth. Thus, before issuing a fine and when deciding on its amount, it will consider its economic impact on the wider sector where the infringer is positioned.
With regards to the fine’s effectiveness, proportionality, and dissuasiveness, the Latvian DPA’s list of criteria mentions that the watchdog will have due regard to elements such as the infringer’s profits, number of employees, special status (e.g. as a social enterprise), and its wider role in society.
Article 83(3) GDPR as the fine’s ceiling: Towards a common interpretation?
The provision reads that “if a controller or processor intentionally or negligently, for the same or linked processing operations, infringes several provisions [of the GDPR], the total amount of the administrative fine shall not exceed the amount specified for the gravest infringement”. Seeking to resolve any possible interpretation issues, the EDPB’s guidelines stress that “The occurrence of several different infringements committed together in any particular single case means that the DPA is able to apply the administrative fines at a level which is effective, proportionate and dissuasive within the limit of the gravest infringement.”
Coming up with further clarification, the Danish DPA’s policy states that Article 83(3)’s ceiling should cover both situations where controllers breach different GDPR provisions with a single act, as well as others where controllers breach a single provision multiple times with a single action (e.g. sending unsolicited marketing emails to multiple recipients once). The Latvian DPA adds that, in those cases, all breaches must be considered together and the corresponding administrative fine should be calculated considering the gravest infringement.
This seems to be different from limiting DPAs to sanction infringers only for the gravest among several infringements they have committed, as the EDPB has recently clarified in its binding decision 1/2021 under Article 65(1) GDPR on the Irish DPC’s draft decision against Whatsapp Ireland. In that context, the EDPB stated that “Although the fine itself may not exceed the legal maximum of the highest fining tier, the infringer shall still be explicitly found guilty of having infringed several provisions and these infringements have to be taken into account when assessing the amount of the final fine that is to be imposed” (para. 326).
2. Making fines predictable: A road to harmonizing enforcement standards?
All the European DPAs that have published fining policies in the last two years have tried to pave the way towards a standardization of the assessments that lead to the determination of an administrative fine. This is well demonstrated by the formulas and tables that DPAs have created to guide such a determination process. But are the DPAs’ approaches consistent, in a way that may lead to harmonized enforcement of data protection rules in Europe, so as to avoid forum shopping?
Dutch DPA (AP)
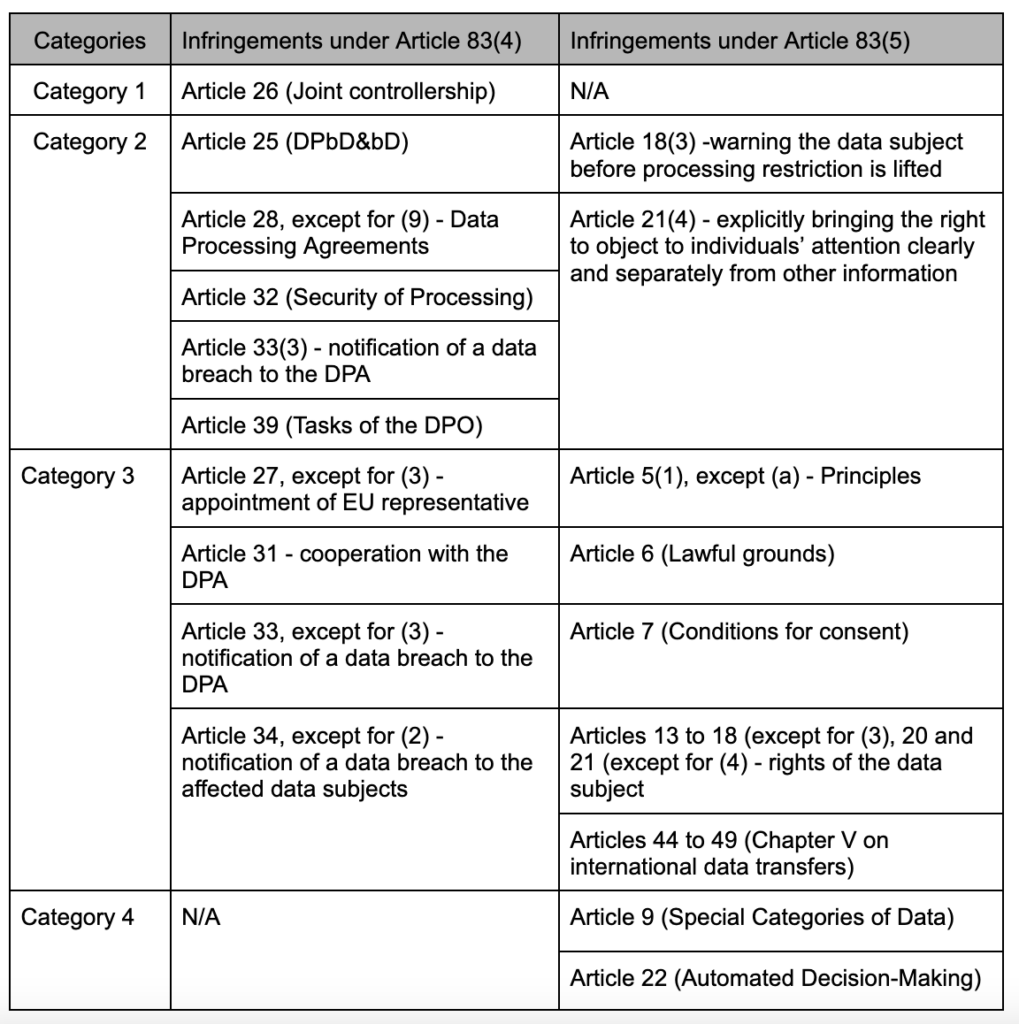
As the first of its kind among EU DPAs’ guidelines, the Dutch DPA’s fining policy is groundbreaking in the way it proposes that the AP should determine the fines it decides to impose for GDPR infringements. It starts by splitting infringements into 4 different categories in accordance with their seriousness, as illustrated below with some examples:
Then, it uses the below table to determine the standard (basic) fine that corresponds to the infringement(s) at stake:
Category 1
Fine range: 0€ to 200.000€
Basic fine: 100.000€
Category 2
Fine range: 120.000€ to 500.000€
Basic fine: 310.000€
Category 3
Fine range: 300.000€ to 750.000€
Basic fine: 525.000€
Category 4
Fine range: 450.000€ to 1.000.000€
Basic fine: 725.000€
To determine the fine’s final amount, the AP uses the basic fine as a starting point and may move it upwards or downwards until the top or bottom of the fine bandwidth for the respective category of infringement. In doing this, the DPA must assess the factors listed under Article 83(2) GDPR, as well as the financial circumstances of the infringer.
However, the DPA may decide to go above or below the bandwidth if it finds that the fine in the default bandwidth would not be appropriate in the specific case. It can then go up to the legal limit of the fine for the respective infringement (10/20M EUR or 2/4% of annual turnover). In case or reduced financial capacity of the infringer, the DPA can choose to go below the immediately lower fine bandwidth when determining the fine.
Danish DPA (Datatilsynet)
First of all, it is important to note that the Danish DPA is one of only two EU DPAs (together with the Estonian DPA) that does not have the legal attributions under its national law to issue administrative fines. It needs to report an infringement of data protection law to the police, along with a determined fine recommendation, so that the infringer is investigated and prosecuted and that a court may ultimately sentence the infringer to pay the fine.
For guiding prosecutors and courts in this regard – which shall also consider the Danish Public Prosecutor’s guide on criminal liability for legal persons -, the Danish DPA thus favors a “standardization” of the levels of fines for specified breaches of data protection law. This should be complemented by a case-by-case assessment, considering the criteria under Article 83(1) to (3) GDPR and the infringer’s ability to pay.
With regards to fines issued against legal persons, the Datatilsynet advises prosecutors to start with determining the fine’s baseline amount, considering the provision of the GDPR which was infringed: it thus separates between infringements leading to 10M EUR/2% of annual turnover fines (first three categories in the table below) and others leading to 20M EUR/4% of annual turnover fines (last three), which we illustrate with some examples:
This division into 6 categories was made by the Danish DPA according to its own assessment of the GDPR provisions at stake, notably of their importance, place in the Regulation and their underlying protection objectives. Categories 1 and 4 are the less serious infringements within their respective provisions. Categories 2 and 5 are more serious infringements and Categories 3 and 6 are the most serious ones.
The “dynamic ceiling” of the fine (2% or 4% of annual turnover) only applies to companies with an annual global (net) turnover – as defined in Article 2(5) of Directive 2013/34/EU – exceeding 3.75M DKK (around 504M EUR). Once the maximum fine in the individual case has been determined, the standard basic amount of the fine may be set as follows:
5% of the maximum amount for infringements falling under Categories 1 and 4
10% of the maximum amount for infringements falling under Categories 2 and 5
20% of the maximum amount for infringements falling under Categories 3 and 6
The basic amount must also consider the size of the breaching company: it should be adjusted in case of SMEs (according to the EU definition). Thus, for the latter, the basic amount of the fine should be adjusted as follows:
Micro-enterprises: down to 0.4% of the standard basic amount
Small enterprises: down to 2% of the standard basic amount
Medium-size enterprises: down to 10% of the standard basic amount
The infringer’s market share should also be taken into account (e.g., an infringement by a company with a low revenue but a significant market share may affect a large number of data subjects).
Once the basic amount has been determined, the Danish DPA recommends the prosecutor to adjust the fine to the criteria set out in Article 83(1) to (3) GDPR – in the manner we have outlined before – and to the infringer’s ability to pay (should the latter so request it).
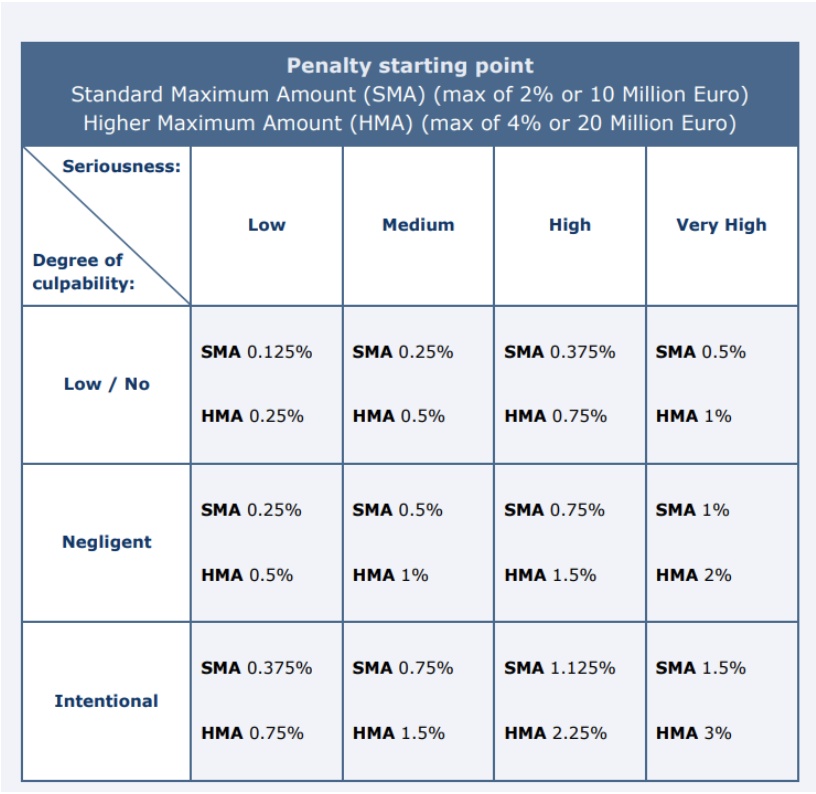
UK DPA (ICO)
The UK’s DPA also proposes to standardize the sums of administrative fines with its own formula and table. Those serve as the basis for calculating fines included in the ICO’s Penalty Notices, but also for the regulator’s preliminary notices of intent (NOI). Through the NOI, the ICO warns the infringer that it intends to issue an administrative fine, laying out the circumstances of the established breaches, the ICO’s investigation findings and the proposed level of penalty, along with its respective rationale. The infringer is allowed to make representations within 21 calendar days of receipt of the NOI, following which the ICO decides whether or not to issue a Penalty Notice.
In its draft Statutory Guidance on Regulatory Action, the ICO discloses that the process of determining the amount of a fine is a multi-step one, which starts with assessing some of the criteria set out in Article 83(2) GDPR – including the infringer’s degree of culpability and the breach’s seriousness -, as well as the infringer’s turnover after review of its accounts. Then, the ICO determines the fine’s starting point as follows:
After that, the ICO considers aggravating and mitigating factors listed under Article 83(2) GDPR to adjust the amount of the fine upwards or downwards within the previously-defined fine band. It then assesses the amount of the fine against the infringer’s financial means, the economic impact of the sanction, and the criteria of effectiveness, proportionality, and dissuasiveness. Lastly, the ICO commits to reduce the amount of the fine in 20% if it is paid within 28 days unless the infringer decides to judicially appeal the fine.
Latvian DPA (DVI)
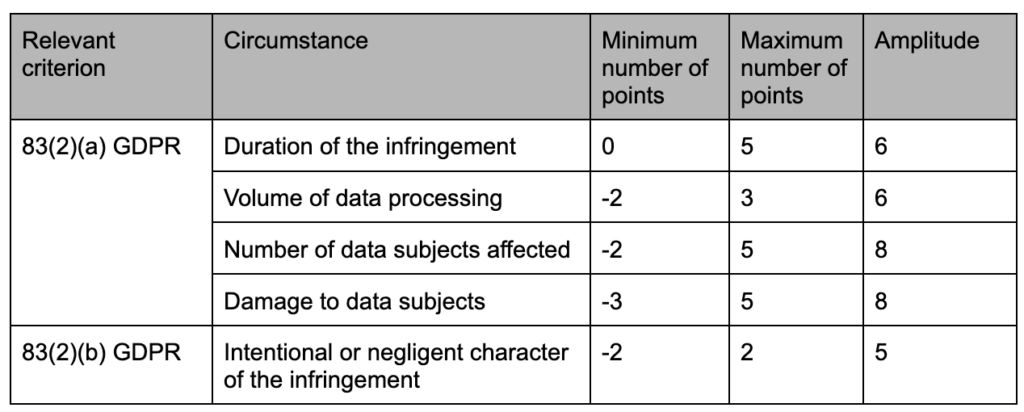
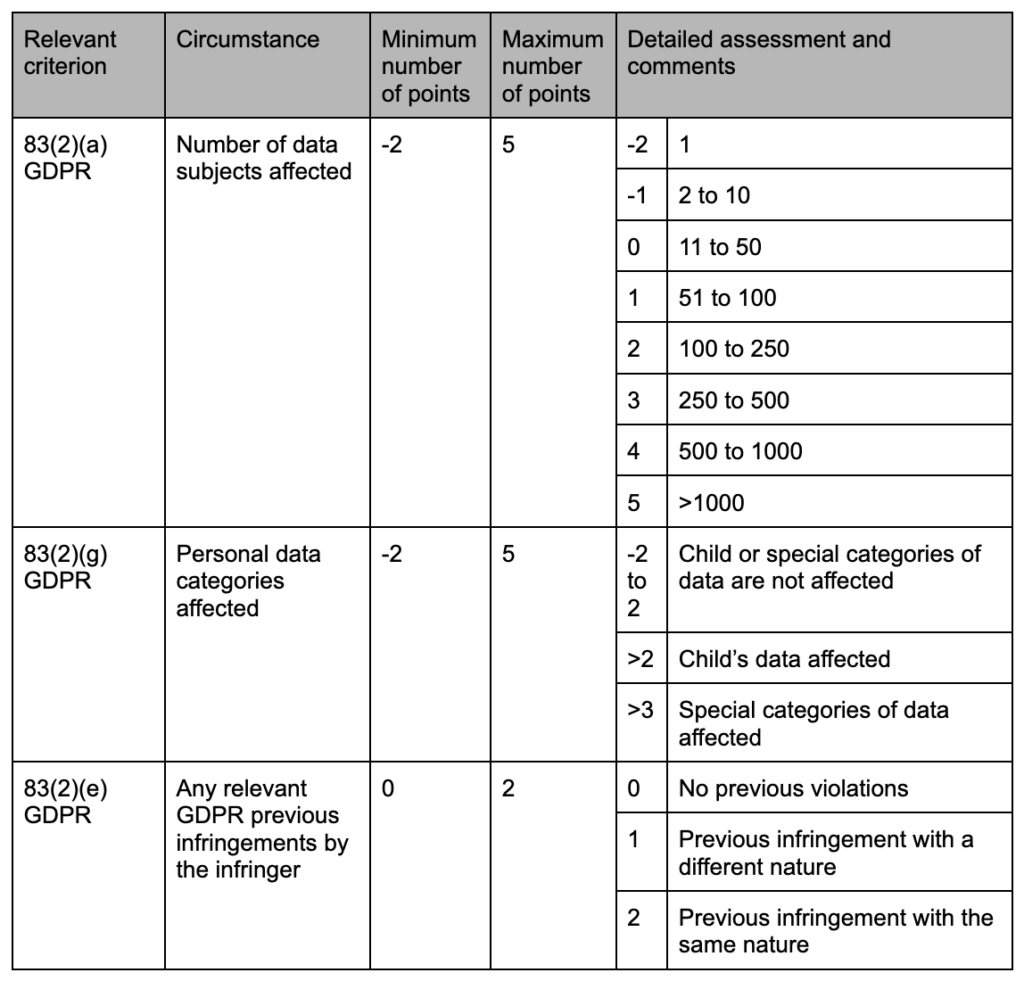
The Latvian DPA’s process for determining the amounts of administrative fines seems to be the most complex, namely because it outlines in a very detailed fashion how the DPA should weigh each of the factors listed under Article 83(2) GDPR in specific cases.
According to the list of criteria published by the DVI in 2021, the DPA starts by determining the infringer’s relevant turnover or income: for individuals, this is the average salary in the country, multiplied by 12; for companies, this is the annual turnover, divided by 365.
Then, the DPA selects the appropriate multiplier, which it will later apply to such turnover or income to obtain the basic amount of the fine. This serves to reflect the gravity of the infringement (low, average, high, very high). To determine the multiplier, the DPA will consider the criteria listed under Article 83(2)(a) to (j), as well as aggravating and mitigating circumstances under Latvian law. This is done in a standardized fashion, by resorting to a table, of which we provide some excerpts below:
With regards to some criteria, the DVI prefers to detail with added precision how it will apply its points attribution system, as the excerpt below demonstrates:
These tables illustrate how, for the Latvian DPA, not all criteria are inherently equally important when assessing data protection breaches, as each criterion must be given an appropriate weight. Such tables provide clarity on the way the criteria are weighed in by the DPA in cases of GDPR infringements.
Then, the DVI multiplies the relevant infringing company’s daily turnover or the individual’s annual income by a multiplier to obtain the basic amount of the administrative fine. To determine such a multiplier, the DPA considers whether there was a procedural or material breach of the GDPR, i.e., one that is covered by Article 83(4) or (5), respectively. In this regard, it uses different tables to determine the multipliers for procedural and material infringements. In case more than one procedural or material breach occurred, the DVI limits the amount of the fine in line with Article 83(3) GDPR. The sum obtained after this calculation is then checked by the DPA against the criteria laid out in Article 83(1) GDPR and the fine ceilings set out in Article 83(4) or (5) – depending on the nature of the infringement – to reach a final amount for the fine.
A Comparative Analysis of Methodologies for Fine Calculation
As we have seen, DPAs who have published their policies with regards to administrative fines under the GDPR diverge substantially on a number of matters. These range from the importance they attribute to given GDPR infringements, to the weight they give to certain criteria that the GDPR prescribes for the determination of fines, under Article 83.
Crucially, the standard fine amounts that DPAs have published in their policies, considering the nature of the infringement at stake and the contribution of the elements listed under Article 83(2) GDPR, also have noteworthy differences:
The Dutch DPA’s standard fine for the most serious infringements (e.g., unlawful automated decision-making) is set at 725.000 EUR;
The Danish DPA establishes a standard fine ceiling for the most serious infringements of 20% of the maximum fine. For companies with an annual global turnover below 504M EUR, this amounts to 4M EUR;
For intentional infringements falling under Article 83(5) GDPR and having a very high degree of seriousness, the ICO establishes that the basic amount of the fine should correspond to 3% of the maximum value defined by law. For companies with an annual global turnover below 504M EUR, this amounts to 600.000 EUR;
Under the Latvian DPA fining framework, a company with a 504M EUR annual turnover could be bound to pay a maximum standard fine of 17.9M EUR for a “material” GDPR infringement (i.e., one that falls under Article 83(5) GDPR).
However, it is clear that this apparent gap between the DPAs’ standard fines can be closed on a case-by-case basis through consideration of additional factors when determining the final amount of administrative fines. Such elements include the infringer’s ability to pay, financial situation, annual turnover, status, societal role, and any detected recidivism.
There may be questions around the extent to which DPAs, in practice, substantially deviate from the fine bandwidths that their fining policies establish to make their fines effective, proportionate, and dissuasive. Those could only be answered through benchmarking each of the DPA’s sanctioning history under the GDPR. This is not the goal of the blogpost, which rather focuses on comparing how DPAs plan to structure their approach to fining in individual cases.
While we could not detect significant alignment in such approaches – despite the common criteria laid down in Article 83 GDPR -, it is possible that the upcoming EDPB guidance on the calculation of administrative fines could lay the ground for more harmonized sanctioning practices in the EU.
Further reading:
FPF Report: “Insights into the future of data protection enforcement: Regulatory strategies of European Data Protection Authorities for 2021-2022”
EDPS upcoming conference: “The Future of Data Protection: Effective Enforcement in the Digital World”
Access Now’s 2021 Report: “Three Years Under the GDPR: An implementation progress report”
FPF Report: A Look into DPA Strategies in the African Continent
Today, the Future of Privacy Forum released a Report looking into the Strategic Plans for the coming years of seven African Data Protection Authorities (DPAs). The Report gives insight into the activity and plans of DPAs from Kenya, Nigeria, South Africa, Benin, Mauritius, Côte d’Ivoire, and Burkina Faso. It also relies on research conducted across several other African jurisdictions who have adopted data protection laws in recent years but have not yet established a DPA, or whose DPAs have not published strategic documents in the past two to three years.
Since the 2001 enactment of Africa’s first data protection law by Cape Verde, many other African countries have followed suit. Two decades later, 33 African countries boast comprehensive data protection laws. This growth in legislation has received well-deserved attention as the continent continues to articulate its position on privacy and data protection matters.
Until now, most publications on the state of data protection in Africa have focused on the processes of creating and enacting comprehensive laws. As a result, other important aspects of the data protection machinery including implementation and enforcement have received little attention. This has hampered efforts to obtain a comprehensive picture on the state of data protection in Africa. Particularly, despite their important role in shaping data protection discourse on the continent, the activities of the Data Protection Authorities (DPAs) entrusted with implementing the laws are not well known or documented. Even with comprehensive data protection laws, not all countries have operational DPAs due to factors such as lack of political will, competing priorities, and financial constraints.
This report seeks to address this gap and shed light on notable activities of established DPAs in select African countries. It analyzes various DPA strategy documents including the annual reports and national data protection plans from seven key jurisdictions and provides a brief overview of the key developments and trends in administrative enforcement. These documents provide important insights into the priority areas of DPAs as well as their current status. While there is significant variation between the seven countries’ plans, key findings indicate common themes.
FPF Weighs in on Automated Decisionmaking, Purpose Limitation, and Global Opt-Outs for California Stakeholder Sessions
This week, Future of Privacy Forum policy experts provided testimony in California public Stakeholder Sessions to provide independent policy recommendations for the California Privacy Protection Agency (CPPA). The Agency heard from a variety of speakers and members of the public, on a broad range of issues relevant to forthcoming rulemaking on the California Privacy Rights Act (CPRA).
Specifically, FPF weighed in on automated decisionmaking (ADM), purpose limitation, and global opt-out preference signals. As a non-profit dedicated to advancing privacy leadership and scholarship, FPF typically weighs in with regulators when we identify opportunities to support meaningful privacy protections and principled business practices with respect to emerging and socially beneficial technologies. In California, the 5th largest economy in the world, the newly established California Privacy Protection Agency is tasked with setting standards that will impact data flows across the United States and globally for years to come.
Automated Decision-making (ADM). The subject of “automated decision-making” (ADM) was discussed on Wednesday, May 4th. Although the California Privacy Rights Act does not provide specific statutory rights around ADM technologies, the Agency is tasked with rulemaking to elaborate on how the law’s individual access and opt-out rights should be interpreted with respect to profiling and ADM.
FPF’s Policy Counsel Tatiana Rice raised the following issues for the Agency on automated decision-making:
Consumers’ rights of access for ADM should center on systems that directly and meaningfully impact individuals’ lives, such as those that affect financial opportunities, housing, or employment. The standard “legal or similarly significant effects” has the benefit of capturing high-risk use cases, while encouraging interoperability with global frameworks, such as existing guidance and case law under Article 22 of the General Data Protection Regulation (GDPR).
Explainability is a crucial principle for developing trustworthy automated systems, and information about ADM should be meaningful and understandable to the average consumer. As a starting point, the Agency should draw from the National Institute of Science and Technology’s Principles for Explainable Artificial Intelligence, which describe ways in which explainable systems should (1) provide an explanation; (2) be understandable to its’ intended end-users; (3) be accurate; and (4) operate within its knowledge limits, or the conditions for which it was designed.
All consumer rights of access should be inclusive and reflective of California’s diverse population, including those who are non-English speaking, differently abled, and lack consistent access to broadband.
Purpose Limitation. The California Privacy Rights Act requires businesses to disclose the purposes for which the personal information they collect will be used, and prohibits them from collecting additional categories of personal information, or using the personal information collected, for additional purposes that are “incompatible with the disclosed purpose for which the personal information was collected,” without giving additional notice. 1798.100(a)(1). As a general business obligation, this provision reflects the principle of “purpose limitation” in the Fair Information Practices (FIPs), and was discussed on Thursday, May 5th.
FPF’s Director of Legislative Research & Analysis Stacey Gray raised the following issues for the Agency on purpose limitation:
Purpose limitation is a fundamental principle of the Fair Information Practices (FIPs) that serves to protect individual and societal privacy interests without relying solely on individual consent management – as such, we encourage the Agency to ensure that it is respected and provide robust guidance on its provisions.
“Incompatible” secondary uses of information should be interpreted strictly and include those not reasonably expected by the average person – for example, invasive profiling unrelated to providing the product or service requested by the consumer; training high-risk algorithmic systems such as facial recognition; or voluntary sharing with law enforcement.
“Compatible” secondary uses of information should include scientific, historical, or archival research in the public interest, when subjected to appropriate privacy and security safeguards.
Opt-out preference signals. Finally, the California Privacy Rights Act envisions a new class of “opt-out preference signals,” sent by browser plug-ins and similar tools to convey an individual’s request to opt-out of certain data processing. As an emerging feature of several U.S. state privacy laws, there are open technical and policy questions for how to ensure that such ‘global’ signals succeed in lowering the burdens of individual privacy self-management.
FPF’s Senior Counsel Keir Lamont provided the following comments to the Agency on global opt-out preference signals on Thursday, May 5th:
Rulemaking should address the primary practical consideration for opt-out preference signals, which is how to address conflicts between different signals or separate, business-specific privacy settings.
The Agency should clarify the extent to which opt-out preference signals can be expected to, and should, apply to separate sets of personal data collected from different sources and in different contexts; and
The Agency should engage with regulators in other states, including Colorado and Connecticut, to establish a multistakeholder process to approve qualifying preference signals as they are developed and refined over time.
Following the public Stakeholder Sessions this week, the Agency is expected to publish draft regulations as soon as Summer or Fall 2022, which will then be available for public comments. Although the timeline could be delayed, the Agency’s goal is to finalize regulations prior to the CPRA’s effective date of January 1, 2023.
FPF Statement on Draft Roe v. Wade Decision
May 3, 2022— Privacy is a fundamental, deeply entrenched right in the United States and around the world. As technology evolves, individuals need more privacy protections, not fewer. This is particularly true when data and decisions about health and autonomy are at stake. Moreover, traditionally underserved communities need courts and lawmakers to elevate their voices, not drown them out. The draft decision overturning Roe v. Wade would reduce privacy protections at a time when individuals and lawmakers are demanding more.
Party of Five: Connecticut Poised to Pass Fifth U.S. State Privacy Law, Improving Upon Virginia, Colorado
This week, the Connecticut legislature passed Senate Bill 6, an ‘Act Concerning Personal Data Privacy and Online Monitoring.’ If SB 6 is enacted by Governor Lamont, Connecticut will follow California, Virginia, Colorado, and Utah as the fifth U.S. state to adopt a baseline regime for the governance of personal data. The law would come into effect on July 1, 2023.
Connecticut’s privacy bill goes beyond existing state privacy laws by directly limiting the use of facial recognition technology, establishing default protections for adolescent data, and strengthening consumer choice, including through requiring recognition of many global opt-out signals. Nevertheless, a federal privacy law remains necessary to ensure that all Americans are guaranteed strong, baseline protections for the processing of their personal information.
-Keir Lamont, Senior Counsel, Future of Privacy Forum
While SB 6 is similar to laws recently passed in Colorado and Virginia, it contains several significant expansions of consumer privacy rights. In addition to core requirements to obtain affirmative consent to process sensitive personal information; consumer rights to opt out of targeted advertising, data sales, and certain profiling decisions; and obligations for businesses to conduct risk assessments and meet purpose specification and data minimization standards, the bill includes:
Clear limits on facial recognition technology: SB 6 would designate biometric data generated from photographs or videos for the unique purpose of identifying a specific individual as a category of sensitive information subject to affirmative consent requirements. In contrast, other recently adopted comprehensive state privacy laws either do not require consent for facial recognition (California), do not define the term “biometric data” (Colorado), or contain ambiguous language (Virginia).
Default protections for adolescent data: Connecticut would join California as the only states to require consent for the monetization of the data of children aged 13 to 15.
Global opt-out signals and stronger consumer opt-out rights: SB 6 would strengthen individual controls by limiting the circumstances where businesses may reject consumer requests to opt out of data sales, targeted advertising, and profiling. Connecticut would also join Colorado as the only state laws to clearly, explicitly require the recognition of ‘global’ signals exercising these opt-out rights.
Explicit right to revoke consent: SB 6 goes beyond other state privacy laws by explicitly requiring companies to provide an easy-to-use mechanism allowing consumers to revoke consent for certain high-risk processing of personal data.
Like other state privacy laws, enforcement of SB 6 would be left to the exclusive discretion of the state Attorney General. However, the bill does not provide for future rulemaking, which may limit the ability of SB 6 to adapt to emerging technologies and business practices, and could prevent harmonization with other state approaches on complicated multi-jurisdictional compliance topics, such as global opt-out preference signals. Finally, along with the much weaker Utah Consumer Privacy Act enacted earlier this year, Connecticut’s SB 6 appears to solidify a trend of emerging state privacy laws iterating on the Virginia-Colorado legislative framework, rather than following the narrower regulatory model under development in California.
FPF New Resource Takes the Guesswork out of Buying Privacy Tech
A new FPF resource helps buyers determine which privacy tools are the most appropriate for their business needs. The Privacy Tech Buyer Framework is a step-by-step tool that provides guidance on buying the best privacy technology through three phases that include simplified steps and case studies.
Navigating the privacy tech acquisition process can be tricky given an increase in privacy tools and services available to businesses.
Understanding your achievable outcomes for your business is the crucial first step in the privacy tech acquisition process. Outcomes may vary for different businesses, and differ between stakeholders in an organization. Phase 1 of the Framework takes you through several categories of business outcomes that can be achieved with privacy technologies.
Phase 2: Privacy Tech Product Categories
Once you identify the business outcomes you want to achieve, the next step in the process is matching business outcomes to categories of privacy technology products. In Phase 2, the Framework outlines several categories of privacy tech products, drawing from the U.S. National Institute of Standards and Technology (NIST)’s Privacy Framework.
Phase 3: Business-Level Tools and Services
In Phase 3 of the Framework, business-level tools and services are separated into categories based on their functionality. The five main categories include: Identification, Governance, Control, Protection, and Communication. Each category contains tools and services organized by their functionality, for example, Protection includes data security, protective technology, and more. Identifying which categories of functions these privacy technologies fall into will help you select the business-level tools and services that best suit your business needs.
Below is just one of several Framework case studies that illustrate hypothetical scenarios in which you might use this to move from a general business outcome towards a specific buy decision for your business.
CASE STUDY: Company Product Development
A company is developing a product and wants to have the right privacy safeguards in place.
In Phase 1, led by the CIO, the company identified one business outcome; data availability and movability. In Phase 2, the Buyer chose the category of Protection to ensure that personal data is excluded from product development while maintaining the ability to provide useful data to users. The Buyer then selected disassociated processing as their business-level tool in Phase 3, with the intention of removing directly identifying information and using technical privacy modes to ensure transformations minimize exposure.
The Privacy Tech Buyer Framework is a gap-filling document meant to aid buyers in identifying what tools and services are available to help their businesses responsibly and legally use personal information to meet business needs and achieve business outcomes. The ultimate aim of the framework is to simplify and clarify the buyer process, making it easier for users to determine which privacy tools and services they should purchase from vendors.
What the Biden Executive Order on Digital Assets Means for Privacy
Author: Dale Rappaneau
Dale Rappaneau is a policy intern at the Future of Privacy Forum and a 3L at the University of Maine School of Law.
On March 9, the Biden Administration issued an Executive Order on “Ensuring Responsible Developments of Digital Assets” (“the Order”), published together with an explanatory Fact Sheet. The Order states that the growing adoption of digital assets throughout the economy and inconsistent controls to mitigate their risks necessitates a new governmental approach to regulating digital assets.
The Order outlines a whole-of-government approach to address a wide range of technological frameworks, including blockchain protocols and centralized systems. The Order frames this approach as an important step toward safeguarding consumers and businesses from illicit activities and potential privacy harms involving digital assets. In particular, it calls for a list of federal agencies and regulators to assess digital assets, consider future action, and ultimately provide reports recommending how to achieve the Order’s numerous policy goals. The Order recognizes the importance of incorporating data and privacy protections into this approach, which indicates that the Administration is actively considering the privacy risks associated with digital assets.
1. Covered Technologies
Definitions
Digital Assets – The Order defines digital assets broadly, including cryptocurrencies, stablecoins, and all central bank digital currencies (CBDCs), regardless of the technology used. The term also refers to any other representations of value or financial instrument issued or represented in a digital form through the use of distributed ledger technology relying on cryptography, such as a blockchain protocol.
CBDC – The Order defines a Central Bank Digital Currency (“CBDC”) as digital money that is a direct liability of the central bank, not of a commercial bank. This definition aligns with the recent Federal Reserve Board CBDC report. A U.S. CBDC could support a faster and more modernized financial system, but it would also raise important policy questions including how it would affect the current rules and regulations of the U.S. financial sector.
Cryptocurrencies – These are digital assets that may operate as a medium of exchange and are recorded through distributed ledger technologies that rely on cryptography. This definition is notable because blockchain is often mistaken as the only form of distributed ledger technology, leading some to believe that all cryptocurrencies require a blockchain. However, the Order defines cryptocurrencies by reference to distributed ledger technology – not blockchain – and seems to cover both mainstream cryptocurrencies utilizing a blockchain (e.g., bitcoin or Ether) and alternative cryptocurrencies built on distributed ledger technology without a blockchain (e.g., IOTA).
Stablecoins – The Order recognizes stablecoins as a category of cryptocurrencies featuring mechanisms aimed at maintaining a stable value. As reported by relevant agencies, stablecoin arrangements may utilize distributed or centralized ledger technology.
Implications of Covered Technologies
From a technical perspective, distributed ledger technologies such as blockchain stand in stark contrast to centralized systems. Blockchain protocols, for example, allow users to conduct financial transactions on a peer-to-peer level, without requiring oversight from the private sector or government. Centralized ledger technology, as used by most credit cards and banks, typically requires a private sector or government actor to facilitate financial transactions. In this environment, the data flows through the actor, who carries obligations to monitor and protect the data.
Despite the technical differences between these approaches, the Order appears to group these very different financial transaction systems into the single umbrella term of digital assets. It does this by including within the scope of the definition of digital assets all CBDCs, even ones utilizing centralized ledger technology, and other assets using distributed ledger technology. This homogenization of technological concepts may indicate that the Administration is seeking a uniform regulatory approach to these technologies.
2. Privacy Considerations of the EO
Section 2 of the Order states the principal policy objectives with respect to digital assets, which include: exploring a U.S. CBDC; ensuring responsible development and use of digital assets and their underlying ledger technologies; and mitigating finance and national security risks posed by the illicit use of digital assets.
Notably, the Administration uses the word “privacy” five times in this section, declaring that digital assets should maintain privacy, shield against arbitrary or unlawful surveillance, and incorporate privacy protections into their architecture. The need to ensure that digital assets preserve privacy raises notable, albeit different, implications for both centralized and decentralized technologies.
Privacy Implications of a United States CBDC
The Order places the highest urgency on developing and deploying a U.S. CBDC, which must be designed to include privacy protections. The Order states that a United States CBDC would be the liability of the Federal Reserve, which is currently experimenting with a number of CBDC system designs, including centralized and decentralized ledger technologies, as well as alternative technologies. Although the Federal Reserve has not chosen a particular system, the monetary authority has listed numerous privacy-related characteristics that should be incorporated into a United States CBDC regardless of the technology used.
First, the Federal Reserve recognizes that a CBDC would generate data about users’ financial transactions in the same ways that commercial banks and nonbanks do today. This may include a user’s name, email address, physical address, know-your-customer (KYC) data, and more. Depending on the design chosen for the CBDC, this data may be centralized under the control of a single entity or distributed across ledgers held by multiple entities or users.
Second, because of the robust rules designed to combat money laundering and financing of terrorism, a CBDC would need to allow intermediaries to verify the identity of the person accessing CBDC, just as banks and financial institutions currently do so. For this reason, the Federal Reserve states that a CBDC would need to safeguard an individual’s privacy while deterring criminal activity.
This intersection between consumer privacy and the transparency needed to monitor criminal activity gets to the heart of the Order. On one hand, a United States CBDC would provide certain data security and privacy protections for consumers under the current rules and regulations imposed on financial institutions. The Gramm-Leach-Bliley Act (GLBA), for example, includes privacy and data security provisions that regulate the collection, use, protection, and disclosure of nonpublic personal information by financial institutions (15 U.S.C.A. §§ 6801 to 6809). But on the other hand, the CBDC would likely require the Federal Reserve, or entrusted intermediaries, to monitor and verify the identity of users to reduce the likelihood of illicit transactions.
It is unclear whether current rules and regulations would apply if the CBDC utilizes distributed ledger technology, given that they typically establish scope via definitions of applicable entities using particular data. Because users (and not financial institutions) hold copies of the data ledger under distributed ledger technology systems, pre-existing privacy laws may fail to cover large amounts of data processing and provide adequate safeguards to consumers. In addition, as the next section suggests, it is unclear how monitoring and verification would occur under a CBDC that uses distributed ledger technology. This raises further questions in how policymakers can navigate the intersection of privacy and transaction monitoring.
Privacy Implications of Distributed Ledger Technologies
Distributed ledger technologies often attempt to create an environment where users do not have to reveal their personal information. Transactions under these systems typically do not filter through a singular entity such as the Federal Reserve, but instead happen on a peer-to-peer level, with users directly exchanging digital assets without third-party oversight. In this environment, users can complete transactions utilizing hashed identifiers rather than their own information, and these transactions usually occur without the supervision of a private or government entity. Together, the use of hashed identifiers and lack of supervision creates a digital environment ripe with identity-shielding protections.
However, experts recognize that distributed ledger technologies also create a multitude of financial risks. If users can conduct transactions on a peer-to-peer level without supervision or revealing their identity, they can more easily conduct illicit activities, including money laundering, terror funding, and human and drug trafficking.
The Order acknowledges these benefits and risks. The Fact Sheet prioritizes privacy protections and efforts to combat criminal activities, which indicates that the Order seeks to emphasize the privacy-preserving aspects of new distributed ledger technologies while finding ways to restrict illicit financial activity. Such an emphasis may represent an enhanced governmental effort to address criminal activities in the digital asset landscape while avoiding measures that would create risks to privacy and data protection.
3. Future Action: Privacy and Law Enforcement Equities
The Order’s repeated emphasis on privacy seems to align with the Biden Administration’s current focus on prioritizing privacy and data protection rulemaking. The Order acknowledges both necessary safeguards to combat illicit activities and the need to embed privacy protections in the regulation of digital assets.
The U.S. Department of the Treasury and the Federal Reserve have articulated concerns regarding how bad actors exploit distributed ledger technologies for illicit purposes, and those agencies will likely make recommendations to strengthen government oversight and supervision capabilities. However, the Order’s emphasis on privacy seems to indicate that the Administration wants to ensure privacy protections while also enabling traceability to monitor users, verify identities, and investigate illicit activities.
The question is, will the Administration find a way to preserve the privacy protections of centralized and distributed ledger technology, while also promoting the efficacy of monitoring illicit activities? That answer will likely come once agencies and regulators start providing reports that recommend steps to achieve the Order’s goals. Until then, the answer remains unknown, and entities utilizing cryptocurrencies or other digital assets should stay aware of a possible shift in how the Federal Government regulates the digital asset landscape.
FPF Launches Infographics in Chinese
As FPF’s work expands to include an international audience, we are pleased to relaunch FPF’s popular infographics in various languages. Because conversations around data protection have become more global, the need for high-quality information and new forms of communication in different languages continues to increase.
The infographics translation project aims to help FPF provide a more inclusive and diverse platform for stakeholders to engage with colleagues and experts across the world and to better navigate the most complex issues and developments in data protection. Previously, the Israel Tech Policy Institute (ITPI) translated some FPF infographics into Hebrew, an effort that provided the groundwork for FPF to target other languages and regions around the world.
The Chinese translation of these infographics was led by Nanda Min Htin and Hunter Dorwart. FPF APAC has translated three infographics into Chinese: Data and the Connected Car, Data De-identification, and Smart Cities.
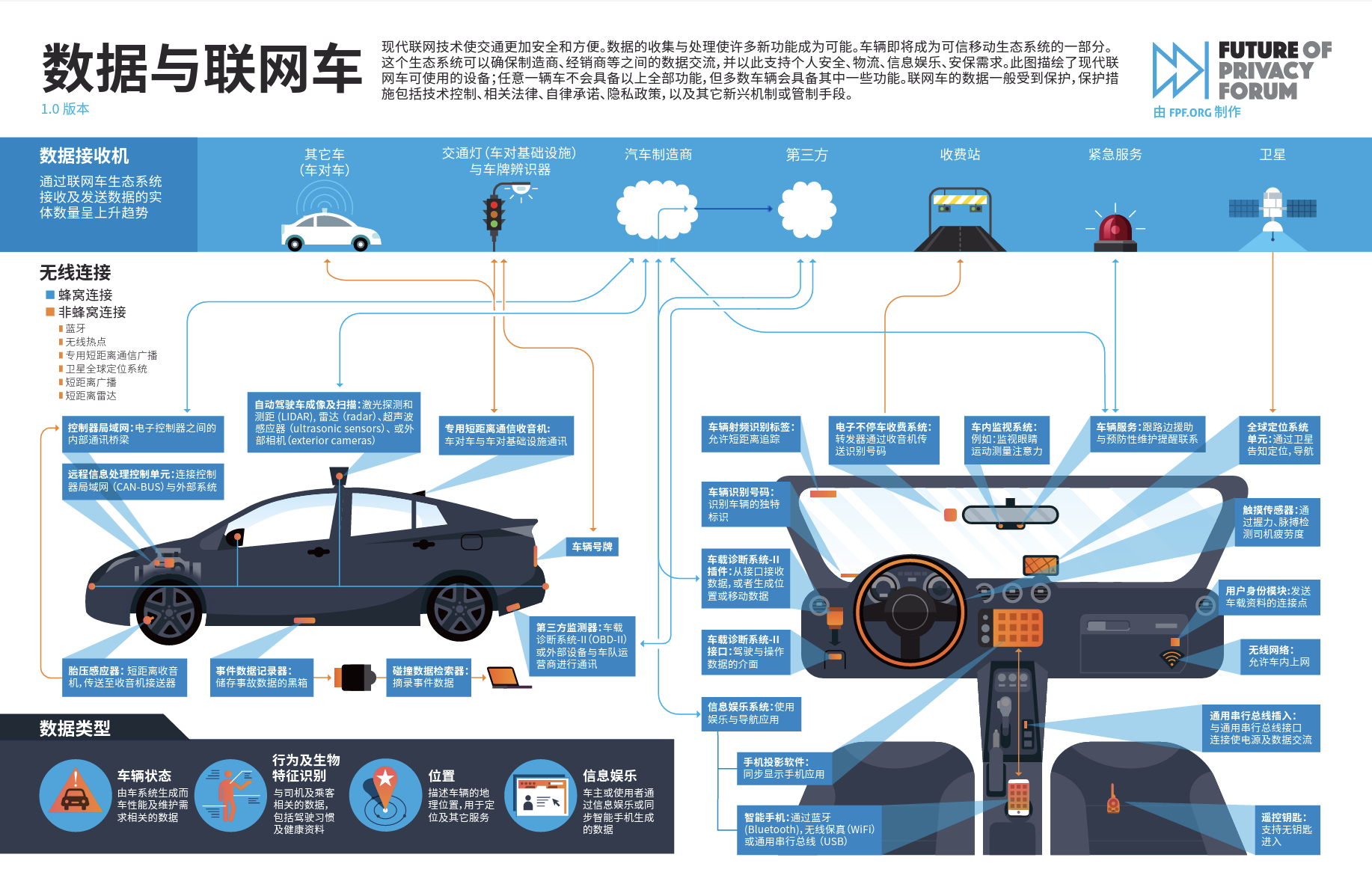
The infographic, “Data and the Connected Car,” describes the core data-generating devices and data flows in today’s connected vehicles. The infographic aims to help consumers, businesses, and regulators understand the emerging data ecosystems that underlie this incredibly dynamic and complex industry.
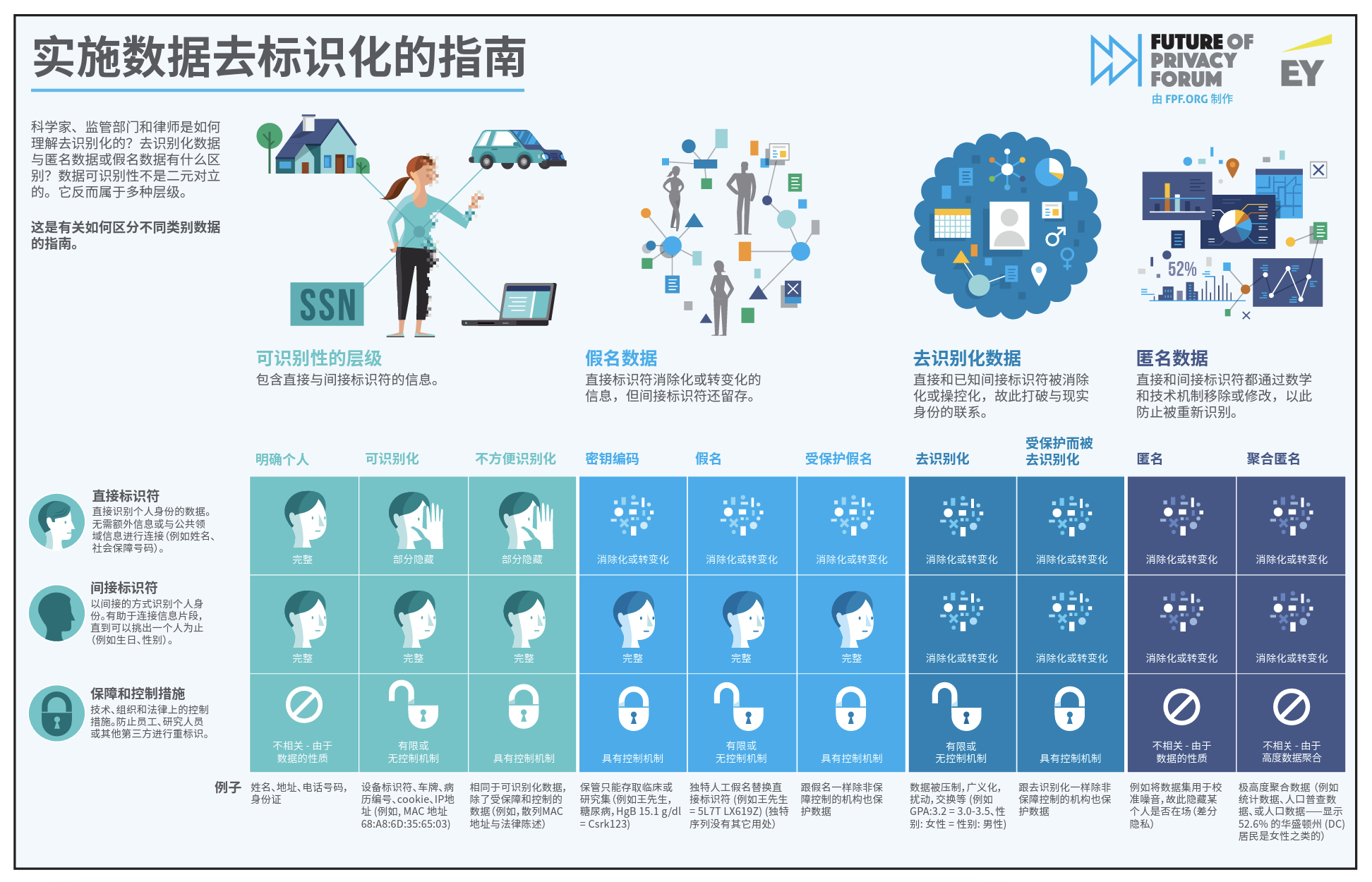
The Data De-Identification infographic highlights complex issues around what constitutes personal information, the scope and possibility of de-identification, and divergences in approaches to the categories of de-identification. This infographic aims to provide stakeholders with an overview of various concepts, methods, and practical examples of de-identification.
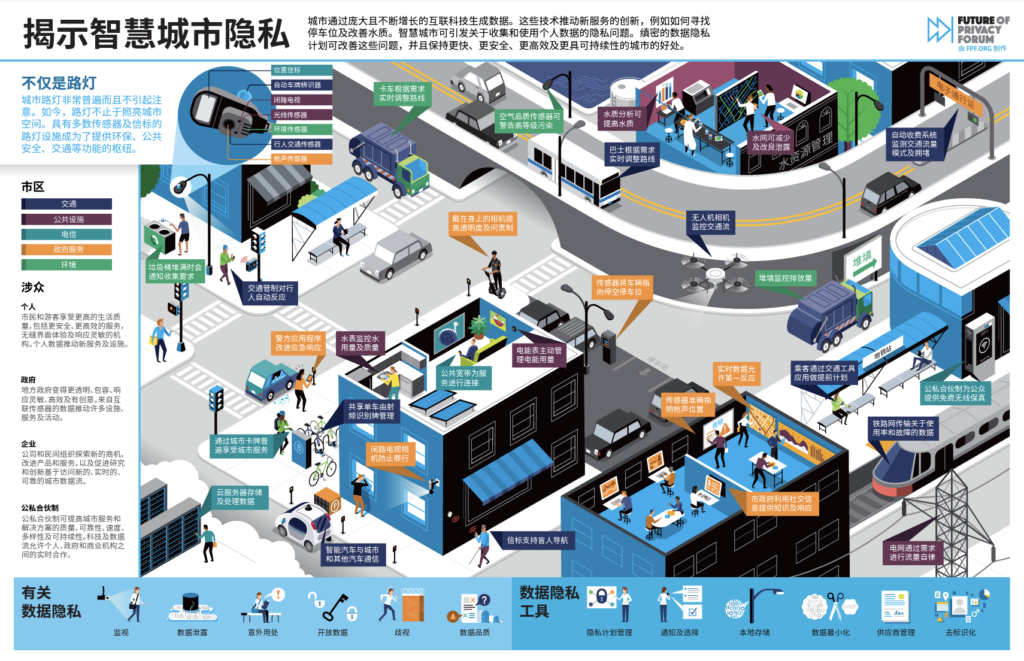
This infographic–Shedding Light on Smart City Privacy–is meant to help citizens, companies, and other stakeholders understand the technologies that create and facilitate smart city and smart community projects. It highlights the wide range of connected technologies and services in today’s cities and provides important context to these new technologies and services, particularly the privacy concerns emanating from this complex ecosystem.
Comparative Look at Models of Data Protection – Series of Webinars Led by the Israel Tech Policy Institute (ITPI)
Authors: Kavisha Patel and Lee Matheson
Kavisha Patel is a current student at Georgetown Law and an FPF Global Privacy Intern.
As a result of Israel’s recently proposed comprehensive privacy law update, the Protection of Privacy Bill, the Israel Tech Policy Institute led a series of three webinars in February 2022 discussing comparative models of data protection around the world. Organized by ITPI Senior Fellow Adv. Rivki Dvash, the webinars aimed to bring together practitioners and experts in the data protection field to explain their perspectives on existing arrangements in various countries with the goal of enriching the ongoing discussion in Israel.
The first webinar, “Legal Bases for Data Processing”, took place on February 9, 2022. The panel for this webinar included Dr. Yaacov Lozowick, Historian, Israel’s Previous Chief Archivist, Lecturer at Bar-Ilan University; Dr. Gabriela Zanfir-Fortuna, Vice President for Global Privacy at The Future of Privacy Forum; Dr. Clarisse Girot, Managing Director for Asia Pacific at the Future of Privacy Forum; and Dr. Bruno Bioni, Director-Founder of Data Privacy Brazil.
The second webinar, “Data Protection Authorities’ Powers of Enforcement and Sanctions”, took place on February 16, 2022. Panelists for this webinar included Adv. Reuven Eidelman, Head of Legal Department at the Israeli Privacy Protection Authority at the Ministry of Justice; Adv. Florence Raynal, Head of the International and European Affairs Department of the CNIL; J.D. Stacey Gray, Director of Legislative Research and Analysis at the Future of Privacy Forum; and Adv. Lore Leitner, Partner at Goodwin in London, UK.
The third webinar, “Civil and Class Actions Under Privacy and Data Protection Law Frameworks in Israel, the EU and the US”, took place on February 23, 2022. Panelists for this webinar included Professor Peter Swire, Professor of Law and Expert on Privacy and Cybersecurity, Georgia Tech University; Sebastião Barros Vale, EU Policy Fellow at the Future of Privacy Forum; and Professor Assaf Hamdani, Professor of Law at Tel Aviv University.
The webinars were moderated by Adv. Limor Shmerling Magazanik, Managing Director of the Israel Tech Policy Institute. Below is a summary of the main points and insights from the series. The recordings of the three sessions are available here.
First Webinar: Legal Bases for Data Processing
Key Insights:
The purpose of personal data protection law is not to completely prohibit the processing of personal information, but to establish a robust means of protection for the processing of personal data so that it will be used in a manner that respects the rights and freedoms of individuals.
There is no hierarchy between the various legal bases for processing under the GDPR, which include consent, contract, legal obligations, vital interests, public interests, and legitimate interests.
Under the GDPR, the legitimate interest basis for lawful processing of data is complex and nuanced. Legitimate interests may only serve as a lawful ground for data processing if those interests are not overridden by the data subjects’ rights, interests and freedoms, requiring a balancing test between the two that must be conducted by the data controller on a case-by-case basis for each processing activity.
Under the Brazilian LGDP, the legitimate interest basis for legal processing of data is similarly subject to principles of necessity, the balancing of rights and freedoms, and sufficient safeguards.
In APAC jurisdictions, the landscape for lawful grounds of data processing are very fragmented, which makes it difficult for cross-border businesses to comply on a systemic basis.
Some controllers interpret the laws and regulations incorrectly, making it very important for regulators to clarify their interpretations.
In practice, due to divergences between countries, many businesses have been building their compliance programs focused on consent, as consent is often a common denominator between data protection regimes as a legal basis for data processing.
Recent recognition of legitimate interests as a lawful ground for data processing in the Singaporean PDPA could influence other APAC countries to do the same. This can be a substitute for consent-based lawful processing.
In the Israeli context, the same laws dictate how contemporary data and archival data is protected. Dr. Lozowick argues that this should change as legitimate interests for scientific and historical research arise when data is dated enough that it is not reflective of current reality.
Meaningful consent (i.e., whether consent is given voluntarily, the extent to which consent is based on understanding, etc.) continues to be a core issue in data protection. As a result, strengthening this basis for data processing is important. This could include increasing transparency through UX/UI design and consideration of users’ vulnerabilities and degrees of literacy.
Any legal system dealing with the crucial issues of data protection today should consider the impact of the passage of time on data privacy interests. Some propose that contemporary data protection arrangements should consider the passage of time as a criterion that reduces the interest in the protection of personal information and strengthens the interest in making information accessible to researchers for the benefit of the public.
Second Webinar: Data Protection Authorities’ Power of Enforcement and Sanctions
Key Insights:
While the GDPR itself does not impose criminal sanctions, some states have added a criminal provision to local law. Even in these countries, criminal enforcement will not be carried out by the national Data Protection Authority (DPA). The latter must pass the matter to a prosecutor, but these rarely take such cases due to limited resources. Nevertheless, there will be criminal enforcement by target authorities in related areas, such as wiretapping and computer hacking.
The GDPR allows for a variety of administrative sanctions, in addition to financial sanctions. The enforcement tool used is tailored to the specific violation.
Each EU DPA determines financial sanctions differently, resulting in a high variance between the fines imposed. Some may not even have the power to issue them on their own: in France, there is a separate body authorized to impose financial sanctions, which is not subordinate to the national DPA (CNIL).
The United States has a wide range of different federal, state, and local laws that apply to privacy and data security both directly and indirectly. The new state laws passed regarding privacy and consumer protection, such as the CCPA and the CPA, differ in some respects.
The Federal Trade Commission (FTC) is the lead data privacy enforcer in the United States. It has no formal complaint mechanism in that it is not required to respond to individual or group complaints. Rather, investigations often come directly from the staff at the FTC or from something raised by Congress.
The FTC often settles cases with companies through agreed arrangements called “consent decrees” which requires the companies to affirmatively take certain actions with respect to privacy and data security (i.e., privacy audits, impact assessments, hiring privacy officers etc.) Many major technological companies are currently under such consent decrees, including Facebook and Google. Although the FTC does not have the authority to initially impose fines under Section 5 of the FTC, violation of the consent decree allows for the imposition of financial sanctions.
The main justification for personal capacity criminal enforcement in Israel is the need for a deterrent against offenders that operate as individuals. The mechanism does not apply personal liability to corporate officers.
Third Webinar: Civil and Class Actions
Key Insights:
In Israel, there is a possibility of class actions arising from a privacy cause of action but only if the plaintiffs are in a special relationship covered by the relationship permissions for class actions. This does not include relationships with government entities, NGOs, or other businesses that do not contract directly with plaintiffs.
Professor Assaf Hamdani suggests that privacy class actions should only be used as a tool if public enforcement is insufficient and where the specific violation merits the use of such a tool. Generally, public enforcement is not driven by fee considerations and public enforcers examine broader issues like the impact of a case.
Under the GDPR, data subjects’ the right to compensation that data subjects have extends to material and non-material damages suffered as a result of a breach. The concept of “non-material damage” is contentious, as national courts across the EU have given it different interpretations. The Court of Justice of the European Union (CJEU) will soon clarify whether the data subject’s sense of discomfort with an unauthorized data disclosure, or their worries, fears, and anxieties count as non-material damages for the purposes of the GDPR. This underlines the importance of having a clear definition of non-material damages in the law when it comes to privacy breaches.
In the EU, representative actions under data protection law may be brought against both private and public entities, just like regular civil actions brought by affected data subjects. In some EU Member-States, national laws allow non-profits to go to court even without the data subject’s mandate, although in those cases they cannot seek compensation on behalf of data subjects. Barros Vale explained that the recently-passed EU Collective Redress Directive is more flexible in this regard, as data subjects may explicitly or tacitly express their wish to be bound by a collective compensation claim even after the action is brought.
In order to combat the possibility of underenforcement or overenforcement, Professor Swire suggests looking at three variables: 1) how likely it is that the company has a privacy violation, 2) how likely it is that an enforcement action will be taken against the company, and 3) how much the company would have to pay in damages, including attorney fees.