Future of Privacy Forum Launches the FPF Center for Artificial Intelligence
The FPF Center for Artificial Intelligence will serve as a catalyst for AI policy and compliance leadership globally, advancing responsible data and AI practices for public and private stakeholders
Today, the Future of Privacy Forum (FPF) launched the FPF Center for Artificial Intelligence, established to better serve policymakers, companies, non-profit organizations, civil society, and academics as they navigate the challenges of AI policy and governance. The Center will expand FPF’s long-standing AI work, introduce large-scale novel research projects, and serve as a source for trusted, nuanced, nonpartisan, and practical expertise.
FPF’s Center work will be international as AI continues to deploy globally and rapidly. Cities, states, countries, and international bodies are already grappling with implementing laws and policies to manage the risks.“Data, privacy, and AI are intrinsically interconnected issues that we have been working on at FPF for more than 15 years, and we remain dedicated to collaborating across the public and private sectors to promote their ethical, responsible, and human-centered use,” saidJules Polonetsky, FPF’s Chief Executive Officer. “But we have reached a tipping point in the development of the technology that will affect future generations for decades to come. At FPF, the word Forum is a core part of our identity. We are a trusted convener positioned to build bridges between stakeholders globally, and we will continue to do so under the new Center for AI, which will sit within FPF.”
The Center will help the organization’s 220+ members navigate AI through the development of best practices, research, legislative tracking, thought leadership, and public-facing resources. It will be a trusted evidence-based source of information for policymakers, and it will collaborate with academia and civil society to amplify relevant research and resources.
“Although AI is not new, we have reached an unprecedented moment in the development of the technology that marks a true inflection point. The complexity, speed and scale of data processing that we are seeing in AI systems can be used to improve people’s lives and spur a potential leapfrogging of societal development, but with that increased capability comes associated risks to individuals and to institutions,” saidAnne J. Flanagan, Vice President for Artificial Intelligence at FPF. “The FPF Center for AI will act as a collaborative force for shared knowledge between stakeholders to support the responsible development of AI, including its fair, safe, and equitable use.”
The Center will officially launch at FPF’s inaugural summit DC Privacy Forum: AI Forward. The in-person and public-facing summit will feature high-profile representatives from the public and private sectors in the world of privacy, data and AI.
FPF’s new Center for Artificial Intelligence will be supported by a Leadership Council of leading experts from around the globe. The Council will consist of members from industry, academia, civil society, and current and former policymakers.
See the full list of founding FPF Center for AI Leadership Council members here.
I am excited about the launch of the Future of Privacy Forum’s new Center for Artificial Intelligence and honored to be part of its leadership council. This announcement builds on many years of partnership and collaboration between Workday and FPF to develop privacy best practices and advance responsible AI, which has already generated meaningful outcomes, including last year’s launch of best practices to foster trust in this technology in the workplace. I look forward to working alongside fellow members of the Council to support the Center’s mission to build trust in AI and am hopeful that together we can map a path forward to fully harness the power of this technology to unlock human potential.
Barbara Cosgrove, Vice President, Chief Privacy Officer, Workday
I’m honored to be a founding member of the Leadership Council of the Future of Privacy Forum’s new Center for Artificial Intelligence. AI’s impact transcends borders, and I’m excited to collaborate with a diverse group of experts around the world to inform companies, civil society, policymakers, and academics as they navigate the challenges and opportunities of AI governance, policy, and existing data protection regulations.
Dr. Gianclaudio Malgieri, Associate Professor of Law & Technology at eLaw, University of Leiden
“As we enter this era of AI, we must require the right balance between allowing innovation to flourish and keeping enterprises accountable for the technologies they create and put on the market. IBM believes it will be crucial that organizations such as the Future of Privacy Forum help advance responsible data and AI policies, and we are proud to join others in industry and academia as part of the Leadership Council.”
Christina Montgomery, Chief Privacy & Trust Officer, AI Ethics Board Chair, IBM
The Future of Privacy Forum (FPF) is a global non-profit organization that brings together academics, civil society, government officials, and industry to evaluate the societal, policy, and legal implications of data use, identify the risks, and develop appropriate protections.
FPF believes technology and data can benefit society and improve lives if the right laws, policies, and rules are in place. FPF has offices in Washington D.C., Brussels, Singapore, and Tel Aviv. Learn more at fpf.org.
FPF Develops Checklist & Guide to Help Schools Vet AI Tools for Legal Compliance
FPF’s Youth and Education team has developed a checklist and accompanying policy brief to help schools vet generative AI tools for compliance with student privacy laws. Vetting Generative AI Tools for Use in Schools is a crucial resource as the use of generative AI tools continues to increase in educational settings. It’s critical for school leaders to understand how existing federal and state student privacy laws, such as the Family Educational Rights and Privacy Act (FERPA) apply to the complexities of machine learning systems to protect student privacy. With these resources, FPF aims to provide much-needed clarity and guidance to educational institutions grappling with these issues.
“AI technology holds immense promise in enhancing educational experiences for students, but it must be implemented responsibly and ethically,” said David Sallay, the Director for Youth & Education Privacy at the Future of Privacy Forum. “With our new checklist, we aim to empower educators and administrators with the knowledge and tools necessary to make informed decisions when selecting generative AI tools for classroom use while safeguarding student privacy.”
The checklist, designed specifically for K -12 schools, outlines key considerations when incorporating generative AI into a school or district’s edtech vetting checklist.
These include:
assessing the requirements for vetting all edtech;
describing the specific use cases;
preparing to address transparency and explainability; and
determining if student PII will be used to train the large language model (LLM).
By prioritizing these steps, educational institutions can promote transparency and protect student privacy while maximizing the benefits of technology-driven learning experiences for students.
The in-depth policy brief outlines the relevant laws and policies a school should consider, the unique compliance considerations of generative AI tools (including data collection, transparency and explainability, product improvement, and high-risk decision-making), and their most likely use cases (student, teacher, and institution-focused).
The brief also encourages schools and districts to update their existing edtech vetting policies to address the unique considerations of AI technologies (or to create a comprehensive policy if one does not already exist) instead of creating a separate vetting process for AI. It also highlights the role that state legislatures can play in ensuring the efficiency of school edtech vetting and oversight and calls on vendors to be proactively transparent with schools about their use of AI.
Check out the LinkedIn Live with CEO Jules Polonetsky and Youth & Education Director David Sallay about the Checklist and Policy Brief.
To read more of the Future of Privacy Forum’s youth and student privacy resources, visitwww.StudentPrivacyCompass.org.
FPF Releases “The Playbook: Data Sharing for Research” Report and Infographic
Facilitating data sharing for research purposes between corporate data holders and academia can unlock new scientific insights and drive progress in public health, education, social science, and a myriad of other fields for the betterment of the broader society. Academic researchers use this data to consider consumer, commercial, and scientific questions at a scale they cannot reach using conventional research data-gathering techniques alone. This data also helped researchers answer questions on topics ranging from bias in targeted advertising and the influence of misinformation on election outcomes to early diagnosis of diseases through data collected by fitness and health apps.
The playbook addresses vital steps for data management, sharing, and program execution between companies and researchers. Creating a data-sharing ecosystem that positively advances scientific research requires a better understanding of the established risks, opportunities to address challenges, and the diverse stakeholders involved in data-sharing decisions. This report aims to encourage safe, responsible data-sharing between industries and researchers.
“Corporate data sharing connects companies with research institutions, by extension increasing the quantity and quality of research for social good,” said Shea Swauger, Senior Researcher for Data Sharing and Ethics. “This Playbook showcases the importance, and advantages, of having appropriate protocols in place to create safe and simple data sharing processes.”
In addition to the Playbook, FPF created a companion infographic summarizing the benefits, challenges, and opportunities of data sharing for research outlined in the larger report.
As a longtime advocate for facilitating the privacy-protective sharing of data by industry to the research community, FPF is proud to have created this set of best practices for researchers, institutions, policymakers, and data-holding companies. In addition to the Playbook, the Future of Privacy Forum has also opened nominations for its annual Award for Research Data Stewardship.
“Our goal with these initiatives is to celebrate the successful research partnerships transforming how corporations and researchers interact with each other,” Swauger said. “Hopefully, we can continue to engage more audiences and encourage others to model their own programs with solid privacy safeguards.”
Shea Swauger, Senior Researcher for Data Sharing and Ethics, Future of privacy Forum
Established by FPF in 2020 with support from The Alfred P. Sloan Foundation, the Award for Research Data Stewardship recognizes excellence in the privacy-protective stewardship of corporate data shared with academic researchers. The call for nominations is open and closes on Tuesday, January 17, 2023. To submit a nomination, visit the FPF site.
FPF has also launched a newly formed Ethics and Data in Research Working Group; this group receives late-breaking analyses of emerging US legislation affecting research and data, meets to discuss the ethical and technological challenges of conducting research, and collaborates to create best practices to protect privacy, decrease risk, and increase data sharing for research, partnerships, and infrastructure. Learn more and join here.
FPF Testifies Before House Subcommittee on Energy and Commerce, Supporting Congress’s Efforts on the “American Data Privacy and Protection Act”
This week, FPF’s Senior Policy Counsel Bertram Lee testified before the U.S. House Energy and Commerce Subcommittee on Consumer Protection and Commerce hearing, “Protecting America’s Consumers: Bipartisan Legislation to Strengthen Data Privacy and Security” regarding the bipartisan, bicameral privacy discussion draft bill, “American Data Privacy and Protection Act” (ADPPA). FPF has a history of supporting the passage of a comprehensive federal consumer privacy law, which would provide businesses and consumers alike with the benefit of clear national standards and protections.
Lee’s testimony opened by applauding the Committee on its efforts towards comprehensive federal privacy legislation and emphasized the “time is now” for its passage. As it is written, the ADPPA would address gaps in the sectoral approach to consumer privacy, establish strong national civil rights protections, and establish new rights and safeguards for the protection of sensitive personal information.
“The ADPPA is more comprehensive in scope, inclusive of civil rights protections, and provides individuals with more varied enforcement mechanisms in comparison to some states’ current privacy regimes,” Lee said in his testimony. “It also includes corporate accountability mechanisms, such as the requiring privacy designations, data security offices, and executive certifications showing compliance, which is missing from current states’ laws. Notably, the ADPPA also requires ‘short-form’ privacy notices to aid consumers of how their data will be used by companies and their rights — a provision that is not found in any state law.”
Lee’s testimony also provided four recommendations to strengthen the bill, which include:
Additional funding and resources for the FTC;
Developing a more iterative process to ensure that the bill can keep up with evolving technologies;
Clarifying the intersection of ADPPA with other federal privacy laws (COPPA, FERPA, HIPAA, etc.); and
Establishing clear definitions and distinctions between different types of covered entities, including service providers.
Many of the recommendations would ensure that the legislation gives individuals meaningful privacy rights and places clear obligations on businesses and other organizations that collect, use and share personal data. The legislation would expand civil rights protections for individuals and communities harmed by algorithmic discrimination as well as require algorithmic assessments and evaluations to better understand how these technologies can impact communities.
Reading the Signs: the Political Agreement on the New Transatlantic Data Privacy Framework
The President of the United States, Joe Biden, and the President of the European Commission, Ursula von der Leyen, announced last Friday, in Brussels, a political agreement on a new Transatlantic framework to replace the Privacy Shield.
This is a significant escalation of the topic within Transatlantic affairs, compared to the 2016 announcement of a new deal to replace the Safe Harbor framework. Back then, it was Commission Vice-President Andrus Ansip and Commissioner Vera Jourova who announced at the beginning of February 2016 that a deal had been reached.
The draft adequacy decision was only published a month after the announcement, and the adequacy decision was adopted 6 months later, in July 2016. Therefore, it should not be at all surprising if another 6 months (or more!) pass before the adequacy decision for the new Framework will produce legal effects and actually be able to support transfers from the EU to the US. Especially since the US side still has to pass at least one Executive Order to provide for the agreed-upon new safeguards.
This means that transfers of personal data from the EU to the US may still be blocked in the following months – possibly without a lawful alternative to continue them – as a consequence of Data Protection Authorities (DPAs) enforcing Chapter V of the General Data Protection Regulation in the light of the Schrems II judgment of the Court of Justice of the EU, either as part of the 101 noyb complaints submitted in August 2020 and slowly starting to be solved, or as part of other individual complaints/court cases.
If you are curious about what the legal process will look like both on the US and EU sides after the agreement “in principle”, check out this blog post by Laila Abdelaziz of the “Privacy across borders project” at American University.
After the agreement “in principle” was announced at the highest possible political level, EU Justice Commissioner Didier Reynders doubled down on the point that this agreement is reached “on the principles” for a new framework, rather than on the details of it. Later on he also gave credit to Commerce Secretary Gina Raimondo and US Attorney General Merrick Garland for their hands-on involvement in working towards this agreement.
In fact, “in principle” became the leitmotif of the announcement, as the first EU Data Protection Authority to react to the announcement was the European Data Protection Supervisor, who wrote that he “Welcomes, in principle”, the announcement of a new EU-US transfers deal – “The details of the new agreement remain to be seen. However, EDPS stresses that a new framework for transatlantic data flows must be sustainable in light of requirements identified by the Court of Justice of the EU”.
Of note, there is no catchy name for the new transfers agreement, which was referred to as the “Trans-Atlantic Data Privacy Framework”. Nonetheless, FPF’s CEO Jules Polonetsky submits the “TA DA!” Agreement, and he has my vote. For his full statement on the political agreement being reached, see our release here.
Some details of the “principles” agreed on were published hours after the announcement, both by the White House and by the European Commission. Below are a couple of things that caught my attention from the two brief Factsheets.
The US has committed to “implement new safeguards” to ensure that SIGINT activities are “necessary and proportionate” (an EU law legal measure – see Article 52 of the EU Charter on how the exercise of fundamental rights can be limited) in the pursuit of defined national security objectives. Therefore, the new agreement is expected to address the lack of safeguards for government access to personal data as specifically outlined by the CJEU in the Schrems II judgment.
The US also committed to creating a “new mechanism for the EU individuals to seek redress if they believe they are unlawfully targeted by signals intelligence activities”. This new mechanism was characterized by the White House as having “independent and binding authority”. Per the White House, this redress mechanism includes “a new multi-layer redress mechanism that includes an independent Data Protection Review Court that would consist of individuals chosen from outside the US Government who would have full authority to adjudicate claims and direct remedial measures as needed”. The EU Commission mentioned in its own Factsheet that this would be a “two-tier redress system”.
Importantly, the White House mentioned in the Factsheet that oversight of intelligence activities will also be boosted – “intelligence agencies will adopt procedures to ensure effective oversight of new privacy and civil liberties standards”. Oversight and redress are different issues and are both equally important – for details, see this piece by Christopher Docksey. However, they tend to be thought of as being one and the same. Being addressed separately in this announcement is significant.
One of the remarkable things about the White House announcement is that it includes several EU law-specific concepts: “necessary and proportionate”, “privacy, data protection” mentioned separately, “legal basis” for data flows. In another nod to the European approach to data protection, the entire issue of ensuring safeguards for data flows is framed as more than a trade or commerce issue – with references to a “shared commitment to privacy, data protection, the rule of law, and our collective security as well as our mutual recognition of the importance of trans-Atlantic data flows to our respective citizens, economies, and societies”.
Last, but not least, Europeans have always framed their concerns related to surveillance and data protection as being fundamental rights concerns. The US also gives a nod to this approach, by referring a couple of times to “privacy and civil liberties” safeguards (adding thus the “civil liberties” dimension) that will be “strengthened”. All of these are positive signs for a “rapprochement” of the two legal systems and are certainly an improvement to the “commerce” focused approach of the past on the US side.
Lastly, it should also be noted that the new framework will continue to be a self-certification scheme managed by the US Department of Commerce.
What does all of this mean in practice? As the White House details, this means that the Biden Administration will have to adopt (at least) an Executive Order (EO) that includes all these commitments and on the basis of which the European Commission will draft an adequacy decision.
Thus, there are great expectations in sight following the White House and European Commission Factsheets, and the entire privacy and data protection community is waiting to see further details.
In the meantime, I’ll leave you with an observation made by my colleague, Amie Stepanovich, VP for US Policy at FPF, who highlighted that Section 702 of the FISA Act is set to expire on December 31, 2023. This presents Congress with an opportunity to act, building on such an extensive amount of work done by the US Government in the context of the Transatlantic Data Transfers debate.
Privacy Best Practices for Rideshare Drivers Using Dashcams
FPF & Uber Publish Guide Highlighting Privacy Best Practices for Drivers who Record Video and Audio on Rideshare Journeys
FPF and Uber have created a guide for US-based rideshare drivers who install “dashcams” – video cameras mounted on a vehicle’s dashboard or windshield. Many drivers install dashcams to improve safety, security, and accountability; the cameras can capture crashes or other safety-related incidents outside and inside cars. Dashcam footage can be helpful to drivers, passengers, insurance companies, and others when adjudicating legal claims. At the same time, dashcams can pose substantial privacy risks if appropriate safeguards are not in place to limit the collection, use, and disclosure of personal data.
Dashcams typically record video outside a vehicle. Many dashcams also record in-vehicle audio and some record in-vehicle video. Regardless of the particular device used, ride-hail drivers who use dashcams must comply with applicable audio and video recording laws.
The guide explains relevant laws and provides practical tips to help drivers be transparent, limit data use and sharing, retain video and audio-only for practical purposes, and use strict security controls. The guide highlights ways that drivers can employ physical signs, in-app notices, and other means to ensure passengers are informed about dashcam use and can make meaningful choices about whether to travel in a dashcam-equipped vehicle. Drivers seeking advice concerning specific legal obligations or incidents should consult legal counsel.
Privacy best practices for dashcams include:
Give individuals notice that they are being recorded
Place recording notices inside and on the vehicle.
Mount the dashcam in a visible location.
Consider, in some situations, giving an oral notification that recording is taking place.
Determine whether the ride sharing service provides recording notifications in the app, and utilize those in-app notices.
Only record audio and video for defined, reasonable purposes
Only keep recordings for as long as needed for the original purpose.
Inform passengers as to why video and/or audio is being recorded.
Limit sharing and use of recorded footage
Only share video and audio with third parties for relevant reasons that align with the original reason for recording.
Thoroughly review the rideshare service’s privacy policy and community guidelines if using an app-based rideshare service, and be aware that many rideshare companies maintain policies against widely disseminating recordings.
Safeguard and encrypt recordings and delete unused footage
Identify dashcam vendors that provide the highest privacy and security safeguards.
Carefully read the terms and conditions when buying dashcams to understand the data flows.
Uber will be making these best practices available to drivers in their app and website.
Many ride-hail drivers use dashcams in their cars, and the guidance and best practices published today provide practical guidance to help drivers implement privacy protections. But driver guidance is only one aspect of ensuring individuals’ privacy and security when traveling. Dashcam manufacturers must implement privacy-protective practices by default and provide easy-to-use privacy options. At the same time, ride-hail platforms must provide drivers with the appropriate tools to notify riders, and carmakers must safeguard drivers’ and passengers’ data collected by OEM devices.
In addition, dashcams are only one example of increasingly sophisticated sensors appearing in passenger vehicles as part of driver monitoring systems and related technologies. Further work is needed to apply comprehensive privacy safeguards to emerging technologies across the connected vehicle sector, from carmakers and rideshare services to mobility services providers and platforms. Comprehensive federal privacy legislation would be a good start. And in the absence of Congressional action, FPF is doing further work to identify key privacy risks and mitigation strategies for the broader class of driver monitoring systems that raise questions about technologies beyond the scope of this dashcam guide.
12th Annual Privacy Papers for Policymakers Awardees Explore the Nature of Privacy Rights & Harms
The winners of the 12th annual Future of Privacy (FPF) Privacy Papers for Policymakers Award ask big questions about what should be the foundational elements of data privacy and protection and who will make key decisions about the application of privacy rights. Their scholarship will inform policy discussions around the world about privacy harms, corporate responsibilities, oversight of algorithms, and biometric data, among other topics.
“Policymakers and regulators in many countries are working to advance data protection laws, often seeking in particular to combat discrimination and unfairness,” said FPF CEO Jules Polonetsky. “FPF is proud to highlight independent researchers tackling big questions about how individuals and society relate to technology and data.”
This year’s papers also explore smartphone platforms as privacy regulators, the concept of data loyalty, and global privacy regulation. The award recognizes leading privacy scholarship that is relevant to policymakers in the U.S. Congress, at U.S. federal agencies, and among international data protection authorities. The winning papers will be presented at a virtual event on February 10, 2022.
The winners of the 2022 Privacy Papers for Policymakers Award are:
Privacy Harms, by Danielle Keats Citron, University of Virginia School of Law; and Daniel J. Solove, George Washington University Law School
This paper looks at how courts define harm in cases involving privacy violations and how the requirement of proof of harm impedes the enforcement of privacy law due to the dispersed and minor effects that most privacy violations have on individuals. However, when these minor effects are suffered at a vast scale, individuals, groups, and society can feel significant harm. This paper offers language for courts to refer to when litigating privacy cases and provides advice as to when privacy harm should be considered in a lawsuit.
In this paper, Green analyzes the use of human oversight of government algorithmic decisions. From this analysis, he concludes that humans are unable to perform the desired oversight responsibilities, and that by continuing to use human oversight as a check on these algorithms, the government legitimizes the use of these faulty algorithms without addressing the associated issues. The paper offers a more stringent approach to determining whether an algorithm should be incorporated into a certain government decision, which includes critically considering the need for the algorithm and evaluating whether people are capable of effectively overseeing the algorithm.
The Surprising Virtues of Data Loyalty, by Woodrow Hartzog, Northeastern University School of Law and Khoury College of Computer Sciences, Stanford Law School Center for Internet and Society; and Neil M. Richards, Washington University School of Law, Yale Information Society Project, Stanford Center for Internet and Society
The data loyalty responsibilities for companies that process human information are now being seriously considered in both the U.S. and Europe. This paper analyzes criticisms of data loyalty that argue that such duties are unnecessary, concluding that data loyalty represents a relational approach to data that allows us to deal substantively with the problem of platforms and human information at both systemic and individual levels. The paper argues that the concept of data loyalty has some surprising virtues, including checking power and limiting systemic abuse by data collectors.
Smartphone Platforms as Privacy Regulators, by Joris van Hoboken, Vrije Universiteit Brussels, Institute for Information Law, University of Amsterdam; and Ronan Ó Fathaigh, Institute for Information Law, University of Amsterdam
In this paper, the authors look at the role of online platforms and their impact on data privacy in today’s digital economy. The paper first distinguishes the different roles that platforms can have in protecting privacy in online ecosystems, including governing access to data, design of relevant interfaces, and policing the behavior of the platform’s users. The authors then provide an argument as to what platforms’ role should be in legal frameworks. They advocate for a compromise between direct regulation of platforms and mere self-regulation, arguing that platforms should be required to make official disclosures about their privacy-related policies and practices for their respective ecosystems.
China enacted the first codified personal information protection law in China in late 2021, the Personal Information Protection Law (PIPL). In this paper, Wang compares China’s PIPL with data protection laws in nine regions to assist overseas Internet companies and personnel who deal with personal information in better understanding the similarities and differences in data protection and compliance between each country and region.
Cameras are everywhere, and with the innovation of video analytics, there are questions being raised about how individuals should be notified that they are being recorded. This paper studied 123 individuals’ sentiments across 2,328 video analytics deployments scenarios to inform their conclusion. In their conclusion, the researchers advocate for the development of interfaces that simplify the task of managing notices and configuring controls, which would allow individuals to communicate their opt-in/opt-out preference to video analytics operators.
From the record number of nominated papers submitted this year, these six papers were selected by a diverse team of academics, advocates, and industry privacy professionals from FPF’s Advisory Board. The winning papers were selected based on the research and solutions that are relevant for policymakers and regulators in the U.S. and abroad.
In addition to the winning papers, FPF has selected two papers for Honorable Mention: Verification Dilemmas and the Promise of Zero-Knowledge Proofs by Kenneth Bamberger, University of California, Berkeley – School of Law; Ran Canetti, Boston University, Department of Computer Science, Boston University, Faculty of Computing and Data Science, Boston University, Center for Reliable Information Systems and Cybersecurity; Shafi Goldwasser, University of California, Berkeley – Simons Institute for the Theory of Computing; Rebecca Wexler, University of California, Berkeley – School of Law; and Evan Zimmerman, University of California, Berkeley – School of Law; and A Taxonomy of Police Technology’s Racial Inequity Problems by Laura Moy, Georgetown University Law Center.
FPF also selected a paper for the Student Paper Award, A Fait Accompli? An Empirical Study into the Absence of Consent to Third Party Tracking in Android Apps by Konrad Kollnig and Reuben Binns, University of Oxford; Pierre Dewitte, KU Leuven; Max van Kleek, Ge Wang, Daniel Omeiza, Helena Webb, and Nigel Shadbolt, University of Oxford. The Student Paper Award Honorable Mention was awarded to Yeji Kim, University of California, Berkeley – School of Law, for her paper, Virtual Reality Data and Its Privacy Regulatory Challenges: A Call to Move Beyond Text-Based Informed Consent.
The winning authors will join FPF staff to present their work at a virtual event with policymakers from around the world, academics, and industry privacy professionals. The event will be held on February 10, 2022, from 1:00 – 3:00 PM EST. The event is free and open to the general public. To register for the event, visit https://bit.ly/3qmJdL2.
Organizations must lead with privacy and ethics when researching and implementing neurotechnology: FPF and IBM Live event and report release
A New FPF and IBM Report and Live Event Explores Questions About Transparency, Consent, Security, and Accuracy of Data
The Future of Privacy Forum (FPF) and the IBM Policy Lab released recommendations for promoting privacy and mitigating risks associated with neurotechnology, specifically with brain-computer interface (BCI). The new report provides developers and policymakers with actionable ways this technology can be implemented while protecting the privacy and rights of its users.
“We have a prime opportunity now to implement strong privacy and human rights protections as brain-computer interfaces become more widely used,” said Jeremy Greenberg, Policy Counsel at the Future of Privacy Forum. “Among other uses, these technologies have tremendous potential to treat people with diseases and conditions like epilepsy or paralysis and make it easier for people with disabilities to communicate, but these benefits can only be fully realized if meaningful privacy and ethical safeguards are in place.”
Brain-computer interfaces are computer-based systems that are capable of directly recording, processing, analyzing, or modulating human brain activity. The sensitivity of data that BCIs collect and the capabilities of the technology raise concerns over consent, as well as the transparency, security, and accuracy of the data. The report offers a number of policy and technical solutions to mitigate the risks of BCIs and highlights their positive uses.
“Emerging innovations like neurotechnology hold great promise to transform healthcare, education, transportation, and more, but they need the right guardrails in place to protect individuals’ privacy,” said IBM Chief Privacy Officer Christina Montgomery. “Working together with the Future of Privacy Forum, the IBM Policy Lab is pleased to release a new framework to help policymakers and businesses navigate the future of neurotechnology while safeguarding human rights.”
FPF and IBM have outlined several key policy recommendations to mitigate the privacy risks associated with BCIs, including:
Rethinking transparency, notice, terms of use, and consent frameworks to empower people around uses of their neurodata;
Ensuring that BCI devices are not allowed for uses to influence decisions about individuals that have legal effects, livelihood effects, or similar significant impacts—such as assessing the truthfulness of statements in legal proceedings; inferring thoughts, emotions or psychological state, or personality attributes as part of hiring or school admissions decisions; or assessing individuals’ eligibility for legal benefits;
Promoting an open and inclusive research ecosystem by encouraging the adoption of open standards for the collection and analysis of neurodata and the sharing of research data with appropriate safeguards in place.
Policymakers and other BCI stakeholders should carefully evaluate how existing policy frameworks apply to neurotechnologies and identify potential areas where existing laws and regulations may be insufficient for the unique risks of neurotechnologies.
FPF and IBM have also included several technical recommendations for BCI devices, including:
Providing hard on/off controls for users;
Allowing users to manage the collection, use, and sharing of personal neurodata on devices and in companion apps;
Offering heightened transparency and control for BCIs that send signals to the brain, rather than merely receive neurodata;
Utilizing best practices for privacy and security to store and process neurodata and use privacy enhancing technologies where appropriate; and
Encrypting sensitive personal neurodata in transit and at rest.
FPF-curated educational resources, policy & regulatory documents, academic papers, thought pieces, and technical analyses regarding brain-computer interfaces are available here.
Read FPF’s four-part series on Brain-Computer Interfaces (BCIs), providing an overview of the technology, use cases, privacy risks, and proposed recommendations for promoting privacy and mitigating risks associated with BCIs.
FPF Launches Asia-Pacific Region Office, Global Data Protection Expert Clarisse Girot Leads Team
The Future of Privacy Forum (FPF) has appointed Clarisse Girot, PhD, LLM, an expert on Asian and European privacy legislation, to lead its new FPF Asia-Pacific office based in Singapore as Director. This new office expands FPF’s international reach in Asia and complements FPF’s offices in the U.S., Europe, and Israel, as well as partnerships around the globe.
Dr. Clarisse Girot is a privacy professional with over twenty years of experience in the privacy and data protection fields. Since 2017, Clarisse has been leading the Asian Business Law Institute’s (ABLI) Data Privacy Project, focusing on the regulations on cross-border data transfers in 14 Asian jurisdictions. Prior to her time at ABLI, Clarisse served as the Counsellor to the President of the French Data Protection Authority (CNIL) and Chair of the Article 29 Working Party. She previously served as head of CNIL’s Department of European and International Affairs, where she sat on the Article 29 Working Party, the group of EU Data Protection Authorities, and was involved in major international cases in data protection and privacy.
“Clarisse is joining FPF at an important time for data protection in the Asia-Pacific region. The two most populous countries in the world, India, and China, are introducing general privacy laws, and established data protection jurisdictions, like Singapore, Japan, South Korea, and New Zealand, have recently updated their laws,” said FPF CEO Jules Polonetsky. “Her extensive knowledge of privacy law will provide vital insights for those interested in compliance with regional privacy frameworks and their evolution over time.”
FPF Asia-Pacific will focus on several priorities by the end of the year including hosting an event at this year’s Singapore Data Protection Week. The office will provide expertise in digital data flows and discuss emerging data protection issues in a way that is useful for regulators, policymakers, and legal professionals. Rajah & Tann Singapore LLP is supporting the work of the FPF Asia-Pacific office.
“The FPF global team will greatly benefit from the addition of Clarisse. She will advise FPF staff, advisory board members, and the public on the most significant privacy developments in the Asia-Pacific region, including data protection bills and cross-border data flows,” said Gabriela Zanfir-Fortuna, Director for Global Privacy at FPF. “Her past experience in both Asia and Europe gives her a unique ability to confront the most complex issues dealing with cross-border data protection.”
As over 140 countries have now enacted a privacy or data protection law, FPF continues to expand its international presence to help data protection experts grapple with the challenges of ensuring responsible uses of data. Following the appointment of Malavika Raghavan as Senior Fellow for India in 2020, the launch of the FPF Asia-Pacific office further expands FPF’s international reach.
Dr. Gabriela Zanfir-Fortuna leads FPF’s international efforts and works on global privacy developments and European data protection law and policy. The FPF Europe office is led by Dr. Rob van Eijk, who prior to joining FPF worked at the Dutch Data Protection Authority as Senior Supervision Officer and Technologist for nearly ten years. FPF has created thriving partnerships with leading privacy research organizations in the European Union, such as Dublin City University and the Brussels Privacy Hub of the Vrije Universiteit Brussel (VUB). FPF continues to serve as a leading voice in Europe on issues of international data flows, the ethics of AI, and emerging privacy issues. FPF Europe recently published a report comparing the regulatory strategy for 2021-2022 of 15 Data Protection Authorities to provide insights into the future of enforcement and regulatory action in the EU.
Outside of Europe, FPF has launched a variety of projects to advance tech policy leadership and scholarship in regions around the world, including Israel and Latin America. The work of the Israel Tech Policy Institute (ITPI), led by Managing Director Limor Shmerling Magazanik, includes publishing a report on AI Ethics in Government Services and organizing an OECD workshop with the Israeli Ministry of Health on access to health data for research.
In Latin America, FPF has partnered with the leading research association Data Privacy Brasil, provided in-depth analysis on Brazil’s LGPD privacy legislation and various data privacy cases decided in the Brazilian Supreme Court. FPF recently organized a panel during the CPDP LatAm Conference which explored the state of Latin American data protection laws alongside experts from Uber, the University of Brasilia, and the Interamerican Institute of Human Rights.
FPF and Leading Health & Equity Organizations Issue Principles for Privacy & Equity in Digital Contact Tracing Technologies
With support from the Robert Wood Johnson Foundation, FPF engaged leaders within the privacy and equity communities to develop actionable guiding principles and a framework to help bolster the responsible implementation of digital contact tracing technologies (DCTT). Today, seven privacy, civil rights, and health equity organizations signed on to these guiding principles for organizations implementing DCTT.
“We learned early in our Privacy and Pandemics initiative that unresolved ethical, legal, social, and equity issues may challenge the responsible implementation of digital contact tracing technologies,” said Jules Polonetsky, CEO of the Future of Privacy Forum. “So we engaged leaders within the civil rights, health equity, and privacy communities to create a set of actionable principles to help guide organizations implementing digital contact tracing that respects individual rights.”
Contact tracing has long been used to monitor the spread of various infectious diseases. In light of COVID-19, governments and companies began deploying digital exposure notification using Bluetooth and geolocation data on mobile devices to boost contact tracing efforts and quickly identify individuals who may have been exposed to the virus. However, as DCTT begins to play an important role in public health, it is important to take necessary steps to ensure equity in access to DCTT and understand the societal risks and tradeoffs that might accompany its implementation today and in the future. Governance efforts that seek to better understand these risks will be better able to bolster public trust in DCTT technologies.
“LGBT Tech is proud to have participated in the development of the Principles and Framework alongside FPF and other organizations. We are heartened to see that the focus of these principles is on historically underserved and under-resourced communities everywhere, like the LGBTQ+ community. We believe the Principles and Framework will help ensure that the needs and vulnerabilities of these populations are at the forefront during today’s pandemic and future pandemics.”
Carlos Gutierrez, Deputy Director, and General Counsel, LGBT Tech
“If we establish practices that protect individual privacy and equity, digital contact tracing technologies could play a pivotal role in tracking infectious diseases,” said Dr. Rachele Hendricks-Sturrup, Research Director at the Duke-Margolis Center for Health Policy. “These principles allow organizations implementing digital contact tracing to take ethical and responsible approaches to how their technology collects, tracks, and shares personal information.”
FPF, together with Dialogue on Diversity, the National Alliance Against Disparities in Patient Health (NADPH), BrightHive, and LGBT Tech, developed the principles, which advise organizations implementing DCTT to commit to the following actions:
Be Transparent About How Data Is Used and Shared.
Apply Strong De-Identification Techniques and Solutions.
Empower Users Through Tiered Opt-in/Opt-out Features and Data Minimization.
Acknowledge and Address Privacy, Security, and Nondiscrimination Protection Gaps.
Create Equitable Access to DCTT.
Acknowledge and Address Implicit Bias Within and Across Public and Private Settings.
Democratize Data for Public Good While Employing Appropriate Privacy Safeguards.
Adopt Privacy-By-Design Standards That Make DCTT Broadly Accessible.
Additional supporters of these principles include the Center for Democracy and Technology and Human Rights First.
To learn more and sign on to the DCTT Principles visit fpf.org/DCTT.
Support for this program was provided by the Robert Wood Johnson Foundation. The views expressed here do not necessarily reflect the views of the Foundation.
Navigating Preemption through the Lens of Existing State Privacy Laws
This post is the second of two posts on federal preemption and enforcement in United States federal privacy legislation. See Preemption in US Privacy Laws (June 14, 2021).
In drafting a federal baseline privacy law in the United States, lawmakers must decide to what extent the law will override state and local privacy laws. In a previous post, we discussed a survey of 12 existing federal privacy laws passed between 1968-2003, and the extent to which they are preemptive of similar state laws.
Another way to approach the same question, however, is to examine the hundreds of existing state privacy laws currently on the books in the United States. Conversations around federal preemption inevitably focus on comprehensive laws like the California Consumer Privacy Act, or the Virginia Consumer Data Protection Act — but there are hundreds of other state privacy laws on the books that regulate commercial and government uses of data.
In reviewing existing state laws, we find that they can be categorized usefully into: laws that complement heavily regulated sectors (such as health and finance); laws of general applicability; common law; laws governing state government activities (such as schools and law enforcement); comprehensive laws; longstanding or narrowly applicable privacy laws; and emerging sectoral laws (such as biometrics or drones regulations). As a resource, we recommend: Robert Ellis Smith, Compilation of State and Federal Privacy Laws (last supplemented in 2018).
Heavily Regulated Sectoral Silos. Most federal proposals for a comprehensive privacy law would not supersede other existing federal laws that contain privacy requirements for businesses, such as the Health Insurance Portability and Accountability Act (HIPAA) or the Gramm-Leach-Bliley Act (GLBA). As a result, a new privacy law should probably not preempt state sectoral laws that: (1) supplement their federal counterparts and (2) were intentionally not preempted by those federal regimes. In many cases, robust compliance regimes have been built around federal and state parallel requirements, creating entrenched privacy expectations, privacy tools, and compliance practices for organizations (“lock in”).
Laws of General Applicability. All 50 states have laws barring unfair and deceptive commercial and trade practices (UDAP), as well as generally applicable laws against fraud, unconscionable contracts, and other consumer protections. In cases where violations involve the mis-use of personal information, such claims could be inadvertently preempted by a national privacy law.
State Common Law. Privacy claims have been evolving in US common law over the last hundred years, and claims vary from state to state. A federal privacy law might preempt (or not preempt) claims brought under theories of negligence, breach of contract, product liability, invasions of privacy, or other “privacy torts.”
State Laws Governing State Government Activities. In general, states retain the right to regulate their own government entities, and a commercial baseline privacy law is unlikely to affect such state privacy laws. These include, for example, state “mini Privacy Acts” applying to state government agencies’ collection of records, state privacy laws applicable to public schools and school districts, and state regulations involving law enforcement — such as government facial recognition bans.
Comprehensive or Non-Sectoral State Laws. Lawmakers considering the extent of federal preemption should take extra care to consider the effect on different aspects of omnibus or comprehensive consumer privacy laws, such as the California Consumer Privacy Act (CCPA), the Colorado Privacy Act, and the Virginia Consumer Data Protection Act. In addition, however, there are a number of other state privacy laws that can be considered “non-sectoral” because they apply broadly to businesses that collect or use personal information. These include, for example, CalOPPA (requiring commercial privacy policies), the California “Shine the Light” law (requiring disclosures from companies that share personal information for direct marketing), data breach notification laws, and data disposal laws.
Congressional intent is the “ultimate touchstone” of preemption. Lawmakers should consider long-term effects on current and future state laws, including how they will be impacted by a preemption provision, as well as how they might be expressly preserved through a Savings Clause. In order to help build consensus, lawmakers should work with stakeholders and experts in the numerous categories of laws discussed above, to consider how they might be impacted by federal preemption.
Manipulative Design: Defining Areas of Focus for Consumer Privacy
In consumer privacy, the phrase “dark patterns” is everywhere. Emerging from a wide range of technical and academic literature, it now appears in at least two US privacy laws: the California Privacy Rights Act and the Colorado Privacy Act (which, if signed by the Governor, will come into effect in 2025).
Under both laws, companies will be prohibited from using “dark patterns,” or “user interface[s] designed or manipulated with the substantial effect of subverting or impairing user autonomy, decision‐making, or choice,” to obtain user consent in certain situations–for example, for the collection of sensitive data.
When organizations give individuals choices, some forms of manipulation have long been barred by consumer protection laws, with the Federal Trade Commission and state Attorneys General prohibiting companies from deceiving or coercing consumers into taking actions they did not intend or striking bargains they did not want. But consumer protection law does not typically prohibit organizations from persuading consumers to make a particular choice. And it is often unclear where the lines fall between cajoling, persuading, pressuring, nagging, annoying, or bullying consumers. The California and Colorado laws seek to do more than merely bar deceptive practices; they prohibit design that “subverts or impairs user autonomy.”
What does it mean to subvert user autonomy, if a design does not already run afoul of traditional consumer protections law? Just as in the physical world, the design of digital platforms and services always influences behavior — what to pay attention to, what to read and in what order, how much time to spend, what to buy, and so on. To paraphrase Harry Brignull (credited with coining the term), not everything “annoying” can be a dark pattern. Some examples of dark patterns are both clear and harmful, such as a design that tricks users into making recurring payments, or a service that offers a “free trial” and then makes it difficult or impossible to cancel. In other cases, the presence of “nudging” may be clear, but harms may be less clear, such as in beta-testing what color shades are most effective at encouraging sales. Still others fall in a legal grey area: for example, is it ever appropriate for a company to repeatedly “nag” users to make a choice that benefits the company, with little or no accompanying benefit to the user?
In Fall 2021, Future of Privacy Forum will host a series of workshops with technical, academic, and legal experts to help define clear areas of focus for consumer privacy, and guidance for policymakers and legislators. These workshops will feature experts on manipulative design in at least three contexts of consumer privacy: (1) Youth & Education; (2) Online Advertising and US Law; and (3) GDPR and European Law.
As lawmakers address this issue, we identify at least four distinct areas of concern:
Designs that cause concrete physical or financial harms to individuals. In some cases, design choices are implicated in concrete physical or financial harms. This might include, for example, a design that tricks users into making recurring payments, or makes unsubscribing from a free trial or other paid service difficult or impossible, leading to unwanted charges.
Designs that impact individual autonomy or dignity (but do not necessarily cause concrete physical or financial harm). In many cases, we observe concerns over autonomy and dignity, even where the use of data would not necessarily cause harm. For the same reasons that there is wide agreement that so-called subliminal messaging in advertising is wrong (as well as illegal), there is a growing awareness that disrespect for user autonomy in consumer privacy is objectionable on its face. As a result, in cases where the law requires consent, such as in the European Union for placement of information onto a user’s device, the law ought to provide a remedy for individuals who have been subject to a violation of that consent.
Designs that persuade, nag, or strongly push users towards a particular outcome, even where it may be possible for users to decline. In many cases, the design of a digital platform or serviceclearlypushes users towards a particular outcome, even if it is possible (if burdensome) for users to make a different choice. In such cases, we observe a wide spectrum of tactics that may be evaluated differently depending on the viewer and the context. Repeated requests may be considered “nagging” or “persuasion”; one person’s “clever marketing,” taken too far, becomes another person’s “guilt-shaming” or “confirm-shaming.” Ultimately, our preference for defaults (“opt in” versus “opt out”), and within those defaults, our level of tolerance for “nudging,” may be driven by the social benefits or values attached to the choice itself.
Designs that exploit biases, vulnerabilities, or heuristics in ways that implicate broader societal harms or values. Finally, we observe that the collection and use of personal information does not always solely impact individual decision-making. Often, the design of online platforms can influence groups in ways that impact societal values, such as the values of privacy, avoidance of “tech addiction,” free speech, the availability of data from or about marginalized groups, or the proliferation of unfair price discrimination or other market manipulation. Understanding how design choices may influence society, even if individuals are minimally impacted, may require examining the issues differently.
This week at the first edition of the annual Dublin Privacy Symposium, FPF will join other experts to discuss principles for transparency and trust. The design of user interfaces for digital products and services pervades modern life and directly impacts the choices people make with respect to sharing their personal information.
recast the conditions to obtain ‘safe harbour’ from liability for online intermediaries, and
unveiled an extensive regulatory regime for a newly defined category of online ‘publishers’, which includes digital news media and Over-The-Top (OTT) services.
The majority of these provisions were unanticipated, resulting in a raft of petitions filed in High Courts across the country challenging the validity of the various aspects of the Rules, including with regard to their constitutionality. On 25 May 2021, the three month compliance period on some new requirements for significant social media intermediaries (so designated by the Rules) expired, without many intermediaries being in compliance opening them up to liability under the Information Technology Act as well as wider civil and criminal laws. This has reignited debates about the impact of the Rules on business continuity and liability, citizens’ access to online services, privacy and security.
Following on FPF’s previous blog highlighting some aspects of these Rules, this article presents an overview of the Rules before deep-diving into critical issues regarding their interpretation and application in India. It concludes by taking stock of some of the emerging effects of these new regulations, which have major implications for millions of Indian users, as well as digital services providers serving the Indian market.
1.Brief overview of the Rules: Two new regimes for ‘intermediaries’ and ‘publishers’
The new Rules create two regimes for two different categories of entities: ‘intermediaries’ and ‘publishers’. Intermediaries have been the subject of prior regulations – the Information Technology (Intermediaries guidelines) Rules, 2011 (the 2011 Rules), now superseded by these Rules. However, the category of “publishers” and related regime created by these Rules did not previously exist.
The Rules begin with commencement provisions and definitions in Part I. Part II of the Rules apply to intermediaries (as defined in the Information Technology Act 2000 (IT Act)) who transmit electronic records on behalf of others, and includes online intermediary platforms (like Youtube, Whatsapp, Facebook). The rules in this part primarily flesh out the protections offered in Section 79 of India’s Information Technology Act 2000 (IT Act), which give passive intermediaries the benefit of a ‘safe harbour’ from liability for objectionable information shared by third parties using their services — somewhat akin to protections under section 230 of the US Communications Decency Act. To claim this protection from liability, intermediaries need to undertake certain ‘due diligence’ measures, including informing users of the types of content that could not be shared, and content take-down procedures (for which safeguards evolved overtime through important case law). The new Rules supersede the 2011 Rules and also significantly expand on them, introducing new provisions and additional due diligence requirements that are detailed further in this blog.
Part III of the Rules apply to a new previously non-existent category of entities designated to be ‘publishers‘. This is further classified into subcategories of ‘publishers of news and current affairs content’ and ‘publishers of online curated content’. Part III then sets up extensive requirements for publishers to adhere to specific codes of ethics, onerous content take-down requirements and three-tier grievance process with appeals lying to an Executive Inter-Departmental Committee of Central Government bureaucrats.
Finally, the Rules contain two provisions that apply to all entities (i.e. intermediaries and publishers) relating to content-blocking orders. They lay out a new process by which Central Government officials can issue directions to delete, modify or block content to intermediaries and publishers, either following a grievance process (Rule 15) or including procedures of “emergency”blocking orders which may be passed ex-parte. These Rules stem from powers to issue directions to intermediaries to block public access of any information through any computer resource (Section 69A of the IT Act). Interestingly, these provisions have been introduced separately from the existing rules for blocking purposes called the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009.
2.Key issues for intermediaries under the Rules
2.1 A new class of ‘social media intermediaries‘
The term ‘intermediary’ is a broadly defined term in the IT Act covering a range of entities involved in the transmission of electronic records. The Rules introduce two new sub-categories, being:
“social media intermediary” defined (in Rule 2(w)) as one who “primarily or solely enables online interaction between two or more users and allows them” to exchange information; and
“significant social media intermediary” (SSMI) comprising social media intermediaries with more than five million registered users in India (following this Government notification of the threshold).
Given that a popular messaging app like Whatsapp has over 400 million users in India, the threshold appears to be fairly conservative. The Government may order anyintermediary to comply with the same obligations as SSMIs (under Rule 6) if their services are adjudged to pose a risk of harm to national security, the sovereignty and integrity of India, India’s foreign relations or to public order.
SSMIs have to follow substantially more onerous “additional due diligence” requirements to claim the intermediary safe harbour (including mandatory traceability of message originators, and proactive automated screening as discussed below). These new requirements raise privacy concerns and data security concerns, as they extend beyond the traditional ideas of platform “due diligence”, they potentially expose content of private communications and in doing so create new privacy risks for users in India.
Extensive new requirements are set out in the new Rule 4 for SSMIs.
In-country employees: SSMIs must appoint in-country employees as (1) Chief Compliance Officer, (2) a nodal contact person for 24×7 coordination with law enforcement agencies and (3) a Resident Grievance Officer specifically responsible for overseeing the internal grievance redress mechanism. Monthly reporting of complaints management is also mandated.
Traceability requirements for SSMIs providing messaging services: Among the most controversial requirements is Rule 4(2) which requires SSMIs providing messaging services to enable the identification of the “first originator” of information on their platforms as required by Government or court orders. This tracing and identification of users is considered incompatible with end-to-end encryption technology employed by messaging applications like Whatsapp and Signal. In their legal challenge to this Rule, Whatsapp has noted that end-to-end encrypted platforms would need to be re-engineered to identify all users since there is no way to predict which user will be the subject of an order seeking first originator information.
Provisions to mandate modifications to the technical design of encrypted platforms to enable traceability seem to go beyond merely requiring intermediary due diligence. Instead they appear to draw on separate Government powers relating to interception and decryption of information (under Section 69 of the IT Act). In addition, separate stand-alone rules laying out procedures and safeguards for such interception and decryption orders already exist in the Information Technology (Procedure and Safeguards for Interception, Monitoring and Decryption of Information) Rules, 2009. Rule 4(2) even acknowledges these provisions–raising the question of whether these Rules (relating to intermediaries and their safe harbours) can be used to expand the scope of section 69 or rules thereunder.
Proceedings initiated by Whatsapp LLC in the Delhi High Court, and Free and Open Source Software (FOSS) developer Praveen Arimbrathodiyil in the Kerala High Court have both challenged the legality and validity of Rule 4(2) on grounds including that they are ultra vires and go beyond the scope of their parent statutory provisions (s. 79 and 69A) and the intent of the IT Act itself. Substantively, the provision is also challenged on the basis that it would violate users’ fundamental rights including the right to privacy, and the right to free speech and expression due to the chilling effect that the stripping back of encryption will have.
Automated content screening: Rule 4(4) mandates that SSMIs must employ technology-based measures including automated tools to proactively identify information depicting (i) rape, child sexual abuse or conduct, or (ii) any information previousy removed following a Government or court order. The latter category is very expansive and allows content take-downs for a broad range of reasons including defamatory or pornographic content, to IP infringements, to content threatening national security or public order (as set out in Rule 3(1)(d)).
Though the objective of the provision is laudable (i.e. to limit the circulation of violent or previously removed content), the move towards proactive automated monitoring has raised serious concerns regarding censorship on social media platforms. Rule 4(4) appears to acknowledge the deep tensions that this requirement raises with privacy and free speech concerns, as seen by the provisions that require these screening measures to be proportionate to the free speech and privacy of users, to be subject to human oversight, and reviews of automated tools to assess fairness, accuracy, propensity for bias or discrimination, and impact on privacy and security. However, given the vagueness of this wording compared to the trade-off of losing intermediary immunity, scholars and commentators are noting the obvious potential for ‘over-compliance’ and excessive screening out of content. Many (including the petitioner in the Praveen Arimbrathodiyil matter) have also noted that automated filters are not sophisticated enough to differentiate between violent unlawful images and legitimate journalistic material. The concern is that such measures could create a large-scale screening out of ‘valid’ speech and expression, with serious consequences for constitutional rights to free speech and expression which also protect ‘the rights of individuals to listen, read and receive the said speech‘ (Tata Press Ltd v. Mahanagar Telephone Nigam Ltd, (1995) 5 SCC 139).
Tighter timelines for grievance redress, content take down and information sharing with law enforcement:Rule 3 includes enhanced requirements to serve privacy policies and user agreements outlining the terms of use, including annual reminders of these terms and any modifications and of the intermediaries’ right to terminate the user’s access for using the service in contravention of these terms. The Rule also has enhanced grievance redress processes for intermediaries, by expanding these requirements to mandate that the complaints system acknowledge complaints within 24 hours, and dispose of them in 15 days. In the case of certain categories of complaints (where a person complains of inappropriate images or impersonations of them being circulated), the removal of access to the material is mandated within 24 hours based on a prima facie assessment.
Such requirements appear to be aimed at creating more user-friendly networks of intermediaries. However, the imposition of a single set of requirements is especially onerous for smaller or volunteer-run intermediary platforms which may not have income streams or staff to provide for such a mechanism. Indeed, the petition in the Praveen Arimbrathodiyil matter has challenged certain of these requirements as being a threat to the future of the volunteer-led Free and Open Source Software (FOSS) movement in India, by placing similar requirements on small FOSS initiatives as on large proprietary Big Tech intermediaries.
Other obligations that stipulate turn-around times for intermediaries include (i) a requirement to remove or disable access to content within 36 hours of receipt of a Government or court order relating the unlawful information on the intermediary’s computer resources (under Rule 3(1)(d)) and (ii) to provide information within 72 hours of receiving an order from a authorised Government agency undertaking investigative activity (under Rule 3(1)(j).
Similar to the concerns with automated screening, there are concerns that the new grievance process could lead to private entities becoming the arbiters of appropriate content/ free speech — a position that was specifically reversed in a seminal 2015 Supreme Court decision that clarified that a Government or Court order was needed for content-takedowns.
3. Key issues for the new ‘publishers’ subject to the Rules, including OTT players
3.1New Codes of Ethics and three-tier redress and oversight system for digital news media and OTT players
Digital news media and OTT players have been designated as ‘publishers of news and current affairs content’ and ‘publishers of online curated content’ respectively in Part III of the Rules. Each category has been then subjected to separate Codes of Ethics. In the case of digital news media, the Codes applicable to the newspapers and cable television have been applied. For OTT players, the Appendix sets out principles regarding content that can be created and display classifications. To enforce these codes and to address grievances from the public on their content, publishers are now mandated to set up a grievance system which will be the first tier of a three-tier “appellate” system culminating in an oversight mechanism by the Central Government with extensive powers of sanction.
Some of the key issues emerging from these Rules in Part III and the challenges to them are highlighted below.
3.2 Lack of legal authority and competence to create these Rules
There has been substantial debate on the lack of clarity regarding the legal authority of the Ministry of Electronics & Information Technology (MeitY) under the IT Act. These concerns arise at various levels.
Authority and competence to regulate ‘publishers’ of original content is unclear: The definition of ‘intermediary’ in the IT Act does not extend to cover types of entities defined to be publishers. The Rules themselves acknowledge that ‘publishers’ are a new category of regulated entity created by the Rules, as opposed to a sub-category of intermediaries. Further, the commencement of the Rules also confirm that they are passed under statutory provisions in the IT Act related to intermediary regulation. It is a well established principle that subordinate rules cannot go beyond the object and scope of parent statutory provisions (Ajoy Kumar Banerjee v Union of India (1984) 3 SCC 127). Consequently, the authority of MeitY to regulate entities that create original content – like online news sources and OTT platforms – remains unclear at best.
Ability to extend substantive provisions in other statutes through the Rules: The Rules apply two codes of conduct to digital publishers of news and current affairs content, namely (i) the Norms of Journalistic Conduct of the Press Council of India under the Press Council Act, 1978; (ii) Programme Code under section 5 of the Cable Television Networks Regulation) Act, 1995. Many, including petitioners in the LiveLaw matterhave noted that the power to make Rules under the IT Act’s s 87 cannot be used to extend or expand requirements under other statutes and their subordinate rules. To bring digital news media or OTT players into existing regulatory regimes for the Press and television broadcasting, amendments to those regimes will be required led by the Ministry of Information and Broadcasting.
Validity of three-tier ‘quasi-judicial’ adjudicatory mechanism, with final appeal to Committee of solely executive functionaries: Rules 11 – 14 create a three-tier grievance and oversight system which can be used by any person with a grievance against content published by any publisher. Under this model, any person having a grievance with any material published by a publisher can complain through the publisher’s redress process. If any grievance is not satisfactorily dealt with by the publisher entity (Level I) in 15 days, it will be escalated to the self regulatory body of which the publisher is a member (Level II) which must also provide a decision to the complainant within 15 days. If the complainant is unsatisfied, they may appeal to the Oversight Mechanism (in Level III). This can be appreciated as an attempt to create feedback loops that can minimise the spread of misleading or incendiary media, disinformation etc through a more effective grievance mechanism. The structure and design of the three-tier structure have however raised specific concerns.
First, there is a concern that Level I & II result in a privatisation of adjudications relating to free speech and expression of creative content producers – which would otherwise be litigated in Courts and Tribunals as matters of free speech. As noted by many (including the LiveLaw petition at page 33), this could have the effect of overturning judicial precedent in Shreya Singhal v. Union of India ((2013) 12 S.C.C. 73) that specifically read down s 79 of the IT Act to avoid a situation where private entities were the arbiters determining the legitimacy of takedown orders. Second, despite referring to “self-regulation” this system is subject to executive oversight (unlike the existing models for offline newspapers and broadcasting).
The Inter-Departmental Committee is entirely composed of Central Government bureaucrats, and it may review complaints through the three-tier system or referred directly by the Ministry following which it can deploy a range of sanctions from warnings, to mandating apologies, to deleting, modifying or blocking content. This also raises the question of whether this Committee meets the legal requirements for any administrative body undertaking a ‘quasi-judicial’ function, especially one that may adjudicate on matters of rights relating to free speech and privacy. Finally, while the objective of creating some standards and codes for such content creators may be laudable it is unclear whether such an extensive oversight mechanism with powers of sanction on online publishers can be validly created under the rubric of intermediary liability provisions.
4. New powers to delete, modify or block information for public access
As described at the start of this blog, the Rules add new powers for the deletion, modification and blocking of content from intermediaries and publishers. While section 69A of the IT Act (and Rules thereunder) do include blocking powers for Government, they only exist vis a vis intermediaries. Rule 15 also expands this power to ‘publishers’. It also provides a new avenue for such orders to intermediaries, outside of the existing rules for blocking information under the Information Technology (Procedure and Safeguards for Blocking for Access of Information by Public) Rules, 2009.
More grave concerns arise from Rule 16 which allows for the passing of emergency orders for blocking information, including without giving an opportunity of hearing for publishers or intermediaries. There is a provision for such an order to be reviewed by the Inter-Departmental Committee within 2 days of its issue.
Both Rule 15 and 16 apply to all entities contemplated in the Rules. Accordingly, they greatly expand executive power and oversight over digital media services in India, including social media, digital news media and OTT on-demand services.
5. Conclusions and future implications
The new Rules in India have opened up deep questions for online intermediaries and providers of digital media services serving the Indian market.
For intermediaries, this creates a difficult and even existential choice: the requirements, (especially relating to traceability and automated screening) appear to set an improbably high bar given the reality of their technical systems. However, failure to comply will result in not only the loss of a safe harbour from liability — but as seen in new Rule 7, also opens them up to punishment under the IT Act and criminal law in India.
For digital news and OTT players, the consequences of non-compliance and the level of enforcement remain to be understood, especially given open questions regarding the validity of legal basis to create these rules. Given the numerous petitions filed against these Rules, there is also substantial uncertainty now regarding the future although the Rules themselves have the full force of law at present.
Overall, it does appear that attempts to create a ‘digital media’ watchdog would be better dealt with in a standalone legislation, potentially sponsored by the Ministry of Information and Broadcasting (MIB) which has the traditional remit over such areas. Indeed, the administration of Part III of the Rules has been delegated by MeitY to MIB pointing to the genuine split in competence between these Ministries.
Finally, the potential overlaps with India’s proposed Personal Data Protection Bill (if passed) also create tensions in the future. It remains to be seen if the provisions on traceability will survive the test of constitutional validity set out in India’s privacy judgement (Justice K.S. Puttaswamy v. Union of India, (2017) 10 SCC 1). Irrespective of this determination, the Rules appear to have some dissonance with the data retention and data minimisation requirements seen in the last draft of the Personal Data Protection Bill, not to mention other obligations relating to Privacy by Design and data security safeguards. Interestingly, despite the Bill’s release in December 2019, a definition for ‘social media intermediary’ that it included in an explanatory clause to its section 26(4) closely track the definition in Rule 2(w), but also departs from it by carving out certain intermediaries from the definition. This is already resulting in moves such as Google’s plea on 2 June 2021 in the Delhi High Court asking for protection from being declared a social media intermediary.
These new Rules have exhumed the inherent tensions that exist within the realm of digital regulation between goals of the freedom of speech and expression, and the right to privacy and competing governance objectives of law enforcement (such as limiting the circulation of violent, harmful or criminal content online) and national security. The ultimate legal effect of these Rules will be determined as much by the outcome of the various petitions challenging their validity, as by the enforcement challenges raised by casting such a wide net that covers millions of users and thousands of entities, who are all engaged in creating India’s growing digital public sphere.
New FPF Report Highlights Privacy Tech Sector Evolving from Compliance Tools to Platforms for Risk Management and Data Utilization
As we enter the third phase of development of the privacy tech market, purchasers are demanding more integrated solutions, product offerings are more comprehensive, and startup valuations are higher than ever, according to a new report from the Future of Privacy Forum and Privacy Tech Alliance. These factors are leading to companies providing a wider range of services, acting as risk management platforms, and focusing on support of business outcomes.
“The privacy tech sector is at an inflection point, as its offerings have expanded beyond assisting with regulatory compliance,” said FPF CEO Jules Polonetsky. “Increasingly, companies want privacy tech to help businesses maximize the utility of data while managing ethics and data protection compliance.”
According to the report, “Privacy Tech’s Third Generation: A Review of the Emerging Privacy Tech Sector,” regulations are often the biggest driver for buyers’ initial privacy tech purchases. Organizations also are deploying tools to mitigate potential harms from the use of data. However, buyers serving global markets increasingly need privacy tech that offers data availability and control and supports its utility, in addition to regulatory compliance.
The report finds the COVID-19 pandemic has accelerated global marketplace adoption of privacy tech as dependence on digital technologies grows. Privacy is becoming a competitive differentiator in some sectors, and TechCrunch reports that 200+ privacy startups have together raised more than $3.5 billion over hundreds of individual rounds of funding.
“The customers buying privacy-enhancing tech used to be primarily Chief Privacy Officers,” said report lead author Tim Sparapani. “Now it’s also Chief Marketing Officers, Chief Data Scientists, and Strategy Officers who value the insights they can glean from de-identified customer data.”
The report highlights five trends in the privacy enhancing tech market:
Buyers desire “enterprise-wide solutions.”
Buyers favor integrated technologies.
Some vendors are moving to either collaborate and integrate or provide fully integrated solutions themselves.
Data is the enterprise asset.
Jurisdiction impacts a shared vernacular problem.
The report also draws seven implications for competition in the market:
Buyers favor integrated solutions over one-off solutions.
Collaborations, partners, cross-selling, and joint ventures between privacy tech vendors are increasing to provide buyers integrated suites of services and to attract additional market share.
Private equity and private equity-backed companies will continue their “roll-up” strategies of buying niche providers to build a package of companies to provide the integrated solutions buyers favor.
Venture capital will continue funding the privacy tech sector, though not every seller has the same level of success fundraising.
Big companies may acquire strategically valuable, niche players.
Small startups may struggle to gain market traction absent a truly novel or superb solution.
Buyers will face challenges in future-proofing their privacy strategies.
The report makes a series of recommendations, including that the industry define as a priority a common vernacular for privacy tech; set standards for technologies in the “privacy stack” such as differential privacy, homomorphic encryption, and federated learning; and explore the needs of companies for privacy tech based upon their size, sector, and structure. It calls on vendors to recognize the need to provide adequate support to customers to increase uptake and speed time from contract signing to successful integration.
The Future of Privacy Forum launched the Privacy Tech Alliance (PTA) as a global initiative with a mission to define, enhance and promote the market for privacy technologies. The PTA brings together innovators in privacy tech with customers and key stakeholders.
Members of the PTA Advisory Board, which includes Anonos, BigID, D-ID, Duality, Ethyca, Immuta, OneTrust, Privacy Analytics, Privitar, SAP, Truata, TrustArc, Wirewheel, and ZL Tech, have formed a working group to address impediments to growth identified in the report. The PTA working group will define a common vernacular and typology for privacy tech as a priority project with chief privacy officers and other industry leaders who are members of FPF. Other work will seek to develop common definitions and standards for privacy-enhancing technologies such as differential privacy, homomorphic encryption, and federated learning and identify emerging trends for venture capitalists and other equity investors in this space. Privacy Tech companies can apply to join the PTA by emailing [email protected].
Perspectives on the Privacy Tech Market
Quotes from Members of the Privacy Tech Alliance Advisory Board on the Release of the “Privacy Tech’s Third Generation” Report
“The ‘Privacy Tech Stack’ outlined by the FPF is a great way for organizations to view their obligations and opportunities to assess and reconcile business and privacy objectives. The Schrems II decision by the Court of Justice of the European Union highlights that skipping the second ‘Process’ layer can result in desired ‘Outcomes’ in the third layer (e.g., cloud processing of, or remote access to, cleartext data) being unlawful – despite their global popularity – without adequate risk management controls for decentralized processing.” — Gary LaFever, CEO & General Counsel, Anonos
“As a founding member of this global initiative, we are excited by the conclusions drawn from this foundational report – we’ve seen parallels in our customer base, from needing an enterprise-wide solution to the rich opportunity for collaboration and integration. The privacy tech sector continues to mature as does the imperative for organizations of all sizes to achieve compliance in light of the increasingly complicated data protection landscape.’’—Heather Federman, VP Privacy and Policy at BigID
“There is no doubt of the massive importance of the privacy sector, an area which is experiencing huge growth. We couldn’t be more proud to be part of the Privacy Tech Alliance Advisory Board and absolutely support the work they are doing to create alignment in the industry and help it face the current set of challenges. In fact we are now working on a similar initiative in the synthetic media space to ensure that ethical considerations are at the forefront of that industry too.” — Gil Perry, Co-Founder & CEO, D-ID
“We congratulate the Future of Privacy Forum and the Privacy Tech Alliance on the publication of this highly comprehensive study, which analyzes key trends within the rapidly expanding privacy tech sector. Enterprises today are increasingly reliant on privacy tech, not only as a means of ensuring regulatory compliance but also in order to drive business value by facilitating secure collaborations on their valuable and often sensitive data. We are proud to be part of the PTA Advisory Board, and look forward to contributing further to its efforts to educate the market on the importance of privacy-tech, the various tools available and their best utilization, ultimately removing barriers to successful deployments of privacy-tech by enterprises in all industry sectors” — Rina Shainski, Chairwoman, Co-founder, Duality
“Since the birth of the privacy tech sector, we’ve been helping companies find and understand the data they have, compare it against applicable global laws and regulations, and remediate any gaps in compliance. But as the industry continues to evolve, privacy tech also is helping show business value beyond just compliance. Companies are becoming more transparent, differentiating on ethics and ESG, and building businesses that differentiate on trust. The privacy tech industry is growing quickly because we’re able to show value for compliance as well as actionable business insights and valuable business outcomes.” — Kabir Barday, CEO, OneTrust
“Leading organizations realize that to be truly competitive in a rapidly evolving marketplace, they need to have a solid defensive footing. Turnkey privacy technologies enable them to move onto the offense by safely leveraging their data assets rapidly at scale.” — Luk Arbuckle, Chief Methodologist, Privacy Analytics
“We appreciate FPF’s analysis of the privacy tech marketplace and we’re looking forward to further research, analysis, and educational efforts by the Privacy Tech Alliance. Customers and consumers alike will benefit from a shared understanding and common definitions for the elements of the privacy stack.” — Corinna Schulze, Director, EU Government Relations, Global Corporate Affairs, SAP
“The report shines a light on the evolving sophistication of the privacy tech market and the critical need for businesses to harness emerging technologies that can tackle the multitude of operational challenges presented by the big data economy. Businesses are no longer simply turning to privacy tech vendors to overcome complexities with compliance and regulation; they are now mapping out ROI-focused data strategies that view privacy as a key commercial differentiator. In terms of market maturity, the report highlights a need to overcome ambiguities surrounding new privacy tech terminology, as well as discrepancies in the mapping of technical capabilities to actual business needs. Moving forward, the advantage will sit with those who can offer the right blend of technical and legal expertise to provide the privacy stack assurances and safeguards that buyers are seeking – from a risk, deployment and speed-to-value perspective. It’s worth noting that the growing importance of data privacy to businesses sits in direct correlation with the growing importance of data privacy to consumers. Trūata’s Global Consumer State of Mind Report 2021 found that 62% of global consumers would feel more reassured and would be more likely to spend with companies if they were officially certified to a data privacy standard. Therefore, in order to manage big data in a privacy-conscious world, the opportunity lies with responsive businesses that move with agility and understand the return on privacy investment. The shift from manual, restrictive data processes towards hyper automation and privacy-enhancing computation is where the competitive advantage can be gained and long-term consumer loyalty—and trust— can be retained.” — Aoife Sexton, Chief Privacy Officer and Chief of Product Innovation, Trūata
“As early pioneers in this space, we’ve had a unique lens on the evolving challenges organizations have faced in trying to integrate technology solutions to address dynamic, changing privacy issues in their organizations, and we believe the Privacy Technology Stack introduced in this report will drive better organizational decision-making related to how technology can be used to sustainably address the relationships among the data, processes, and outcomes.” — Chris Babel, CEO, TrustArc
“It’s important for companies that use data to do so ethically and in compliance with the law, but those are not the only reasons why the privacy tech sector is booming. In fact, companies with exceptional privacy operations gain a competitive advantage, strengthen customer relationships, and accelerate sales.” — Justin Antonipillai, Founder & CEO, Wirewheel
The right to be forgotten is not compatible with the Brazilian Constitution. Or is it?
The Brazilian Supreme Federal Court, or “STF” in its Brazilian acronym, recently took a landmark decision concerning the right to be forgotten (RTBF), finding that it is incompatible with the Brazilian Constitution. This attracted international attention to Brazil for a topic quite distant than the sadly frequent environmental, health, and political crises.
Readers should be warned that while reading this piece they might experience disappointment, perhaps even frustration, then renewed interest and curiosity and finally – and hopefully – an increased open-mindedness, understanding a new facet of the RTBF debate, and how this is playing out at constitutional level in Brazil.
This might happen because although the STF relies on the “RTBF” label, the content behind such label is quite different from what one might expect after following the same debate in Europe. From a comparative law perspective, this landmark judgment tellingly shows how similar constitutional rights play out in different legal cultures and may lead to heterogeneous outcomes based on the constitutional frameworks of reference.
How it started: insolvency seasoned with personal data
As it is well-known, the first global debate on what it means to be “forgotten” in the digital environment arose in Europe, thanks to Mario Costeja Gonzalez, a Spaniard who, paradoxically, will never be forgotten by anyone due to his key role in the construction of the RTBF.
Costeja famously requested to deindex from Google Search information about himself that he considered to be no longer relevant. Indeed, when anyone “googled” his name, the search engine provided as the top results some link to articles reporting Costeja’s past insolvency as a debtor. Costeja argued that, despite having been convicted for insolvency, he had already paid his debt with Justice and society many years before and it was therefore unfair that his name would continue to be associated ad aeternum with a mistake he made in the past.
The follow up is well known in data protection circles. The case reached the Court of Justice of the European Union (CJEU), which, in its landmark Google Spain Judgment (C-131/12), established that search engines shall be considered as data controllers and, therefore, they have an obligation to de-index information that is inappropriate, excessive, not relevant, or no longer relevant, when a data subject to whom such data refer requests it. Such an obligation was a consequence of Article 12.b of Directive 95/46 on the protection of personal data, a pre-GDPR provision that set the basis for the European conception of the RTBF, providing for the “rectification, erasure or blocking of data the processing of which does not comply with the provisions of [the] Directive, in particular because of the incomplete or inaccurate nature of the data.”
The indirect consequence of this historic decision, and the debate it generated, is that we have all come to consider the RTBF in the terms set by the CJEU. However, what is essential to emphasize is that the CJEU approach is only one possible conception and, importantly, it was possible because of the specific characteristics of the EU legal and institutional framework. We have come to think that RTBF means the establishment of a mechanism like the one resulting from the Google Spain case, but this is the result of a particular conception of the RTBF and of how this particular conception should – or could – be implemented.
The fact that the RTBF has been predominantly analyzed and discussed through the European lenses does not mean that this is the only possible perspective, nor that this approach is necessary the best. In fact, the Brazilian conception of the RTBF is remarkably different from a conceptual, constitutional, and institutional standpoint. The main concern of the Brazilian RTBF is not how a data controller might process personal data (this is the part where frustration and disappointment might likely arise in the reader) but the STF itself leaves the door open to such possibility (this is the point where renewed interest and curiosity may arise).
The Brazilian conception of the right to be forgotten
Although the RTBF has acquired a fundamental relevance in digital policy circles, it is important to emphasize that, until recently, Brazilian jurisprudence had mainly focused on the juridical need for “forgetting” only in the analogue sphere. Indeed, before the CJEU Google Spain decision, the Brazilian Supreme Court of Justice or “STJ” – the other Brazilian Supreme Court that deals with the interpretation of the Law, differently from the previously mentioned STF, which deals with the interpretation of constitutional matters – had already considered the RTBF as a right not to be remembered, affirmed by the individual vis-à-vis traditional media outlets.
This interpretation first emerged in the “Candelaria massacre” case, a gloomy page of Brazilian history, featuring a multiple homicide perpetrated in 1993 in front of the Candelaria Church, a beautiful colonial Baroque building in Rio de Janeiro’s downtown. The gravity and the particularly picturesque stage of the massacre led Globo TV, a leading Brazilian broadcaster, to feature the massacre in a TV show called Linha Direta. Importantly, the show included in the narration some details about a man suspected of being one of the perpetrators of the massacre but later discharged.
Understandably, the man filed a complaint arguing that the inclusion of his personal information in the TV show was causing him severe emotional distress, while also reviving suspects against him, for a crime he had already been discharged of many years before. In September 2013, further to Special Appeal No. 1,334,097, the STJ agreed with the plaintiff establishing the man’s “right not to be remembered against his will, specifically with regard to discrediting facts.” This is how the RTBF was born in Brazil.
Importantly for our present discussion, this interpretation is not born out of digital technology and does not impinge upon the delisting of specific type of information as results of search engine queries. In Brazilian jurisprudence the RTBF has been conceived as a general right to effectively limit the publication of certain information. The man included in the Globo reportage had been discharged many years before, hence he had a right to be “let alone,” as Warren and Brandeis would argue, and not to be remembered for something he had not even committed. The STJ, therefore, constructed its vision of the RTBF, based on article 5.X of the Brazilian Constitution, enshrining the fundamental right to intimacy and preservation of image, two fundamental features of privacy.
Hence, although they utilize the same label, the STJ and CJEU conceptualize two remarkably different rights, when they refer to the RTBF. While both conceptions aim at limiting access to specific types of personal information, the Brazilian conception differs from the EU one on at least three different levels.
First, their constitutional foundations. While both conceptions are intimately intertwined with individuals’ informational self-determination, the STJ built the RTBF based on the protection of privacy, honour and image, whereas the CJEU built it upon the fundamental right to data protection, which in the EU framework is a standalone fundamental right. Conspicuously, in the Brazilian constitutional framework an explicit right to data protection did not exist at the time of the Candelaria case and only since 2020 it has been in the process of being recognized.
Secondly, and consequently, the original goal of the Brazilian conception of the RTBF was not to regulate how a controller should process personal data but rather to protect the private sphere of the individual. In this perspective, the goal of STJ was not – and could not have been – to regulate the deindexation of specific incorrect or outdated information, but rather to regulate the deletion of “discrediting facts” so that the private life, honour and image of any individual might be illegitimately violated.
Finally, yet extremely importantly, the fact that, at the time of the decision, an institutional framework dedicated to data protection was simply absent in Brazil did not allow the STJ to have the same leeway of the CJEU. The EU Justices enjoyed the privilege of delegating to search engine the implementation of the RTBF because, such implementation would have received guidance and would have been subject to the review of a well-consolidated system of European Data Protection Authorities. At the EU level, DPAs are expected to guarantee a harmonious and consistent interpretation and application of data protection law. At the Brazilian level, a DPA has just been established in late 2020 and announced its first regulatory agenda only in late January 2021.
This latter point is far from trivial and, in the opinion of this author, an essential preoccupation that might have driven the subsequent RTBF conceptualization of the STJ.
The stress-test
The soundness of the Brazilian definition of the RTBF, however, was going to be tested again by the STJ, in the context of another grim and unfortunate page of Brazilian story, the Aida Curi case. This case originated with the sexual assault and subsequent homicide of the young Aida Curi, in Copacabana, Rio de Janeiro, on the evening of 14 July 1958. At the time the case crystallized considerable media attention, not only because of its mysterious circumstances and the young age of the victim, but also because the sexual assault perpetrators tried to dissimulate it by throwing the body of the victim from the rooftop of a very high building on the Avenida Atlantica, the fancy avenue right in front of the Copacabana beach.
Needless to say, Globo TV considered the case as a perfect story for yet another Linha Direta episode. Aida Curi’s relatives, far from enjoying the TV show, sued the broadcaster for moral damages and demanded the full enjoyment of their RTBF – in the Brazilian conception, of course. According to the plaintiffs, it was indeed not conceivable that, almost 50 years after the murder, Globo TV could publicly broadcast personal information about the victim – and her family – including the victim’s name and address, in addition to unauthorized images, thus bringing back a long-closed and extremely traumatic set of events.
The brothers of Aida Curi claimed reparation against Rede Globo, but the STJ, decided that the time passed was enough to mitigate the effects of anguish and pain on the dignity of Aida Curi’s relatives, while arguing that it was impossible to report the events without mentioning the victim. This decision was appealed by Ms Curi’s family members, who demanded by means of Extraordinary Appeal No. 1,010,606, that STF recognized “their right to forget the tragedy.” It is interesting to note that the way the demand is constructed in this Appeal exemplifies tellingly the Brazilian conception of “forgetting” as erasure and prohibition from divulgation.
At this point, the STF identified in the Appeal the interest of debating the issue “with general repercussion” which is a peculiar judicial process that the Court can utilize when recognizes that a given case has particular relevance and transcendence for the Brazilian legal and judicial system. Indeed, the decision of a case with general repercussion does not only bind the parties but rather establishes a jurisprudence that must be replicated by all lower-level courts.
In February 2021, the STF finally deliberated on the Aida Curi case, establishing that “the idea of a right to be forgotten is incompatible with the Constitution, thus understood as the power to prevent, due to the passage of time, the disclosure of facts or data that are true and lawfully obtained and published in analogue or digital media” and that “any excesses or abuses in the exercise of freedom of expression and information must be analyzed on a case-by-case basis, based on constitutional parameters – especially those relating to the protection of honor, image, privacy and personality in general – and the explicit and specific legal provisions existing in the criminal and civil spheres.”
In other words, what the STF has deemed as incompatible with the Federal Constitution is a specific interpretation of the Brazilian version of the RTBF. What is not compatible with the Constitution is to argue that the RTBF allows to prohibit publishing true facts, lawfully obtained. At the same time, however, the STF clearly states that it remains possible for any Court of law to evaluate, on a case-by-case basis and according to constitutional parameters and existing legal provisions, if a specific episode can allow the use of the RTBF to prohibit the divulgation of information that undermine the dignity, honour, privacy, or other fundamental interests of the individual.
Hence, while explicitly prohibiting the use of the RTBF as a general right to censorship, the STF leaves room for the use of the RTBF for delisting specific personal data in an EU-like fashion, while specifying that this must be done finding guidance in the Constitution and the Law.
What next?
Given the core differences between the Brazilian and EU conception of the RTBF, as highlighted above, it is understandable in the opinion of this author that the STF adopted a less proactive and more conservative approach. This must be especially considered in light of the very recent establishment of a data protection institutional system in Brazil.
It is understandable that the STF might have preferred to de facto delegate the interpretation of when and how the RTBF could be rightfully invoked before Courts, according to constitutional and legal parameters. First, in the Brazilian interpretation of the RTBF, this right fundamentally insist on the protection of privacy – i.e. the private sphere of an individual – and, while admitting the existence of data protection concerns, these are not the main ground on which the Brazilian RTBF conception relays.
It is understandable that in a country and a region where the social need to remember and shed light on what happened in a recent history, marked by dictatorships, well-hidden atrocities, and opacity, outweighs the legitimate individual interest to prohibit the circulation of truthful and legally obtained information. In the digital sphere, however, the RTBF quintessentially translates into an extension of informational self-determination, which the Brazilian General Data Protection Law, better known as “LGPD” (Law No. 13.709 / 2018), enshrines in its article 2 as one of the “foundations” of data protection in the country and that whose fundamental character was recently recognized by the STF itself.
In this perspective, it is useful to remind the dissenting opinion of Justice Luiz Edson Fachin, in the Aida Curi case, stressing that “although it does not expressly name it, the Constitution of the Republic, in its text, contains the pillars of the right to be forgotten, as it celebrates the dignity of the human person (article 1, III), the right to privacy (article 5, X) and the right to informational self-determination – which was recognized, for example, in the disposal of the precautionary measures of the Direct Unconstitutionality Actions No. 6,387, 6,388, 6,389, 6,390 and 6,393, under the rapporteurship of Justice Rosa Weber (article 5, XII).”
It is the opinion of this author that the Brazilian debate on the RTBF in the digital sphere would be clearer if it its dimension as a right to deindexation of search engines results were to be clearly regulated. It is understandable that the STF did not dare regulating this, given its interpretation of the RTBF and the very embryonic data protection institutional framework in Brazil. However, given the increasing datafication we are currently witnessing, it would be naïve not to expect that further RTBF claims concerning the digital environment and, specifically, the way search engines process personal data will keep emerging.
The fact that the STF has left the door open to apply the RTBF in the case-by-case analysis of individual claims may reassure the reader regarding the primacy of constitutional and legal arguments in such case-by-case analysis. It may also lead the reader to – very legitimately – wonder whether such a choice is the facto the most efficient to deal with the potentially enormous number of claims and in the most coherent way, given the margin of appreciation and interpretation that each different Court may have.
An informed debate able to clearly highlight what are the existing options and what might be the most efficient and just ways to implement them, considering the Brazilian context, would be beneficial. This will likely be one of the goals of the upcoming Latin American edition of the Computers, Privacy and Data Protection conference (CPDP LatAm) that will take place in July, entirely online, and will aim at exploring the most pressing issues for Latin American countries regarding privacy and data protection.
If you have any questions about engaging with The Future of Privacy Forum on Global Privacy and Digital Policymaking contact Dr. Gabriela Zanfir-Fortuna, Senior Counsel, at [email protected].
FPF announces appointment of Malavika Raghavan as Senior Fellow for India
The Future of Privacy Forum announces the appointment of Malavika Raghavan as Senior Fellow for India, expanding our Global Privacy team to one of the key jurisdictions for the future of privacy and data protection law.
Malavika is a thought leader and a lawyer working on interdisciplinary research, focusing on the impacts of digitisation on the lives of lower-income individuals. Her work since 2016 has focused on the regulation and use of personal data in service delivery by the Indian State and private sector actors. She has founded and led the Future of Finance Initiative for Dvara Research (an Indian think tank) in partnership with the Gates Foundation from 2016 until 2020, anchoring its research agenda and policy advocacy on emerging issues at the intersection of technology, finance and inclusion. Research that she led at Dvara Research was cited by the India’s Data Protection Committee in its White Paper as well as its final report with proposals for India’s draft Personal Data Protection Bill, with specific reliance placed on such research on aspects of regulatory design and enforcement. See Malavika’s full bio here.
“We are delighted to welcome Malavika to our Global Privacy team. For the following year, she will be our adviser to understand the most significant developments in privacy and data protection in India, from following the debate and legislative process of the Data Protection Bill and the processing of non-personal data initiatives, to understanding the consequences of the publication of the new IT Guidelines. India is one of the most interesting jurisdictions to follow in the world, for many reasons: the innovative thinking on data protection regulation, the potentially groundbreaking regulation of non-personal data and the outstanding number of individuals whose privacy and data protection rights will be envisaged by these developments, which will test the power structures of digital regulation and safeguarding fundamental rights in this new era”, said Dr. Gabriela Zanfir-Fortuna, Global Privacy lead at FPF.
We have asked Malavika to share her thoughts for FPF’s blog on what are the most significant developments in privacy and digital regulation in India and about India’s role in the global privacy and digital regulation debate.
FPF: What are some of the most significant developments in the past couple of years in India in terms of data protection, privacy, digital regulation?
Malavika Raghavan: “Undoubtedly, the turning point for the privacy debate India was the 2017 judgement of the Indian Supreme Court in Justice KS Puttaswamy v Union of India. The judgment affirmed the right to privacy as a constitutional guarantee, protected by Part III (Fundamental Rights) of the Indian Constitution. It was also regenerative, bringing our constitutional jurisprudence into the 21st century by re-interpreting timeless principles for the digital age, and casting privacy as a prerequisite for accessing other rights—including the right to life and liberty, to freedom of expression and to equality—given the ubiquitous digitisation of human experience we are witnessing today.
Overnight, Puttaswamy also re-balanced conversations in favour of privacy safeguards to make these equal priorities for builders of digital systems, rather than framing these issues as obstacles to innovation and efficiency. In addition, it challenged the narrative that privacy is an elite construct that only wealthy or privileged people deserve— since many litigants in the original case that had created the Puttaswamy reference were from marginalised groups. Since then, a string of interesting developments have arisen as new cases are reassessing the impact of digital technology on individuals in India, for e.g. the boundaries case of private sector data sharing (such as between Whatsapp and Facebook), or the State’s use of personal data (as in the case concerning Aadhaar, our national identification system) among others.
Puttaswamy also provided fillip for a big legislative development, which is the creation of an omnibus data protection law in India. A bill to create this framework was proposed by a Committee of Experts under the chairmanship of Justice Srikrishna (an ex-Supreme Court judge), which has been making its way through ministerial and Parliamentary processes. There’s a large possibility that this law will be passed by the Indian parliament in 2021! Definitely a big development to watch.
FPF: How do you see India’s role in the global privacy and digital regulation debate?
Malavika Raghavan: “India’s strategy on privacy and digital regulation will undoubtedly have global impact, given that India is home to 1/7th of the world’s population! The mobile internet revolution has created a huge impact on our society with millions getting access to digital services in the last couple of decades. This has created nuanced mental models and social norms around digital technologies that are slowly being documented through research and analysis.
The challenge for policy makers is to create regulations that match these expectations and the realities of Indian users to achieve reasonable, fair regulations. As we have already seen from sectoral regulations (such as those from our Central Bank around cross border payments data flows) such regulations also have huge consequences for global firms interacting with Indian users and their personal data.
In this context, I think India can have the late-mover advantage in some ways when it comes to digital regulation. If we play our cards right, we can take the best lessons from the experience of other countries in the last few decades and eschew the missteps. More pragmatically, it seems inevitable that India’s approach to privacy and digital regulation will also be strongly influenced by the Government’s economic, geopolitical and national security agenda (both internationally and domestically).
One thing is for certain: there is no path-dependence. Our legislators and courts are thinking in unique and unexpected ways that are indeed likely to result in a fourth way (as described by the Srikrishna Data Protection Committee’s final report), compared to the approach in the US, EU and China.”
If you have any questions about engaging with The Future of Privacy Forum on Global Privacy and Digital Policymaking contact Dr. Gabriela Zanfir-Fortuna, Senior Counsel, at [email protected].
India: Massive overhaul of digital regulation, with strict rules for take-down of illegal content and Automated scanning of online content
On February 25, the Indian Government notified and published Information Technology (Guidelines for Intermediaries and Digital media Ethics Code) Rules 2021. These rules mirror the Digital Services Act (DSA) proposal of the EU to some extent, since they propose a tiered approach based on the scale of the platform, they touch on intermediary liability, content moderation, take-down of illegal content from online platforms, as well as internal accountability and oversight mechanisms, but they go beyond such rules by adding a Code of Ethics for digital media, similar to the Code of Ethics classic journalistic outlets must follow, and by proposing an “online content” labelling scheme for content that is safe for children.
The Code of Ethics applies to online news publishers, as well as intermediaries that “enable the transmission of news and current affairs”. This part of the Guidelines (the Code of Ethics) has already been challenged in the Delhi High Court by news publishers this week.
The Guidelines have raised several types of concerns in India, from their impact on freedom of expression, impact on the right to privacy through the automated scanning of content and the imposed traceability of even end-to-end encrypted messages so that the originator can be identified, to the choice of the Government to use executive action for such profound changes. The Government, through the two Ministries involved in the process, is scheduled to testify in the Standing Committee of Information Technology of the Parliament on March 15.
New obligations for intermediaries
“Intermediaries” include “websites, apps and portals of social media networks, media sharing websites, blogs, online discussion forums, and other such functionally similar intermediaries” (as defined in rule 2(1)(m)).
Here are some of the most important rules laid out in Part II of the Guidelines, dedicated to Due Diligence by Intermediaries:
All intermediaries, regardless of size or nature, will be under an obligation to “remove or disable access” as early as possible and no later than 36 hours of content subject to a Court order or an order of a Government agency (see rule 4(1)(d)).
All intermediaries will be under an obligation to inform users at least once per year about their content policies, which must at a minimum include rules such as not uploading, storing or sharing information that “belongs to another person and to which the user does not have any right”, “deceives or misleads the addressee about the origin of the message”, “is patently false and untrue” or “is harmful to minors” (see rules 4(1)(b) and (f)).
All intermediaries will have to provide information to authorities for the purpose of identity verification and for investigating and prosecuting offenses, within 72 hours of receiving an order from an authorised government agency (see rule 4(1)(j)).
All intermediaries will have to take all measures to remove or limit accesswithin 24 hours of receiving a complaint from a user, to any content that reveals nudity, amounts to sexual harassment, or represents a deep fake, and the content is transmitted with the intent to harass, intimidate, threaten or abuse an individual (see rule 4(1)(p)).
“Significant social media intermediaries” have enhanced obligations
“Significant social media intermediaries” are social media services with a number of users above a threshold which will be defined and notified by the Central Government. This concept is similar to the the DSA’s “Very Large Online Platform”, however the DSA includes clear criteria in the proposed act itself on how to identify a VLOP.
As for Significant Social Media Intermediaries” in India, they will have additional obligations (similar to how the DSA proposal in the EU scales obligations):
“Significant social media intermediaries” that provide messaging services will be under an obligation to identify the “first originator” of a message following a Court order or an order from a Competent Authority (see rule 5(2)). This provision raises significant concerns over end-to-end encryption and encryption backdoors.
They will have to appoint a Chief Compliance Officer for the purposes of complying with these rules and who will be liable for failing to ensure that the intermediary observes due diligence obligations; the CCO will have to hold an Indian passport and will have to be based in India;
They will have to appoint a Chief Grievance Officer, who also must be based in India.
Publish compliance reports every 6 months.
Deploy automated scanning to proactively identify all identical information to content removed following an order (under the 36 hours rule), as well as child sexual abuse and related content (see rule 5(4)).
Set up an internal mechanism for receiving complaints.
These “Guidelines” seem to have the legal effect of a statute, and they are being adopted through executive action to replace Guidelines adopted in 2011 by the Government, under powers conferred to it in the Information Technology Act 2000. The new Guidelines would enter into force immediately after publication in the Official Gazette (no information as to when publication is scheduled). The Code of Ethics would enter into force three months after the publication in the Official Gazette. As mentioned above, there are already some challenges in Court against part of these rules.
This analysis by Rahul Matthan, who raises questions with regard to “identifying the first originator” rule, arguing that it is likely the Indian Supreme Court would declare such a measure unconstitutional: “Traceability is Antithetical to Liberty”.
Another jurisdiction to keep your eyes on: Australia
Also note that, while the European Union is starting its heavy and slow legislative machine, by appointing Rapporteurs in the European Parliament and having first discussions on the DSA proposal in the relevant working group of the Council, another country is set to soon adopt digital content rules: Australia. The Government is currently considering an Online Safety Bill, which was open to public consultation until mid February and which would also include a “modernised online content scheme”, creating new classes of harmful online content, as well as take-down requirements for image-based abuse, cyber abuse and harmful content online, requiring removal within 24 hours of receiving a notice from the eSafety Commissioner.
If you have any questions about engaging with The Future of Privacy Forum on Global Privacy and Digital Policymaking contact Dr. Gabriela Zanfir-Fortuna, Senior Counsel, at [email protected].
Russia: New Law Requires Express Consent for Making Personal Data Available to the Public and for Any Subsequent Dissemination
Authors: Gabriela Zanfir-Fortuna and Regina Iminova
Source: Pixabay.Com, by Opsa
Amendments to the Russian general data protection law (Federal Law No. 152-FZ on Personal Data) adopted at the end of 2020 enter into force today (Monday, March 1st), with some of them having the effective date postponed until July 1st. The changes are part of a legislative package that is also seeing the Criminal Code being amended to criminalize disclosure of personal data about “protected persons” (several categories of government officials). The amendments to the data protection law envision the introduction of consent based restrictions for any organization or individual that publishes personal data initially, as well as for those that collect and further disseminate personal data that has been distributed on the basis of consent in the public sphere, such as on social media, blogs or any other sources.
The amendments:
introduce a new category of personal data, defined as “personal data allowed by the data subject to be disseminated” (hereinafter PDD – personal data allowed for dissemination);
include strict rules for initially making personal data available to an unlimited number of persons, but also for further processing PDD by other organizations or individuals, including for further disseminating this type of data – all of this must be done on the basis of specific, affirmative and separately collected consent from the data subject, the existence of which must be proved at any point of the use and further use;
introduce the possibility of the Russian regulator enforcing this law (“Roskomnadzor”) to record in a centralized information system the consent obtained for dissemination of personal data to an unlimited number of persons;
introduce an absolute right to opt out of the dissemination of personal data, “at any time”.
The potential impact of the amendments is broad. The new law prima facie affects social media services, online publishers, streaming services, bloggers, or any other entity who might be considered as making personal data available to “an indefinite number of persons.” They now have to collect and prove they have separate consent for making personal data publicly available, as well as for further publishing or disseminating PDD which has been lawfully published by other parties originally.
Importantly, the new provisions in the Personal Data Law dedicated to PDD do not include any specific exception for processing PDD for journalistic purposes. The only exception recognized is processing PDD “in the state and public interests defined by the legislation of the Russian Federation”. The Explanatory Note accompanying the amendments confirms that consent is the exclusive lawful ground that can justify dissemination and further processing of PDD and that the only exception to this rule is the one mentioned above, for state or public interests as defined by law. It is thus expected that the amendments might create a chilling effect on freedom of expression, especially when also taking into account the corresponding changes to the Criminal Code.
The new rules seem to be part of a broader effort in Russia to regulate information shared online and available to the public. In this context, it is noteworthy that other amendments to Law 149-FZ on Information, IT and Protection of Information solely impacting social media services were also passed into law in December 2020, and already entered into force on February 1st, 2021. Social networks are now required to monitor content and “restrict access immediately” of users that post information about state secrets, justification of terrorism or calls to terrorism, pornography, promoting violence and cruelty, or obscene language, manufacturing of drugs, information on methods to commit suicide, as well as calls for mass riots.
Below we provide a closer look at the amendments to the Personal Data Law that entered into force on March 1st, 2021.
A new category of personal data is defined
The new law defines a category of “personal data allowed by the data subject to be disseminated” (PDD), the definition being added as paragraph 1.1 to Article 3 of the Law. This new category of personal data is defined as “personal data to which an unlimited number of persons have access to, and which is provided by the data subject by giving specific consent for the dissemination of such data, in accordance with the conditions in the Personal Data Law” (unofficial translation).
The old law had a dedicated provision that referred to how this type of personal data could be lawfully processed, but it was vague and offered almost no details. In particular, Article 6(10) of the Personal Data Law (the provision corresponding to Article 6 GDPR on lawful grounds for processing) provided that processing of personal data is lawful when the data subject gives access to their personal data to an unlimited number of persons. The amendments abrogate this paragraph, before introducing an entirely new article containing a detailed list of conditions for processing PDD only on the basis of consent (the new Article 10.1).
Perhaps in order to avoid misunderstanding on how the new rules for processing PDD fit with the general conditions on lawful grounds for processing personal data, a new paragraph 2 is introduced in Article 10 of the law, which details conditions for processing special categories of personal data, to clarify that processing of PDD “shall be carried out in compliance with the prohibitions and conditions provided for in Article 10.1 of this Federal Law”.
Specific, express, unambiguous and separate consent is required
Under the new law, “data operators” that process PDD must obtain specific and express consent from data subjects to process personal data, which includes any use, dissemination of the data. Notably, under the Russian law, “data operators” designate both controllers and processors in the sense of the General Data Protection Regulation (GDPR), or businesses and service providers in the sense of the California Consumer Privacy Act (CCPA).
Specifically, under Article 10.1(1), the data operator must ensure that it obtains a separate consent dedicated to dissemination, other than the general consent for processing personal data or other type of consent. Importantly, “under no circumstances” may individuals’ silence or inaction be taken to indicate their consent to the processing of their personal data for dissemination, under Article 10.1(8).
In addition, the data subject must be provided with the possibility to select the categories of personal data which they permit for dissemination. Moreover, the data subject also must be provided with the possibility to establish “prohibitions on the transfer (except for granting access) of [PDD] by the operator to an unlimited number of persons, as well as prohibitions on processing or conditions of processing (except for access) of these personal data by an unlimited number of persons”, per Article 10.1(9). It seems that these prohibitions refer to specific categories of personal data provided by the data subject to the operator (out of a set of personal data, some categories may be authorized for dissemination, while others may be prohibited from dissemination).
If the data subject discloses personal data to an unlimited number of persons without providing to the operator the specific consent required by the new law, not only the original operator, but all subsequent persons or operators that processed or further disseminated the PDD have the burden of proof to “provide evidence of the legality of subsequent dissemination or other processing”, under Article 10.1(2), which seems to imply that they must prove consent was obtained for dissemination (probatio diabolica in this case). According to the Explanatory Note to the amendments, it seems that the intention was indeed to turn the burden of proof of legality of processing PDD from data subjects to the data operators, since the Note makes a specific reference to the fact that before the amendments the burden of proof rested with data subjects.
If the separate consent for dissemination of personal data is not obtained by the operator, but other conditions for lawfulness of processing are met, the personal data can be processed by the operator, but without the right to distribute or disseminate them – Article 10.1.(4).
A Consent Management Platform for PDD, managed by the Roskomnadzor
The express consent to process PDD can be given directly to the operator or through a special “information system” (which seems to be a consent management platform) of the Roskomnadzor, according to Article 10.1(6). The provisions related to setting up this consent platform for PDD will enter into force on July 1st, 2021. The Roskomnadzor is expected to provide technical details about the functioning of this consent management platform and guidelines on how it is supposed to be used in the following months.
Absolute right to opt-out of dissemination of PDD
Notably, the dissemination of PDD can be halted at any time, on request of the individual, regardless of whether the dissemination is lawful or not, according to Article 12.1(12). This type of request is akin to a withdrawal of consent. The provision includes some requirements for the content of such a request. For instance, it requires writing contact information and listing the personal data that should be terminated. Consent to the processing of the provided personal data is terminated once the operator receives the opt-out request – Article 10.1(13).
A request to opt-out of having personal data disseminated to the public when this is done unlawfully (without the data subject’s specific, affirmative consent) can also be made through a Court, as an alternative to submitting it directly to the data operator. In this case, the operator must terminate the transmission of or access to personal data within three business days from when such demand was received or within the timeframe set in the decision of the court which has come into effect – Article 10.1(14).
A new criminal offense: The prohibition on disclosure of personal data about protected persons
Sharing personal data or information about intelligence officers and their personal property is now a criminal offense under the new rules, which amended the Criminal Code. The law obliges any operators of personal data, including government departments and mobile operators, to ensure the confidentiality of personal information concerning protected persons, their relatives, and their property. Under the new law, “protected persons” include employees of the Investigative Committee, FSB, Federal Protective Service, National Guard, Ministry of Internal Affairs, and Ministry of Defense judges, prosecutors, investigators, law enforcement officers and their relatives. Moreover, the list of protected persons can be further detailed by the head of the relevant state body in which the specified persons work.
Previously, the law allowed for the temporary prohibition of the dissemination of personal data of protected persons only in the event of imminent danger in connection with official duties and activities. The new amendments make it possible to take protective measures in the absence of a threat of encroachment on their life, health and property.
What to watch next: New amendments to the general Personal Data Law are on their way in 2021
There are several developments to follow in this fast changing environment. First, at the end of January, the Russian President gave the government until August 1 to create a set of rules for foreign tech companies operating in Russia, including a requirement to open branch offices in the country.
Second, a bill (No. 992331-7) proposing new amendments to the overall framework of the Personal Data Law (No. 152-FZ) was introduced in July 2020 and was the subject of a Resolution that passed in the State Duma on February 16, allowing for a period for amendments to be submitted, until March 16. The bill is on the agenda for a potential vote in May. The changes would entail expanding the possibility to obtain valid consent through other unique identifiers which are currently not accepted by the law, such as unique online IDs, changes to purpose limitation, a possible certification scheme for effective methods to erase personal data and new competences for the Roskomnadzor to establish requirements for deidentification of personal data and specific methods for effective deidentification.
If you have any questions on Global Privacy and Data Protection developments, contact Gabriela Zanfir-Fortuna at [email protected]
Colorado Revises Its AI Act: What Changed and Why
On May 15, Governor Polis signed SB 189, revising the Colorado AI Act (CAIA) after two years of intense negotiations and national debate over the original 2024 law’s approach to AI regulation. The revised law, the Colorado ADM Act (CADMA), reflects a fundamental shift in approach: shifting from an algorithmic discrimination framework to a transparency-focused one, as well as narrowing the scope of covered AI systems, streamlining disclosures and consumer rights, and replacing governance requirements with liability allocation under existing anti-discrimination laws.
This post examines the key changes between CAIA and CADMA, explores the context that drove these revisions, and analyzes their practical implications. Side-by-side legislative comparison chart below.
Regulates developers and deployers of covered automated decision-making technologies (ADMT) used for making consequential decisions regarding covered domains (e.g., education, employment, financial or lending)
Requires developers to provide deployers a general statement that includes information regarding the covered ADMT.
Requires deployers to disclose to consumers use of covered ADMT for consequential decisions prior to use.
Requires deployers to notify consumers whether and to what extent a covered ADMT contributed to a consequential decision if an adverse decision is reached.
Provides consumers certain rights if an adverse decision is reached pursuant to deployers’ use of a covered ADMT, including rights of explanation, correction, and appeal.
Clarifies that developers and deployers are subject to existing anti-discrimination law, while developers’ liability is limited to intended use of covered ADMT.
The law will be enforced by the Colorado Attorney General (AG), with no private right of action, and go into effect January 1, 2027.
From Anti-Discrimination Governance to Transparency
Enacted in 2024, Colorado SB 205 (Colorado AI Act) (CAIA) aimed to mitigate risks of discriminatory outcomes from AI-driven decisions in consequential domains by regulating how such systems are developed and deployed. The law subjected developers and deployers to a duty of care to protect consumers from algorithmic discrimination, with such duty presumptively fulfilled if the developer or deployer complied with the Act’s requirements. For developers, those requirements included: disclosing information to deployers regarding known limitations, possible biases, and risk mitigation measures; making publicly available information regarding high-risk AI systems and known or foreseeable risks of algorithmic discrimination; and notifying the state AG upon discovery that a high-risk AI system caused algorithmic discrimination. For deployers, those requirements included: maintaining a risk management policy and program to identify and mitigate the risk of algorithmic discrimination; annually conducting impact assessments on high-risk AI systems; publicly disclosing information regarding high-risk AI use and how known or foreseeable risks of algorithmic discrimination were managed; and also notifying the state AG upon discovery of algorithmic discrimination. See full overview of requirements in FPF’s Colorado AI Act Policy Brief(2024).
CADMA eliminates CAIA’s governance requirements and references to algorithmic discrimination, focusing instead on transparency. Where risk is mentioned, it refers only to undefined “known risks” or “known limitations” rather than discrimination-specific concerns. Key areas of this shift include:
Removal of the duty of care to mitigate algorithmic discrimination;
Removal of algorithmic discrimination incident reporting;
Removal of risk management and impact assessments regarding algorithmic discrimination; and
Narrowing of transparency requirements and removal of disclosing bias-related information, now only “known limitations”;
Why the Change: Upon signature of the original CAIA, Governor Polis expressed reservations about its potential to “tamper innovation and deter competition.” The law faced criticism from some industry groups who argued that compliance costs would disproportionately burden small businesses lacking resources for comprehensive governance programs, while other commentators contended the law reflected ideological priorities, which was later reflected in a constitutional challenge against the law by xAI. Meanwhile, a deregulatory shift in the 2025 legislative landscape, and other states failing to enact comparable AI laws, left Colorado as an outlier.
Nonetheless, a coalition of labor, consumer, civil rights, privacy, and public interest groups continued to support the law, emphasizing the need to protect consumers when AI systems shape critical life and career decisions. After failed negotiations in 2025, Polis convened a working group to develop revisions balancing consumer protection with reduced compliance burdens.
Changes in Scope
CADMA regulates “covered automated decision-making technology” (ADMT), defined as technology that processes personal data and is used to materially influence consequential decisions. In contrast, CAIA regulated “high-risk AI systems” that were a substantial factor in, or are capable of altering, consequential decisions. Although this change was likely intended to streamline coverage, CADMA’s scope is not easily characterized as simply narrower or broader than CAIA’s. It may apply to a narrower set of technologies, but its definition of “consequential decision” may be broader and its exceptions differ from CAIA’s.
Covered Technologies: CADMA narrows the scope of covered technologies through two requirements: systems must process personal data and actually be used to “materially influence” decisions—contrasting with CAIA’s lower bar of being a “substantial factor” or merely capable of altering outcomes.
Covered Decisions / Domains: Both versions address the same domains (employment, housing, education, etc.), but CADMA may broaden coverage by: (1) lowering the impact threshold—decisions need only “relate to” a covered domain, rather than have a “material, legal, or similarly significant effect” as under CAIA; and (2) expanding decision types beyond CAIA’s “provision or denial of, or cost or terms of” to include “delay” and “alteration.” However, CADMA narrows employment coverage to hiring decisions only, whereas CAIA applied to a broader set of employment decisions.
Exemptions: CADMA does not include CAIA’s small deployer exemption. It retains most other CAIA exemptions but removes AI-enabled video games, public interest research, and entities subject to federal standards or contracts. It also narrows CAIA’s broad exemption for legal compliance and investigations to cover only anti-terrorism and money laundering activities. Notably, CADMA adds a new exemption for advertising, which CAIA would have covered under decisions regarding “access to” consequential domains.
Why the Change: The scope changes appear to reflect competing pressures. The higher technology threshold aligns with Governor Polis’s stated streamlining goals, while the broader decision definitions and fewer exemptions may reflect consumer advocates’ push to maintain protective scope. The language shifts may also reflect a change in authorship. Senator Rodriguez’s CAIA borrowed heavily from data privacy law—using “material, legal, or similarly significant effect” from the Colorado Privacy Act and including standard privacy law exemptions. CADMA’s drafting by the Governor’s office moved away from this privacy framework terminology and approach.
Narrowing employment coverage to hiring decisions also likely represents a compromise between industry and advocates–preserving protections for one of the highest-stakes employment decisions while substantially reducing the compliance footprint for ongoing employee management systems.
Streamlining Disclosures and Consumer Rights
CADMA maintains three of CAIA’s transparency requirements regarding covered systems, though in narrower form. However, it removes CAIA’s general disclosure requirement regarding any consumer-facing AI system.
Developers to Deployers: Developers must still provide information to deployers regarding the covered ADMT, though narrowed from CAIA’s “disclosures and documentation” to a general statement regarding the ADMT’s use, limitations, and monitoring.
Deployers to Consumers (Pre-Use): Deployers must still provide information to consumers prior to ADMT use, but CADMA narrows the upfront disclosure to only a statement that ADMT is being used and instructions for obtaining additional information. Details about the system’s purpose and the nature of the decision are required only when the ADMT produces an adverse outcome.
Deployers to Consumers (Post-Adverse Decision): If an adverse decision is reached pursuant to covered ADMT use, deployers must provide consumers a plain language description of the consequential decision and the role the covered ADMT played, instructions on how to request additional information, and an explanation of their rights.
Similarly, CADMA largely maintains the CAIA’s consumer rights (e.g., right to explanation, correction, and appeal) but limits them to instances of adverse decisions. Consumers must be able to request the name of the covered ADMT, the inputs used, and the categories and sources of personal information used; they must be provided the opportunity to correct any inaccurate personal data used by the covered ADMT pursuant to the Colorado Privacy Act (CPA); and they must be provided an opportunity for meaningful human review and reconsideration, to the extent commercially reasonable. Notably, deployers would only need to inform consumers of their existing rights under the CPA when an adverse decision is reached (despite the CPA not containing such limitation). Unlike the CAIA, it does not appear that deployers must respond to consumer requests in a specific time period.
Additionally, while not detailed here, CADMA includes sections regarding when notices under other laws, such as FERPA, satisfy these requirements. Developers and deployers must maintain necessary recordkeeping to demonstrate compliance for at least three years. The state AG may conduct rulemaking on the post-adverse disclosures and consumer rights.
Why the Change: The streamlined transparency requirements and consumer rights reflect Governor Polis’s goals for reduced compliance burdens for small businesses. Nonetheless, retaining these provisions, even in streamlined form, preserves two features: disclosure that enables anti-discrimination claims (discussed below) and universal application to entities of all sizes and sectors, unlike privacy laws that exempt smaller companies and government agencies through threshold requirements.
CADMA explicitly permits compliance with consent requirements through other regulatory frameworks like FERPA and FCRA, likely responding to regulated entities’ desire to integrate AI obligations into existing processes.
From Prescriptive Compliance to Discrimination Liability
The liability framework represents one of CADMA’s most fundamental departures from CAIA. CAIA established a statutory duty of care: compliance with the Act’s breadth of governance, transparency, and consumer rights requirements created a rebuttable presumption that developers and deployers had fulfilled their obligations. Noncompliance exposed entities to AG enforcement, though defendants could assert an affirmative defense by demonstrating they had cured the violation and adopted a recognized risk management framework, such as NIST’s AI RMF. Courts would ultimately assess whether an entity’s conduct was “reasonable” under the duty of care—functionally applying a negligence standard. Importantly, CAIA did not displace liability under existing anti-discrimination statutes, though compliance documentation likely would have served as evidence in both CAIA enforcement actions and parallel discrimination claims.
In contrast, CADMA eliminates the duty of care framework and most governance requirements, making entities primarily liable for transparency and consumer rights violations. Noncompliance triggers AG enforcement, though entities receive a 60-day cure period before penalties attach. CADMA replaces CAIA’s algorithmic discrimination controls by clarifying that existing anti-discrimination law applies to developers and deployers of covered ADMT. However, developers may not be liable if a deployer uses their ADMT in a manner unintended by the developer. CADMA also restricts indemnification, where deployers cannot contractually shift liability to developers.
In practice, this means entities face narrower compliance obligations under CADMA with a 60-day cure opportunity before penalties. However, navigating the courts may become less predictable without prescribed controls to establish “reasonableness” or safe harbors. Additionally, the “intended use” standard for discrimination liability, alongside the indemnification prohibition, makes documentation critical: developers need clear specifications about proper deployment, while deployers must demonstrate they followed those specifications or accept liability for misuse.
Why the Change: The shift from prescriptive controls to liability allocation reflects different regulatory philosophies: whether the state should mandate specific compliance measures or allow market-driven risk management with ex post liability. Organizations with low risk tolerance and substantial resources may prefer detailed upfront requirements that clearly define regulatory expectations and enable comprehensive compliance mapping. But resource-constrained entities with higher risk tolerance, such as startups, may prefer ambiguity: they may rather risk case-by-case adjudication than invest scarce resources in compliance with prescriptive frameworks that may not materialize into actual liability.
This tension manifests as a choice between legislative prescription and judicial development. CAIA’s approach—detailed governance requirements that created a presumption of compliance—favored entities seeking regulatory certainty. CADMA’s approach—limited transparency and general applicability of existing law with liability determined through enforcement or litigation—favors entities preferring to allocate resources to growth rather than preemptive compliance. Given Governor Polis’s emphasis on reducing burdens for startups and innovation-focused businesses, CADMA adopted the latter approach.
Conclusion
After two years of contentious debate and revision, Colorado’s AI regulation has finally reached legislative resolution. With the law scheduled to take effect before the next legislative session, entities can begin compliance planning after prolonged uncertainty. Senator Rodriguez’s retirement further marks the close of this legislative chapter. While others, such as CAIA co-sponsor Representative Brianna Titone (D), may pursue future revisions, Rodriguez’s position as both primary sponsor and Senate Majority Leader was critical to advancing the bill through contentious negotiations. Further statutory changes seem unlikely without similarly positioned leadership, though the AG’s rulemaking process may determine implementation details and enforcement approaches that could significantly affect CADMA’s real-world impact.
Colorado’s journey from comprehensive governance to an approach centered on transparency will continue to offer critical data for the debate on whether consequential algorithmic systems require specialized governance frameworks or can be adequately governed through transparency and existing law.
The EU Commission’s Approach to Age Verification: Mobile Apps, DSA Enforcement, and Challenging National Social Media Bans
On 29 April 2026, the European Commission published its Recommendation for a common approach for EU-wide age verification technologies, a non-binding policy document with the aim of harmonizing future measures for the protection of children online.
This blog post outlines the Commission’s emerging strategic approach to the implementation of EU-wide age verification measures, provides an analysis of the legal framework envisioned for their deployment, and includes notes on the Commission’s thinking with regard to possible social media bans in individual Member States. A number of key takeaways emerge:
In response to growing tensions surrounding the possibility of social media bans in a number of EU countries, theCommission is accelerating its attempts to enable the roll-out of age verification solutions, urging Member States to implement these by 31 December 2026;
An analysis of the applicable legal framework, and primarily the Digital Services Act (DSA), shows that since none of its Articles include specific mention of minimum age requirements or of age verification measures, it is still unclear whether age verification solutions will be voluntary or mandatory – it is worth noting here, however, that this does not mean that age assurance methods should not be implemented, as shown by emerging DSA enforcement on the topic;
While the Commission’s 2025 Guidelines on the protection of minors under the DSA focus on a variety of age assurance methods, this Recommendation aims to advance the EU’s strategic approach to age verification in particular, contributing to a growing global trend focused on age verification for service access or limitations;
The Commission aims to develop an EU age verification blueprint – a publicly available technical specification comprising the architecture, protocols, and interfaces to be used by Member States and providers to roll out national age verification measures;
An EU age verification schemewill also be developed by the Commission to establish the framework for “proof of age attestations,” including a list of trusted EU-based providers for such attestations;
While significant references are made to privacy and to ensuring that age verification measures are “privacy-preserving,” there is no reference to the GDPR and little detail regarding the technical parameters that will be expected;
Invoking Directive 2015/1535 on technical regulations and two CJEU cases from 1996 and 2000, the Commission aims to make it procedurally challenging for any individual EU Member State to implement a social media ban.
1. Applicable legal framework – From the Digital Services Act to the (not-yet-published) Digital Fairness Act
Article 28(1) DSA states that “providers of online platforms accessible to minors shall put in place appropriate and proportionate measures to ensure a high level of privacy, safety, and security of minors, on their service.” While the remainder of the Article covers advertising based on profiling and the further processing of personal data for the purpose of proving whether the user is a minor, it does not include mention of age verification measures.
The Commission’s Recommendation, in paragraph 3, also makes reference to the July 2025 Guidelines for the protection of minors under the DSA, also issued by the Commission, which specifies general guidance on the application of age assurance measures. It is worth noting that, while in the 2025 DSA Guidelines the Commission focuses on self-declaration, age estimation, and age verification as tools to ensure the protection of minors online, the 2026 Recommendation aims to advance the EU’s strategic approach to age verification in particular, recognizing the higher degree of accuracy of the latter.
The Recommendation additionally references Articles 34 and 35(1) of the Digital Markets Act (DMA) in which Very Large Online Platforms and Online Search Engines are required to “assess and mitigate actual or foreseeable risks that their service may pose to the protection of minors.” It also references Article 44(1)(j) DSA which enables the Commission to develop voluntary targeted standards to protect minors online, and recognizes that no such standards have been developed yet.
The Audiovisual Media Services Directive, through which video-sharing platforms have an obligation to protect minors from accessing harmful audiovisual content, and the Unfair Commercial Practices Directive which recognizes minors as vulnerable users that must be protected, similarly form the basis of the applicable legal framework for age verification in the EU. Finally, the upcoming Digital Fairness Act is expected to fill any gaps left unaddressed, though the Recommendation does not specify which ones.
Two notes are particularly relevant when considering the applicable legal framework:
Mandatory or voluntary? – While the requirement to implement age verification tools is not explicitly included in any of the abovementioned laws as a legally binding obligation for digital services providers, both the Commission’s DSA Guidelines and the Recommendation may be taken into consideration by national Courts when interpreting existing, binding EU law.
Lessons from emerging enforcement under the DSA is, however, showing the inadequacy of age assurance methods currently being implemented for compliance which are, so far, largely based on self declaration and age estimation (rather than age verification) – for example, the Commission preliminarily finds (April 2026) Meta in breach of the DSA for failing to prevent minors under 13 from accessing Facebook and Instagram; and the Commission opens an investigation into Snapchat (March 2026) for not preventing users under 13 from accessing the app, and not adequately assessing whether users are under 17, which it deems necessary in order to ensure an age-appropriate experience.
Enforcement also shows inconsistencies in EU harmonization regarding the age of a minor – While there is no consistent and agreed upon age of the child under EU law, the Recommendation defines a “minor” as anyone under the age of 18 – however, across individual Member States the age of the minor can range from 13 to 18.
Under the GDPR, which is not referenced by the Recommendation, the processing of personal data of a child in relation to the offer of information society services directly to them is lawful where that child is at least 16 years old (Article 8(1)), though Member State law may provide for a lower age (which must not be under 13).
Since Member States have discretion in defining the age of a minor within their national territory, “EU-wide” age verification measures may become fragmented depending on this definition.
2. Age verification blueprint and age verification scheme
When it comes to operationalizing EU-wide age verification tools, the Commission will develop a blueprint consisting of the technical specifications that such tools should follow and an open source implementation as a mobile app that can be customized to national contexts. This will be consistent with the EU Digital Identity Wallet, acting as an additional “age verification functionality”, which Member States are expected to operationalize by the end of 2026. It is worth noting that the EU Digital Identity Wallet is also voluntary for citizens and businesses, although Member States have the obligation to make the option available.
The Commission will additionally develop an age verification scheme, with requirements for providers of proof of age attestations and age verification solutions to meet, and including a list of EU-based trusted providers of such attestations. The role of the attestation is to ensure conformity with the criteria of effectiveness of the age verification solution, namely accuracy, reliability, robustness, non-intrusiveness, and non-discrimination (these criteria are outlined in the Commission’s 2025 DSA Guidelines, mentioned above).
Two notes are particularly relevant here:
While the Recommendation does not include significant details regarding the proof of age attestations, its reference to conformity is reminiscent of the Conformity Assessment required under the EU AI Act, hinting at the further expansion of a product safety approach across the EU digital regulatory ecosystem;
The Recommendation specifically notes that the trusted providers of such attestations, which can be public or private entities, must be EU-based, recalling the Commission’s broader strategic goals in the area of EU digital sovereignty.
From a global perspective, the Commission’s age verification scheme may be comparable to recent age assurance developments in other jurisdictions—such as the ongoing rulemaking efforts by the New York Attorney General’s Office to establish age assurance standards and accuracy benchmarking requirements under the SAFE for Kids Act, and Australia’s Age Assurance Technology Trial which assessed a variety of age assurance solutions and vendors but sought only to determine the feasibility of age assurance mechanisms from participating vendors rather than assess provider conformity with legal requirements. Notably, the Commission’s efforts seemingly go beyond both New York’s and Australia’s since it aims to establish requirements for conformity supplemented by a list of EU-vetted, trusted providers for use in legal compliance.
3. “Privacy-preserving” age verification?
Notable references are made throughout the Recommendation to the importance of privacy. Through this Recommendation, the Commission aims to facilitate the development of “harmonised, privacy-preserving, cybersecure, data protection compliant and robust EU age verification solutions.” Without reference to the GDPR, the Recommendation nonetheless relies on key data protection principles and requirements, interpreting “privacy-preserving” as preventing unnecessary data collection, unauthorized access or misuse of personal information.
To be privacy-preserving, the age verification solution should, by default, limit the information shared to the relying party to a true or false response regarding the age of the individual, without providing any further information about them. Additionally, the Recommendation states that verification methods “should include technical safeguards to protect citizens from privacy and data protection risks, such as tracking of their online activity, including the use of zero knowledge proofs.”
While there is no further elaboration of the expected technical safeguards or the privacy-enhancing technologies that could be deployed, it is likely that there will be significant interest in these attributes, particularly following the security flaws found in the EU “age checking app” launched by the Commission in early April.
4. On social media bans: From political debate to procedural impossibility
The Commission’s Recommendation is timely in that it comes as some individual EU Member States, such as France (for under 15s), Spain (for under 16s), and Germany (for under 14s, with stricter rules for under 17s), consider social media bans.
With a view to harmonization and the prevention of barriers within the internal market, the Recommendation invokes an administrative requirement found in Directive 2015/1535 laying down a procedure for the provision of information in the field of technical regulations and of rules on Information Society services. On this basis, where Member States consider introducing technical measures restricting minors’ access to online platforms, they have an obligation to report such measures to the Commission beforethey are adopted. This notification triggers a 3-month (extendable) standstill period during which the Member State is prevented from adopting the restriction, and a series of dialogues both with the Commission and with other Member States through the Digital Services Expert Group. Digital Services Coordinators, on the basis of the DSA, can also bring the issue for consideration to the European Board for Digital Services, a forum for cooperation for ensuring the coherent enforcement of the DSA.
Should a Member State fail to notify the Commission of the draft technical measure they are considering for restricting minors’ access to online platforms, it would be considered “a procedural defect that renders the measure unenforceable against individuals in national court proceedings”, and would be inapplicable to individuals. The Recommendation cites CJEU Case C-194/94, CIA-Security and Case C-443/98, Unilever in its reasoning. Furthermore, the Commission could initiate proceedings against a Member State should the proposed national measures regarding restricting minors’ access to online platforms be found to be incompatible with the DSA.
As regulators globally continue to navigate the intensifying youth online safety space, the Commission’s Recommendation adds another thread to the global patchwork of proposals aimed at restricting or banning social media access for minors. Several countries outside the EU are considering bans for minors, such as Australia and Indonesia which both recently started implementing social media bans (for under 16s), or targeted restrictions on social media access, such as in Brazil (which requires that accounts of minors under 16 are linked to a parent account in the recently effective Digital ECA) and the US (where legislation is pending that would ban minors under 13 from holding accounts and restrict use of certain platform features within teen accounts).
5. Concluding Notes
It is still uncertain how the age verification landscape will develop across the EU. As enforcement shows that the currently implemented lower-accuracy age assurance measures are increasingly deemed incompatible with the DSA, and political pressure grows within and across Member States to more adequately protect minors online, the Commission is attempting to set the tone for a harmonized approach.
While the Recommendation is a non-binding, soft law instrument, it shows the Commission’s strategic direction and positioning regarding age verification measures. Nevertheless, specific details regarding the technical specifications, protocols, interface, the interoperable and privacy-preserving features of such tools, as well as how (and when) each individual Member State will operationalize them, remain open questions.
Taking stock: The Impact of the India AI Impact Summit 2026
India’s hosting of the AI Impact Summit 2026 was an ambitious undertaking. With 600,000 attendees and 92 signatories to the New Delhi Declaration, the Summit was a showcase of a Global South country taking a leading role in shaping the AI governance agenda. The Summit’s official framing centered on infrastructure, compute, and equitable access to AI. What emerged across the week, and across FPF’s engagements in New Delhi before and during the Summit, was a global AI governance conversation defined by the tension between ambitious multilateral declarations and the slower, harder work of building the institutions and tools needed to make them real.
Now that the dust has settled, this blog post takes stock of the impact the Summit has had on the global AI governance conversation, drawing takeaways from FPF’s participation in events across Pre-Summit and the Summit itself. The threads that emerged from our engagements with the programming in New Delhi and now continue to manifest in various ways are: (1) the growing role of sandboxes as governance infrastructure; (2) whether global AI policy conversations can hold together in the face of geopolitical divergence; and (3) the sharpening focus on children’s safety and agentic AI as specific governance challenges that are moving faster than the frameworks designed to address them.
Theme 1: For AI governance to scale, it needs the right testing environments, and sandboxes are emerging as an answer
FPF participated in two events tied to India’s AI Impact Summit 2026, both co-organized with Nasscom. On 20 January 2026, FPF and Nasscom co-hosted a Pre-Summit Event in New Delhi titled “Building Safe Spaces for AI Impact: Regulatory and Private Sandboxes,” bringing together senior government leaders, regulators, global industry representatives, and policy experts. From 16–21 February 2026, Jules Polonetsky, CEO of FPF, Josh Lee Kok Thong, Managing Director for APAC, and Bilal Mohamed, Policy Manager for India, represented FPF at the Summit itself, co-organizing a high-level panel with Nasscom, hosting an FPF Salon Dinner on 17 February, and participating in bilateral engagements throughout the week.
The FPF delegation at the India AI Impact Summit 2026. From L-R: Josh Lee Kok Thong, Managing Director (APAC); Jules Polonetsky, CEO; Bilal Mohamed, Policy Manager for India Photo credit: Josh Lee
One of the clearest messages from the Pre-Summit Event was that the global AI governance conversation has moved decisively beyond the question of what principles should govern AI toward the more difficult question of how to build the regulatory infrastructure needed to put those principles into practice. Sandboxes (whether in their regulatory and private organizational forms), are emerging as one possible lever to achieving this.
The Pre-Summit Event’s first panel, moderated by Josh, brought together regulators from India, Singapore, and Brazil alongside industry experts to examine the evolution of regulatory sandboxing. Two key insights emerged:
First, sandboxes have seen global uptake as a mechanism for translating governance principles into practice. Over 200 regulatory sandboxes are now in operation globally, 70 of which are focused on AI. More importantly, their function is changing. Where early sandboxes primarily granted permission for testing, well-designed sandboxes today generate the real-world evidence regulators need to write better-calibrated rules. Singapore’s Infocomm Media Development Authority (IMDA) has pioneered a phased methodology moving from case studies to guidelines to formal standards, offering a model of prospective enforcement grounded in observed technical reality.
Second, sandboxes are becoming interoperable by necessity. AI-driven products cut across sectors in ways that engage multiple regulators simultaneously. The Reserve Bank of India’s Interoperable Regulatory Sandbox mechanism, introduced in 2022, was designed to test products that trigger obligations across jurisdictional lines. Similarly, Brazil’s Agencia Nacional de Proteção de Dados (ANPD) deliberately involves other regulators, technical experts, and civil society from the outset, recognizing that the questions sandboxes address are rarely confined to a single institution’s mandate.
The second panel examined how organizations are building private sandboxes for AI governance. The discussion, featuring representatives from Coforge, PayPal, Salesforce, Palo Alto Networks, and European Data Protection Supervisor (EDPS) AI Unit, highlighted two practical insights:
First, private sandboxes help organizations build trust with both consumers and regulators. Sudheer described Salesforce’s “Customer Zero” approach: before any AI product reaches customers, it is deployed internally across Salesforce’s 80,000-person workforce. The Salesforce philosophy of “build it, use it, fix it, scale it, and then sell it” surfaces real-world failures that may be limited by laboratory testing and allows governance guardrails to be refined before external rollout. Sam described how Palo Alto Networks used isolated “dirty lab” environments to subject models to curated malicious prompts, simulating prompt injection, data leakage, and adversarial manipulation, to establish a behavioural baseline before deployment. For companies navigating frameworks like India’s Digital Personal Data Protection Act, 2023 (DPDP Act), internal sandboxes serve as a signal of due diligence to regulators, demonstrating structured processes throughout the product lifecycle.
Second, unlike generative AI systems (whose failure modes are at least probabilistically characterized), agentic systems take autonomous actions, which means sandboxing must simulate intent rather than just behavior. More broadly, governance frameworks must be built to outlast the specific technologies they regulate. As Christian Lau of Dynamo AI described during the first panel, organizations must “separate the governance layer from the tech layer,” building accountability mechanisms that remain intact as models evolve.
Theme 2: Geopolitical divergence is exposing the limits of international AI governance
As the first Global South host of the AI Summits, India played an important bridging role, keeping the focus on how AI can drive economic development across Africa, South America, and Asia. The adoption of the New Delhi Declaration, signed by 92 countries and international organizations – including the US, China, and G7 nations – reflected genuine multilateral ambition, even as its voluntary and non-binding character also revealed the limits of that ambition.
The Summit provided a platform for different philosophies on AI governance and oversight to be articulated, with geopolitics in the backdrop. Michael Kratsios, Director of the White House Office of Science and Technology Policy, argued that AI policy must remain national and local, and that international fora risk creating centralized oversight that could stifle innovation under the guise of safety. Implementing this vision, the US outlined a set of parallel initiatives: an American AI Exports Program, new development finance instruments, a Tech Corps initiative embedding US technical experts with partner governments, and an AI Agent Standards Initiative through the Department of Commerce.
On the other hand, the President of France, Emannuel Macron, who hosted the previous edition of the AI Summit in Paris, promoted the EU AI Act in his speech as evidence that responsible and competitive AI are not in opposition, and argued for an approach that treats oversight as foundational to AI development rather than an obstacle to it.
India, as host, articulated its own approach. During the fireside chat concluding the Pre-Summit Event, S. Krishnan, Secretary, Ministry of Electronics and Information Technology (MeitY), outlined a philosophy of regulation “only when necessary,” explaining that India’s constitutional framework allows sectoral regulators such as Securities and Exchange Board of India (SEBI) and the Royal Bank of India (RBI) to oversee AI within their respective domains, rather than relying on a single, prescriptive national law. This middle path eyed by India relies heavily on the kind of regulatory infrastructure discussed in Theme 1.
FPF’s Managing Director for APAC Josh Lee Kok Thong engaging MeitY Secretary S. Krishnan during the fireside chat at the FPF-Nasscom Pre-Summit Event. Photo credit: Nasscom
FPF’s own Summit panel, titled “From Policy to Practice: Governing AI for Global Impact“, co-organized with Nasscom and moderated by Ashish Aggarwal (Nasscom), brought this tension into sharper relief. The panel featured Carina Prunkl (INRIA), Jules Polonetsky (FPF), Gail Kent (Google), Ivana Bartoletti (Wipro), and Wifredo Fernandez (xAI). Three insights from the discussion stood out.
First, it was highlighted that a critical question for the adoption of responsible AI practices is whether emerging baselines are clear and accessible enough to prevent a race to the bottom on safety. As Jules Polonetsky noted, weak or expensive compliance infrastructure creates competitive pressure to cut corners, a particular risk for startups and smaller players.
Second, governance frameworks must be built for specific contexts rather than transplanted from elsewhere. As Gail Kent noted, Indian users rely heavily on voice, video, and image-based inputs rather than text, which fundamentally changes the safety and privacy challenges that need local attention. Third, as Ivana Bartoletti argued, India’s “techno-legal” approach positions it to be an architect of governance solutions rather than a recipient of frameworks designed elsewhere.
These observations point to something important that focusing on divergent regulatory philosophies can obscure. The real risk in global AI governance may lie less in countries choosing different regulatory models, and more in those models being either ineffective overall or inaccessible to smaller actors that a shared floor on safety ceases to exist.
A packed full house at FPF’s and Nasscom’s official session at the India AI Impact Summit. Photo credit: Josh Lee
Theme 3: There is a cross-border consensus to regulate for children’s safety, but approaches vary
Despite differences in AI regulatory philosophies exposed during the Summit, child safety emerged as a point of cross-border consensus. Prime Minister of India, Narendra Modi, called for AI to be child-safe and family-guided, and for mandatory authenticity labels on AI-generated content. President Macron urged India to join a coalition restricting social media access for children.
Prime Minister Modi’s remarks were also grounded in a domestic regulatory development that had unfolded days before the Summit. On 10 February 2026, MeitY notified the IT (Intermediary Guidelines and Digital Media Ethics Code) Amendment Rules, 2026, introducing India’s first formal framework for synthetically generated content. The amendments require intermediaries to label AI-generated content, block the creation and dissemination of child sexual abuse material and non-consensual intimate imagery, and comply with a three-hour takedown window for prohibited content.
In India, the momentum has not been limited to the federal government. On 6 March 2026, the state government of Karnataka announced in its 2026–27 State Budget a proposed ban on social media use for children under 16, citing concerns over digital addiction, mental health, and declining academic performance. On the same day, the Chief Minister of Andhra Pradesh, Chandrababu Naidu, announced that the state would implement a ban on social media for children under 13 within 90 days. At the federal level, the DPDP Act already requires parental consent for the processing of personal data of children below the age of 18.
India’s actions sit within a broader global trend. In July 2025, the EU adopted guidelines on the protection of minors under the DSA; Australia implemented a social media age ban for under-16s in December 2025; and Singapore’s IMDA introduced age assurance requirements for app stores. In the weeks since the Summit, that response has accelerated. The White House’s National Policy Framework for AI placed children’s safety at the center of its legislative recommendations. Dozens of chatbot safety bills are under consideration in state legislatures across the US, and the US Congress. In the UK, Prime Minister Keir Starmer announced that AI chatbots will be brought under the Online Safety Act. The World Economic Forum’s Global Risks Report 2026 ranked online harms among the top risks of the next decade.
Taken together, this activity signals that child safety in the age of AI has become the rare governance issue that commands cross-jurisdictional political consensus, even as the jurisdictions diverge on almost every other dimension of AI oversight. The harder question is whether frameworks across jurisdictions, which share the same underlying concerns but differ in their approaches to age assurance, parental consent, and platform liability, can converge enough to hold platforms to consistent and effective standards. It is a question that India, with its large minor population and newly enacted synthetic media rules, has a significant stake in helping to answer.
Conclusion
The vivid debates at the Summit showed that AI governance approaches will be shaped by the economic, political, and legal contexts in which different nations operate. The real question is whether enough common ground can be built to prevent a race to the bottom on safety and responsible AI, as was highlighted by the FPF-Nasscom panel.
India’s hosting of the Summit was an important signal that this work is genuinely global in its participants and ambitions. The governance gaps that came into focus in New Delhi, from agentic AI accountability to the protection of children in AI-mediated spaces, to the question of whether voluntary multilateral declarations can be turned into durable commitments, represent the agenda for the conversations ahead.
The New(ish) Architecture of Consumer Health and Artificial Intelligence
The rise of AI-powered health tools is prompting new thinking about how, where, and when sensitive health information receives legal protection. According to media reports, consumers are now using general-purpose AI tools to upload or query health information, including medical records, and several companies have recently released large language model (LLM)-based tools customized for consumer health uses. While such records are protected by the Health Insurance Portability and Accountability Act’s (HIPAA) Privacy Rule when collected by healthcare providers and health plans, they largely fall outside HIPAA’s protections once uploaded to consumer-facing AI platforms.
Using online tools to seek health information is not new and consumers have long used health and wellness wearables and apps to share medical information for holistic health experiences, often with beneficial outcomes. Where downloading medical records is still a frustrating or limited experience, policy and technical architectures have emerged to facilitate consumer-directed health information-seeking. What is new is the underlying health data architecture utilized by AI tools and LLMs. This new architecture is a combination of policy shifts, product features, and public privacy commitments – setting new consumer expectations for how consumer health data should be handled based on old frameworks like HIPAA.
This blog post examines the emerging architecture of AI-powered health tools and its implications for privacy, governance, and consumer protection. We explore:
A New(ish) Health Data Architecture: Under mandatory patient access policies, patients are transferring HIPAA-protected data out of covered environments—effectively stripping it of its HIPAA status—where it is commingled with consumer health information in AI and LLM-based tools. Novel data and privacy protection practices and policies are emerging that seek to meet patient-consumer expectations for protection and may establish new industry standards around health data architecture.
Key Implications: This evolving architecture raises critical questions about regulatory applicability when medical records move outside HIPAA’s scope, how platforms should handle inferred health information about non-users, whether AI can adequately account for clinical nuance and medical judgment, and how to measure the effectiveness of voluntary privacy safeguards.
Traditional Health Data Architectures: Client-Server
A fundamental challenge in consumer health technology has been navigating the governance practices and technical architecture needed to handle two categories of health information regulated by distinct legal frameworks. Medical Records or Protected Health Information (PHI) held by healthcare providers, health plans, and their business associates are protected by HIPAA—a highly regulated, entity-based framework that attaches protections based on who holds the data and in what context it was collected. Consumer Health Data or Information, by contrast, collected by commercial entities like health and wellness apps that fall outside HIPAA’s scope, is governed by a variety of state consumer privacy and protection laws—which are data-based frameworks where protections depend on the type of information collected and where the individual lives. This divide is not new: even before AI, online symptom checkers and wellness tools required personal health information to function while operating outside HIPAA’s regulatory perimeter.
Until recently, patient portals which siloed HIPAA-protected data in authorized environments and consumer informational websites used a similar technical architecture of client-server. In a client-server architecture, users would input information into a web-based form (client), which would then send this data to a central server that would store the data according to protection requirements. Servers would run a pre-programmed, rules-based logic engine to organize, analyze, and respond to user requests or queries. The process was largely deterministic and relied on the explicit technical rules encoded by human experts.
Patient/Consumers as the New(ish) Arbiters of Data and Privacy
Another architectural shift in policy is the enforcement of the individual patient’s power to access and move their electronic health records (EHRs) between systems and protection frameworks. Individuals have historically had tacit but inconsistent access to their electronic health information (EHI) as facilitated by the HIPAA covered entity. Federal law penalizes Information blocking where medical information is not accessible to individuals who are entitled to access. The 21st Century Cures Act (Cures Act) defines information blocking as “a practice by an individual or entity that is likely to interfere with, prevent, or materially discourage the access, exchange, or use of electronic health information except as required by law or as specified in an information blocking exception.” As of February 2026, the Information Blocking Complaint Portal has been open and actively used, with over 1,600 complaints submitted and some predicting enforcement in the future.
The requirement for HIPAA-covered entities to facilitate access and transfer of EHI, per the Cures Act, allows individuals to control that version of their information and upload or transfer it as they want or need. This policy transformation is facilitated by an associated technical shift under the Cures Act where healthcare entities must maintain standardized APIs allowing data to be interoperationalized and more easily moved between systems. This interoperability and access is the essential precursor to the consumer health AI that may include previously HIPAA-protected information. Without this first step, many individuals may not have had easy access or transferability of EHI, whereas now, individuals may largely access, download, and upload their EHI at will with few barriers. Simply put, individuals are, now more formally, the arbiters of their own data and privacy protections regarding their EHI and will choose which systems to move their medical records into or out of. Individuals, however, may or may not be aware of what protections apply, meaning that at least in regards to data and privacy protections, individuals may not always be making informed decisions when moving their EHI.
LLMs can integrate patient-accessed and -uploaded medical records with non-HIPAA consumer health data; these systems go far beyond existing querying tools familiar to stakeholders and into longitudinal, pattern-aware platforms. This convergence creates a centralized point of sensitive and variably-regulated health data, fundamentally shifting privacy obligations and trade-offs for all stakeholders throughout the data lifecycle.
The New Architecture for Health Data Protection
The confluence of shifting from deterministic client-server to AI architectures and the evolution of individuals’ access to the information in their medical records changes health data systems. This technological and regulatory evolution redefines how organizations handle consumer health data, creating new data ecosystem practices and expectations.
Key examples of the practices starting to emerge in response to this evolved ecosystem center on public promises to maintain HIPAA level data and privacy protections for consumer data. Simultaneously, governance frameworks beyond traditional regulations—such as voluntary public commitments and AI ethics boards—proactively manage AI risks. These technical and policy changes, coupled with heightened privacy commitments that exceed legal requirements, establish new expectations for handling consumer health data (regardless of HIPAA status). This new architecture—involving technology, policy, and design— merits careful evaluation, introducing challenges in explainability, bias, and control that require innovative policy and technical responses.
Examples of Revised Architectural Approaches
Some entities have explored mechanisms for revising this traditional architecture. For example:
Health Data Segmentation and Expanded Protection Promises: While traditional consumer health tools may have had the option to upload health records from various sources, the health records would not remain separate or receive additional protections. Once a user had voluntarily shared health data, regardless of source, with a non-HIPAA entity, the data was protected in the same way as other health or wellness data. Some AI companies are now purporting to implement “purpose-built isolation, separate memories, and compartmentalized storage” – continuing the practice of allowing individuals to upload their medical records but offering separate digital space for centralization that also encompassed health and wellness data.
Data Minimization, Necessity Requirements, and AI Training Policies: Another growing piece of policy architecture emerges around how AI platforms and downstream entities handle user data, which can be understood through two distinct regulatory developments with potentially overlapping impacts. First, new laws and regulations are increasingly imposing substantive data minimization requirements that tie the collection or processing of personal data strictly to what is “necessary” to provide a requested product or service. If these necessity requirements are interpreted narrowly, or if they fail to include exceptions for routine activities such as product improvement and development, they may effectively prohibit companies from training AI models on uploaded or shared consumer health data, regardless of company’s promises to not train on the data.
Second, distinct from general data minimization rules, new AI-specific laws and regulations may take a more direct approach by outright banning the training of AI models on some or all user input data. Together, these legal frameworks aim to limit the potential for secondary uses and unintentional data leakage, fundamentally shifting the responsibility for data protection upstream to foundational AI providers. This proactive and multi-pronged approach underscores that restricting data use is likely an essential aspect of data governance as consumer health data increasingly intersects with powerful, continuously learning AI systems.
Critical Implications This Architecture Raises
Regulatory Fragmentation Meets Novel Architecture in Health Data and Privacy Protections
The architectural convergence of patient-controlled and interoperable HIPAA-protected data with non-HIPAA health data creates unique regulatory compliance challenges. When individuals upload medical records to AI platforms that aren’t HIPAA-covered entities, that data may lose HIPAA protection and become subject to a fragmented patchwork of state and federal laws—with protections varying significantly based on the user’s location and the nature of the data.
What makes this particularly complex for LLM-based health tools is that the same system may be simultaneously subject to multiple, sometimes conflicting, regulatory frameworks. A single platform might need to comply with:
Youth protection laws, when known minors share health information that contains or signals their age and with verifiable-parental consent (VPC.)
The bottom line: both standard general purpose LLMs and health-focused LLMs will be subject to similar standards of consumer protection, privacy, and AI laws. Furthermore, where companies publicly state a health-focused LLM will have increased protections due to the sensitive nature of the health information uploaded to the LLM, regulators may enforce those public statements.
Multi-Party Consent for Auxiliary Data in Single-User Systems
Though the conversation around consumer health AI often remains focused exclusively on the data of the individual user who is sharing, medical records and health conversations often contain information about people who didn’t consent to share their data with an AI platform. Although a platform may not retain the medical record itself, a range of information and inferences may be drawn from the information it contains. This auxiliary data can include:
Group Data: Information pertaining to third parties, such as children, older adults, or family members, whose data may be present in a shared record (including separately regulated genetic information), regardless of the user’s purpose for uploading it (which could range from well-intentioned care coordination to malicious use).
Provider Data: Identifiers, tax numbers, notes, or references concerning healthcare providers and potentially medical facility staff, raising privacy concerns for these employees.
Intellectual Property: Data that may be subject to copyright, trade protections, or clinical secrecy (e.g., specific internal protocols, proprietary clinical methodologies, or copyrighted educational materials found within a medical record).
Because traditional consent frameworks often assume a single data subject, this architecture reveals the limitations of that assumption.
Medical practice routinely involves judgment calls that fall outside standard protocols but serve patients well. Off-label prescribing (e.g. using FDA-approved drugs for conditions they weren’t officially approved to treat) is one common example. This practice is evidence-based and widespread in clinical medicine, but general-purpose LLMs may flag it as incorrect or potentially dangerous, creating questions around liability.
The implication extends beyond off-label prescribing to any clinical decision involving nuance: evolving treatment guidelines, patient-specific contraindications, or the expert reasoning that experienced practitioners apply to complex cases. When AI systems interpret these decisions as errors rather than judgment calls, they risk undermining the patient-provider relationship and creating confusion about appropriate treatment. The challenge is designing systems that can acknowledge uncertainty and defer to clinical expertise rather than treating medicine as a domain with algorithmic certainty.
Conclusion
The integration of AI into health data introduces a new challenge by centralizing highly-regulated medical records with less-regulated consumer health information, often outside of HIPAA protections. This shift raises critical questions about the practical implementation of technical privacy safeguards, the management of sensitive “auxiliary data” (like information about family members or providers) within uploaded records, and the ability of AI models to interpret complex clinical nuances, such as off-label prescribing. Moving forward, clarity in protections and applicable state and federal regulations are crucial to ensure the benefits of these changing technologies going forward.
Celebrating Another Year of Privacy and AI Governance: FPF at the 2026 IAPP Global Summit
Authored by FPF Communications Intern Celeste Valentino
FPF experts participated in the 2026 IAPP Global Summit and hosted FPF privacy executive convenings in Washington, D.C. from March 31 to April 2. As a major gathering for privacy professionals, the event featured a heavy schedule of workshops and panels focused on the intersection of U.S. and global governance with shifting technology and policy. From exploring high-stakes AI regulation and youth-centered design to discussing the future of the privacy workforce, FPF experts joined industry pioneers and global regulators to provide expert analysis on the most pressing issues in privacy and AI governance.
Through member meet-ups, vibrant networking at our annual Spring Social, and engaging discussions at our Exhibition Hall Booth, FPF spent the week equipping practitioners with the frameworks and foresight needed to navigate a rapidly shifting digital landscape.
We kicked off our member convenings with a Privacy Executives Network (PEN) breakfast on March 30 at the Marriott Marquis Anthem. Attendees discussed data mapping and minimization, AI vendor deployment, agentic AI controls, and more.
Later on, FPF Senior Fellow, Tanya Richardson, spoke on a panel titled “In AI We Trust? Governing High-Stakes AI Before Regulators Step In.” Appearing alongside Hope Anderson (Partner, Data, Privacy and Cybersecurity, White & Case), Taylor Galusha, (Lead Privacy and AI Counsel, Chime), and Marisha Pareek (Senior Privacy Counsel, DoorDash), the panel provided a comprehensive toolkit and actionable framework designed to help organizations navigate the rapidly tightening landscape of AI regulation and enforcement.
As the first day of the conference came to a close, FPF welcomed visiting DPAs, VIPs, and industry leaders into our Washington, D.C. office for our annual Spring Social. The evening featured fantastic networking, stimulating conversation, and fresh introductions as we toasted to another exciting year in privacy and data protection. A special thank you to our sponsors FTI Consulting, RadarFirst, and TrustArc!
The next morning, FPF held a Global PEN breakfast roundtable. CEO Jules Polonetsky and V.P. of Global Policy, Gabriela Zanfir-Fortuna facilitated a conversation centered around global privacy and AI regulation. Members and special guests discussed global anonymization frameworks, synthetic data, digital sovereignty, and tools to help scale AI and privacy governance.
In the afternoon, FPF hosted a PEN lunch with Mike Macko, Deputy Director of Enforcement at the California Privacy Protection Agency. Macko discussed the CPPA’s enforcement strategy and 2026 priorities, including the critical role of internal privacy teams for organizational risk management, the agency’s interpretation of data minimization in enforcement actions, expectations for user interfaces handling consumer preferences, and coordination with state Attorneys General on cross-jurisdictional enforcement.
FPF CEO Jules Polonetsky joined Joe Jones (IAPP), Julie Brill (Harvard Law School and Innovation Labs), and Nicole Wong (NWong Strategies) at “(De)coding for (de)regulation”. The group examined how the global push for technological sovereignty and data-driven growth is fundamentally transforming traditional regulatory compliance into a strategic driver for innovation.
At the same time, FPF Director for Youth Policy, Holly Hawkins, spoke on the panel “Personal, Private, Protected: The Future of Youth Personalization.” This discussion featured Emily Kirstein (Google), Morgan Reed (ACT | The App Association), and Yalda Uhls (Center for Scholars & Storytellers, University of California, Los Angeles); where they challenged the idea that AI-driven personalization must come at the expense of youth safety, arguing instead for a “youth-centered by design” framework.
Next door, FPF Senior Fellow Doug Miller was part of the panel “Beyond Automation: Growing the Next Generation of AI-ready Professionals,” with industry leaders including, Noga Rosenthal (Ampersand), Andrew Dale (OpenAP), and Katherine Fick (IBM), where Doug shared practical strategies for mentoring the next generation, focusing on fostering human judgment and evolving skillsets to ensure leadership remains resilient in an AI-augmented workplace.
Closing out the conference, two FPF experts led immersive training sessions, sharing their deep expertise and insights with fellow practitioners.
In the morning, FPF Senior Director for U.S. Legislation, Tatiana Rice helped lead “U.S. State Privacy Crash Course — What is New and What is Next?”, guiding participants to understand the commonalities in U.S. legal requirements. In the afternoon, Tanya Richardson took over to co-lead “Adtech, Marketing and the Future of Consent in the Era of AI”, a workshop intended to examine how shifting AI regulations are reshaping legal and technical decision-making in adtech.
Throughout the week, the FPF booth served as a central hub for IAPP GS attendees, attracting a diverse crowd of policymakers, industry executives, and privacy scholars. Visitors engaged with our staff to explore FPF membership and discuss pressing initiatives such as the regulation of AI agents and the everchanging landscape of U.S. privacy regulation while picking up infographics, and other resources.
We hope you enjoyed this year’s IAPP Global Summit as much as we did! If you missed us at our booth, visit FPF.org for all our reports, publications, and infographics. Follow us on X, LinkedIn, Instagram, and YouTube, and subscribe to our newsletter for the latest.
Adapting the Privacy Profession to Changing Times
As spring comes into full bloom, the changing of the seasons offers an opportunity for privacy teams to start thinking about how they can be more effective in their workplaces. Privacy work needs to evolve in a couple of important ways, and the value of that work for the organization may have its highest manifestation as a strategic partner helping the organization itself re-invent its work.
One path is through alliance. It is true that many new issues are coming up that, to some organizations, may seem to be a higher priority than privacy. These issues of course include AI but also youth online safety, age assurance, and cybersecurity. There is a growing basket of privacy and compliance issues: governance risk and compliance, data protection, trust and safety, content moderation, AI governance, cybersecurity, and in advertising, debates around the appropriate role of generative AI in creating ads. We might previously have thought of these issues as “privacy adjacent” but increasingly we can think of them as “data governance gateways.” The organization prioritizes these issues because they must, and yet each one is a gateway back to privacy concerns. Leading with these other issues can create a path back to the key data governance issue on the agenda of the privacy team.
Managing these data governance gateways means building alliances with the other people at the organization integral to concerns. Some privacy teams have felt stretched as their work on AI privacy and governance has grown, but these issues can be reframed as a gift to the privacy team because it is something that the organization deems important and a high priority. Leading on governance in a strategically critical area allows privacy teams to get the attention of the C-Suite and other key stakeholders and make the case for why resources are needed to fulfill it. The organization probably already is prioritizing cybersecurity, so a good relationship with the CISO team is vitally important: it may have budget resources that the privacy team does not. These other issues and teams offer the potential for networks of alliances. On an organization chart, these developments might look like a diminution of privacy team influence. But real influence is shaped by productive interactions, effective communication of a clear message, and the finesse and persistence entailed in effective leadership across different teams of stakeholders. The skill and mindset for privacy executives of leading across teams has never been more important.
It’s also possible for privacy teams to continue to evolve. In their early stages, the privacy team was the “Lonely Voice,” an appendage to the legal department or the marketing team that tried desperately to get attention to its issues but was often a low priority voice. We certainly hope that no privacy teams are still stuck there. Many of them advanced to a higher evolution, establishing effective partnerships in the organization with other key stakeholders, including marketing teams, sales teams, product teams, and privacy engineers. Successful teams positioned themselves to be the “Pathfinder” helping guide the organization through the minefield of increasing regulation and law and enabling the organization to execute its goals.
Over the past few years, we have started seeing the next evolution of the privacy team’s role, initially to a broader data governance role and now to a position more readily perceived as a strategic partner, helping the organization compete in the age of AI. More than ever legal regulatory and enforcement trends demand consideration of data stewardship, accuracy, bias, transparency, and safety in the business planning and strategy processes. Cybersecurity, always a major risk, is deeply stressed by the new threats enabled by AI. Beyond regulatory and enforcement trends, AI is reshaping how every business plans and operates and data protection and governance issues are increasingly strategic, if AI enablement is to advance.
The alliances across various compliance or data governance gateway stakeholders that the privacy executive builds now become of strategic importance not just for the privacy team but for the organization itself. It’s helpful to think of “data governance” not just as the small basket of privacy issues but as a larger basket of “data governance gateway” or “privacy adjacent” issues for which there is a cohort of allies – a “compliance alliance” – with significant influence across the organization. This new compliance cohort now must be the strategic partner helping the organization succeed. These executives, whether Chief Privacy Officer, Data Governance Leader, Responsible AI executive or other, are well positioned to lead this effort as they work across teams and silos.
Consider cybersecurity, where substantial investment is required in core technology and resources, but equally important are cultural changes that need to be made to reduce risk from avoidable human mistakes made by employees. Focusing on cultural change with deeper business awareness across all teams, not just the cybersecurity team, will ultimately help the organization protect itself. The cybersecurity team benefits from this compliance alliance.
In advertising and ad tech, AI drives a substantial strategic imperative for companies to think about how to incorporate AI into their offerings. The challenge of offering opt outs from targeting, sharing, selling, across many state regimes is trending toward more comprehensive, perhaps browser-based approaches that likely will increase opt out rates. Some companies may benefit from reducing their emphasis on ID-based targeting and shift resources toward a strategic approach that includes building audiences using AI and more multichannel pathways to finding people to buy products. Digital advertising still has a future, but so do many other forms of marketing. Advertisers not thinking more holistically about the various ways that they could connect to consumers are going to miss out. Publishers can be thinking more clearly about adopting AI and being able to interact with the likely growth in standardized agentic AI. Advertisers need to get their arms around generative AI that creates the ads at a far greater speed but needs to also deepen connection to actual humans, because many consumers may respond better to more meaningful human connection. Publishers and advertisers have a strategic interest in finding more creative ways of connecting to actual consumers in a way that actually matters for those consumers, rather than responding to the various measurement techniques that might be counting clicks or traffic or eyeballs without really focusing on what’s actually moving products. Given the dependence on new uses of data, continual engagement with data governance teams on these issues is paramount.
New laws that promise protections to people who are under 18 (beyond COPPA’s 12 and under consent requirement) are an increasingly urgent area of focus for companies. These laws are generating serious strategic conversations about whether under-eighteens should be part of their business at all, and if so, how they can provide age-appropriate experiences for that cohort. Privacy leaders, as part of the larger “compliance alliance,” are well positioned to tee up that discussion.
In what parts or regions of the world will the organization compete, given the diversity and changing nature of digital rules outside the United States? Companies might well think about what other regions they operate in, balancing that with the various state laws in the United States, and reflect on how to plan and design systems to efficiently address regulatory and enforcement trends. We have probably passed the point where ad hoc adaptation suffices. Once again, the privacy team brings strategic value.
For the privacy team that is facing expanded work with limited resources, there is opportunity to build alliances and to reframe this work in a way that is more germane and central to the organization’s mission. Becoming a genuine strategic partner that helps the business rethink how it profits in the face of new regulations and new technologies builds the case of expanded resources.
Unquestionably, this approach raises the degree of difficulty and level of effort for privacy teams and data governance executives. A strategic executive needs to develop the skills of connection, leadership without authority, and leading across teams. Performing at this level requires highly effective communication – and what makes communication most effective is persistent and consistent messaging. It will require advancing pragmatic solutions focused more on cost and revenue opportunity and much less on risk and fear. It will require motivating privacy teams that may feel demotivated with clarity, purpose, and in-the-trenches support so that they know someone is looking out for them.
One note of caution: A commitment to collaboration and saying, “Yes, and . . . “ to business initiatives cannot mean that privacy teams or the “compliance alliance” never say no. They obviously can’t be perceived as a blocker by default, but they have to earn trust to effectively encourage responsible design decisions that consumers and other business partners trust. This is a key part of the partnership: Honest guidance that builds a successful business, not enablement that ignores the fact that success is not when the ship sails, but when it arrives safely in port, having delivered the goods.
Dwight Eisenhower is credited with saying that if a problem seems unsolvable, make it bigger. What this gets at is that often we try to solve problems by breaking them into smaller pieces, but sometimes the solution is found by reframing, up-leveling, and finding new pathways into the problem. That is going to be the pathway for privacy teams to show their value to organizations now: They’ve got to make the compliance problem – and the business opportunity – bigger. Making the business challenge bigger makes it more relevant and facilitates development of alliances with influential stakeholders in the organization. It also elevates privacy professionals as strategic partners at a moment in which the business has little choice but to rethink how it grows in a time of rapid change. It is seizing a propitious moment. It is embracing the uncertainty of moving forward with the promise of success and growth rather than being diminished. It embraces hope, not fear. It centers the idea that technology is part of how the organization will progress and yet it still preserves the fundamental truth that it will be humans working together, communicating effectively, and uniting around a common purpose of helping the organization succeed that will make privacy teams continue to be relevant in 2026 and beyond.
FPF has launched a project which I lead to help senior privacy and data governance executives more effectively frame their value to senior management and boards. While full participation is limited to our members, please reach out with any useful ideas. If you would benefit from participating and want to learn more about FPF membership, contact [email protected].
More Parties, More Risks, More Opportunity? Evolving Governance to Support Cyber Resilience Amidst Evolving Policy and Technological Change
*Special thanks to Jim Siegl and Jocelyn Aqua for their advice and expertise.
Summary: Artificial Intelligence (AI) presents fundamental opportunities and challenges for defense of increasingly complex digital ecosystems amid rising attack costs, fragmented regulation, and evolving industry practices. A coordinated response across the public and private sectors, including smart deployment of AI tools for risk detection and defense, is critical to building resilient AI systems and securing supply chains. This article describes emerging risks, identifies regulations and governance frameworks relevant to addressing them, and proposes governance steps that organizations can take to improve supply chain resilience.
In recent years, third-party and supply chain cybersecurity attacks have become one of the most significant risks to national and organizational security. The 2020 SolarWinds breach demonstrated how integrated environments built on shared code, automated updates, and implicit trust in upstream vendors can allow a single vendor breach to cascade across agencies and enterprises. That incident granted foreign adversaries unauthorized access to more than 200 public and private organizations, including the Departments of Homeland Security, Treasury, and Commerce. Although the U.S. Securities and Exchange Commission (SEC) ultimately dismissed the SEC’s civil enforcement action against SolarWinds, this incident illustrates how an attack on one trusted software provider can lead to system-wide failures. In 2023, PyTorch, an open-source artificial intelligence/machine learning (AI/ML) framework, was injected with malware following a supply chain attack. In 2024, the XZ Utils backdoor illustrated how a single vulnerability in a trusted open-source library can compromise the build process and enable remote code execution across countless systems.
The threat became more pronounced in 2025. Approximately 30% of cybersecurity breaches last year originated from third-party relationships – double the percentage from just two years earlier. This rise tracks closely with increased reliance on external vendors, cloud platforms, model providers, and open-source components. While the growth of these interconnected supply chains can yield efficiencies and service improvements and accelerate innovation, they can also multiply the number of attack surfaces that bad actors can exploit.
Over several years, FPF has been exploring the ways that AI can accentuate security risks, while also creating new detection and defense capabilities. The recent announcement of Project Glasswing put a spotlight on the presence of both opportunity and risk as AI technologies rapidly evolve. Autonomous and agentic systems, add new layers of complexity and risk – as well as opportunities to more effectively detect, combat and mitigate those risks. Unlike traditional software, agentic AI systems may ingest external data, reuse pretrained models, and act across organizational boundaries with limited human intervention, which introduces or exacerbates distinct vulnerabilities. These risks intersect with traditional cybersecurity concerns but require new or expanded governance mechanisms around data provenance, model integrity, and automated decision-making.
Emerging Risks in AI-Enabled Supply Chains
Organizations must navigate an evolving industry landscape while managing an interconnected network of vendors, cloud services, and open-source components, creating systemic risk from a single compromised dependency that can cascade across operations.
Risks and Opportunities from Third-Party Components and Systems
Third-party software libraries, datasets, and cloud infrastructure can yield enormous value for organizations, including for risk management and cyber defense. At the same time, these tools can introduce vulnerabilities that are difficult to detect or control. In AI ecosystems, dependency chains are often deeper and less transparent than in traditional software systems, encompassing not just code, but models, training data and pre-trained weights. The proliferation of new AI-driven technologies and services, particularly those that involve agents, amplifies these risks. Once deployed, these agentic AI systems can act independently and potentially bypass traditional security controls.
Amplified Risk by AI Systems
AI systems and plugins can introduce new or exacerbate established cyber attack methods. These techniques exploit the model’s reliance on data and user input to manipulate system behavior or extract sensitive information. Specific examples include:
Data and model poisoning through compromised training data or dependency libraries that alter model behavior at scale;
Prompt injection attacks where malicious inputs manipulate model outputs or downstream actions without altering underlying infrastructure;
Autonomous agent exploits, where AI agents interact with external systems or application programming interfaces (APIs) using delegated credentials, tool access, or persistent permissions without sufficient guardrails; or
Cross-system interdependency, when a compromise in one model, tool, or plugin spreads across an entire interconnected ecosystem.
Agentic AI systems introduce a distinct risk profile characterized by autonomy, multi-step decision-making, and the ability to take actions in external environments. Rather than producing static outputs in response to bounded inputs, these systems can plan, iterate, and take actions across external environments using delegated tools and credentials. This shift effectively extends the operational boundary of the system to include external services, APIs, and data sources in real time. As a result, risk is no longer confined to model performance or data integrity, but includes the downstream effects of autonomous decision-making and execution across interconnected systems.
These risks are amplified in environments where agents operate with persistent credentials or broad API access. In such contexts, a single compromised interaction can propagate across systems, particularly when agents are designed to optimize for task completion without sufficiently robust constraints on permissible actions. The resulting behavior may be difficult to predict or audit, as it emerges from the interaction between model outputs, tool responses, and external system states rather than from a single deterministic process.
As organizations deploy agentic AI, institutional decisionmaking can risk becoming more distributed and opaque. Agents may interact autonomously with external systems, exacerbating cybersecurity risks such as propagation of incorrect or malicious instructions across the supply chain, extraction of confidential data, and escalation-of-privilege scenarios (if access controls are misconfigured). The autonomy of agents may require new or evolved forms of oversight, logging, and training.
AI Governance and Accountability
Technical controls alone are insufficient to mitigate AI-specific supply chain risks. Effective enterprise cybersecurity requires active leadership oversight and a culture of accountability. Executives must move beyond a “baseline understanding” and toward a risk-aware mindset where cybersecurity training is tailored to AI specific industry roles and threat models. Company policies and protocols should incorporate this understanding. Human governance is essential to assess and enforce organizational standards.
Applicable Regulations and Governance Frameworks
In the absence of a single statutory framework that governs the intersection of AI and cybersecurity, federal and state agencies have developed a range of guidelines, voluntary frameworks, certifications, and procurement requirements that seek to address growing cyber and AI governance risks.
Security Guidance from the Federal Government
Several federal frameworks provide relevant guidance for companies around third-party and supply chain cyber risk:
National Institute of Standards and Technology (NIST) Cybersecurity Framework(CSF) and NIST Special Publications (SPs) 800-171and 800-161: Offers detailed technical guidance for supply chain risk management (SCRM), with emphasis risk assessments, dependency mapping, continuous monitoring, and vendor due diligence.
The NIST Cybersecurity Framework is a voluntary and scalable cybersecurity risk guidance. The updated CSF 2.0 includes “govern” as a key function, which embeds cybersecurity governance into enterprise risk management, aligning strategy, policy, and oversight with business objectives.
NIST SP 800-161 provides comprehensive guidance for enterprise SCRM. It recommends a multidisciplinary governance structure, emphasizes iterative risk assessment and monitoring, and integrates risk management into procurement processes.
Cybersecurity and Infrastructure Security Agency (CISA) Secure by Demand Guide: Provides buyers a checklist of questions to assess software manufacturers’ supply chain security practices, such as establishing secure authentication defaults, reporting vulnerabilities, and providing security logs and a software bill of materials (SBOMs).
CISA Tabletop Exercise Packages (CTEPs) and Tips: Supports agencies and vendors in evaluating their cloud and procurement-related cybersecurity frameworks.
CISA also offersbest practicesfor cloud security and third-party risk management that emphasize shared responsibility models, continuous monitoring, and secure integration of AI services.
Department of Defense’s Cybersecurity Maturity Model Certification (CMMC): Sets standards for federal contractors, including vendors supplying AI services or model components to defense agencies.
Federal Risk and Authorization Management Program (FedRAMP): Establishes security requirements for cloud service providers, and its procurement standards now extend to AI services deployed within federal environments.
AI Guidance from the Federal Government
Federal guidance on AI-related cybersecurity continues to evolve, offering several guides for how to approach AI-related risks in supply chains:
NIST AI Risk Management Framework (AI RMF): Provides a structured approach for assessing AI-related risks, encouraging transparency and accountability across the AI lifecycle.
The White House AI Action Plan sets out high-level policy principles around safety, transparency, and procurement/vendor accountability, calling for stronger oversight mechanisms to ensure that AI tools integrated into supply chains are trustworthy and secure.
State Governance
States are taking an increasingly active role in regulating AI and related cybersecurity risks. In particular, California has a number of strong AI procurement and cyber requirements.
New York Department of Financial Services (NYDFS) – 2025 Industry Guidance: Highlights the importance of incorporating AI governance into cybersecurity compliance (and noted that automation can amplify existing vulnerabilities), requiring financial institutions to evaluate AI model risks, confirm training data provenance, and assess vendor-level AI controls.
California Privacy Protection Agency (CPPA) – 2025 Regulations: One of the first comprehensive state-level efforts to regulate AI systems and third-party data handling practices. Applicable provisions govern automated decision-making technologies (ADMT), mandatory cybersecurity audits for parties meeting certain thresholds associated with business volume and the selling and sharing of data; and and vendor accountability.
Industry Guidance
In addition to regulatory guidance and frameworks from federal and state government agencies, there are a number of industry standards and best practices that may address AI- and agent-related third-party and supply chain cybersecurity risks. Examples include:
Open Worldwide Application Security Project (OWASP) GenAI Security Project – CheatSheet – A Practical Guide for Securely Using Third-Party MCP Servers 1.0: Provides a framework for companies and developers using a third-party Model Context Protocol (MCP). Along with mapping out common threat types, this cheat sheet provides actionable controls and workflows, such as strong authentication processes, sandboxed environments, and validation measures (e.g., establishing a “trusted MCP registry” and instituting periodic audits).
SysAdmin, Audit, Network, and Security (SANS) Institute – Critical AI Security Guidelines: Provides a practitioner-oriented framework to help organizations build, deploy, and operate secure AI systems. Recommends developing strict access or authentication controls, safe deployment strategies (e.g., sandboxing or red-teaming), risk-based deployment, and regular data sanitization and validation.
Snowflake – AI Security Framework: Develops a threat taxonomy of security and privacy risks specific to AI systems to help cross-discipline teams evaluate AI risk in a systematic way. The framework also provides mitigation strategies to address listed risks, though specific implementation would depend on the architecture, environment, and threat model.
Massachusetts Institute of Technology (MIT) AI Risk Initiative – Mapping Frameworks at the Intersection of AI Safety and Traditional Risk Management: Although this analysis does not provide specific risk mitigation strategies, it provides an overview of almost a dozen AI risk management frameworks that sit “at the intersection of traditional risk management and AI safety” (with a particular emphasis on frontier, general-purpose, or “high-risk” AI systems). The MIT initiative could serve as a starting point for companies who want to ground their AI risk-management in proven safety or risk frameworks.
Across the public and the private sector, guidance on third-party and AI-related cyber risk is converging around core principles of transparency, accountability, and continuous oversight and governance. Federal frameworks have established baseline expectations for secure procurement and vendor management, while states are advancing more specific AI governance requirements. Industry standards can complement these efforts by offering practical controls and methodologies for implementing secure and responsible AI practices. Collectively, these frameworks underscore the need for organizations to adopt an integrated, risk-based approach to managing third-party and AI supply-chain security.
Recommendations and Next Steps
To strengthen AI-driven supply chain resilience, organizations should prioritize:
AI Models and Agents Monitoring: Establish passive AI agent monitoring, then consider moving toward active “guardrails” to intercept and block anomalous agent actions, cross-system API calls, or unauthorized data exfiltration in real-time.
Provenance for Third-Party AI Models Requirements: Consider creating AI Bills of Materials (AI-BOM), which would mandate vendors to provide a standardized AI-BOM that inventories code libraries (a “Software Bill of Materials” or SBOM), model provenance, training dataset origins, and cryptographic signatures of model weights to prevent tampering.
AI-Specific Vendor Risk Assessments: Evaluate not only traditional cybersecurity controls but also model lineage, dataset provenance, and plugin dependencies. Consider AI-specific adversarial red-teaming (i.e., updating vendor risk assessments to include results from adversarial testing such as prompt injection and data poisoning resilience).
Contracts and Procurement Controls: Include model security obligations, and update notification requirements and audit rights. Consider updating vendor contracts to ensure that no high-impact decision is made without a clear path for human intervention.
Organizational Literacy: Ensure boards and executives understand AI-specific supply chain risks to enable informed oversight decisions. Elevate AI literacy beyond the IT department. Form a committee of legal, security, and business leaders to define the organization’s risk appetite for third-party AI dependencies and agentic autonomy.
Conclusion
The accelerating convergence of AI adoption, complex vendor ecosystems, and increasingly sophisticated cyber threats has elevated third-party and supply-chain security to a critical strategic priority for industry leadership. Recent incidents and rising breach rates demonstrate that traditional governance models must evolve for environments characterized by autonomous systems, complex dependency chains, and cross-system interdependencies. Both the private and public sector are responding with increasingly aligned expectations that emphasize transparency, accountability, and continuous monitoring across the AI lifecycle and vendor ecosystem.
For organizations, the imperative is to move beyond fragmented or compliance-only approaches and adopt an integrated, risk-based governance model that unifies traditional cybersecurity controls with AI-specific safeguards and robust oversight. Businesses that strengthen vendor accountability, implement continuous model monitoring, and invest in organizational education will be best positioned to mitigate systemic risks, realize new opportunities to strengthen defenses, maintain operational resilience, and meet evolving regulatory obligations.
For questions about FPF membership or our ongoing work related to the topics discussed in this blog, please contact info@org.
Contextualizing the Proposed SECURE Data Act in the State Privacy Landscape
Special thanks to FPF’s Dr. Gabriela Zanfir-Fortuna, VP of Global Policy, for her contributions to this analysis.
The House Committee on Energy and Commerce’s Republican data privacy working group released their long-awaited comprehensive consumer privacy bill on April 22, titled the “Securing and Establishing Consumer Uniform Rights and Enforcement over Data Act” (SECURE Data Act) (H.R. 8413). Compared to prior federal efforts, the SECURE Data Act closely resembles many of the existing state comprehensive privacy laws—particularly those based on the Washington Privacy Act (WPA) framework—in terms of its structure, terminology, consumer rights, and business obligations.
This blog post provides a detailed overview of the SECURE Data Act, including its scope, provisions, and how it compares to the other state laws based on the WPA framework.
Our key observations:
Reflects Narrow WPA Baseline: The bill is closest to some of the narrower iterations of the WPA controller/processor framework, such as the laws in Kentucky, Iowa, Tennessee, Utah, and Alabama’s recently enacted law. It does include certain provisions absent from some of the narrowest state frameworks, such as data minimization (not in Iowa or Utah) and anti-discrimination protections (not in Utah). The comparisons to state privacy laws focus on the laws other than the CCPA because they share the same key terms and structure as this bill. We simply note that this bill is consistently narrower and less prescriptive than what is required under the CCPA.
Adopts Narrow Outlier Provisions: The bill selects particular narrow approaches used by only a handful of states: Virginia’s narrow biometric data definition (which broadly exempts photos, videos, and audio without limiting language), the pseudonymous data exception for consumer opt-out rights (Tennessee, Iowa, Florida, Alabama only), the absence of data protection impact assessments (Iowa, Utah, Alabama only), and no requirement for controllers to recognize opt-out preference signals (although the Secretary of Commerce would be required to conduct a study on the feasibility of such).
Novel Additions: While narrow overall, the bill includes elements beyond typical state frameworks: a federal data broker registry, classification of all teens’ data (ages 13-16) as sensitive data with parental controls, application to common carriers, and a Code of Conduct certification process (modeled on COPPA safe harbor), providing a rebuttable presumption of compliance. The bill would recognize Global Cross-Border Privacy Rules (CBPR) as an approved code. Only Tennessee has a comparable affirmative defense provision.
Broad Preemption: The bill’s scope and broad preemption language could preempt state comprehensive privacy laws, sectoral laws (Illinois BIPA, Washington My Health My Data Act, kids’ privacy laws), and data broker laws (California Delete Act or similar registration laws in Texas, Nevada, Oregon, and Vermont). Preemption is not automatic though and would require litigation on a state-by-state basis. Laws like the CCPA/CPRA that cover exempted categories (employee data, B2B data) may prove difficult to fully preempt.
1. Scope
Applicability: The bill would apply to businesses subject to the FTC Act or a common carrier subject to title II of the Communications Act of 1934 that, excluding personal data controlled or processed solely for completing a payment transactions, either (1) have gross annual revenue in excess of $25 million and collect or process the personal data of at least 200K consumers annually or (2) collect and process personal data of at least 100K consumers and derive at least 25% of their annual gross revenue from selling such personal data.
These default and data sale thresholds are structurally similar to how most state comprehensive privacy laws are scoped, but the figures themselves are higher than in any of the states.
Nonetheless, direct comparison is difficult since these thresholds are comparing state laws applicability at 100,000 consumers per state, while the federal bill applies at 200,000 consumers nationally. Thus, for businesses operating across multiple states, the federal threshold may be easier to meet despite the higher absolute number, while the bill’s additional revenue requirement ($25M) could exclude smaller data-intensive entities within scope of many state laws.
Exemptions: Consistent with most of the state laws, this bill includes a variety of entity-level exemptions, such as: federal, state, or local governmental entities (or any entities acting as a processor on behalf of a federal or state governmental entity); financial institutions subject to the Gramm-Leach-Bliley Act (GLBA); HIPAA-covered entities or business associates; nonprofits; and institutions of higher education.
Notable data-level exemptions include: HIPAA-protected health information; health records; personal data that may impact the creditworthiness, credit standing, character, or general reputation of a consumer and is collected or disclosed by a consumer reporting agency or a furnisher engaged in activities subject to the Fair Credit Reporting Act (FCRA); and information subject to other laws such as the Drivers Privacy Protection Act (DPPA), the Family Educational Rights and Privacy Act (FERPA), and GLBA. As mentioned above, the bill also broadly exempts “publicly available information.” This is defined consistently with many state privacy laws as information that (1) is lawfully made available through government records or (2) “information that a business has reason to believe is lawfully made available to the public through widely distributed media, by the consumer, or by a person to whom the consumer has disclosed the information, unless the consumer has restricted the information to a specific audience.” There are also exceptions for deidentified and pseudonymous data, both of which are defined in the bill.
One point of comparison with the state legislative landscape is the distinction between entity- and data-level exemptions. The newer and recently amended state laws have tended to eschew entity-level exemptions, particularly under GLBA and HIPAA, in favor of data-level exemptions. This bill opts for the broader entity-level exemptions. Although financial institutions would be broadly exempted from the bill, Congress is working on financial privacy as well. The SECURE Data Act was jointly released alongside the House Committee on Financial Services’ GUARD Financial Data Act, which would update GLBA to strengthen financial privacy protections.
In addition to the entity- and data-level exemptions, the bill also includes a variety of exceptions for common business activities, such as cooperation with law enforcement, providing a product or service specifically requested by a consumer or a parent of a consumer, preventing security incidents, engaging in public or peer-reviewed scientific or statistical research in the public interest (subject to safeguards), conducting internal research for product development and improvement, performing internal operations reasonably aligned with consumers’ expectations, and more. These exceptions are common in state privacy laws.
Key Definitions: The definitions in this bill are generally consistent with the majority of state comprehensive privacy laws, including common core definitions such as “consumer” (an individual acting in their individual or household capacity and not in a commercial or employment context), “personal data” (any information that is linked or reasonably linkable to an identified or identifiable natural person, excluding deidentified data or publicly available information); and “sensitive data” (includes sensitive characteristics [such as race and ethnicity, religious belief, sexual orientation, citizenship], genetic and biometric data, and personal data from a child). As discussed below, the bill includes a novel extension of sensitive data to also include teens, defined as individuals aged 13 or over but under 16.
There are a few definitions that, while consistent with some state laws, are among the narrowest versions of those definitions. “Biometric data,” for example, does not include data generated from photographs or video or audio recordings, even if such data is used to identify an individual. The “sale of personal data” is also defined narrowly as the exchange of personal data for “monetary consideration,” whereas many states have extended this to include exchanges “for other valuable consideration.”
2. Consumer Rights
Similar to much of the bill, the consumer rights most closely resemble the narrower iterations of the WPA framework. This bill includes the standard consumer rights to: confirm whether the controller is processing one’s personal data and to access that data; correct inaccuracies in one’s personal data, taking into account the nature of the personal data and the purpose of the processing; delete one’s personal data provided by, or obtained from, the consumer; obtain a copy of one’s personal data in a portable format (if technically feasible); and to opt-out of the processing of one’s personal data for targeted advertising, the sale of personal data, and profiling in furtherance of a solely automated decision that has a legal or similarly significant effect on the consumer. The bill also includes the requirement to obtain consent prior to processing a consumer’s sensitive data as a consumer right rather than a controller obligation.
Although the standard rights are all present, this bill lacks some of the newer rights that have been included in a few of the state laws. For example, Oregon, Delaware, Maryland, and Minnesota all provide a right to know third party recipients of one’s personal data. Minnesota and Connecticut include rights to contest certain adverse profiling decisions. Neither of those rights are in this bill.
Another significant aspect of these rights is the pseudonymous data exemption. Consistent with a few of the state privacy laws, this bill provides that the consumer rights do not apply to pseudonymous data. This arguably narrows the right to opt-out of targeted advertising, if a controller is able to demonstrate that “any information necessary to identify the consumer is kept separately and is subject to appropriate administrative and technical measures to ensure that the personal data is not attributed to an identified or identifiable natural person.” Because the requirement to obtain consent before processing a consumer’s sensitive data is included in the same section as the consumer rights, this also arguably brings pseudonymous data outside the scope of that opt-in consent requirement, which is something that none of the state comprehensive privacy laws have done. However, that is debatable. The pseudonymous data exception provides that “[a]n assertion of any consumer right under section 2 does not apply to pseudonymous data” provided additional protections are met. The word “assertion” implies an affirmative action on the part of the consumer, which may limit the exception to only the consumer rights and not the consent requirement. Furthermore, Section 2, although labeled “Consumer privacy rights,” has distinct subheadings for “(a) Consumer Privacy Rights” and “(b) Consent Required for Processing Sensitive Data.” Although the exception says “any consumer right under section 2,” it could be interpreted to apply only to the rights in subsection 2(a). Nevertheless, pseudonymous data is still subject to a number of protections under the bill, such as data minimization and data security obligations.
Finally, it is notable that this bill does not impose a requirement for controllers to recognize and comply with opt-out preference signals (OOPS) / a universal opt-out mechanism (UOOM). Privacy scholars and advocacy groups have long criticized the control-based model of American privacy law for requiring consumers to affirmatively exercise data rights, which is difficult for consumers to do at scale. A growing number of states—including California, Colorado, Connecticut, Delaware, Maryland, Minnesota, Montana, Nebraska, New Hampshire, New Jersey, Oregon, and Texas—have added the ability for consumers to exercise their opt-out rights on a default basis via a UOOM, such as the Global Privacy Control. While this bill does not require controllers to comply with such signals, it does direct the Secretary of Commerce to conduct a study on the feasibility and efficacy of such tools.
3. Business Obligations
The duties for controllers and processors under this bill largely align with those commonly found in state comprehensive privacy laws. For example, controllers are subject to procedural data minimization and purpose limitation requirements that tie data collection and processing to what is disclosed in a controller’s privacy notice. This is consistent with the approach taken in most of the state privacy laws. A controller must—
Limit the collection of personal data to what is adequate, relevant, and reasonably necessary in relation to the purposes for which such data is processed, as disclosed to the consumer; and
Obtain the consumer’s consent to process personal data for purposes that are neither reasonably necessary to nor compatible with the disclosed purposes for which such data is processed, as disclosed to the consumer.
Data security is another requirement that closely tracks the language adopted in almost every state comprehensive privacy law. A controller is required to establish, implement, and maintain reasonable data security practices to protect the confidentiality, integrity, and accessibility of personal data, and such practices must be appropriate to the volume and nature of the personal data at issue. While this is consistent with the language commonly seen in the state laws, the bill deviates slightly by adding a rebuttable presumption that a controller has taken appropriate security measures if the controller (1) complies with a relevant code of conduct (see below) or (2) has data security practices that are “state-of-the-art . . . including such a practice demonstrated by adherence to a widely-accepted technical specification or through a third-party attestation” and its security program “reasonably conforms to a relevant Federal or widely-accepted international risk management framework.”
Controllers are also subject to familiar requirements, such as providing a privacy notice that meets enumerated criteria (including a more novel requirement that the privacy notice disclose if personal data has been transferred to, processed in, stored in, or sold to North Korea, China, Russia, or Iran), a prohibition on processing personal data in violation of civil rights law, and oversight/contractual requirements with respect to their processors.
Notably absent from the bill is a requirement to conduct data protection impact assessments (DPIAs). All of the state comprehensive privacy laws except those in Alabama, Iowa, and Utah require some form of assessment for processing activities that present a heightened risk of harm to consumers. DPIAs are also a core component of most industry best practices.
4. Youth Privacy
As is commonly the case in comprehensive privacy laws, the bill classifies personal data of children (under 13) as sensitive data. However, the bill extends this classification to all teens’ data (aged 13 through 15), requires parental consent for teen data processing and consumer rights, and omits a defined knowledge standard—representing a meaningful departure from typical state (and federal) approaches. Additionally, this bill does not include a duty of care or heightened privacy protections and risk assessment requirements, such as those adopted in Connecticut, Colorado, and Montana.
As discussed above, controllers would be prohibited from processing a consumer’s sensitive data without consent. Consistent with the state laws, there is a clarification that processing the sensitive data of a child (although this is normally restricted to a “known child”) must be done in accordance with the Children’s Online Privacy Protection Act (COPPA). This bill goes further, however, by also requiring the verifiable consent of a parent to process the sensitive data of a teen. In turn, VPC, under the bill, would require direct notice to the parent and unambiguous pre-collection authorization for both initial and subsequent personal data processing or use. Note that “sensitive data of a child” or “sensitive data of a teen” means any personal data of either category because sensitive data includes “personal data collected from a child or teen.”
Furthermore, consumer rights requests on behalf of children and teens would only be exercised by a parent, defined broadly to include natural parents, adoptive parents, legal guardians, and those with legal custody. This is arguably narrower than under the state laws, which often provide that a parent or guardian “may” invoke rights on behalf of the child. Similar to state laws that aim to deconflict consumer rights requests with COPPA requirements, controllers who comply with consumer rights processes under COPPA for children’s data requests would be deemed compliant with consumer rights requirements under this bill. These parental rights with respect to processing teens’ sensitive data and invoking teens’ data rights are a contrast to the state privacy laws. While a growing number of states envision some layer of heightened protections for teens, these laws typically do not require parental consent for processing the data of minors above the age of 12, broadly maintaining teen autonomy over data collection and processing decisions.
The bill notably omits a knowledge standard for child and teen requirements—arguably creating ambiguity regarding when controllers should be on notice to implement age-specific protections and obligations. In contrast, state privacy laws commonly utilize either “actual knowledge” or “actual knowledge or wilful disregards” standards. Note that Congress is concurrently considering several other youth privacy and online safety legislative proposals—including COPPA 2.0 and the App Store Accountability Act—which could inform the future trajectory of this bill’s minor-specific protections and age-based knowledge triggers among related frameworks.
5. Novel Requirements: Data Brokers, Cross-Border Data Transfers, and Codes of Conduct
While the majority of this bill borrows heavily from existing laws in states like Kentucky and Tennessee, it includes a few requirements that are either atypical or completely novel: data broker registration, explicit authority for the Secretary of Commerce to advise on cross-border data transfers, and Codes of Conduct under the law.
First, the bill requires data brokers to register with the FTC, which would then publish a searchable registry. Similar requirements are seen in standalone data broker registry laws in Vermont, California, Nevada, Texas, and Oregon, though each varies in definitions and specific obligations. California’s Delete Act goes the furthest by creating an accessible deletion mechanism that allows a consumer to submit a deletion request to all registered data brokers. Compared to most state data broker laws, however, the bill’s definition of “data broker” is fairly narrow, covering a controller that (i) collects and processes personal data of a consumer who is not a customer or client of the controller or a user, reader, or subscriber of a product or service by the controller and (ii) derives at least 50% of its annual gross revenue from selling personal data. “Data broker” does not include a person acting as a processor.
A novel addition to this bill compared to past iterations of a federal privacy framework are provisions concerning international data flows and the protection of personal data in international commerce. Notably, though, the bill does not propose any restrictions for the transfer of personal data of US persons across borders. On the contrary, the provisions seem to converge towards supporting the international flow of personal data.
The bill would designate the Secretary of Commerce as the President’s principal advisor on international personal data flows and empower the Secretary to: assess foreign governments’ data protection frameworks for alignment with the bill’s protections; develop policy recommendations addressing topics such as the impact of international data flows on consumer rights, economic competitiveness, and U.S. security interests, including mitigation of risks posed to the international flow of personal data by “covered nations” (i.e., North Korea, China, Russia, and Iran); and negotiate international agreements with foreign governments, forums, or political and economic unions to promote cross-border data flows. The latter provision would seemingly cover agreements such as the existing EU/UK/Switzerland – U.S. Data Privacy Framework, opening the possibility for such agreements with other nations or political unions as well (more ambiguous is how the provision would relate to coverage of cross-border data transfers in international trade agreements, like the US-Mexico-Canada Agreement and the US-Japan Digital Trade Agreement). The concept of “assessing” foreign governments’ data protection frameworks for “alignment” with the protections in the bill is reminiscent of “adequacy assessments” in global international data transfers legal regimes. A data protection regime found adequate usually means that personal data can flow with no restrictions to that foreign nation. However, it is not clear to what end the assessment proposed in the bill would be conducted.
Finally, one of the more interesting additions to the bill is codes of conduct. Any controller or processor (or group thereof) would be able to submit an application to the Secretary of Commerce for “approval of a code of conduct that meets or exceeds the requirements . . . under this Act.” Such a code of conduct must include an independent organization to administer the code, assess compliance, and refer would-be violators to the FTC or a state attorney general. There would be a public comment period prior to approval, and the Secretary could later withdraw approval. Controllers or processors in compliance with an approved code of conduct would be entitled to a rebuttable presumption that they are in compliance with the relevant requirements of the Act. These codes of conduct appear loosely comparable to the safe harbor program provided in the COPPA Rule. Notably, a certification by the controller pursuant to the Global Cross Border Privacy Rules system (or any successor system) or a a processor pursuant to the Global Cross Border Privacy Rules System Privacy Recognition for Processors (or any successor system) would be treated as participation in an approved code of conduct. This appears to be inspired by similar provisions in Tennessee’s law and is consistent with efforts across successive U.S. administrations to promote the Global CBPR system.
6. Preemption
With respect to state law, the bill includes broad preemption language that would prohibit any state, or political subdivision of a state, from prescribing, maintaining, or enforcing any law, rule, regulation, or other provision if it “relates to the provisions of this Act.” This broad “relates to” standard could preempt:
State comprehensive privacy laws;
Sectoral privacy laws including Illinois BIPA, Washington My Health My Data Act, and kids’ privacy laws; and
Data broker laws, including the California Delete Act and state data broker registration requirements.
Nonetheless, if this law passed, preemption would not be automatic. State laws would need to be challenged individually in court to determine whether specific provisions conflict with or “relate to” the federal law. For example, the CCPA/CPRA may be more difficult to fully preempt because it covers employee data, B2B data, and applicant data—categories the federal bill exempts.
With respect to federal law, the bill explicitly preserves a number of federal privacy laws and regulations, including COPPA, GLBA, HIPAA, FCRA, and FERPA (to the extent a controller or processor is an educational agency or institution). The Communications Act of 1934 and any FCC regulations promulgated under that law would not apply to a controller or processor with respect to the collection, use, processing, transferring, or security of personal data. This bill would repeal the Video Privacy Protection Act (VPPA), 18 U.S.C. § 2710.
7. Enforcement
Enforcement authority for violations of the bill would be given exclusively to the FTC and state attorneys general. This approach is consistent with all of the state comprehensive privacy laws—but for California’s narrow private right of action (PRA) with respect to data breaches, none of the state comprehensive privacy laws include a PRA.
The FTC would enforce violations of the bill as a violation of a trade regulation rule regarding unfair or deceptive acts or practices under the FTC Act. The FTC would also be authorized to enforce the bill against common carriers under the Communications Act of 1934. Notably, the FTC would be prohibited from enforcing any violation of section 3(c) of the bill, which prohibits a controller from processing personal data in violation of a federal law that prohibits unlawful discrimination against a consumer. Rather, the FTC would be directed to transmit any information indicating a violation of that provision to any agency with authority to initiate an enforcement action concerning it.
The bill also empowers state attorneys general as parens patriae to bring civil actions seeking injunctive relief, damages, restitution, and other legal and equitable relief. Prior to filing an action, a state AG must provide the FTC with written notice of the action, allowing the FTC to intervene in the matter. A state AG would be prohibited from bringing an action against any defendant named in an ongoing civil action under the bill instituted by the FTC or the Attorney General of the United States (note: this is the only reference to the Attorney General of the United States under the bill). Overall, this enforcement structure is conceptually similar to that under COPPA, under which the FTC is the federal enforcement authority but state attorneys general are empowered to pursue actions providing that they notify the FTC, which has the right to intervene. It is notable that the state enforcement authority is limited solely to attorneys general whereas prior efforts such as the ADPPA and the APRA included carve-outs for a “State Privacy Authority of a State” or “an officer or office of a State authorized to enforce privacy or data security laws.” Without a comparable exception, CalPrivacy would not be able to enforce this bill.
The bill includes a right to cure, requiring the FTC or a state AG to provide notice of an alleged violation and allowing 45 days for the controller or processor to cure the violation and promise that no such further violation shall occur. The state privacy laws are split as to whether they include a right to cure—some include no right to cure, some include a permissive cure option at the AG’s discretion, some have a right to cure that will sunset after a set date, and some have a mandatory right to cure with no sunset provision. An additional source of flexibility is the addition of codes of conduct (discussed below) which can entitle a participating controller or processor to a rebuttable presumption of compliance with this bill.
8. Conclusion
It’s a running joke in the privacy community that important bills always drop on Friday afternoons or holidays, so it was no surprise that this bill was released on everyone’s favorite spring holiday—Earth Day. Humor aside, a federal comprehensive privacy law is long overdue, and it is encouraging to see Congress renewing its attention to this topic. It remains to be seen whether the SECURE Data Act will fare better than prior efforts such as the ADPPA and the APRA. Although it appears that significant partisan consensus building has already gone into this process, which could ease the bill’s passage through committee, time is running out for the 119th United States Congress.
What is already evident, however, is how much influence the state comprehensive privacy landscape exerted on this bill as compared to prior efforts. The bill’s key terms, rights, obligations, and overall structure closely resemble that of most of the state comprehensive privacy laws, based on the flexible WPA framework, even if the specific provisions selected hew more closely to the narrower iterations of that framework. We note that a number of the exclusions or omissions in the bill are likely intended to create a margin for negotiations with other members and stakeholders in order to garner support. Although the time frame is uncertain, this bill is the first significant proposal drafted to reflect the current landscape of state laws that already protect a majority of U.S. residents and may reflect a first draft of a framework that eventually becomes law.
FPF will continue to monitor how this bill evolves as it progresses through committee and a broad set of stakeholders across industry, civil society, and academia provide their feedback.
FPF on the Securing and Establishing Consumer Uniform Rights and Enforcement Over Data (“SECURE Data”) Act
The U.S. is overdue to adopt comprehensive federal consumer privacy legislation. Baseline protections for personal information in a federal privacy law would provide an essential foundation for progress on other Congressional priorities, including AI governance and youth online safety, and it’s encouraging to see Congress renewing its attention to this topic. In the absence of a federal law, twenty-one states have enacted comprehensive privacy laws that, while varying in detail, have generally converged around a common framework. The “SECURE Data Act” largely follows that consensus model, which could facilitate compliance for businesses already navigating state requirements. However, several states have taken different approaches or amended their laws in recent years, including expansions related to health data, minors’ data, and geolocation—raising questions about the extent to which a federal baseline should reflect these alternatives. Arriving at consensus will require careful analysis of which state provisions represent essential protections versus regulatory variation, and consultation with diverse stakeholders including industry, consumer advocates, state regulators, and technical experts. – Matthew Reisman, FPF Vice President for U.S. Policy
The Alabama Personal Data Protection Act Brings Consumer Privacy to the Heart of Dixie
We had to wait almost two years between when the 19th and 20th state comprehensive privacy laws were enacted, but the gap between the 20th and 21st proved to be a mere month. Governor Ivey signed HB 351, the Alabama Personal Data Protection Act (APDPA) into law on April 16. While this law is based on the popular Washington Privacy Act framework, it departs from that framework in a few ways (most notably in terms of what it is missing). For example, the law lacks a requirement to conduct data protection assessments and makes only passing references to authorized agents and opt-out preference signals.
The APDPA will go into effect on May 1, 2027. This blog post provides an overview of the law’s scope, definitions, consumer rights, business obligations, and enforcement provisions.
Scope
Covered Entities: The APDPA includes low applicability thresholds, applying to persons that conduct business in, or target products or services to the residents of, Alabama and either (1) control or process the personal data of more than 25,000 consumers (excluding data processed solely for completing a payment transaction), or (2) derive more than 25% of gross revenue from selling personal data, regardless of the number of consumers whose personal data is processed or sold. These thresholds are low. Most state comprehensive privacy laws set the main processing threshold at 100,000 affected consumers and the data sales revenue threshold usually also requires a minimum number of affected consumers (e.g., 25,000). For a list of applicability thresholds in other laws, see page 34 in FPF’s report on the state comprehensive privacy laws.
Entity and Data-Level Exemptions: This law includes a broad set of entity-level exemptions, including familiar exemptions for political subdivisions of the state, institutions of higher education, national securities associations, financial institutions and affiliates subject to 15 U.S.C. Chapter 94 or Title V of GLBA, and covered entities and business associates under HIPAA. The law also includes exemptions for certain political organizations and business entities that sell data primarily to certain political organizations. The law’s data-level exemptions include protected health information under HIPAA (in addition to other health and research -related exemptions), personal data covered by GLBA, personal information used for activities regulated by and authorized under FCRA, personal data regulated by FERPA, and more. Exceptions for Common Business Activities: Consistent with other state privacy laws, the APDPA includes a list of broad exceptions, such as: complying with federal, state, and local laws, regulations, inquiries, and investigations; preparing legal defenses; providing a product or service specifically requested by a consumer; performing a contract to which a consumer is a party or taking steps at the request of a consumer prior to entering a contract; taking immediate steps to protect an interest essential for the life or physical safety of an individual; preventing, detecting, or responding to security incidents or illegal activity; engaging in public or peer-reviewed research or processing in the interest of public health, subject to enumerated safeguards; internal research for product improvement; internal operations reasonably aligned with consumers’ expectations; and more.
Is there a small business exemption? State comprehensive privacy laws typically try to exclude small businesses, either by imposing high processing thresholds or by including an exemption for small businesses as a defined term. The APDPA includes a small business exemption, but the language departs from what other states have done. The law provides: “This act shall not apply to any of the following: . . . A business, including an organization cooperatively organized under Chapter 6 of Title 37, Code of Alabama 1975, or an entity that is an instrumentality of a municipal corporation, with fewer than 500 employees, provided the business does not engage in the sale of personal data.” The nonprofit exemption similarly applies only to nonprofits of a certain size (fewer than 100 employees) and who do not sell personal data.
As drafted, the small business exemption is a little ambiguous. Based on the original language in the bill as introduced, the intent appears to be to broadly exclude businesses with fewer than 500 employees that do not sell personal data. However, the added language concerning cooperatively organized public utilities and entities that are instrumentalities of a municipal corporation could be read as narrowing the exemption to apply only to such entities. The distinction lies in whether the language “or an entity that is an instrumentality of a municipal corporation” applies to “[a] business” or “an organization cooperatively organized . . . .”
Assuming the broader interpretation is correct and this applies to businesses other than those that are instrumentalities of municipalities, this exception is nonetheless different than how other states—Texas, Nebraska, and Minnesota—have approached this issue. Those states’ laws exempt “small businesses” as defined by the U.S. Small Business Administration—a definition that varies based on industry—and allow small businesses to sell sensitive data with a consumer’s consent.
Definitions
The definitions generally align with the majority of state comprehensive privacy laws. For example: biometric data includes information generated from a photograph, video, or audio recording if used to identify an individual; consumer is defined as an individual acting in their personal (non-employment) capacity; controller is defined as an entity that determines the purposes and means of processing personal data; personal data is defined as any information that is linked or reasonably linkable to an identified or identifiable individual and does not include deidentified data or publicly available information; and there is nothing novel in the definition of sensitive data.
One unique definition worth noting is the “sale of personal data.” The most common definition under state comprehensive privacy laws is the exchange of personal data for monetary or other valuable consideration by the controller to a third party. (See, e.g., Conn. Gen. Stat. § 42-515). Under the APDPA, a sale of personal data means the exchange of personal data (1) for monetary consideration by a controller to a third party, or (2) “for other valuable consideration by a controller to a third party where the controller receives a material benefit and the third party is not restricted in its subsequent uses of the personal data.” The “other valuable consideration” prong is potentially narrower than other laws that do not explicitly limit sales to exchanges where the data-recipient is “not restricted” in how they subsequently use the data. Depending on how specific a “restriction” on subsequent use must be, this could bring a number of data sharing agreements outside of the scope of the consumer opt-out right. More importantly, however, a sale of personal data does not include a “disclosure or transfer of personal data to a third party for the purposes of providing analytics services.” Given the prevalence of data-sharing for analytics agreements, this exception could narrow the consumer right to opt-out of the sale of personal data.
Consumer Rights
This law includes the standard suite of consumer rights to: confirm whether one’s personal data is being processed and to access such data; correct inaccuracies in one’s personal data; have one’s personal data deleted; obtain a copy of one’s personal data in a portable format; and opt-out of the processing of one’s personal data for the purposes of targeted advertising, the sale of one’s personal data, and profiling in further of solely automated significant decisions concerning a consumer. Controllers must allow consumers to revoke previously given consent. These rights (including the opt-out right) do not apply to pseudonymous data if the controller is able to demonstrate that information necessary to identify the consumer is kept separately and subject to effective technical and organizational controls that prevent the controller from accessing the information.
State comprehensive privacy laws typically allow consumers to exercise their opt-out rights via an authorized agent and, increasingly, via opt-out preference signals (“OOPS”). OOPS are usually introduced with a delayed effective date and a number of requirements for such a signal to be valid (e.g., it may not unfairly disadvantage another controller or make use of a default setting). This law does not explicitly provide for authorized agents or OOPS. However, the law does include a tacit acknowledge that a controller must comply with an OOPS because it describes what a controller must do if an OOPS conflicts with a consumer’s existing controller-specific privacy setting or voluntary participation in a controller’s bona fide loyalty program: “[T]he controller shall comply with the consumer’s opt-out preference signal but may notify the consumer of the conflict and provide the choice to confirm controller-specific privacy settings or participation in such a program.” Similarly, the only reference to an “authorized agent” comes when the law specifies that the means for consumers to exercise rights must consider “the ability of the controller to authenticate the identity of the consumer or authorized agent making the request” (emphasis added). These passing references to OOPS and authorized agents create significant ambiguity for controllers as to when they must comply with an OOPS or an authorized agent request (and, for authorized agents, which rights would be in scope).
Business Obligations
Controllers and processors have enumerated responsibilities under the law, including transparency, data minimization, data security, non-retaliation, oversight of processors, and consent requirements for adolescents. Notably, this law does not require controllers to conduct data protection assessments for processing activities that pose a heightened risk of harm, breaking from the majority of state comprehensive privacy laws.
Transparency: A controller is required to provide consumers with a “reasonably accurate, clear, and meaningful privacy notice” that includes required information, such as categories of personal data processed and processing purposes. Processing personal data for targeted advertising or selling personal data to third parties must be clearly and conspicuously disclosed in addition to how to opt-out of such.
A controller must limit the collection of personal data to what is adequate, relevant, and reasonably necessary in relation to the purposes for which the personal data is processed, as disclosed by the controller;
A controller cannot process personal data for purposes that are not reasonably necessary to, or compatible with, the disclosed purposes for which the personal data is processed, as disclosed by the controller; and
A controller cannot process a consumer’s sensitive data without obtaining the consumer’s consent.
Data Security: A controller must establish, implement, and maintain reasonable administrative, technical, and physical data security practices to protect personal data.
Non-retaliation: Controllers are prohibited from denying goods or services or providing a different level of quality for goods or services to a consumer in response to a consumer exercising an op-t-out right, subject to exceptions (e.g., if the data is necessary to providing a service or the data is processed in connection with a bona fide loyalty program). The law separately provides that, if a controller responds to a consumer opt-out request by informing the consumer of a charge for using a product or service, the controller must present the terms of any financial incentive for the retention, use, or disclosure of the consumer’s personal data.
Processors: Processors are required to adhere to the instructions of a controller and assist the controller in meeting its obligations under the law, including by assisting the controller in responding to consumer rights requests as appropriate. There must be a valid contract in place between the controller and processor that meets statutory criteria (e.g., setting forth instructions for processing data, imposing a duty of confidentiality with respect to the personal data, obligating subcontractors to meet the processor’s obligations).
Adolescent Privacy: This law approaches children’s and adolescents’ privacy similar to other state privacy laws. Personal data collected from a known child is considered sensitive data, a parent or legal guardian of a known child may exercise the consumer’s rights on behalf of the known child, and a controller cannot process personal data concerning a known child unless the processing is in accordance with COPPA. Additionally, the law has heightened protections for teenagers. Consistent with a growing minority of the state privacy laws—California, Montana, Oregon, Delaware, New Jersey, New Hampshire, and Minnesota—Alabama has heightened protections for teenagers. For consumers whom the controller has actual knowledge are at least 13 years of age but younger than 16, the controller cannot process the consumer’s personal data for targeted advertising or sell the personal data without the consumer’s consent.
Enforcement
The law will go into effect on May 1, 2027 and will be enforced by the attorney general. The enforcement language is slightly ambiguous with respect to private rights of action (PRA). It is common under other state privacy laws to explicitly foreclose private lawsuits by providing that the law will be enforced “exclusively” by the attorney general and that nothing in the law will be interpreted as a basis for a private right of action under that law “or any other law.” (See, e.g., Conn. Gen. Stat. § 42-525(d).) The APDPA, in contrast, merely provides that “[t]he Attorney General may enforce violations of this act.” Absent a disclaimer to the contrary, plaintiffs may try to allege that a violation of the APDPA gives rise to a cause of action under another law.
The law includes a mandatory cure period, requiring the AG to notify a controller of alleged violations and allowing 45 days to resolve violations. Civil penalties for violations are higher than most other states—up to $15,000 per violation.

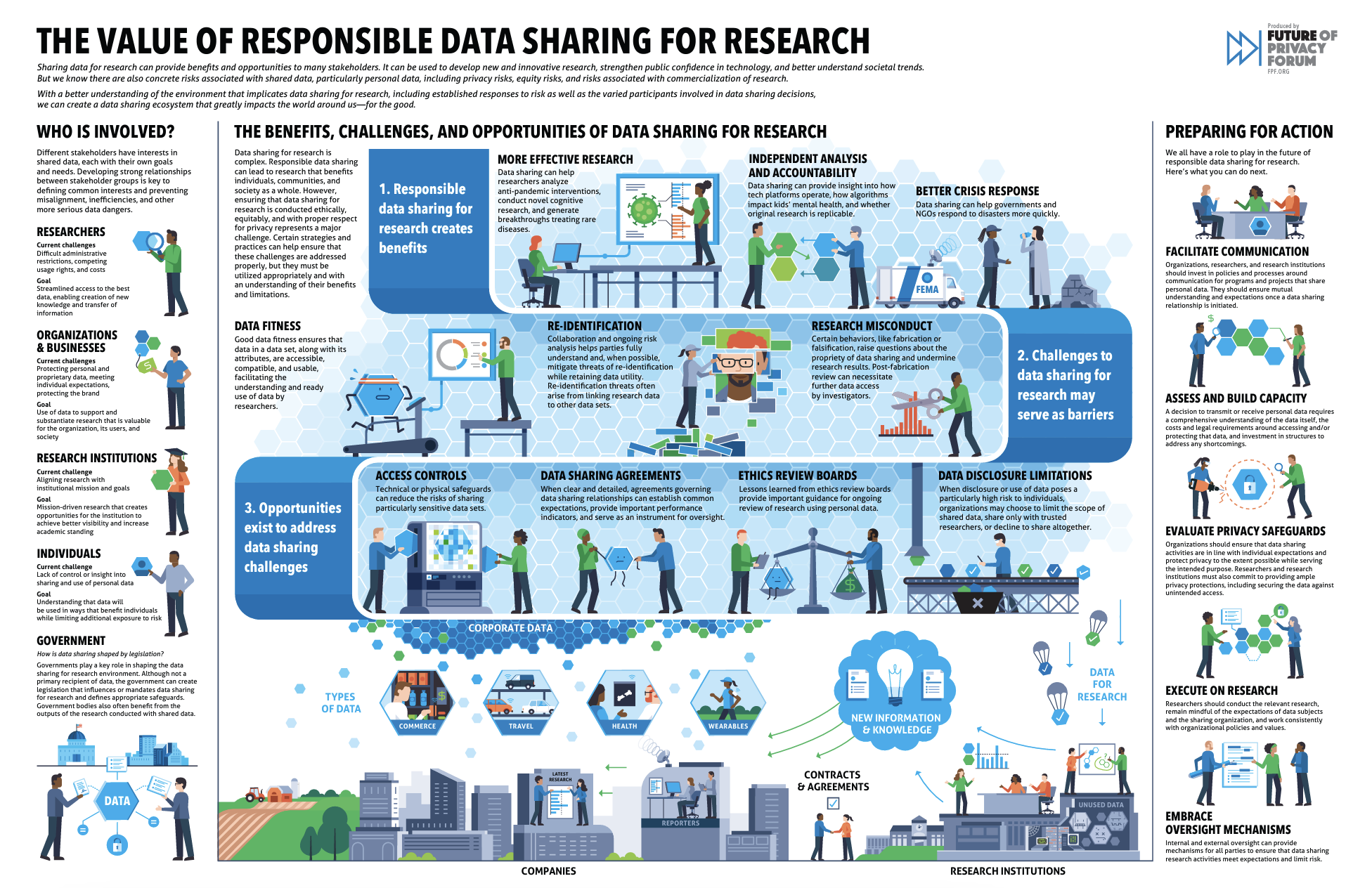




















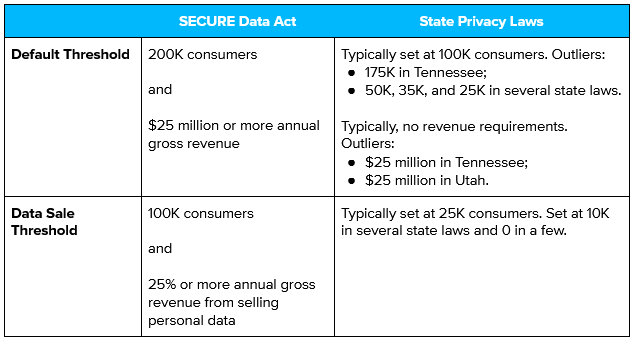

{kind=link}