recast the conditions to obtain ‘safe harbour’ from liability for online intermediaries, and
unveiled an extensive regulatory regime for a newly defined category of online ‘publishers’, which includes digital news media and Over-The-Top (OTT) services.
The majority of these provisions were unanticipated, resulting in a raft of petitions filed in High Courts across the country challenging the validity of the various aspects of the Rules, including with regard to their constitutionality. On 25 May 2021, the three month compliance period on some new requirements for significant social media intermediaries (so designated by the Rules) expired, without many intermediaries being in compliance opening them up to liability under the Information Technology Act as well as wider civil and criminal laws. This has reignited debates about the impact of the Rules on business continuity and liability, citizens’ access to online services, privacy and security.
Following on FPF’s previous blog highlighting some aspects of these Rules, this article presents an overview of the Rules before deep-diving into critical issues regarding their interpretation and application in India. It concludes by taking stock of some of the emerging effects of these new regulations, which have major implications for millions of Indian users, as well as digital services providers serving the Indian market.
1.Brief overview of the Rules: Two new regimes for ‘intermediaries’ and ‘publishers’
The new Rules create two regimes for two different categories of entities: ‘intermediaries’ and ‘publishers’. Intermediaries have been the subject of prior regulations – the Information Technology (Intermediaries guidelines) Rules, 2011 (the 2011 Rules), now superseded by these Rules. However, the category of “publishers” and related regime created by these Rules did not previously exist.
The Rules begin with commencement provisions and definitions in Part I. Part II of the Rules apply to intermediaries (as defined in the Information Technology Act 2000 (IT Act)) who transmit electronic records on behalf of others, and includes online intermediary platforms (like Youtube, Whatsapp, Facebook). The rules in this part primarily flesh out the protections offered in Section 79 of India’s Information Technology Act 2000 (IT Act), which give passive intermediaries the benefit of a ‘safe harbour’ from liability for objectionable information shared by third parties using their services — somewhat akin to protections under section 230 of the US Communications Decency Act. To claim this protection from liability, intermediaries need to undertake certain ‘due diligence’ measures, including informing users of the types of content that could not be shared, and content take-down procedures (for which safeguards evolved overtime through important case law). The new Rules supersede the 2011 Rules and also significantly expand on them, introducing new provisions and additional due diligence requirements that are detailed further in this blog.
Part III of the Rules apply to a new previously non-existent category of entities designated to be ‘publishers‘. This is further classified into subcategories of ‘publishers of news and current affairs content’ and ‘publishers of online curated content’. Part III then sets up extensive requirements for publishers to adhere to specific codes of ethics, onerous content take-down requirements and three-tier grievance process with appeals lying to an Executive Inter-Departmental Committee of Central Government bureaucrats.
Finally, the Rules contain two provisions that apply to all entities (i.e. intermediaries and publishers) relating to content-blocking orders. They lay out a new process by which Central Government officials can issue directions to delete, modify or block content to intermediaries and publishers, either following a grievance process (Rule 15) or including procedures of “emergency”blocking orders which may be passed ex-parte. These Rules stem from powers to issue directions to intermediaries to block public access of any information through any computer resource (Section 69A of the IT Act). Interestingly, these provisions have been introduced separately from the existing rules for blocking purposes called the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009.
2.Key issues for intermediaries under the Rules
2.1 A new class of ‘social media intermediaries‘
The term ‘intermediary’ is a broadly defined term in the IT Act covering a range of entities involved in the transmission of electronic records. The Rules introduce two new sub-categories, being:
“social media intermediary” defined (in Rule 2(w)) as one who “primarily or solely enables online interaction between two or more users and allows them” to exchange information; and
“significant social media intermediary” (SSMI) comprising social media intermediaries with more than five million registered users in India (following this Government notification of the threshold).
Given that a popular messaging app like Whatsapp has over 400 million users in India, the threshold appears to be fairly conservative. The Government may order anyintermediary to comply with the same obligations as SSMIs (under Rule 6) if their services are adjudged to pose a risk of harm to national security, the sovereignty and integrity of India, India’s foreign relations or to public order.
SSMIs have to follow substantially more onerous “additional due diligence” requirements to claim the intermediary safe harbour (including mandatory traceability of message originators, and proactive automated screening as discussed below). These new requirements raise privacy concerns and data security concerns, as they extend beyond the traditional ideas of platform “due diligence”, they potentially expose content of private communications and in doing so create new privacy risks for users in India.
Extensive new requirements are set out in the new Rule 4 for SSMIs.
In-country employees: SSMIs must appoint in-country employees as (1) Chief Compliance Officer, (2) a nodal contact person for 24×7 coordination with law enforcement agencies and (3) a Resident Grievance Officer specifically responsible for overseeing the internal grievance redress mechanism. Monthly reporting of complaints management is also mandated.
Traceability requirements for SSMIs providing messaging services: Among the most controversial requirements is Rule 4(2) which requires SSMIs providing messaging services to enable the identification of the “first originator” of information on their platforms as required by Government or court orders. This tracing and identification of users is considered incompatible with end-to-end encryption technology employed by messaging applications like Whatsapp and Signal. In their legal challenge to this Rule, Whatsapp has noted that end-to-end encrypted platforms would need to be re-engineered to identify all users since there is no way to predict which user will be the subject of an order seeking first originator information.
Provisions to mandate modifications to the technical design of encrypted platforms to enable traceability seem to go beyond merely requiring intermediary due diligence. Instead they appear to draw on separate Government powers relating to interception and decryption of information (under Section 69 of the IT Act). In addition, separate stand-alone rules laying out procedures and safeguards for such interception and decryption orders already exist in the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009. Rule 4(2) even acknowledges these provisions–raising the question of whether these Rules (relating to intermediaries and their safe harbours) can be used to expand the scope of section 69 or rules thereunder.
Proceedings initiated by Whatsapp LLC in the Delhi High Court, and Free and Open Source Software (FOSS) developer Praveen Arimbrathodiyil in the Kerala High Court have both challenged the legality and validity of Rule 4(2) on grounds including that they are ultra vires and go beyond the scope of their parent statutory provisions (s. 79 and 69A) and the intent of the IT Act itself. Substantively, the provision is also challenged on the basis that it would violate users’ fundamental rights including the right to privacy, and the right to free speech and expression due to the chilling effect that the stripping back of encryption will have.
Automated content screening: Rule 4(4) mandates that SSMIs must employ technology-based measures including automated tools to proactively identify information depicting (i) rape, child sexual abuse or conduct, or (ii) any information previousy removed following a Government or court order. The latter category is very expansive and allows content take-downs for a broad range of reasons including defamatory or pornographic content, to IP infringements, to content threatening national security or public order (as set out in Rule 3(1)(d)).
Though the objective of the provision is laudable (i.e. to limit the circulation of violent or previously removed content), the move towards proactive automated monitoring has raised serious concerns regarding censorship on social media platforms. Rule 4(4) appears to acknowledge the deep tensions that this requirement raises with privacy and free speech concerns, as seen by the provisions that require these screening measures to be proportionate to the free speech and privacy of users, to be subject to human oversight, and reviews of automated tools to assess fairness, accuracy, propensity for bias or discrimination, and impact on privacy and security. However, given the vagueness of this wording compared to the trade-off of losing intermediary immunity, scholars and commentators are noting the obvious potential for ‘over-compliance’ and excessive screening out of content. Many (including the petitioner in the Praveen Arimbrathodiyil matter) have also noted that automated filters are not sophisticated enough to differentiate between violent unlawful images and legitimate journalistic material. The concern is that such measures could create a large-scale screening out of ‘valid’ speech and expression, with serious consequences for constitutional rights to free speech and expression which also protect ‘the rights of individuals to listen, read and receive the said speech‘ (Tata Press Ltd v. Mahanagar Telephone Nigam Ltd, (1995) 5 SCC 139).
Tighter timelines for grievance redress, content take down and information sharing with law enforcement:Rule 3 includes enhanced requirements to serve privacy policies and user agreements outlining the terms of use, including annual reminders of these terms and any modifications and of the intermediaries’ right to terminate the user’s access for using the service in contravention of these terms. The Rule also has enhanced grievance redress processes for intermediaries, by expanding these requirements to mandate that the complaints system acknowledge complaints within 24 hours, and dispose of them in 15 days. In the case of certain categories of complaints (where a person complains of inappropriate images or impersonations of them being circulated), the removal of access to the material is mandated within 24 hours based on a prima facie assessment.
Such requirements appear to be aimed at creating more user-friendly networks of intermediaries. However, the imposition of a single set of requirements is especially onerous for smaller or volunteer-run intermediary platforms which may not have income streams or staff to provide for such a mechanism. Indeed, the petition in the Praveen Arimbrathodiyil matter has challenged certain of these requirements as being a threat to the future of the volunteer-led Free and Open Source Software (FOSS) movement in India, by placing similar requirements on small FOSS initiatives as on large proprietary Big Tech intermediaries.
Other obligations that stipulate turn-around times for intermediaries include (i) a requirement to remove or disable access to content within 36 hours of receipt of a Government or court order relating the unlawful information on the intermediary’s computer resources (under Rule 3(1)(d)) and (ii) to provide information within 72 hours of receiving an order from a authorised Government agency undertaking investigative activity (under Rule 3(1)(j).
Similar to the concerns with automated screening, there are concerns that the new grievance process could lead to private entities becoming the arbiters of appropriate content/ free speech — a position that was specifically reversed in a seminal 2015 Supreme Court decision that clarified that a Government or Court order was needed for content-takedowns.
3. Key issues for the new ‘publishers’ subject to the Rules, including OTT players
3.1New Codes of Ethics and three-tier redress and oversight system for digital news media and OTT players
Digital news media and OTT players have been designated as ‘publishers of news and current affairs content’ and ‘publishers of online curated content’ respectively in Part III of the Rules. Each category has been then subjected to separate Codes of Ethics. In the case of digital news media, the Codes applicable to the newspapers and cable television have been applied. For OTT players, the Appendix sets out principles regarding content that can be created and display classifications. To enforce these codes and to address grievances from the public on their content, publishers are now mandated to set up a grievance system which will be the first tier of a three-tier “appellate” system culminating in an oversight mechanism by the Central Government with extensive powers of sanction.
Some of the key issues emerging from these Rules in Part III and the challenges to them are highlighted below.
3.2 Lack of legal authority and competence to create these Rules
There has been substantial debate on the lack of clarity regarding the legal authority of the Ministry of Electronics & Information Technology (MeitY) under the IT Act. These concerns arise at various levels.
Authority and competence to regulate ‘publishers’ of original content is unclear: The definition of ‘intermediary’ in the IT Act does not extend to cover types of entities defined to be publishers. The Rules themselves acknowledge that ‘publishers’ are a new category of regulated entity created by the Rules, as opposed to a sub-category of intermediaries. Further, the commencement of the Rules also confirm that they are passed under statutory provisions in the IT Act related to intermediary regulation. It is a well established principle that subordinate rules cannot go beyond the object and scope of parent statutory provisions (Ajoy Kumar Banerjee v Union of India (1984) 3 SCC 127). Consequently, the authority of MeitY to regulate entities that create original content – like online news sources and OTT platforms – remains unclear at best.
Ability to extend substantive provisions in other statutes through the Rules: The Rules apply two codes of conduct to digital publishers of news and current affairs content, namely (i) the Norms of Journalistic Conduct of the Press Council of India under the Press Council Act, 1978; (ii) Programme Code under section 5 of the Cable Television Networks Regulation) Act, 1995. Many, including petitioners in the LiveLaw matterhave noted that the power to make Rules under the IT Act’s s 87 cannot be used to extend or expand requirements under other statutes and their subordinate rules. To bring digital news media or OTT players into existing regulatory regimes for the Press and television broadcasting, amendments to those regimes will be required led by the Ministry of Information and Broadcasting.
Validity of three-tier ‘quasi-judicial’ adjudicatory mechanism, with final appeal to Committee of solely executive functionaries: Rules 11 – 14 create a three-tier grievance and oversight system which can be used by any person with a grievance against content published by any publisher. Under this model, any person having a grievance with any material published by a publisher can complain through the publisher’s redress process. If any grievance is not satisfactorily dealt with by the publisher entity (Level I) in 15 days, it will be escalated to the self regulatory body of which the publisher is a member (Level II) which must also provide a decision to the complainant within 15 days. If the complainant is unsatisfied, they may appeal to the Oversight Mechanism (in Level III). This can be appreciated as an attempt to create feedback loops that can minimise the spread of misleading or incendiary media, disinformation etc through a more effective grievance mechanism. The structure and design of the three-tier structure have however raised specific concerns.
First, there is a concern that Level I & II result in a privatisation of adjudications relating to free speech and expression of creative content producers – which would otherwise be litigated in Courts and Tribunals as matters of free speech. As noted by many (including the LiveLaw petition at page 33), this could have the effect of overturning judicial precedent in Shreya Singhal v. Union of India ((2013) 12 S.C.C. 73) that specifically read down s 79 of the IT Act to avoid a situation where private entities were the arbiters determining the legitimacy of takedown orders. Second, despite referring to “self-regulation” this system is subject to executive oversight (unlike the existing models for offline newspapers and broadcasting).
The Inter-Departmental Committee is entirely composed of Central Government bureaucrats, and it may review complaints through the three-tier system or referred directly by the Ministry following which it can deploy a range of sanctions from warnings, to mandating apologies, to deleting, modifying or blocking content. This also raises the question of whether this Committee meets the legal requirements for any administrative body undertaking a ‘quasi-judicial’ function, especially one that may adjudicate on matters of rights relating to free speech and privacy. Finally, while the objective of creating some standards and codes for such content creators may be laudable it is unclear whether such an extensive oversight mechanism with powers of sanction on online publishers can be validly created under the rubric of intermediary liability provisions.
4. New powers to delete, modify or block information for public access
As described at the start of this blog, the Rules add new powers for the deletion, modification and blocking of content from intermediaries and publishers. While section 69A of the IT Act (and Rules thereunder) do include blocking powers for Government, they only exist vis a vis intermediaries. Rule 15 also expands this power to ‘publishers’. It also provides a new avenue for such orders to intermediaries, outside of the existing rules for blocking information under the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009.
More grave concerns arise from Rule 16 which allows for the passing of emergency orders for blocking information, including without giving an opportunity of hearing for publishers or intermediaries. There is a provision for such an order to be reviewed by the Inter-Departmental Committee within 2 days of its issue.
Both Rule 15 and 16 apply to all entities contemplated in the Rules. Accordingly, they greatly expand executive power and oversight over digital media services in India, including social media, digital news media and OTT on-demand services.
5. Conclusions and future implications
The new Rules in India have opened up deep questions for online intermediaries and providers of digital media services serving the Indian market.
For intermediaries, this creates a difficult and even existential choice: the requirements, (especially relating to traceability and automated screening) appear to set an improbably high bar given the reality of their technical systems. However, failure to comply will result in not only the loss of a safe harbour from liability — but as seen in new Rule 7, also opens them up to punishment under the IT Act and criminal law in India.
For digital news and OTT players, the consequences of non-compliance and the level of enforcement remain to be understood, especially given open questions regarding the validity of legal basis to create these rules. Given the numerous petitions filed against these Rules, there is also substantial uncertainty now regarding the future although the Rules themselves have the full force of law at present.
Overall, it does appear that attempts to create a ‘digital media’ watchdog would be better dealt with in a standalone legislation, potentially sponsored by the Ministry of Information and Broadcasting (MIB) which has the traditional remit over such areas. Indeed, the administration of Part III of the Rules has been delegated by MeitY to MIB pointing to the genuine split in competence between these Ministries.
Finally, the potential overlaps with India’s proposed Personal Data Protection Bill (if passed) also create tensions in the future. It remains to be seen if the provisions on traceability will survive the test of constitutional validity set out in India’s privacy judgement (Justice K.S. Puttaswamy v. Union of India, (2017) 10 SCC 1). Irrespective of this determination, the Rules appear to have some dissonance with the data retention and data minimisation requirements seen in the last draft of the Personal Data Protection Bill, not to mention other obligations relating to Privacy by Design and data security safeguards. Interestingly, despite the Bill’s release in December 2019, a definition for ‘social media intermediary’ that it included in an explanatory clause to its section 26(4) closely track the definition in Rule 2(w), but also departs from it by carving out certain intermediaries from the definition. This is already resulting in moves such as Google’s plea on 2 June 2021 in the Delhi High Court asking for protection from being declared a social media intermediary.
These new Rules have exhumed the inherent tensions that exist within the realm of digital regulation between goals of the freedom of speech and expression, and the right to privacy and competing governance objectives of law enforcement (such as limiting the circulation of violent, harmful or criminal content online) and national security. The ultimate legal effect of these Rules will be determined as much by the outcome of the various petitions challenging their validity, as by the enforcement challenges raised by casting such a wide net that covers millions of users and thousands of entities, who are all engaged in creating India’s growing digital public sphere.
New FPF Report Highlights Privacy Tech Sector Evolving from Compliance Tools to Platforms for Risk Management and Data Utilization
As we enter the third phase of development of the privacy tech market, purchasers are demanding more integrated solutions, product offerings are more comprehensive, and startup valuations are higher than ever, according to a new report from the Future of Privacy Forum and Privacy Tech Alliance. These factors are leading to companies providing a wider range of services, acting as risk management platforms, and focusing on support of business outcomes.
“The privacy tech sector is at an inflection point, as its offerings have expanded beyond assisting with regulatory compliance,” said FPF CEO Jules Polonetsky. “Increasingly, companies want privacy tech to help businesses maximize the utility of data while managing ethics and data protection compliance.”
According to the report, “Privacy Tech’s Third Generation: A Review of the Emerging Privacy Tech Sector,” regulations are often the biggest driver for buyers’ initial privacy tech purchases. Organizations also are deploying tools to mitigate potential harms from the use of data. However, buyers serving global markets increasingly need privacy tech that offers data availability and control and supports its utility, in addition to regulatory compliance.
The report finds the COVID-19 pandemic has accelerated global marketplace adoption of privacy tech as dependence on digital technologies grows. Privacy is becoming a competitive differentiator in some sectors, and TechCrunch reports that 200+ privacy startups have together raised more than $3.5 billion over hundreds of individual rounds of funding.
“The customers buying privacy-enhancing tech used to be primarily Chief Privacy Officers,” said report lead author Tim Sparapani. “Now it’s also Chief Marketing Officers, Chief Data Scientists, and Strategy Officers who value the insights they can glean from de-identified customer data.”
The report highlights five trends in the privacy enhancing tech market:
Buyers desire “enterprise-wide solutions.”
Buyers favor integrated technologies.
Some vendors are moving to either collaborate and integrate or provide fully integrated solutions themselves.
Data is the enterprise asset.
Jurisdiction impacts a shared vernacular problem.
The report also draws seven implications for competition in the market:
Buyers favor integrated solutions over one-off solutions.
Collaborations, partners, cross-selling, and joint ventures between privacy tech vendors are increasing to provide buyers integrated suites of services and to attract additional market share.
Private equity and private equity-backed companies will continue their “roll-up” strategies of buying niche providers to build a package of companies to provide the integrated solutions buyers favor.
Venture capital will continue funding the privacy tech sector, though not every seller has the same level of success fundraising.
Big companies may acquire strategically valuable, niche players.
Small startups may struggle to gain market traction absent a truly novel or superb solution.
Buyers will face challenges in future-proofing their privacy strategies.
The report makes a series of recommendations, including that the industry define as a priority a common vernacular for privacy tech; set standards for technologies in the “privacy stack” such as differential privacy, homomorphic encryption, and federated learning; and explore the needs of companies for privacy tech based upon their size, sector, and structure. It calls on vendors to recognize the need to provide adequate support to customers to increase uptake and speed time from contract signing to successful integration.
The Future of Privacy Forum launched the Privacy Tech Alliance (PTA) as a global initiative with a mission to define, enhance and promote the market for privacy technologies. The PTA brings together innovators in privacy tech with customers and key stakeholders.
Members of the PTA Advisory Board, which includes Anonos, BigID, D-ID, Duality, Ethyca, Immuta, OneTrust, Privacy Analytics, Privitar, SAP, Truata, TrustArc, Wirewheel, and ZL Tech, have formed a working group to address impediments to growth identified in the report. The PTA working group will define a common vernacular and typology for privacy tech as a priority project with chief privacy officers and other industry leaders who are members of FPF. Other work will seek to develop common definitions and standards for privacy-enhancing technologies such as differential privacy, homomorphic encryption, and federated learning and identify emerging trends for venture capitalists and other equity investors in this space. Privacy Tech companies can apply to join the PTA by emailing [email protected].
Perspectives on the Privacy Tech Market
Quotes from Members of the Privacy Tech Alliance Advisory Board on the Release of the “Privacy Tech’s Third Generation” Report
“The ‘Privacy Tech Stack’ outlined by the FPF is a great way for organizations to view their obligations and opportunities to assess and reconcile business and privacy objectives. The Schrems II decision by the Court of Justice of the European Union highlights that skipping the second ‘Process’ layer can result in desired ‘Outcomes’ in the third layer (e.g., cloud processing of, or remote access to, cleartext data) being unlawful – despite their global popularity – without adequate risk management controls for decentralized processing.” — Gary LaFever, CEO & General Counsel, Anonos
“As a founding member of this global initiative, we are excited by the conclusions drawn from this foundational report – we’ve seen parallels in our customer base, from needing an enterprise-wide solution to the rich opportunity for collaboration and integration. The privacy tech sector continues to mature as does the imperative for organizations of all sizes to achieve compliance in light of the increasingly complicated data protection landscape.’’—Heather Federman, VP Privacy and Policy at BigID
“There is no doubt of the massive importance of the privacy sector, an area which is experiencing huge growth. We couldn’t be more proud to be part of the Privacy Tech Alliance Advisory Board and absolutely support the work they are doing to create alignment in the industry and help it face the current set of challenges. In fact we are now working on a similar initiative in the synthetic media space to ensure that ethical considerations are at the forefront of that industry too.” — Gil Perry, Co-Founder & CEO, D-ID
“We congratulate the Future of Privacy Forum and the Privacy Tech Alliance on the publication of this highly comprehensive study, which analyzes key trends within the rapidly expanding privacy tech sector. Enterprises today are increasingly reliant on privacy tech, not only as a means of ensuring regulatory compliance but also in order to drive business value by facilitating secure collaborations on their valuable and often sensitive data. We are proud to be part of the PTA Advisory Board, and look forward to contributing further to its efforts to educate the market on the importance of privacy-tech, the various tools available and their best utilization, ultimately removing barriers to successful deployments of privacy-tech by enterprises in all industry sectors” — Rina Shainski, Chairwoman, Co-founder, Duality
“Since the birth of the privacy tech sector, we’ve been helping companies find and understand the data they have, compare it against applicable global laws and regulations, and remediate any gaps in compliance. But as the industry continues to evolve, privacy tech also is helping show business value beyond just compliance. Companies are becoming more transparent, differentiating on ethics and ESG, and building businesses that differentiate on trust. The privacy tech industry is growing quickly because we’re able to show value for compliance as well as actionable business insights and valuable business outcomes.” — Kabir Barday, CEO, OneTrust
“Leading organizations realize that to be truly competitive in a rapidly evolving marketplace, they need to have a solid defensive footing. Turnkey privacy technologies enable them to move onto the offense by safely leveraging their data assets rapidly at scale.” — Luk Arbuckle, Chief Methodologist, Privacy Analytics
“We appreciate FPF’s analysis of the privacy tech marketplace and we’re looking forward to further research, analysis, and educational efforts by the Privacy Tech Alliance. Customers and consumers alike will benefit from a shared understanding and common definitions for the elements of the privacy stack.” — Corinna Schulze, Director, EU Government Relations, Global Corporate Affairs, SAP
“The report shines a light on the evolving sophistication of the privacy tech market and the critical need for businesses to harness emerging technologies that can tackle the multitude of operational challenges presented by the big data economy. Businesses are no longer simply turning to privacy tech vendors to overcome complexities with compliance and regulation; they are now mapping out ROI-focused data strategies that view privacy as a key commercial differentiator. In terms of market maturity, the report highlights a need to overcome ambiguities surrounding new privacy tech terminology, as well as discrepancies in the mapping of technical capabilities to actual business needs. Moving forward, the advantage will sit with those who can offer the right blend of technical and legal expertise to provide the privacy stack assurances and safeguards that buyers are seeking – from a risk, deployment and speed-to-value perspective. It’s worth noting that the growing importance of data privacy to businesses sits in direct correlation with the growing importance of data privacy to consumers. Trūata’s Global Consumer State of Mind Report 2021 found that 62% of global consumers would feel more reassured and would be more likely to spend with companies if they were officially certified to a data privacy standard. Therefore, in order to manage big data in a privacy-conscious world, the opportunity lies with responsive businesses that move with agility and understand the return on privacy investment. The shift from manual, restrictive data processes towards hyper automation and privacy-enhancing computation is where the competitive advantage can be gained and long-term consumer loyalty—and trust— can be retained.” — Aoife Sexton, Chief Privacy Officer and Chief of Product Innovation, Trūata
“As early pioneers in this space, we’ve had a unique lens on the evolving challenges organizations have faced in trying to integrate technology solutions to address dynamic, changing privacy issues in their organizations, and we believe the Privacy Technology Stack introduced in this report will drive better organizational decision-making related to how technology can be used to sustainably address the relationships among the data, processes, and outcomes.” — Chris Babel, CEO, TrustArc
“It’s important for companies that use data to do so ethically and in compliance with the law, but those are not the only reasons why the privacy tech sector is booming. In fact, companies with exceptional privacy operations gain a competitive advantage, strengthen customer relationships, and accelerate sales.” — Justin Antonipillai, Founder & CEO, Wirewheel
Colorado Privacy Act Passes Legislature: Growing Inconsistencies Ramp Up Pressure for Federal Privacy Law
Today, the Colorado Senate approved the House version of the Colorado Privacy Act (SB21-190) that passed yesterday, on June 7. If approved by Governor Jared Polis, Colorado will follow Virginia and California as the third U.S. state to establish baseline legal protections for consumer privacy.
“Although the Colorado Privacy Act contains notable advances that build on California and Virginia — in particular, formalizing a global privacy control, and applying to non-profit organizations — there continues to be an urgent need for Congress to set federal standards that create baseline nationwide protections for all.”
Statement by Polly Sanderson, Policy Counsel, Future of Privacy Forum
Colorado’s law features elements of both Virginia and California’s consumer privacy laws, as well as some elements unique to Colorado. The law is the first in the U.S. to apply to non-profit entities in addition to commercial entities. It contains a strong consent standard to process personal data for incompatible secondary uses and to process sensitive data such as health information, race, ethnicity, and other sensitive categories. The bill prohibits controllers from employing so-called “dark patterns” to obtain consent and allows consumers to exercise their opt-out rights via authorized agents. Consumers will be able to express their intent to opt-out of sales and targeted advertising via a universal opt-out mechanism established by the Colorado Attorney General, who is also granted authority to issue opinion letters and interpretive guidance on what constitutes a violation of the Act.
Similar to Virginia’s recently passed Consumer Data Protection Act, Colorado’s law requires controllers to conduct data protection assessments for processing activities that present a heightened risk of harm to a consumer. This, along with FIPPs-inspired data minimization and purpose specification provisions, promotes organizational accountability and moves beyond a notice and consent framework. By excluding de-identified data from the scope of personal data and excluding pseudonymous data from the rights of access, correction, deletion, and portability, the law follows existing standards and incentivizes covered entities to maintain data in less identifiable formats.
As a growing number of states begin to pass their own consumer privacy laws, concerns about interoperability may begin to emerge. For instance, definitional differences regarding what constitutes sensitive data, pseudonymous data, and biometric data may present operational challenges for businesses. Similarly, the scope of access, deletion, and other consumer rights differ between Colorado, Virginia, and California, creating potential implementation challenges. Finally, the research exemptions of each of these laws differ in their flexibility, consent, and oversight requirements.
Media Inquiries: Polly Sanderson, Senior Counsel at [email protected]
Privacy Trends: Four State Bills to Watch that Diverge from California and Washington Models
During 2021, state lawmakers have proposed a range of models to regulate consumer privacy and data protection.
As the first state to pass consumer privacy legislation in 2018, California established a highly influential model with the California Consumer Privacy Act. In the years since, other states have introduced dozens of nearly identical CCPA-like state bills. In 2019, the Washington Privacy Act became an alternative model, which also saw large numbers of nearly identical WPA-like state bills introduced in other states throughout 2019-2021. In February, 2021, the passage of the Virginia Consumer Data Protection Act cemented the Washington model as an influential alternative framework.
In 2021, however, numerous divergent frameworks have begun to emerge, with the potential to establish strong consumer protections, conflict with other states, and potentially influence federal privacy law. These proposals diverge from the California and Washington models in key ways, and are worth examining because of how they show ongoing cross-pollination, reveal concerns driving lawmakers about the inadequacy of notice and choice frameworks, and offer novel approaches for lawmakers and other stakeholders to discuss, debate, and consider.
The California Model
As the first state to enact consumer privacy legislation in 2018, California has a distinct and highly influential model for consumer privacy law. Since the passage of the California Consumer Privacy Act (CCPA), a proliferation of state proposals have adopted a similar framework, scope, and terminology. This reflects a general desire among state legislators to provide their constituents with at least the same privacy rights as those afforded to Californians, but in 2018, many hadn’t yet conceptualized alternative frameworks of their own.
California-style proposals adopt “business-service provider” terminology, focus on consumer-business relationships, and are characterized by their focus on providing consumers with greater transparency and control over their personal data. They feature a bundle of privacy rights, including the right for consumers to “opt-out” of sales (or sharing) of personal data, and require businesses to post “Do Not Sell” links on their website homepages. Often, California-style proposals also include provisions which aim to make it easier for consumers to exercise their opt-out rights, such as authorized agent and universal opt-out provisions.
Though none have passed into law, the California model has influenced many state proposals over the past three years, such as Alaska’s failed HB 159 / SB 116, Florida’s failed HB 969 / SB 1734, and New York Governor Cuomo’s failed Data Accountability and Transparency Act incorporated into Budget Legislation. Oklahoma’s failed HB 1602 also adopted a similar framework, though it would require businesses to obtain “opt-in” consent to sell personal data, rather than “opt-out.”
The Washington Model
The Washington Privacy Act (WPA – SB 5062), sponsored by Sen. Reuven Carlyle (D), recently failed for the third consecutive legislative session. However, in February, 2021, Virginia passed legislation which follows the general framework of the WPA. Virginia’s Consumer Data Protection Act (VA-CDPA) sponsored by Delegate Cliff Hayes (D) and Sen. David Marsden (D), will become effective on January 1, 2023.
The framework includes (1) processor/controller terminology; (2) heightened privacy protections for sensitive data; (3) individual rights of access, deletion, correction, portability, and the right to opt-out of sales, targeted advertising, and profiling in the furtherance of legal (or similarly significant) decisions; (4) differential treatment of pseudonymous data, (5) data protection impact assessments for high risk data processing activities, (6) flexibility for research, and (7) enforcement by the Attorney General.
Numerous other active state bills adopt this framework, such as Colorado SB21-190, Connecticut SB 893, and failed proposals in Utah, Minnesota, and elsewhere. The Colorado and Connecticut proposals are both on the Senate floor calendars in their respective states. Of course, each WPA-type bill contains important differences. For instance, the Colorado and Connecticut proposals both broadly exclude pseudonymous data from all consumer rights, including opt-out rights. The Colorado proposal also features a global/universal opt-out provision for sales and targeted advertising, an opt-out standard for the processing of sensitive data (rather than opt-in), a prescriptive HIPAA de-identification standard (rather than the FTC’s 3-part test), and public research exemptions that do not incorporate provisions mandating oversight by an institutional review board (IRB) or a similar oversight body.
Growing Divergence and Cross-Pollination
In the three years since the passage of the CCPA, legislative divergence has increased as more and more states have convened task forces to study consumer privacy issues, and held hearings, roundtables, and 1-on-1’s with diverse experts from academia, the advocacy community, and industry. In other words, the laboratories of democracy have been experimenting — a trend which will likely continue in 2022 and beyond as legislators’ views on consumer privacy continue to become more sophisticated and nuanced.
State bills in 2021, as compared to 2019-2020, are increasingly focused on bolstering notice and choice regimes (including a shift towards more “opt-in” rather than “opt-out” requirements), are borrowing more features from other laws (such as the GDPR’s “legitimate interests” framework), and in some cases experimenting with novel approaches (such as fiduciary duties, or “data streams”).
For example, some state bills would require businesses to provide two-tiered short-form and long-form disclosures, and would authorize a government agency to develop a uniform logo or button to promote individual awareness of the short-form notice. Numerous proposals would generally require opt-in consent for all data processing, would prohibit manipulative user interfaces to obtain consent, and would designate user-enabled privacy controls as a valid mechanism for an individual to communicate their privacy preferences. Some proposals feature additional rights, such as the right not to be subject to “surreptitious surveillance,” the right not to be subject to a solely automated decision, and the right to object to processing.
There is also a trend among proposals towards moving beyond a notice and choice framework, with the aim of moving the burden of privacy management away from individuals. For instance, many include strong purpose specification and data minimization requirements, and some include outright prohibitions on discriminatory data processing. At least one state (NJ A. 3283, discussed below) has taken inspiration from the EU’s General Data Protection Regulation (GDPR) by recognizing “legitimate interests” along with other lawful bases for data processing.
Many proposals are taking novel or unique approaches to privacy legislation. For example, a Texas proposal leans towards conceptualizing personal data as property by enabling an individual to exchange their “data stream” as consideration for a contract with a business. Meanwhile, various proposals contain duties of loyalty, care, and confidentiality. These trust-based duties were first introduced into US legislation in 2018, when Sen. Brian Schatz (D-HI) introduced the Data Care Act (S. 2961). At that time, it wasn’t clear whether trust-based duties would become influential in the US. The fact that they have demonstrates the potential for cross-pollination between federal and state proposals.
Four Notable Models to Watch
Amidst such a large volume of California and Washington-like bills, it may be easy to miss the handful of states where legislators are taking a different approach to baseline or comprehensive privacy legislation. Even if they do not pass, these bills are worth examining because they could eventually influence federal privacy law. Additionally, they can provide insights into some of the most pressing concerns of policymakers, such as whether (and how) to regulate automated decision-making, including profiling? Whether a framework should be based on privacy self-management, relationships of trust, civil rights, or personal data as property? How personal data should be defined, and whether it should be subcategorized according to sensitivity, identifiability, source (first party, third party, derived) or something else? Answering these types of questions is not straightforward, and there are many reasonable philosophical positions for stakeholders to take. Close attention to legislative proposals can help to promote nuanced dialogue and debate about the relative merits and drawbacks of different approaches.
Four active bills that are worth watching are (1) the New York Privacy Act (NYPA – S. 6701), (2) the New Jersey Disclosure and Accountability Transparency Act (NJ DaTA – A. 3283), (3) the Massachusetts Information Privacy Act (MIPA – S.46), and (4) Texas’s HB 3741.
New York Privacy Act (NYPA)
The New York Privacy Act (NYPA) (S. 6701) introduced by Sen. Kevin Thomas in May, 2021, has several distinctive features, such as an opt-in consent framework, duties of loyalty and care, heightened protections for certain types of consequential automated decision-making, and a data broker registry. The proposal passed out of the Consumer Protection Committee on May 18, and is now on the floor calendar. The legislature adjourns June 10.
Opt-In Consent & Global Consent Mechanism: The requirement for controllers to obtain opt-in consent to process a consumer’s personal data is accompanied by a prohibition on manipulative user interface design choices in order to obtain consent. Controllers would also be required to treat user-enabled privacy controls (e.g., browser plug-ins, device settings, or other mechanisms) that communicate or signal the consumer’s choice not to be subject to targeted advertising or the sale of their personal data as a denial of consent.
Duty of Loyalty & Care: The “duty of loyalty” would require a controller to obtain consent to process data in ways that are reasonably foreseeable to be against a consumer’s physical, financial, psychological, or reputational interests. The proposal also contains a “duty of care,” requiring controllers to conduct and document annual, nonpublic risk assessments for all processing of personal data. Of note, the “duty of loyalty” is distinct from the “fiduciary duty” contained in an earlier 2019 version of the NYPA (S. 5642).
Automated Decision Making: Annual public impact assessments would be required for a controller or processor “engaged in” consequential automated decisions (such as financial, housing, and employment). Whenever a controller makes an automated decision involving solely automated processing that “results in” a denial of financial or lending services, housing, public accommodation, insurance, health care services, or access to basic necessities, such as food and water, the controller must: (i) disclose that the decision was made by a solely automated process; (ii) provide an avenue for the affected consumer to appeal the decision, including by allowing the affected consumer to (a) express their point of view, (b) contest the decision, and (c) obtain meaningful human review; and (iii) explain how to appeal the decision.
Data Broker Registry: The NYPA would establish a data broker registry and prohibit controllers from sharing personal data with data brokers that fail to register.
New Jersey Disclosure and Accountability Transparency Act (NJ DaTA)
The New Jersey Disclosure and Accountability Transparency Act (NJ DaTA – A. 3283) introduced by Assemblyman Andrew Zwicker (D) was heard before the Assembly Science, Innovation and Technology Committee on March 15, 2021. The legislature will remain in session through 2021. The framework includes six lawful bases for data processing, affirmative data processing duties, the right for an individual to object to processing, and heightened requirements surrounding automated decision-making.
Six Lawful Grounds for Processing: The framework creates six lawful grounds for processing, including “legitimate interests” pursued, affirmative consent, contractual necessity, to protect the vital interests of a person, compliance with a legal obligation, and necessary for the performance of a task.
Data Processing Duties: NJ DaTA would require for: (1) all data collection to be for a specified, explicit, and legitimate purpose, (2) data to be processed lawfully, fairly, and transparently, (3) data collection and processing to be adequate, relevant, and limited to what is necessary, (4) data to be accurate and kept up to date, (5) data to be kept in a form which permits identification of consumers for no longer than is necessary for the processing purposes, (6) data security. Data protection impact assessments would also be required prior to processing personal data.
Right to Object to Processing: In addition to the rights of access, correction, deletion, and portability, the proposal would grant individuals the right to object to the processing of personal data. For a controller to continue to process personal data in this circumstance, the controller must demonstrate “compelling legitimate grounds” for processing which override the interests, rights, and freedoms of the consumer. The proposal would also grant individuals a right to object to processing of personal data for the purpose of direct marketing, including profiling. When a consumer objects to processing for this purpose, the controller must stop processing.
Automated Decision-Making: The proposal would create the right for a consumer not to be subject to a decision based on solely automated decision making, including profiling, which produces legal effects concerning the consumer. NJ DaTA would require controllers to provide specific notice to consumers at the time of collection of personal data regarding the existence of automated decision making, including profiling, meaningful information concerning the logic involved, and significance and potential consequences for the consumer.
New Data Protection Office: NJ DaTA would establish an Office of Data Protection and Responsible Uses in the Division of Consumer Affairs to oversee compliance with the Act.
Massachusetts Information Privacy Act (MIPA)
The Massachusetts Information Privacy Act (MIPA – S.46) was introduced by Sen. Cynthia Stone Creem’s (D) in March, 2021. The legislature will remain in session through 2021. MIPA’s framework is based on a framework of notice and consent, with additional trust-based obligations for covered entities. Heightened protections arise for biometric data, location data, and “surreptitious surveillance” is prohibited.
Two-Tiered Notice: MIPA would require two-tiered privacy notice, including a long-form and a short-form privacy policy to be made available at the point or prior to the point of sale of a product or service. MIPA would also authorize a government agency to develop a uniform logo or button to promote individual awareness of the short-form notice.
Opt-In Consent: Opt-in consent would be annually required to collect or process personal data.
Prohibition of Surreptitious Surveillance: MIPA would prohibit “surreptitious surveillance,” meaning that a covered entity would be required to obtain opt-in consent every 180 days in order to “activate the microphone, camera, or any other sensor” on individuals’ connected devices.
Heightened Protections for Biometric and Location Data: MIPA would require covered entities to obtain specific opt-in consent annually to collect and process location or biometric data, and additional consent to disclose it to third parties. Covered entities would also be required to establish a retention schedule and guidelines for permanently destroying biometric or location data.
Data Processing Duties: MIPA contains strict purpose limitations, and duties of loyalty, care, and confidentiality. It would also require covered entities to process personal data and use automated decision systems “discreetly and honestly,” to be “protective” of personal data, “loyal” to individuals, and “honest” about processing risks. The duty of loyalty would require covered entities to not use personal data or information derived from personal data in ways that: (1) benefit themselves to the detriment of an individual, (2) result in reasonably foreseeable and material physical or financial harm to an individual, or (3) would be unexpected and highly offensive to a reasonable individual.
Discrimination Prohibition: MIPA would prohibit a covered entity from engaging in acts or practices that directly result in discrimination against or otherwise make an opportunity, or a public accommodation, unavailable on the basis of an individual’s or group’s actual or perceived belonging to a protected class. This includes a prohibition on targeting advertisements on the basis of actual or perceived belonging to a protected class.
Texas HB 3741
HB 3741, introduced by Rep. Capriglione (R), was referred to the Business & Industry Committee on Mar. 22. Texas’s legislative session is scheduled to end May 31, 2021. The proposal has numerous unique features. It would enable a consumer to provide their “data stream” as consideration under contract, it imposes different restrictions on three defined subcategories of personal data, and it would require opt-in consent for geotracking. In addition, businesses would be required to maintain accurate personal data.
Data Streams: The proposal would enable an individual to provide their “data stream” as consideration under contract. “Data stream” is defined as “the continuous transmission of an individual ’s personal identifying information through online activity or with a device connected to the Internet that can be used by the business to provide for the monetization of the information, customer relationship management, or continuous identification of an individual for commercial purposes.”
Three Categories of Personal Data: HB 3741 divides personal data into three subcategories of “personally identifiable information.”
Category 1 information includes personal data “that an individual may use in a personal, civic, or business setting,” including a SSN, a driver’s license number, passport number, unique biometric information, physical or mental health information, private communications, etc.
Category 2 information includes personal data that may present a “privacy risk” to an individual, including members of a constitutionally protected class.” It includes information such as racial or ethnic origin, religion, age, precise geolocation, or physical or mental impairment. “Privacy risk” is defined broadly. Businesses would be prohibited from selling, transferring, or communicating category 2 information to a third party.
Category 3 information includes time of birth and political party or association. Businesses would be prohibited from collecting or processing category 3 information.
Opt-In Consent for Geolocation Tracking: Consent would be required to perform geolocation tracking of an individual, and to sell geolocation information. Individuals would also have the rights of access, correction, deletion, and portability.
Duty to Maintain Accurate Information: Businesses would be required to maintain accurate information, and to protect and properly secure personal data.
South Korea: The First Case Where the Personal Information Protection Act was Applied to an AI System
As AI regulation is being considered in the European Union, privacy commissioners and data protection authorities around the world are starting to apply existing comprehensive data protection laws against AI systems and how they process personal information. On April 28th, the South Korean Personal Information Protection Commission (PIPC) imposed sanctions and a fine of KRW 103.3 million (USD 92,900) on ScatterLab, Inc., developer of the chatbot “Iruda,” for eight violations of the Personal Information Protection Act (PIPA). This is the first time PIPC sanctioned an AI technology company for indiscriminate personal information processing.
“Iruda” caused considerablecontroversy in South Korea in early January after complaints of the chatbot using vulgar and discriminatory racist, homophobic, and ableist language in conversations with users. The chatbot, which assumed the persona of a 20-year-old college student named “Iruda” (Lee Luda), attracted more than 750,000 users on Facebook Messenger less than a month after release. The media reports prompted PIPC to launch an official investigation on January 12th, soliciting input from industry, law, academia, and civil society groups on personal information processing and legal and technical perspectives on AI development and services.
PIPC’s investigation found that ScatterLab used KakaoTalk, a popular South Korean messaging app, messages collected by its apps “Text At” and “Science of Love” between February 2020 to January 2021 to develop and operate its AI chatbot “Iruda.” Around 9.4 billion KakaoTalk messages from 600,000 users were employed in training algorithms to develop the “Iruda” AI model, without any efforts by ScatterLab to delete or encrypt users’ personal information, including their names, mobile phone numbers, and addresses. Additionally, 100 million KakaoTalk messages from women in their twenties were added to the response database with “Iruda” programmed to select and respond with one of these messages.
With regards to ScatterLab employing users’ KakaoTalk messages to develop and operate “Iruda,” PIPC found that including a “New Service Development” clause in the terms to log into the apps “Text At” and “Science of Love” did not amount to user’s “explicit consent.” The description of “New Service Development” was determined to be insufficient for users to anticipate that their KakaoTalk messages would be used to develop and operate “Iruda.” Therefore, PIPC determined that ScatterLab processed the user’s personal information beyond the purpose of collection.
In addition, ScatterLab posted its AI models on the code sharing and collaboration platform Github from October 2019 to January 2021, which included 1,431 KakaoTalk messages revealing 22 names (excluding last names), 34 locations (excluding districts and neighborhoods), gender, and relationships (friends or romantic partners) of users. This was found to be in violation of PIPA Article 28-2(2) which states, “A personal information controller shall not include information that may be used to identify a certain individual when providing pseudonymized information to a third party.”
ScatterLab also faced accusations of collecting personal information of over 200,000 children under the age of 14 without parental consent in the development and operation of its app services, “Text At,” “Science of Love,” and “Iruda,” as its services did not require age verification prior to subscribing.
PIPC Chairman Jong-in Yoon highlighted the complexity of the case at hand and the reasons why extensive public consultation took place as part of the proceedings: “Even the experts did not agree so there was more intense debate than ever before and the ‘Iruda’ case was decided after very careful review.” He explained, “This case is meaningful in that it has made clear that companies are prohibited from indiscriminately using personal information collected for specific services without clearly informing and obtaining explicit consent from data subjects.” Chairman Yoon added, “We hope that the results of this case will guide AI technology companies in setting the right direction for the processing of personal information and provide an opportunity for companies to strengthen their self management and supervision.”
PIPC plans to be active in supporting compliant AI Systems
PIPC also stated that it seeks to help AI technology companies in improving their privacy capabilities by having AI developers and operators present a “Self-Checklist for Personal Information Protection of AI Services” on-site, as well as support on-site consulting. PIPC plans to actively support AI technology companies to develop AI and data-based industries while protecting people’s personal information.
ScatterLab responded to the decision, “We feel a heavy sense of social responsibility as an AI tech company regarding the necessity to engage in proper personal information processing in the course of developing related technologies and services,” and stated that, “Upon the PIPC’s decision, we will not only actively implement the corrective actions put forth by the PIPC but also work to comply with the law and industry guidelines related to personal information processing.”
Talking to Kids About Privacy: Advice from a Panel of International Experts
Now more than ever, as kids spend much of their lives online to learn, explore, play, and connect, it is essential to ensure their knowledge and understanding of online safety and privacy keeps pace. On May 13th, the Future of Privacy Forum and Common Sense assembled a panel of youth privacy experts from around the world for a webinar presentation on, “Talking to Kids about Privacy,” exploring both the importance of and approaches to talking to kids about privacy. Watch a recording of the webinar here.
The virtual discussion, moderated by FPF’s Amelia Vance and Jasmine Park, aimed to provide parents and educators with tools and resources to facilitate productive conversations with kids of all ages. The panelists were Rob Girling, Co-Founder of strategy and design firm Artefact, Sonia Livingstone, Professor of Social Psychology at the London School of Economics and Political Science (LSE), Kelly Mendoza, Vice President of Education Programs at Common Sense, Anna Morgan, Head of Legal and Deputy Commissioner of the Irish Data Protection Commission (DPC), and Daniel Solove, Professor of Law at George Washington University Law School and Founder of TeachPrivacy.
The first thing that parents and educators need to know? “Contrary to popular opinion, kids really care about their privacy in their personal lives, and especially now, in their digital lives,” shared panelist Sonia Livingstone. “When they understand how their data is being kept, shared, monetized and so forth, they are outraged.” To help inform youth, Livingstone curated an online toolkit with young people to answer frequently asked privacy questions that emerged from her research.
And a close second: their views about privacy are closely shaped by their environment. “How children understand privacy is in some ways colored by the part of the world they come from and the culture and ideas about family and ideas about institutions that they can trust, and especially how far the digital world has already become something they rely upon,” Livingstone added.
Kelly Mendoza encouraged audience members to start having conversations about privacy with kids at a young age, and to get beyond the common but too simple advice to not share personal information online. Common Sense’s Digital Citizenship Curriculum provides free lesson plans to address timely topics and prepare students to take ownership of their digital lives by grade and topic.
She also emphasized the important role that schools play in educating parents about privacy in her remarks. “It’s important that schools and educators and parents work together because really we’re finding that schools can play a really powerful role in educating parents,” Mendoza said. “Schools need to do a better job of communicating – what tools are they using? How are they rated and reviewed? What are the privacy risks? And why are they using this technology?” A useful starting point for schools and parents is Common Sense’s Family Engagement Resources Toolkit, which includes tips, activities, and other resources.
Several panelists emphasized the critical role schools play in educating students about privacy. To do so effectively, schools engage and educate teachers to ensure they are informed and equipped to have meaningful conversations about privacy with their students.
Anna Morgan provided a model for engaging children in informing data protection policies through classroom-based lesson plans. Recognizing that the General Data Protection Regulation (GDPR) and Data Protection Law are complex, the DPC provided teachers with a quick start guide to provide background knowledge, enabling them to engage in discussions with children about their data protection rights and entitlements.
Privacy can be a difficult concept to explain, and there’s nothing quite like a creative demonstration to bring privacy concerns to life. One example: the DPC created a fictitious app to solicit children’s reactions to the use of their personal data. Through their consultation, Morgan shared that 60 percent of the children surveyed believed that their personal data should not be used to serve them with targeted advertising, finding it scary and creepy to have ads following them around. A full report from the consultation can be found here.
Daniel Solove also highlighted the need for educational systems to teach privacy. “Children today are growing up in a world where massive quantities of personal information are being gathered from them. They’re growing up in a world where they’re more under surveillance than any other generation. There’s more information about them online than any other generation. And the ability for them to put information online and get it out to the world is also unprecedented,” Solove noted. “So I think it’s very important that they learn about these things, and as a first step, they need to appreciate and understand the value of privacy and why it matters.”
One way for kids to learn about privacy is through storytelling. Solove recently authored a new children’s book about privacy titled, THE EYEMONGER, and shared his motivations for writing the book with the audience. “There really wasn’t anything out there that explained to children what privacy was, why we should care about it, or really any of the issues that are involved in this space, so that prompted me to try to do something about it.” He also compiled a list of resources to accompany the book and help educators and parents teach privacy to their children.
Building on the thread of creating outside-the-box interactive experiences to help kids understand privacy, Rob Girling shared with the audience a game called The Most Likely Machine, developed by Artefact Group to help preteens understand algorithms. Girling saw a need to teach algorithmic literacy given the impact on children’s lives, from determining college and job applications to search engine results. For Girling, “It’s just starting to introduce the idea that underneath algorithms are human biases and data that is often biased. That’s the key learning we want kids to take away.”
Each of the panelists shared a number of terrific resources and recommendations for parents and educators, which we have listed and linked to below, along with a few of our own.
The author thanks Hunter Dorwart for his contribution to this text.
The Cyberspace Administration of China (CAC) released a draft regulation on car privacy and data security on May 12, 2021. China has been very active in automated vehicle development and deployment and has also proposed last fall a draft comprehensive privacy law, which is moving towards adoption likely by the end of this year.
The draft car privacy and data security regulation (“Several Provisions on the Management of Automobile Data Security”; hereinafter, “draft regulation”) is interesting for those tracking automated vehicle (AV) and privacy regulations around the world and is relevant beyond China – not only due to the size of the Chinese market and its potential impact on all actors in the “connected cars” space present there, but also because dedicated legislation for car privacy and data security is novel for most jurisdictions. In fact, the draft regulation raises several interesting privacy and data protection aspects worthy of further consideration, such as its strict rules on consent, privacy by design, and data localization requirements. The CAC is seeking public comment on the draft, and the deadline for comments is June 11, 2021.
The draft regulation complements other regulatory developments around connected and automated vehicles and data. For example, on April 29, 2021, the National Information Security Standardization Technical Committee (TC 260), which is jointly administered by the CAC and the Standardization Administration of China, published a draft Standard on Information Security Technology Security Requirements for Data Collected by Connected Vehicles. The Standard sets forth security requirements for data collection to ensure compliance with other laws and facilitate a safe environment for networked vehicles. Standards like this are an essential component of corporate governance in China and notably fill in compliance gaps left in the law.
The publication of the draft regulation and the draft standard indicate that the Chinese government is turning its attention towards the data and security practices of the connected cars industry. Below we explain the key aspects of this draft regulation, summarize some of the noteworthy provisions, and conclude with the key takeaways for everyone in the car ecosystem.
Broad scope of covered entities: from OEMs to online ride-hailing companies
The draft regulation aims to strengthen the protection of “personal information” and “important data,” regulate data processing related to cars, and maintain national security and public interests. The scope of application of this draft regulation is fairly broad, both in terms of who it applies to and the types of data it covers.
The draft regulation applies to “operators” that collect, analyze, store, transmit, query, utilize, delete, and provide (activities collectively referred to as processing) personal information or important information overseas (during the design, production, sales, operation, maintenance, and management of cars) and “within the territory of the People’s Republic of China.”
“Operators” are entities that design or manufacture cars, or service institutions such as OEMs (original equipment manufacturers), component and software providers, dealers, maintenance organizations, online car-hailing companies, insurance companies, etc. (Note: The draft regulation includes “etc.,” here and throughout, which appears to mean that it is a non-exhaustive list.)
Covered data: Distinction among “personal information,” “important data,” and “sensitive personal information”
The draft regulation considers three data types, with an emphasis on “personal information” and “important data”, which are defined terms under Article 3. In addition, there is also a third type mentioned within the draft, at Article 8, and in a separate press release document: “sensitive personal information.”
Personal information includes data from car owners, drivers, passengers, pedestrians, etc. (non-exhaustive list) and also includes information that can infer personal identity and describe personal behavior. This is a broad definition and is notable because it explicitly includes information about passengers and pedestrians. As the business models evolve and the ecosystem of players in the car space grows, it has become more important to consider individuals other than just the driver or registered user of the car. The draft regulation appears to use the words “users” and “personal information subjects” when referring to this group of individuals broadly and also uses “driver,” “owner,” and “passenger” throughout.
The second type of data covered is “important data,” which includes:
Data on the flow of people and vehicles in important sensitive areas such as military management zones, national defense science and industry units involving state secrets, and party and government agencies at or above the county level;
Surveying and mapping data higher than the accuracy of the publicly released maps of the state;
Operating data of the car charging network;
Data such as vehicle types and vehicle flow on the road;
External audio and video data including faces, voices, license plates, etc.;
Other data that may affect national security and public interests as specified by the State Cyberspace Administration and the relevant departments of the State Council.
The inclusion of this data type is notable because it is defined in addition to “sensitive personal information” and includes data about users and infrastructure (i.e., the car charging network). Article 11 prescribes that when handling important data, operators should report to the provincial cyberspace administration and relevant departments the type, scale, scope, storage location and retention period, the purposes for collection, whether it was shared with a third party, etc. in advance (presumably in advance of processing this type of data, but this is something that may need to be clarified).
The third type of data mentioned in the draft regulation is “sensitive personal information,” and this includes vehicle location, driver or passenger audio and video, and data that can be used to determine illegal driving. There are certain obligations for operators processing this type of data (Articles 8 and 16).
Article 8 prescribes that where “sensitive personal information” is collected or provided outside of the vehicle, operators must meet certain obligations:
Ensuring that it is for the purpose of directly serving the driver or passenger (e.g., enhancing driver safety, assisting driving, navigation, entertainment, etc.),
Informing the driver and passengers that this data is being collected through a display panel or voice in the car,
Ensuring that the driver consents and authorizes the collection each time they enter the car (the default is not to collect),
Allowing the driver to terminate data collection at any time,
Allowing the vehicle owner to view and make inquiries about the sensitive personal information collected, and
Enabling deletion of this data upon request by the driver (the operator shall delete it within two weeks).
The definitions of these three types of data mirror similar definitions in other Chinese laws or draft laws currently being considered for adoption, such as the Civil Code and, respectively, the Personal Information Protection Law and the Cybersecurity Law. Consistency across these laws indicates a harmonization of China’s emerging data governance regulatory model.
Obligations based on the Fair Information Practice Principles
Articles 4 – 10 include many of the fair information practice principles, such as purpose specification and data minimization in Article 4 and security safeguards in Article 5, as well as privacy by design (Articles 6(4), 6(5), and 9). There are a few notable provisions worth discussing in more detail which are organized under the following headings below: local processing, transparency and notice, consent and user control, biometric data, annual data security management, and violations and penalties.
Local (“on device”) processing
Personal information and important data should be processed inside the vehicle, wherever possible (Article 6(1)). Where data processing outside of the car is necessary, operators should ensure the data has been anonymized wherever possible (Article 6(2)).
Transparency and Notice
When processing personal information, the operator is required to give notice of the types of data being collected and provide the contact information for the person responsible for processing user rights (Article 7). This notice can be provided through user manuals, onboard display panels, or other appropriate methods. The notice should include the purpose for collection, the moment that personal information is collected, how users can stop the collection, where and for how long data is stored, and how to delete data stored in the car and outside of the vehicle.
Regarding sensitive personal information (Article 8(3)), the operator is obliged to inform the driver and passengers that this data is being collected through a display panel or a voice in the car. This provision does not include “user manuals” as an example of how to provide notice, which potentially means that this data type is worthy of more active notice than personal information. This is notable because operators cannot rely on notice being given through a privacy notice placed on a website or in the car’s manual.
Consent and User Control, including a two-week deletion deadline
Article 9 requires operators to obtain consent to collect personal information, except where laws do not require consent. This provision notes that consent is often difficult to obtain (e.g., collecting audio and video of pedestrians outside the car). Because of this difficulty, data should only be collected when necessary and should be processed locally in the vehicle. Operators should also employ privacy by design measures, such as de-identification on devices.
Article 8(2) (requirements when collecting sensitive personal information) requires operators to obtain the driver’s consent and authorization each time the driver enters the car. Once the driver leaves the driver’s seat, that consent session has ended, and a new one must begin once the driver gets back into the seat. The driver must be able to stop the collection of this type of data at any time, be able to view and make inquiries about the data collected, and request the deletion of the data (the operator has two weeks to delete the data). It is worth noting that Article 8 includes six subsections, some of which appear to apply only to the driver or owner and not passengers or pedestrians.
These consent and user control requirements are quite notable and would have a non-trivial impact on the design of the car, the user experience, as well as the internal operations of the operator. It could potentially impact the user experience negatively if consent and authorization were required each time the driver got into the driver’s seat. For example, a relevant comparable experience is using a website and facing the consent-related pop-ups that must be closed out before being able to read or use the website at every visit. Furthermore, stopping the collection of location data, video data, and other telematics data (if used to determine illegal driving) could also present safety and functionality risks and cause the car not to operate as intended or safely. These are some of the areas where stakeholders are expected to submit comments for the public consultation.
Biometric data
Biometric data is mentioned throughout the draft regulation, as this type of data is implicitly or explicitly included in the definitions of personal information, important data, and sensitive personal information. Biometric data is specifically mentioned in Article 10, which is about the biometric data of drivers. Biometric data is an increasingly common data type collected by cars and deserves special attention. Article 10 would require that the biometric data of the driver (e.g., fingerprints, voiceprints, faces, heart rhythms, etc.) only be collected for the convenience of the user or to increase the security of the vehicle. Operators should also provide alternatives to biometrics.
Data localization
Articles 12-15 and 18 concern data localization. Both personal information and important data should be stored within China, but if it is necessary to store elsewhere, the operator must complete an “outbound security assessment” through the State Cyberspace Administration, and the operator is permitted to send only the data specified in that assessment overseas. The operator is also responsible for overseeing the overseas recipient’s use of the data to ensure appropriate security and for handling all user complaints.
Annual data security management status
Article 17 places additional obligations on operators to report their annual data security management status to relevant authorities before December 15 of each year when:
They process personal information of more than 100,000 users, or
They process important data.
Given that this draft regulation applies to passengers and pedestrians in addition to drivers, it would not take long for the threshold of 100,000 users to be met, especially for operators who manage a fleet of cars for rental or ride-hail. Additionally, since the definitions of personal information and important data are so broad, it is likely that many operators would trigger this reporting obligation. The obligations include recording the contact information of the person responsible for data security and handling user rights; recording relevant information about the scale and scope of data processing; recording with whom data is shared domestically; and other security conditions to be specified. If data is transferred overseas, there are additional obligations (Article 18).
Violations and Penalties
Violation of the regulations would result in punishment in accordance with the “Network Security Law of the People’s Republic of China” and other laws and regulations. Operators may also be held criminally responsible.
Conclusion
China’s draft car privacy and security regulation provides relevant information for policymakers and others thinking carefully about privacy and data protection regarding cars. The draft regulation’s scope is very broad and includes many players in the mobility ecosystem beyond OEMs and suppliers (e.g., online car-hailing companies and insurance companies).
With regards to user rights, the draft regulation recognizes that other individuals, in addition to the driver, will have their personal information processed and provides data protection and user rights to these individuals (e.g., passengers and pedestrians). The draft regulation would apply to three broad categories of data (personal information, important data, and sensitive personal information).
In privacy and data protection laws from the EU to the US, we have continued to see different obligations arise depending on the type or sensitivity of data and how data is used. This underscores the need for organizations to have a complete data map; indeed, it is crucial that all operators in the connected and automated car ecosystem have a sound understanding of what data is being collected from which person and where that data is flowing.
The draft regulation also highlights the importance of transparency and notice, as well as the challenges of consent and user control. It is a challenge to appropriately notify drivers, passengers, and pedestrians about all of the data types being collected by a vehicle.
Privacy and data protection laws will have a direct impact on the design, user experience, and even the enjoyment and safety of cars. It is crucial that all stakeholders are given the opportunity to provide feedback in the drafting of privacy and data protection laws that regulate data flows in the car ecosystem and that privacy professionals, engineers, and designers become much more comfortable working together to operationalize these rules.
Automated Decision-Making Systems: Considerations for State Policymakers
In legislatures across the United States, state lawmakers are introducing proposals to govern the uses of automated decision-making systems (ADS) in record numbers. In contrast to comprehensive privacy bills that would regulate collection and use of personal information, automated decision-making system (ADS) bills in 2021 specifically seek to address increasing concerns about racial bias or unfair outcomes in automated decisions that impact consumers, including housing, insurance, financial, or governmental decisions.
So far, ADS bills have taken a range of approaches, with most prioritizing restrictions on government use and procurement of ADS (Maryland HB 1323); requiring inventories of government ADSs currently in use (Vermont H 0236); impact assessments for procurement (CA AB-13); external audits (New York A6042); or outright prohibitions on the procurement of certain types of unfair ADS (Washington SB 5116). A handful of others would seek to regulate commercial actors, including in insurance decisions (Colorado SB 169), consumer finance (New Jersey S1943), or the use of automated decision-making in employment or hiring decisions (Illinois HB 0053, New York A7244).
At a high level, each of these bills share similar characteristics. Each proposes general definitions and general solutions that cover specific, complex tools used in areas as varied as traffic forecasting and employment screening. But the bills are not consistent with regard to requirements and obligations. For example, among the bills that would require impact assessments, some require impact assessments universally for all ADS in use by government agencies, others would require impact assessments only for specifically risky uses of ADS.
As states evaluate possible regulatory approaches, lawmakers should: (1) avoid a “one size fits all” approach to defining automated decision-making by clearly defining the particular systems of concern; (2) consult with experts in governmental, evidence-based policymaking; (3) ensure that impact assessments and disclosures of risk meet the needs of their intended audiences; (4) look to existing law and guidance from other state, federal, and international jurisdictions; and (5) ensure appropriate timelines for technical and legal compliance, including time for building capacity and attracting qualified experts.
1. Avoid “one size fits all” solutions by clearly identifying the automated decision-making systems of concern.
An important first step to the regulation of automated decision-making systems (“ADS”) is to identify the scope of systems that are of concern. Many lawmakers have indicated that they are seeking to address automated decisions such as those that use consumer data to create “risk scores,” creditworthiness profiles, or other kinds of profiles that materially impact our lives and involve the potential for systematic bias against categories of people. But, the wealth of possible forms of ADS and the many settings for their use can make defining these systems in legislation very challenging.
Automated systems are present in almost all walks of modern life, from managing wastewater treatment facilities to performing basic tasks such as operating traffic signals. ADS can automate the processing of personal data, administrative data, or myriad forms of other data, through the use of tools ranging in complexity from simple spreadsheet formulas, to advanced statistical modeling, rules-based artificial intelligence, or machine learning. In an effort to navigate this complexity, it can be tempting to draft very general definitions of ADS. However, these definitions risk being overbroad and capturing ADS systems that are not truly of concern — i.e. because they do not impact people or carry out significant decision-making.
For example, a definition such as “a computational process, including one derived from machine learning, statistics, or other data processing or artificial intelligence techniques, thatmakes a decision or facilitates human decision-making” (New Jersey S1943) would likely include a wide range of traditional statistical data processing, such as estimating average number of vehicles per hour on a highway to facilitate automatic lane closures in intelligent traffic systems. This would place an additional, significant requirement for conducting complex impact assessments for many of the tools behind established operational processes. In contrast, California’s AB-13 takes a more tailored approach, aiming to regulate “high-risk application[s]” of algorithms that involve “a score, classification, recommendation, or other simplified output,” that support or replace human decision-making, in situations that “materially impact a person” (12115(a)&(b)).
In general, compliance-heavy requirements or prohibitions on certain practices may be appropriate only for some high-risk systems. The same requirements would be overly prescriptive or infeasible for systems powering ordinary, operational decision-making. Successfully distinguishing between high-risk use cases and those without significant, personal impact will be crucial to crafting tailored legislation that addresses the targeted, unfair outcomes without overburdening other applications.
Lawmakers should ask questions such as:
Who owns or is responsible for the ADS? Is the system being used by government decision-makers, commercial actors, or both (private vendors contracted by government agencies)? The relevant “owner” of a system may determine the right balance of transparency, accountability, and access to underlying data necessary to accomplish the legislative goals.
What kind of data is involved? Many systems use a wide range of data that may or may not include personal information (information related to reasonably identifiable individuals), and may or may not include “sensitive data” (personal data that reveals information about race, religion, health conditions, or other highly personal information). In some cases, non-sensitive data can act as a “proxy” for sensitive information (such as the use of zip code as a proxy for race). Data may also be obtained from sources of varying quality, accuracy, or ethical collection, for example: public records, government collection, regulated commercial sectors (banks or credit agencies), commercial data brokers, or other commercial sources.
Who is impacted by the decision-making? Does the decision-making impact individuals, groups of individuals, or neither? Is there a possibility for disparate impact in who is affected, i.e. that certain races, genders, income levels, or other categories of people will be impacted differently or worse than others?
Is the decision-making legally significant? In most cases, our tolerance for automated decision-making depends on the decision being made. Some decisions are commonplace or operational, such as automated electrical grid management. Other decisions are so relevant to our individual lives and autonomy that use of automated systems in this context demands greater transparency, human involvement, or even auditing such as: financial opportunities, housing, lending, educational opportunities, or employment. Still other decisions may be in a “grey area”: for example, automated delivery of online advertisements is common, but questions about algorithmic bias in ad quality or who sees certain types of ads (e.g. ads for particular jobs) are leading to increasing scrutiny.
Does the system assist human decision-making or replace it? Some systems replace human decision-making entirely, such as when a system generates an automated approval or denial of a financial opportunity that occurs without human review. Other systems assist human decision-makers by generating outputs such as scores or classifications that allow decision-makers to complete tasks, such as grading a test or diagnosing a health condition.
When do “meaningful changes” occur? Many legislative efforts seek to trigger requirements for new or updated impact assessments when ADSs change, or “meaningfully change.” For such requirements, lawmakers should establish clear criteria for what constitutes a “meaningful change.” For example, machine learning systems that adapt based upon a stream of sensor or customer data change constantly, whether by changing the weights attached to features or by eliminating features. Whether adaptations made as a consequence of typical machine learning operations constitute meaningful changes is an important question best poised to be answered in ways specific to each learning and adapting system. The velocity and variety of changes to ADS driven by machine learning may require other forms of ongoing assessment to identify abnormalities or potential harms as they arise.
These questions can help guide legislative definitions and scope. A “one size fits all” solution not only risks creating burdensome requirements in situations where they are not needed, but is also less likely to ensure stronger requirements in situations where they are needed — leaving potentially biased algorithms to operate without sufficient review or standards to address resulting outcomes that are biased or unfair. An appropriate definition is a critical first step for effective regulation.
2. Consult with experts in governmental, evidence-based policymaking.
Evidence-based policymaking legislation, popular in the late 1990s and early 2000s, required states to construct systems to eradicate human bias by employing data-driven practices for key areas of state decision-making, such as criminal justice, student achievement predictions, and even land use planning. For example, as defined by the National Institute of Corrections, the vision for implementing evidence based practice in community corrections is “to build learning organizations that reduce recidivism through systematic integration of evidence-based principles in collaboration with community and justice partners” (see resources at the Judicial Council of California 2021). The areas chosen for application of evidence-based policymaking are presently causing high degrees of concern about applications of ADS as the mechanisms for ensuring use of evidence and elimination of subjectivity. Examining the goals envisioned in evidence-based policymaking legislation may clarify whether ADS are appropriate tools for satisfying those goals.
In addition to consulting the policies encouraging evidence-based making in order to identify the goals for automated decision-making systems (ADSs) the evidence-based research findings reviewed to support this legislation can also direct legislators to contextually relevant, expert, sources of data that should be incorporated into ADS or into the evaluation of ADS. Likewise, legislators should reflect on the challenges to implementation of effective evidence-based decision-making, such as unclear definitions, poor data quality, challenges to statistical modelling, and a lack of interoperability of public data sources, as these challenges are similar to those complicating use of ADS.
3. Ensure that impact assessments and disclosures of risk meet the needs of their intended audiences.
Most ADS legislative efforts aim to increase transparency or accountability through various forms of mandated notices, disclosures, data protection impact assessments, or other risk assessments and mitigation strategies. These requirements serve multiple, important goals, including helping regulators understand data processing, and increasing internal accountability through greater process documentation. In addition, public disclosures of risk assessments benefit a wide range of stakeholders, including: the public, consumers, businesses, regulators, watchdogs, technologists, and academic researchers.
Given the needs of different audiences and users of such information,lawmakers should ensure that impact assessments and mandated disclosures are leveraged effectively to support the goals of the legislation. For example, where legislators intend to improve equity of outcomes between groups, they should include legislative support for tools to improve communication to these groups and to support incorporation of these groups into technical communities. Where sponsors of ADS bills intend to increase public awareness of automated decision-making in particular contexts, legislation should require and fund consumer education that is easy to understand, available in multiple languages, and accessible to broad audiences. In contrast, if the goal is to increase regulator accountability and technical enforcement, legislation might mandate more detailed or technical disclosures be provided non-publicly or upon request to government agencies.
The National Institutes of Standards and Technology (NIST) has offered recent guidance on explainability in artificial intelligence that might serve as a helpful model for ensuring that impact assessments are useful for the multiple audiences they may serve. The NIST draft guidelines suggest four principles for explainability for audience sensitive, purpose driven, ADS assessment tools: (1) Systems offer accompanying evidence or reason(s) for all outputs; (2) Systems provide explanations that are understandable to individual users; (3) The explanation correctly reflects the system’s process for generating the output; and (4) The system only operates under conditions for which it was designed or when the system reaches a sufficient confidence in its output (p.2). These four principles shape the types of explanations needed to ensure confidence in algorithmic or automated decision-making systems (ADSs), such as explanations for user benefit, for social acceptance, for regulatory and compliance purposes, for system development, and for owner benefit (p. 4-5).
Similarly, the European Commission’s Guidelines on Automated Individual Decision-Making and Profiling provides recommendations for complying with the GDPR’s requirement that individual users be given “meaningful information about the logic involved.” Rather than requiring a complex explanation or exposure of the algorithmic code, the Commission explains that a controller should find simple ways to tell the data subject the rationale behind, or the criteria relied upon to reach a decision. This may include which characteristics are considered to make a decision, the source of the information, and its relevance. It should not be overly technical, but sufficiently comprehensive for a consumer to understand the reason for the decision.
Regardless of the audience, mandated disclosures should be used cautiously as, especially when made public, such disclosures can also create certain risks, such as opportunities for data breaches, exfiltration of intellectual property (IP), or even attacks on the algorithmic system which could identify individuals or cause the systems to behave in unintended ways.
4. Look to existing law and guidance from other state, federal, and international jurisdictions.
Although US lawmakers have specific goals, needs, and concerns driving legislation in their jurisdictions, there are clear lessons to be learned from other regimes with respect to automated decision-making. Most significantly, there has been a growing, active wave of legal and technical guidance in the European Union in recent years regarding profiling and automated decision-making, following the passage of the GDPR. Lawmakers may also seek to ensure interoperability with the newly passed California Privacy Rights Act (CPRA) or Virginia Consumer Data Protection Act (VA-CDPA), both of which create requirements that impact automated decision-making, including profiling. Finally, the Federal Trade Commission enforces a number of laws that could be harnessed to address concerns about biased or unfair decision-making. Of note, Singapore is also a leader in this space, launching their Model AI Governance Framework in 2019. It is useful to understand the advantages or limitations of each model and to recognize the practical challenges of adapting systems for each jurisdiction.
General Data Protection Regulation (GDPR)
The EU General Data Protection Regulation (GDPR) broadly regulates public and private collection of personal information. This includes a requirement that all data processing be fair (Art. 5(1)(a)). The GDPR also creates heightened safeguards specifically for high risk automated processing that impact individuals, especially with respect to decisions that produce legal, or other significant, effects concerning individuals. These safeguards include organizational responsibilities (data protection impact assessments); and individual empowerment provisions (disclosures, and the right not to be subject to certain kinds of decisions based solely on automated processing).
Organizational Responsibilities. Data protection impact assessments (DPIAs) required under the GDPR for “high risk” processing activities, must include a systematic description of the envisaged processing operations and the purposes of the processing, an assessment of the necessity and proportionality of the processing operations in relation to the purposes, an assessment of the risks to the rights and freedoms of data subjects, and measures envisaged to address the risks, including safeguards, security measures and mechanisms to ensure the protection of personal data. Recital 75 of the GDPR, which details the Art. 35 DPIA requirements, provides details about the nature of the data processing risks intended to be covered. In addition the GDPR requires all automated processing to incorporate technical and organizational measures to implement data protection by design principles (Art. 25).
Individual Control. In addition to providing organizational responsibilities such as data protection impact assessments (DPIAs), the GDPR also requires controllers to provide data subjects with information relating to their automated processing activities (Art. 13 & 14). In particular, controllers must disclose the existence of automated decision-making, including profiling, meaningful information about the logic involved, and the significance and envisaged consequences of processing for the data subject. These disclosures are required when personal data is collected from a data subject, and also when personal data is not obtained from a data subject. In addition, the GDPR creates the right for an individual not to be subject to decisions based solely on automated processing which produce legal, or similarly significant, effects concerning an individual (Art. 22). Suitable measures to safeguard the data subject’s rights, freedoms, and legitimate interests include the rights for an individual to: (1) obtain human intervention on the part of the controller (human in the loop), (2) express their point of view, and (3) contest a decision.
California Privacy Rights Act (CRPA)
The California Privacy Rights Act (CPRA), passed via Ballot Initiative in 2020, expands on the California Consumer Privacy Act (CCPA)’s requirements that businesses comply with consumer requests to access, delete, and opt-out of the sale of consumer data.
While the CPRA does not create any direct consumer rights or organizational responsibilities with respect to automated decision-making, its consumer access rights includes access to information about “inferences drawn . . . to create a profile” (Sec. 1798.140(v)(1)(K)) and most likely information about the use of the consumer’s data for automated decision-making.
Notably, the CPRA added a new definition of “profiling” to the CCPA, while authorizing the new California oversight agency to engage in rulemaking. In alignment with the GDPR, the CPRA defines “profiling” as “any form of automated processing of personal Information . . . to evaluate certain personal aspects relating to a natural person, and in particular to analyze or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behavior, location or movements” (1798.140(z)).
The CPRA authorizes the new California Privacy Protection Agency to issue regulations governing automated decision-making, including “governing access and opt‐out rights with respect to businesses’ use of [ADS], including profiling and requiring businesses’ response to access requests to include meaningful information about the logic involved in such decision-making processes, as well as a description of the likely outcome of the process with respect to the consumer.” (1798.185(a)(16)). Notably, this language lacks the GDPR’s “legal or similarly significant” caveat, meaning that the CPRA requirements around access and opt-outs may extend to processing activities such as targeted advertising based on profiling.
Virginia Consumer Data Protection Act (VA-CDPA)
The Virginia Consumer Data Protection Act (VA-CDPA), which passed in 2021 in Virginia and will come into effect in 2023, takes an approach towards automated decision-making inspired by both the GDPR and CPRA.
First, its definition of “profiling” aligns with that of the GDPR and CPRA (§ 59.1-571). Second, it imposes a responsibility upon data controllers to conduct data protection impact assessments (DPIAs) for high risk profiling activities (§ 59.1-576). Third, it creates a right for individuals to opt out of having their personal data processed for the purpose of profiling in the furtherance of decisions that produce legal or similarly significant effects concerning the consumer (§ 59.1-573(5)).
Organizational Responsibilities. The VA-CDPA requires data controllers to conduct and document data protection impact assessments (DPIAs) for “profiling” that creates a “reasonably foreseeable risk of (i) unfair or deceptive treatment of, or unlawful disparate impact on, consumers; (ii) financial, physical, or reputational injury to consumers; (iii) a physical or other intrusion upon the solitude or seclusion, or the private affairs or concerns, of consumers, where such intrusion would be offensive to a reasonable person; or (iv) other substantial injury to consumers.” These DPIA’s are required to identify and weigh the benefits against the risks that may flow from the processing, as mitigated by safeguards employed to reduce such risks. They are not intended to be made public or provided to consumers. Instead, these confidential documents must be made available to the State Attorney General upon request, pursuant to an investigative civil demand.
Individual Control. The VA-CDPA grants consumers the right to submit an authenticated request to opt-out of the processing of personal data for purposes of profiling “in the furtherance of decisions that produce legal or similarly significant effects concerning the consumer,” which is defined as “a decision made by the controller that results in the provision or denial by the controller of financial and lending services, housing, insurance, education enrollment, criminal justice, employment opportunities, health care services, or access to basic necessities, such as food and water.”
The FTC Act and broadly applicable consumer protection laws
Finally, a range of federal consumer protection and sectoral laws already apply to many businesses’ uses of automated decision-making systems. The Federal Trade Commission (FTC) enforces long-standing consumer protection laws prohibiting “unfair” and “deceptive” trade practices, including the FTC Act. As recently as April 2021, the FTC warned businesses of the potential for enforcement actions for biased and unfair outcomes in AI, specifically noting that the “sale or use of – for example – racially biased algorithms” would violate Section 5 of the FTC Act.
The FTC also noted its decades of experience enforcing other federal laws that are applicable to certain uses of AI and automated decisions, including the Fair Credit Reporting Act (if an algorithm is used to deny people employment, housing, credit, insurance, or other benefits), and the Equal Credit Opportunity Act (making it “illegal for a company to use a biased algorithm that results in credit discrimination on the basis of race, color, religion, national origin, sex, marital status, age, or because a person receives public assistance”).
Comparison chart:
5.Ensure appropriate timelines for technical and legal compliance, including building capacity and attracting qualified experts.
In general, timelines for government agencies and companies to comply with the law should be appropriate to the complexity of the systems that will be needed to review for impact. Many government offices may not be aware that the systems they use every day to improve throughput, efficiency, and effective program monitoring may constitute “automated decision-making.” For example, organizations using Customer Relations Management (CRM) software from large vendors may be using predictive and profiling systems built into that software. Also, governmental offices suffer from siloed procurement and development strategies and may have built or purchased overlapping ADS to serve specific, sometimes narrow, needs.
Lack of government funding, modernization, or resources to address the complexity of the systems themselves, and the lack of prior requirements for tracking automated systems in contracts or procurement decisions, means that many agencies will not readily have access to technical information on all systems in use. Automated decision-making systems (ADSs) have been shown to suffer from technological debt, opaque and incomplete technical documentation, or are dependent on smaller automated systems that can only be discovered through careful review of source code and complex information architectures.
Challenges such as these were highlighted during 2020 as a result of the COVID-19 pandemic, which prompted millions to pursue temporary unemployment benefits. When applications for unemployment benefits surged, some state unemployment agencies discovered that their programs were written in the infrequently used programming language, COBOL. Many resource-strapped agencies were using stop-gap code, intended for temporary use, to translate COBOL into more contemporary coding languages. As a result, many agencies lacked programming experts and capacity to efficiently process the influx of claims. Regulators should ensure that offices have time, personnel, and funding to undertake the digital archaeology necessary to reveal the many layers of ADSs used today.
Finally, lawmakers should not overlook the challenges of identifying and attracting qualified technical and legal experts. For example, many legislative efforts envision a new or expanded government oversight office with the responsibility to review automated impact assessments. Not only will the personnel needed for these offices need to be able to meaningfully interpret algorithmic impact assessments, they will need to do so in an environment of high sensitivity, publicity, and technological change. As observed in many state and federal bills calling for STEM and AI workforce development, the talent pipeline is limited and legislatures should address the challenges of attracting appropriate talent as a key component of these bills. Likewise, identifying appropriate expectations of performance, including ethical performance, for ADS review staff will take time, resources, and collaboration with new actors, such as the National Society of Professional Engineers, whose code of conduct governs many working in fields responsible for designing or using ADS.
What’s Next for Automated Decision System Regulation?
States are continuing to take up the challenge of regulating these complex and pervasive systems. To ensure that these proposals achieve their intended goals, legislators must address the ongoing issues of definition, scope, audience, timelines and resources, and mitigating unintended consequences. More broadly, legislation should help motivate more challenging public conversations about evaluating the benefits and risks of using ADS as well as the social and community goals for regulating these systems.
At the highest level, legislatures should bear in mind that ADS are engineered systems or products that are subject to product regulations and ethical standards for those building products. In addition to existing laws and guidance, legislators can consult the norms of engineering ethics, such as the NSPE’s code of ethics, which requires that engineers ensure their products are designed so as to protect as paramount the safety, health and welfare of the public. Stakeholder engagement, including with consumers, technologists, and the academic community, is imperative to ensuring that legislation is effective.
FPF Ethical Data Use Committee will Support Research Relying on Private Sector Data
FPF has launched an independent ethical review committee to provide oversight for research projects that rely upon sharing of corporate data with researchers. Whether researchers are studying the impact of platforms on society, supporting evidence based policymaking, or understanding issues from COVID to climate change, personal data held by companies is increasingly essential to advancing scientific knowledge.
Companies want to be able to cooperate with researchers to use data and machine learning tools to drive innovation and investment, while ensuring compliance with data protection rules and ethical guidelines. To accomplish this, some companies are ramping up their internal ethical knowledge base and staff. However, reviewing high-risk, high-reward analytics projects in-house can be expensive, complex, and may lead to accusations of favoritism or ethics-washing. Traditional academic IRBs may consider the corporate data previously collected for business uses to be out of scope of their review, creating a gap for independent expert ethical review.
Many of the projects that seek to expand human knowledge rely on insights derived from combinations of data and use of machine learning or other advanced data analysis techniques. Sharing data for research drives innovation but it may also create novel risks that must be responsibly considered.
The FPF Ethical Data Use Committee (EDUC) provides companies and their research partners with ethics review as a service. The EDUC will provide an independent expert review of proposed research data uses to help companies limit the risks of unintended outcomes or data-based discrimination. The committee also will help researchers ensure ethical alignment with their uses of secondary data. As part of the review, the committee will provide specific recommendations for companies and researchers to implement that could mitigate the identified risks of individual and group or social harms. These reviews are particularly useful for many uses of data, including for machine-learning based research, models or systems.
The Committee – designed and developed with the generous support of Schmidt Futures and building on previous FPF work funded by the Alfred P Sloan Foundation and the National Science Foundation – will include experts from a range of disciplines, including academic researchers, ethicists, technologists, privacy professionals, lawyers, and others. They will complete training on data protection and privacy, AI and analytics, applied ethics, and other topics in addition to their own expertise, to serve terms on the Committee. Technical specialists will also be tapped for guidance on specific topic areas as required.
At this time, the Ethical Data Use Committee is preparing for final user-preference pilot testing. We are soliciting partners who aspire to be the first to use this system under cost conditions that will not be available once the review committee becomes fully operational. Companies and researchers participating in this final testing phase can do so confidentially, at no cost, if you provide feedback on the process.
If you have a project that you think should be reviewed by the Ethical Data Use Committee or if you would like to recommend yourself or someone else as a member for the inaugural review term, please contact Dr. Sara Jordan at [email protected].
FPF Welcomes New Members to the Youth & Education Privacy Team
We are thrilled to announce two new members of FPF’s Youth & Education Privacy team. The new staff – Joanna Grama and Jim Siegl – will help expand FPF’s technical assistance and training, resource creation and distribution, and state and federal legislative tracking.
You can read more about Joanna and Jim below. Please join us in welcoming them to the team!
Joanna Grama is a Senior Fellow with the Future of Privacy Forum’s Youth and Education team. Joanna will be assisting with various Youth and Education team projects, including the Train-the-Trainer program for higher education.
Joanna has more than 20 years of experience with a strong focus in law, higher education, data privacy, and information security. A former member of the U.S. Department of Homeland Security’s Data Privacy and Integrity Advisory Committee, Joanna is a frequent author and regular speaker on privacy and information security topics. The third edition of her textbook, LEGAL AND PRIVACY ISSUES IN INFORMATION SECURITY, was published in late 2020.
An associate vice president at Vantage Technology Consulting Group, Joanna is also a board member and vice president for the Central Indiana chapter of the Information Systems Audit and Control Association (ISACA); and a member of the International Association for Privacy Professionals (IAPP), the American Bar Association, Section of Science and Technology Law (Information Security Committee), and the Indiana State Bar Association (Written Publications Committee). She has earned the CISSP, CIPT, CRISC, and GSTRT certifications.
Joanna was formerly the Director of Cybersecurity and IT Governance, Risk and Compliance programs at EDUCAUSE. Joanna graduated from the University of Illinois College of Law with honors. Her undergraduate degree is from the University of Minnesota-Twin Cities.
“I have spent my career looking at technology use in higher education through a lens that includes law, policy, information security, and privacy. Joining FPF, and the Youth and Education Privacy team in particular, is a “bucket list” opportunity for me. I am excited to contribute thought leadership around student data privacy issues during a time of great technological change.”
Jim Siegl
Jim Siegl, CIPT, is a Senior Technologist with the Youth & Education Privacy team. For nearly two decades prior to joining FPF, Jim was a Technology Architect for the Fairfax County Public School District with a focus on privacy, security, identity management, interoperability, and learning management systems. He was a co-author of the CoSN Privacy Toolkit and the Trusted Learning Environment (TLE) seal program and holds a Master of Science in the Management of Information Technology from the University of Virginia.
“I am excited about joining FPF’s Youth & Education Privacy team during such a unique moment in time for student privacy. I’m looking forward to being a resource to stakeholders as they navigate new and existing student privacy concerns.”
Interested in student privacy? Subscribe to our monthly education privacy newsletter here. Want more info? Check out Student Privacy Compass, the education privacy resource center website.








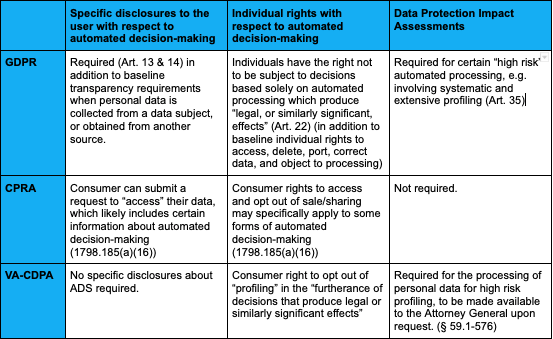

 Jim Siegl
Jim Siegl