Machine Learning and Speech: A Review of FPF’s Digital Data Flows Masterclass
On Wednesday, December 9, 2020, FPF hosted a Digital Data Flows Masterclass on Machine Learning and Speech. The masterclass on Machine Learning and Speech is the first masterclass of a new series after completing the VUB-FPF Digital Data Flows Masterclass series with eight topics.
Professor Marine Carpuat (Associate Professor in Computer Science at the University of Maryland) starts with an introduction on the more advanced aspects of (un)supervised learning. One of the unique takeaways of the presentation is that Prof. Carpuat’s explanation of mathematical models to an audience without a mathematical background is second to none. Dr. Prem Natarajan (VP, Alexa AI-Natural Understanding) guides us through the intricacies of Machine Learning in the context of voice assistants. As a practitioner, Dr. Natarajan brings unique examples to this class. The presenters explored the differences between supervised, semi-supervised, and unsupervised machine learning (ML) and the impact of these recent technical developments on machine translation and speech recognition technologies. In addition, they briefly explored the history of machine learning to draw lessons from the long-term development of artificial intelligence and put new advancements in context. FPF’s Dr. Sara Jordan and Dr. Rob van Eijk moderated the discussion following expert overviews.
As a sub-field of computational linguistics, machine translation studies the use of software to translate text or speech from one language to another. Applications that use machine translation find the best fit for a translation based on probabilistic modelling. This means that for any given sentence in a language, translation models will find the highest probability of resemblance to a human translation and use that sentence in a translation.
Machine translation has made considerable progress over the years. Previous models would break down simple sentences into individual words without taking into account the context of the sentence itself. This often led to incomplete, simplistic, or wholly incorrect translations. The introduction of deep learning and neural networks to machine translation greatly increased the quality and fluency of these translations by allowing translation tools to put the meaning of each word within the overall context of the sentence.
Yet for all the progress, many challenges lay ahead. Deep learning requires very large datasets and paired translation examples (e.g., English to French), which might not exist for certain languages. Even when there is a large pool of data, sentences often have multiple correct translations, which poses additional problems for machine learning. In addition, the deployment of these models in the real world has also raised concerns, as translation errors can sometimes have severe consequences.
Machine translation tools generally use sequence-to-sequence models (Seq2Seq) that share architecture with word embedding and other representation models. Seq2Seq models convert sequences from one language (e.g., English) to generate text in another (e.g., French). Seq2Seq models form the backbone of more accurate natural language processing (NLP) tools due to their use of recurrent neural networks (RNN), which allow models to take into account the context of the former input word when processing the next output word. Developers use Seq2Seq models for multiple use cases including dialogue construction, text summarization, question answering, image captioning, and style transfer.
Word embedding refers to language processing models that map words and phrases onto vector space of real numbers through neural networks or other probabilistic models. This allows translation models to reduce confusion arising from a large dimension of possible outputs and better represent the context of a sentence in which words appear. These tools generally increase the performance of Seq2Seq models and NLP generally because they help models understand the context in which words appear.
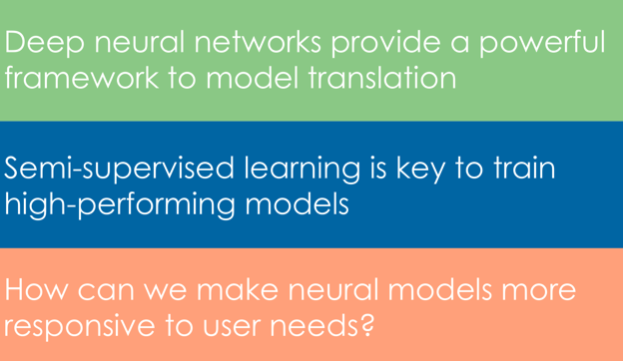
Figure 1. How to Train a Machine Learning Model?
How to Train a Machine Learning Model – Supervised, Unsupervised, and Semi-Supervised Learning
Training neural models with limited translation data poses multiple problems (see also, Figure 1). For instance, situations calling for a more formal translation need plenty of formal writing data to achieve accuracy and fluency. But issues may arise if the model must account for different writing styles or more informal contexts. Fortunately, developers can apply different training paradigms, including supervised, unsupervised, and semi-supervised learning, to better train models with diverse and limited translation data.
Supervised learning is a process of learning from labeled examples. Developers feed the model with instances of previous tests and answer keys to improve the model’s accuracy and precision. Supervised learning allows the model to match input source and output target sequences with correct translations through parallel sampling, which refers to sampling a limited subset of data for one language against a whole body of data for another. In other words, the translation model can learn from examples of text in one language to better calculate the probability of a correct translation in another. Under this type of learning, it is important to create parameters that give a high probability of success to avoid overfitting and make the model generalizable across contexts.
On the other end of the spectrum, unsupervised learning gives previous tests to the model without answer keys. Under this type of training, models learn by making connections between unpaired monolingual samples in each language. Put simply, machine translation models study individual words in a language (e.g., through a dictionary) and draw connections between those words. This helps the model find similarities or patterns in language across the data and predict the next word in a sentence from the previous word in that sentence.
Unsupervised learning is a simple yet powerful tool. It works extremely well when the developer has a large pool of data to help the model reinforce its understanding of the syntactic or grammatical structures between languages. For example, deep learning encodes an English sentence and plugs it into the French output model which then generates a translation based on the cross-lingual correspondences it learned through the data. While many applications of unsupervised learning are still at the proof of concept stage, this learning technique offers a promising avenue for language processing developers.
Finally, semi-supervised learning combines elements of both supervised and unsupervised learning and is the primary training method for translation models. The model learns from a multitude of unpaired samples (unsupervised learning) but then receives paired samples (supervised learning) to reinforce cross-lingual connections. Put simply, unsupervised training helps the model learn syntactic patterns in languages, while supervised training helps the model understand the full meaning of a sentence in context. Combinations of both training techniques strengthen syntactic and semantic connections simultaneously.
Limitations and Challenges of Machine Translation
While the accuracy and quality of machine translation have increased through supervised, unsupervised, and semi-supervised learning, there are still many obstacles to scale the 7,111 languages spoken in the world today. Indeed, while the lack of data poses its own challenges for training purposes, machine translation still runs into problems with adequacy, accuracy, and fluency in languages where plenty of data exists.
Developers have addressed these problems by attempting to quantify adequacy and compute the semantic similarity between machine translation and human translation. One common method is BLEU, which counts the exact matches of word sequences between human translation and the machine output. Another, BVSS, combines word pair similarity into a sentence score to measure a translation against a real-world output. In practice, developers need to use both metrics at the same time in order to make machine translation more adequate and fluent.
From a high-level perspective, neural models employing machine learning produce more fluent translations than older statistical models. Forward-looking models are beginning to build systems that adapt to different audiences and can incorporate other metrics of translation such as formality and style. While much work is needed in both supervised and unsupervised learning, case studies have already revealed a promising ground for future improvements.
Machine Learning and Speech
Many of the lessons learned in recent advancements of machine translation also apply to the area of speech recognition. The introduction of deep learning and automatic features in both fields has accelerated development, bringing more complexity and new challenges to training and refining machine learning models than what came before. As the application of machine translation and speech recognition become more prevalent in the economy, it is important to understand where the field came from and where it is going.
Like machine translation, speech recognition has a long history that stretches back to the invention of artificial intelligence (AI) as a formal academic discipline in the 1950s. The introduction of neural networks and statistical models in the 1980s and 1990s marked a watershed moment in the development of machine learning and speech. Inputting human interaction directly into the machine helped create trainable models and gave impetus to a variety of speech recognition projects.
Yet while the idea of machine learning through neural networking became widespread in the discipline, the lack of computing power and data inhibited its development. With widespread increases in computational power in the 1990s and 2000s, researchers were able to introduce automatic machine learning tools, which greatly accelerated the development of speech recognition and machine translation. But as automatic models became more sophisticated in identifying recognizing inputs and reducing recognition errors, these models also led to decreased interpretability.
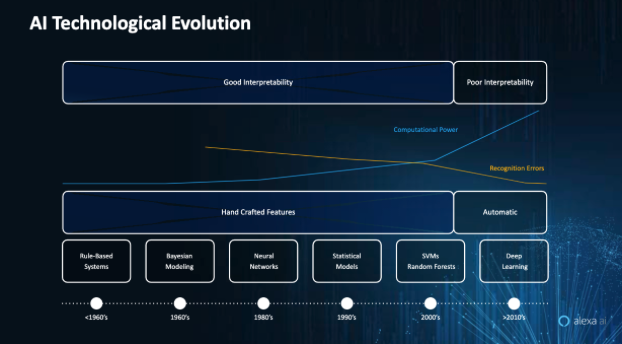
Figure 2. Historical overview of the technological evolution of AI/ML.
Since then, correcting for poor interpretability in these models has involved a range of training methods, including supervised and unsupervised learning. The widespread availability of data has helped this process because developers can now find novel ways to make automatic features more reliable and accurate.
As speech recognition technology begins to interface with humans through conversational AI, the competency of these models may greatly improve. This is because engaging with data in real time allows machine learning models to adapt to novel situations when presented with new information or new vocabulary that it did not previously know. To this end, research is currently moving in the direction of parameter defining and error evaluation in order to make training more accurate and effective.
To be sure, advancements in human-computer interface have a history going back to the era of Markov Models in the 1980s (see, Figure 2). However, today the proliferation of practical speech recognition applications fueled by automatic features has underscored a change in the pace of research. In addition, the role of data, including less labelled data, has also become increasingly important in the process of training models.
Advancements in Training Models
Indeed, present speech recognition technology utilizes a range of learning methods at the cutting edge of deep learning, including active learning, transfer learning, semi-supervised learning, learning to paraphrase, self-learning, and teaching AI.
Active learning refers to a training process where different loss functions divide training data in different ways to test the models adaptability to new contexts with the same data. Transfer learning data takes data-rich domains and finds ways to transfer learning to new domains that lack corresponding data. For instance, in the context of language learning, this type of learning takes lessons learned from one language and transfers them to another.
As discussed above, semi-supervised learning trains large models with a combination of supervised and unsupervised learning and uses such models to train smaller models and filter unlabeled data. Indeed with semi-supervised training, the current trend is moving away from supervised learning and reducing reliance on annotated data for training purposes.
Learning to paraphrase refers to a learning process where a model will take a first pass at guessing the meaning of an input, receive a new paraphrased version of the input, and then attempt again at decoding a correct output. Related to this, self-learning takes signals from the real-world environment and makes connections between data, without requiring any human intervention in the process. Finally, teaching AI allows models to integrate natural language with common-sense reasoning and learn new concepts through direct and interactive teaching from customers.
Each of these training methods marks a departure from past learning paradigms that required direct supervision and labelled data from human trainers. While limitations in the overall architecture of training models still exist, major areas of research today focus on approximating the performance of supervised learning models with less labelled data.
Self-Learning in New Applications and Products
These advancements are coinciding with the proliferation of consumer products designed and optimized for conversational translation. Speech recognition converts audio into sequences of phonemes and then uses machine translation to select the best output between alternate interpretations of those phonemes. New applications on the consumer market can directly learn through their interaction with the consumer by combining traditional machine translation models with neural language models that apply AI and self-learning.
Learning models that can act more independently and filter unlabelled data will become more effective in adapting to novel contexts and processing language more accurately and fluently. Already, developers are improving the level of fluency in these products by incorporating conversational-speech data that includes tone of voice, formality, and colloquial expressions in the training.
How Federal Privacy Legislation Could Affect US-EU-UK Relations
With more than 30 bills filed in the United States Congress since 2018 to regulate privacy with overwhelming support from the public, it looks like the US might be going through a ‘privacy renaissance’. This week, FPF Senior Counsel Dr. Gabriela Zanfir-Fortuna’s article, “America’s ‘privacy renaissance’: What to expect under a new presidency and Congress,” was featured in the Ada Lovelace Institute Blog. In the article, Gabriela lays out similarities and differences between the two major federal privacy bills currently in Congress, the SAFE DATA Act and the Consumer Online Privacy Act (COPRA), before breaking down the potential implications that a federal privacy bill passed by the incoming Biden administration would have on US-EU-UK relations during a time that the President of the EU Commission called, “an unprecedented window of opportunity to set a joint EU-US tech agenda.”
Seven Questions to Ask if You Have XR on Your Holiday Wish List
The holidays are right around the corner, and with so many of us sheltering in place in response to COVID-19, some are looking for an escape from the same four walls. Enter XR to help virtually transport us to new worlds, immersive games, and social interactions. XR, or extended reality, is an umbrella term for virtual reality (VR), augmented reality (AR), and other immersive technology. In 2020, we have seen increasingly accessible and affordable XR on the market, and undoubtedly much of this technology is at the top of holiday wishlists. But new tech raises new questions about the privacy and security of personal data. Below are seven questions consumers should be asking before buying an XR gift for a loved one (or themselves) this holiday season, along with answers to better understand the implications of jumping into virtual (or augmented) reality.
Top questions to consider when purchasing a gift for the holidays:
What is XR anyway? And for that matter, what are VR and AR? Is there a difference?
Will my XR system collect or share my data?
Okay, but what does that mean for my privacy?
Are there any safety risks?
My kid has been asking me about an XR toy or game. Is it appropriate for children?
Are there any psychological impacts associated with XR?
What about inclusion? Is XR accessible for everyone?
1. What is XR anyway? And for that matter, what are VR and AR? Is there a difference?
The terms virtual reality (VR), augmented reality (AR) and extended reality (XR) are often used interchangeably but there are significant differences. XR serves as an umbrella term for AR, VR, and other immersive technology, but VR and AR are separate technologies that offer different experiences. Consumers should understand the differences between these terms prior to making a holiday purchase.
VR: These systems seek to replace physical reality with a fully immersive digital environment, giving the user a sense of presence and making them feel like they are within and interacting in a virtual world. VR requires specialty hardware, most commonly using headsets that rely on spatial, audio, stereoscopic displays, and motion-tracking sensors to simulate a “real” experience. Users can also navigate within a VR experience through the use of haptic (or “experience through touch”) controls, hand gestures, or other movements. While VR has not yet reached the impressive feat of a Star Trek holodeck, such immersive experiences could be available to consumers in the future.
AR: Unlike VR, which aims to replace the physical world with a digital one, AR imposes digital elements onto the real world so that the user experiences the digital elements within the context of their real, physical existence. Digital elements may include: video, graphics, sound, or other virtual content such as real-time commentary and annotations. Today, AR is most often accessed through smartphone cameras—as with the popular mobile game Pokémon Go, heads-up displays (HUD) in vehicles, and home gaming systems, such as the Nintendo Switch.
XR: is most commonly used as an umbrella term for AR, VR, and other immersive technology. Other than AR and VR, XR technology includes mixed reality (MR), in which virtual and real-world elements interact with each other. Today MR is most commonly found in enterprise applications, rather than consumer devices, but could be increasingly targeted to consumers in the future. XR hobbyists should continue to watch this space for new developments and applications.
2. Will my XR system collect or share my data?
XR products collect personal information and other data about the user and how the user interacts with the product. Most immersive products must collect a large swath of data in order to function. Some estimates show that twenty minutes of VR use can generate approximately two million data points and unique recordings of body language, biometrics, or other physiological information. Unique recordings might include a user’s fingerprint, scans of hand or face geometry, iris and eye tracking, as well as other movement patterns, skin temperature, and heart rate. AR use may require a vast amount of spatial and mapping data to successfully overlay digital information onto images or video of private homes and public spaces. Thus the collection of location data as well as access to cameras and physical spaces occupied by the user is inherent in the product operations. Many XR systems also collect: name, address, email, IP address, and other personal information commonly collected by Internet-connected devices. In-product purchasing can add further details to an XR user’s profile, preferences, and interests.
Some XR providers share personal data with subsidiaries and third parties for a number of purposes—from improving content and informing future updates to using XR data for advertising and recommendations for online content.
3. Ok, but what does that mean for my privacy?
User privacy is impacted by data collection, use, and sharing involving XR technology. Data collected by XR systems can often be used to identify, analyze, track, or market to a particular user. Many leading consumer-focused VR headset manufacturers de-identify user data prior to sharing it with third parties, but risks can remain. For example, a recent study showed that a machine learning model trained on individuals’ head and hand movements during a five minute VR session could identify the original user with 95% accuracy based on this data alone.
Moreover, the analysis of personal data from VR users can reveal sensitive details about the user’s body and life. Much of the tracking experienced in VR involves biometric or biologically-derived information, such as head and hand movement, hand geometry (the measurement and dimensions of a user’s hands), fingerprints, eye gaze and movement, and gait. Because these details are associated with the human body, these elements typically cannot be altered by the user and can reveal intimate details about a user’s height, weight, or medical condition. Additionally, tracking a user’s movements, such as eye gaze, can reveal intimate details about a user’s physical or emotional reactions to content, including a user’s likes and dislikes.
As for AR, information about a user’s location is often collected, whether it be longitudinal or latitudinal coordinates, images or video taken by an AR app of a recognizable location such as a park or a restaurant, or the dimensions or images of a user’s home. Location information is sensitive when recorded over time, leading to inferences about a user such as where they live, work, worship, or seek medical care. Moreover, data collected within the home is historically considered sensitive as it could reveal personal information about the activities of a user or their family.
Companies’ data sharing practices should also be on users’ radar as potentially impacting privacy. XR providers may share data with third parties to serve ads to users both in XR environments and other digital contexts. The content of these ads could be largely based on how the user interacts with XR from the types of devices they access, experiences they choose to purchase or download, and how they interact with the technology.
4. Are there any safety risks?
XR developers are increasingly aware of the safety risks associated with immersive and emerging technology and have sought to address them. For example, when a user is fully immersed in a VR world, there is a risk that the user will trip over or bump into real-world objects or people. VR developers address these sorts of safety concerns by requiring the user to create virtual boundaries to prevent themselves from coming into unwanted contact with furniture, walls, and others. Additionally, many VR developers recommend at the start of an XR experience that users make certain they have a wide enough space to move limbs without obstruction to safely enjoy the experience. AR experiences can be safer, particularly when AR content does not obscure a user’s surroundings. But AR content experienced in public runs the risk of turning users’ attention away from other pedestrians, nearby objects, or even moving vehicles.
Other safety concerns include online harassment in social XR. Like with other social media, cyberbullying and harassment can impact XR social experiences. However, harassment and cyberbullying in VR can result in even more negative feelings than harassment in other forms of social media because of the immersive nature of VR. For example, reports have shown that women are often subject to harassment in VR by other users, sometimes leading them to choose non-gendered avatars in VR, or to opt-out of VR entirely. Developers recognize the potential for especially harmful harassment in VR and are taking steps to mitigate harassment through heavy moderation, reporting, and providing users with multiple ways to quickly exit a VR experience.
Relatedly, deep fakes and other manipulative or harmful content may be present in XR experiences. VR avatars today are generally cartoonish, rather than realistic representations. But it is possible that new risks will emerge as more realistic avatar technology permits malicious users to create or manipulate avatars depicting another person without their consent.
5. My kid has been asking me about an XR toy or game. Is it appropriate for children?
XR can provide fun, engaging, and educational experiences for children, but parents should be aware of age restrictions on XR products and applications. Consumer-facing VR headsets are typically directed to children at least 13 years old and are best enjoyed by teens and adults. On the other hand, many AR games and applications are directed to younger children and available on gaming consoles and other devices enjoyed by kids as young as elementary school.
Adults should be aware that the psychological impact of XR on children has not been widely researched, but some studies indicate that developing minds could be especially susceptible to negative content. Moreover, parents should be aware that cyberbullying and harassment of children and teens that occurs in gaming and on social media can be present in social and gaming XR experiences; this could be especially harmful given the sense of presence children and teens feel in XR.
Screen time is another major concern for many parents. Most VR experiences are designed for shorter playtime sessions than traditional video games—many titles clock in at around 30 minutes. Shorter XR sessions can help users avoid the nausea or other negative health impacts associated with extended XR experiences. Unlike traditional gaming, VR often involves movements of limbs and at times exercise through content that encourages movement, including fitness-specific content. On the other hand, AR content experienced on smart devices and more traditional gaming consoles are often intended for longer and sometimes less active engagement. Parents concerned with screen time will want to consider how XR will reduce, increase, or have little impact on children’s total screen time.
6. Are there any psychological impacts associated with XR?
Researchers are just starting to unpack the psychological impact of XR. However, thought leaders have pointed to potential positive psychological impacts of XR, especially VR, as being the ultimate empathy machine. Imagine, for instance, the ability for a user to “walk a mile in someone else’s shoes” in an immersive environment to gain a greater understanding of someone else’s lived experience leading to educational and engaging content. However, consumers should consider that the sense of presence users feel in immersive XR might also trigger negative, strange, or uncomfortable emotions in some situations. Additionally, XR can influence the ways in which some users walk, interact with others, and concentrate in real life, for good or for ill. Relatedly, some studies point to XR potentially resulting in body ownership illusions and body dysmorphia.
More research is needed in this area for consumers to gain a better understanding of how activities in the virtual world may impact life offline. Users would be wise to be cautious, and contemplate on their own how their online behavior in XR impacts their offline behavior, thoughts, and feelings.
7. What about inclusion? Is XR accessible for everyone?
Many XR developers are currently working to create inclusive experiences for a diverse group of users far beyond the early adopters of VR technology. Early adopters often skew well-off, tech-savvy, and largely male. But XR technologies can bolster inclusion, representation, and diversity. For example, some social VR platforms are adding a wider range of customizable avatar features, including a greater range of skin tones and virtual clothing such as hijabs.
Beyond increased representation of avatars, some developers are making hardware changes to make the technology more accessible. For example, a developer recently designed a specialty VR head strap made to more comfortably fit Black women with larger hairstyles and head wraps, rather than the more restrictive head strap that comes standard with most VR headsets. Researchers are designing XR technology that better maps to women’s’ physiology to mitigate the higher rates of cybersickness experienced by women when VR headsets cannot properly adjust to fit their field of view and distance between pupils, which often differs from that of men. Other hardware developments include increasingly lighter headsets that allow for better mobility and more comfortable wear, especially important for older users and users with limited muscle coordination.
Additionally, VR developers are introducing an increasing number of headsets that are both more user friendly out of the box and are offered at lower price points. Popular consumer VR headsets are available as stand alone devices that no longer need to be tethered to an advanced gaming PC. Many of these headsets are now available at a price point more akin to other gaming consoles on the market.
Further, there is increasing recognition that XR can provide engaging experiences for the disability community. For example, users with limited mobility could enjoy virtual content that seemingly transports them to another location that was previously inaccessible. More research, study, and development is required to make XR accessible for everyone, but consumers should be aware of the current efforts to make XR accessible to an increasing number of individuals and communities.
Conclusion
The above questions and answers represent just a handful of the many questions, concerns, and fascinations expressed by consumers looking to purchase an XR experience for the holidays. There are already many XR devices, applications, games, and other content on the market with more on the way. New, improved, and never-before-seen XR technical feats will debut at major events, such as January’s Consumer Electronics Show (CES), but the above questions and answers will equally apply. While stakeholders should continue to promote responsible XR, consumers would be wise to familiarize themselves with the potential risks and benefits of XR this holiday season and beyond.
*Image courtesy of Darlene Alderson from Pexels, availablehere.
The Complex Landscape of Enforcing the LGPD in Brazil: Public Prosecutors, Courts and the National System of Consumer Defense
On Tuesday, November 24, 2020, the Future of Privacy Forum (FPF) and Data Privacy Brasil (DPB) co-hosted a landscape webinar exploring the relationship between Brazil’s legal system and the implementation of Brazil’s new data protection law, Lei Geral de Proteção de Dados (LGPD). As a federation, Brazil hosts many separate authorities and courts with their own competencies and powers on the national, state/regional, and municipal levels. Brazil’s recently created National Data Protection Authority (NDPA) will operate in a very complex system, alongside well established enforcers of the law, like consumer protection authorities and public prosecutors, on top of broad private rights of action granted by the LGPD directly to individuals. Because of this complex environment, uncertainty may appear as to how the LGPD will be implemented and enforced in practice.
What are the various legal and regulatory institutions in Brazil that have authority over data protection? Will the implementation of the LGPD create more fragmentation and lead to a conflict of these competencies or will the LGPD help produce more consistency across the board? What are the solutions to solve potential sources of conflict in the Brazilian legal system? FPF’s Gabriela Zanfir-Fortuna and Data Privacy Brasil’s Bruno Bioni and Renato Leite Monteiro convened a panel of experts to discuss these questions.
The speakers included:
Danilo Doneda, Professor at IDP and advisor to the National Council for the Protection of Personal Data and Privacy (CNPD)
Laura Schertel, Professor at IDP and UNB, and Director of the IDP Law, Internet and Society Center
Rafael Zanatta, Director of Data Privacy Brasil Research Association
This blog (1) summarizes the contributions of our three guest speakers, focusing on (2) public prosecutors under the Public Ministry, (3) recent case-law from the two highest Federal Brazilian Courts, (4) the national system of consumer defence, and (5) outlines potential conflicts of competence, before reaching (6) conclusions.
1. Background
Since the enactment of the LGPD into law in 2018 commentators both within and outside of Brazil have pointed out that the lack of clarification around provisions and terms in the LGPD have created uncertainty as to how regulators will implement the law. From a broader perspective, however, the structure of the legal system of Brazil makes clarity even more difficult. This is because many legal institutions in Brazil have competences to enforce consumer protection laws, including issues that involve data protection and privacy.
In addition, while the LGPD operates as a federal law, state and municipal authorities introduced data and consumer protection measures within their jurisdictions well before the LGPD’s enactment. Such diffusion has created a mosaic of legal competences and introduced a range of complexities that all data protection practitioners should be aware of when engaging with Brazil and its new data protection law.
Below we discuss how the Public Ministries, recent case law from Brazil’s Constitutional Court and Superior Court, and the National System of Consumer Defense, have each applied their own regulatory and legal authority to affect Brazil’s data protection ecosystem. We also examine the implications of these various authorities for a potential conflict of competences before discussing a proposed amendment to Brazil’s constitution that could provide for more legal harmonization.
2. Public Ministries
Legally structured by the 1988 Constitution, the Public Ministry (Ministério Público) hosts independent public prosecutors at both the federal and state level. The Ministries have specific functions in Brazil to uphold justice and bring cases at all levels of Brazil’s court system such as before the Supreme Federal Court and the state appellate courts. The public prosecutors operate independently from the three major branches of government and help protect constitutional rights by initiating civil actions to adjudicate issues that involve collective rights. There are currently 31 different Public Ministries throughout Brazil.
Every prosecutor in the Public Ministries can start a civil action or procedure if he or she believes there is a basis in law. This relative flexibility presents wide implications for data protection as a public prosecutor may take action under the LGPD outside of the NDPA which could lead to a unique Brazilian way of enforcing and clarifying the law. On the one hand, legal uncertainty may arise from a profusion of individual initiatives by public prosecutors. On the other, the role of Public Ministries is pivotal as it could serve as a check to any NDPA action that runs contrary to public consumer interest.
3. Recent Case Law
In addition to the Public Ministries, recent case law in Brazil also shines light on some unique regulatory challenges facing the implementation of the LGPD. This case law illustrates how data protection was a fundamental issue in the judicial system before the enactment of the recent law, particularly in the area of consumer protection. Some of the most important decisions have clarified many issues for data protection such as the rights of data subjects, the scope of surveillance, and the application of key processing principles such as purpose limitation. As such, grasping the implications of this case law is critical for understanding how regulators will implement the LGPD.
The Supreme Federal Court, which serves as Brazil’s highest court, recently issued a decision related to Covid-19. In this case (ADI 6387), a legal provision mandated personal data sharing for statistical purposes as an emergency measure in response to the pandemic. Many organizations throughout Brazil contested this provisional measure, arguing it did not meet the standards of purpose limitation, transparency, information security, and that it was overly broad. The Court agreed, upholding a higher bar for purpose limitation and many key aspects of the LGPD as well as clarifying some constitutional issues surrounding data protection.
While the decision has not neutralized all of the risks for data protection in Brazil, it did establish precedent for lower courts and sent a clear message by recognizing data protection as an autonomous fundamental right. In so holding, the Court acknowledged that other constitutional protections of individuals such as privacy and due process explicitly extended to the online world and the protection of personal data. It also clarified that, contrary to arguments made by the Federal Attorney General and the Attorney General of the Republic, there is no irrelevant data in this day and age, and even personal data that may seem trivial, such as individuals’ names, phone numbers and addresses, deserve constitutional protection from abuse. The decision notably took influence from the European Charter of Fundamental Rights.
Another recent case discussed the implications of consent for the credit scoring industry in Brazil. Although obtaining consent is not mandatory for companies that engage in credit scoring, the Superior Court of Justice, the highest court of appeal in the Brazilian jurisdiction, held that such companies must follow data protection standards in the credit scoring process. The Court discussed five broad principles that entities must follow going forward.
In addition, courts have also independently clarified the right to be forgotten. In DPN v. Google Brasil Internet Ltda in 2018, a lower court in Brazil mandated that search engines had to uphold the right of individuals to be forgotten in indexing search results. While the Superior Court of Justice may still decide the scope of this right under the LGPD, this case illustrates that the issue has already received attention from at least one important court in the country and could be influential for ongoing legal decisions.
Finally, two additional cases also shed light on how recent case law has influenced data protection in Brazil. One case held that contracts that preclude the ability of consumers to have a say about the scope of data disclosure were illegal (Case “José Galvão Silva vs Procob SA”, Special Appeal 1.758.799, State of Minas Gerais, decided by the Superior Court of Justice in November 2019). Another mandated the government of São Paulo remove cameras from the Metros, finding that such pervasive installation of surveillance equipment.
3. National System of Consumer Defense
The National System of Consumer Defense (SNDC) also raises complexities for the implementation of the LGPD in Brazil. Established with the Brazilian Code of Consumer Protection in 1990 and regulated by Presidential Decree nº 2.181/1997, the SNDC brings together federal, state, and municipal agencies, as well as civil society organizations, to prevent, investigate and prosecute violations of consumer protection law. As a broad institutional framework for consumer protection, the SNDC has over 30 years of experience and covers 798 units spread across 591 Brazilian cities.
The Procons (Procuradoria de Proteção e Defesa do Consumidor) function within the National System to help consumers administratively file complaints, give instructions and information about consumer rights, and verify judgments. The Procons have issued a few decisions related to data protection over the years that have generated attention. For example, one decision in 2019 by the Procon in São Paulo resulted in a large fine for Google and Apple for imposing unfair terms for the use of FaceApp without making such terms available in Portuguese. Another in 2020 saw the Procon-SP reach an agreement with the energy distributor Enel over consumer complaints of increased and incorrect billings. In the agreement, the Procon stipulated that Enel must demonstrate the security and technical measures it will take to ensure that the problem does not recur.
While the SNDC can take separate enforcement measures against companies that violate consumer protection laws, including those operating online, potential coordination problems with this competency and the LGPD may arise in the future. Article 18 of the LGPD states that data subjects can exercise all of their rights before consumer-defense entities such as the SNDC. However, Article 55(k) also specifies that the Brazilian DPA will have the final say in interpreting such rights. Because these two institutions may conflict in their subsequent interpretations concerning these issues, cooperation could be hindered and result in more legal confusion and fragmentation. The LGPD may have predicted such a scenario, since Article 55(k) also states that the NDPA will articulate its performance with that of other bodies and entities with sanctioning or normative competencies related to the protection of personal data, and that it will be the central body of interpretation and implementation of the law. How this will all play out is something for the coming months (considering that the administrative sanctions provided for by the LGPD will only be enforceable after August 2021).
4. Conflicts of Competencies
Indeed, conflicts between all three of the institutions mentioned above may surface with the implementation of the LGPD. Because each of these authorities have competencies over online consumer protection, a ruling or judgment from one could be inconsistent with enforcement actions taken by the NDPA, especially given the ambiguity and lack of clarification around specific terms and provisions within the LGPD. Such conflict could create further uncertainty as to the application of data protection standards within the unique and complex institutional structure of Brazil’s legal system.
While there are many potential resolutions of these conflicts, it is hard to predict exactly how the process will play out. The LGPD does not preclude other competences from enforcing data protection in Brazil. Nor will the law dismantle the Brazilian legal system. However, it does state that the various public bodies engaged in data protection will coordinate with one another to fulfill their duties effectively.
The challenge is generating the operational capacity for cooperation within the Brazilian government itself, given that the employees and staff within these institutions change. Currently, the NDPA has coordinated experts from different subject areas to create a National Council within the Data Protection Authority to provide technical and operational guidance on solving some of these institutional issues. Hopefully as the NDPA gains more experience, some of these larger potential sources of conflict can be addressed.
Finally, a proposed amendment to Brazil’s constitution (Proposal of Constitutional Amendment n. 17/2019) could also help provide more coherency and coordination between the various institutions that enforce data protection. The proposed amendment would explicitly recognize data protection as a constitutional right, give exclusive competence over data protection to the Union (seeking to avoid regulation with antagonistic results), and ensure that the NDPA has functional, financial, and administrative independence to exercise authority under the law.
5. Conclusion
Brazil has come a long way in the construction of a solid data protection normative framework, in which the LGPD is a central part. Before that, the protection of individuals’ personal data was mobilized mainly through a robust system of consumer protection that congregates Public Ministries, several administrative bodies such as the Procons, as well as civil society organizations.
The LGPD standardized the discipline of personal data protection in Brazil, creating general obligations for all sectors and systematizing the rights of data subjects. It has been driving the adequacy of companies and the public sector alike, and the debates it has generated certainly represent the most important movement towards the consolidation of a data protection culture in the country.
However, it is essential to note that the law operates within an existing framework, and therefore, it must be harmonized with other norms and institutions. There is a challenge for regulators in how they interpret and advance the right to data protection while remaining cohesive across institutional competences to supervise and enforce the law.
In that sense, the LGPD has proposed an articulation of all bodies that may have overlapping competencies on the matter of data protection, with the NDPA serving as the nerve center of interpretation and development of guidelines of implementation. This suggests that initiatives of cooperation are ahead of us, but it is too early to note what issues may arise from the combination of several different paths for data protection enforcement that the Brazilian legal environment provides, as well as how those issues will be addressed and eventually resolved.
This scenario makes the harmonization of the interpretation of the General Personal Data Protection Law challenging. For companies operating in Brazil, this requires a more sophisticated capacity for mapping legal risks. For Brazilian authorities, it demands a greater capacity for institutional articulation. For civil society, it demands a broader monitoring capacity and multiple dialogues with authorities. For all stakeholders, the challenge is significant. As composer Antonio Carlos Jobim once said, “Brazil is not for beginners”.
Defining and regulating location data in a privacy law can be an elusive challenge. In part, this is due to its ubiquity in our lives: information about how devices and people move through spaces over time is utilized by Wi-Fi networks, smartphones, mobile apps, and a world of emerging screenless technologies, such as wearable fitness devices, scooters, autonomous vehicles, and video analytics. Existing legal and self-regulatory regimes in the United States (and globally) approach location data in a variety of ways that may serve as a model for policymakers.
Read the policy brief to learn about the challenges associated with defining location data, when location data is considered “personal” data, and the specific legal protections for location data in the United States and around the world.
The Spectrum of Artificial Intelligence – An Infographic Tool
UPDATED August 3, 2021and June 2023. FPF released the white paper, The Spectrum of AI: Companion to the FPF AI Infographic, to provide additional detail and analysis for use of this Infographic tool as an educational resources for policymakers or regulators.
AI is the computerized ability to perform tasks commonly associated with human intelligence, including reasoning, discovering patterns and meaning, generalizing knowledge across spheres of application, and learning from experience. The growth of AI-based systems in recent years has garnered much attention, particularly in the sphere of Machine Learning (ML). A subset of AI, ML systems “learn” from the success or accuracy of their outputs, and can adapt their programming over time, with minimal human intervention. But there are other types of AI that, alone or in combination, lie behind many of the real-world applications in common use.
General AI – truly human-level computational systems – does not yet exist. But Narrow AI exists in many fields and applications where computerized systems enhance human output or outperform humans at defined tasks. This chart is designed to identify and explain the main types of AI, their relationship to each other, and provide some specific examples of how they are currently in place throughout our day-to-day lives. It also demonstrates how AI exists within the timeline of human knowledge and development. Building on knowledge from philosophy, mathematics, physics, ethics, and logic, and more recently, statistical analytics and modeling, it also reflects the foundational role of computer design and security.
There is not 100 percent consensus around the labels for the various types of AI, but for our purposes, we have adopted the following categories as representing generally accepted terms in common use.
Symbolic AI, including subsets: Expert Systems, Search, and Planning & Scheduling
Rules Based
Robotics
Computer Sensing
Knowledge Engineering
Natural Language Processing, and of course,
Machine Learning, including Deep Learning, Neural Networks, Reinforcement Learning, and General Adversarial Networks (GANs)
To aid in understanding these various types of AI programming, we have highlighted a specific use case in a number of broad topic areas.
Finance – Tax Compliance programs that allow you to fill out your tax forms and ensure your information included and provided in a way that is within current legal requirements of the tax code.
Healthcare – Ambient Charting, where conversations between doctors and patients are recorded and added to the patient record as they happen, with key words and followups noted as appropriate.
Tracking – as used in Workplace Monitoring to provide both physical and digital accountability, while enforcing security policies.
Mobility and Transportation – Turn-by-Turn Navigation provides real-time guidance through traffic or even when an area is under construction.
Social Media – platforms use AI to face the challenges around appropriate and effective Speech or Content Moderation.
Forecasting – Supply Chain Management has reached new levels of efficiency and accuracy with AI-based modeling and predictions.
For further information or to provide comments or suggestions, please contact Brenda Leong ([email protected]) or Dr. Sara Jordan ([email protected]).
FPF and LGBT Tech Host Discussion in Honor of Human Rights Day
Yesterday, in honor of International Human Rights Day, a time when individuals and organizations around the world celebrate the 1948 ratification of the Universal Declaration of Human Rights, FPF and LGBT Tech hosted a discussion exploring the “LGBTQ+ Right to Privacy.”
The conversation featured tech privacy and policy experts from both FPF and LGBT Tech, including: Christopher Wood, Executive Director, LGBT Tech; Christopher Wolf, Founder and Board Chair, FPF; Carlos Gutierrez, Deputy Director & General Counsel, LGBT Tech; Dr. Sara Jordan, Artificial Intelligence and Ethics Policy Counsel, FPF; and Katelyn Ringrose, Christopher Wolf Diversity Law Fellow, FPF. The conversation was moderated by Jules Polonetsky, FPF CEO.
The conversation revolved around issues related to the United Nations 2020 theme — which is “Stand Up for Human Rights” — and the speakers tackled entrenched and systematic inequalities experienced by the LGBTQ+ community from a privacy and equity perspective.
Throughout the discussion, speakers noted the many beneficial uses of data pertaining to an individual’s sexual orientation, gender identity and sex life; while also discussing the many ways that such data can be used to perpetuate systems that discriminate against, oppress, or otherwise harm members of the LGBTQ+ community.
For example, while the collection of health data is important in the context of COVID-19 contact tracing, the LGBTQ+ community has not always benefited from inclusive data protection practices and may be less willing to have their data collected and used in the name of public health. According to Carlos Gutierrez, Deputy Director & General Counsel of LGBT Tech, “historically, HIV laws were weaponized against the LGBTQ community, and gay men. Getting an HIV positive test result could mean the loss of employment, dropped insurance, and more.”
And while certain uses of data may pose risk for the LGBTQ community, speakers also pointed out that that inclusive data collection for marginalized communities tends to benefit society as a whole. For example, Dr. Sara Jordan, Artificial Intelligence and Ethics Policy Counsel for FPF, noted that existing definitions for sexual orientation and gender identity data (SOGI data) often do not address issues pertaining to the intersex community, and how identifying such gaps and leveraging data for good can allow the research community to “advance research, or identify ways to redirect existing research streams.” This, Dr. Jordan noted, will allow the benefits of using this data to “flow directly” back to individuals and communities in need of such advances.
Watch the full discussion here on LGBTQ+ data privacy here:
Regarding FPF or LGBT Tech’s joint efforts related to LGBTQ+ privacy; contact either Katelyn Ringrose at[email protected] or Chris Wood at [email protected]with any questions, comments, or to get involved.
Legislative Findings: Brookings Builds on U.S. Privacy Legislation Report
Today, the Brookings Institution released model legislative findings for federal privacy legislation, intended to accompany the model privacy legislation they published in June, 2020. The findings are designed to motivate discussion and to reconcile differences between two of the leading proposals: Sen. Maria Cantwell’s (D-WA) Consumer Online Privacy Rights Act and Sen. Roger Wicker’s (R-MS) SAFE DATA Act. The legislative findings also provide useful framing for the recommendations and options outlined in Brookings’ Report, “Bridging the gaps: A path forward to federal privacy legislation.”
// WHY LEGISLATIVE FINDINGS MATTER
Many federal and state laws begin with a non-binding “legislative findings” section that outlines the various goals that legislators are trying to achieve through the legislation. The articulation of the foundational principles and aims of privacy legislation is powerful and important for a number of non-operational reasons. These include building support among the public and members of Congress, declaring American values to the world, informing judicial and agency interpretation, and clearly expressing grounds to uphold the legislation against constitutional challenges.
Despite these reasons, ten of the dozen proposals for comprehensive privacy legislation introduced in the 116th Congress excluded statements of legislative findings. In contrast, the EU’s General Data Protection Regulation (GDPR) is accompanied by 173 recitals that explain and offer commentary to the law.
// WHAT THE BROOKINGS PROPOSED LEGISLATIVE FINDINGS CONTAIN
The legislative findings proposed by the Brookings Institution are not intended to be set in stone, but instead to provide a comprehensive outline for Congress and stakeholders to consider as they continue to draft privacy legislation. They also provide a framing for the detailed recommendations outlined in the recent report, “Bridging the gaps: A path forward to federal privacy legislation,” which advocates for a risk-based approach, tailored preemption and enforcement, and individual rights aimed at recognized privacy harms.
In summary, the proposed legislative findings contain (1) a statement of the legal, moral, and historical foundations of privacy in America; (2) technology developments that underlie the need for legislation; (3) the effects of these developments that privacy legislation aims to address; (4) how privacy legislation aims to address these effects; and (5) a set of policy declarations that express key governmental objectives.
You can read the model legislation with legislative findings in full here.
You can read Brookings’ full release for the legislative findings here.
You can read the Brookings report from June 2020, here.
You can read FPF’s brief analysis of the key areas of debate contained in the Brookings report here.
This year, FPF has observed considerable progress among stakeholders towards developing nuanced and workable solutions in key remaining areas of debate — including enforcement and preemption. This progress has been promoted by important legislative and judicial developments in the states and abroad, as well as the accelerated adoption of technologies for remote learning, work, and leisure activities during the COVID-19 pandemic. With all this in mind, we are optimistic that the new Administration will create fertile ground for the enactment of bipartisan privacy legislation in the 117th Congress.
A Deep Dive into New Zealand’s New Privacy Law: Extraterritorial Effect, Cross-Border Data Transfers Restrictions and New Powers of the Privacy Commissioner
By Caroline Hopland, Hunter Dorwart and Gabriela Zanfir-Fortuna
Last week, on December 1st, the newly amended Privacy Act 2020 (Act) of New Zealand came into force. The act was passed by the New Zealand Parliament on June 20, 2020 and made significant changes to the 1993 law, Privacy Act 1993. The amendments cover a broad range of topics including the extraterritorial scope of the law, new mandatory data breach notification requirements, changes to “compliance notices” as a key enforcement tool of the Office of the Privacy Commissioner, to data subject access requests, restrictions on cross-border transfers of personal information, and the enforcement regime overall.
One key feature of the Act as compared to other comprehensive privacy and data protection laws around the world is how central the Privacy Commissioner is in shaping and enforcing the law, including with regard to being a necessary “stop” before a claim made by an individual or a representative action gets to the Human Rights Tribunal. The Act gives the Commissioner greater powers to ensure covered entities are complying with the law, to adopt “codes of practice”, and broad authority to issue sweeping compliance notices and prohibit cross-border transfers of personal information. Such broad discretion may initially create legal uncertainty regarding specific compliance requirements, as well as the scope of the rights of data subjects. For instance, the Commissioner at any time may issue clarification guidelines known as “codes of practice” that modify the baseline of obligations set out in the law and clarify the obligations of data controllers.
The law mentions the OECD Guidelines in multiple sections as a baseline for compliance, and explicitly recognizes other data protection regimes such as European Union’s General Data Protection Regulation (GDPR) as providing a comparable level of protection.
However, the Act diverges from the GDPR and other data protection laws inspired by it in terms of its smaller set of rights of the data subject, its lukewarm penalty structure for non-compliance and its original framework for individual redress. Under the updated law, individuals do not have a right to erasure (“right to be forgotten”), a right to data portability or any specific rights, such as objection, in relation to automated decision-making. In fact, profiling and automated decision-making are not specifically addressed, and the Commissioner may only fine companies up to $10,000 New Zealand dollars (app. 7,000 USD) for violations of the Act.
Notably, Commissioner John Edwards stated in a recent radio interview that this Act was deliberately designed to sit mid-range in the spectrum of privacy regulations around the world. He went on to note that in 2011, the New Zealand Law Commission contemplated whether the Commissioner could impose much larger fines to entities like in Europe. However, it decided to instead grant the Commissioner discretion to issue compliance notices to see if there is a change of behavior, and will assess its effectiveness in a few years.
It should be noted that New Zealand is one of the countries whose legal system received an “adequacy decision” from the European Commission allowing unrestricted transfers of personal data from the EU. New Zealand’s adequacy is set to be reassessed as part of the European Commission’s efforts to re-assess adequacy decisions in the light of the GDPR, and this assessment will be done on the basis of the new law (New Zealand’s adequacy was issued in 2012, under the former Data Protection Directive 95/46/EC).
Below we discuss some key changes of the Act, specifically 1) its broadened extraterritorial scope, 2) cross-border transfer restrictions, 3) the Information Privacy Principles and Codes of Practice that may detail and enhance them, 4) updated data access requests by data subjects, 5) the new data breach notification requirements, 6) “compliance notices” regarding breaches of the Act and the new penalties framework, 7) the private right of action enshrined by the law and possible class actions, and 8) rules on public sector data sharing, before reaching 9) conclusions.
1. Extraterritorial Scope of the Law
The Act expanded its scope to overseas organizations that carry out business in New Zealand, regardless of where they collect or hold data and where the data subjects are located. Under the Act, carrying on business in New Zealand extends beyond traditional commercial activities such as having a place of business in the country or receiving money for the supply of goods and services in the country. Therefore, the new scope of the law could in theory encompass a range of other potential overseas organizations, such as non-profits, as long as they carry out their activities in New Zealand.
In addition, the act also applies to non-resident individuals, if, while in New Zealand, they either collect or hold personal information about anyone from anywhere in the world, even if the individual previously collected the information while outside of New Zealand. Lastly, the Act applies to “agencies” which refer to not only private companies and organizations but also certain public bodies such as government departments, both within and outside of New Zealand. “Agency” is somewhat of a nuanced term in the Act, which can find correspondents to both controllers and processors as defined under the GDPR (or “businesses” and “service providers” as defined by California Consumer Privacy Act – “CCPA”). While the Act does not contain a separate chapter laying out specific obligations for the subsequent processing of data by an organization on behalf of another organization, it does extend liability to “agents” of the “principal agency” which could encompass GDPR-processors/CCPA-business-providers. This widely expands the category of entities who have direct obligations under this Act.
2. Cross-Border Data Transfers
The Privacy Act includes a new Information Privacy Principle (IPP), IPP 12, which lays out rules for disclosing personal information outside New Zealand. According to this new principle, an agency may only disclose personal information to a foreign entity only if one of six grounds is satisfied:
(a) express and informed consent of the individual in the cases where the exporter informs them that the importer may not be required to protect their personal information in a comparable manner with the protection afforded in the Privacy Act;
(b) in the course of the importer carrying out business in New Zealand and the exporter reasonably believing that the importer is subject to the Privacy Act;
(c) the exporter reasonably believing that the importer is subject to comparable privacy laws to the Privacy Act;
(d) the exporter reasonably believing that the importer is a participant to a “prescribed binding scheme”;
(e) the exporter reasonably believing that the importer is subject to privacy laws of a “prescribed country”; and
(f) the exporter reasonably believing that the importer is required to protect the information in a comparable way to the Privacy Act, such as for example pursuant to an agreement between the two. Both countries and binding schemes can be “prescribed” through action by the Governor-General by Order in Council.
It is interesting to note how New Zealand’s Privacy Act solved a couple of the big questions stemming from GDPR’s rules on international data transfers: consent of the individual may be considered a valid mechanism for cross-border transfers only where the data importer is not subject to similar obligations to those in the jurisdiction of the data exporter; if the privacy law of the exporter applies to the importer by virtue of its extraterritorial effect, then no additional safeguards are required for the personal information being transferred. Another point to note is that the GDPR “essential equivalence” standard has a correspondent in the seemingly more straight-forward “comparable laws” standard under the Privacy Act.
The Privacy Act also gives the Commissioner broad authority to prohibit cross-border transfers of personal information outside of New Zealand, similar to the provisions in the old law. If the recipient country does not provide legal safeguards comparable to those covered in the Act and the transfer would likely contravene the basic principles set out in Part Two of the OECD Guidelines and in Schedule 8 of the Act, the Commissioner may issue a transfer prohibition notice to the company in question. This does not apply to transfers that receive authorization from the Commissioner or are otherwise authorised by “any enactment”, or that occur on the basis of an internationally binding convention.
The Commissioner will consider broad factors to determine whether to prohibit transfers. These include:
the likelihood the transfer would harm any individual;
the general desirability of facilitating the free flow of information; and
any existing or developing international guidelines relevant to cross-border data flows such as the OECD Guidelines and the GDPR.
Entities transferring data abroad must receive a transfer prohibition notice in order for the Commissioner to effectuate the prohibition. Before becoming effective, each notice must meet a series of requirements such as the nature of the prohibition, the personal information the prohibition applies to, and the grounds for prohibition. The Commissioner must reply within 20 days to any request to vary or cancel the notice and must provide a reason if the request is refused.
Organizations may appeal to the Human Rights Review Tribunal (Tribunal) the decision of the Commissioner to issue a transfer prohibition notice against all or any part of the notice or against the refusal by the Commission to vary or cancel the notice. The Tribunal must allow an appeal if it considers that the Commissioner’s decision violates the law or if the decision results from an inappropriate use of the Commissioner’s discretion. On appeal, the Tribunal may modify the notice to exclude any statement that it finds does not have effect.
The law imposes a penalty for any person who without reasonable excuse fails or refuses to comply with a transfer prohibition notice up to $10,000 New Zealand dollars.
3. Information Privacy Principles and Codes of Practice
The Act sets forth IPPs that impose broad obligations on entities for their processing activities and serve as a benchmark for the Commissioner to implement further guidance through legally binding codes of practice. These principles relate to different dimensions of information processing such as purpose, manner of collection, storage and security, access, correction, accuracy, and limits on use and disclosure.
Many of the IPPs have not changed from the previous version of the law. For instance, IPP 3 specifies that entities collecting personal data must take reasonable measures to inform the individual of specific facts such as the purpose of collection and the intended recipients of the information. If the collection is authorized or required by a separate law, the entity must inform the individual of such law and explain whether the supply of the information is voluntary or required. IPP 3 also lists grounds that excuse an entity from providing such information to the individual.
Notable changes to the IPPs compared to the previous law include heightened fairness requirements for entities that collect information from children or young persons (IPP 4) and a purpose limitation principle (IPP 1) that requires entities to collect identifying information from people only when necessary. IPP 1 also specifies that information must be collected for a lawful purpose connected with the act of processing.
The Act does not explicitly specify lawful grounds nor provides for a general consent requirement for all processing activities. It does, however, impose limits on the disclosure of personal information without consent or another valid justification such as protecting public safety, upholding the legitimate and reasonable activities of law enforcement, or facilitating the execution of a contract as a going concern. In fact, the IPPs and, generally, the other provisions of the Act differentiate among “collection”, “use” and “disclosure” of personal information, proposing a different set of rules for each of them. Note that the Act does not specify what are “lawful means” of collection, only that entities collecting data must use one. The Commissioner can issue further modification or guidance through a code of practice to impose further requirements on these baseline provisions.
In addition, IPP 10 imposes limits on the use of personal data but provides some exceptions such as when the data has been de-identified or will be used for statistical or research purposes in a form that will not reasonably lead to the identification of an individual. Publicly available data, data used in the furtherance of law enforcement, or data used to prevent or lessen substantial injury to an individual or the public health, may also trigger an exception to the general purpose limitation rule.
Note that an agency does not breach the IPPs in relation to information held overseas if the action is required by law of any country other than New Zealand.
The Act acknowledges a range of situations in which certain IPPs do not apply such as a household exemption similar to the one provided in the GDPR, information collected before 1993, the activities of intelligence and security agencies, information gained during an investigation initiated by the Commissioner or an Ombudsman, and information collected by Statistics New Zealand. Under certain circumstances, the Commissioner may authorize the processing of personal information otherwise in breach of certain IPPs if the Commissioner determines that the public interest in granting authorization substantially outweighs the possibility of adverse effect on the individuals concerned.
As stated above, the Commissioner has broad discretion to issue codes of practice in relation to the IPPs to modify and clarify the application of the law. These codes of practice may prescribe a broad list of measures including:
how companies must comply with the IPPs;
specific requirements for types of information, businesses, industries or activities;
technical controls relating to specific processing activities;
guidelines and fee structures; and
review and monitoring mechanisms.
The Act specifies that failure to comply with a code of practice amounts to a breach of an IPP. The Commissioner may issue a compliance notice (see below) for agencies that violate any code of practice or any of the baseline IPPs set forth in the law.
4. Rights of Individuals: Access and Correction Requests
The IPPs also specify the rights of the individuals whose personal information is collected and used vis-a-vis processing entities, including the right to access and correct personal information. Individuals or representatives of individuals may issue an IPP 6 access or an IPP 7 correction request to which the entity receiving the request must promptly respond by either granting or refusing the request with reasons for the decision. If an entity does not hold the information and believes that another entity does, it must promptly transfer the request to the other entity unless good cause exists to believe that the data subject does not want the request to be transferred. Under this scenario, the entity must then notify the data subject of its decision.
The Act expanded the range of withholding grounds that entities may rely on to refuse an access request, compared to the old law. Notably, companies may now refuse access to protect an individual if disclosure would likely pose a serious threat to 1) life, health (including both mental and physical) or safety of an individual, or 2) to public health and public safety. Companies may also refuse to disclose information of an individual under 16 years old if they determine such disclosure would be contrary to the interests of the individual. Other withholding grounds include: 1) protection of security, 2) defense and international relations, 3) protection of trade secrets, 4) inability of the entity to locate the data, 5) the use of data law enforcement, or 6) rejection of frivolous requests.
The Act also specifies the means by which an entity can make information available to a data subject under an access request. Entities must make available information in a manner preferred by the requestor unless doing so would be overly burdensome or contrary to any legal duty of the entity.
For IPP 7 correction requests, the Act specifies that an individual may either request the entity to correct personal information or attach a statement of correction, but does not specify that an individual can request the entity to erase the personal information. The Act does not include a right to be forgotten nor a right to data portability.
Finally, the Act specifies that the Commissioner cannot modify or restrict the entitlements under IPP 6 or 7 for access and correction requests. The Act, however, does not facially preclude the Commissioner from expanding the scope of these rights or the obligations of entities in relation to these rights through codes of practices. Given the broad discretion the Act gives to the Commissioner, an interesting legal question arises as to whether the Commissioner could have the authority to require companies to provide for portability or erasure.
5. Data Breach Notifications
The Act introduces mandatory data breach notification requirements for organizations when a notifiable privacy breach has occurred having affected individuals. Entities will be under a legal duty to notify the Commissioner and any affected individuals if the breach could cause serious harm to anyone; and a failure to do so is a criminal offense, punishable as a fine up to $10,000 New Zealand dollars.
The Act defines a privacy breach, in relation to personal information held by an agency, as an 1) unauthorized or accidental access to, or disclosure, alteration, loss, or destruction of, the personal information; or 2) an action that prevents the agency from accessing the information on either a temporary or permanent basis; whether or not it is ongoing, was caused by a person inside or outside it, or is attributable in whole or in part to any action by it.
The Act defines a notifiable data breach as 1) a privacy breach that it is reasonable to believe has caused serious harm to an affected individual or individuals or is likely to do so; but 2) does not include a privacy breach if the personal information that is the subject of the breach is held by an entity who is an individual and the information is held solely for the purposes of, or in connection with, the individual’s personal or domestic affairs.
According to the Act, an affected individual is one whose personal information relating to them was the subject of a privacy breach; and is an individual inside or outside New Zealand, and can even be deceased if 1) a sector-specific code of practice applies to deceased persons, and 2) to the extent that the code of practice applies one or more IPPs to that information.
An organization must consider several elements when assessing whether a privacy breach is likely to cause serious harm in order to decide whether the breach is notifiable, such as any action it took to reduce the risk of harm following the breach or whether the personal information is sensitive. If unsure whether a breach is notifiable, an organization can use the Office of the Privacy Commissioner’s NotifyUs tool to determine whether it has a legal duty to report it.
Further, it must notify the Commissioner and affected individuals as soon as practicable after learning that a notifiable privacy breach occurred. Both the notification to the Commissioner and the notification to data subjects must contain a list of specific information defined by the law, including a description of steps that the organization took in response to the privacy breach.
The entity can also identify the person or body, if known, that has obtained or could obtain the affected individual’s personal information, if it reasonably believes that identification is necessary to prevent or lessen a serious threat to the life or health of the affected individual or another individual. It can also provide this information incrementally, as it becomes known, in order to comply with the requirements around providing any new or available information as soon as practicable. It must not include, however, any particulars about any other affected individuals.
Moreover, if it is not reasonably practicable to notify each affected individual, the organization must instead give public notice of the breach in a way that no affected individual is identified.
An entity is not required to notify an affected individual or give public notice under certain circumstances, such as if it believes it would endanger someone’s safety, reveal a trade secret, the affected individual is under the age of 16 and the entity believes that notice would be contrary to the individual’s interests, or if, after consultation with an individual’s health practitioner (where practicable), it believes that the notice would likely prejudice that individual’s health. Further, an organization may also delay notifying affected individuals or giving public notice of the breach under certain circumstances.
An entity who fails to notify the Commissioner of a notifiable data breach can be liable and fined up to $10,000 New Zealand dollars.
Specific employees, agents and members of agencies who fail to comply with these procedures, (notifying the Commissioner and affected individuals, or giving public notice) will not be personally liable, and their acts or knowledge of the breach will be treated as being done and known by the employer or entity.
6. Compliance Notices, Appeals and Fines
For any breaches of this Act, including the IPPs, interference with the privacy of an individual under another Act, breaches of any codes of practice or a code of conduct under another Act, the Commissioner may issue a “compliance notice” to the breaching entity. This grants the Commissioner greater discretion to require entities to act or refrain from certain behaviors. Compliance notices are enforced through the Tribunal, and a failure to comply is a criminal offense, resulting in fines up to $10,000 New Zealand dollars.
The Commissioner will consider a number of factors prior to issuing a compliance notice to an entity, such as the seriousness of the breach, the number of people affected, and the likely costs to the entity in order to comply with the notice. Prior to issuing a compliance notice, the Commissioner must also send the organization a written notice about the breach, any particular steps the organization should take to remedy it and dates to do so, and allow the organization a reasonable opportunity to respond.
A compliance notice then issued by the Commissioner will describe the breach, citing the relevant statutory provisions, require the entity to remedy it, and inform it of its appeal rights. The notice might also require the entity to take particular steps to remedy the breach, conditions that the Commissioner considers appropriate, dates the entity must remedy the breach or report to the Commissioner, or other useful information.
Once the compliance notice has been issued, the entity must, within a “practicable time”, take steps to comply with the notice and any particular steps specified within it, and remedy the breach by the date stated in the notice. The Commissioner, believing it is within the public’s interest, can publish 1) the entity’s identity, 2) details about the notice or the breach, or 3) a statement or comment about the breach.
6.1 Appeal of Compliance Notice
Businesses should be aware of the option to appeal a compliance notice, but also the potential of enforcement proceedings or interim orders brought and issued against them with respect to failing to comply with the notice. An entity may appeal to the Tribunal, 1) all or part of a compliance notice issued against it, or 2) the Commissioner’s decision to amend or cancel the notice. The appeal must be filed within 15 working days from the day on which the compliance notice was issued or the notice of the decision is given to the entity.
However, the Tribunal cannot cancel or modify a notice simply because 1) the breach was unintentional or without negligence on the part of the agency, or 2) the organization took steps to remedy the breach, unless there is no further reasonable step it could take to do so.
6.2 Enforcement of Compliance Notice
The Commissioner may also bring enforcement proceedings to the Tribunal for an agency’s noncompliance with a notice. The Commissioner can bring enforcement proceedings if, after the statutory period, no appeal has been filed against a notice, and, if either 1) the Commissioner has reason to believe that the entity did not, or will not, remedy the breach (if applicable, by the date stated in the notice), or 2) it failed to report to the Commissioner the steps it took to remedy the breach by the date stated in the notice. The entity may object to enforcement of the notice only on the ground that it believes it has fully complied with the notice. The Tribunal can determine whether the notice has been fully complied with, or order the entity to comply with the notice or perform an act specified in the order.
6.3 Remedies, Costs, and Enforcement
In the enforcement proceedings brought by the Commissioner, the Tribunal may grant an order requiring the entity to 1) comply with the notice by a date specified in the order (which may vary from the original date stated in the notice), 2) perform any act specified in the order by a date specified in the order (for example, reporting to the Commissioner on progress in complying with the notice), and 3) award costs it considers appropriate. In an appeal brought by the agency, the Tribunal may grant an order that 1) confirms, cancels, or modifies the notice and 2) confirms, overturns, or modifies the decision, and 3) award costs it considers appropriate.
An award of costs may be enforced in the District Court as if it were an order of that Court. An entity that, without reasonable excuse, fails to comply with the Tribunal’s decisions above can be fined up to $10,000 New Zealand dollars. Lastly, the Commissioner is entitled to appear or be represented by a lawyer or an agent during these proceedings.
6.4 Liability and Penalties
The Act imposes a $10,000 New Zealand dollars maximum fine on persons that fail to comply with any lawful requirement of the Commissioner or without reasonable excuse, obstructs, hinders or resists the Commissioner or any other person exercising authority under the law.
In addition, the Act also penalizes persons up to $10,000 New Zealand dollars who 1) knowingly make a false statement to the Commissioner or any other person exercising power under the Act; 2) misrepresent any authority they hold under the Act; 3) mislead companies by impersonating or pretending to be acting under the authority of an individual for the purpose of unlawfully obtaining access and using that individual’s information; or 4) destroy any document containing personal information knowing that it is subject to a data subject request.
Finally, the Act also sets out liability for companies for actions taken by their employees or agents. Unless the company does not know of the employee’s actions or has not given express or implied authority to its agents, it may be liable for any violation listed above carried out by such employees or agents. The Act offers an affirmative defense for companies that take reasonably practicable steps to prevent their employees or agents from violating the law.
Note that the law does not contain offenses punishable by imprisonment for officers or individuals that contravene its provisions.
7. Limited Private Right of Action, Class Actions
As far as the IPPs are concerned, they “do not confer on any person any right that is enforceable in a court of law”, except for the right of access (IPP6(1)) and only in relation to public sector agencies (see Section 31). However, individuals may challenge before the Human Rights Review Tribunal a Commissioner’s decision or failure of the company to comply with such a decision.
An individual may bring multiple complaints to the Privacy Commission on behalf of multiple aggrieved parties for an “interference with the privacy of an individual.” The Act defines an interference broadly as a breach of the Act or a private contract that could cause damage to the individual, adversely affect the rights of the individual or result in significant humiliation of the individual. An interference also includes decisions by companies to improperly refuse an access request or otherwise fail to respond timely to such requests.
After receiving the complaint, the Commissioner must consider the complaint and decide to either not investigate, refer the complaint to another person or overseas privacy enforcement agency, explore the possibility of securing settlement between the parties, or conduct an investigation. The Commissioner has wide authority to decide between any of these routes, but must respond to the complainant as soon as practicable with the reason for decision. Notably, the Commissioner may also refer a complaint directly to the Director of Human Rights Proceedings, as appointed under the New Zealand Human Rights Act, without conducting an investigation if it is unable to secure a settlement or discovers parties to a settlement have failed to comply with the terms of the settlement.
The Act gives the Commissioner discretion to collect information in the course of an investigation and regulate its own procedure. The Commissioner must conduct the investigation in a timely manner but has the authority to act upon the investigation in any manner the Commissioner finds satisfactory. After completing the investigation, the Commissioner may decide that it has no merits and dismiss the complaint.
When the complaint does have merits, the Commissioner must first attempt to secure settlement or obtain assurances between the parties before acting otherwise. If this fails, the Commissioner has broad discretion to either direct the company take remedial action with respect to an access request, refer the complaint directly to the Director, or take any other action the Commissioner considers appropriate.
Aggrieved individuals may appeal to the Human Rights Review Tribunal a Commissioner’s decision or failure of the company to comply with such a decision. Appeals may be commenced by the individual, a representative of the aggrieved individual or a representative lawfully acting on behalf of a class of aggrieved individuals. On appeal, the Tribunal may impose broad remedies to correct the interference, including actual and expected damages as well as damages for humiliation suffered by the individual. Companies may also appeal decisions reached by the Commissioner including enforcement of access.
8. Public Sector Data Sharing
The Act also sets forth provisions governing data sharing agreements between public entities in New Zealand. While the amendments did not change this section of the law, it is worth noting that New Zealand has its own regime governing the sharing of information between its public sector institutions. Each agreement pursuant to the law must meet certain transparency requirements including notifying any individual of an adverse action against them resulting from the agreement. These agreements help agencies access information to facilitate the execution of their legal duties and obligations.
Finally, the Act establishes provisions governing information matching programs. These programs allow entities to compare personal information as long as the parties meet a set of requirements including heightened notice, reporting and transparency obligations.
9. Conclusions
The New Zealand Privacy Act of 2020 is an interesting framework on the global privacy map, characterized by great responsibility in the hands of the Privacy Commissioner to breath life into the law and keep it up to date in the digital era. While being marginally inspired by GDPR provisions, and being able thus to contribute to interoperability of privacy regimes around the world, it stays true to New Zealand’s decades-old history of regulating privacy and data protection.
This blog is part of a series of overviews of new laws and bills around the world regulating the processing of personal data, coordinated by Gabriela Zanfir-Fortuna, Senior Counsel for Global Privacy ([email protected]).
Future of Privacy Forum, National Education Association Call for Review of Mandatory Video Policies in Online Learning
The Future of Privacy Forum (FPF) and National Education Association (NEA) today released new recommendations for the use of video conferencing platforms in online learning. The recommendations ask schools and districts to reconsider mandatory video requirements that create unique privacy and equity risks for students, including increased data collection, an implied lack of trust, and conflating students’ school and home lives.
“Mandating the use of video requires students to share more about their private home lives than they may want to, from their living situation to who they live with, creating potential social harm,” said Amelia Vance, FPF’s Director of Youth and Education Privacy. “It also risks deepening existing inequities, presenting additional challenges for students with disabilities, English language learners, and students with limited access to adequate wi-fi or video-supported devices. Video can be a helpful tool in online learning, but it shouldn’t be a mandatory one – or the only one – that educators use to engage with and assess students.”
“Video mandates during virtual class instruction coerces students to further blur the vanishing line between their home and school lives. When educators are required by districts to force video use, it violates the trust they’ve built with their students over countless hours of relationship-building through this pandemic and needlessly puts learning at risk in the pursuit of administrative oversight,” said Donna M. Harris-Aikens, Senior Director of Education Policy and Practice at the National Education Association.
Seventy-seven percent of students started the fall semester remotely, and as COVID-19 cases spike this winter, schools across the country are closing back down or delaying their in-person reopening plans. Recognizing that online learning, including video, is likely to remain essential through the remainder of the 2020-21 school year, FPF and NEA developed these recommendations to serve as a resource for educators that are continuing to navigate an evolving and unprecedented time in education.
Before mandating the use of video, the recommendations encourage educators to explore alternatives and considerations, including:
Considering alternatives to create and measure classroom engagement, such as quizzes at the end of a lesson, or encouraging students to respond and interact with material in different ways, including “reactions,” emojis, or the chat feature. Another option: using avatars protects student privacy while encouraging creativity and allows educators to feel as if they are teaching to more than a blank screen.
Considering privacy and equity throughout the process. There is no substitute to an in-person learning environment. While video may seem like the closest alternative, educators should carefully weigh the benefits and risks posed to privacy and equity, from increased data collection to the permanent documentation of deeply personal aspects of students’ home lives.
Teaching students about privacy and how to ingrain it into their online lives. The shift to online learning creates a key opportunity to teach student safe online practices, and the role they play in protecting their own privacy. Students should understand the implications of sharing personal information, what data is being collected about them, and how to adjust settings within products and services to be more privacy-protective, including to minimize data collection, data sharing, and third-party tracking.