FPF Holiday Gift Guide for AI-Enabled, Privacy-Forward AgeTech
On Cyber Monday, giving supportive technology to an older loved one or caregiver is a great option. Finding the perfect holiday gift for an older adult who values their independence can be a challenge. This year, it might be worth exploring the exciting world of AI-enabled AgeTech. It’s not only gadgets; it’s also about giving the gift of autonomy, safety, and a little bit of futuristic fun. Here are three types of AI-enabled AgeTech to consider and information help pick the right privacy fit for the older adult and/or caregiver in your like this holiday season.
Mobility and Movement AgeTech
This category is all about keeping the adventure going, whether it’s a trip across town or safely navigating the living room. These gifts use AI-driven features to support physical activity and reduce the worry of falls or isolation. Think of them as the ultimate support tech for staying active.
For those who need a little help around the house, AI-powered home assistant robots can fetch items on command. For AI-driven transportation, AI is used to find the best route to a place, match riders with the best-suited drivers, and interpret voice commands. In wearables, AI continuously analyzes data like gait and heart rate to learn baseline health patterns, allowing it to detect a potential fall or an abnormal health trend and generate emergency alerts. In future AI-powered home assistant robots, AI might be the brain behind the natural language processing that understands commands and the mapping needed to safely find its way around and pick up tissues, medication bottles, or other small items.
Gift Guide: Mobility and Movement AgeTech
These capabilities rely on personal data to understand where a person is on a map or in their house. These devices collect location or spatial data to help individuals know where they are or let others know where they are. Sometimes these data are collected at the same time as when the person moves for features like “trip share” to help others know where they are. Many mobility AgeTech gifts may also collect body movement data, such as steps, balance, gait patterns, and alerts for inactivity or potential falls.
For any AgeTech gift receiver, be clear that, in some cases, AI may need to continuously analyze personal habit and location data to learn baseline patterns and be useful and even to reduce bias. They must consent to this ongoing collection and processing of data if they or their caregivers want to use certain features. Given sensitive data, how private information might be shared with others or how the company might share the data based on their policies, especially if the AI integrates with other services should be transparent and easy to understand.
State Consumer AI and Data Privacy Laws
Location data is protected under several state privacy laws, including when it is collected by AI. In states that have enacted privacy laws, special consent to collect or process “sensitive” data including location data may be requested by AgeTech devices or apps for certain features or functions. Currently, 20 states in the U.S. have enacted a consumer data privacy law. These laws generally provide consumers with rights to access, delete, and correct their personal data; and provide special protections for sensitive data, such as biometric identifiers, precise geolocation, and certain financial identifiers.
In 2025, state legislatures passed a number of AI-focused bills that covered issues such as chatbots, deepfakes, and more. These existing and proposed regulations may have impacts on AgeTech design and practices, as they determine safeguards and accountability mechanisms that developers must incorporate to ensure AgeTech tools remain compliant and safe for older adults.
Connection and Companionship AgeTech
These gifts leverage AI to offer sympathetic companionship, reduce the complexities of care coordination, and foster connection between individuals and their communities of care. They are specifically engineered to bridge the distance in modern caregiving, providing an essential safeguard against social isolation and loneliness.
Gift givers will find a mix of helpful tools here, like typical AI-driven calendar apps repurposed as digital care hubs for all family members to coordinate; simplified communication devices (tablets with custom, easy interfaces) paired with a friendly AI helper for calls and reminders; and even AI animatronic pets that respond to touch and voice, offering therapeutic benefits without the chores associated with a real pet.
Gift Guide: Connection and Companionship AgeTech
These devices may log personal routines, capturing medication times, appointments, and daily habits. They may also collect voice interactions with AI helpers and may collect data related to mood, emotions, pain, or cognition through check-ins or certain body-related data (including neural data) during check-ins.
Gift-givers should discuss potential gifts with older adults and consider the privacy of others who might be unintentionally surveilled, such as friends, workers, or bystanders. Since caregivers often view shared calendars and activity logs, ensure access controls are distinct, role-based, and align with the older adult’s preferences. The older adult should control data access (e.g., medical routines vs. social events). Be transparent about whether AI companions record conversations or check-in responses, and how that sensitive personal data is stored and analyzed.
Health and Wellness Data Protections
The Health Insurance Portability and Accountability Act (HIPAA), does not protect all health data. HIPAA very generally applies to health care professionals and plans providing payment and insurance for health care services. So an AI companion health device provided as part of treatment by your doctor will be covered by HIPAA, but one sold directly to a consumer is less likely to be protected by HIPAA. However, some states have recently passed laws providing certain rights to consumers for general health information that is not protected by HIPAA.
Daily Life and Task Support AgeTech
This tech category covers life’s essentials through AI-driven automation, focusing on managing finances, medication, and overall health with intelligent, passive monitoring. It’s about creating powerful, often invisible, digital safeguards, ranging from financial safeguard tools to connected health devices integrated into AI-based AI-driven homes, that offer profound peace of mind by anticipating and flagging risks.
This is where gift givers can find presents to help protect older adults and caregivers from increasingly common AI-driven leveraging machine learning to identify and flag suspicious activity targeting older populations. Look for AI financial tools that watch bank accounts for potential fraud or unusual activity, connected home devices that passively check for health changes, and AI-driven pill dispensers that light up and accurately sort medication.
Gift Guide: Daily Life and Task Support AgeTech
The sensitive data collected by these devices can be a major target of scammers and other bad actors. Some tools may collect transaction history and alerts for “unusual” spending to help reduce scam risks. Other AgeTech may log medication “adherence” (timestamps of dispensed doses) or need an older adult’s medical history to work well. In newer systems with advanced identification technologies, it could also include biometric data such as fingerprints or face scans used to ensure safe access to individual accounts.
Gift-givers need to consider how the AI determines something is “unusual” to avoid unnecessary worry from false alarms in banking or health. For devices like AI-driven pill dispensers, also ask what happens to the device’s functionality if the subscription is canceled. For passive monitoring devices, ensure meaningful consent; the older adult must have explicit, ongoing understanding and consent for continuous collection of highly sensitive data that happens while living their daily life from bathroom trips to spending habits.
Financial Data Protections
Those giving gifts of this kind may want to consult with a trusted financial institution or professional before purchasing. If a financial-monitoring tool is instead provided by a non-bank (such as a consumer-facing fintech app), consumer financial protections may not apply, even if the data is still highly sensitive. State privacy laws and FTC authority may offer protections that can vary in scope.
AI-enabled AgeTech Gift Checklist
We suggest evaluating AgeTech products through a practical lens:
What data is collected and how? For example: voice recordings via microphone in an AI-enabled companion bot.
Who will manage access data privacy, and consents for the device or account? The older adult? Caregivers? Both?
What protections apply? HIPAA, state AI or privacy laws.?
How does the AI ensure safety and reliability? For example: fall detection accuracy, avoiding false alarms for “unusual” activity.
Since multiple state and federal laws create a mix of protections, gift givers need to take an extra step to understand the protections and choose the best balance of safety, privacy, and support to go with their AgeTech present. A national privacy law could simplify the inconsistency and gaps, but does not seem to be on the agenda in Congress.
The United States population demographics point to an increasingly aged population, and AI-enabled AgeTech has shown promise in supporting the independence of older adults. Gift-givers have an opportunity to offer tools that support independence and strengthen autonomy, especially as AI continues to be adapted to older adults’ specific needs and preferences. In a recent national poll by the University of Michigan, 96% of older adults who used AI-powered home security devices and systems and 80% who used AI-powered voice assistants in the past year said these devices help them live independently and safely in their home.
Whether the device helps someone move confidently, stay socially engaged, or manage essential tasks, each category relies on sensitive personal data that must be handled thoughtfully. By thinking through how these technologies work, what information they collect, and the rights and safeguards that protect that data, you can ensure your presents are empowering and future-thinking.
Happy Holidays from the Future of Privacy Forum!
GPA 2025: AI development and human oversight of decisions involving AI systems were this year’s focus for Global Privacy regulators
The 47th Global Privacy Assembly (GPA), an annual gathering of the world’s privacy and data protection authorities, took place between September 15 and 19, 2025, hosted by South Korea’s Personal Information Protection Commission in Seoul. Over 140 authorities from more than 90 countries are members of the GPA, and its annual conferences serve as an excellent bellwether for the priorities of the global data protection and privacy regulatory community, providing the gathered authorities an opportunity to share policy updates, priorities, collaborate on global standards, and adopt joint resolutions on the most critical issues in data protection.
This year, the GPA adopted three resolutions after completing its five-day agenda, including two closed-session days for members and observers only:
The first key takeaway from the results of GPA’s Closed Session is a substantial difference in the scope of the resolutions relative to prior years. In contrast to the five resolutions adopted in 2024 or the seven adopted in 2023, which covered a wide variety of data protection topics from surveillance to the use of health data for scientific research, the 2025 resolutions are much more narrowly tailored and primarily focused on AI, with a pinch of digital literacy. Taken together with the meeting’s content and agenda, these resolutions provide insight into the current priorities of the global privacy regulatory community – and perhaps unsurprisingly, reflect a much-narrowed focus on AI issues compared to previous years.
Across all three resolutions adopted in 2025, a few core issues become apparent:
First, regulators are continuing to promote shared conceptual frameworks for data protection regulation, with a particular focus on raising awareness of privacy and data protection issues throughout the world.
Second, regulators are starting to zoom into specific issues related to AI and personal data processing, departing from the general, broad approach shown so far: training and fine-tuning of AI models and meaningful human oversight over individual decisions involving AI were the two concrete topics subject to convergence of regulatory perspectives this year.
Third, a risk-based consensus for evaluating AI seems to be holding, with all three resolutions framing discussions of AI policy in the context of risk, and discussing the specific problem of bias in the context of AI-related data processing.
Fourth, there remains great interest in mutual cooperation through the GPA or other international fora; all three of the 2025 resolutions explicitly promote this goal.
Finally, exploring what topics the Assembly didn’t address is also interesting. A deeper dive into each resolution is illustrative of some of the shared goals of the global privacy regulatory community – particularly in an age where major tech policymakers in the U.S., the European Union, and around the world are overwhelmingly focused on AI. It should be noted that the three resolutions passed quasi-unanimously, with only one abstention among GPA members noted in the public documents (US Federal Trade Commission).
Resolution on the collection, use and disclosure of personal data to pre-train, train and fine-tune AI models
The first resolution, covering the collection, use and disclosure of personal data to pre-train, train, and fine-tune AI models, was sponsored by the Office of the Australian Information Commissioner and co-sponsored by 15 other GPA member authorities. The GPA resolved to four specific steps after articulating a greater number of underlying concerns – specifically, that:
The collection, use and disclosure of personal data for the pre-training, training, and fine tuning of AI models is within the scope of data protection and privacy principles.
The members of the GPA will promote these privacy principles and engage with other policy makers and international bodies (specifically naming the OECD, Council of Europe, and the UN) to raise awareness and educate AI developers and deployers.
The members of the GPA will coordinate enforcement efforts on generative AI technologies in particular to ensure a “consistent standard of data protection and privacy” is applied.
The members of the GPA will commit to sharing developments on education, compliance and enforcement on generative AI technologies to foster the coherence of regulatory proposals.
The specific resolved steps indicate a particular focus on generative AI technologies, and a recognition that in order to be effective, it is likely that regulatory standards will need to be consistent across international boundaries. Three of the four steps also emphasize cooperation among international privacy enforcement authorities; although notably this resolution does not include any specific proposals for adopting shared terminology directly.
The broader document relies on a rights-based understanding of data protection rights and notes several times that the untrammeled collection and use of personal data in the development of AI technologies may imperil the fundamental right to privacy, but casts the development of AI technologies in a rights-consistent manner as “ensur[ing] their trustworthiness and facilitat[ing] their adoption.” The resolution repeatedly emphasizes that all stages of the algorithmic lifecycle are important in the context of processing personal data.
The resolution also provides eight familiar data protection principles that are reminiscent of the OECD’s data protection principles and the Fair Information Practice Principles that preceded them – under this resolution personal data should only be used throughout the AI lifecycle when its use comports with: a lawful and fair basis for processing; purpose specification and use limitation; data minimization; transparency; accuracy; data security; accountability and privacy by design; and the rights of data subjects.
The resolution does characterize some of these principles in ways specific to the training of AI models – critically noting that:
Related to the first principle of lawfulness, “the public availability of [personal] data does not automatically imply a lawful basis for its processing, which must always be assessed in light of the data subject’s reasonable expectation of privacy.”
Regarding the third principle of data minimisation, “consideration should be given to whether the AI model can be trained without the collection or use of personal data.”
Concerning the fifth principle, accuracy, that developers should “undertake appropriate testing to ensure a high degree of accuracy in [a] model’s outputs.”
A component of the sixth principle, data security, is an obligation on entities developing or deploying AI systems to put in place “effective safeguards to prevent and detect attempts to extract or reconstruct personal data from trained AI models.”
This articulation of traditional data protection principles demonstrates how the global data protection community is considering how the existing principles-based data privacy frameworks will specifically apply to AI and other emerging technologies.
Resolution on meaningful human oversight of decisions involving AI systems
The second resolution of 2025 was submitted by the Office of the Privacy Commissioner of Canada and was joined by thirteen co-sponsors, and focused on addressing how the members could synchronize their approaches to “meaningful human oversight” of AI decision-making. After explanatory text, the Assembly resolved four specific points:
GPA Members should promote a common understanding of the notion of meaningful human oversight of decisions, which includes the considerations set out in [the second] resolution.
GPA Members should encourage the designation of overseers with “necessary competence, training, resources, and awareness of contextual information and specific information regarding AI systems as a means of meaningful oversight.”
The Assembly should use the GPA Ethics and Data Protection in Artificial Intelligence Working group to share knowledge and best practices to support practical implementation of “meaningful human oversight” in their respective jurisdictions.
The Assembly should continue to promote the development of technologies or processes that advance explainability for AI systems.
This resolution, topically much more narrowly focused than the first one analyzed above, is based on the contention that AI systems’ decision-making processes may have “significant adverse effects on individuals’ rights and freedoms” if there is no “meaningful human oversight” of system decision-making and thus no effective recourse for an impacted individual to challenge such a decision. This is a notable premise, as only this resolution (of the three) also acknowledges that “some privacy and data protection laws” establish a right not to be subject to automated decision-making along the lines of Article 22 GDPR.
Ahead of the specifically resolved points, the second resolution appears to identify the potential for “timely human review” of automated decisions that “may significantly affect individuals’ fundamental rights and freedoms” as the critical threshold for ensuring that automated decisionmaking and AI technologies do not erode data protection rights. Another critical piece is the distinction the Assembly makes between “human oversight” – which may occur throughout the decision-making process, and “human review” – which may occur exclusively after the fact – the GPA explicitly identifies “human review” as only one activity within a broader concept of “oversight.”
Most critically, the GPA identifies specific considerations in evaluating whether a human oversight system is “meaningful”:
Agency – essentially, whether the overseer has effective control to make decisions and act independently.
Clarity of [overseer] role – preemptively setting forth what the overseer does with AI decisions – whether they are to accept, reject, or modify rejections, and how they are to consider AI system outputs.
Knowledge and expertise – ensuring that overseers have appropriate knowledge and training to evaluate an AI system’s decision, including awareness of specific circumstances where a system’s outputs may require additional scrutiny.
Resources – ensuring overseers have sufficient resources to oversee a decision.
Timing and effectiveness – ensuring oversight is appropriately integrated into decisionmaking processes such that overseers may “agree with, contest, or mitigate the potential impacts of the AI system’s decision.”
Evaluation and Accountability – ensuring overseers are evaluated on the basis of whether oversight was performed, rather than the outcome of the oversight decision.
The resolution also considers tools that organizations possess in order to ensure that “meaningful oversight” is actually occurring, including:
Clarifying the “intention” and value of oversight
Training
Designing the oversight process
Escalation
Documentation
Assessments
Evaluation and testing of the process
Evaluation of outcomes
Overall, the resolution notes that human oversight mechanisms are the responsibility of developers and deployers, and are critical in mitigating the risk to fundamental rights and freedoms posed by potential bias in algorithmic decision making, specifically noting the risks of self-reinforcing bias based on training data or the improper weighting of past decisions as threats meaningful oversight processes can counteract.
Resolution on Digital Education, Privacy and Personal Data Protection for Responsible Inclusive Digital Citizenship
The third and final resolution of 2025 was submitted by the Institute for Transparency, Access to Public Information and Protection of Personal Data of the State of Mexico and Municipalities (Infoem), a new body that has replaced Mexico’s former GPA representative, the the National Institute for Transparency, Access to Information and Personal Data Protection (INAI). This resolution was joined by only seven co-sponsors, and reflected the GPA’s commitment to developing privacy in the digital education space and promoting “inclusive digital citizenship.” Here, the GPA resolved five particular points, each accompanied by a number of recommendations for GPA Members:
GPA Members should promote privacy and technology ethics as cross-cutting issues across the full spectrum of education, from early childhood to university.
States and authorities should ensure education related to digital privacy promotes lawfulness and diversity for all, particularly children and vulnerable communities.
GPA Members should promote the “understanding, exercise, and defense of personal data rights” as well as consideration of ongoing issues around the use of emerging technologies.
GPA Members should work to strengthen regulatory frameworks, align strategies with international human rights and data protection instruments, and actively engage in international cooperation networks alongside other international bodies related to data protection and education.
Promote a “culture of privacy” relying on awareness-raising, continuous training, and capacity building.
The resolution also evidences the 2025 Assembly’s specific concerns relating to generative AI, including a statement “reaffirming that … generative artificial intelligence, pose[s] specific risks to vulnerable groups and must be addressed using an approach based on ethics and privacy by design” and recommending under the resolved points that GPA members “[p]romote the creation and inclusion of educational content that allows for understanding and exercising rights related to personal data — such as access, rectification, erasure, objection, and portability, among others — as well as critical reflection on the responsible use of emerging technologies.”
Among its generalized resolved points, the Assembly critically recommends that GPA Members may:
Promote the creation of a base or certification on data protection for educational institutions that integrate best practices in data protection and digital citizenship, in collaboration with networks such as the GPA or the Ibero-American Data Protection Network (RIPD).
Promote participation in international networks that foster cooperation on data protection in education, with the aim of sharing experiences, methodologies, and common frameworks for action – again referencing the GPA working group on Digital Education and the Ibero-American Data Protection Network specifically.
Finally, the third resolution also includes an optional “Glossary” that offers definitions for some of the terminology that it uses. Although the glossary does not seek to define “artificial intelligence”, “personal data,” or, indeed, “children,” the glossary does offer definitions for both “digital citizenship” – “the ability to participate actively, ethically, and responsibly in digital environments, exercising rights and fulfilling duties, with special attention to the protection of privacy and personal data” and “age assurance” – “a mechanism or procedure for verifying or estimating the age of users in digital environments, in order to protect children from online risks.” Glossaries such as this one are useful in evaluating where areas of conceptual agreement in terminology (and thus, regulatory scope) are emerging among the global regulatory community.
Sandboxes and Simplification: not yet in focus
It is also worth noting a few specific areas that the GPA did not address in this year’s resolutions. As previously noted, the topical range of the resolutions was more targeted than in prior years. Within the narrowed focus on AI, the Assembly did not make any mention of regulatory sandboxes for AI governance, nor challenged or referred to the ongoing push for regulatory simplification, both topics increasingly common to the discussion relative to AI regulation around the globe. Something to follow for next year’s GPA will be how privacy regulators will engage with these trends.
Concluding remarks
The resolutions adopted by the GPA in 2025 indicate increasing focus and specialization of the world’s privacy regulators onto AI issues, at least for the immediate future. In contrast to the multi-subject resolutions of previous years (some of which were AI related, true) this years’ GPA produced resolutions that were essentially only concerned with AI, although still approaching the new technology in the context of its impact on pre-existing data protection rights. Moving into 2026, it would be wise to observe whether the GPA (or other internationally cooperative bodies) pursue mutually consistent conceptual and enforcement frameworks, particularly concerning the definitions of AI systems and associated oversight mechanisms.
Understanding the New Wave of Chatbot Legislation: California SB 243 and Beyond
As more states consider how to govern AI-powered chatbots, California’s SB 243 joins New York’s S-3008C as one of the first few enacted laws governing companion chatbots and stands out as the first to include protections tailored to minors. Signed by Governor Gavin Newsom this month, the law focuses on transparency and youth safety, requiring “companion chatbot” operators to adopt new disclosure and risk-mitigation measures. Notably, because SB 243 creates a private right of action for injured individuals, the law has drawn attention for its potential implications for significant damage claims.
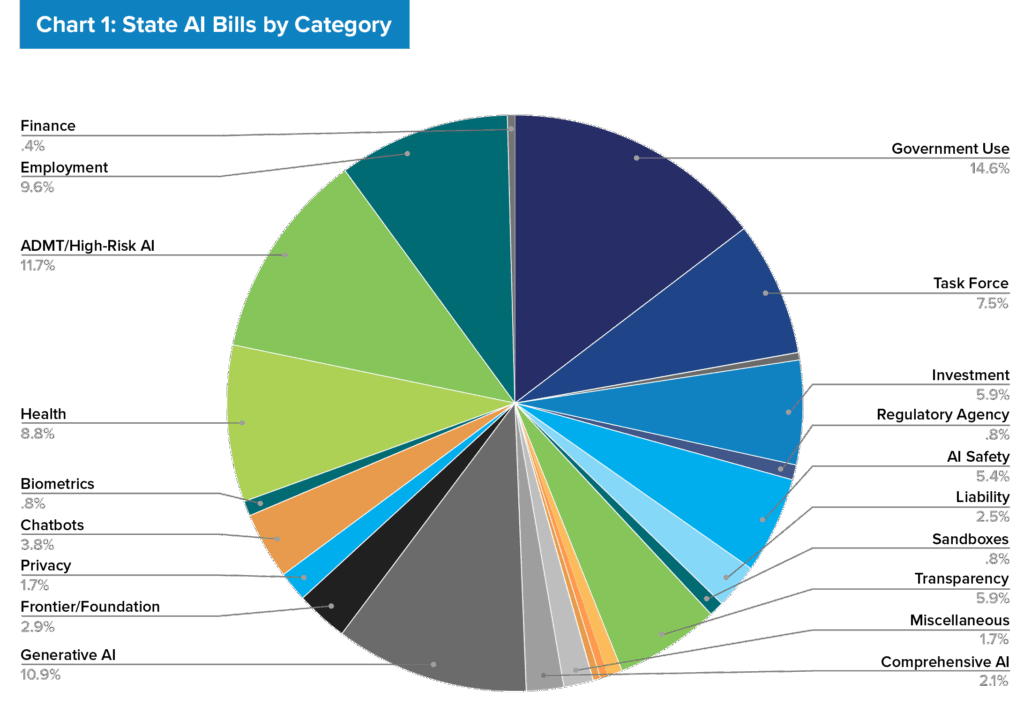
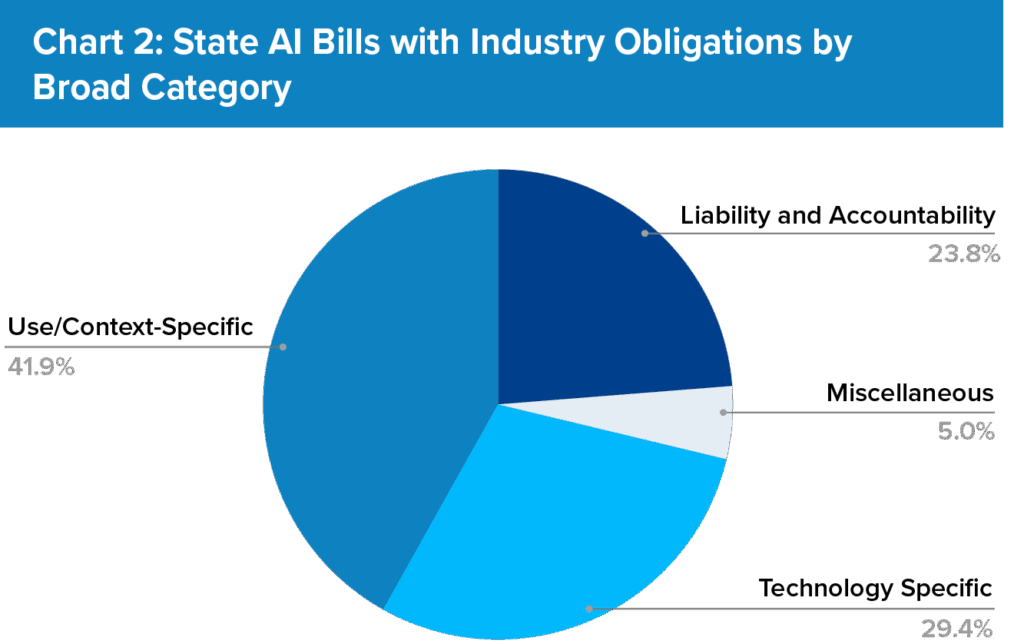
The law’s passage comes amid a broader wave of state activity on chatbot legislation. As detailed in the Future of Privacy Forum’sState of State AI Report, 2025 was the first year multiple states introduced or enacted bills explicitly targeting chatbots, including Utah, New York, California, and Maine1. This growing attention reflects both the growing integration of chatbots into daily life–for instance, tools that personalize learning, travel, or writing–and increasing calls for transparency and user protection2.
While SB 243 is distinct in its focus on youth safeguards, it reflects broader efforts on the state-level to define standards for responsible chatbot deployment. As additional legislatures weigh similar proposals, understanding how these frameworks differ in scope, obligations, and enforcement will be key to interpreting the next phase of chatbot governance in 2026.
A series of high-profile incidents and lawsuits in recent months has drawn sustained attention to AI chatbots, particularly companion chatbots or systems designed to simulate empathetic, human-like conversations and adapt to users’ emotional needs. Unlike informational or customer-service bots, these chatbots often have names and personalities and sustain ongoing exchanges that can resemble real relationships. Some reports claim these chatbots are especially popular among teens.
Early research underscores the complex role that these systems can play in human lives. A Common Sense Media survey asserts that nearly three in four teens (72%) have used an AI companion, with many reporting frequent or emotionally oriented interactions. However, like many technologies, their impact is complex and evolving. A Stanford study found that 3% of young adults using a companion chatbot credited it with temporarily halting suicidal thoughts and other studies have suggested that chatbots can help alleviate the U.S.’s loneliness epidemic. Yet, several cases have also emerged in which chatbots allegedly encouraged children and teens to commit suicide or self-harm, leading to litigation and public outcry.
This growing scrutiny has shaped how Congress and the states are legislating in 2025, with most proposals focusing on transparency, safety protocols, and youth protection. At the same time, these frameworks have prompted familiar policy debates around innovation, data privacy, and liability.
SB 243 Explained
According to the bill’s author, Senator Padilla (D), California’s SB 243 was enacted in response to these growing concerns, requiring companion chatbot operators to maintain certain disclosures, safety protocols, and additional safeguards when the user is known to be a minor.
While California is not the first state to regulate companion chatbots—New York’s S-3008C, enacted earlier this year, includes similar transparency and safety provisions—SB 243 is the first to establish youth-specific protections. Its requirements reflect a more targeted approach, combining user disclosure, crisis-intervention protocols, and minor-focused safeguards within a single framework. As one of the first laws to address youth interaction with companion chatbots, SB 243 may shape how other states craft their own measures, even as policymakers experiment with differing approaches.
A. Scope
California’s SB 243 defines a “companion chatbot,” as an AI system that provides “adaptive, human-like responses to user inputs,” is capable of meeting a “user’s social needs,” exhibits “anthropomorphic features,” and is able to “sustain a relationship across multiple interactions.” Unlike New York’s S-3008C, enacted earlier in 2025, SB 243 does not reference a chatbot’s ability to retain user history or initiate unsolicited prompts, resulting in a slightly broader definition focused on foreseeable use in emotionally oriented contexts.
The law excludes several categories of systems from this definition, including chatbots used solely for customer service, internal research, or operational purposes; bots embedded in video games that cannot discuss mental health, self-harm, or sexually explicit content; and stand-alone consumer devices such as voice-activated assistants. It also defines an “operator”as any person making a companion chatbot platform available to users in California.
Even with these carveouts, however, compliance determinations may hinge on subjective interpretations; for example, whether a chatbot’s repeated customer interactions could still be viewed as “sustained.” As a result, entities may face ongoing uncertainty in determining which products fall within scope, particularly for more general-purpose conversational technologies.
B. Requirements
SB 243 imposes both disclosure, safety protocol, and minor-specific safeguards, as well as a private right of action that allows individuals to seek damages of at least $1,000, along with injunctive relief and attorney’s fees.
Disclosure: The law requires operators to provide a “clear and conspicuous” notice that the chatbot is AI in cases where a reasonable person could be “misled to believe” they are interacting with a human. It also mandates a disclaimer that companion chatbots may not be suitable for minors.
Safety Protocols: SB 243 requires operators to maintain procedures to prevent the generation of content related to suicidal ideation or self-harm, and implement mechanisms to direct users to crisis helplines. These protocols must be publicly available on the operator’s website and annually reported to the California Office of Suicide Prevention, including data on the number crisis referrals but no personal user information.
Safeguards for Minors: When an operator knows a user is a minor, the law also requires operators to disclose to the user that they are interacting with AI, provide a notification every three hours during sustained interactions to take a break, and take reasonable steps to prevent chatbots from suggesting or engaging in sexually explicit content.
However, these requirements raise familiar concerns regarding data privacy, compliance, and youth safety. To identify and respond to risks of suicidal ideation, operators may need to monitor and analyze user interactions, potentially processing and retaining sensitive mental health information which could create tension with existing privacy obligations. Similarly, what it means for an operator to “know” a user is a minor may depend on what information an operator collects about a user and how SB 243 interacts with other recent California laws–such as AB 1043, which establishes an age assurance framework.
Aditionally, this law directs operators to use “evidence-based methods” for detecting suicidal ideation, though it does not specify what qualifies as evidence-based or “suicidal ideation.” This language introduces some practical ambiguity, as developers must determine which conversational indicators trigger reporting and what methodologies satisfy this “evidence-based” requirement.
How SB 243 Fits into the Broader Landscape
SB 243 reflects many of the same themes found across state chatbot legislation introduced in 2025. Two central regulatory approaches emerged this year—identity disclosure through user notification and safety protocols to mitigate harm—both of which are incorporated into California’s framework. Across states, lawmakers have emphasized transparency, particularly in emotionally sensitive contexts, to ensure users understand when they are engaging with an AI system rather than a human.
A. Identity Disclosure and User Notification
Six of the seven key chatbot bills in 2025 included a user disclosure requirement, mandating that operators clearly notify users when they are interacting with AI rather than a human. While all require disclosures to be “clear and conspicuous,” states vary in how prescriptive they are about timing and format.
New York’sS-3008C (enacted) and S 5668 (proposed) require disclosure at the start of each chatbot interaction and at least once every three hours during ongoing conversations. California’sSB 243 includes a similar three-hour notification rule, but only when the operator knows the user is a minor. In contrast, Maine’s LD 1727 (enacted) simply requires disclosure “in a clear and conspicuous manner” without specifying frequency, while Utah’sSB 452 (enacted) ties disclosure to user engagement, requiring it before chatbot features are accessed or when a user asks whether AI is being used.
Lawmakers are increasingly treating disclosure as a baseline governance mechanism for AI, as noted in FPF’s State of State AI Report. From a compliance perspective, disclosure standards provide tangible obligations for developers to operationalize. From a consumer protection standpoint, legislators view them as tools to promote transparency, prevent deception, and curb excessive engagement by reminding users, especially minors, that they are interacting with an AI system.
B. Safety Protocols and Risk Mitigation
Alongside disclosure requirements, several 2025 chatbot bills, including California’s SB 243, introduce safety protocol obligations aimed at reducing risks of self-harm or related harms. Similar to SB 243, New York’s S-3008C (enacted) makes it unlawful to offer AI companions without taking “reasonable efforts” to detect and address self-harm, while New York’s S 5668 (proposed) would have expanded the scope to include physical or financial harm to others.
These provisions are intended to operate as accountability mechanisms, requiring operators to proactively identify and mitigate risks associated with companion chatbots. However, as discussed above, requiring chatbot operators to make interventions in response to perceived mental health crises or other potential harms increases the likelihood that operators will need to retain chat logs and make potentially sensitive inferences about users. Retention and processing of user data in this way may be inconsistent with users’ expressed privacy preferences and potentially conflict with operators’ obligations under privacy laws.
Notably, safety protocol requirements appeared only in companion chatbot legislation, not in broader chatbot bills such as Maine’s LD 1727 (enacted), reflecting lawmakers’ heightened concern about self-harm and mental health risks linked to ongoing litigation and public scrutiny of companion chatbots.
C. Other Trends and Influences
California’s SB 243 also reflects other trends within 2025 chatbot legislation. For example, chatbot legislation generally did not include requirements to undertake impact assessments or audits. An earlier draft of SB 243 included a third-party audit requirement for companion chatbot operators, but the provision was removed before enactment, suggesting that state lawmakers continue to favor disclosure and protocols over more prescriptive oversight mechanisms.
Governor Newsom’s signature on SB 243 also coincided with his veto of California’s AB 1064, a more restrictive companion chatbot bill for minors. AB 1064 would have prohibited making companion chatbots available to minors unless they were “not foreseeably capable” of encouraging self-harm or other high-risk behaviors. In his veto message, Newsom cautioned that the measure’s prohibitions were overly broad and could “unintentionally lead to a total ban” on such products, while signaling interest in building on SB 243’s transparency-based framework for future legislation.
As of the close of 2025 legislative sessions, no state had enacted a ban on chatbot availability for minors or adults. SB 243’s emphasis on transparency and safety protocols, rather than outright restrictions, may preview future legislative debates.
Looking Ahead: What to Expect in 2026
The surge of chatbot legislation in 2025 offers a strong signal of where lawmakers may turn next. Companion chatbots are likely to remain central, particularly around youth safety and mental health, with future proposals potentially building on California’s SB 243 by adding youth-specific provisions or linking chatbot oversight to age assurance and data protection frameworks. A key question for 2026 is whether states will continue to favor these disclosure-based frameworks or begin shifting toward use restrictions. While Governor Newsom’s veto of AB 1064 suggested lawmakers may prioritize transparency and safety standards over outright bans, the newly introduced federal “Guidelines for User Age-Verification and Responsible Dialogue (GUARD) Act,” which includes both disclosure requirements and a ban on AI companions for minors, may reopen that debate.
The scope of regulation could also expand as states begin to explore sector-specific chatbots, particularly in mental health, where new legislation in New York and Massachusetts would prohibit AI chatbots for therapeutic use. Other areas such as education and employment, already the focus of broader AI legislation, may also draw attention as lawmakers consider how conversational AI shapes consumer and workplace experiences. Taken together, these developments suggest that 2026 may be the “year of the chatbots,” with states prepared to test new approaches to transparency, safety, and youth protection while continuing to define responsible chatbot governance.
Other bills enacted in 2025 include provisions that would cover chatbots within their broader scope of AI technologies; however, these figures reflect legislation that focused narrowly on chatbots. ↩︎
The following is a guest post to the FPF blog authored by Cédric Burton, Partner and Global Co-Chair Data, Privacy and Cybersecurity, Wilson Sonsini Brussels. The guest post reflects the opinion of the author only and does not necessarily reflect the position or views of FPF and our stakeholder communities. FPF provides this platform to foster diverse perspectives and informed discussion.
On 4 September 2025, the Court of Justice of the European Union (CJEU) delivered its judgment inEDPS v SRB (C-413/23), which is a ground-breaking judgment regarding the interpretation of the concept of “personal data” under EU data protection law. This concept is central to the EU data protection legal framework and holds considerable importance for its implementation in practice. The SRB judgment is remarkable as it clearly departs from the long-standing position of data protection authorities, which have treated pseudonymized data as invariably personal data.
The dispute arose from the resolution of Banco Popular, in which the Single Resolution Board (SRB) transferred pseudonymized comments submitted by shareholders and creditors to Deloitte, acting as an independent valuer.
In its decision, the Court provided three critical clarifications:
Opinions or personal views are “personal data” since they are inherently linked to their author (para. 60).
The concept of “personal data” is relative. Pseudonymized data are not always personal; their classification depends on the perspective of the actor processing them (paras. 76–77, 86).
The controller’s duty to provide notice applies ex ante at the time of collection, before the data have undergone pseudonymization, and must be assessed from the controller’s standpoint, regardless of whether the recipient can re-identify it (paras. 102, 112).
This post reviews the background of the case and the Court’s holdings, considers their broader implications and practical challenges for international data transfers, controller-processor contracts, transparency obligations and PETs, among others, before concluding with some brief reflections.
1. Background of the case
The dispute originated in June 2017, following the resolution of Banco Popular Español under the Single Resolution Mechanism Regulation, which led to the creation of the Single Resolution Board (SRB). The SRB launched a process to assess whether former shareholders and creditors were entitled to compensation. Deloitte was appointed as an independent auditor to evaluate whether they would have received a better valuation under regular insolvency proceedings.
In August 2018, the SRB published its preliminary decision, opening a two-phase “right to be heard” process. Shareholders and creditors first had to register with proof of identity and ownership of Banco Popular instruments. Those deemed eligible could then submit comments through an online form. More than 23,000 comments were received, each assigned an alphanumeric code. In June 2019, the SRB transferred 1,104 comments relevant to the valuation to Deloitte via a secure server. Deloitte never received the underlying identification data or the key linking codes to individuals.
Several participants complained to the European Data Protection Supervisor (EDPS) that they had not been informed of this disclosure to Deloitte. In a revised decision of 24 November 2020, the EDPS found that Deloitte had received pseudonymized personal data and that the SRB had failed to notify the participants that their personal data will be shared with Deloitte as a recipient, in breach of Article 15(1)(d) of Regulation 2018/1725 (the data protection regulation of the EU institutions, or the ‘EUDPR’). The SRB brought an action before the General Court, which annulled that EDPS decision in its judgment of 26 April 2023 (SRB v EDPS, T-557/20). The EDPS appealed the General Court’s decision.
On appeal, the CJEU was asked to rule on three fundamental questions: (1) Whether opinions or personal views qualify as “personal data”; (2) Whether pseudonymized data must always be treated as personal data, or whether this depends on the perspective of the recipient; and (3) How to define the scope of the controller’s duty to inform under Article 15(1)(d) of the EUDPR. Although the case arose under the EUDPR rather than the General Data Protection Regulation (GDPR), the Court stressed that the two regimes are aligned. Concepts such as “personal data,”1 “pseudonymization,” and the duty to inform must be interpreted homogeneously across both frameworks (C-413/23 P, para. 52).
2. The Court’s holdings
In its judgment, the CJEU set aside the General Court’s ruling in SRB v EDPS (T-557/20), which had annulled the revised decision of the EDPS of 24 November 2020 and held the following conclusions:
2.1. Opinions are inherently personal data
The CJEU held that personal opinions or views, as the “expression of a person’s thinking”, are necessarily “linked” to their authors and therefore qualify as personal data (paras. 58–60). The General Court erred in law in requiring the EDPS to examine the content, purpose, or effect of the comments to establish whether they “related” to the authors.
This reasoning builds on earlier case law: in Nowak (C-434/16), the Court found that examiners’ annotations were personal data both for the candidate and for the examiner, as they expressed personal opinions; in IAB Europe (C-604/22), it reaffirmed the breadth of the concept of “personal data”, holding that information enabling the singling out of individuals (such as the TC String) could fall within its scope; and, in OC v Commission (C-479/22 P), it stressed that the definition must be interpreted broadly, covering both objective and subjective information.
This decision marks a notable shift in emphasis. In IAB Europe (C-604/22), the Court reaffirmed the very broad scope of “personal data” and the general test that data relate to a person by its content, purpose, or effect. In EDPS v SRB (C-413/23), the Court did not depart from that test, but added an important clarification: when information consists of personal opinions or views, its very nature makes it inherently linked to their authors, and thus personal data, without any need for analysis of content, purpose, or effect.
2.2. Whether pseudonymized data is personal data is contextual
The Court drew a clear distinction between pseudonymization and anonymization. Under Article 3(6) of EUDPR, pseudonymization is a safeguard that reduces the risk of identification, but it does not automatically render data anonymous (paras. 71–72). Importantly, when analyzing the context of the matter, the CJEU concludes:
● From the SRB’s perspective, as a controller holding the re-identification key, pseudonymized comments necessarily remained personal data (para. 76).
● For Deloitte (the recipient of the pseudonymized data), which lacked the key and had no reasonable means of re-identifying the authors, those same pseudonymized comments might not have constituted personal data (para. 77).
Accordingly, the Court concluded that pseudonymized data “must not be regarded as constituting, in all cases and for every person, personal data,” since their classification depends on the circumstances of the processing and the position of the actor involved (para. 86).
2.3. Transparency obligations apply ex ante from the initial controller’s perspective
The Court held that Article 15(1)(d) EUDPR requires controllers to inform data subjects about who the recipients of their data are “at the time when personal data are obtained” (para. 102). The assessment must be made from the controller’s perspective, and not that of any subsequent recipient. Accordingly, the SRB was required to disclose Deloitte as a recipient at the time of collection, irrespective of whether the data remained personal data for Deloitte after pseudonymization (para. 112). The Court’s reasoning relies on the fact that the processing was based on consent: for consent to be valid, participants had to be clearly informed of the potential disclosure of their data to third parties (paras. 106–108). On this basis, the Court maintained as valid the initial EDPS decision.
3. Broad implications and practical challenges
The Court’s holdings are a welcome development, as they introduce greater flexibility in the concept of personal data. However, they also generate significant practical challenges for data controllers and raise broader implications for EU data protection law.
3.1. Are opinions always personal data?
According to the CJEU, yes. In practice, this means that any opinions or views expressed should be treated as personal data by companies by default, even if they are later anonymized, aggregated, or pseudonymized for onward sharing.
3.2. The challenges of a case-by-case classification
This ruling is welcome as it introduces a relative approach to the concept of personal data and moves away from the dogmatic approach followed by EU data protection authorities; however, it also raises several important questions. Whether pseudonymized data is personal data depends on whether the recipient has realistic means of re-identification (paras. 71–77). In practice, this means that pseudonymized data may or may not be considered personal data, and such an assessment must be made on a case-by-case basis. On the one hand, this may alleviate the burden on data recipients who lack the means to reasonably identify the individuals: if they do not process personal data, the GDPR does not apply.
On the other hand, pseudonymization is not a free pass. A dataset may still qualify as personal data: (1) if the recipient has reasonable means to re-identify the individual; (2) for the controller who holds the means of re-identification, even if recipients do not; (3) if it is further disclosed to a third party who can re-identify them. This will create practical challenges for data controllers to assess identifiability at each stage of the data flow and not assume that pseudonymization automatically takes them outside the scope of EU data protection law.
Importantly, the Court’s emphasis on the relative nature of pseudonymized data (identifiable for one actor but not for another) is also applicable to personal data as such. For example, information that clearly identifies an individual for a controller may not identify anyone for a recipient if it lacks the necessary context to identify the individual. The relativity analysis is not dependent on pseudonymization as such — pseudonymization was just the vehicle in this case.
The Court’s recognition that personal data may be viewed differently by controllers and recipients creates a practical tension that is likely to arise in contract negotiations. One party may insist that a dataset is personal data and subject to GDPR, while the other considers it anonymous in their hands. This divergence is likely to occur in outsourcing arrangements, as well as in intra-group data agreements. It will complicate contract negotiations, as each party will try to align the contract with its own assessment.
A similar tension may also arise when data subjects seek to exercise their rights. If Controller A discloses pseudonymized data to Recipient B, for whom the dataset is effectively anonymous, what happens if an individual submits an access or erasure request directly to B? In practice, B will be unable to confirm or deny whether it processes that individual’s data. Following the Court’s reasoning, the GDPR would not apply to B, meaning it would have no obligation to respond to this request. Article 11 GDPR adds an additional layer of complexity. It provides that, where the controller cannot identify a data subject, it is not required to process additional information solely to comply with data-subject requests—unless the data subject provides such information to enable identification. However, if the dataset is not personal data for B in the first place, Article 11 GDPR arguably falls outside the analysis. This grey area illustrates the practical difficulty of aligning data-subject rights with the Court’s relative conception of personal data.
3.3. Downstream disclosure and “re-personalization”
For organizations, the practical message is clear: at least when relying on consent, all potential recipients must be disclosed upfront (see also section 3.6. below) — pseudonymization or aggregation cannot be used to sidestep transparency obligations. Yet what looks straightforward on paper quickly becomes complicated in practice. As the Court noted, data that are not personal for one recipient may become personal for another with the means to re-identify (para. 86). How should the initial controller handle this? The Court’s logic suggests that both recipients must be disclosed. But should the controller go further and explain that, for recipient A, the dataset remains personal data, whereas for recipient B it does not?
The difficulty is magnified in real-world scenarios. Unlike SRB, which involved a single consultancy mandate with Deloitte, data is typically shared with multiple recipients for various purposes and often flows through multiple processing chains. In such cases, who bears the transparency burden — the original controller at the point of collection, or downstream recipients under Articles 13 – 14 of the GDPR? Can controllers legitimately rely on Article 14(5) GDPR if they lack the means to contact individuals? To avoid uncertainty and regulatory exposure, data controllers will need to anticipate these scenarios, address them in their data-sharing agreements, and allocate responsibility for transparency as precisely as possible.
3.4. Controllers vs. processors
The Court referred to Deloitte as a “recipient” and assessed identifiability “under its control” (para. 77). It did not expressly qualify Deloitte as a controller, but the reasoning assumed a degree of independence, which implies controllership. Had Deloitte been acting as a processor, would the Court have reached the same conclusion since data processors act on behalf and upon instructions of the controller?
3.5. International transfers
Although not directly at issue, the Court’s reasoning has clear implications for cross-border data transfers. For data exporters, pseudonymized data will most likely remain personal and thus require, absent an adequacy decision, appropriate transfer mechanisms such as standard contractual clauses (SCCs) or binding corporate rules (BCRs). For the recipient, however, the same data may not qualify as personal if the pseudonymization is sufficiently robust. This asymmetry creates friction: why should a recipient accept the obligations of SCCs if it does not consider itself subject to data protection law? Take, for example, an EU company transferring pseudonymized datasets to a U.S. analytics provider. From the exporter’s perspective, the transfer falls within Chapter V GDPR and must be covered by SCCs. Yet the U.S. recipient may not consider itself subject to data protection rules if it cannot re-identify individuals. Why, then, should it agree to the obligations in SCCs? In practice, controllers may need to adapt SCCs or introduce supplementary “riders” to reflect this divergence and clearly allocate responsibilities.
3.6. Does the Legal basis for data processing matter?
The CJEU underlined that consent is valid only if data subjects are informed of the recipients of their data (paras. 106–108). This suggests that the legal basis for processing (consent) was a decisive factor in this decision. However, where processing relies on other legal grounds such as the legitimate interests of the data controller, a failure to disclose recipients could still infringe transparency obligations, since data subjects can only meaningfully exercise their right to object if they know who will receive their data.
3.7. Incentives for pseudonymization and PETs
The judgment highlights the compliance advantages of effective pseudonymization and the use of privacy-enhancing technologies (PETs). Where recipients cannot reasonably re-identify individuals, they may not be subject to the same obligations. This creates a clear incentive for organizations to invest in robust PETs — not only as a risk-mitigation tool, but also as a potential business differentiator in data-intensive markets.
4. Conclusion
The Court’s judgment in EDPS v SRB holds that personal opinions are personal data, clarifies that pseudonymized data are not always personal but must be assessed on a case-by-case basis, and provides that transparency obligations apply ex ante from the controller’s perspective. It underscores that the concept of personal data is relative rather than absolute, and will require regulators to move away from a dogmatic approach to data protection law.
For data controllers, the ruling introduces greater flexibility. However, it also entails longer and more challenging contract negotiations, closer scrutiny of role qualifications, stricter transparency obligations, and a strategic incentive to invest in PETs. Pseudonymization is no longer merely a technical safeguard: it has become a legal hinge that determines whether data falls inside or outside the scope of EU data protection law. The timing is notable. The European Data Protection Board has issued the consultation version of its Guidelines 01/2025 on pseudonymization, yet the Court’s reasoning directly contradicts parts of that guidance (see p. 4, stating that pseudonymised data are personal data). At the Global Privacy Assembly in Seoul in September 2025, the EDPB announced that updated guidance on pseudonymization and the long-awaited guidance on anonymization are forthcoming. This judgment should shape both.
Article 4(1) GDPR defines ‘personal data’ as meaning “any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.” ↩︎
The Draghi Dilemma: The Right and the Wrong Way to Undertake GDPR Reform
The following is a guest post to the FPF blog authored by Christopher Kuner, Visiting Fellow at the European Centre on Privacy and Cybersecurity at Maastricht University and FPF Senior Fellow. The guest post reflects the opinion of the author only and does not necessarily reflect the position or views of FPF and our stakeholder communities. FPF provides this platform to foster diverse perspectives and informed discussion.
There has been much interest in the report on European competitiveness issued in September 2024 by former Italian Prime Minister and European Central Bank President Mario Draghi at the request of European Commission President Ursula von der Leyen, which calls for reform of the EU General Data Protection Regulation (“GDPR”). Draghi’s views have led to discussion about whether fundamental changes to the GDPR are needed, particularly to improve the EU’s position as a global leader in artificial intelligence (AI). In order to protect fundamental rights, maintain legal certainty, and continue to ensure a high level of protection, any reform should be evidence-based, targeted, transparent, and further the EU’s values.
Draghi’s criticisms
In his report, Draghi makes valid criticisms of the inconsistent and fragmented implementation of the GDPR in the Member States (see p. 69). However, his more recent remarks have been more pointed. In a speech at a high-level Commission conference on 16 September 2025, Draghi not only denounced “heavy gold-plating” by Member States in GDPR implementation, but also called for a “radical simplification” of “the primary law” of the GDPR (p. 4). Under Article 97 GDPR, the Commission must prepare an evaluation of it every four years. Its last evaluation, issued in 2024, identified several challenges to the effective operation of the GDPR, but did not call for large-scale reform.
Under pressure following Draghi’s report, the Commission proposed without any consultation a “GDPR Omnibus” on 21 May 2025 containing targeted amendments that eliminate record-keeping requirements for some categories of smaller data controllers. The Commission’s proposal was accompanied by sensationalist claims in the press (such as that the GDPR is on an EU “hit list” and will be consumed in a “red tape bonfire”) and incoherent political statements (such as claims by the Danish Digital Minister that there are “a lot of good things about the GDPR” but that it regulates “in a stupid way”), which seemed to raise the political temperature and push onto the public agenda the idea of radical change of the GDPR.
Later this year the Commission is set to announce a “Digital Omnibus” with proposals for simplification of its data legislation “to quickly reduce the burden on businesses”. It seems possible that political pressure in the EU as well as criticism from the Trump Administration could lead to further proposals for GDPR reform as well.
The politics of reform
Despite Draghi’s claims (see p. 4 of his speech), so far there has been no widespread public pressure for “radical simplification” of the GDPR. The participants at a Commission Implementation Dialogue on application of the GDPR held on 16 July 2025, which included stakeholders from business, civil society, and academia (including myself), concluded that there should be no major changes to the GDPR, while identifying some targeted reforms that could be considered. Anyone who has been involved in EU data protection law for the past few decades can remember claims similar to Draghi’s going back to the entry into force of the EU Data Protection Directive 95/46/EC in the 1990s that data protection law throttles economic growth, all of which have proved to be hyperbolic.
Thus far, GDPR reform has been dealt with on the technocratic level, and the Commission has demonstrated no desire to open up discussion about it to a wider audience. For example, its call for evidence with regard to the Digital Omnibus proposal expected later this year does not mention the GDPR, suggesting that any further proposals for its reform may be announced without public consultation. The text of the GDPR is finely-balanced, and changes to one provision that on the surface seem minor may create uncertainties or conflicts with other provisions, unless they are carefully considered. Pushing through reforms hastily can lead to unintended consequences that exacerbate existing problems and increase public cynicism of the EU legislative process.
Efficiency vs. values
One would expect that an experienced European leader and outstanding public servant such as Draghi would mention that the GDPR protects fundamental rights set out in the TFEU and the EU Charter of Fundamental Rights. However, he has not done this, while giving the impression that the GDPR is little more than red tape that the EU can change at will. His call for simplification of the “primary law” of the GDPR seems to advocate changes to its fundamental principles, but this could bring any reform into conflict with the TFEU and the Charter and lead to challenges before the Court of Justice.
In his report and speech, Draghi fails to buttress his criticism with any European scholarship on the GDPR, and refers only to a study published by the National Bureau of Economic Research (NBER), a US-based economic research organisation, concluding that the GDPR creates economic inefficiencies (see p. 4, footnote 6 of his speech). This conclusion is not a surprise, since, like other forms of regulation designed to protect fundamental rights and human dignity, economic efficiency is not one of the GDPR’s primary goals. Draghi thus fails to recognise, as Leff argued in his famous review of Posner’s Economic Analysis of Law, that it is useless to evaluate activities using criteria of economic efficiency when they pursue other overriding values that go beyond economics.
The place of data protection in the EU legal order has been better recognised by President of the Court of Justice Koen Lenaerts, who stated concerning EU data protection law in an interview in 2015 (paywall) that “Europe must not be ashamed of its basic principles: The rule of law is not up for sale. It is a matter of upholding the requirements in the European Union, of the rule of law, of fundamental rights”. The enthusiastic reception of Draghi’s pronouncements by EU leaders (see, for example, the lavish praise of von der Leyen) seems to indicate that not all European politicians share this view.
The right way to undertake GDPR reform
No legislation is perfect, and discussion of whether the GDPR could be improved should not be taboo. However, any reform must recognise the status of data protection as a fundamental right in the EU legal order; failing to do so would create legal uncertainty for companies and undermine the trust of individuals and thus be counterproductive. Von der Leyen herself recognised the importance of data protection in furthering the data economy in her speech at the World Economic Forum on 22 January 2020, where she called it “the pillar” of the EU’s data strategy, and stated that “with the General Data Protection Regulation we set the pattern for the world”. If the EU wants the GDPR to continue to be a model that other legal systems strive to emulate, then it must ensure that any reform is based on the following principles.
Decisions about reform of the GDPR should be subject to an evidence-based assessment grounded on criteria such as effectiveness, efficiency, relevancy, and coherency as set out in the Commission’s Better Regulation Guidelines. This should include consultations with stakeholders, thorough review of research on the GDPR (in particular that conducted by European scholars), and public hearings or conferences. It must clearly articulate its goals and proceed where the evidence leads it, and not rely on anecdotes or political pronouncements.
If further reform is found necessary, it should be targeted at a few specific areas, and not open the GDPR to wide-ranging changes. Draghi makes some valid points by criticising the current situation as not meeting the objectives of the GDPR to eliminate barriers to economic activities between the Member States (GDPR Recital 9) and to create legal certainty for economic operators (Recital 17). As he argues, there is too much fragmentation in the implementation of the GDPR in the Member States. However, reform should focus not only on the need to remove burdens on business but also on making the GDPR work better for individuals, which Draghi does not mention at all.
The EU institutions, with input from the European Data Protection Board, should agree on a limited number of clearly-defined priorities to be dealt with in any reform. Any changes that affect the fundamental principles of the GDPR or reduce the level of protection should be off-limits. It should be remembered that the original passage of the GDPR resulted in thousands of amendments in the European Parliament and took several years, so that any radical reform would take so much time that it would fail to attain the goal of rapidly improving EU competitiveness. Thoughtful suggestions for targeted reform of the GDPR have already been made by Padova and Thess (my colleagues, in the interest of full disclosure!) and by Voss and Schrems.
It must be conducted transparently in order to ensure legitimacy. Only an open and transparent evaluation of the GDPR can maintain the trust of citizens, ensure a high level of data protection, and advance European competitiveness. There should not be a repetition of the procedure used to rush through the Commission’s amendments to the GDPR proposed in May 2025.
Finally, reform must further the EU’s values. As Article 2 and 3(1) TEU set out, the EU was founded on values such as “human dignity, freedom, democracy, equality, the rule of law and respect for human rights”, which are also at the heart of the GDPR (see Recital 4). Any reform must respect these values and ensure that the protection the GDPR provides is not reduced. Improvement of competitiveness is an important goal, particularly in light of the many geopolitical challenges the EU faces, but cannot override the values set out in the EU constitutional treaties.
GDPR reform should not be a “Brussels bubble” exercise conducted at a technocratic level. Only an open and transparent process allowing for input by citizens and other relevant stakeholders can ensure a result that is in line with the EU’s values and protects the fundamental rights of individuals, while making a contribution to improving the EU’s competitiveness.
FPF Releases Issue Brief on New CCPA Regulations for Automated Decisionmaking Technology, Risk Assessments, and Cybersecurity Audits
Since the California Consumer Privacy Act (CCPA) was enacted in 2018, business obligations under the law have continued to evolve due to several rounds of rulemaking by both the Attorney General and the California Privacy Protection Agency (CPPA). The latest regulations from the CPPA are some of the most significant yet. Starting January 1, 2026, businesses will be subject to extensive new obligations concerning automated decisionmaking technology (ADMT), risk assessments, and cybersecurity audits. Today, the Future of Privacy Forum released an issue brief covering these extensive new regulations, providing stakeholders a comprehensive overview of these new legal requirements and context on how they fit into the existing state privacy law landscape.
(1) Businesses using ADMT to make significant decisions about consumers must (a) provide pre-use notice to consumers, and comply with consumer requests to opt-out of the use of ADMT and to access information about the business’s ADMT use;
(2) Businesses whose processing of personal information presents significant risk to consumers’ privacy must (a) Conduct a risk assessment before initiating the high-risk activity, (b) regularly submit information about conducted risk assessments to the CPPA, and (c) disclose completed risk assessment reports to the Attorney General or the CPPA upon demand; and (3) Businesses whose processing of personal information presents significant risk to consumers’ security must (a) conduct an annual cybersecurity audit, and (b) a qualified member of the business’s executive management team must submit a written attestation that an audit has been conducted.
Future of Privacy Forum Appoints Four New Members to Its Board of Directors
Julie Brill and Jocelyn Aqua also join FPF as senior fellows
Washington, D.C.— The Future of Privacy Forum (FPF), a global non-profit focused on data protection, AI, and emerging technologies, is pleased to announce the election of Anne Bradley, Peter Lefkowitz, Nuala O’Connor, and Harriet Pearson to its Board of Directors. These accomplished leaders bring decades of experience at the intersection of technology, law, business, and public policy, further strengthening FPF’s mission to advance principled and pragmatic data practices in support of emerging technologies.
“FPF is fortunate to welcome Anne, Peter, Nuala, and Harriett to our board,” said Jules Polonetsky, FPF CEO. “Their collective experience will be invaluable in guiding FPF’s work at a time when data, privacy, and emerging technologies are reshaping every sector of society.” Alan Raul, FPF’s Board President, added, “Our stellar new members will complement the Board’s existing luminaries, and support FPF’s outstanding professionals who provide global thought leadership in our new era of digital governance.”
Anne Bradley, a lawyer, technologist, and business leader, currently serves as Chief Customer Officer at Luminos.ai. Anne built the privacy programs for two major global brands, serving as the first in-house privacy counsel at Hulu and as Chief Privacy Officer for Nike. She also serves as a Senior Fellow at FPF, providing staff and members guidance on a range of issues.
Peter Lefkowitz, a leading attorney and data protection executive, previously served as Chief Privacy Officer at Oracle, GE, and Citrix. A past Chairman of the Board for the IAPP, he has advocated for balanced data protection regulation with legislators in the U.S. and EU and has extensive experience engaging with cybersecurity agencies and privacy regulators.
Nuala O’Connor has spent her pioneering career working at the intersection of emerging technologies, digital rights, and ethics across the public and private sectors. She was the first Chief Privacy Officer of the U.S. Department of Homeland Security; served as President and CEO of the Center for Democracy and Technology; and held senior roles at Walmart, Amazon, GE, and DoubleClick. O’Connor is a senior advisor to EqualAI, serves on the advisory board of Kekst CNC, and is a life member of the Council on Foreign Relations.
Harriet Pearson brings more than 30 years of experience at the intersection of IT, business, and law. Prior to founding her consultancy, Axia Advisory, she served as Executive Deputy Superintendent and head of the Cybersecurity Division at the New York Department of Financial Services. Earlier in her career, she founded and led the global cybersecurity practice at Hogan Lovells and served as IBM’s first Chief Privacy Officer. She helped found the IAPP and Georgetown Cybersecurity Law Institute, and has served on numerous boards and advisory councils.
Composed of leaders from industry, academia, and civil society, the input of FPF’s Board of Directors ensures that FPF’s work is expert-driven and independent.
FPF has also added two Senior Fellows to its roster of experts, Julie Brill and Jocelyn Aqua. Currently leading Brill Strategies, Brill was former Chief Privacy Officer, Corporate Vice President for Privacy, Safety and Regulatory Affairs, and Corporate Vice President for Global Tech and Regulatory Policy at Microsoft. Brill was a Commissioner of the US Federal Trade Commission from 2010-2016. Jocelyn Acqua, is Co-Chair of the Data, Privacy and Cybersecurity Practice at HWG, LLP, and a former partner at PwC. .
To learn more about the Future of Privacy Forum, visit fpf.org.
###
California’s SB 53: The First Frontier AI Law, Explained
California Enacts First Frontier AI Law as New York Weighs Its Own
On September 29, Governor Newsom (D) signed SB 53, the “Transparency in Frontier Artificial Intelligence Act (TFAIA),” authored by Sen. Scott Wiener (D). The law makes California the first state to enact a statute specifically targeting frontier artificial intelligence (AI) safety and transparency. SB 53 requires advanced AI developers to publish governance frameworks and transparency reports, establishes mechanisms for reporting critical safety incidents, extends whistleblower protections, and calls for the development of a public computing cluster.
In his signing statement, Newsom described SB 53 as a blueprint for other states, arguing on behalf of California’s role in shaping “well-balanced AI policies beyond our borders—especially in the absence of a comprehensive federal framework.” Supporters view the bill as a critical first step toward promoting transparency and reducing serious safety risks, while critics argue its requirements could be unduly burdensome on AI developers, potentially inhibiting innovation. These debates come as New York considers its own frontier AI bill–A 6953 or the Responsible AI Safety and Education (RAISE) Act, which could become the second major state law in this space–and as Congress introduces its own frontier model legislation. Understanding SB 53’s requirements, how it evolved from earlier proposals, and how it compares to New York’s RAISE Act is critical for anticipating where U.S. policy on frontier model safety may be headed.
SB 53 regulates developers of the most advanced and resource-intensive AI models by imposing disclosure and transparency obligations, including the adoption of written governance frameworks and reporting of safety incidents. To target this select set of developers, the law specifically scopes the definitions of “frontier model,” “frontier developer,” and “large frontier developer.”
Scope
The law regulates frontier developers, defined as entities that “trained or initiated the training” of high-compute frontier models. It separately defines large frontier developers, or those with annual gross revenues above $500 million, targeting compliance towards the largest AI companies. SB 53 applies to frontier models, defined as foundation models trained with more than 10^26 computational operations, including cumulative compute from both initial training and subsequent fine-tuning or modifications.
Notably, SB 53 is focused on preventing catastrophic risk, defined as a foreseeable and material risk that a frontier model could:
Contribute to the death or serious injury of 50 or more people or cause at least $1 billion in damages;
Provide expert-level assistance in creating or releasing a chemical, biological, radiological, or nuclear weapon;
Engage in criminal conduct or a cyberattack without meaningful human intervention; or
Evade the control of its developer or user.
Other proposed bills, like New York’s RAISE Act, set a narrower liability standard: harm must be a “probable consequence” of the developer’s activities, the developer’s actions must be a “substantial factor,” and the harm could not have been “reasonably prevented.” SB 53 lacks these qualifiers, applying a broader standard for when risk triggers compliance.
Requirements:
SB 53 establishes four major obligations, dividing some responsibilities between all frontier developers and the narrower subset of “large frontier developers.”
Frontier AI Framework: Large frontier developers must publish an annual Frontier AI framework describing how catastrophic risks are identified, mitigated, and governed. Among other items, the framework must include documentation of governance structures, mitigation processes, cybersecurity practices, and a developer’s alignment with national/international standards. The framework must also assess catastrophic risk from internal use of models, raising the scope of compliance obligations. Frontier developers may make redactions to the framework to protect trade secrets, cybersecurity, and national security.
Transparency Report: Before deploying a frontier model, all frontier developers (not only “large” developers) must publish a transparency report. Reports must include model details (intended uses, modalities, restrictions), as well as summaries of catastrophic risk assessments, their results, and the role of any third-party evaluators.
Disclosure of Safety Incidents: Frontier developers are required to report critical safety incidents to the Office of Emergency Services (OES). OES must also establish a mechanism for the public to report critical safety incidents. Covered incidents include unauthorized tampering with a model that causes serious harm, the materialization of a catastrophic risk, loss of control of a frontier model that results in injury or major property damage, or a model deliberately evading developer safeguards. Frontier developers are required to report any critical safety incident within 15 days of discovery, shortened to 24 hours if the incident poses imminent danger of death or serious injury.
Whistleblower Protections: SB 53 prohibits retaliation against employees or contractors who report activity from catastrophic risks. Employers must provide notice of employee rights and maintain anonymous reporting channels.
Enforcement:
SB 53 authorizes the Attorney General to bring civil actions for violations, with penalties of up to $1 million per violation, scaled to the severity of the offense. The law also empowers the California Department of Technology to recommend updates to key statutory definitions, such as “frontier model” or “large frontier developer,” to reflect technological change. Any updates must be adopted by the Legislature, but this mechanism offers definitional adaptability. Notably, earlier drafts of SB 53 would have provided the Attorney General (AG) direct rulemaking authority over these definitions. However, the final version of the bill removes the AG rulemaking authority in favor of the Department of Technology recommendations to the Legislature.
From SB 1047 to SB 53: How the Bill Narrowed
SB 53 is a pared-down successor to last year’s SB 1047, which Governor Newsom vetoed. In his veto statement, Newsom called for an approach to frontier model regulation “informed by an empirical trajectory analysis of AI systems and capabilities,” leading to the creation of the Joint California Policy Working Group on AI Frontier Models. The group released a report offering regulatory best practices, which emphasized whistleblower protections and alignment with leading safety practices.
When the bill returned in 2025, it passed without many of SB 1047’s most controversial provisions, including:
Mandating full shutdown capabilities (or “kill switch”) for covered models, criticized as technically infeasible and a barrier to open-source development;
Imposing pre-training requirements, obligating developers to implement safety protocols, cybersecurity protections, and full shutdown capabilities before beginning initial training of a covered model;
Requiring annual audits by independent third-party assessors;
Strict 72-hour reporting window for safety incidents; and
Steep penalties tied to compute cost, up to 10% for first violations and 30% for subsequent ones.
By contrast, SB 53 focuses on deployment-stage obligations, lengthens reporting timelines to 15 days, caps penalties at $1 million per violation, and streamlines the information required in transparency reports and frameworks (removing, for example, testing disclosure requirements). These changes produced a narrower bill with reduced obligations for frontier developers, satisfying some but not all critics.
Comparison with New York’s RAISE Act
With SB 53 now law, attention turns to New York and the Responsible AI Safety and Education (RAISE) Act, which is pending on Governor Hochul’s desk. Like SB 53, the RAISE Act was inspired by last year’s SB 1047 and seeks to regulate frontier AI models. Hochul has as late as January 1, 2026, to sign, veto, or issue chapter amendments, a process that allows the governor to negotiate substantial changes with the legislature at the time of signature. Given Newsom’s signature of SB 53, a central question is whether RAISE will be amended to more closely align with the California law.
To help stakeholders track these dynamics, we’ve created a side-by-side comparison of the two bills. Broadly, SB 53 is more detailed in content—requiring frameworks, transparency reports, and whistleblower protections—while RAISE is stricter in enforcement, with higher penalties and liability provisions. Both bills share core elements, such as compute thresholds, catastrophic risk definitions, and mandatory frameworks/protocols. Key differences include:
Strict Liability: RAISE prohibits deployment of frontier models that pose an “unreasonable risk of critical harm,” a standard absent from SB 53.
Scope: SB 53 uses broader definitions of catastrophic risk and distinguishes between “frontier developers” and “large frontier developers,” which are those with $500M+ annual revenue. RAISE applies only to “large developers,” defined as those spending $100M+ on compute, which could bring a distinct group of companies into scope when compared to SB 53.
Requirements: SB 53 imposes additional obligations, including employee whistleblower protections and public transparency reports. Where requirements overlap, such as safety incident reporting, SB 53 allows public reporting and offers a longer timeline (15 days), while RAISE sets a 72-hour window and uses stricter qualifiers.
Enforcement: SB 53 caps penalties at $1 million per violation and empowers the California Department of Technology to recommend definitional updates. RAISE authorizes significantly higher penalties (up to $10 million for a first violation and $30 million for subsequent ones).
The bills highlight how state legislators are experimenting with comparable, yet distinct, approaches to AI frontier model regulation–California’s highlighting transparency and employee protections, with New York’s emphasizing stronger penalties and liability standards.
Conclusion
SB 53 makes California the first state to enact legislation focused on frontier AI, establishing transparency, disclosure, and governance requirements for high-compute model developers. Compared to last year’s broader SB 1047, the new law takes a narrower approach, scaling back several of the compliance obligations.
Attention now turns to New York, where the RAISE Act awaits action by the governor. Whether signed as written or amended through the chapter amendment process to reflect aspects of SB 53, the bill could become a second state-level framework for frontier AI. Other states, including Michigan, have introduced proposals of their own, illustrating the potential for a patchwork of requirements across jurisdictions.
As detailed in FPF’s recent report, State of State AI: Legislative Approaches to AI in 2025, this year’s legislative landscape highlights ongoing state experimentation in AI governance. With SB 53 enacted and the RAISE Act under consideration, state-level activity is moving from proposal to implementation, raising questions about how divergent approaches may shape compliance expectations and interact with future federal efforts.
The State of State AI: Legislative Approaches to AI in 2025
State lawmakers accelerated their focus on AI regulation in 2025, proposing a vast array of new regulatory models. From chatbots and frontier models to healthcare, liability, and sandboxes, legislators examined nearly every aspect of AI as they sought to address its impact on their constituents.
To help stakeholders understand this rapidly evolving environment, the Future of Privacy Forum (FPF) has published The State of State AI: Legislative Approaches to AI in2025.
This report analyzes how states shaped AI legislation during the 2025 legislative session, spotlighting the trends and thematic approaches that steered state policymaking. By grouping legislation into three primary categories: (1) use- and context-specific measures, (2) technology-specific bills, and (3) liability and accountability frameworks, this report highlights the most important developments for industry, policymakers, and other stakeholders within AI governance.
In 2025, FPF tracked 210 billsacross 42 states that could directly or indirectly affect private-sector AI development and deployment. Of those, 20 bills (around 9%) were enrolled or enacted.1 While other trackers estimated that more than 1,000 AI-related bills were introduced this year, FPF’s methodology applies a narrower lens, focusing on measures most likely to create direct compliance implications for private-sector AI developers and deployers.2
Key Takeaways
State lawmakers moved away from sweeping frameworks regulating AI, towards narrower, transparency-driven approaches.
Three key approaches to private sector AI regulation emerged: use and context-specific regulations targeting sensitive applications, technology-specific regulations, and a liability and accountability approach that utilizes, clarifies, or modifies existing liability regimes’ application to AI.
The most commonly enrolled or enacted frameworks include AI’s application in healthcare, chatbots, and innovation safeguards.
Legislatures signaled an interest in balancing consumer protection with support for AI growth, including testing novel innovation-forward mechanisms, such as sandboxes and liability defenses.
Looking ahead to 2026,issues like definitional uncertainty remain persistent while newer trends around topics like agentic AI and algorithmic pricing are starting to emerge.
Classification of AI Legislation
To provide a framework to analyze the diverse set of bills introduced in 2025, FPF classified state legislation into four categories based on their primary focus. This classification highlights whether lawmakers concentrated on specific applications, particular technologies, liability and accountability questions, or government use and strategy. While many bills touch on multiple themes, this framework is designed to capture each bill’s primary focus and enable consistent comparisons across jurisdictions.
Table I.
Use / Context-Specific Bills
Focuses on certain uses of AI in high-risk decisionmaking or contexts–such as healthcare, employment, and finance–as well as broader proposals that address AI systems used in a variety of consequential decisionmaking contexts. These bills typically focus on applications where AI may significantly impact individuals’ rights, access to services, or economic opportunities. Examples of enacted frameworks: Illinois HB 1806 (AI in mental health), Montana SB 212 (AI in critical infrastructure)
Technology-Specific Bills
Focuses on specific types of AI technologies,such as generative AI, frontier/foundation models, and chatbots. These bills often tailor requirements to the functionality, capabilities, or use patterns of each system type. Examples of enacted frameworks: New York S 6453 (frontier models), Maine LD 1727 (chatbots), Utah SB 226 (generative AI)
Bills Focused on Liability and Accountability
Focuses on defining, clarifying, or qualifying legal responsibility for use and development of AI systems utilizing existing legal tools, such as clarifying liability standards, creating affirmative defenses, or authorizing regulatory sandboxes. These aim to support accountability, responsible innovation, and greater legal clarity. Examples of enacted frameworks: Texas HB 149 (regulatory sandbox), Arkansas HB 1876 (copyright ownership of synthetic content)
Government Use and Strategy Bills
Focuses on requirements for government agencies’ use of AI that have downstream or indirect effects on the private sector, such as creating standards and requirements for agencies procuring AI systems from private sector vendors. Examples of enacted frameworks: Kentucky SB 4 (high-risk AI in government), New York A 433 (automated employment decision making in government)
Table II. Organizes the 210 bills tracked by FPF’s U.S. Legislation Team in 2025 across 18 subcategories.
Table III. Organizes the 210 bills tracked by FPF’s U.S. Legislation Team in 2025 into overarching themes, excluding bills focused on government use and strategy that do not set direct industry obligations. Bills in the “miscellaneous” category primarily reflect comprehensive AI legislation.
Use or Context-Specific Approaches to AI Regulation
In 2025, nine laws were enrolled or enacted and six additional billspassed at least one chamber that sought to regulate AI based on its use or context.
Focus on health-related AI applications: Legislatures concentrated on AI in sensitive health contexts, especially mental health and companion chatbots, often setting disclosure obligations. These health-specific laws primarily focus on limiting or guiding AI use by licensed professionals, particularly in mental health contexts. Looking beyond enrolled or enacted measures, nearly 9% of all introduced AI-related bills tracked by FPF in 2025 focused specifically on healthcare. From a compliance perspective, most prohibit AI from independently diagnosing patients, making treatment decisions, or replacing human providers, and many impose disclosure obligations when AI is used in patient communications.
High-risk frameworks arose only through amendments to existing law: In contrast to 2024, when Colorado enacted the Colorado Artificial Intelligence Act (CAIA), an AI law regulating different forms of “high-risk” systems used in consequential decision making, no similarly broad legislation was passed in 2025. Several jurisdictions advanced “high risk” approaches through amendments to existing laws or rulemaking efforts–many of which predate Colorado’s AI law but reflect a similar focus on automated decision-making systems across consequential decisionmaking contexts. These include amendments to existing data privacy laws’ provisions on automated decision making under the California Privacy Protection Agency’s (CPPA) regulations, Connecticut’s SB 1295 (enacted), and New Jersey’s ongoing rulemaking.
Growing emphasis on disclosures: User-facing disclosures became the most common safeguard, with eight of the enrolled or enacted laws and regulations requiring that individuals be informed when they are interacting with, or subject to, decisions made by an AI system.
Shift toward fewer governance requirements: Compared to 2024 proposals, 2025 legislation shifted away from compliance mandates, like impact assessments, in favor of transparency measures. For the few laws that did include governance-related processes, the obligations were generally “softer,” such as being tied to an affirmative defense (e.g. Utah’s HB 452, enacted) or satisfied through adherence to federal requirements (e.g. Montana’s SB 212, enacted).
Technology-Specific Approaches to AI Regulation
In 2025, ten laws were enrolled or enacted and five additional billspassed at least one chamber that targeted specific types of AI technologies, rather than just their use contexts.
Chatbots as a key legislative focus: Several new laws focused on chatbots—particularly “companion” and mental health chatbots—introducing compliance requirements for user disclosure, safety protocols to address risks like suicide and self-harm, and restrictions on data use and advertising. Chatbots drew heightened legislative attention following recent court cases and high-profile incidents involving chatbot that allegedly promoted suicidal ideation to youth. As a result, several of these bills, like New York’s S-3008C (enacted), introduce safety-focused provisions, including directing users to crisis resources. Additionally, six of the seven key chatbot bills include a requirement for chatbot operators to notify users that the chatbot is not human, in efforts to promote user awareness.
Frontier/foundation models regulation reintroduced: California and New York revived frontier model legislation (SB 53 and the RAISE Act, enrolled), building on 2024’s California’s SB 1047 (vetoed) but with narrower scope and streamlined requirements for written safety protocols. Similar bills were introduced in Rhode Island, Michigan, and Illinois, centered on preventing “catastrophic risks” from the most powerful AI systems, like large-scale security failures that could lead to human injury or harms to critical infrastructure.
Generative AI proposals centered on labeling:A majority of generative AI bills in 2025 focused on content labeling—either required disclosures visible to users at the time of interaction, or a more technical effort of tagging of provenance or training data to enhance content traceability—to address risks of deception and misinformation. Bills include: California’s AB 853 (enrolled), New York’s S 6954 (proposed), California’s SB 11 (enrolled), and New York’s S 934 (proposed).
Liability and Accountability Approaches to AI Regulation
This past year, eightlaws were enrolled or enacted and ninenotable bills passed at least one chamber that focused on defining, clarifying, or qualifying legal responsibility for use and deployment of AI systems. State legislatures tested different ways to balance liability, safety, and innovation.
Clarifying liability regimes for accountability:Across numerous states, lawmakers looked to affirmative defenses, or legal claims that allow defendants to dismiss lawsuits based on certain grounds, as a solution for incentivizing responsible AI practices while maintaining flexibility and reducing legal risks for businesses. Examples include: Utah’s HB 452 (enacted) allowing an affirmative defense if a provider maintained certain AI governance measures and California’s SB 813 (proposed) allowing AI developers to use certified third-party audits as an affirmative defense in civil lawsuits. Legislators also sought to update privacy and tort statutes to address AI-specific risks, such as Texas’ TRAIGA amendment (enacted) of the Texas biometric privacy law to account for AI training.
Prioritization of innovation-focused measures: States experimented with regulatory sandboxes that allow controlled AI development, with the enactment of new regulatory sandboxes in Texas and Delaware, along with the first official sandbox agreement under Utah’s 2024 AI Policy Act (SB 149). Other legislation, such as Montana’s SB 212 (enacted), introduced “right to compute” provisions to protect AI development and deployment.
Enforcement tools and defense strategies: Legislatures expanded Attorney General investigative powers (such as civil investigative demands) in bills including Texas’ TRAIGA (enacted) and Virginia HB 2094 (vetoed). A variety of other defense mechanisms were introduced, including specific protections for whistleblowers, as represented in California’s SB 53 (enrolled).
Looking Ahead to 2026
As the 2026 legislative cycle begins, states are expected to revisit unfinished debates from 2025 while turning to new and fast-evolving issues. Frontier/foundation models, chatbots, and health-related AI will remain central topics, while definitional uncertainty, agentic AI, and algorithmic pricing signal the next wave of policy debates.
Definitional Uncertainty: States continue to diverge in how they define artificial intelligence itself, as well as categories like frontier models, generative AI, and chatbots. Definitional variations, such as compute thresholds for “frontier” systems or qualifiers in generative AI definitions, are shaping which technologies fall under regulatory scope. These differences will become more consequential as more bills are enrolled, expanding the compliance landscape.
Agentic AI: Legislators are beginning to explore “AI agents” capable of autonomous planning and action, systems that move beyond generative AI’s content creation and towards more complex functions. Early governance experiments include Virginia’s “regulatory reduction pilot” and Delaware’s agentic AI sandbox, but few bills directly address these agents. Existing risk frameworks may prove ill-suited for agentic AI, as harms are harder to trace across agents’ multiple decision nodes, suggesting that governance approaches may need to adapt in 2026.
Algorithmic pricing: States are testing ways to regulate AI-driven pricing tools, with bills targeting discrimination, transparency, and competition. New York enacted disclosure requirements for “personalized algorithmic pricing” (S 3008, enacted), while California (AB 446 and SB 384, proposed), Colorado, and Minnesota floated their own frameworks. In 2026, lawmakers may focus on more precise definitions or stronger disclosure or prohibition measures amid growing legislative activity on algorithmic pricing.
Conclusion
In 2025, state legislatures sought to demonstrate that they could be laboratories of democracy for AI governance: testing disclosure rules, liability frameworks, and technology-specific measures. With definitional questions still unsettled and new issues like agentic AI and algorithmic pricing on the horizon, state legislatures are poised to remain active in 2026. These developments illustrate both the opportunities and challenges of state-driven approaches, underscoring the value of comparative analysis as policymakers and stakeholders weigh whether, and in what form, federal standards may emerge. At the same time, signals from federal debates, increased industry advocacy, and international developments are beginning to shape state efforts, pointing to ongoing interplay between state experimentation and broader policy currents.
Upon publication of this report, bills in California and New York are still awaiting gubernatorial action. This total is limited to bills with direct implications for industry and excludes measures focused solely on government use of AI or those that only extend the effective date of prior legislation. ↩︎
This report excludes: bills and resolutions that merely reference AI in passing; updates to criminal statutes; and legislation focused on areas like elections, housing, agriculture, state investments in workforce development, and public education, which are less likely to involve direct obligations for companies developing or deploying AI technologies. ↩︎
Call for Nominations: 16th Annual Privacy Papers for Policymakers Awards
The 16th Privacy Papers for Policymakers call for submissions is now open until October 30, 2025. FPF’s Privacy Papers for Policymakers Award recognizes leading privacy research and analytical scholarship relevant to policymakers in the U.S. and internationally. The award highlights important work that analyzes current and emerging privacy issues and proposes achievable short-term solutions or means of analysis that have the potential to lead to real-world policy solutions.
FPF welcomes privacy scholars, researchers, and students to submit completed papers focusing on privacy or AI governance, specifically emphasizing data protection, and be relevant to policymakers in this field. Submissions may include academic papers, books, empirical research, or other longer-form analyses from any region completed, accepted, or published within the last 12 months. Submissions should be submitted in English as a PDF, DOC, or DOCX, or a publicly available link, with a one-page Executive Summary or Abstract, and the author’s complete contact and affiliation information.
Submissions are evaluated by a diverse team of FPF staff members based on originality, applicability to policymaking, and overall quality of writing. Summaries of the winning papers will be published in a digest on the FPF website, and winning authors will have the opportunity to present their work during a virtual event in 2026 in front of top policymakers and privacy leaders. All winners are also highlighted during the event and in a press release to the media.