Today, almost everything we do online involves companies collecting personal information about us. Personal data is collected and regularly used for a number of reasons – like when you use social media accounts, when you shop online or redeem digital coupons at the store, or when you search the internet.
Sometimes, information is collected about you by one company, and then shared or sold to another. While data collection can offer benefits to both you and businesses – like connecting with friends, getting directions, or sales promotions – it can also be used in ways that are intrusive – unless you take control.
There are many ways you can protect your personal data and information and control how it is shared and used. On this Data Privacy Day – recognized annually on January 28 to mark the anniversary of Convention 108, the first binding international treaty to protect personal data– the Future of Privacy Forum and other organizations are raising awareness and promoting best practices for data privacy.
For the second year in a row, FPF is partnering with Snap to provide a privacy-themed Snap filter to spread awareness of the importance of data privacy to your networks. Scan the Snapcode below to check it out:
Share the pictures you took using our interactive lens on social media using the hashtag #FPFDataPrivacyDay2022.
You should know that there are steps you can take to better protect your privacy online. Below, we’ve listed five tips you can follow to better protect your privacy when using your mobile device.
1. Check Your Privacy Settings
Many social media sites include options on how you can tailor your privacy settings to limit the ways data is collected or used. Snap provides privacy options that control who can contact you, and many other options. Start with the Snap Privacy Center to review your settings. You can find those choices here.
Snap provides options for you to view any data they have collected about you, including the date your account was created and the devices that have access to your account. Downloading your data allows you to view the types of information that has been collected and modify your settings accordingly.
Instagram allows you to manage a variety of privacy settings, including who has access to your posts, who can comment on or like your post, and manage what happens to posts after you delete them. You can view and change your settings here.
TikTok allows you to decide between public and private accounts, decide which accounts can view posted videos, and allows you to change your personalized ad settings. You can check your settings here.
Twitter allows you to manage if they share your information with third-party businesses, if the site can track your internet browsing outside of Twitter, and allows you to choose if you’d like ads to be tailored to you. Check your settings here.
Facebook provides a range of privacy settings that can be found here.
What other apps do you use often? Check to see which settings they provide!
2. Limit Sharing of Location Data
Most social media sites will ask for access to your location data. Do they need it for some reason that is obvious, like helping you with directions or showing your nearby friends? Feel free to say no. And be aware that location data is often used to tailor ads and recommendations based on locations you have recently visited. Allowing access to location services may also permit the sharing of location information with third-parties.
Snap has a variety of ways to control who is able to view your location. On their settings page, you can select whether no one, just select users, or all friends will be able to view your location on Snap Map. You can also choose to deny individual users from viewing your location.
To check the location permissions allowed to social media sites on an iPhone or Android, follow the below steps.
Navigate to “Settings”, then “Location,” and then “App Permissions”
Select the social media app you’d like to prevent from accessing your location
Make sure “Don’t Allow” is selected or “Allow only while using the app”.
3. Keep Your Devices & Apps Up to Date
Keeping software current and up to date is the only way to make sure that your device is protected against the latest software vulnerabilities. Having the latest security software, web browser, and operating system installed is the best way to protect against various online threats. By enabling automatic updates on your devices, you can be sure that your apps and operating system are always up to date.
Users can check the status of their operating systems in the settings app. For iPhone users, navigate to “Software Update,” and for Android devices, look for the “Security” page in settings.
4. Use a Password Manager
Utilizing a strong and secure password for each web-based account you have helps ensure personal data and information are protected from unauthorized use. It can be difficult to remember complex passwords for every account and using a password manager can help. Password managers save passwords as you create and log in to your accounts, often alerting you of any duplicates and suggesting the creation of a stronger password. For example, when signing up for new accounts and services, if you use an Apple product, you can allow your iPhone, Mac, or iPad to generate strong passwords and safely store them in iCloud Keychain for later access. Some of the best third-party password managers can be found here.
5. Enable Two-Factor Authentication
Two-factor authentication adds an additional layer of protection to your accounts. The first authentication is the normal username and password combination that has been used for years. The second factor is either a text message or email including a code that is sent to a personal device. This added step makes it harder for malicious actors to gain access to your accounts. Two-factor authentication only adds a few seconds to your day, but can save you from the headache and harm that comes from compromised accounts. To be even safer, use an authenticator app as your second factor.
As many of us continue to work and learn remotely, it’s important to stay aware of the information you share on and offline. Remember to adjust your settings regularly, staying on top of any privacy changes and updates made on the web applications you use daily. Take charge of protecting your personal data and encourage others to look at the information they may be sharing. By adjusting your settings and making changes to your web accounts and devices, you can better maintain the security and privacy of your personal data.
If you’re interested in learning more about one of the topics discussed here or about other issues that are driving the future of privacy, sign up for our monthly briefing, check out one of our upcoming events, or follow us on Twitter and LinkedIn. FPF brings together some of the top minds in privacy to discuss how we can all benefit from the insights gained from data, while respecting the individual right to privacy.
Five Burning Questions (and Zero Predictions) for the U.S. State Privacy Landscape in 2022
Entering 2022, the United States remains one of the only major economic powers that lacks a comprehensive, national framework governing the collection and use of consumer data throughout the economy. An ongoing impasse in federal efforts to advance privacy legislation has created a vacuum that state lawmakers, seeking to secure privacy rights and protections for their constituents, are actively working to fill.
Last year we saw scores of comprehensive privacy bills introduced in dozens of states, though when the dust settled, only Virginia and Colorado had joined California in successfully enacting new privacy regimes. Now, at the outset of a new legislative calendar, many state legislatures are positioned to make progress on privacy legislation. While stakeholders are eager to learn which (if any) states will push new laws over the finish line, it remains too early in the lawmaking cycle to make such predictions with confidence. So instead, this post explores five key questions about the state privacy landscape that will determine whether 2022 proves to be a pivotal year for the protection of consumer data in the United States.
1. Will A Single (State) Framework Emerge Supreme?
A common refrain heard in the U.S. privacy debate is that each state creating its own data privacy rules threatens to create a confusing and costly “patchwork” of divergent laws. While some degree of tension between different state privacy laws is already baked into the landscape, regulated entities may be hoping that a particular regulatory approach emerges as an interoperable norm across the states. Some of the likely contenders for this title are laid out below.
California Model
California was the first mover on comprehensive privacy legislation, enacting the California Consumer Privacy Act (CCPA) in June 2018. At the time, many observers predicted that the “California effect” would establish the CCPA as a de-facto national standard and drive the adoption of similar laws throughout the nation (reminiscent of breach reporting statutes in the 2000s). True to form, 2019 and 2020 saw dozens of CCPA-style copycat bills introduced; however, no such bill has yet proven successful. One possible reason is that California’s approach to privacy has been something of a ‘moving target’ – having undergone multiple amendments, an extended Attorney General rulemaking process, the conversion of the CCPA into the California Privacy Rights Act (CPRA) by ballot initiative, and the recent launch of a new CPRA rulemaking process.
Virginia/Colorado Model
In 2021, a new challenger appeared with the enactment of the Virginia Consumer Data Protection Act (VCDPA) and the Colorado Privacy Act (CPA). While containing multiple important distinctions (that will be explored in a subsequent post), these laws generally adhere to the same basic framework for establishing consumer privacy rights and dividing business obligations between data “controllers” and “processors.” The Virginia/Colorado model also exceeds California in certain key areas, including by requiring affirmative consent for the processing of “sensitive” personal data. As a result, this framework could represent a more stable approach to protecting privacy than California that may be palatable to consumer and industry stakeholders alike.
Other Models
While California and the Virginia/Colorado models are the clear favorites, they are not the full field of contenders that could emerge as the dominant U.S. privacy framework. Last July, the Uniform Law Commission (ULC) finalized its model privacy law, the “Uniform Personal Data Protection Act,” which has already been introduced in the District of Columbia (CB 24-451), Nebraska (LB 1188), and Oklahoma (HB 3447). Notably, the ULC model significantly conflicts with established privacy frameworks and has received reactions ranging from skepticism to hostility from both industry and consumer advocacy groups, creating questions about its political viability.
There is also pending legislation in several states that, if enacted, would constitute distinct regulatory approaches from the adopted laws. For example, there are bills to watch in Massachusetts (S 46) (establishing fiduciary-style obligations on businesses); New Jersey (A 505) (including a ‘legitimate interest’ basis for data processing); and Oklahoma (HB 2969) (containing expansive use limitation requirements).
In surveying the state privacy bills introduced this year, a clear divide between the California and Colorado/Virginia frameworks is evident. State bills in Alaska (HB 222) and Indiana (HB 1261) include California-style rights for consumers to opt-out of the sale and sharing of personal information and to limit the use and disclosure of sensitive personal information. Elsewhere in Hawaii (SB 2797) and Pennsylvania (HB 2257), legislative proposals more closely follow the Virginia/Colorado approach to requiring affirmative consent for processing “sensitive data” in addition to creating opt-out rights for data sales, targeted advertising, and profiling.
2. Where Will Regulatory Processes Lead?
While much attention will be paid to the state legislative horse race, two states with laws on the books will undertake important privacy rulemaking processes this year. In California, the newly constituted California Privacy Protection Agency (CPPA) is directed to conduct a wide-ranging rulemaking that will clarify key definitions and compliance issues left open under the CPRA. Rulemaking subjects include the CPRA’s new right of correction, valid uses of data for ‘business purposes,’ and the application of the law to automated decision-making processes. In Colorado, the Attorney General has similarly been delegated broad rulemaking authority and is specifically tasked with the adoption of “rules that detail the technical specifications for one or more universal opt-out mechanisms” (discussed further below).
California and Colorado’s rulemaking processes will likely have significant impacts on the ultimate implementation and exercise of consumers’ new privacy rights in these states. Furthermore, while the CPRA and CPA statutes specifically direct the development of rules governing certain issues, their grants of rulemaking authority are open-ended, meaning that final regulations may potentially broaden the consumer rights and business compliance obligations established under these laws. However, such an expansive regulatory approach would likely be strongly contested. For example, the CPPA’s request for comment on preliminary rulemaking activity surfaced significant fault lines in stakeholder expectations for what CPRA rulemaking can and should entail for significant elements of the law.
Not all new state privacy laws will necessarily provide for open-ended rulemaking processes and Virginia’s privacy law lacks a rulemaking process entirely. Privacy bills under consideration in 2022 have largely followed an ‘all-or-nothing’ approach to rulemaking with legislation such as Maryland (SB 11) and Washington (HB 1850) seeking to give the state Attorney General or other regulators broad rulemaking authority and bills like Ohio (HB 376) providing for no rulemaking at all. Going forward, the inclusion of rulemaking authority in new privacy laws could create additional divergences between different state approaches. However, rulemaking may also help state laws remain flexible in light of changing technology and allow lawmakers to delegate some of the more nuanced technical issues to experts with the benefit of public participation.
3. How will State Activity Impact the Federal Debate?
Despite the introduction of over a dozen federal bills and numerous hearings since 2018, bipartisan federal collaboration on comprehensive privacy legislation has repeatedly stalled out. Key lawmakers remain divided over critical issues such as private rights of action, preemption, and how to regulate against discriminatory uses of data.
Advancements in privacy at the state level will likely breathe new life into the dormant federal debate – but its impact remains uncertain. One possibility is that the adoption of additional state privacy laws may ultimately create so much regulatory complexity for industry that breakthrough on federal privacy legislation becomes inevitable.
Alternatively, the enactment of even a single state law that contains a broad private right of action may push concerned industry stakeholders towards compromise over a federal privacy bill. Most industry participants view private lawsuits as particularly ‘Ill-Suited’ for the privacy context, and no state has yet enacted comprehensive privacy legislation providing for expansive private lawsuits. A range of approaches to the issue of private lawsuits have been taken in the legislation under consideration this year. In addition to bills that would establish expansive causes of action such as New York (S 6701) or explicitly disclaim such suits like Florida (SB 1864), some bills would restrict lawsuits to particular violations like Florida (HB 9) or permit lawsuits but restrict statutory damages such as Washington State (SB 5813).
Finally, the successful enactment of state privacy laws containing novel approaches to protecting privacy could inform new legislative proposals at the federal level. Given that the only states to enact comprehensive privacy laws have had (at the time) unified Democratic governments, the adoption of a privacy law by a Republican-led state could impact the contours of the federal conversation. Serious efforts to enact privacy legislation have been undertaken in Republican controlled state legislatures in Florida, Ohio, and Oklahoma, with more likely on the way.
4. Will ‘Universal’ Privacy Controls be the Next Big Thing?
Many stakeholders have expressed concern that leading privacy frameworks rely too heavily on individual controls and consent options that are overwhelming and unscalable for ordinary consumers in practice. One response to this criticism has been the development and legal recognition of ‘user-selected universal opt-out mechanisms,’ often exercised through browser settings or plug-ins, that signal a consumer’s request to exercise their privacy rights to the websites they visit. Under present law, such privacy controls are omitted from the VCDPA; recognized, but not clearly mandated under the CPRA; and will be required in Colorado come 2024.
As a newer approach to expressing privacy preferences, stakeholders have raised questions about the legal and practical effects that this class of ‘universal’ controls should carry. For example, how businesses should respond if they receive multiple, conflicting signals from different browsers or devices used by the same person. Furthermore, the potential development of separate processes governing the adoption of new signal mechanisms and likely state-by-state differences in the underlying privacy rights these controls will exercise could further complicate their use.
Nevertheless, ‘universal’ privacy controls represent a significant opportunity to advance consumer privacy interests and appear poised to become an increasingly prominent aspect of the privacy debate in the years to come. At present, the majority of active state bills would give businesses flexibility in determining context-appropriate methods for the exercise of consumers privacy rights including in Florida (SB 1864) and Kentucky (SB 15). However, bills in Maryland (SB 11) and Alaska (HB 159) would join Colorado in providing for the mandatory recognition of such signals.
5. Will Sectoral Privacy Laws Lead the Way?
This post has focused on ‘comprehensive’ privacy legislation, broad-based legal frameworks that would establish baseline, industry and technology neutral rules for the protection of personal data throughout a state’s economy. However, state lawmakers are also on track to propose hundreds of more narrowly focused privacy bills that would regulate either particular industries such as data brokers (Delaware HB 262) or ISPs (New York S 3885); categories of information such as childrens’ data (Washington State HB 1697) or biometrics (Kentucky HB 32); or establish specific business obligations such as reasonable security practices (West Virginia HB 2925) or transparency requirements (New Jersey A 1971). While some of these proposals are particularly narrow or limited in scope (for example, establishing a commission to study a particular issue), others could serve as both templates and catalysts for sweeping change in Americans’ privacy expectations and outcomes.
Conclusion
This commentary has noted several states where privacy legislation is already under serious consideration for the 2022 legislative calendar. However, the past informs us that fast-shifting local political dynamics can kick up surprises for state privacy efforts. Last year’s adoption of new privacy laws in Colorado and Virginia took many observers by surprise, and successful legislation may emerge from unexpected jurisdictions again this year. This post has posed many questions but can offer only one clear forecast: a turbulent and exciting year for consumer privacy legislation is just beginning. Be sure to follow the Future of Privacy Forum for updates on the U.S. privacy landscape throughout the year.
Addressing the Intersection of Civil Rights and Privacy: Federal Legislative Efforts
Last month, the National Telecommunications and Information Administration (NTIA) hosted virtual listening sessions on the intersection of data privacy, equity, and civil rights. Around the same time, the FTC announced that they will begin rulemaking on discriminatory practices in automated decision making, and currently, an influx of state legislation containing civil rights provisions have been introduced.
Decades of research demonstrate the effects of data processing on existing structural inequalities such as race, gender, and disability, and there have been numerous attempts by federal and state governments to regulate the disparate impacts of data practices on protected classes. Though the intersection of data privacy and civil rights has been discussed in policy circles for years, these bills containing civil rights provisions have been surprisingly under-analyzed.
In the coming weeks and months, FPF will be publishing a blog series to provide an informative overview of government efforts to regulate discriminatory data practices through proposed legislation and executive agency enforcement. This blog is the first in the series and will cover federal legislative efforts.
In sum:
In recent years, both Democrats and Republicans have introduced several comprehensive data privacy bills that would prohibit data processing that violates anti-discrimination laws. There is party division in areas of auditing/reporting burdens and enforcement.
There is also division on the scope of civil rights protections. While some proposals intend to apply data processing activities to what is prohibited under the existing federal anti-discrimination framework, others propose effectively expanding civil rights laws, such as expanding the definition of “protected classes” and extending public accommodation law (which has traditionally only applied to physical spaces) to online sellers of goods and services.
Some representatives and advocates remain concerned about the effects and enforcement of adtech and targeted advertising on marginalized and vulnerable populations.
Leading Federal Comprehensive Data Privacy Bills
Members of Congress have introduced a number of comprehensive data privacy bills in recent years, some of which contain civil rights provisions. The leading proposals from Democratic and Republican leaders in the Senate Commerce Committee are the Consumer Online Privacy Rights Act (COPRA) and the SAFE DATA (Setting an American Framework to Ensure Data Access, Transparency, and Accountability Act).
Table 1 (below) provides a helpful comparison of the key civil rights provisions in each bill. In general, COPRA contains more comprehensive civil rights provisions than the SAFE DATA Act, which mainly codifies unlawful data processing activities under federal anti-discrimination laws and permits the FTC to inform other agencies about potential violations.
Under COPRA, it would be unlawful to conduct discriminatory data processing in areas covered by federal anti-discrimination laws, such as housing, employment, and education, on the basis of a protected class. Protected classes would include those already protected under the law (race, sex, disability, etc.), as well as include new ones such as source of income, familial status, and biometric information. COPRA would also require entities to conduct impact assessments on the accuracy, bias, and potential discrimination of their algorithms. Violations of the law would be enforced through the FTC, state AGs, or through a private right of action, where a plaintiff could recover up to $1,000 per violation per day. Small businesses, however, would be exempt. In comparison (see Table 1), the SAFE DATA Act contains few civil rights provisions.
Table 1.
COPRA, Section 108
SAFE DATA, Section 201
Discrimination Provisions
A covered entity shall not process or transfer covered data on the basis of [protected class] for the purpose of:
(A) advertising, marketing, soliciting, offering, selling, leasing, licensing, renting, or otherwise commercially contracting for a housing, employment, credit, or education opportunity, in a manner that unlawfully discriminates against or otherwise makes the opportunity unavailable to the individual or class of individuals; OR
(B) in a manner that unlawfully segregates, discriminates against, or otherwise makes unavailable to the individual or class of individuals the goods, services, facilities, privileges, advantages, or accommodations of any place of public accommodation.
Whenever the Commission obtains information that a covered entity may have processed or transferred covered data in violation of Federal anti-discrimination laws, the Commission shall transmit such information…to the appropriate Executive agency or State agency with authority to initiate proceedings relating to such violation.
Algorithmic Decision-making
[A] covered entity engaged in algorithmic decision-making…to make or facilitate advertising for housing, education, employment or credit opportunities…or restrictions on the use of, any place of public accommodation, must annually conduct an impact assessment of such algorithmic decision-making that—
(A) describes and evaluates the development of the covered entity’s algorithmic decision-making processes including the design and training data used to develop the algorithmic decision-making process, how the algorithmic decision-making process was tested for accuracy, fairness, bias, and discrimination; and
(B) assesses whether the algorithmic decision-making system produces discriminatory results on the basis of an individual’s or class of individuals’ [protected class]
The Commission shall conduct a study…examining the use of algorithms to process covered data in a manner that may violate Federal anti-discrimination laws.
Enforcement
FTC, state attorneys general, and by individuals through a private right of action.
A plaintiff bringing suit would not be required to prove injury in fact (a violation alone is the injury) and could seek damages up to $1000/violation (or actual damages, if greater).
The bill would also invalidate any pre-dispute arbitration agreement that waives claims arising under this law.
FTC, or other appropriate state or federal agency.
Table 1
Federal Sectoral Legislation
In some cases, sectoral efforts have taken a more dynamic approach to addressing specific harms. For example, Senator Markey (D-MA) introduced the Algorithmic Justice and Online Platform Transparency Act, which would prohibit unlawful discrimination in automated decision-making (as opposed to general data processing, as in COPRA and SAFE DATA) and impose transparency requirements mandating review and assessment of algorithms for disparate impact on protected classes.
Importantly, the bill would explicitly extend public accommodation law to “any commercial entity that offers goods and services through the internet to the general public.” Currently, Title II and III of the Civil Rights Act of 1964 prohibit discrimination on the basis of race, color, national origin, or disability in places of “public accomodation,” such as hotels, restaurants, theaters, and similar physical spaces. The law has not been amended to extend to online commerce (and federal circuit courts are split on the issue with respect to Title III). While COPRA includes “places of public accommodation” within its scope of entities that may not conduct discriminatory data processing, it does not explicitly expand federal anti-discrimination law to online retailers and marketplaces. Markey’s bill would.
In a more recent example, the “Banning Surveillance Advertising Act,” introduced by Anna Eshoo (D-CA) this week, would flatly prohibit targeted advertising based on protected characteristics under current federal anti-discrimination law – such race, color, sex (including sexual orientation and gender expression), and disability. Unlike COPRA, the SAFE DATA Act, and the Markey bill, this legislation contains no small business exemption.
Advocates’ Goals
Most proposals have not gone as far as some civil rights advocates have proposed. For example, the Lawyers’ Committee for Civil Rights Under Law and Free Press introduced a comprehensive Model Bill in March 2019, that would not only would prohibit discriminationin economic opportunities (housing, employment, credit, insurance, or education) and in public accomodations (including any business that offers goods or services through the internet, as in the Markey bill), but also in any manner that would interfere with a person’s right to vote. Similar to COPRA, the Model Bill would also impose auditing requirements for discriminatory processing.
In the Lawyers’ Committee proposal, the law would be enforced by the FTC, the states, the DOJ Civil Rights Division, or through a private right of action. The civil penalty for violation would be heftier than other legislation, with $16,500 per violation (or up to 4% of annual revenue if punitive damages are warranted or the action is brought by the state).
Other notable provisions in the Model Bill which are not in COPRA nor the SAFE DATA Act include:
Expanded Definition of “Privacy Risk.” The expanded definition would include intangible harms such as psychological harm (anxiety, embarrassment, fear), stigmatization or reputational harm, and disruption from unwanted commercial solicitations.
Shifting Burden of Proof. Typically, a party bringing a civil suit has a duty to prove each assertion or claim. Similar to existing civil rights law, however, the Model Bill would utilize a burden-shifting framework: where if the plaintiff demonstrates disparate impact on the basis of a protected characteristic from a data processing activity, the burden would shift to the defendant to show that such processing was necessary to achieve a substantial, legitimate, and nondiscriminatory interest. If the defendant meets that burden, the burden shifts back to the plaintiff to demonstrate that an alternative policy or practice could serve such interest with a less discriminatory effect.
Affirmative Duty to Interrupt. Entities would have a duty to prevent or aid in preventing civil rights violations under the law, where any entity that makes a conscious effort to avoid actual knowledge of violation and has the ability to prevent or halt such violation shall also be liable.
Targeted Advertising. At least some forms of targeted advertising would be regulated as an unfair and deceptive practice through the FTC, taking into consideration factors like predatory or manipulative practices that harm marginalized populations, as well as methods for promoting diversity and inclusion of small businesses owned by underrepresented populations, amongst others.
We anticipate that the debate regarding the scope and substance of civil rights protections in data privacy policy is just beginning. The NTIA intends to publish a Notice and Request for Comments in the Federal Register regarding this topic, where members of the public unable to participate in the Listening Sessions are encouraged to respond.
Brain-Computer Interfaces & Data Protection: Understanding the Technology and Data Flows
This post is the first in a four-part series on Brain-Computer Interfaces (BCIs), providing an overview of the technology, use cases, privacy risks, and proposed recommendations for promoting privacy and mitigating risks associated with BCIs.
Click here for FPF and IBM’s full report: Privacy and the Connected Mind. Additionally, FPF-curated resources, including policy & regulatory documents, academic papers, thought pieces, and technical analyses regarding brain-computer interfaces are here.
I. Introduction – What are BCIs and Where are They Used?
Today, Brain-Computer Interfaces (BCIs) are primarily used in the health-care context for purposes including rehabilitation, diagnosis, symptom management, and accessibility. While BCI technologies are not yet widely adopted in the consumer space, there is increasing interest and proliferation of new direct-to-consumer neurotechnologies from gaming to education. It is important to understand how these technologies use data to provide services to individuals and institutions, as well as how the emergence of such technologies across sectors can create privacy risks. As organizations work to build BCIs while mitigating privacy risks, it is paramount for policymakers, consumers, and other stakeholders to understand the state of the technology today and associated neurodata and its flows.
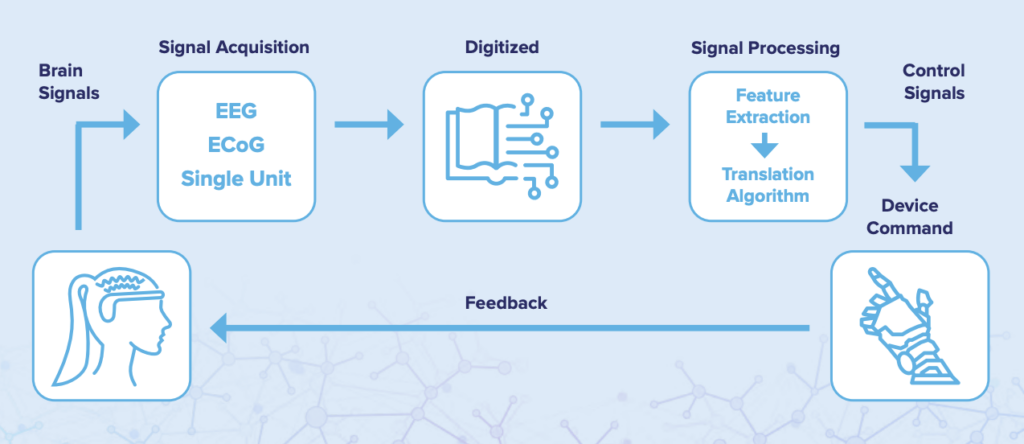
BCIs are computer-based systems that directly record, process, or analyze brain-specific neurodata and translate these data into outputs that can be used as visualizations or aggregates for interpretation and reporting purposes and/or as commands to control external interfaces, influence behaviors or modulate neural activity.
BCIs can be broadly divided into three categories: 1) those that record brain activity; 2) those that modulate brain activity; and 3) those that do both, also called bi-directional BCIs (BBCIs).
BCIs can be invasive or non-invasive and employ a number of techniques for collecting neurodata and modulating neural signals.
Neurodata is data generated by the nervous system, which consists of the electrical activities between neurons or proxies of this activity.
Personal neurodata is neurodata that is reasonably linkable to an individual.
BCIs that record brain activity are more commonly used in the healthcare, gaming, and military contexts. Modulating BCIs are typically found in the healthcare context, such as when used to treat Parkinson’s disease and other movement disorders by using deep brain stimulation. BCIs cannot at present or in the near future “read a person’s complete thoughts,” serve as an accurate lie detector, or pump information directly into the brain.
II. BCIs Can Be Invasive or Non-Invasive. Both Employ a Number of Techniques for Recording Neurodata and Modulating Neural Signals
Invasive BCIs are installed directly into—or on top of—the wearer’s brain through a surgical procedure. Today, invasive BCIs are used in the health context for a variety of purposes, such as improving patients’ motor skills. Invasive BCI implants can involve a number of different types of implants. An electrode array called a Utah Array is installed into the brain and relies on a series of small metal spikes set within a small square implant to record or modulate brain signals. Other prominent examples of invasive BCIs rely on electrocorticography (ECoG), where electrodes are attached to the brain’s exposed surface to measure the cerebral cortex’s electrical activity. ECoG is most widely used to help medical providers locate the brain area that is the center of epileptic seizures.
Unlike invasive BCIs, non-invasive BCIs do not require surgery. Instead, non-invasive BCIs rely on external electrodes and other sensors to collect and modulate neural signals. One of the most prominent examples of a non-invasive BCI technology is an electroencephalogram (EEG)—a method for recording the brain’s electrical activity, with electrodes placed on the scalp’s surface to measure neurons’ activity. EEG-based BCIs are common in gaming where collected brain signals are used to control in-game characters and select in-game items. Another noteworthy non-invasive method is near-infrared spectroscopy (fNIRS), which measures proxies of brain activity via changes in blood flow to certain regions, specifically changes in oxygenated and deoxygenated hemoglobin concentration using near-infrared light. fNIRS is especially prominent in wellness and medical BCIs, such as those used to control prosthetic limbs.
Other non-invasive techniques go beyond simply recording neurodata by also modulating the brain. For example, transcranial direct current stimulation (tDCS) and transcranial magnetic stimulation (TMS) are both used to modulate neuroactivity. Non-invasive neurotechnologies should not be equated to non-harmful technologies—just because a device is not directly implanted to sit on or within the brain does not mean that it does not pose unique health and other privacy and data use risks.
Both invasive and non-invasive BCIs are generally characterized by four components:
Signal Acquisition and Digitization: Involves sensors (e.g. EEG, fMRI, ect.) measuring neural signals. The device amplifies to levels that enable processing and sometimes filters collected signals to remove unwanted data elements, such as noise and artifacts. These signals are digitized and transferred to a computer.
Feature Extraction: As part of signal processing, applicable signals are separated from extraneous data elements, including artifacts and other undesirable elements.
Feature Translation: Signals are transformed into usable outputs.
Device Output: Translated signals can be used as visualizations for research or care, or they can be used as directed instructions, including feedforward commands utilized to operate external BCI components (e.g. external software or hardware like a robotic arm) or feedback commands which may provide afferent (conducted inward) information to the user or may directly modulate on-going neural signals.
III. Recorded Neurodata Becomes Personal Neurodata When it is Reasonably Linkable to an Individual
Neurodata is data generated by the nervous system, which consists of the electrical activities between neurons or proxies of this activity. Neurodata can be both directly recorded from the brain—in the case of BCIs—or indirectly recorded from an individual’s spinal cord, muscles, or peripheral nerves.
At times, neurodata can be personally identifiable when reasonably linkable to an individual or when combined with other identifying data associated with an individual, such as when part of a particular user profile. The recording and processing of personal neurodata can produce information related to an individual’s biology and cognitive state that is directly tied to that user’s record, use, or account. Additionally, the processing of personal neurodata can lead to inferences about an individual’s moods, intentions, and various physiological characteristics, such as arousal. Machine learning (ML) sometimes plays a role as a tool for helping determine if a neurodata pattern matches a general identifier or particular class or physiological state. Although identifying an individual based solely on their recorded personal neurodata is difficult, such identification has been shown to be possible with relatively minimal data (less than 30 seconds-worth of electrical activity) within a lab setting. Some experts believe that such identification is feasible more broadly in the near term.
Personal neurodata can reveal seemingly innocuous data; record behavioral interactive activity; include health information associated with an individual; or potentially provide insight into an individual’s feelings or intentions. BCIs may eventually progress into new arenas, recording increasingly sensitive personal neurodata, leading to intimate inferences about individuals. Those applications may seek to include transcribing a wide-range of a wearer’s thoughts into text, serving as an accurate lie detector, and even implanting information directly into the brain. However, these speculative uses are still in the early research phases and could be decades from fruition, or perhaps never emerge.
IV. Conclusion
As BCIs evolve and are more commercially available across numerous sectors, it is paramount to understand the unique risks such technologies pose. Although our report, and this blog series, primarily focus on the privacy concerns—including questions about the transparency, control, security, and accuracy of data— around the existing and emerging BCI capabilities, these technologies also raise important technical considerations and ethical implications, related to, for example fairness, justice, human rights, and personal dignity. We will highlight where additional ethical and technical concerns emerge in various use cases and applications of BCIs throughout this series.
12th Annual Privacy Papers for Policymakers Awardees Explore the Nature of Privacy Rights & Harms
The winners of the 12th annual Future of Privacy (FPF) Privacy Papers for Policymakers Award ask big questions about what should be the foundational elements of data privacy and protection and who will make key decisions about the application of privacy rights. Their scholarship will inform policy discussions around the world about privacy harms, corporate responsibilities, oversight of algorithms, and biometric data, among other topics.
“Policymakers and regulators in many countries are working to advance data protection laws, often seeking in particular to combat discrimination and unfairness,” said FPF CEO Jules Polonetsky. “FPF is proud to highlight independent researchers tackling big questions about how individuals and society relate to technology and data.”
This year’s papers also explore smartphone platforms as privacy regulators, the concept of data loyalty, and global privacy regulation. The award recognizes leading privacy scholarship that is relevant to policymakers in the U.S. Congress, at U.S. federal agencies, and among international data protection authorities. The winning papers will be presented at a virtual event on February 10, 2022.
The winners of the 2022 Privacy Papers for Policymakers Award are:
Privacy Harms, by Danielle Keats Citron, University of Virginia School of Law; and Daniel J. Solove, George Washington University Law School
This paper looks at how courts define harm in cases involving privacy violations and how the requirement of proof of harm impedes the enforcement of privacy law due to the dispersed and minor effects that most privacy violations have on individuals. However, when these minor effects are suffered at a vast scale, individuals, groups, and society can feel significant harm. This paper offers language for courts to refer to when litigating privacy cases and provides advice as to when privacy harm should be considered in a lawsuit.
In this paper, Green analyzes the use of human oversight of government algorithmic decisions. From this analysis, he concludes that humans are unable to perform the desired oversight responsibilities, and that by continuing to use human oversight as a check on these algorithms, the government legitimizes the use of these faulty algorithms without addressing the associated issues. The paper offers a more stringent approach to determining whether an algorithm should be incorporated into a certain government decision, which includes critically considering the need for the algorithm and evaluating whether people are capable of effectively overseeing the algorithm.
The Surprising Virtues of Data Loyalty, by Woodrow Hartzog, Northeastern University School of Law and Khoury College of Computer Sciences, Stanford Law School Center for Internet and Society; and Neil M. Richards, Washington University School of Law, Yale Information Society Project, Stanford Center for Internet and Society
The data loyalty responsibilities for companies that process human information are now being seriously considered in both the U.S. and Europe. This paper analyzes criticisms of data loyalty that argue that such duties are unnecessary, concluding that data loyalty represents a relational approach to data that allows us to deal substantively with the problem of platforms and human information at both systemic and individual levels. The paper argues that the concept of data loyalty has some surprising virtues, including checking power and limiting systemic abuse by data collectors.
Smartphone Platforms as Privacy Regulators, by Joris van Hoboken, Vrije Universiteit Brussels, Institute for Information Law, University of Amsterdam; and Ronan Ó Fathaigh, Institute for Information Law, University of Amsterdam
In this paper, the authors look at the role of online platforms and their impact on data privacy in today’s digital economy. The paper first distinguishes the different roles that platforms can have in protecting privacy in online ecosystems, including governing access to data, design of relevant interfaces, and policing the behavior of the platform’s users. The authors then provide an argument as to what platforms’ role should be in legal frameworks. They advocate for a compromise between direct regulation of platforms and mere self-regulation, arguing that platforms should be required to make official disclosures about their privacy-related policies and practices for their respective ecosystems.
China enacted the first codified personal information protection law in China in late 2021, the Personal Information Protection Law (PIPL). In this paper, Wang compares China’s PIPL with data protection laws in nine regions to assist overseas Internet companies and personnel who deal with personal information in better understanding the similarities and differences in data protection and compliance between each country and region.
Cameras are everywhere, and with the innovation of video analytics, there are questions being raised about how individuals should be notified that they are being recorded. This paper studied 123 individuals’ sentiments across 2,328 video analytics deployments scenarios to inform their conclusion. In their conclusion, the researchers advocate for the development of interfaces that simplify the task of managing notices and configuring controls, which would allow individuals to communicate their opt-in/opt-out preference to video analytics operators.
From the record number of nominated papers submitted this year, these six papers were selected by a diverse team of academics, advocates, and industry privacy professionals from FPF’s Advisory Board. The winning papers were selected based on the research and solutions that are relevant for policymakers and regulators in the U.S. and abroad.
In addition to the winning papers, FPF has selected two papers for Honorable Mention: Verification Dilemmas and the Promise of Zero-Knowledge Proofs by Kenneth Bamberger, University of California, Berkeley – School of Law; Ran Canetti, Boston University, Department of Computer Science, Boston University, Faculty of Computing and Data Science, Boston University, Center for Reliable Information Systems and Cybersecurity; Shafi Goldwasser, University of California, Berkeley – Simons Institute for the Theory of Computing; Rebecca Wexler, University of California, Berkeley – School of Law; and Evan Zimmerman, University of California, Berkeley – School of Law; and A Taxonomy of Police Technology’s Racial Inequity Problems by Laura Moy, Georgetown University Law Center.
FPF also selected a paper for the Student Paper Award, A Fait Accompli? An Empirical Study into the Absence of Consent to Third Party Tracking in Android Apps by Konrad Kollnig and Reuben Binns, University of Oxford; Pierre Dewitte, KU Leuven; Max van Kleek, Ge Wang, Daniel Omeiza, Helena Webb, and Nigel Shadbolt, University of Oxford. The Student Paper Award Honorable Mention was awarded to Yeji Kim, University of California, Berkeley – School of Law, for her paper, Virtual Reality Data and Its Privacy Regulatory Challenges: A Call to Move Beyond Text-Based Informed Consent.
The winning authors will join FPF staff to present their work at a virtual event with policymakers from around the world, academics, and industry privacy professionals. The event will be held on February 10, 2022, from 1:00 – 3:00 PM EST. The event is free and open to the general public. To register for the event, visit https://bit.ly/3qmJdL2.
Overcoming Hurdles to Effective Data Sharing for Researchers
In 2021, challenges faced by academics in accessing corporate data sets for research and the issues that companies were experiencing to make privacy-respecting research data available broke into the news. With its long history of research data sharing, FPF saw an opportunity to bring together leaders from the corporate, research, and policy communities for a conversation to pave a way forward on this critical issue. We held a series of four engaging dinner-time conversations to listen and learn from the myriad voices invested in research data sharing. Together, we explored what it will take to create a low-friction, high-efficacy, trusted, safe, ethical, and accountable environment for research data sharing.
FPF formed an expert program committee to set the agenda for the discussion series. The committee guided our selection of topics to discuss, helped identify talented experts to present their views, and introduced FPF to new and salient stakeholders to the research data sharing conversation. The four virtual dinners were held on Thursday, November 4, November 16, December 2, and December 18. Below are significant points of discussion from each event.
The Landscape of Data Sharing
During the first dinner discussion, participants emphasized the importance of reviewing research for ethical soundness and methodological rigor. Many highlighted the challenges of performing consistent and fair ethical and methodological reviews given corporate and research stakeholders’ different expectations and capabilities. FPF has explored this dynamic in the past: both companies and researchers operate with a responsibility to the public that requires technical, ethical, and organizational work to fulfill. The ability of critical stakeholders, including consumers themselves, to articulate the clear and practical steps they take to build trusted public engagement in data sharing varies widely.
Participants offered that one of the key steps necessary to improve public and stakeholder trust in data sharing is to improve education for all parties on the topic. In particular, current efforts should be revised and expanded to more intuitively explain data collection, stewardship, hygiene, interoperability, and the differences in corporate and researchers’ data needs and expectations. Participants suggested improving consumers’ digital literacy so that consent to collecting or using personal data can be more meaningful and dynamic.
Research Ethics and Integrity for a Data Sharing Environment
During our second dinner, two topics emerged. First, participants pointed out how regulations and organizational rules limit the ability of institutions to superintend the ethical, technical, and administrative reviews called for in discussions of data sharing.
Second, the participants honed in on data de-identification and anonymization as critical components of ethical and technical review of proposed data uses for research. While variations in the interpretation of research ethics regulations and norms by Institutional Review Boards (IRBs) lead to an inconsistent and shifting landscape for researchers and companies, the expert panelists pointed out that the variation between IRBs is not as significant as the variation between regulatory controls for research governed by federal restrictions (the Common Rule) and those applied to commercial research under consumer protection laws.
Several participants advocated for a comprehensive U.S. federal data privacy law to equalize institutional variations, eliminate gaps between consumer data protection and research data protections, and clarify protections for research uses of commercial data. Efforts to close such regulatory gaps would require educating all stakeholders, including legislators, researchers, data scientists, and companies’ data protection officers, about the relative differences between risks around research data and risks associated with commercial use or breach of consumer data.
While participants recommended comprehensive privacy legislation as an ideal, serious consideration was paid to the role that specific agency rule-making efforts could play in this space. One of the topics for rulemaking was the concept of data anonymization. Participants considered how to achieve agreement on the ethical imperative for data anonymization. They identified some important steps toward anonymization, such as developing a more agreeable definition of “anonymous” that could be implemented by the many different parties involved in the research data sharing process and providing essential technical support to achieve the expected standards of data anonymization.
The Challenges of Sharing Data from the Perspective of Corporations
During our third dinner, the discussion focused on assessing researchers’ fitness to access an organization’s data. We also discussed evaluating research projects in light of public interest expectations. There was widespread agreement that data sharing is vital for various reasons, such as promoting the next generation of scientific breakthroughs and holding companies publicly accountable. On the other hand, there was disagreement on ensuring that data is available for research and that individuals’ privacy is continuously protected.
Some asserted that privacy was being used as an argument by companies to protect their interests and that it is not as tricky a standard to achieve as is described. Others disagreed with this assessment, saying that they always assumed the worst when it came to the efficacy of privacy protections.
There are also technical and social barriers to democratizing access to corporate data for research. Participants pointed out that technical barriers can be low bars, like file size and type, or high barriers, such as overcoming data fragmentation, including personnel expertise when reviewing projects, building and maintaining shareable data, and managing sector-specific privacy legislation that governs what companies must do to achieve existing data privacy requirements.
Social barriers were discussed as high bars, like limiting access to researchers affiliated with the “right” institutions. Participants discussed how to sufficiently democratize know-how to expand corporate data-sharing and build and maintain the trusted network relationships critical for facilitating data sharing across various parts of the researcher-company environment. Consent reemerged as both a technical and social barrier to data sharing. In particular, participants addressed the problem of securing consumers’ meaningful consent for the use of data in unforeseen but beneficial research use cases that may arise far in the future.
Legislation, Regulation, and Standardization in Data Sharing
During the final dinner conversation, participants tackled the challenging issues of legislation, regulation, and standardization in the research data sharing environment. There was broad agreement that there should be standards for data sharing to make the process more accessible and data more usable. Most participants agreed that data should be FAIR and harmonious. Still, there was disagreement over what field or institution is a good model for this (economics, astronomy, and the US Census were discussed as possibilities).
There was agreement that researchers should meet a certain standard to be given access, but this must be done carefully to avoid creating tiers of first and second-class researchers. The discussion highlighted the importance of having shared standards, vocabulary, terminology, and expectations about the amount of data and supporting material to be transferred.
Interoperability of terms, ontologies, and expectations was another concern flagged throughout the dinner; merely having data available to researchers does not guarantee that they can use it. There was disagreement about what kind of role the National Institutes of Standards and Technology (NIST), the Federal Trade Commission (FTC), and the National Science Foundation (NSF), or researchers’ professional institutions should play or if all of them should play a role in enforcing these standards.
Having access to the code used to process data represents another barrier to research. It isn’t easy to replicate experiments and make discoveries without interoperability and code sharing. There was agreement that an unethical side of data use could complicate any efforts to create positive benefits. Those challenges include zombie data, predatory publication outlets, rogue analysts, and restricting access to research that may have national security implications.
Some Topics Came Up Repeatedly
Persistent topics of discussion throughout the dinners that should be addressed through future legislative or regulatory efforts included: ensuring data quality, data storage requirements (i.e., whether data resides with the firm or with a third party), the incentive structure for academics to share their data with other scholars and with companies, and the emerging role for synthetic data as a method for sharing valuable data representation without transferring the customers’ actual specific and sensitive data.
The series also tackled challenging privacy questions in general, such as: are there special considerations for sharing the data of children or teens (or other vulnerable or protected classes)? Is there a role for funders and publishers to more strongly require documentation for verifying accountability around the use of shared data? Is there a need for involvement by the Office of Research Integrity (ORI) and research misconduct investigators in the supervision of research data sharing?
Next steps toward Responsible Research Data Sharing
In the coming weeks and months, FPF will work with participants in the dinner series to consolidate the knowledge shared during the salon series into a “Playbook for Responsible Data Sharing for Research.” Developed for corporate data protection officers and their counterparts in research institutions, this playbook will cover:
the contracting, capacity-stabilization, and accountability-assurances that should govern research projects using shared data;
managing review of ethics and research project design while respecting research independence review the design of research projects using shared data;
the challenges that researchers must surmount to access and use shared data resources;
the need for effective communication of the findings from such research projects.
We look forward to sharing the “Playbook for Responsible Data Sharing for Research” with the FPF community and our many new friends and partners from the research community in the early months of 2022. Follow FPF on LinkedIn and Twitter, and subscribe to email to receive notification of its release.
FPF in 2021: Delivering Privacy Insights & Expert Analysis
With the last days of 2021 upon us, we wanted to take a moment to reflect on this exciting year that saw FPF expand its presence both domestically and around the globe, while producing engaging events, thought-provoking analysis, and insightful reports with real-world impact.
Growing Global Expertise
The scope of FPF’s international work continued to expand this year, as policymakers around the world are focused on ways to establish or improve privacy frameworks. More than 120 countries have now enacted a privacy or data protection law, and FPF both closely followed and advised upon significant developments in Asia, the European Union, and Latin America.
FPF saw its presence in Asia grow substantially this year with the opening of the FPF Asia-Pacific office, headed by Dr. Clarisse Girot. The FPF Asia-Pacific office will provide expertise in digital data flows and discuss emerging data protection issues in a way that is useful for regulators, policymakers, and data protection professionals. Along with the opening of the office, FPF also announced a partnership with the Asian Business Law Institute (ABLI) to support the convergence of data protection regulations and best privacy practices in the Asia-Pacific region. The Asia-Pacific office held several events in the months following its opening, including a virtual event during Singapore’s Personal Data Protection Week and an event co-hosted with the Asian Development Bank titled Trade-Offs or Synergies? Data Privacy and Protection as an Engine of Data-Driven Innovation.
Following the Indian government’s passage of regulations that placed strict rules for the removal of illegal content and automated scanning of online content, FPF published a review of the new rules and included relevant resources with more information. This year also saw FPF announce Malavika Raghavan as the new Senior Fellow for India. This appointment further expanded FPF’s reach in Asia to one of the key jurisdictions for the future of data protection and privacy law.
International data flows have been an important topic of discussion over the past year. Following the Schrems II decision in 2020, which had serious implications for data flows coming from the EU into the US, the FPF global team created a series of informative infographics that explains the complexity of international data flows in two distinct contexts: retail and education services.
Scholarship & Analysis on Impactful Topics
The core of FPF’s work remains focused on providing insightful, independent analysis on pressing privacy issues. 2021 saw FPF provide this important leadership through events, awards, projects, papers, and more, providing insights into issues such as academic data sharing, digital contact tracing technologies, and neurotechnologies.
For the second year, FPF recognized privacy-protective research collaboration between a company and researchers with the Award for Research Data Stewardship. The first winning project this year is a collaboration between Stanford Medicine researchers led by Tejaswini Mishra, Ph.D., Professor Michael Snyder, Ph.D., and medical wearable and digital biomarker company Empatica. The other team recognized is a collaboration between Google’s COVID-19 Mobility Reports and COVID-19 Aggregated Mobility Research Dataset projects, and researchers from multiple universities in the United States and around the globe. These projects demonstrated how privately-held data can be responsibly shared with academic researchers, supporting significant progress in medicine, public health, education, social science, and other fields.
FPF created a new Open Banking Working Group to discuss issues surrounding open banking. FPF has released several blog posts and hosted events on the topic, with more to come in the new year.
FPF offered resources and best practices for a variety of topics this year. In August, with support from the Robert Wood Johnson Foundation, we developed actionable guiding principles to bolster the responsible implementation of digital contact tracing technologies. The principles we laid out allow organizations implementing this technology to do so in a way that takes a responsible approach to how their technology collects, tracks, and shares personal information.
It is important to take steps to ensure equity in access to DCTT and understand the societal risks and tradeoffs that may accompany its implementation. Privacy leaders who understand these risks will be better able to bolster trust in this technology within their organizations.
To better assist organizations’ shared mobility data access and reduce privacy risks in their data-sharing process, FPF and SAE’s Mobility Data Collaborative (MDC) created a transportation-tailored privacy assessment that provides practical guidance for data from ride-hailing services, e-scooters, or bike-sharing programs.
“Micromobility services can play a key role in improving access to jobs, food and health care. However, there are multiple factors for companies and government agencies to consider before sharing mobility data with other organizations, including the precision, immediacy, and type of data shared.”
FPF and the Privacy Tech Alliance released a report titled, “Privacy Tech’s Third Generation: A Review of the Emerging Privacy Tech Sector,” which analyzed the evolving privacy technology market, examined trends and predictions in the field, and identified five market trends and their implications for the future. The report focused on the COVID-19 pandemic’s role in accelerating the global marketplace adoption of privacy tech.
FPF held a series of workshops focused on manipulative design with technical, academic, and legal experts to define clear areas of focus for consumer privacy, and guidance for policymakers and legislators. These workshops looked at manipulative design through a variety of different contexts including youth and education, online advertising and U.S. law, and GDPR and European law. The issue of manipulative design, transparency, and trust was also discussed during the first annual Dublin Privacy Symposium, which was hosted by FPF.
In collaboration with the IBM Policy Lab, FPF released a set of recommendations to promote privacy and mitigate risks associated with brain-computer interfaces. The report provides developers and policymakers with actionable ways this technology can be implemented while protecting the privacy and rights of its users. Following the release of the report, FPF and the IBM Policy Lab hosted an online event discussing the report and the brain-computer interface field more broadly.
FPF recognizes the need for access to personal information for independent research and for platform accountability and supports this research when it is done responsibly. In November and December, FPF hosted a series of salon dinners titled, “Promoting Responsible Research Data Access,” which brought together the many voices needed for a robust conversation on how we can unlock data for scientific research and will lead to a playbook for privacy-protective research access to corporate data.
Expanding the Conversation Around Responsible Data Use
FPF continues to convene industry experts, academics, consumer advocates, and other experts to explore the challenging issues in the data privacy field. Members of our team have also testified in front of state and national legislative bodies as experts for potential privacy legislation.
For the 11th year in a row, FPF recognized leading privacy research and analytical work with the Privacy Papers for Policymakers Award held virtually for the first time. The winners spoke on their research in front of an audience of academic, industry, and policy professionals in the privacy field. The event was headlined by a keynote address by FTC Chairwoman Rebecca Kelly Slaughter, her first major speech as then acting chair of the FTC. In her remarks, she focused on making enforcement more efficient and effective, how to protect privacy during the pandemic, and the overlap of COVID-19 and issues related to privacy.
FPF launched a new training program in 2021 focused on the use of data-driven technologies. The Understanding Digital Data Flows training program provided a deep dive into how technology and personal data are utilized in a variety of sectors. The training sessions were led by FPF experts and discussed topics including artificial intelligence, de-identification, and more. These informative trainings will continue into 2022 and the first eight sessions are already open for registration.
In the same vein, FPF released a series of insights for lawyers to understand before advising clients on issues of artificial intelligence. Among the insights were an explanation of AI’s probabilistic, complex, and dynamic nature, the importance of transparency in AI use, and the issue that algorithmic bias presents to AI users.
Laws like ECOA, GDPR, CPRA, the proposed EU AI regulation, and others are forming a legal foundation for regulating AI… As more organizations begin to entrust AI with high-stakes decisions, there is a reckoning on the horizon.
To add to the conversation surrounding COPPA and verifiable parental consent, FPF released a report outlining suggested solutions collected through research and insights from stakeholders. In the report, key friction points in the verifiable consent process are identified, which include: efficiency, accessibility, privacy and security, and convenience and cost barriers. Throughout the year, FPF collected comments from industry professionals, advocates, and academics to help identify possible solutions to untangle the challenges associated with verifiable parental consent, which will inform our work in 2022.
Following the release of a report which provided recommendations on the use of augmented and virtual reality technologies, FPF hosted XR Week, a week dedicated to ethical and privacy concerns of AR and VR technologies. The week included several events including a roundtable with expert participants and several conversations held in a virtual reality space.
During debate over Maryland HB 1062, which proposed several updates to Maryland’s Student Data Privacy Act, FPF’s Amelia Vance testified in front of the Maryland House Ways and Means Committee on the bill. In her testimony, Amelia voiced her approval of many of the proposed updates and offered recommendations on two amendments, clarifying how the bill defines “operator,” and the scope of the Council’s recommendations.
The FPF Youth & Education team released a series of resources focused on school surveillance and student monitoring. In October, the team released an infographic, “Understanding Student Monitoring,” that depicts reasons schools monitor student activity, what types of data are being monitored, and how that data can be utilized. Following reports that the Pasco County (FL) Sheriff’s Office was keeping a list of students who may be “potential criminals,” FPF released a report advocating for transparency and accountability for parents and students, FERPA compliance, and more robust privacy training for law enforcement and SROs.
Earlier this month, Stacey Gray testified in front of the U.S. Senate Finance Subcommittee on Fiscal Responsibility and Economic Growth on consumer privacy in the technology sector. Her testimony focused on the term “data brokers” and explained how third-party data processing is central to many concerns around privacy, fairness, accountability, and crafting effective privacy regulation.
The FPF team welcomed many new faces during 2021 and saw the promotion of key staff members to senior positions. John Verdi became Senior Vice President of Policy, Amelia Vance was elevated to Vice President of the Youth & Education program, Gabriela Zanfir-Fortuna was promoted to Vice President for Global Privacy, and Stacey Gray was promoted to Director of Legislative Research & Analysis. This year, the leadership team also saw the addition of Amie Stepanovich as Vice President of U.S. Policy and Rebekah Stroman as Chief of Staff. 2021 also saw us welcome Clarisse Girot, Lee Matheson, Keir Lamont, Tatiana Rice, Nancy Levesque, Payal Shah, Joanna Grama, and Jim Siegl to the FPF staff.
“The FPF team has grown to meet the need for independent privacy expertise, especially in the international, youth & education, and policy spaces,” said Jules Polonetsky, CEO of FPF. “I could not be more proud of the high-quality work that the FPF staff has produced to increase understanding of how technology impacts civil and human rights. We’re looking forward to 2022 and wish everyone a Happy Holidays and a Happy New Year.”
This is by no means a comprehensive list of all of FPF’s important work in 2021, but we hope it gives you a sense of the impact that our work had on both the privacy community and society at large. Keep updated on FPF’s work by subscribing to our monthly briefing and following us on Twitter and LinkedIn.
On behalf of the entire FPF staff we wish you a Happy New Year!
Public Comments Surface Fault Lines in Expectations for New California Privacy Law
In November 2020, California voters adopted the California Privacy Rights Act (“CPRA”) ballot initiative, which was developed to strengthen and expand upon the underlying California Consumer Privacy Act (“CCPA”) that the state legislature adopted in 2018. While the CPRA provides for significant new consumer rights and responsible data processing obligations on covered businesses, many questions regarding the scope and practical operation of these requirements remain unresolved. A recently released set of public comments on a CPRA rulemaking process brings some of these contested issues into sharper focus.
The CPRA delegates both rulemaking and enforcement authority to a brand new, privacy-specific body, the California Privacy Protection Agency (“the Agency”). Following the appointment of a governing board, the Agency took its first public-facing steps towards rulemaking in September, 2021, issuing an invitation for comment on 8 topics focused on new and undecided issues introduced by the CPRA. Last week, the Agency published approximately 70 submissions that it received during the course of its 45-day comment period.
A variety of individuals and organizations filed comments including trade associations and companies representing diverse industry sectors, consumer rights groups, and academics. One noteworthy filing is from Californians for Consumer Privacy, a nonprofit organization helmed by Alastair Mactaggart. Given the group’s role in drafting the California Privacy Rights Act ballot initiative and driving the public advocacy campaign that led to its adoption, these comments are indicative of the intent behind some of the ambiguous and contested provisions of the CPRA.
Across hundreds of pages of comments, stakeholders displayed sharp disagreements on what the CPRA does and should require on multiple consequential issues. These contested topics for CPRA rulemaking include (1) how businesses should conduct and submit privacy and security risk assessments, (2) the ways that automated decisionmaking technologies shall be regulated, (3) whether the CPRA requires the recognition of user enabled opt-out signals, (4) the scope of the Agency’s audit authority, and (5) how the Agency should further define and regulate manipulative design interfaces known as “dark patterns.”
1. Privacy and Security Risk Assessments
The CPRA brings California into greater alignment with other global and domestic privacy frameworks by requiring organizations engaged in data processing that poses a “significant risk” to consumer privacy and security to conduct and submit to the Agency risk assessments on a “regular basis.” However, the CPRA leaves many details to Agency regulations, including the specific activities that trigger the requirement to conduct an assessment, the scope and procedures for completing assessments, and the cadence for submitting assessments to the Agency. Comments revealed a variety of preferences for how and when businesses should be required to conduct and submit assessments.
Filings from industry stakeholders frequently raised concerns that the adoption of overly formalistic procedures and reporting requirements for risk assessments would create unnecessary burdens to both businesses and the Agency. Multiple industry groups suggested that assessments should be submitted to the Agency only upon request (consistent with the Virginia and Colorado privacy laws), or, if mandatory, once every 3 years. Civil society organizations typically sought to impose more expansive assessment requirements on covered businesses, with one coalition arguing that assessments should be conducted in advance of any change in business practices that “might alter the resulting risks to individuals’ privacy,” and be resubmitted to the Agency at 6 month intervals.
Californians for Consumer Privacy encouraged the Agency to adopt a graduated approach, with requirements to conduct risk assessments initially falling on only large processors of personal information. The group further suggested variable timing requirements for submitting those assessments established on the basis of the “intensity” of personal information and sensitive personal information processing.
2. Automated Decisionmaking Technology
The CPRA directs the Agency to develop regulations “governing access and opt-out rights” with respect to the use of automated decisionmaking technology, (“ADT”) including “profiling.” The Agency sought comments on multiple aspects of these rights, including the activities that should constitute regulated ADT, what businesses should do to provide consumers with “meaningful information about the logic” of automated decisionmaking processes, and the scope of consumers’ opt-out rights with regards to ADT. Industry and civil society comments differed in how to define the scope of ADT and whether the CPRA creates a standalone consumer right to opt-out of ADT beyond the CPRA’s rights to opt-out of the sale and sharing of personal information and to limit the use of sensitive personal information.
Numerous commenters, including the Future of Privacy Forum, recommended that the Agency define the scope of regulated ADT to decisions that produce “legal or similarly significant effects” to consumers, noting a similar standard under the GDPR. Legal or similarly significant effects would include, for example, automatic refusal of an online credit application; decisions made by online job recruitment platforms; decisions that affect other financial, credit, employment, health, or education opportunities and likely, in certain contexts, behavioral advertising.
Several industry groups such as the California Grocers Association further sought to ensure that the regulations will govern only “fully” automated processes that produce “final” decisions. Supporting this analysis, many commenters pointed to a universe of clearly low-risk, socially beneficial tools such as calculators, spreadsheets, GPS systems, and spell-checkers that could be swept up by overly broad regulation. Civil society groups including EFF and EPIC largely took a different approach, arguing that given emerging concerns of algorithmic harm and bias, the Agency’s regulations should more broadly define ADT, to include, for example, “systems that provide recommendations, support a decision, or contextualize information.”
Notably, Californians for Consumer Privacy argued that the Agency’s regulations should “specify that consumers have the right to opt-out of this automated decisionmaking” (referencing the online advertising ecosystem), and that the Agency should subsequently expand the right to opt-out of ADT to “other areas of online and business activity.” In stark contrast to this view, several industry groups argued that the Agency cannot create a standalone consumer right to opt-out of ADT as such a right is not provided for in the CPRA itself. Two prominent trade associations, CTIA and TechNet, further asserted that such a delegation of rulemaking authority would be “unconstitutional.”
3. Opt-Out Preference Signals
One of the most high profile debates in the present consumer privacy landscape concerns the adoption of “user-enabled global privacy controls,” a potentially broad array of technical signals first recognized under the CCPA’s regulations. In July 2021, a California Attorney General FAQ page was updated to assert that one such tool, a browser-signal named the Global Privacy Control (“GPC”) “must be honored by covered businesses as a valid consumer request to stop the sale of personal information.” The public comments revealed stark differences in statutory interpretation as to whether or not the CPRA requires that businesses honor this class of controls.
Industry groups including ESA, California Retailers Association, and the California Chamber of Commerce largely adopted the interpretation that the text of the CPRA makes business recognition of opt-out preference signals optional, based on the reading that CPRA sections 1798.135(b)(1),(3) offer multiple paths to complying with the exercise of user rights. One exception came from Mozilla, which recently implemented the GPC in the Firefox browser, and noted that enforceability of preference signals under the CCPA “remains ambiguous” and encouraged the Agency to expressly require that companies comply with the GPC under the CPRA.
On the other hand, civil society organizations tended to argue that the CPRA expressly mandates the recognition of global signals, pointing to section 1798.135(e), which concerns the exercise of consumer rights (including by opt-out signals) carried out by other authorized persons. Consumer Reports argued that recognition of these signals is required by the “plain language” of this provision and also noted that this interpretation would be consistent with the CPRA’s stated purpose of strengthening the CCPA. Californians for Consumer Privacy also took a firm stance, arguing that “there is no reading of the statute that would allow a business to [refuse] to honor a global opt-out signal enabled by a consumer” and criticized “misinformation we have seen from the advertising and technologies industries” on the scope of CPRA opt-out rights.
In the Future of Privacy Forum’s comments, we noted that regardless of whether the recognition of global opt-out signals is mandated or voluntary, the Agency has an important opportunity to set clear standards for the adoption of signals that will comply with the CPRA, GDPR, or the Colorado Privacy Act (which will require recognition of certain preference signals by 2025). In this context, the Agency should work with expert stakeholders to address many unresolved operational issues, such as how signals should be interpreted if they conflict with other consumer choices, and establish procedures for the approval of new signals over time.
4. Agency Audit Authority
The CPRA empowers the Agency to conduct audits of businesses to ensure compliance with the Act. Again, many of the details for the breadth and conduct of such audits are left to rulemaking, and the Agency requested expansive feedback on issues including the scope of its audit authority, the processes that audits should follow, and the criteria the Agency should use in selecting businesses to audit.
Californians for Consumer Privacy stated that the Agency Auditor’s scope should “only be limited by whether a request is reasonably linked to a potential violation of the CPRA.” The group further argued that the Agency should leave the determination of its auditing criteria to its Executive Director and Auditor rather than through rulemaking, so as not to alert businesses to these factors.
In contrast, industry groups suggested multiple approaches to clearly defining audit authority and criteria. Popular recommendations include requirements that the Agency (1) have evidence of a violation of a substantive provision of the CPRA that risks significant harm to consumers prior to initiating an audit, (2) provide 90-days notice to a business prior to an audit, (3) impose guardrails to ensure that audits are separate and independent from the Agency’s investigation and enforcement teams, and (4) create “fair and equal treatment” rules for determining what companies are audited.
5. “Dark Patterns”
Finally, the Agency requested feedback on a number of definitions used by the CPRA including manipulative design interfaces known as “dark patterns.” The CPRA defines “dark patterns” as “a user interface designed or manipulated with the substantial effect of subverting or impairing user autonomy, decision-making, or choice, as further defined by regulation.” The Act contains relatively limited prohibitions on their application, stating that the use of “dark patterns” invalidates user “consent” and further directs Agency rulemaking to ensure that web pages that permit users to opt back-in to the sale or use of their information under the CPRA do not utilize “dark patterns.” Nevertheless, the concept of “dark patterns” has received increasing regulatory attention in recent years and has been flagged by Agency Board Chairperson Urban as a potential subject for discussion at a forthcoming series of “informational hearings.”
Industry groups such as the Internet Association raised concerns with the definition of “dark patterns” under the CPRA, arguing that essentially any interface could be interpreted as impairing user choice and therefore be considered a “dark pattern” under the Act, including the use of privacy-protective default settings. Several of these organizations requested that the definition of “dark patterns” be narrowed to focus on design practices that amount to consumer fraud and encouraged forthcoming regulations to provide clear examples of such conduct.
In contrast, a group of Stanford academics led by Professor Jen King suggested regulation on this subject beyond the context of consent interfaces and specifically requested an expanded definition of “dark patterns” to encompass novel interfaces such as voice activated systems. Similarly, despite raising concerns with the suitability of the term “dark patterns,” Common Sense Media suggested defining manipulative designs “as broadly as possible” to include features that encourage children to share personal information.
Conclusion
The Agency’s request for comments has revealed significant divergences in policy and statutory interpretation between stakeholders for the appropriate scope and application of CPRA requirements. Forthcoming resolution of contested issues through Agency rulemaking will likely carry significant implications for the exercise of consumer rights under the CPRA as well as the practical compliance obligations for covered businesses. Interested parties will hope to learn more about the ultimate scope and operation of the CPRA in early-2022, when the Agency intends to publish its initial set of proposed regulations and statement of reasons.
Future of Privacy Forum Adds Amie Stepanovich, Additional Experts to U.S. & Global Policy Teams
New staff members add expertise and expand US policy engagement for independent data protection non-profit
The Future of Privacy Forum (FPF) has added three new members to its U.S. policy team and a senior fellow to its global team. Amie Stepanovich will join FPF as VP of U.S. Policy, Keir Lamont joins as Senior Counsel, Tatiana Rice joins as Policy Counsel, and Simon McDougall joins as Senior Fellow, Global. FPF’s Stacey Gray assumes a new role as Director of Legislative Research & Analysis.
“FPF welcomes a widely respected voice in privacy law to our team in Amie Stepanovich,” said John Verdi, FPF’s SVP of Policy. “Amie is a leading thinker with deep experience in privacy law and human rights, which makes her an invaluable advisor to policymakers, industry leaders, and academics studying the intersection of tech and data protection.”
Amie will join FPF in January of 2022 as VP of U.S. Policy. Before joining FPF, Amie served as the Executive Director of Silicon Flatirons, a center at the University of Colorado, Boulder focused on convening multi-stakeholder discussions and developing the next generation of technology lawyers and policy experts. Amie also previously served as U.S. Policy Manager and Global Privacy Counsel at Access Now where she worked to protect human rights through law and policy involving technologies and their use. Prior to her time at Access Now, Amie was the Director of the Domestic Surveillance Project at the Electronic Privacy Information Center. Amie has also served on FPF’s Advisory Board.
In a further expansion of FPF’s U.S. team, Keir Lamont and Tatiana Rice have joined the organization to focus on legislative research and analysis in the United States.
“Keir and Tatiana will grow FPF’s ability to serve as an independent voice on complex legislative and policy matters at the state and national levels,” said Stacey Gray, FPF’s newly-named Director of Legislative Research & Analysis. “As the national conversation about data privacy and tech ethics continues, FPF will support policymakers with informational resources on new technologies and regulatory approaches through our public engagement, publications, testimony, events, and other programs.”
Keir joins FPF as Senior Counsel on the legislation team, where he will support policymaker education and independent analysis concerning federal, state, and local consumer privacy laws and regulations. Prior to joining FPF, Keir worked as Policy Counsel for the Computer and Communication Industry Association, where he focused on issues related to privacy, security, and emerging technology. Before joining CCIA, Keir managed the Program on Data and Governance at The Ohio State University Moritz College of Law. He was previously a fellow at ZwillGen and Access Now.
Tatiana joins FPF as Policy Counsel on the legislation team, where she will analyze legal and legislative trends relating to data privacy and emerging technologies on both the federal and state levels. Tatiana comes to FPF from Shook, Hardy & Bacon LLP, where she led biometric compliance efforts and assisted clients with managing data privacy compliance, litigation, and investigation.
Simon McDougall joins FPF as a Senior Fellow, working closely with the FPF Global team. Simon previously was a member of the Executive Team and Management Board of the UK Information Commissioner’s Office. He established the Regulatory Innovation and Technology Directorate, led the ICO’s response to the Covid pandemic, and worked with the CMA, FCA, and Ofcom to establish the Digital Regulation Cooperation Forum. Prior to this appointment, Simon led a global privacy consulting practice at Promontory, an IBM company, leading projects across Europe, the U.S., and Asia. He previously led a similar team for Deloitte in the UK.
FPF brings together privacy experts to explore the challenges posed by technological innovation and develop privacy protections, ethical norms, and workable business practices. FPF believes lawmakers and regulators make better policy decisions when they understand the key technologies, business practices, and legal tools available to regulate privacy and data protection.
FPF’s Stacey Gray Testifies Before Senate Finance Committee Regarding Data Brokers, Urges Congress Pass a Comprehensive Federal Privacy Law
Today, Future of Privacy Forum Senior Counsel Stacey Gray testified before the U.S. Senate Finance Subcommittee on Fiscal Responsibility and Economic Growth regarding consumer privacy in the technology sector.
Stacey’s testimony explains that the term “data brokers” typically encompasses a wide variety of companies and business practices that use personal information for different purposes, some of which directly benefit consumers, and others that primarily benefit the purchasers or users of data. Recent laws and proposed bills define data brokers as entities without a direct relationship with consumers, and this third-party data processing is at the heart of concerns around privacy, fairness, and accountability; the third-party relationship also presents a challenge for crafting effective regulation. While a “first party” company that collects and uses personal data can exercise enormous influence and market power, there is still some degree of public accountability to users who are aware that the company exists and can delete accounts or raise alarms when practices go too far. In contrast, a business lacking a direct relationship with consumers – like a data broker – does not have the same reputational interests, business incentives, or in some cases legal requirements, to limit the collection of consumer data or protect it against misuse.
The lack of a consumer relationship also means that businesses engaged in legitimate data processing often cannot rely on the traditional privacy mechanisms of notice and choice. Meaningful affirmative consent, or “opt-in,” may be impossible or impractical for a business to obtain, while “opting out” after the fact tends to be both inadequate as a safeguard and impractical for consumers to navigate. Consumers can become overwhelmed with choices, and often lack the knowledge to assess future risks, complex technology, or future secondary uses.
What does this all mean? First and foremost, Congress should pass baseline comprehensive privacy legislation that establishes clear rules for both data brokers and first-party companies that process personal information. It should address the gaps in the current U.S. sectoral approach to consumer privacy; and it should incorporate but not rely solely on consumer choice: a privacy law should also codify clear limits on the collection of data; in accountability measures such as transparency; risk assessment and auditing; limitations on the use of sensitive data; and limits on retention.
In the absence of comprehensive legislation, there are a number of steps Congress can take to address risks related to consumer privacy and data brokers, including 1) empowering the Federal Trade Commission to continue using its authority to enforce against unfair and deceptive trade practices through funding; staff; the establishment of a Privacy Bureau; and civil fining authority; 2) limiting the ability of law enforcement agencies to purchase information from data brokers; 3) enacting sectoral legislation for uniquely high-risk technologies, such as facial recognition; or 4) updating existing laws, such as the Fair Credit Reporting Act, to more effectively cover emerging uses of data.
FPF will continue to provide expert testimony to governing bodies and organizations to shape privacy best practices and policies, both in the United States and globally.